실습 환경 세팅
import pandas as pd
rich_df = pd.read_csv('TopRichestInWorld.csv',usecols=['Country/Territory','Industry'])
rich_df
rich_country = pd.read_csv('TopRichestInWorld.csv',usecols=['Country/Territory']).squeeze()
rich_country데이터 프레임 생성 : 'Country/Territory','Industry' 컬럼이 있는 rich_df 데이터 프레임과
Series 생성 : 'Country/Territory’ 정보가 있는 rich_country Series를 생성해줬다.
.**value_counts()**
rich_country의 데이터별 갯수를 구해보자
rich_country.value_counts()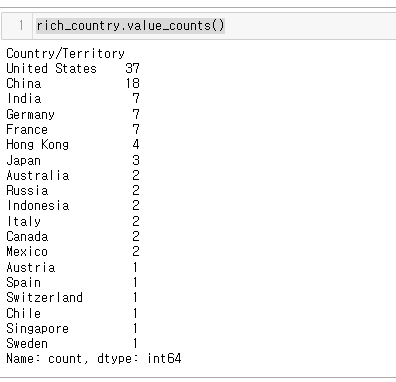
문제!
강의에서 갑자기 문제를 내셨다!
문제1) TopRichestInWorld.csv 에서 산업열만 가져오기
rich_industry = pd.read_csv('TopRichestInWorld.csv',usecols=['Industry']).squeeze()
rich_industry문제2) 부자들이 가장 많이 하는 산업 구하기
rich_industry.value_counts()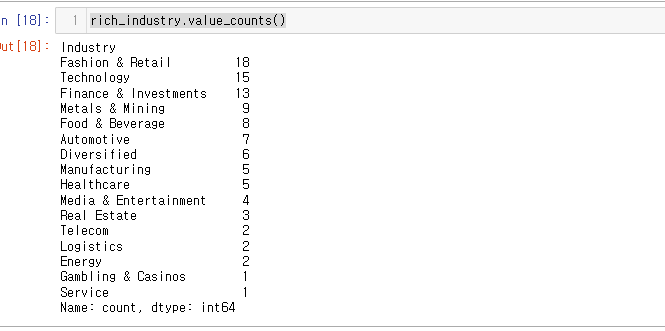
정답은 Fashion & Retail !
**normalize= - 정규화**
- 정규화란 백분율로 만드는 것을 뜻한다.
- value_counts() 인자 값 중 하나로 default 값은
normalize = False이다.
rich_country.value_counts(normalize = True)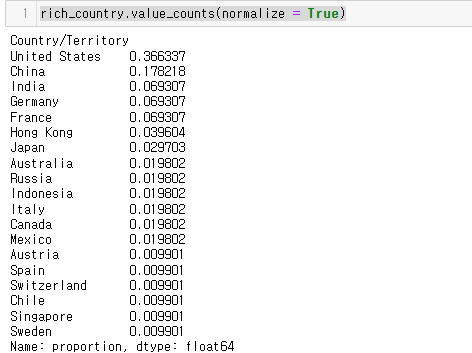
미국이 36%, 중국이 17% 이다.
rich_country.value_counts(normalize = True).sum()
모든 %를 더하면 1이 나올 것이다.
만약 1이 안나온다면 뭐가 잘못된 것!
bins=
- 계급(구간)과 도수를 구해주는 함수
- 도수분포표를 만들때 사용
- bins가 지정이 되지 않으면 고유 값의 빈도로 카운트
- 숫자처럼 연속형 데이터만 사용 가능
- 아래 실습에서 사용한 나이같은 데이터만 사용 가능.
- 나라, 산업같은 데이터는 실행 불가
실습
rich_age = pd.read_csv('TopRichestInWorld.csv',usecols=['Age']).squeeze()
rich_age나이를 가지고 있는 함수를 만들어 준다.
이후 이 나이의 구간을 5개로 나누고자 한다면
rich_age.value_counts(bins = 5)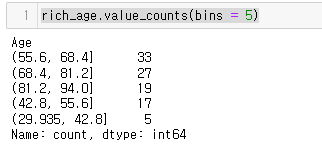
계급별 도수를 구해준다.
dropna= -NaN처리
- 기본적으로
dropna=True의 값을 가지고 있다.
실습
결측치가 있는 리스트를 만들어보자.
data = ['banana',None, 'apple', 'banana', 'apple']
data_set = pd.Series(data)
data_set이후 value_counts 메소드를 사용하게 된다면
data_set.value_counts()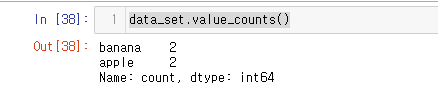
None 데이터는 구해지지 않는다.
이때 인자값에 dropna=False를 넣어주면 None 데이터도 구해준다.
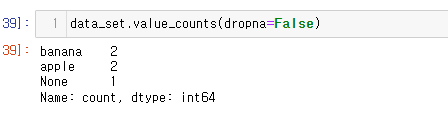
dropna=는 다양한 상황에서 사용할 수 있을 것이다.
예를 들어 value_counts 같은 함수에서도!

LV. 1