recyclebin 구조 확인
desc recyclebin;
--휴지통(recyclebin) 보기
SELECT * FROM recyclebin;
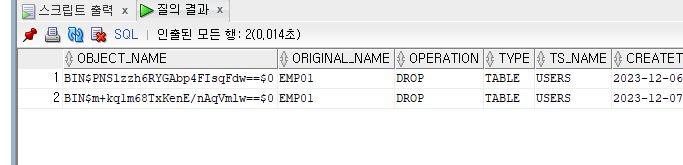
-- 휴지통 비우기
purge recyclebin;
--실수로 지운 테이블이라 삭제를 취소하려면 다음과 같은 명령으로 다시 복구하면 된다.
--flashback table table_name to before drop;
flashback table emp01 to before drop;
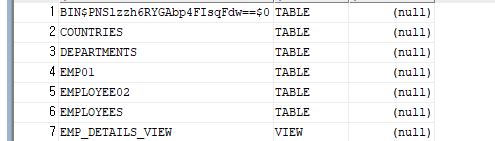
--새로운 이름으로 복원하는 방법
FLASHBACK TABLE emp0 TO BEFORE DROP
RENAME TO emp02;
--휴지통에 넣지 않고 바로 테이블을 삭제하려면 다음과 같은 명령으로 휴지통에 넣지 않고 삭제를 할 수 있다.
--drop table table_name purge;
drop table emp01 purge;
* 테이블 삭제와 무결성 제약 조건
삭제하고자 하는 테이블의 기본 키나 고유 키를 다른 테이블에서 참조해서 사용하는 경우에는 해당
테이블을 제거할 수 없다. 이러한 경우에는 참조하는 테이블을 먼저 제거한 후에 해당 테이블을 삭제
테이블 명을 변경하는 RENAME 문
RENAME old_name TO new_name
ex) RENAME EMPLOYEE02 TO EMPLOYEES01;
SELECT * FROM TAB;
테이블의 모든 로우를 제거해 TRUNCATE 문
TRUNCATE table table_name
다시 복원할 방법이 없기 때문에 신중하게 사용
ex) EMPLOYEES01 테이블 모든 로우를 제거
SELECT * FROM EMPLOYEES01;
TRUNCATE TABLE EMPLOYEES01;
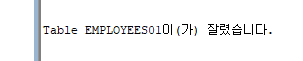
라는 문구를 알 수 있다.
SELECT * FROM EMPLOYEES01;
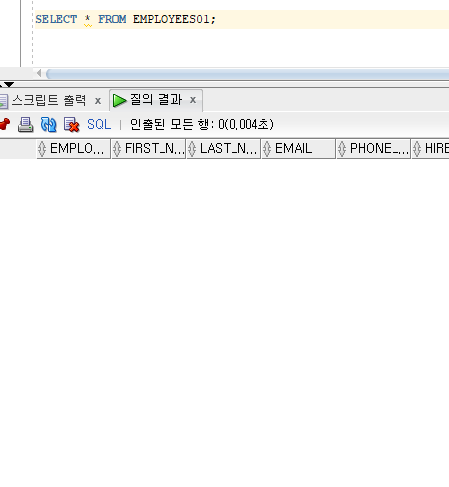
삭제한 데이터를 검색해 보면 아무데이터가 뜨지 않는 것을 볼 수 있다.

DELETE 데이터만 지워지고 쓰고 있던 디스크상의 공간을 그대로 가지고 있다.
TRUNCATE 모든 데이터를 삭제하고 디스크 상의 공간도 줄어들게 된다.
DROP 데이터와 테이블 전체를 삭제
테이블 만들기
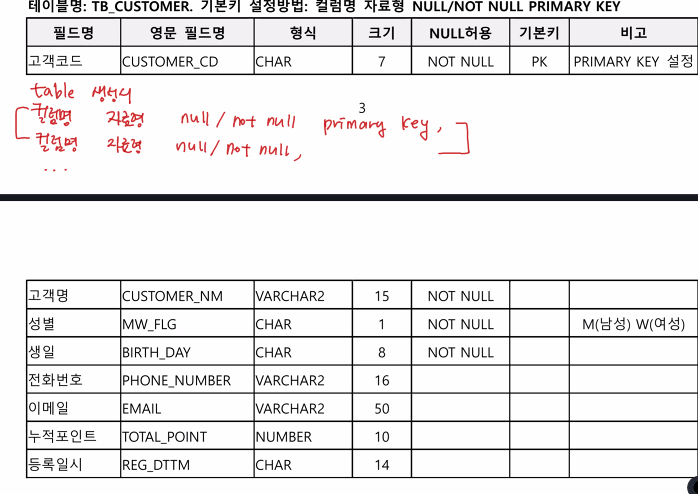
CREATE TABLE TB_CUSTOMER(
CUSTOMER_CD CHAR(7) NOT NULL PRIMARY KEY,
CUSTOMER_NM VARCHAR2(15) NOT NULL,
MW_FLG CHAR(1) NOT NULL,
BIRTH_DAY CHAR(8) NOT NULL,
PHONE_NUMBER VARCHAR2(16),
EMAIL VARCHAR2(50),
TOTAL_POINT NUMBER(10),
REG_DTTM CHAR(14)
);
테이블에 내용을 추가 ㆍ 수정 ㆍ 삭제하기 위한 DML
테이블에 새로운 행을 추가하는 INSERT 문
테이블의 내용을 수정하기 위한 UPDATE문
테이블에 불필요한 행을 삭제하기 위한 DELETE
1) INSERT 문
특정 컬럼에만 DATA 입력
INSERT INTO table name(column value,...)
VALUES(column_value,...)
모든 컬럼에 DATA 입력
INSERT INTO table name
VALUES(column_value, ...)
새로운 행을 추가하기 위해 INSERT문을 사용하면 한번에 하나의 행만 삽입된다(레코드 추가)
기술한 칼럼 목록 순서대로 VALUES에 지정된 값이 삽입된다.
만약 칼럼목록을 기술하지 않으면 테이블에 있는 칼럼의 디폴트 순서대로 VALUES이하의 값이 삽입되며 문자와 날짜 값은 단일 따옴표(' ')을 사용해야 한다.
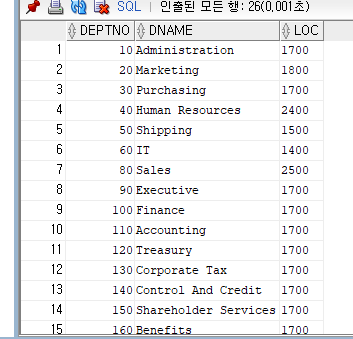
부서테이블 DEPT을 생성
CREATE TABLE DEPT(
DEPTNO NUMBER(2),
DNAME VARCHAR2(14),
LOC VARCHAR2(13)
);
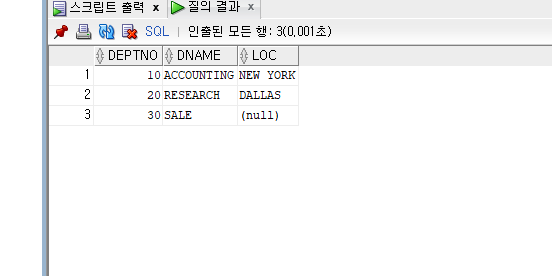
칼럼 DEPTNO에 10번 부서, DNAME에는 'ACCOUNTING'을 , LOC에는 'NEW YORK' 을 추가
INSERT INT DEPT(DEPTNO, DNAME, LOC)
VALUES(10,'ACCOUNTING', 'NEW YORK');
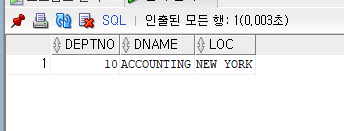
1행의 데이터가 출력되는 것을 알 수 있다.
롤백(F12) 입력 잘못했을때 되돌리는
커밋(F11) 완료 버튼
커밋을 클릭하면 롤백 불가
INSERT 구문에서 오류 발생의 예
-칼럼명에 기술된 목록의 수보다 VALUES 다음에 나오는 괄호 안에 기술한 값의 개수가 적으면 에러가 발생
INSERT INTO DEPT (DEPTNO, DNAME, LOC)
VALUES(10,'ACCOUNTING)'
오류
반대로
VALUES 값의 수가 더 많으면
오류가 뜬다.
-칼럼과 입력할 값의 데이터 타입이 서로 맞지 않을 경우에도 에러가 발생
INSERT INTO DETP ( DEPTNO, DNAME, LOC)
VALUES(10,'ACCOUNTING','NEW YORK');

칼럼명을 생략한 INSERT 구문
테이블에 로우를 추가 할 때 몇몇 특정 칼럼이 아닌 모든 칼럼에 자료를 입력하는 경우 굳이 칼럼 목록을 기술하지 않아도 된다.
칼럼 목록이 생략되면 VALUES 절 다음의 값들이 테이블의 기본 칼럼 순서대로 입력
칼럼명을 생략한 채 테이블이 갖는 모든 칼럼에 데이터 추가
INSERT INTO DEPT
VALUES(20,'RESEARCH','DALLAS');
NULL 값의 삽입
데이터를 입력하는 시점에서 해당 칼럼 값을 모르거나 확정되지 않았을 경우NULL 입력
암시적인방법과 명시적인 방법이 있다
부서 테이블에 칼럼이 NULL값 허용하는지 살펴보면 NULL값을 입력하지 못하는 칼럼에 대해서는 NOT NULL이라고 표시
암시적으로 NULL 값 삽입
암시적인 방법은 칼럼명 리스트에 칼럼을 생략하는 것이다. 즉, 다른 칼럼은 값을 입력하지만 이렇게 생략한 칼럼에는 암시적으로 NULL값이 할당됨
지역명이 결정되지 않은 30부서에 부서명만 입력
INSERT INTO DEPT(DEPMTNO, DNAME)
VALUES(30,'SALE');
NOT NULL로 구조변경 하는 법

2) 명시적인 NULL 삽입
칼럼을 생략한 경우에는
DEPT 행 만들때
명시적으로 값을 줘야한다.
INSERT INTO DEPT(DEPTNO, DNAME)
VALUES(30,'SALE');
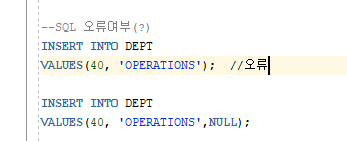
--SQL 오류여부(?)
INSERT INTO DEPT
VALUES(40, 'OPERATIONS'); //오류
INSERT INTO DEPT
VALUES(40, 'OPERATIONS',NULL);

NULL 값을 갖는 칼럼을 추가하기 위해서 NULL 대신 ''를 사용할 수 있다.
INSERT INTO DEPT
VALUES(50,"",'CHICAGO');
기존 데이터를 삭제하고 다시 입력 작업
DELETE FROM DEPT;
기존 테이블에 존재하는 데이터를 다른 테이블에 입력할 때 다음과 같은 쿼리문을 작성
INSERT INTO table_name(column1, column2,...)
SELECT column1, column2,... FROM table_name WHERE 조건;
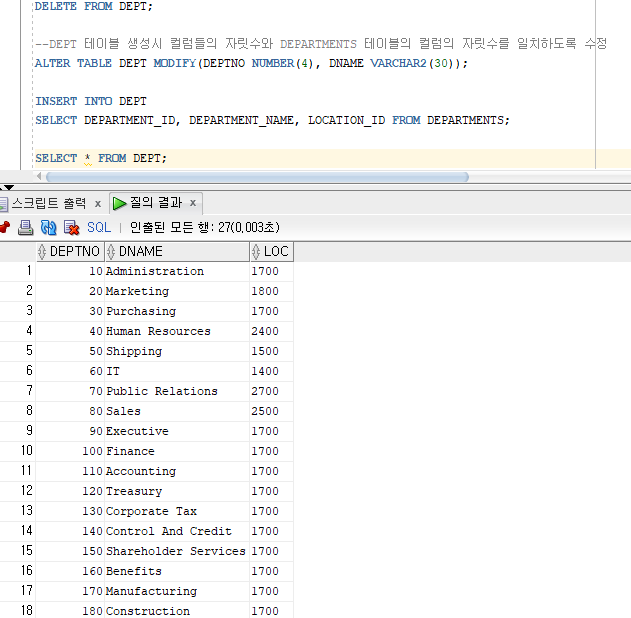
DEPT 테이블 생성시 컬럼들의 자릿수와 DEPARTMENTS 테이블의 컬럼의 자릿수를 일치하도록 수정
ALTER TABLE DEPT MODIFY(DEPTNO NUMBER(4), DNAME VARCHAR2(30));
INSERT INTO DEPT
SELECT DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION_ID FROM DEPARTMENTS;
복사 테이블
1)테이블 구조와 레코드 복사
2)테이블 구조 복사
레코드 복사
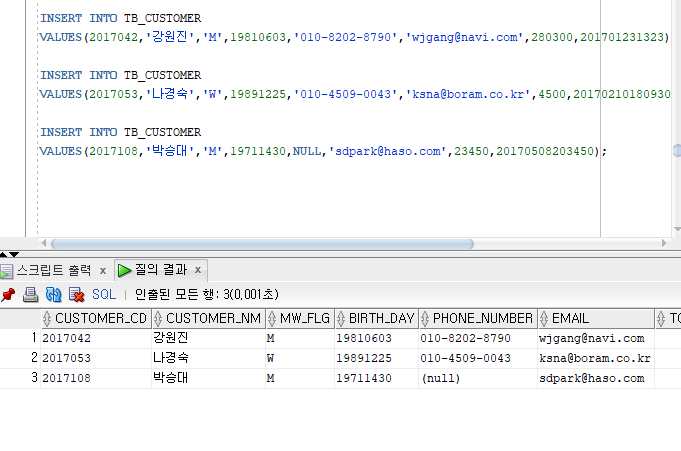
--DELETE FROM TB_CUSTOMER;
--INSERT ALL
--두 개 이상의 테이블을 한번에 삽입 가능
-- 단, 각 서브쿼리의 조건절이 같아야함
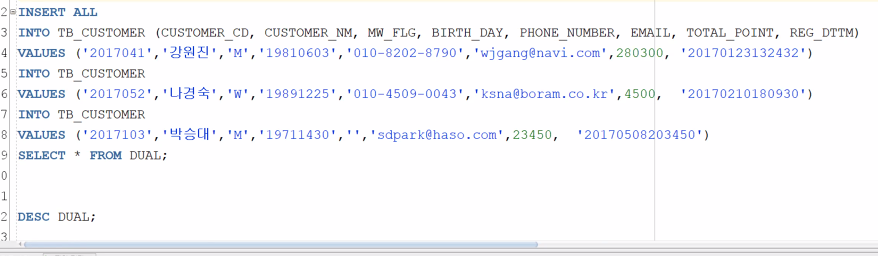
이렇게 값 넣기도 가능하다.
DUAL은 임시 테이블
CREATE TABLE EMP01
AS
SELECT EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID, HIRE_DATE
FROM EMPLOYEES
WHERE 1= 0;
CREATE TABLE EMP_MANAGER
AS
SELECT EMPLOYEE_ID, FIRST_NAME, MANAGER_ID
FROM EMPLOYEES
WHERE 1 = 0;
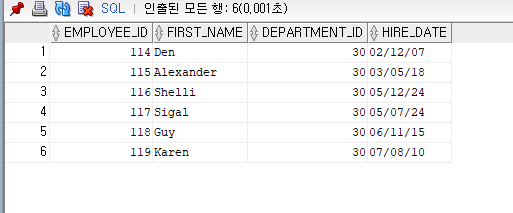
--EMP01테이블에 EMPLOYEES 테이블에서 부서코드가 30인 직원의
--사번, 이름, 소속부서, 입사일을 삽입하고
--EMP_MANAGER테이블에 EMPLOYEES 테이블의 부서코드가 30인 직원의
--사번, 이름, 관리자 사번을 조회하여 삽입
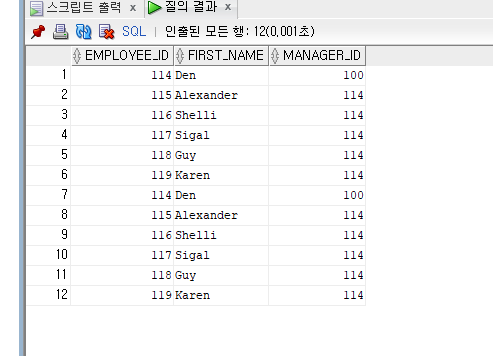
INSERT ALL
INTO EMP01
VALUES(EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID, HIRE_DATE)
INTO EMP_MANAGER
VALUES(EMPLOYEE_ID, FIRST_NAME, MANAGER_ID)
SELECT EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID, HIRE_DATE, MANAGER_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID =30;
SELECT FROM EMP01;
SELECT FROM EMP_MANAGER;
--EMPLOYEES 테이블의 구조를 복사하여 사번, 이름, 입사일, 급여를 저장할 수 있는 테이블 EMP_OLD와 EMP_NEW 생성
CREATE TABLE EMP_OLD
AS
SELECT DEPARTMENT_ID, FIRST_NAME, HIRE_DATE, SALARY
FROM EMPLOYEES
WHERE 1=0; //구조만 복사하기위한
CREATE TABLE EMP_NEW
AS
SELECT DEPARTMENT_ID, FIRST_NAME, HIRE_DATE, SALARY
FROM EMPLOYEES
WHERE 1=0;
-- EMPLOYEES 테이블의 입사일 기준으로
-- 2006년 1월 1일 전에 입사한 사원의 사번, 이름, 입사일, 급여를 조회해서 EMP_OLD 테이블에 삽입
-- 후에 입사한 사원의 정보는 EMP_NEW 테이블에 삽입
INSERT ALL
WHEN HIRE_DATE <'2006/01/01' THEN
INTO EMP_OLD
VALUES(DEPARTMENT_ID, FIRST_NAME, HIRE_DATE, SALARY)
WHEN HIRE_DATE >= '2006/01/01' THEN
INTO EMP_NEW
VALUES(DEPARTMENT_ID, FIRST_NAME, HIRE_DATE, SALARY)
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE, SALARY
FROM EMPLOYEES;
SELECT FROM EMP_OLD;
SELECT FROM EMP_NEW;

테이블의 내용을 수정하기 위한 UPDATE 문
UPDATE talbe_name
SET column_name1 = value1.column_name2 = value2,...
WHERE conditions;
UPDATE문은 기존의 행을 수정. 따라서 어떤 행의 데이터를 수정하는지 WHERE절을 이용하여 조건을 지정해야함. WHERE절을 사용하지 않을 경우 테이블에 있는 모든 행이 수정됨.
WHERE절의 사용 유무를 신중하게 판단
-- 테이블 내용을 수정 UPDATE문---
CREATE TABLE EMP
AS
SELECT * FROM EMPLOYEES;
UPDATE EMP
SET DEPARTMENT_ID=30;
SELECT * FROM EMP;
--모든 사원의 급여를 10% 인상
UPDATE EMP
SET SALARY = SALARY * 1.1;
SELECT * FROM EMP;
--입사일을 오늘로 수정
UPDATE EMP SET HIRE_DATE = SYSDATE;
SELECT * FROM EMP;
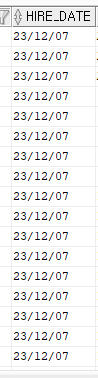
SYSDATE는 현재 날짜 값 뿐만아니라 시간의 값도 가지고 있다
--새롭게 사원 테이블을 생성
DROP TABLE EMP;
CREATE TABLE EMP
AS
SELECT * FROM EMPLOYEES;
SELECT * FROM EMP;
--부서번호가 10번인 사원의 부서번호를 30번으로 수정
UPDATE EMP
SET DEPARTMENT_ID = 30
WHERE DEPARTMENT_ID = 10; //SELECT * FROM EMP;
SELECT * FROM EMP;
--급여가 3000 이상인 사원만 급여를 10% 인상
UPDATE EMP
SET SALARY = SALARY * 1.1
WHERE SALARY >= 3000;
SELECT * FROM EMP;
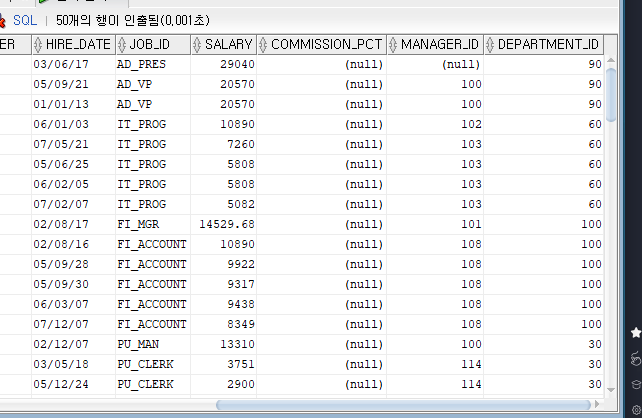
--2007년에 입사한 사원의 입사일이 오늘로 수정
UPDATE EMP
SET HIRE_DATE = SYSDATE
WHERE SUBSTR(HIRE_DATE,1,2)='07';
조건식에서 SUBSTR(가져올 대상,N번쨰에서,N자)='N번째에서 N자를';
SELECT * FROM EMP WHERE FIRST_NAME = 'Susan';
Susan의 부서번호는 20번으로, 직급은 'FI_MGR'
UPDATE EMP
SET DEPARTMENT_ID = 20,JOB_ID ='FI_MGR'
WHERE FIRST_NAME = 'Susan';

LAST_NAME이 Russell인 사원의 급여를 17000로, 커미션 비율이 0.45로 인상된다.
UPDATE EMP
SET SALARY = 17000, COMMISSION_PCT = 0.45
WHERE LAST_NAME = 'Russell';

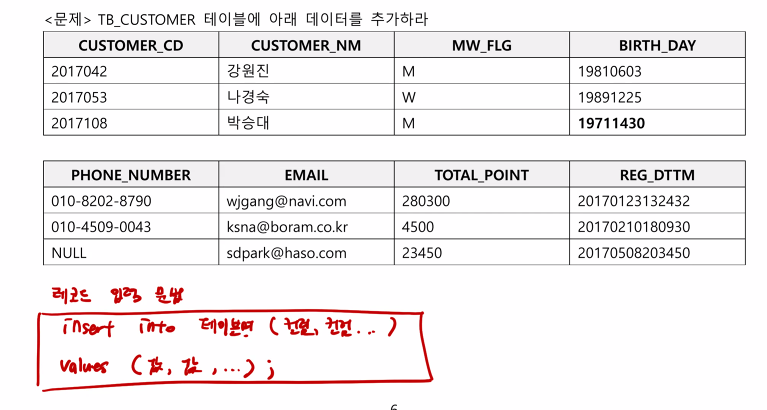
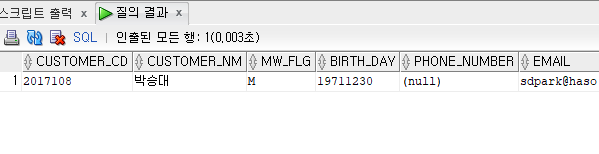
--<문제> tb_customer 테이블에서 '박승대 고객'의 생년월일을 19711230인데 잘못입력하여 19711430
--을 입력하였다. 생년월일을 수정해주세요
select * from tb_customer where customer_nm='박승대';
update tb_customer
set birth_day='19711230'
where birth_day='19711430';
테이블에 불필요한 행(레코드)을 삭제하기 위한 DELETE문
테이블에 특정 로우(행)의 데이터를 삭ㅈ한다.
DELETE FROM table_name
WHERE conditions;
delete from dept where deptno=70;
데이터를 조회 해보면 deptno 70번만 없는걸 확인할 수 있다.
DML (데이터 조작어)
-데이터 입력
insert into 테이블명(컬럼,,)
values(값,..)
-데이터 수정
update 테이블명
set 컬럼=값, 컬럼=값
where 조건문;
-데이터 삭제
delete from 테이블명
where 조건문;
DELETE와 TRUNCATE의 차이점
-DELETE 명령어
DELETE 명령어를 사용하여 TABLE의 행을 삭제할 경우에 행이 많으면 행이 삭제될 때마다 많은 자원이 소모 왜냐하면 delete 명령어는 삭제 이전 상태로 원상ㅇ 복귀할 경우를 생각해서 rollback정보를저장하고 있어야 하기 때문
-TRUNCATE 명령어
truncate 로 table 모든행 삭제시 DDL명령문으로 rollback이 될 수 없다.
어떤 rollback 정보도 만들지 않고 즉시 commit 하기에 빠르고 효율적이다.
commit을 작업할 때 마다 습관적으로 해야한다.
MERGE 문
조건을 비교해서 테이블에 해당 조건에 맞는 데이터가 없으면 INSERT문 있으면 UPDATE를 수행하는 문장이다.
MERGE INTO table_name
USING( update나 insert 될 데이터 원천)
ON ( update될 조건 )
WHEN MATCHED THEN
UPDATE SET 컬럼1= 값1, 컬럼2 = 값2,...
WHEN NOT MATCHED THEN
INSERT ( 컬럼1,컬럼2,...) VALUES (값1, 값2,...)
--구조가 같은 두개의 테이블을 하나의 테이블로 합치는 기능 제공
-- 두 테이블에서 지정하는 조건의 값이 존재하면 update되고 조건의 값이 없으면 insert 함
--TB_ADD_CUSTOMER 테이블의 내용을 TB_CUSTOMER 테이블과 비교하여 데이터가 있을 경우 업데이트하고 데이터가 없을 경우 입력되도록 쿼리문을 작성한다.
TB_ADD_CUSTOMER 테이블의 내용을 TB_CUSTOMER 테이블과 비교하여 데이터가 있을 경우 업데이트하고 데이터가 없을 경우 입력되도록 쿼리문을 작성한다.
MERGE INTO TB_CUSTOMER CU
USING TB_ADD_CUSTOMER NC
ON (CU.CUSTOMER_CD = NC.CUSTOMER_CD)
WHEN MATCHED THEN
UPDATE SET CU.CUSTOMER_NM = NC.CUSTOMER_NM,
CU.MW_FLG=NC.MW_FLG,
CU.BIRTH_DAY=NC.BIRTH_DAY,
CU.PHONE_NUMBER=NC.PHONE_NUMBER
WHEN NOT MATCHED THEN
INSERT(CU.CUSTOMER_CD,CU.CUSTOMER_NM,CU.MW_FLG,CU.BIRTH_DAY,
CU.PHONE_NUMBER, CU.EMAIL, CU.TOTAL_POINT, CU.REG_DTTM)
VALUES(NC.CUSTOMER_CD, NC.CUSTOMER_NM,NC.MW_FLG,NC.BIRTH_DAY,
NC.PHONE_NUMBER,'',0,TO_CHAR(SYSDATE,'YYYYMMDDHHMISS'));
SELECT FROM TB_CUSTOMER;
SELECT FROM TB_ADD_CUSTOMER;
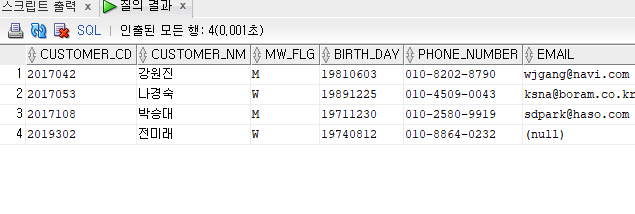
없는데이터의 추가로 인해 두개의 테이블이 병합된것을 볼 수 있다.
무결성 제약 조건
잘못된 데이터가 입력되지 않도록 무결성 제약 조건을 지정
NULL을 허용하지 않도록 하려면 NOT NULL 제약 조건을 지정
항상 유일해야하는 고유 키를 지정하려면 UNIQUE 제약 조건을 설정 (UK)
칼럼값은 반드시 존재해야 하고 유일하도록 하려면 PRIMARY KEY 제약 조건을 설정(PK)
해당 칼럼값은 참조되는 테이블의 칼럼에 하나 이상과 일치하도록 하려면 FOREIGN KEY 제약조건을 설정(FK)
1) 무결성 제약 조건의 개념과 종류
데이터 무결성이란 데이터베이스 내의 데이터에 대한 정확성,일관선,유효성,신뢰성을 보장하기 위해 데이터 변경 혹은 수정 시 여러가지 제한을 두어 데이터의 정확성을 보증하는 것
제약조건이란 바람직하지 않은 데이터가 저장되는 것을 방지하기 위해 테이블을 생성할 때 각 컬럼에 대해서 정의하는 여러가지 규칙을 말한다.

UNIQUE 제약 조건 (유일키 -UK)
NULL값 허용
INSERT INTO EMP02(EMPNO, ENAME, JOB, DEPTNO)
VALUES(7499, 'ALLEN', 'SALESMAN', 30);
--ORA-00001: 무결성 제약 조건(HR.SYS_C008437)에 위배됩니다
INSERT INTO EMP02(EMPNO, ENAME, JOB, DEPTNO)
VALUES(7499, 'ALLEN', 'SALESMAN', 30);
INSERT INTO EMP02(EMPNO, ENAME, JOB, DEPTNO)
VALUES(NULL, 'JONES', 'MANAGER', 20);
INSERT INTO EMP02(EMPNO, ENAME, JOB, DEPTNO)
VALUES(NULL, 'JONES', 'SALESMAN', 10);
SELECT * FROM EMP02;
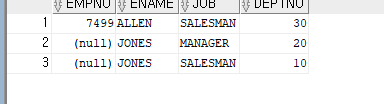
UNIQUE KEY 를 쓸때 널 값을 허용하지 않게 하려면 NOT NULL 기입해야함.
UNIQUE와 NULL의 관계
UNIQUE는 NULL 값을 예외로 간주. 만악 NULL 값마저도 입력되지 않게 제한하려면 테이블 생성시 EMPNO NUMBER(4) NOT NULL UNIQUE 처럼 두가지 제약조건을 기술해야함
데이터 딕셔너리
데이터베이스 자원을 효율적으로 관리하기 위한 다양한 정보를 저장하는 시스템 테이블을 데이터 딕셔너리라고 한다. 데이터 딕셔너리는 사용자가 테이블을 생성하거나 사용자를 변경하는 등의 작업을 할 때 데이터베이스 서버에 의해 자동으로 갱신되는 테이블로 사용자는 데이터 딕셔너리의 내용을 직접 수정하거나 삭제할수 없다. 데이터 딕셔너리 원 테이블은 직접 조회하기란 거의 불가능.
의미 있는 자료 조회가 불가능하기에 오라클은 사용자가 이해할 수 있는 데이터를 산출해 줄 수 있도록 하기 위해서 데이터 딕셔너리에서 파생한 데이터 딕셔너리 뷰를 제공.
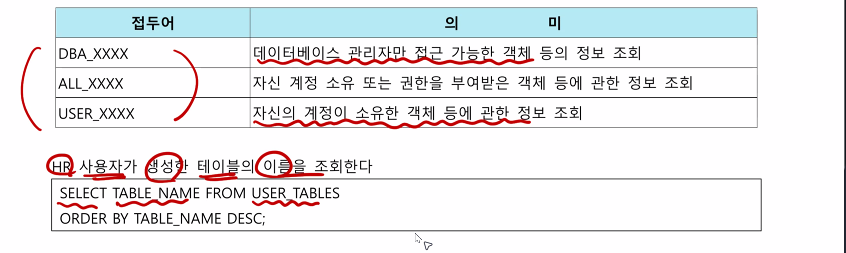
제약조건 확인하기
CONTRAINT_TYPE 의미
P PRIMARY KEY
R FOREIGN KEY
U UNIQUE
C CHECK , NOT NULL
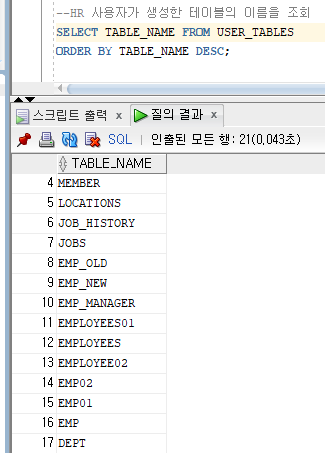
--HR 사용자가 생성한 테이블의 이름을 조회
SELECT TABLE_NAME FROM USER_TABLES
ORDER BY TABLE_NAME DESC;
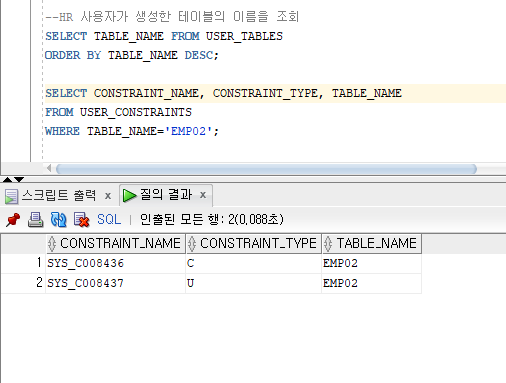
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, TABLE_NAME
FROM USER_CONSTRAINTS
WHERE TABLE_NAME='EMP02';
SELECT OWNER, CONSTRAINT_NAME, TABLE_NAME, COLUMN_NAME FROM USER_CONS_COLUMNS
WHERE TABLE_NAME = 'EMP02';
부모키가 되기 위한 칼럼은 반드시 부모 테이블의 기본키나 유일키로 설정되어 있어야 함.
CREATE TABLE DEPT01(
DEPTNO NUMBER(2) PRIMARY KEY,
DNAME VARCHAR2(14) NOT NULL,
LOC VARCHAR2(13)
);
INSERT INTO DEPT01 ( DEPTNO, DNAME, LOC)VALUES(10,'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT01 ( DEPTNO, DNAME, LOC)VALUES(20,'RESEARCH', 'DALLAS');
INSERT INTO DEPT01 ( DEPTNO, DNAME, LOC)VALUES(30,'SALES', 'CHICAGO');
INSERT INTO DEPT01 ( DEPTNO, DNAME, LOC)VALUES(40,'OPERATIONS', 'BOSTUN');
INSERT INTO EMP03
VALUES(7566,'JONES','MANAGER',50);
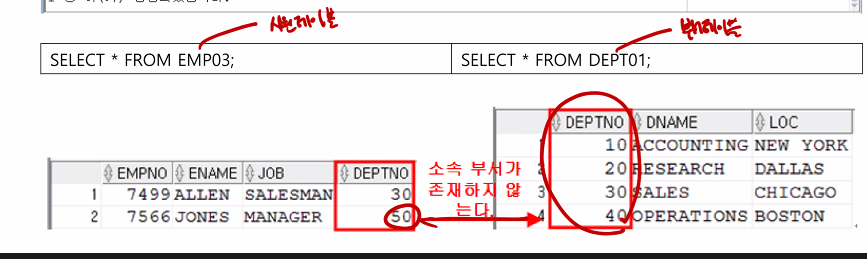
외래키 제약 조건은 EMP04 테이블을 생성시 칼럼명과 자료형을 기술한 후에 REFERENCES를 기술하면
된다. DEPTNO 칼럼을 참조하게 외래키 제약조건을 설정
CREATE TABLE EMP04(
EMPNO NUMBER(4) PRIMARY KEY, --사원번호
ENAME VARCHAR2(10) NOT NULL, --사원명
JOB VARCHAR2(9), --직무
DEPTNO NUMBER(2) REFERENCES DEPT01(DEPTNO) --부서번호
);
INSERT INTO EMP04
VALUES(7499, 'ALLEN', 'SALESMAN',30);
SELECT * FROM EMP04;
INSERT INTO EMP04
VALUES(7566,'JONES','MANAGER',50);
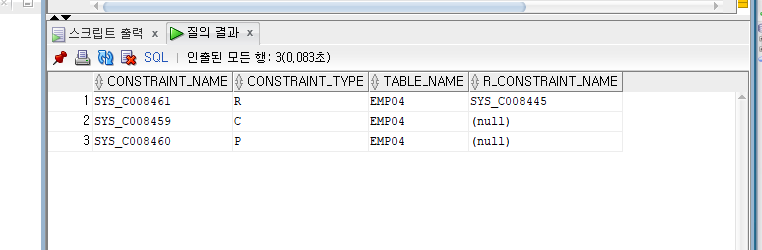
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, TABLE_NAME, R_CONSTRAINT_NAME
FROM USER_CONSTRAINTS
WHERE TABLE_NAME='EMP04';
--EMP05 사원 테이블에 GENDER(성별) 칼럼을 추가하되, GENDER칼럼에는 'M'또는 'F'의 두 값만 저장할 수 이ㅣㅆ는 CHECK 제약조건을 설정
CREATE TABLE EMP05(
EMPNO NUMBER(4) PRIMARY KEY,
ENAME VARCHAR2(10) NOT NULL,
GENDER VARCHAR2(1) CHECK (GENDER IN('M','F')),
REGDATE DATE DEFAULT SYSDATE
);
SELECT * FROM EMP05;
--NOT NULL, CHECK, DEFAULT 변경은
--ALTER TABLE 테이블 MODIFY (컬럼명 자료형 제약조건)으로
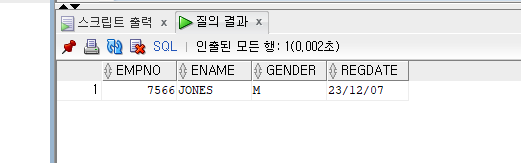
INSERT INTO EMP05(EMPNO, ENAME, GENDER)
VALUES(7566, 'JONES', 'M');
SELECT * FROM EMP05;
--ORA-02290: 체크 제약조건(HR.SYS_C008466)이 위배되었습니다
INSERT INTO EMP05(EMPNO, ENAME, GENDER)
VALUES(7566, 'JONES', 'A');
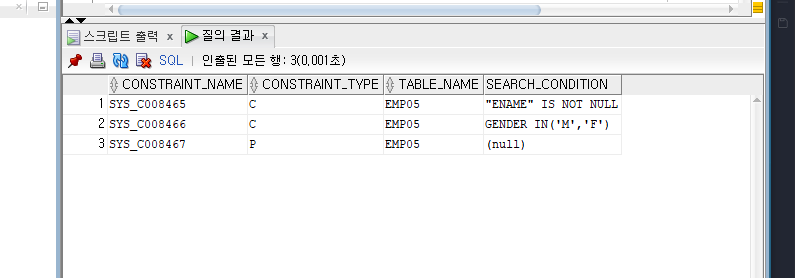
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE, TABLE_NAME, SEARCH_CONDITION
FROM USER_CONSTRAINTS
WHERE TABLE_NAME='EMP05';