SELECT 문으로 특정 데이터 추출하기
1)데이터를 조회하기 위한 SELECT
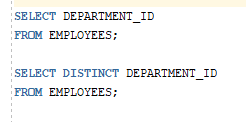
SELECT [DISTINCT] {*,column[Alias],...}
FROM 테이블명;
ex) DEPARTMENTS 테이블의 모든 내용 출력
SELECT * FROM DEPARTMENTS;
쿼리문은 대소문자 구분 없음 다만 값은 대소문자 구분은함
쿼리문은 마지막에 세미콜론 안들어감
ORA-00904: "DEPARTMENT_I": 부적합한 식별
이 오류가 뜨면 식별자이름 잘못 쓴 것 !
ORA-00942: 테이블 또는 뷰가 존재하지 않습니다
사용자가 잘못됐거나
테이블 이름이 잘못 된것!
<문제> 사원의 이름과 급여와 입사일자 만을 출력하는 SQL문을 작성
힌트: 사원 정보가 저장된 테이블은 EMPLOYEES이고, 사원이름 칼럼은 FIRST_NAME, LAST_NAME과, 급여 칼럼은 SALARY 입사일자 칼럼은 HIRE_DATE이다.

작성을 하면
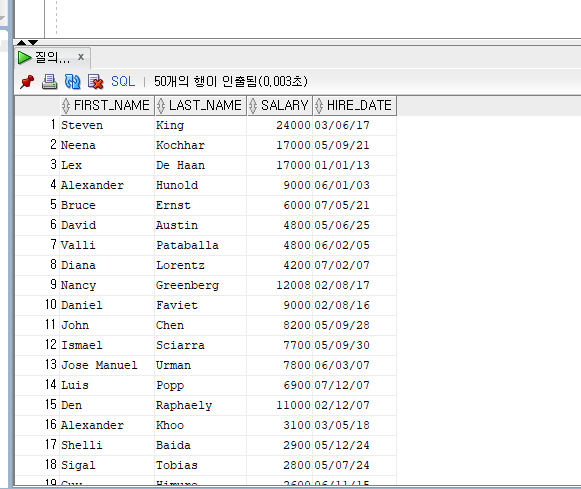
이렇게 나오는걸 확인할 수 있다.
칼럼 이름에 별칭 지정하기
AS로 컬럼에 별칭 부여하기: 칼럼을 기술한 바로 뒤에 AS라는 키워드를 쓴 후 별칭을 기술
SELECT DEPARTMENT_ID AS DepartmentNo, DEPARTMENT_NAME AS DepartmentName
FROM DEPARTMENTS;
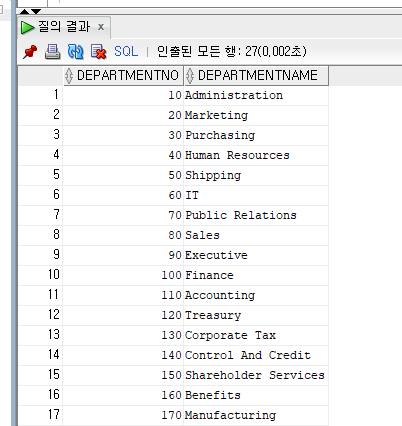
위에 별칭이 바뀐걸 확인할 수 있다. 전체 대문자로 출력됨.
오라클에서는 큰 따옴표 안씀 작은 따옴표만 쓴다
-별칭에 한글,공백문자나 $._,# 등 특수문자를 표현하고 싶거나 대소문자를 구별하고 싶으면 ""을 사용한다.
AS를 생략하고 ""를 사용하여 별칭부여가 가능하다
함수=>별칭
Concatenation 연산자의 정의와 사용(연결 연산자)
오라클에서는 여러 개의 컬럼을 연결할 때 사용하기 위해서 Concatenation 연산자를 제공해 준다. 컬럼과 문자열 사이에 "||"(Concatenation 연산자)를 기술하여 하나로 연결하여 출력하게 된다.
<예> EMPLOYEES 테이블에서 여러 컬럼을 하나의 문자열로 출력
SELECT FIRST_NAME || '의 직급은 ' || JOB_ID ||' 입니다' AS 직급
FROM EMPLOYEES;
결과는 이러하게 나오는걸 확인 할 수 있다.

컬럼 두개를 이어서 하나의 별칭으로 지칭하고싶을 때는 컬럼 ||' ' ||컬럼 AS 별칭
을 쓰자.
중복된 데이터를 한번씩 만 출력하게 하는 DISTINCT
SELECT JOB_ID FROM EMPLOYEES;
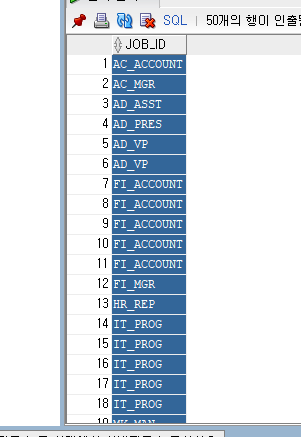
예> EMPLOYEES 테이블에서 칼럼 JOB_ID를 표시하되 중복된 값은 한번만 표시해라
SELECT DISTINCT JOB_ID
FROM EMPLOYEE;
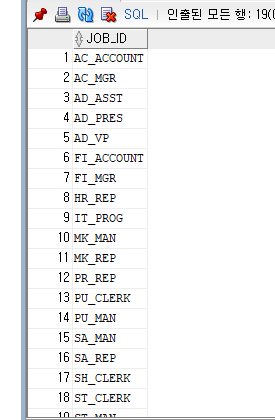
<문제> 직원들이 어떤 부서에 소속되어 있는지 소속 부서번호(DEPARTMENT_ID) 출력하되 중복되지 않고
한번씩 출력하는 쿼리문을 작성하자.
결과를 확인해보면
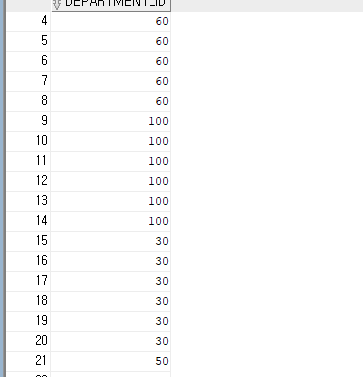
DISTINCT를 사용한 결과값은
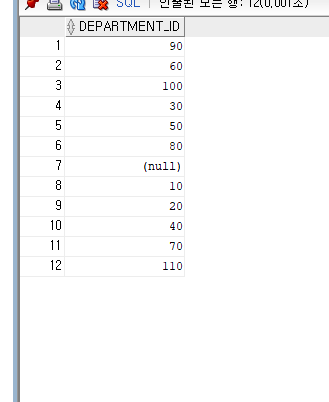
결과를 보면 중복된 값이 사라진 것을 확인 할 수 있다.
(null) 부서에 소속되지 않은 사람 ex) ceo
WHERE 조건과 비교 연산자
SELECT [DISTINCT] {*column[Alias],...}
FROM 테이블명
WHORE 조건들;
-두 쿼리문을 비교
예> 전체 직원을 대상
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY
FROM EMPLOYEES;
예> 급여를 10000 이상 받는 직원들 대상
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE SALARY >= 10000;
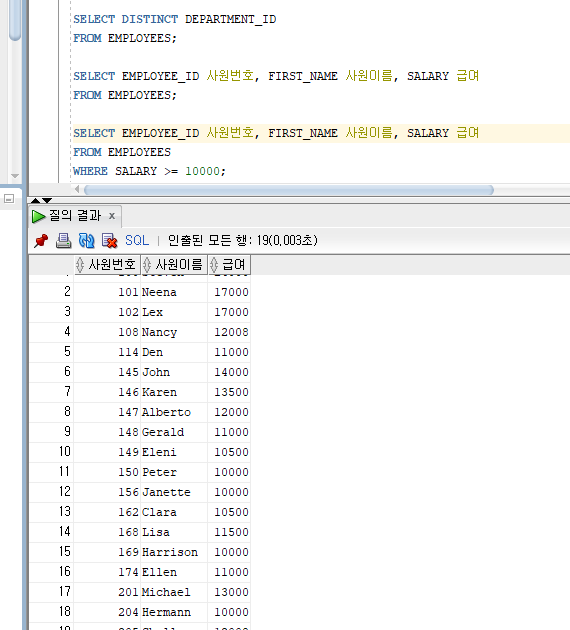
결과를 보면 급여가 10000 이상인 사원들만 보여지는걸 알 수있다.
ㆍ산술 연산자
ㆍ비교연산자
같다 = (값은 대소문자 구별)
같지 않다 <>, !=, ^=
--사원에 급여를 1000인상하여 사원번호, 사원명, 급여, 인상급여, 입사일을 출력하시오.
SELECT EMPLOYEE_ID 사원번호, FIRST_NAME 사원명, SALARY 급여, SALARY+1000 인상급여, HIRE_DATE 입사일
FROM EMPLOYEES;
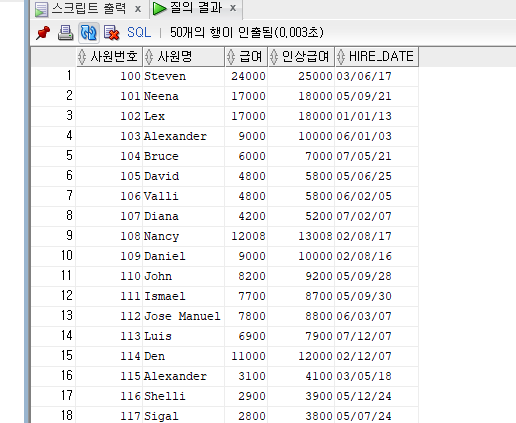
--문자 데이터 조회
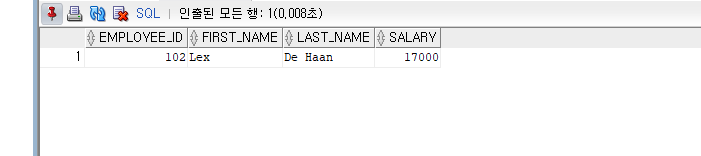
--이름(FIRST_NAME)이 'Lex'인 직원
SELECT EMPLOYEE_ID, FIRST_NAME, LAST_NAME, SALARY
FROM EMPLOYEES WHERE FIRST_NAME='Lex';
--날짜 데이터 조회
--2008년 이후에 입사한 직원
SELECT FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
WHERE HIRE_DATE >= '2008'; -- 에러 발생.리터럴이 형식 문자열과 일치하지 않음(ORA-01861)

아래 코드 처럼 고치고 실행 시켜 보자
SELECT FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
WHERE HIRE_DATE >= '2008/01/01';
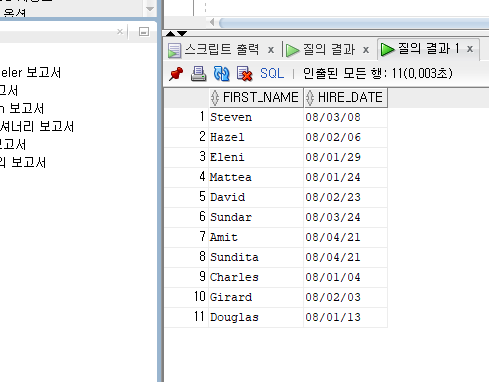
2008/01/01 이후의 값들이 나오는걸 알 수 있다.
ㆍ논리 연산자
AND 연산자
:두 가지 조건중 둘 다 만족하는 값을 검색할 수 있도록 하기 위한 연산자
OR 연산자
:두 가지 조건중에서 한가지만 만족하더라도 검색할 수 있도록 하기 위해서는 OR연산자를 사용한다.
--논리 연산자
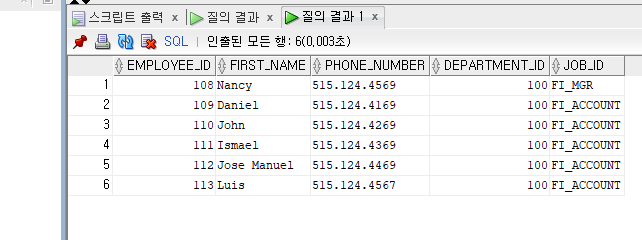
--부서번호가 100번이고 직급이 FI_MGR인 직원
SELECT EMPLOYEE_ID, FIRST_NAME, PHONE_NUMBER, DEPARTMENT_ID , JOB_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 100 OR JOB_ID = 'FI_MGR';
--문제> 급여가 5000에서 10000이하 직원 정보 출력
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY
FROM EMPLOYEES
WHERE SALARY >=5000 AND SALARY <=10000;

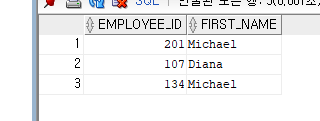
--<문제> 사원번호가 134이거나 201이거나 107인 직원 정보 출력
SELECT EMPLOYEE_ID,FIRST_NAME
FROM EMPLOYEES
WHERE EMPLOYEE_ID= 134 OR EMPLOYEE_ID= 201 OR EMPLOYEE_ID = 107;
NOT 연산자
반대되는 논리값을 구한다.
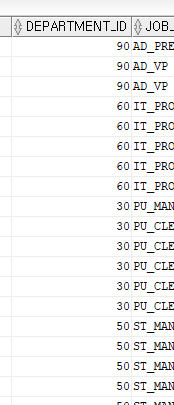
예> 부서번호가 100번이 아닌 직원
SELECT EMPLOYEE_ID,FIRST_NAME, PHONE_NUMBER, DEPARTMENT_ID,JOB_ID
FROM EMPLOYEES
WHERE NOT DEPARTMENT ID = 100;
--<문제> 업무 ID가 FI_MGR가 아닌 직원(모든데이터)
ELECT EMPLOYEE_ID, FIRST_NAME, SALARY , JOB_ID
FROM EMPLOYEES
WHERE JOB_ID<> 'FI_MGR';

--<예> 급여가 2000에서부터 3000까지의 범위에 속한 사원
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY BETWEEN 2000 AND 3000;

BETWEEN AND 연산자
특정 범위 내에 속하는 데이터를 알아보려고 할 때 사용
column_name BETWEEN A AND B
--<문제> 급여가 2500에서 4500까지의 범위에 속한 직원의 직원번호, 이름, 급여를 출력
--<AND 연산자와 BETWEEN AND 연산자 사용)
SELECT EMPLOYEE_ID, FIRST_NAME SALARY
FORM EMPLOYEES
IN 연산자
동일한 칼람이 여러 개의 값중에 하나인지를 살펴보기 위해서 간단하게 표현할 수 있는 IN연산자를 사용한다
OR 대신IN을 사용해 보자
column_name In(A,B,C)
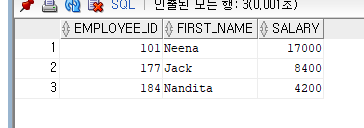
예>직원번호가 177이거나 101이거나 184인 사원
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE EMPLOYEE_ID=177 OR EMPLOYEE_ID=101 OR EMPLOYEE ID = 184;
SELECT EMPLOYEE_ID, FIRST_NAME,SALARY
FROM EMPLOYEES
WHERE EMPLOYEE_ID IN(177,101,184);
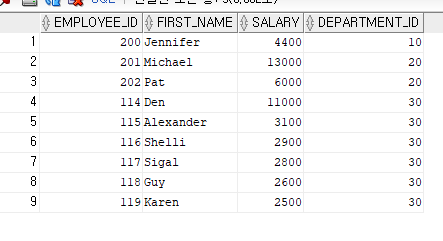
--<문제> 부서번호가 10, 20, 30 중 하나에 소속된 직원의 직원번호, 이름 , 급여를 출력
--(OR 연산자와 IN 연산자 사용)
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY, DEPARTMENT_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID=10 OR DEPARTMENT_ID=20 OR DEPARTMENT_ID=30;
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY, DEPARTMENT_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID IN(10, 20, 30);
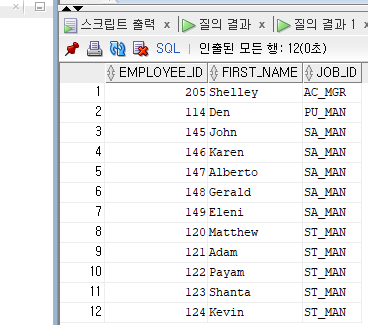
--<문제> 사원테이블에서 JON_ID가 'SA_MAN', 'ST_MAN' , 'PU_MAN', 'AC_MGR'인
--사원번호, 사원명, 직무번호를 출력
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID
FROM EMPLOYEES
WHERE JOB_ID IN('SA_MAN', 'ST_MAN' , 'PU_MAN', 'AC_MGR');
LIKE 연산자
검색하고자 하는 값을 정확히 모를 경우 와일드카드와 함께 사용하여 원하는 내용을 검색하는 연산자.
column_name LIKE pattern
와일드카드 % 문자가 없거나, 하나 이상의 문자가 어떤 값이 오든 상관없다
_ 하나의 문자가 어떤 값이 오든 상관없다.
1)와일드카드(%) 사용하기
%는 검색하고자 하는 값을 정확히 모를 경우 사용. %는 몇 개의 문자가 오든 상관없다는 의미
--<예> 이름이 k로 시작하는 사원
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME LIKE 'k%';
예> 이름 중에 k를 포함하는 사원
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME LIKE '%k%';
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE LOWER(FIRST_NAME) LIKE '%k%';
SELECT EMPLOYEE_ID, LOWER(FIRST_NAME) "FIRST NAME"
FROM EMPLOYEES
WHERE LOWER(FIRST_NAME) LIKE '%k%';
--<예> 이름이 k로 끝나는 사원
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME LIKE '%k';
2)와일드카드(_)사용하기
_는 한 문자를 대신해서 사용한 것
예> 이름의 두 번째 글자가 d인 사원
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME LIKE '_d%';
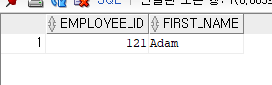

-- 핸드폰번호에서 5번째 1인 레코드를 조회하고자 함.
SELECT EMPLOYEE_ID, FIRST_NAME, PHONE_NUMBER
FROM EMPLOYEES
WHERE phone_number LIKE '____1%';
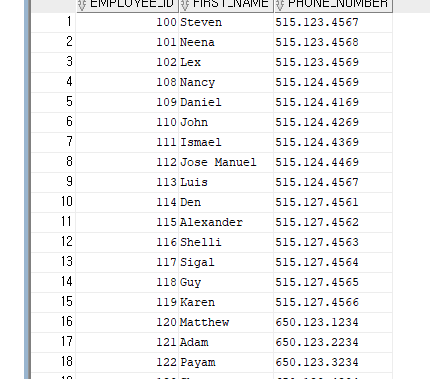
--사원테이블(EMPLOYEES)에서 직무ID에 3번째 _를 포함하고 4번째 자리인 값이 P인 레코드를 조회하고자 함.
SELECT EMPLOYEE_ID,FIRST_NAME,JOB_ID
FROM EMPLOYEES
WHERE JOB_ID LIKE '___P%'
이렇게 사용하면 3번째에 뭘 오든 상관 없다는 뜻이므로 ESCAPE를 사용한다.
--ESCAPE
--LIKE 연산으로 '%'나 ''가 포함돈 문자를 검색하고자 할때 사용된다.
--'%'나 '' 앞에 ESCAPE로 특수문자를 지정하면 검색할수 있다.
--특수문자는 아무거나 상관없이 사용 가능하다.
--구문 마지막에 ESCAPTE 에 사용할 문자열만 지정해주면 '_'나'%' 를 검색에 사용할 수 있게 도와준다.
--사원테이블(EMPLOYEES)에서 직무ID에 3번째 _를 포함하고 4번째 자리인 값이 P인 레코드를 조회하고자 함.
SELECT * FROM EMPLOYEES
WHERE JOB_ID LIKE '___P%' ESCAPE '\';
SELECT * FROM EMPLOYEES
WHERE JOB_ID LIKE '__@_P%' ESCAPE '@';
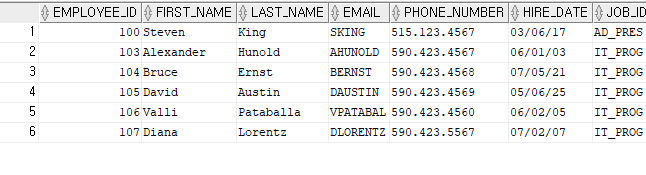
문제> 이름이 a를 포함하지 않은 직원의 직원번호, 이름을 출력
SELECT * FROM EMPLOYEES
WHERE LOWER(FIRST_NAME) NOT LIKE '%a%';
NULL을 위한 연산자
오라클에서는 칼럼에 NULL값이 저장되는 것을 허용
NULL은 미확정, 알 수 없는(unknown) 값을 의미. 0(Zero)도 빈 공간도 아닌 어떤 값이
하지만 어떤 값인지를 알아낼 수 없는 것을 의미한다. NULL은 연산,할당,비교가 불가능하다
예> 100 + NULL = NULL
예> 커미션을 받지 않는 사원에 대한 검색
SELECT EMPLOYEE_ID, FIRST_NAME, COMMISSION_PCT, JOB_ID
FROM EMPLOYEES
WHERE COMMISSION_PCT= NULL;
NULL이 저장되어 있는 경우에는 = 연산자로 판단할 수 없다
--커미션을 받지 않은 사원
SELECT EMPLOYEE_ID, FIRST_NAME, COMMISSION_PCT, JOB_ID
FROM EMPLOYEES
WHERE COMMISSION_PCT IS NULL;
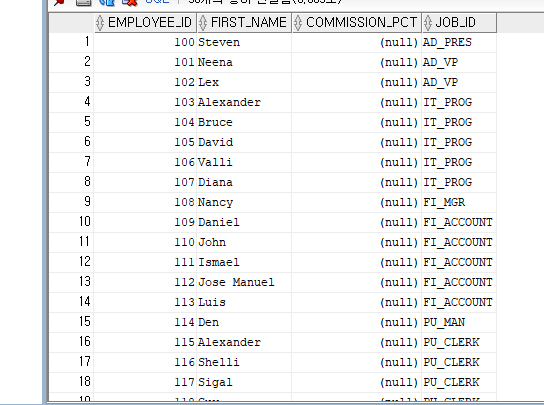
IS NULL과 IS NOT NULL
INS NOT NULL > NULL이 아니면 만족
NULL은 값이 아니므로 = 또는 !=로 비교할 수 없다.
예> 커미션을 받는 사원
SELECT EMPLOYEE_ID, FIRST_NAME, COMMISSION_PCT, JOB_ID
FROM EMPLOYEES
WHERE COMMISSION_PCT IS NOT NULL;
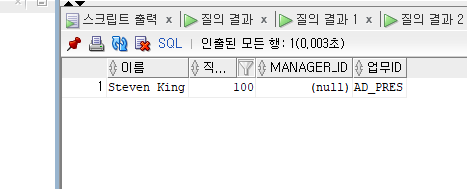
--<문제> 자신의 직속상관이 없는 직원의 전체 이름과 직원번호, 업무ID를 출력
SELECT FIRST_NAME||' '||LAST_NAME 이름,EMPLOYEE_ID 직원번호, manager_id , JOB_ID 업무ID
FROM EMPLOYEES
WHERE MANAGER_ID IS NULL;
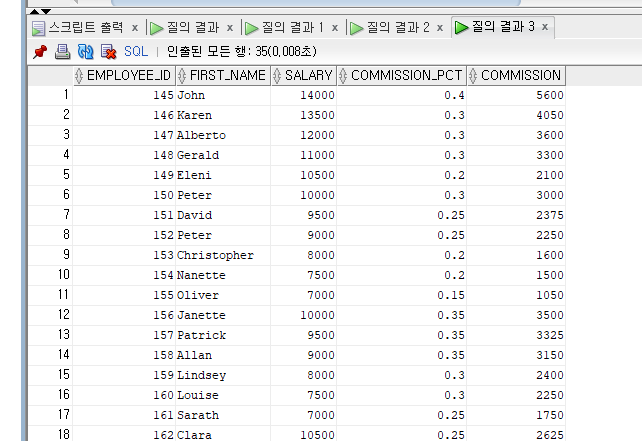
--<문제> 커미션을 받는 사원만 출력하되 사원번호, 이름, 급여, 수당율, 수당금액(계산식 - 급여수당율)을 출력.
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY, COMMISSION_PCT, SALARY COMMISSION_PCT COMMISSION
FROM EMPLOYEES
WHERE commission_pct IS NOT NULL;
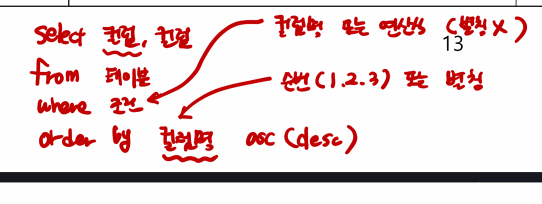
정렬의 ORDER BY 절
ORDER BY 절은 로우(행)을 정렬하는데 사용하며 쿼리문 맨 뒤에 기술해야 하며, 정렬의 기준이되는
칼럼 이름 또는 SELECT 절에서 명시된 별칭을 사용할 수 있다.
ASC(오름차순)
숫자 작은값부터 정렬 문자 사전 순서로 정렬
DESC(내림차순)
숫자 큰 값부터 정렬
문자 사전 반대 순서로 정렬
컬럼명 에 순번(1,2,3)은
SELECT 뒤의 컬럼 순서를 말하는 것
ORDER BY 다음 컬럼명에는 별칭을 사용가능
ASC(오름차순) DESC(내림차순)
날짜 빠른 순서로 정렬 늦은 날짜 순서
NULL 가장 마지막 가장 먼저
경우 소문자를 가장 큰 값으로, NULL값은 모든 값을 중 가장 작은 값으로 인식
기준첨은 첫번째가 기준 같은 값이 존재하면(중복) 그러면 두번째꺼로 정렬
1)오름차순 정렬을 위한 ASC
예>사번을 기준으로 오름차순 정렬
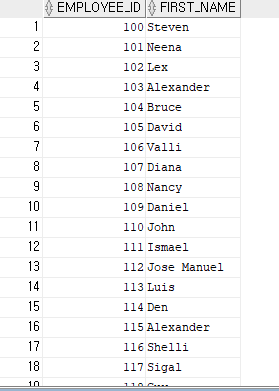
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPPLOYEES
ORDER BY EMPLOYEE_ID ASC(생략가능);
또는
ORDER BY EMPLOYEE_ID;
2)내림차순 정렬 예제
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
ORDER BY EMPLOYEE_ID DESC;
--자바 인덱스:0 ~ 배열의 크기(배열.length)-1. j(0)a(1)v(2)a(3)
--오라클 : 1 ~
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
ORDER BY 1 DESC;
-- ORDER BY 컬럼명( 또는 순번)
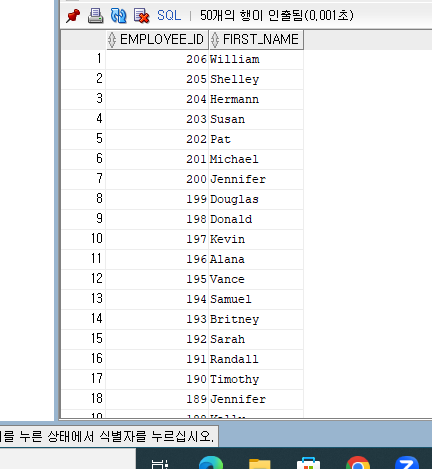
-- NULL을 포함한 컬럼은 ASC: NULL 레코드를 제일 마지막에 / DESC: NULL 레코드를 제일 먼저 출력
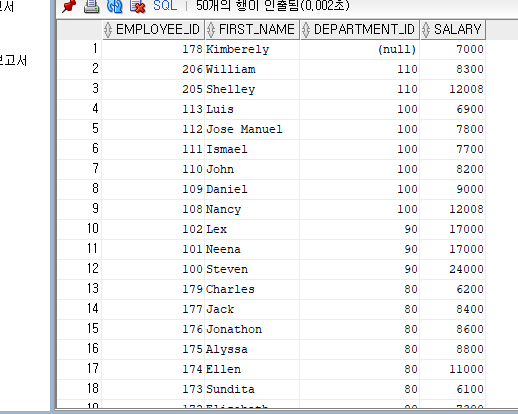
--문제> 직원번호, 이름, 급여, 부서번호를 급여가 높은 순으로 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID,SALARY
FROM EMPLOYEES
ORDER BY 3 DESC, 1 DESC; //첫번째 정렬을 기준으로 하되 같은 급여받는 사람 있으면 사원번호가 낮은 순서대로 정렬
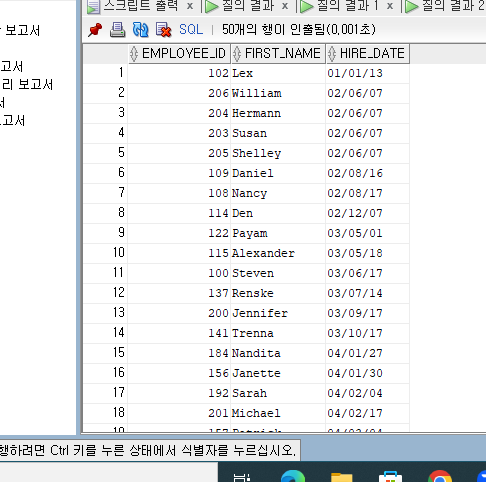
--문제> 입사일이 가장 최근인 직원 순으로 직원번호, 이름 입사일을 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
ORDER BY HIRE_DATE ASC;
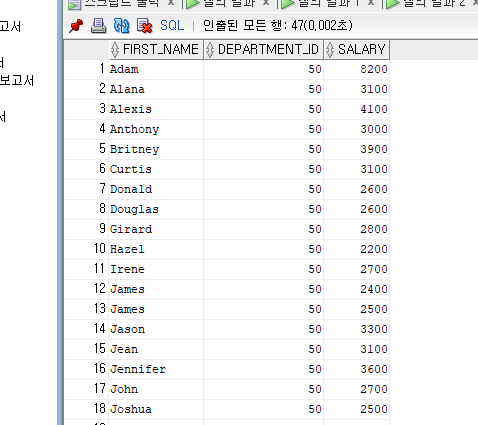
--문제> 부서번호가 20, 50번 부서에서 근무하는 모든 사원들의 이름(FIRST_NAME), 부서 번호, 급여를
--사원의 이름순(알파벳순)으로 출력하라.
SELECT FIRST_NAME, DEPARTMENT_ID, SALARY
FROM EMPLOYEES
WHERE DEPARTMENT_ID IN(20,50)
ORDER BY FIRST_NAME ASC;
테이블 구조를 결정하는 DDL로 테이블 생성, 변경, 삭제
DDL
테이블의 구조 자체를 생성, 수정, 제거하도록 하는 명령문 집합이다.
CREATE ALTER DROP RENAME TRUNCATE
1)CREATE TABLE 테이블 구조 정의: 새로운 테이블을 생성하기 위한 CREATE가 있다.
CREATE TABLE table_name
(column_name data_type expr,...);
칼럼을 정의할때 지정할 수 있는 자료형
CHAR(size)
단위는 byte나 문자수가 된다. char(6 byte)와 char(6 char)으로 정의가 가능한데 그때 영문일 경우는 둘 다 6개의 데이터를 저장할 수 있으며 한글은 char(6 char)에만 6개의 글자를 저장할 수 있다.
고정 길이 문자 데이터. 입력된 자료의 길이와는 상관없이 정해진 길이만큼 저장 영역 차지(문자길이+공백).
데이터 입력하지 않으면 NULL 자동입력, 지정된 길이보다 긴 데이터가 입력시 오류 발생
최대크기 2000byte / 최소크기: 1byte
VARCHAR2(size)
가변 길이 문자 데이터, 실제 입력된 문자열의 길이만큼 저장 영역 차지
최대크기 4000byte / 최소크기: 1 바이트
NUMBER
NUMBER(p)
NUMBER(p,s)
형식: NUMBER(전체 자릿수(p), 소수점 이하 자릿수(s))로 표현되는 숫자 데이터 타입
전체 자릿수만 지정하면 소수점 이하는 반올림되어 정수값만 저장된다. 전체 자릿수도 소수점 이하 자릿수도 모두 생략하면 입력한 데이터만큼 공간이 할당됨.
둘다 지정한 경우 실수 형태의 값이 저장.
최대 22바이트
정밀도(p) : 1~ 38, 디폴트 값은 38 / 스케일(s): -84 ~ 127. 디폴트 값은 0
NUMBER(3): 3자리 수치 (999까지 표현이 가능)
NUMBER(6,2): 소수점 2자리를 포함한 6자리 수치
NVARCHAR 문자열의 바이트가 아닌 문자 갯수 자체를 길이로 취급하여 유니코드를 지원하기 위한 자료형
BLOB 대용량의 바이너리 데이터를 저장하기 위한 데이터 타입.
CLOB 대용량의 텍스트 데이터를 저장하기 위한 데이터 타입.
DATE 날짜 형식을 저장하기 위한 데이터 타입
TIMESTAMP DATE 데이터 타입의 확장된 형태
ROWID 테이블 내 행의 고유 주소를 가지는 64진수 문자 타입.
해당 6 바이트(제한된 ROWID) 또는 10 바이트(확장된 ROWID)
ㆍ 테이블명과 칼럼명을 부여하기 위한 규칙
-반드시 문자(A-Z,a-z)로 시작,컬럼명은 최대 30바이트까지
-A-Z까지의 대ㆍ소문자와 0~9까지의 숫자, 특수기호(_,$,#)만 가능
-오라클에서 사용되는 예약어나 다른 객체명과 중복생성 불가능
-공백을 허용하지 않는다
-대소문자 구별이 없다. 소문자로 저장하려면""로 묶어주어야함
한테이블에서 사용 가능한 컬럼은 최대 255개까지
3)ALTER TABLE로 테이블 구조 변경
ALTER TABLE 명령어는 테이블에서 칼럼의 추가, 삭제, 칼럼의 타입이나 길이를 변경할 때 사용

새로운 칼럼 추가
ALTER TABLE table_name
ADD(column_name data_type expr, ...);
예) EMP01 테이블에 문자 타입의 직급(JOB)칼럼을 추가
ALTER TABLE EMP01
ADD(JOB VARCHAR2(9));
DESC EMP01;

생성을 확인
-- EMP01에 입사일 칼럼(CREDATE)을 날짜형으로 추가
ALTER TABLE EMP01
ADD(CREDATE DATE);
DESC EMP01;

ALTER TABLE로 기존 칼럼 수정
ALTER TABLE명령어에 MODIFY절을 사용하여 칼럼 수정한다. 데이터의 타입,크기를 변경가능
ALTER TABLE table_name
MODIFY(column_name data type expr,...);

예) 직급을 최대 30자까지 입력할 수 있도록 크기 수정
ALTER TABLE EMP01
MODIFY(JOB VARCHAR2(30));
DESC EMP01;

JOB의 자료형 크기가 달라진 걸 확인할 수 있다.
ALTER TABLE로 기존 칼럼명 변경
ALTER TABLE table_name
RENAME COLUMN old name TO new_name;
예> 입사일 컬럼의 이름을 CREDATE 에서 REGDATE로 컬럼명 변경
ALTER TABLE EMP01
RENAME COLUMN CREDATE TO REGDATE;
DESC EMP01;
ALTER TABLE로 기존 칼럼 삭제
ALTER TABLE table_name
DROP COLUMN column_name;
예) 직급 (JOB)칼럼 삭제
ALTER TABLE EMP01
DROP COLUMN JOB;

변경 된 것을 확인할 수 있다.
DESC EMP01;
DROP TALE로 테이블 구조 삭제
테이블을 제거하면 테이블에 저장되어 있는 데이터도 함께 제거된다.
제거된 데이터는 다시 복구하기 힘들기 때문에 명령어 사용시 유의
DROP TABLE table_name;
예> EMP01 테이블을 삭제
DROP TABLE EMP01;
--삭제 확인
SELECT * FROM TAB;
삭제된걸 확인.
