boost course의 딥러닝으로 만드는 질의응답 시스템 강의를 보고 복습차원에서 저일한 것입니다.
Extraction-based MRC

- 질문에 대한 답변이 지문내에 span으로 존재하는 경우
- 문제를 정답을 생성하는 것이 아닌 text의 위치를 파악하는 문제로 바꿔 해결
- SQuAD, KorQuAD, NewsQA, etc.
Evaluation of Extraction-based MRC
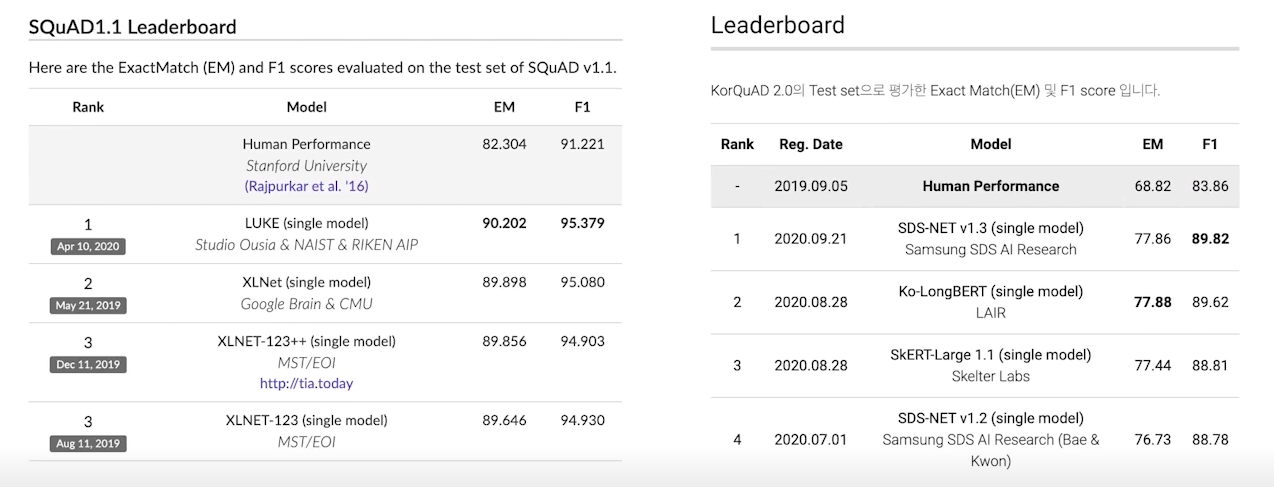
EM(exact match)

- 예측값과 정답의 chatacter 단위가 완전히 똑같은 경우에만 정답처리
F1 Score

- 예측값과 정답의 overlap을 계산
- 0 ~ 1점 사이의 점수를 부여
Overview of Extraction-based MRC
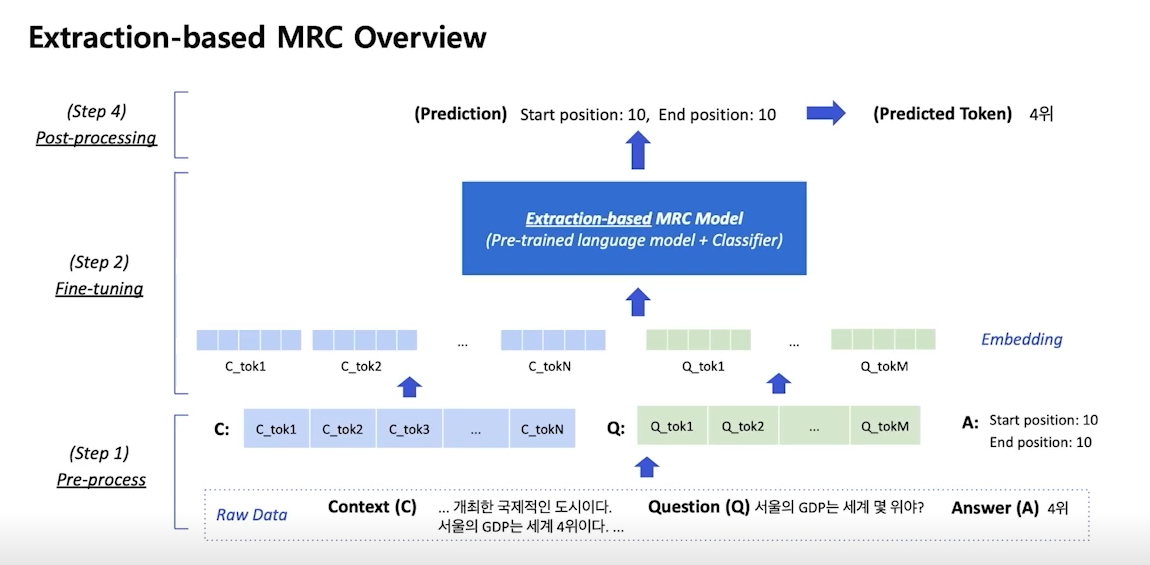
- context와 question의 concat이 입력으로 들어감
- 각 token이 start position 또는 end position이 될 확률을 계산하도록 모델이 학습
- 각 점수 중 가장 높은 점수를 가진 token이 각 position이 됨
Preprocessing
example of inputs


Tokenization
- 텍스트를 작은 단위로 나누는 것(띄어쓰기, 형태소, subword)
- 최근엔 OOV문제를 해결해주고 정보학적 이점을 가진 BPE를 주로 사용(wordpiece tokenizer)

special tokens
- [CLS] - input의 첫부분에 나오는 토큰
- [SEP] - 질문과 문단을 구분해주는 토큰

attention mask
- 입력 sequence 중에서 attention을 할 때에 무시할 토큰을 표시, 입력과 같이 input으로 사용
- 0은 무시, 1은 포함
- [PAD] 토큰으 의미가 없기 때문에 보통 무시

token type IDs
- 입력이 2개 이사으이 시퀀스일 때 각각을 구분하기 위해 사용되는 ID
output
- 정답은 문서 내 존쟈허눈 연속된 토큰아므로 시작과 끝 위치를 알아야 함
- Extraction-based 에선 시작과 끝 위치를 알아내는 token classification의 문제로 학습
Fine-tunning
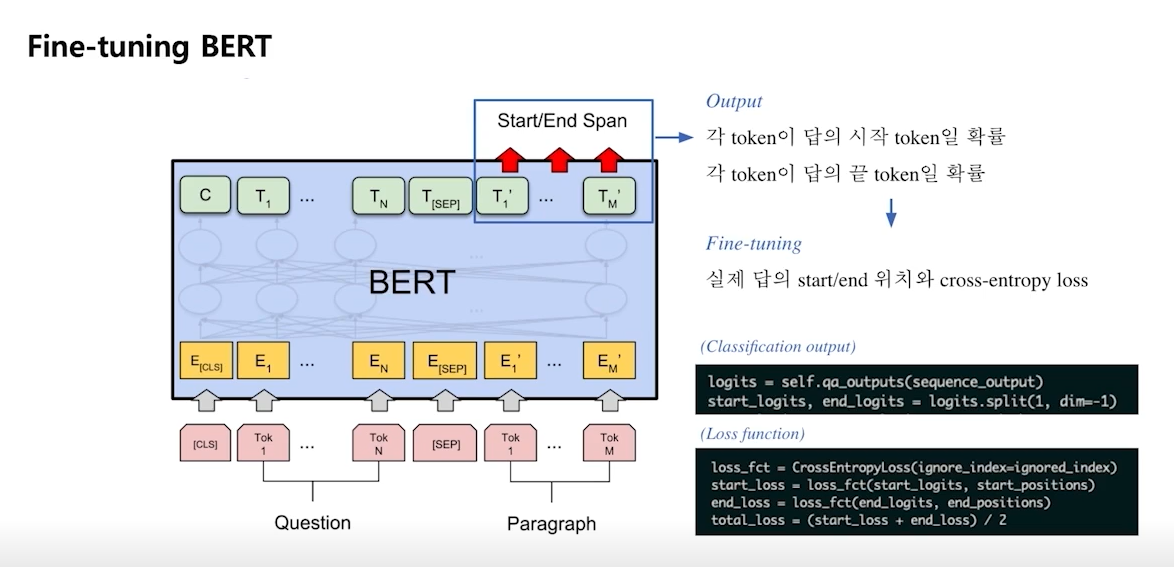
- BERT의 각 token별 output을 linear transformation을 통해 1개의 값으로 변경
- 구해진 하나의 값은 점수로 볼 수 있음
- 위 방법을 start / end position에서 똑같이 실행
Post-processing
불가능한 답 제거
- end position이 start position보다 앞에 있는 경우
- 예측한 position이 context의 범위를 벗어난 경우
- 미리 설정한 max answer length보다 더 긴 경우
최적의 답안 찾기
- start / end position prediction에서 score가 가장 높은 n개를 각각 찾음
- 불가능한 start / end 조합 제거
- 가능한 조합들 중 score가 가장 큰 순서대로 정리
- score가 가장 큰 조합을 prediction으로 사용
- top-k개가 필요한 경우 차례대로 내보냄

NLP취준생