이진검색트리
이진검색트리
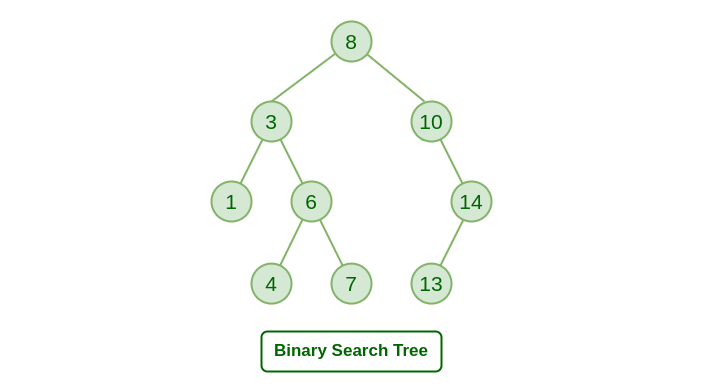
이진 탐색 트리(BST: binary search tree)는 다음과 같은 속성이 있는 이진 트리 자료 구조이다.
- 각 노드에 값이 있다.
- 노드의 왼쪽 서브트리에는 그 노드의 값보다 작은 값들을 지닌 노드들로 이루어져 있다.
- 노드의 오른쪽 서브트리에는 그 노드의 값보다 큰 값들을 지닌 노드들로 이루어져 있다.
- 좌우 하위 트리는 각각이 다시 이진 탐색 트리여야 한다.
- 중복된 값을 허용하지 않는다.
BST를 사용하는 이유
-
효율적인 탐색
BST는 평균적으로 O(log n)의 시간 복잡도로 요소를 탐색할 수 있다. 이는 배열이나 연결 리스트와 비교했을 때 매우 효율적인 성능을 제공한다. -
정렬된 데이터 유지
BST는 삽입 연산 시 자동으로 정렬된 순서를 유지한다. 이를 통해 추가적인 정렬 작업 없이도 데이터를 정렬된 상태로 유지할 수 있다. 이는 중복을 허용하지 않는 경우에 특히 유용하다. -
동적 데이터 관리
BST는 동적으로 데이터를 삽입하고 삭제할 수 있다. 배열과는 달리 크기를 미리 지정할 필요가 없으며, 필요에 따라 노드를 추가하거나 제거할 수 있다. 이를 통해 메모리 효율성을 높일 수 있다. -
범위 검색 (Range Query)
BST는 특정 범위 내의 값을 효율적으로 검색할 수 있다. 예를 들어, 특정 값 이상이면서 특정 값 이하인 요소들을 찾는 작업이 용이하다. 이는 데이터베이스 인덱싱과 같은 응용 분야에서 매우 유용하다. -
순회(traversal) 용이
BST는 다양한 순회 방법(전위 순회, 중위 순회, 후위 순회)을 제공하여 데이터를 다양한 방식으로 처리할 수 있다. 특히, 중위 순회를 사용하면 트리의 요소들을 오름차순으로 방문할 수 있다.
BST의 단점
- 최악의 경우 시간 복잡도
BST의 성능은 트리의 높이에 크게 의존한다. 트리가 균형을 이루지 못하면, 높이가 최대 n이 되어 탐색, 삽입, 삭제 연산의 시간 복잡도가 O(n)이 될 수 있다. 특히, 이미 정렬된 데이터를 삽입하는 경우 트리가 한쪽으로 치우쳐 선형 구조가 되어 성능이 저하된다. - 중복 값 처리
BST는 중복 값을 허용하지 않는다. 중복 값을 허용하려면 트리의 구조와 연산을 변경해야 하며, 이는 구현을 복잡하게 만들 수 있다.
BST의 구현
class BinarySearchTree {
//첫 시작은 root로 해야하기 때문이다.
Node root;
//맨처음 root는 null로 넣고 시작
BinarySearchTree() {
root = null;
}
// 삽입과정
void insert(int key) {
root = insertRec(root, key);
}
Node insertRec(Node root, int key) {
// 맨 처음 root가 비어있다면? 어쩔 수 없다..
if (root == null) {
root = new Node(key);
return root;
}
// 왼쪽 오른쪽 둘중 하나에 넣자.
if (key < root.key) {
root.left = insertRec(root.left, key);
} else if (key > root.key) {
root.right = insertRec(root.right, key);
}
return root;
}
// 탐색
boolean search(int key) {
return searchRec(root, key) != null;
}
Node searchRec(Node root, int key) {
if (root == null || root.key == key) {
return root;
}
if (root.key > key) {
return searchRec(root.left, key);
}
return searchRec(root.right, key);
}
// 삭제
void delete(int key) {
root = deleteRec(root, key);
}
Node deleteRec(Node root, int key) {
if (root == null) {
return root;
}
if (key < root.key) {
root.left = deleteRec(root.left, key);
} else if (key > root.key) {
root.right = deleteRec(root.right, key);
} else {
if (root.left == null) {
return root.right;
} else if (root.right == null) {
return root.left;
}
root.key = minValue(root.right);
root.right = deleteRec(root.right, root.key);
}
return root;
}
int minValue(Node root) {
int minValue = root.key;
while (root.left != null) {
minValue = root.left.key;
root = root.left;
}
return minValue;
}
}
// Node는 key와 왼쪽 오른쪽만 있으면 된다.
class Node {
int key;
Node left, right;
public Node(int item) {
this.key = item;
this.left = null;
this.right = null;
}
}
불균형을 극복하기 위한 방법
- 이진 검색 트리의 유일한 단점은 균형있는 트리를 만들지 못한다는 점이다.
- 이를 해결하기 위해 여러 트리가 도안되었다.
- AVL-tree
- 레드 블랙 트리
대표적으로 위와 같이 2가지가 존재한다. 하지만 일반적으로 레드 블랙 트리를 사용한다 .
특히 TreeSet은 블랙이진트리로 구현된 자료구조이다.
간단하게 레드 블랙 이진트리란?
- 노드는 빨간색 또는 검은색이다.
- 루트 노드는 항상 검은색입니다.
- 모든 리프 노드(NIL 노드)는 검은색이다.
- 빨간색 노드의 자식은 항상 검은색이다 (즉, 빨간색 노드가 연속으로 두 번 나올 수 없습니다).
- 어떤 노드에서든 그 노드로부터 자손인 모든 리프 노드에 이르는 경로에는 동일한 수의 검은색 노드가 포함된다.
필자도 어려워서.. 잘은 모르겠다.
