boost course 딥러닝으로 만드는 질의응답 시스템 정리입니다.
MRC(Machine Reading Comprehension)
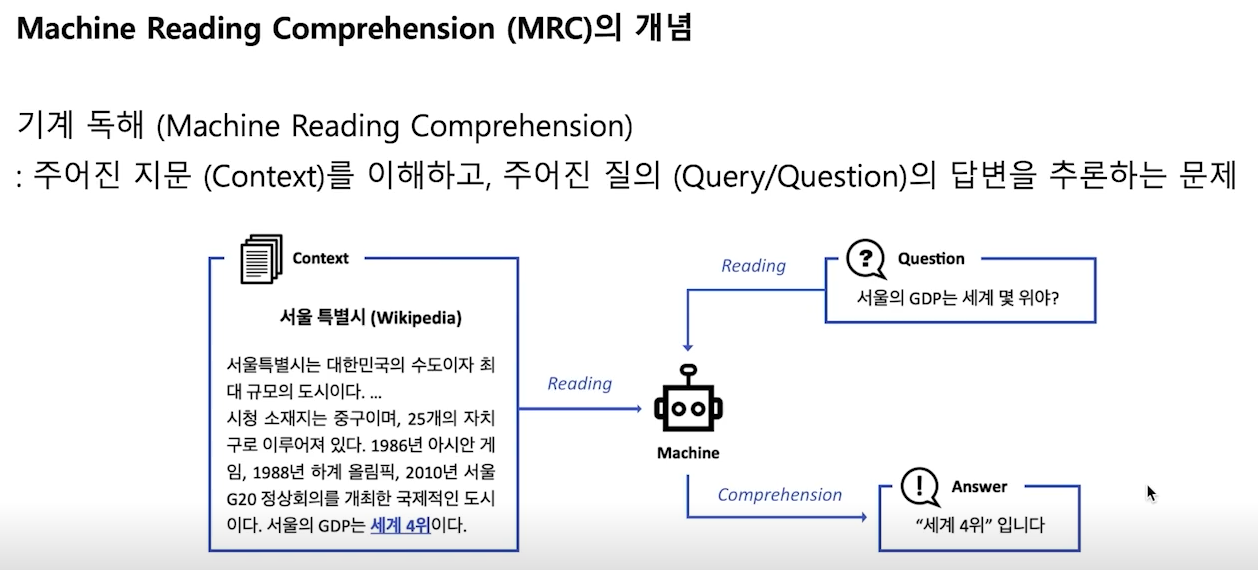
- MRC - 주어진 문단을 이해하고 문단에 기반하여 주어진 질문에 대한 답변을 맞추는 문제
- Input - context(문단), question(질문)
- output - answer(문단에 대한 정답)
Google이나 Naver 등의 검색엔진, 대화 시스템, 인공지능 스피커 등에서 많이 사용
Kinds of MRC
Extractice Answer Datasets

- question에 대한 answer이 주어진 context안에 그데로 span으로 존재하는 경우
- Question & Answering
Descriptive/ Narrative Answer Datasets

- answer이 정답 지문내에서 추출한 span의 형태가 아니라 question을 보고 생성된 sentence의 형태
- 지문 안에 그데로 존재하지 않음
Multiple-choice Datasets

- 질문과 정답에 기반하여 주어진 보기 중 정답을 맞추는 방식
- 다지선다형 문제
Challenges in MRC

pharaphrased paragraph
- 단어들의 구성이 유사하지는 않지만 동일한 의미의 문장을 이해하는 부분에 어려움이 존재
- P1의 경우 문단에서 직접적인 단어들을 언급(selected, mission)
- P2의 경우 문단에서 직접적인 단어들을 언급하지는 않았지만 비슷한 의미를 가진 경우
coreference ewsolution
- 그 사람, 그것 등 특정 사물이나 사람을 지칭하는 단어들이 무었을 지칭하는가에 대한 이해 어려움
unanserable questions

- 정답이 질문안에 존재하지 않는 경우
multi-hop reasoning

- 정답이 여러개의 문서에 퍼져있는 경우
- 여러개의 문서에서 question에 대한 supporting factor를 찾아야 함
Evaluation in MRC
EM(exact match) / F-1 Score
- extractive, multiple-choice에서 사용 (단지 token의 overlap만 고료)
- EM(exact match) - 예측한 정답이 실제 정답과 정확하게 일치하는 샘플의 비율
- 예측한 정답이 실제 정답 사이의 token overlap을 F1으로 계산
ROGUE-L / BLEU Score
- descriptive datasets에서 사용 (n-gram 기반으로 고려)
- ROGUE-L - 예측한 값과 실제값 사이의 overlap recall
- BLEU - 예측한 값과 실제값 사이의 overlap precision
Unicode & Tokenization
Unicode

- 전세계의 문자를 일관되게 표현하고 다룰 수 있도록 만들어진 문자 셋
- 각 문자마다 숫자 하나에 매핑 됨
Encoding
- 문자를 컴퓨터에서 저장 및 처리할 수 있게 이진수로 바꾼 것
Handling Unicode in Python

ord
- 문자를 유니코드 code point로 반환
chr - code point를 문자로 변환
Unicode & Korean

- 완성형 - 한국어의 자음 모음 조합으로 나타낼 수 있는 모든 완성형 한글(가, 각, ...)
- 조합형 - 조합하여 글자를 만들 수 있는 초/중/종성
Tokenization
- 텍스트를 토큰 단위로 나누는 것
- 단어, 띄어쓰기, 형태소, subword를 기준으로 사용
Subword tokenization

- 자주 사용되는 글자 조합은 한 단위로 취급하고, 자주 쓰이지 않느 조합은 subword로 쪼갬
- "##" 은 decoding과정에서 해당 토큰을 앞 토큰에 띄어쓰지 않고 붙여서 표현한다는 의미
BPE(byte-pair encoding)
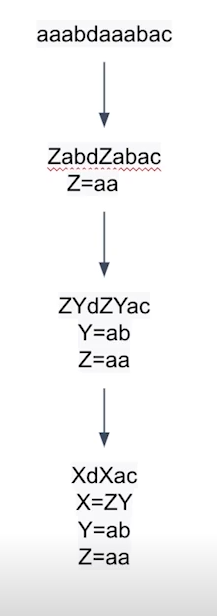
- 데이터 압축용으로 제안된 알고리즘
- 자주 나오는 글자 단위를 다른 글자로 치환
KorQuad
- LG CNS가 AI 언어지능 연구를 위해 공개한 질의응답/기계독해 데이터셋



NLP취준생