가상 A/B 테스트 데이터 소개 및 t_score 추출
A/B 테스트 시스템은 런타임 시스템과 분석 시스템 두 개로
구성되는데 이에 대해 살펴보자
테이블 소개
Production DB에 저장되는 정보들을 Data Warehouse로 적재했다고 가정
-
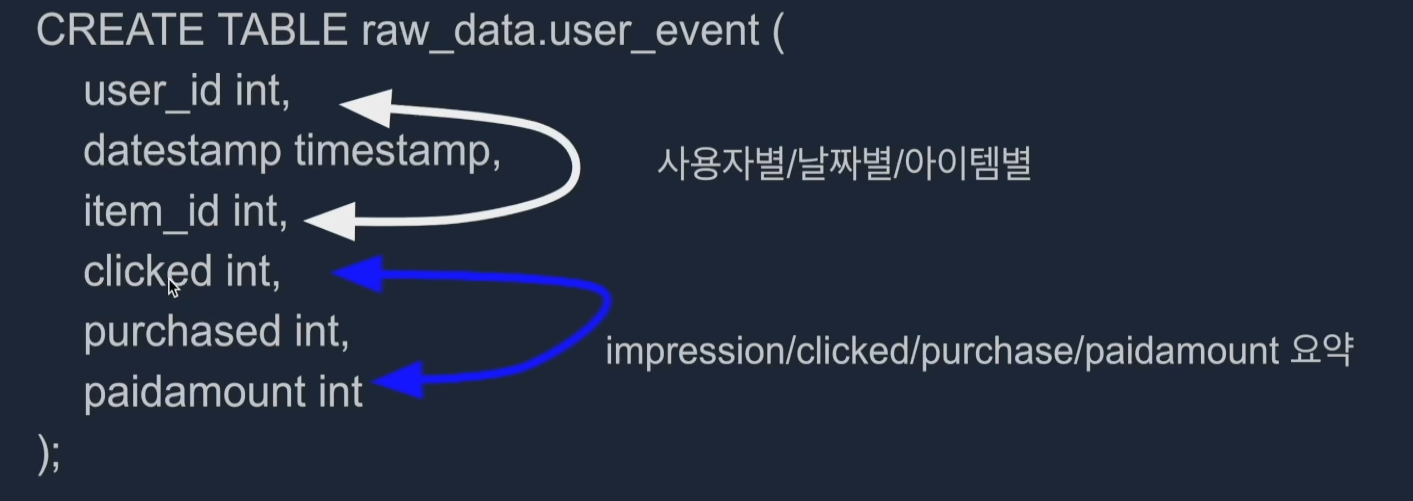
raw_data.user_event
- 사용자/날짜/아이템별로 impression이 있는 경우 그 정보를 기록하고 impression으로부터
클릭, 구매, 구매시 금액을 기록. 실제 환경에서는 이런 aggregate 정보를 로그 파일등의 소스
(하나 이상의 소스가 될 수도 있음)로부터 만들어내는 프로세스가 필요함
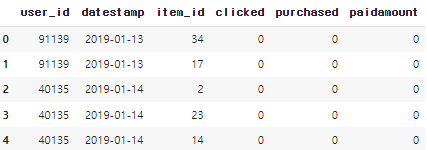
- 사용자/날짜/아이템별로 impression이 있는 경우 그 정보를 기록하고 impression으로부터
-
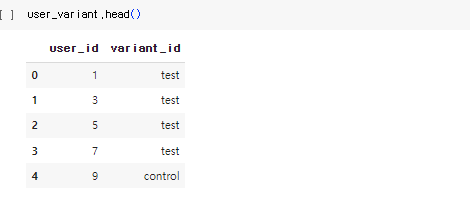
raw_data.user_variant
- 사용자가 소속한 AB test variant를 기록한 파일 (control vs. test)

-
raw_data.user_metadata
- 사용자에 관한 메타 정보가 기록된 파일 (성별, 나이 등등)

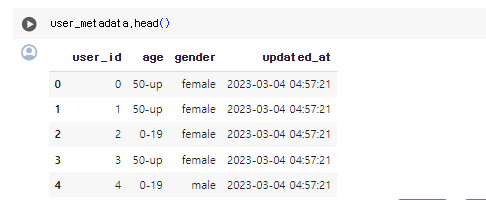
- 사용자에 관한 메타 정보가 기록된 파일 (성별, 나이 등등)
이제 각 테이블을 조인해서
고객별
총 impression
총 click
총 purchase
총 revenue
등을 한번에 볼 수 있는 요약 테이블을 만들어보자.
실습 진행
- variant_daily_sessions 이라는 요약 테이블 생성
CREATE TABLE analytics.variant_daily_sessions AS
SELECT
variant_id,
user_id,
datestamp,
count(distinct item_id) num_of_items, -- 총 impression
sum(clicked) num_of_clicks, -- 총 click
sum(purchased) num_of_purchases, -- 총 purchase
sum(paidamount) revenue -- 총 revenue
FROM raw_data.user_event ue
JOIN raw_data.user_variant uv ON ue.user_id = uv.user_id
GROUP by 1, 2, 3;
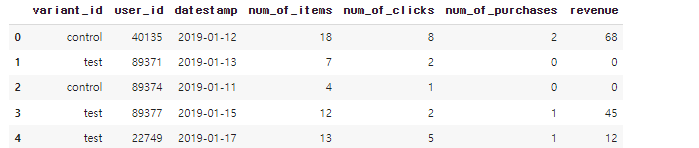
- variant_id별 유저 수 확인
variant_daily_sessions.groupby('variant_id').size()출력값
variant_id
control 82526
test 83116
dtype: int64
해당 두 값이 95% 신뢰구간에 따라 50:50이어야 된다.
z-score 또는 p-value로 파악
- variant_id별 매출 비교
variant_daily_sessions.groupby('variant_id')["revenue"].mean() #매출평출력값
variant_id
control 5.590990
test 5.570203
Name: revenue, dtype: float64
두 값이 동일해야 됨.
이는 t-test를 통해 파악할 수 있다.
근데 딱 봐도 동일해 보임.
이후에는 해당 데이터를 기반으로 t-score를 계산하는 방식을 진행해보자
Two Sample T-test 진행
Two Sample T-test이란?
두 개의 값을 비교할때 사용하는 테스트
결과값은 t-score로 나옴.
샘플의 크기가 크다면 z-score와 동일한 결과가 나온다.
위에서 추출한
variant_id 별 사용자 가 50:50으로 잘 나누어져 있나 확인해 보자.
- T-Test 공식 요약
- x1과 x2는 각 집단의 평균
n1과 n2는 각 집단의 크기
s1과 s2는 각 집단의 표준편차
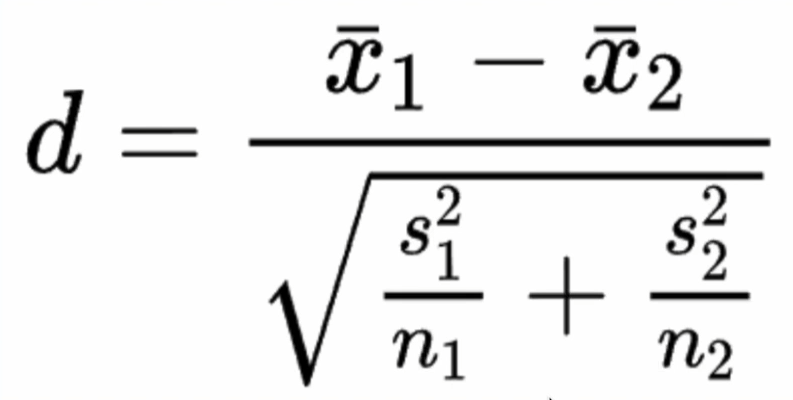
- x1과 x2는 각 집단의 평균
t-score 계산 - 함수 사용
scipy.stats.ttest_ind를 이용한 t-score 계산 진행!
그러기 위해서는 variant_id 별 비교 데이터가 배열 또는 리스트의 형태로 있어야 된다.
- 각 variant_id별 매출 정보를 배열 형태로 추출
from scipy import stats
# control 그룹에 속한 매출액 정보를 numpy 배열로 받아오기
a = variant_daily_sessions[variant_daily_sessions["variant_id"]=="control"]["revenue"].to_numpy()
# test 그룹에 속한 매출액 정보를 numpy 배열로 받아오기
b = variant_daily_sessions[variant_daily_sessions["variant_id"]=="test"]["revenue"].to_numpy() 
stats.ttest_ind()를 통해 t-score와 p-value를 계산
# ttest_ind 함수를 사용해서 두 그룹의 값들을 비교
# 이 함수는 t-score (사실상 z-score)와 p value를 계산해서 리턴해줌
t, p = stats.ttest_ind(b, a)
print(t, p)추출값 : -0.30893666944286313 0.7573700906452349
- t-score의 경우 -0.308이 나왔다.
-1.96~1.96 사이이므로 두 값은 동일하다고 볼 수 있다. - p-value의 경우 0.75가 나왔다.
0.5이상이므로 두 값은 동일하다고 볼 수 있다.
t-score 계산 - 직접 계산
Python의 경우 함수가 있기에 쉽게 계산이 가능하지만,
테블로와 같은 BI툴에 적용하기 위해서는 직접 식을 사용할 줄 알아야 된다.
계산방법
- 그룹별로 크기와 평균과 각 원소 제곱의 합을 알면 계산 가능
- mean_b와 mean_a (평균)
- n_b와 n_a (크기)
- square_b와 square_a (제곱의 평균)
- 먼저 variance(표준편차의 제곱)은 아래와 같이 계산
- var_b = square_b - mean_b*mean_b
- var_a = square_a - mean_a*mean_a
- 최종 t-score는 아래와 같이 계산
- (mean_b - mean_a)/math.sqrt(var_b/n_b + var_a/n_a)
코드
- 데이터 값,
평균,
제곱 평균을 구해줌.
n_a = 82526
n_b = 83116
mean_a = 5.590990
mean_b = 5.570203
square_a = 219.259967
square_b = 217.960044
- 아래의 계산 진행.
var_b = square_b - mean_bmean_b
var_a = square_a - mean_amean_a
import math
var_a = (square_a - mean_a*mean_a)
var_b = (square_b - mean_b*mean_b)
print(var_a, var_b)출력값 : 188.0007978199 186.932882538791
- t-score 계산
(mean_b - mean_a)/math.sqrt(var_b/n_b + var_a/n_a)
t_score = (mean_b - mean_a)/math.sqrt(var_a/n_a+var_b/n_b)
print(t_score)출력값 : -0.3089440714048208
