부스트코스의 딥러닝으로 만드는 질의응답 시스템을 보고 정리한 것입니다.
Passage Retrieval
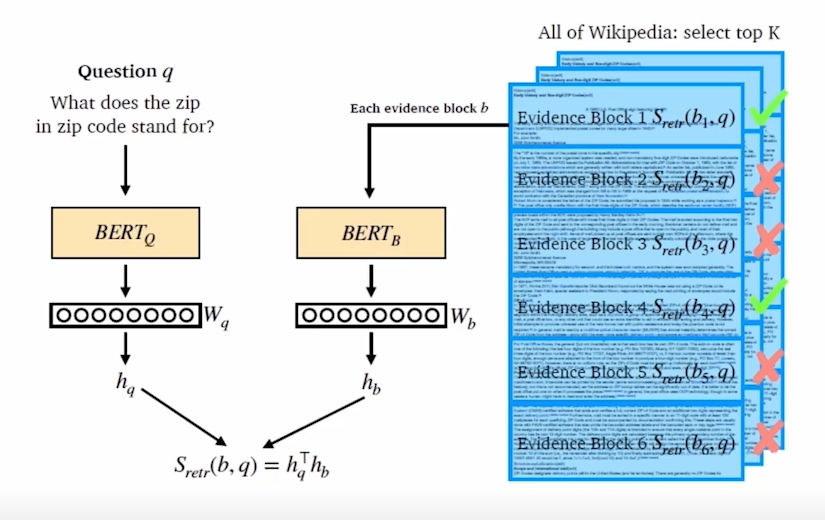
- question, passage 두 부분에 encoder 존재
- question은 입력과 동시에 encoding을 함
- passage는 미리 encoding을 해 둠
- passage의 수가 많아지면 많아질수록 계산량이 증가
Similarity Search
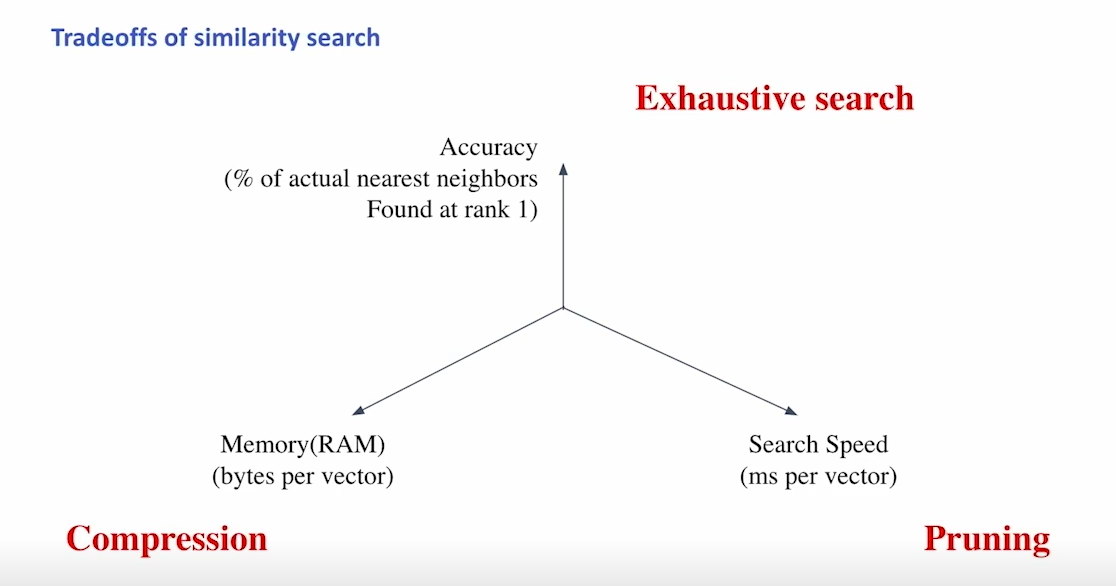
maximum inner product
- 주어진 질문과 passage 사이의 inner dot product를 계산
- 문서의 갯수가 엄청 많은 경우 exhaustive search로 찾는 것은 시간적 비용이 너무 큼
- memory, accuracy, speed 사이의 trade off가 존재
Approximation Similarity Search
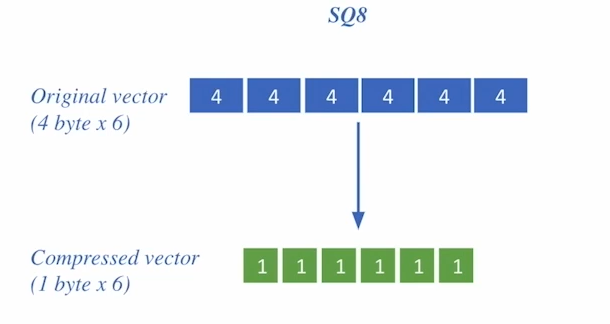
Compression - scalar quantization
- 벡터를 압축하는 방법
- 4byte -> 1byte
- 메모리가 더 적게 들고 정보 손실도 적음
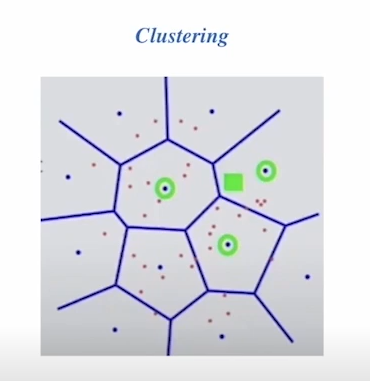
Pruning - inverted file
- search space를 줄여 속도 개선
- 클러스터링을 통하여 미리 벡터공간을 나누어 둠
- 근접한 클러스터에 대해서만 exhaustive search를 진행
Introduction to Faiss
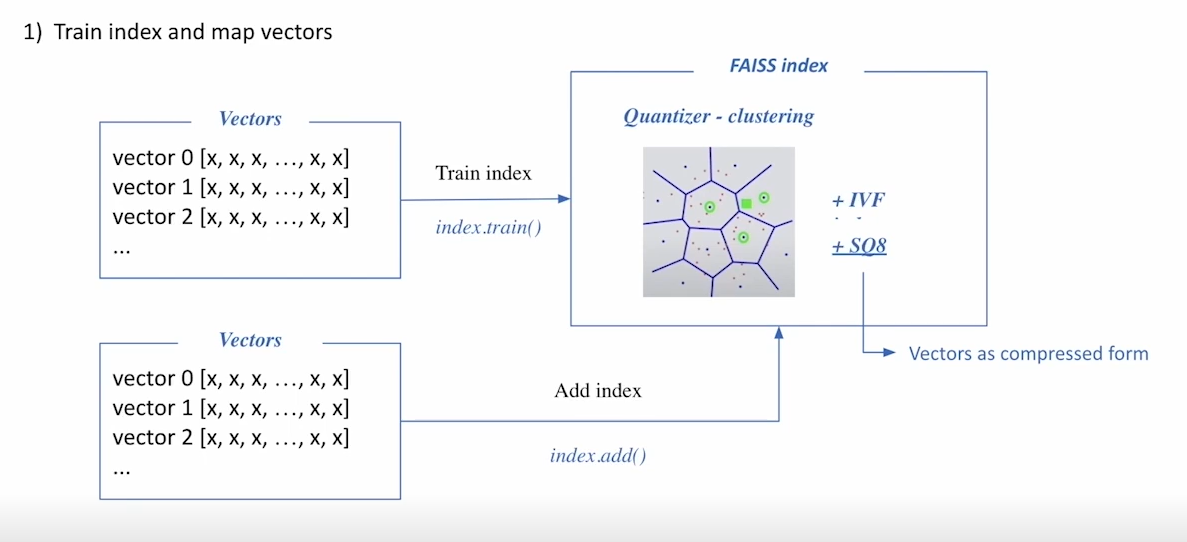
- indexing을 도와주는 것 (embedding을 해주는 것은 아님)
- encoder를 통해 문서벡터를 얻은 후 clustering을 위해 index training 과정을 거침
- 그 후 inference time에 question vector가 들어옴
- 가장 가까운 cluster를 방문해서 cluster 내의 vector을 일일이 비교하여 top-k의 문서 벡터를 추출

NLP취준생