EDA (탐색적 데이터 분석)
위치 추정
데이터를 살펴보는 가장 기본적인 방법은
각 변수들의 대표값Typical value을 구하는 것이다.
이는 곧 대부분의 값이 어디쯤에 위치하는지를 나타내는 추정값이다. (중심경향성)
평균
-
데이터를 요약할 때 가장 흔하게 쓰이는 대표값은 평균,
그 중에서도 산술평균인데, 산술평균은 모든 값의 총합을 값의 갯수로 나눈 값이다. -
산술평균은 계산하기 쉽고 사용하기 편리하다는 장점이 있지만,
데이터를 대표하는 가장 좋은 값은 아닐 수 있다. 예를 들어,
- 산술평균은 극단값의 영향을 쉽게 받는다.
- 위와 비슷한 맥락에서, 산술평균은 전체 데이터의 분포 상태를 반영하지 못한다. -
평균을 조금 변형한 값들 중 하나로 절사평균이 있다. 절사평균은 값들을 크기 순서대로 정렬한 후, 양 끝에서 일정 갯수의 값들을 삭제한 뒤 남은 값들을 가지고 구한 평균을 말한다.
- 절사평균은 정의상 극단값의 영향을 제거한다.
- 예를 들어, 국제 다이빙 대회에서는 5명의 심판이 매긴 점수 중 가장 높은 점수와 가장 낮은 점수를 제외한 나머지 3명의 점수를 평균한 값으로 최종 성적을 매긴다.
- 혹시 한 심판이 자국 선수에게 유리한 심사를 하더라도, 절사평균을 구하는 과정에 의해 이 심판이 전체 성적에 영향을 주기 어려워진다.
-
또 다른 종류의 평균으로 지정한 가중치를 곱한 x의 총합을 가중치의 총합으로 나눈 가중평균이 있다. 가중평균을 사용하게 된 2가지 중요한 이유로는
- 어떤 값들이 다른 값들에 비해 큰 변화량을 가질 때, 이런 관측값에 더 낮은 가중치를 줄 수 있다. 예컨대 여러 개의 센서에서 가져온 데이터의 평균을 구한다고 할 때, 한 센서의 정확도가 유난히 떨어진다면 그 센서에서 나온 데이터에서는 낮은 가중치를 주는 것이 합리적이다.
- 데이터를 수집할 때 서로 다른 대조군에 대해 항상 똑같은 수의 데이터가 얻어지지는 않는다. 이를 보정하기 위해 데이터가 부족한 소수 그룹에 대해 오히려 더 높은 가중치를 적용할 필요도 있을 것이다.
중간값과 로버스트 추정
-
데이터를 일렬로 정렬했을 때 한가운데에 위치하는 값을 중간값이라고 한다. 만약 데이터의 갯수가 짝수라면, 이 때의 중간값은 가운데 있는 두 값의 평균으로 한다.
-
모든 관측치를 다 사용하는 평균과 달리 중간값은 정렬된 데이터의 가운데에 있는 값들만으로 결정된다. 얼핏 보기에 불리할 것처럼 보이지만, 많은 경우 데이터에 민감한 평균보다는 중간값이 위치 추정에 더 유리하다.
-
가중평균을 사용하는 이유와 동일하게, 중간값을 구할 때도 가중 중간값을 쓸 수 있다. 가중 중간값은 단순히 가운데 위치한 값이 아닌, 어떤 위치를 기준으로 상위 절반의 가중치의 합이 하위 절반의 가중치의 합과 동일한 위치의 값이다.
-
중간값과 마찬가지로, 가중 중간값 역시 특잇값에 로버스트하다.
-
특잇값은 어떤 데이터 집합에서 다른 값들과 매우 멀리 떨어진 값인데, 몇 가지 관습적인 정의가 있긴 하지만 정확한 정의는 다소 주관적일 수 있다. (얼마나 멀리 떨어져야 특잇값으로 볼 것인지?)
- 특잇값은 데이터의 값 자체가 유효하지 않다거나 잘못되었다는 뜻이 아니다.
- 다만 데이터에 특잇값이 섞여있을 경우 평균은 잘못된 위치 추정을 할 수 있는 위험이 있는 반면, 중간값은 여전히 설득력 있는 결과를 줄 수 있을 것이다.
-
중간값만이 유일하게 로버스트한 위치 추정 방법은 아니다. 위에서 본 절사평균 역시 특잇값의 영향을 줄이기 위해 많이 사용된다. 절사평균은 특잇값에 대해 로버스트하지만, 위치 추정을 위해 (중간값보다는) 더 많은 데이터를 사용한다는 점에서 평균과 중간값의 절충안으로도 볼 수 있다.
코드 실습
-
기본 라이브러리와 데이터를 불러온다. 미국 각 주의 인구와 살인 비율을 보여주는 state 데이터를 사용했다. 라이브러리 중 scipy, wquantiles는 각각 절사평균과 가중 중간값을 구하기 위해 불러온 것이다.
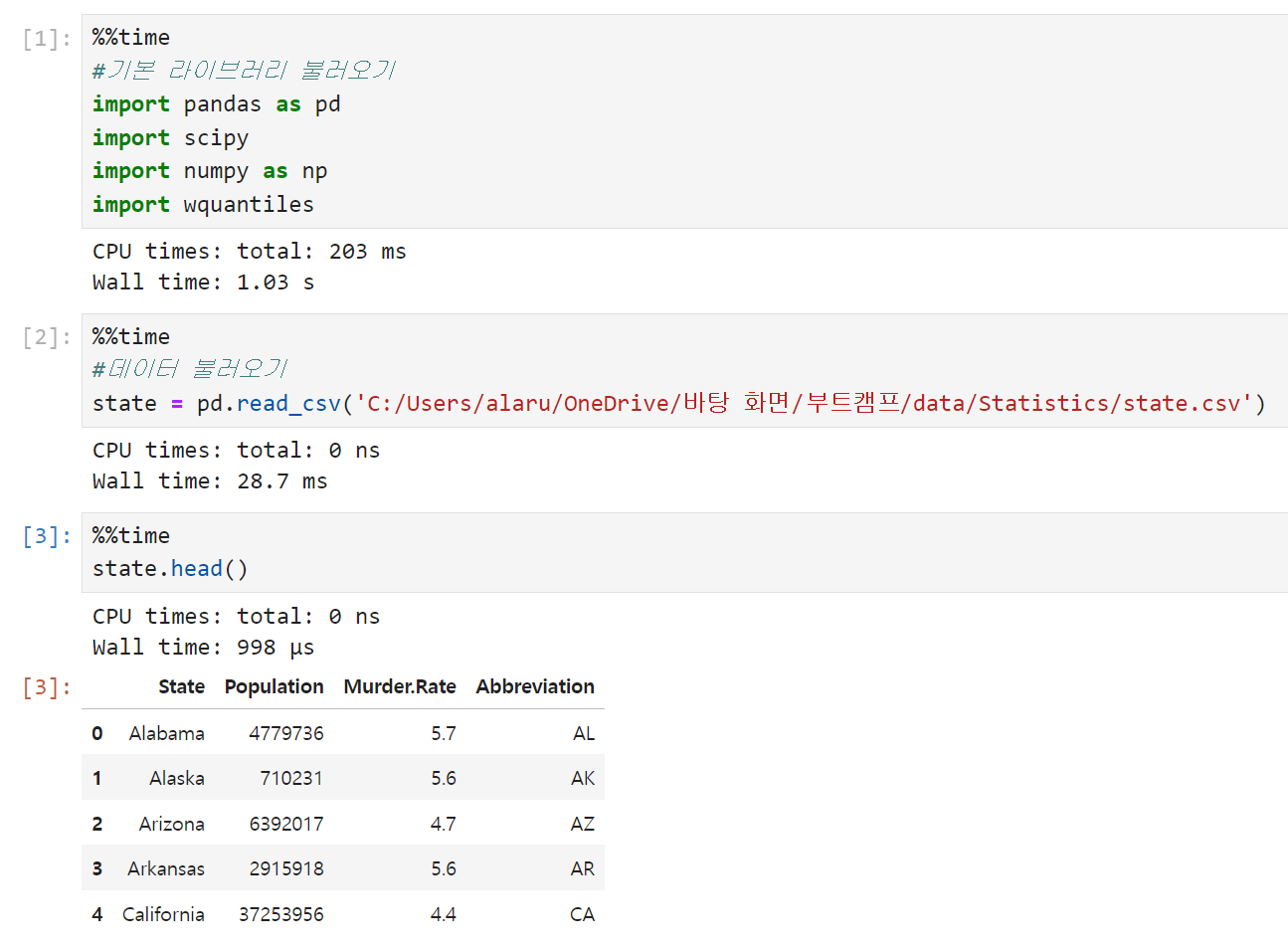
-
순서대로 산술평균, 절사평균, 중앙값을 구한 결과다. 산술평균과 중앙값을 비교했을 때 산술평균 쪽이 훨씬 큰 것으로 보아 인구(Population)에 큰 값들이 많이 포함되어 있을 거라고 추측해 볼 수 있다.
평균은 절사평균보다 크고, 절사평균은 중앙값보다 크다.
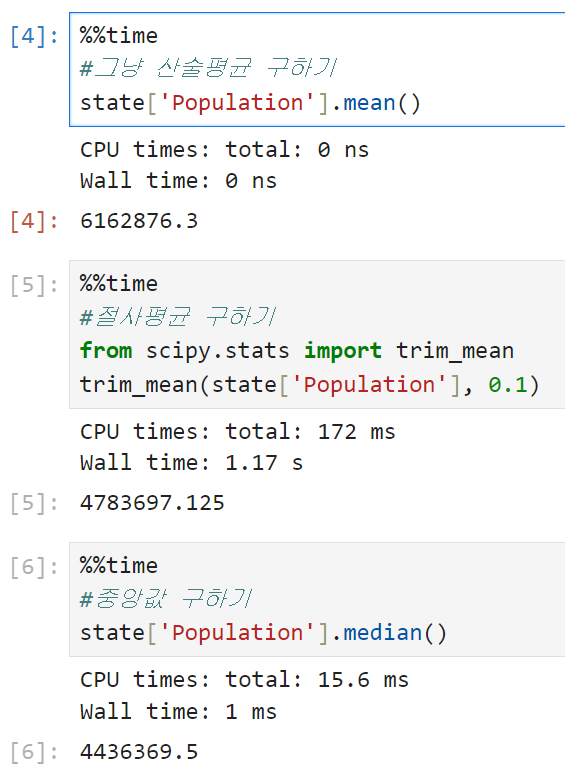
코드상에서 trim_mean은 절사평균을 나타내고, trim = 0.1의 파라미터는 위아래로 10%의 값을 제외하고 평균을 구한다는 의미다. trim 값을 0.05로 바꾸면 위아래로 5%의 값을 제외하고 계산된 평균이 나온다. -
미국 전체의 평균적인 살인율을 계산하려면 주마다 인구 수가 다른 점을 고려하기 위해 가중평균이나 가중 중간값을 사용해야 한다.
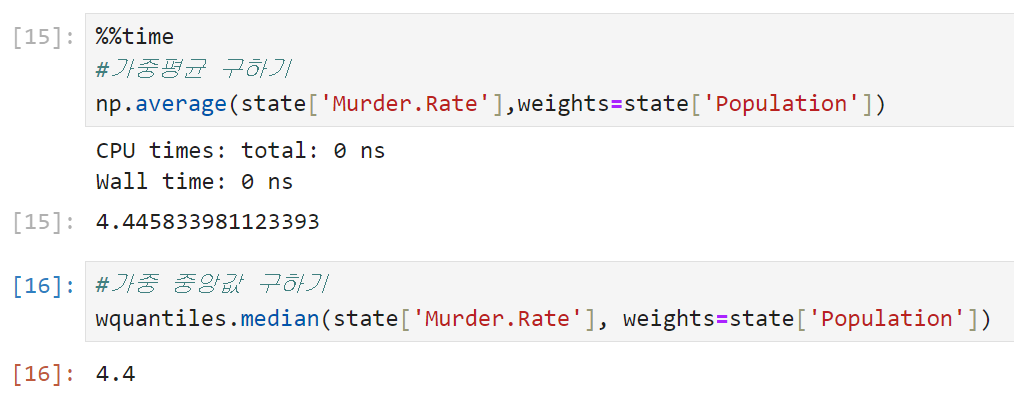
가중평균을 구하기 위해 넘파이, 가중 중간값을 구하기 위해 wquantiles를 사용한다.
이 경우에서는 가중평균과 가중 중앙값이 거의 비슷하다.
