boost course의 딥러닝으로 만드는 질의응답 시스템을 보고 정리하였습니다.
Sparse embedding
- 0인 값이 많아 비효율적
- 유사성 고려 x
Dense Embedding
- 더 작은 차원의 고밀도 벡터로 변환
- 각 차원이 특정 단어에 대응되지 안흠
- 대부분의 요소가 non-zero
- 단어의 유사성 또는 맥락을 파악하는 경우 성능이 뛰어남
- 사전학습 모델의 발달로 훨씬 더 많이 이용
Overview of Dense Embedding
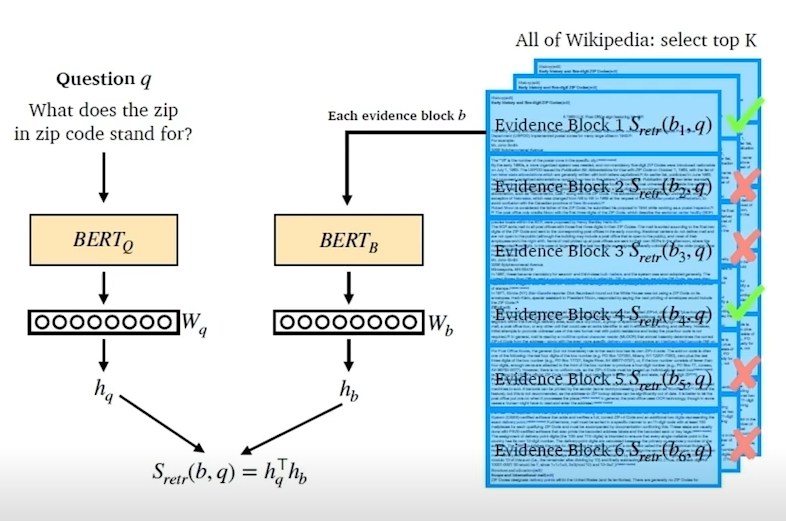
- question과 passage를 인코더를 통하여 벡터형태로 변환
- 두개의 dot product를 통한 유사도 계산
pretraining dense encoder
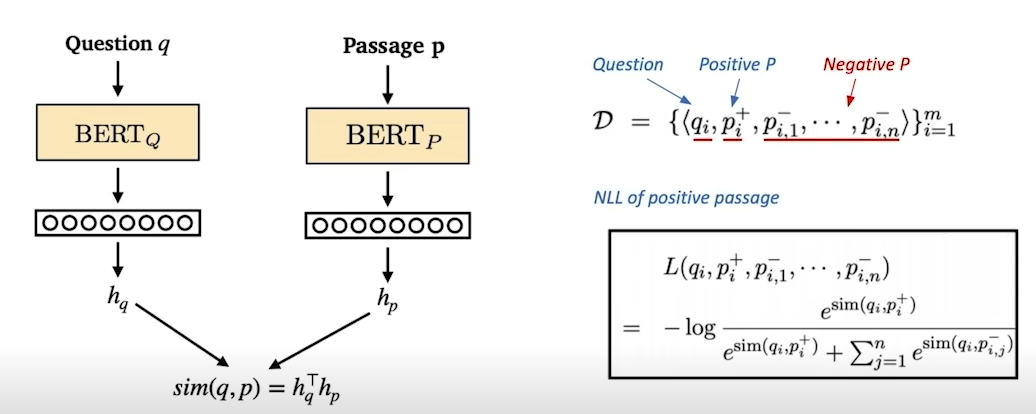
- bert와 같은 사전학습모델을 사용
- question과 passage에 각각 다른 인코더를 사용
- CLS 토큰을 사용

- 학습목표 - question과 embedding 간의 거리를 좁히는 것, dot product score를 높이는 것
- 데이터 셋의 question과 passage의 pair는 기존의 MRC 데이터셋 활용
OBJECT FUNCTION
evaluation
- 실제 MRC 질문에 대한 정답을 가지고 있는지에 대한 여부
Passage Retrieval - Dense Embedding
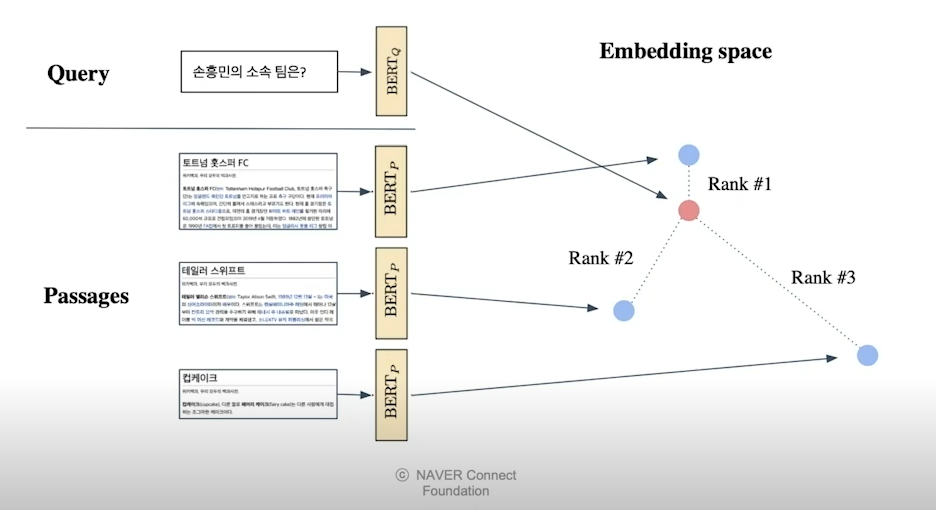
- passage와 query를 각각 임베딩한 후 query로 부터 가장 가까운 순서대로 순위를 매김
- 여기서 나온 passage를 기준으로 MRC task를 수행
how to make better dense embedding
- 학습 방법 개선(DPR)
- 인코더 모델 개선(더 좋은 pretrain model 사용)
- 데이터 개선

NLP취준생