두 개 이상의 변수 탐색 (다변량분석)
- 평균이나 분산처럼 익숙한 추정값들은 한 번에 하나의 변수를 다룬다. (일변량분석)
상관분석은 한 번에 두 변수를 비교할 때 중요한 방법이다. (이변량분석)
셋 이상의 변수를 다룰 때는 조금 더 복잡한 분석 방법을 사용한다. (다변량분석)
육각형 구간, 등고선
-
산점도는 데이터의 갯수가 상대적으로 적을 때는 유용한 방법이지만, 수십만, 혹은 수백만의 레코드를 나타내려면 점들이 너무 밀집되어 있어 알아보기 어려운 단점이 있다. 따라서 이런 상황에서는 다른 형태의 시각화 방법을 사용해야 하는데, 육각형 구간 그림이 그 방법 중 하나다.
-
아래는 워싱턴 주 킹 카운티의 주택 시설에 대한 과세 평가 금액 정보를 담고 있는 데이터다. 데이터의 주요 부분에 집중하기 위해 아주 비싸거나 너무 작은, 혹은 너무 큰 주택들은 데이터프레임에서 제거한다.
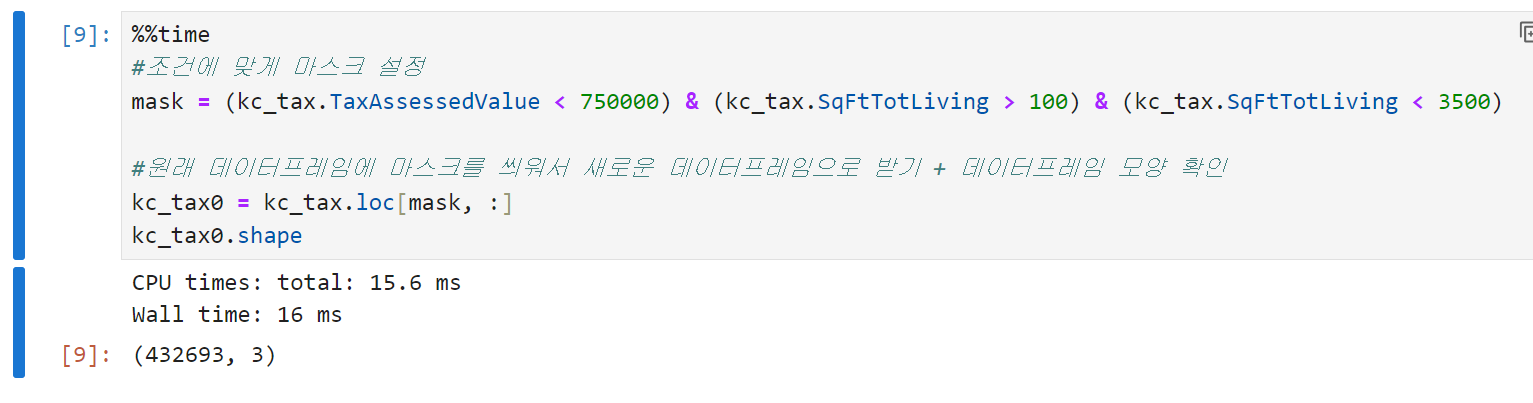
-
육각형 구간 그림을 그리는 코드는 아래와 같다.
- gridsize : 육각형의 크기를 결정하는 인수
- sharex=False : 두 개의 변수가 x축을 공유할지를 묻는 인자다. 이 경우는 y축에 들어갈 값이 세금평가가치밖에 없으므로 False로 설정하는 것이 큰 의미는 없는데, 만약 저걸 True로 설정하고 서브플롯이 들어가면 두 개의 서로 다른 y에 대해 x축을 공유하게 된다.
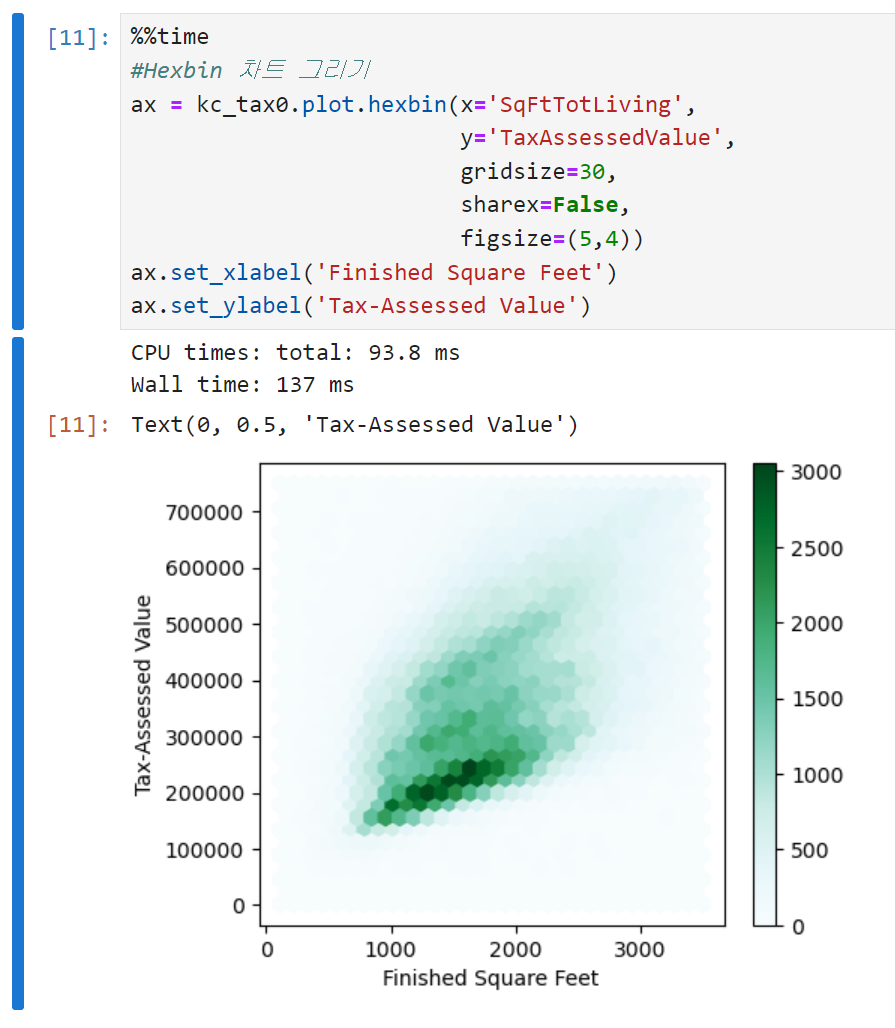
-
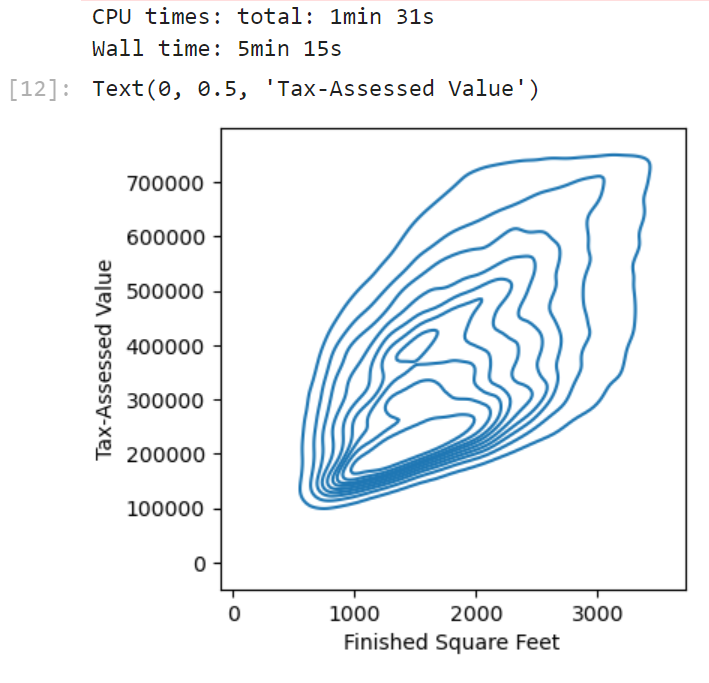
산점도 위에 등고선을 표시하는 방법도 있다. 등고선은 x축, y축의 두 변수로 이루어진 지형에서의 등고선을 말한다. 등고선 위의 점들은 밀도가 같고, 꼭대기 쪽으로 갈수록 밀도가 높아진다. 여기서도 seaborn 라이브러리의 커널밀도추정 함수를 이용했다. 문제는 코드의 실행시간이 말도 안 되게 오래 걸린다는 것. (5분 15초ㄷㄷ) 체감상 머신러닝 프로젝트 때 그리드서치 했을 때보다 오래 걸리는 듯. 함부로 그리면 안 되겠다.

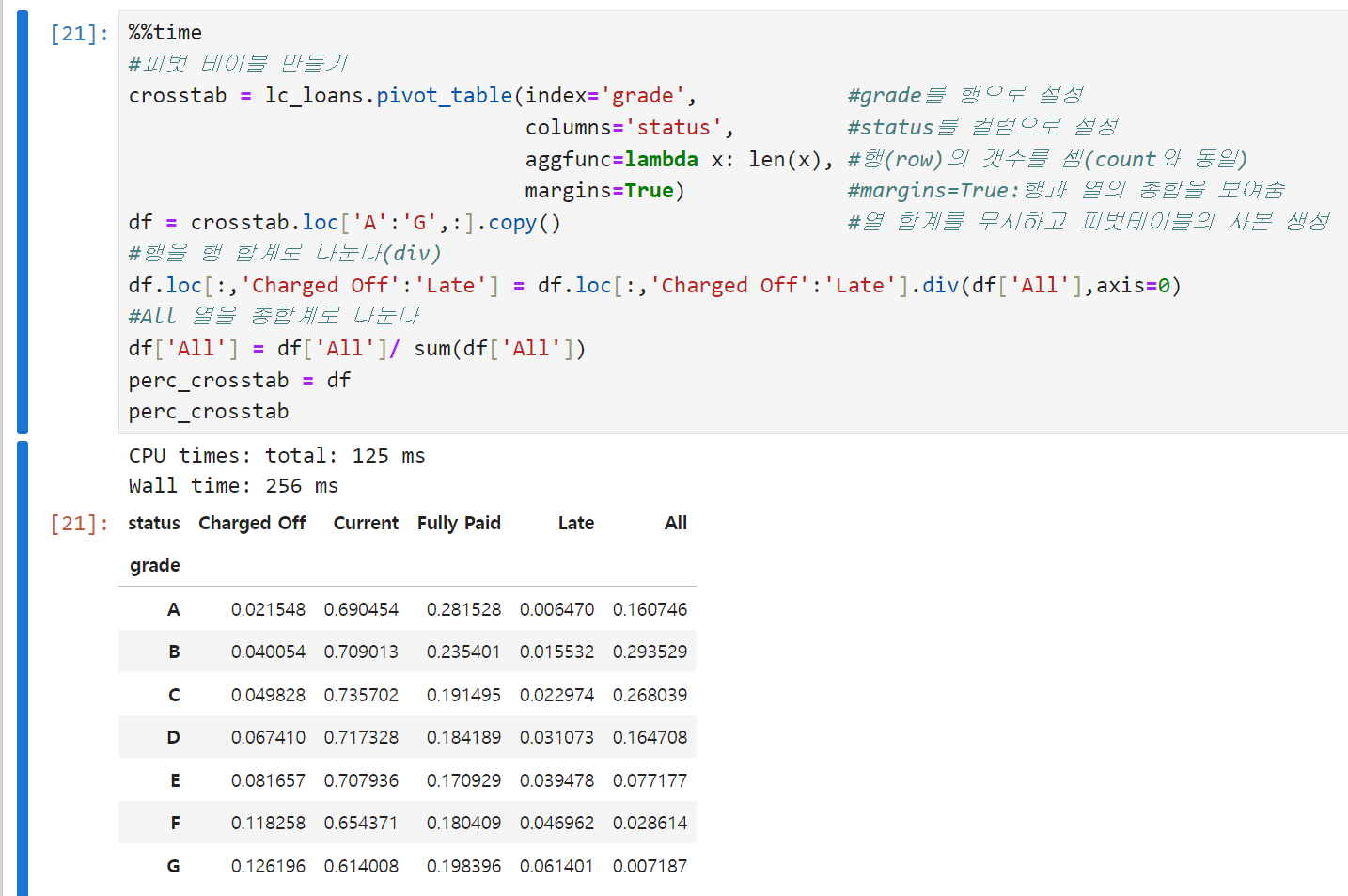
범주형 변수 vs 범주형 변수
- 분할표는 두 범주형 변수를 요약하는 데 효과적인 방법으로, 범주별 빈도수를 기록한 표다. 엑셀의 피벗테이블이라고 생각하면 편하다. 아래 예시는 개인대출 등급과 대출 결과를 나타내는 분할표인데, 등급은 A(높음)부터 G(낮음)까지다. 높은 등급의 대출일수록 낮은 등급에 비해 연체late나 삭제charged off 비율이 낮다는 것을 알 수 있다. 다만 표를 '읽어야' 한다는 점에서 다른 시각화 방식보다는 불리할 수도 있을 듯.
범주형 변수 vs 수치형 변수
-
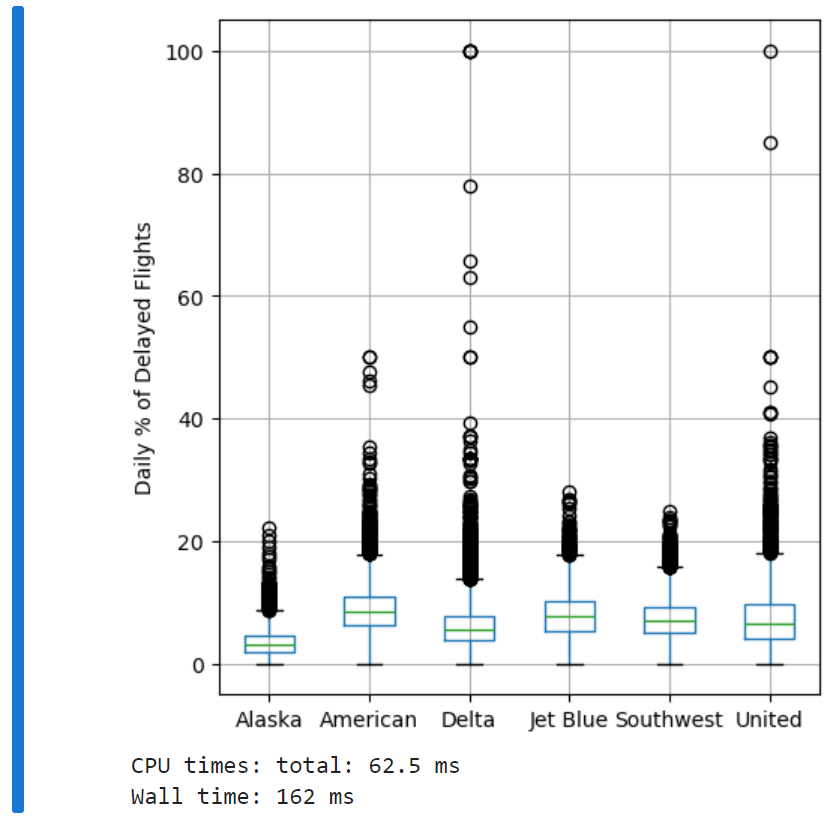
박스플롯 복습. 알래스카 항공의 지연이 가장 적었던 반면, 아메리카 항공의 지연이 가장 많았던 걸로 보인다. (박스플롯의 위아래 너비가 가장 높은 구간에 걸쳐 있음) 심지어 알래스카 항공의 상위 사분위수보다 아메리칸 항공의 하위 사분위수가 더 크다.

-
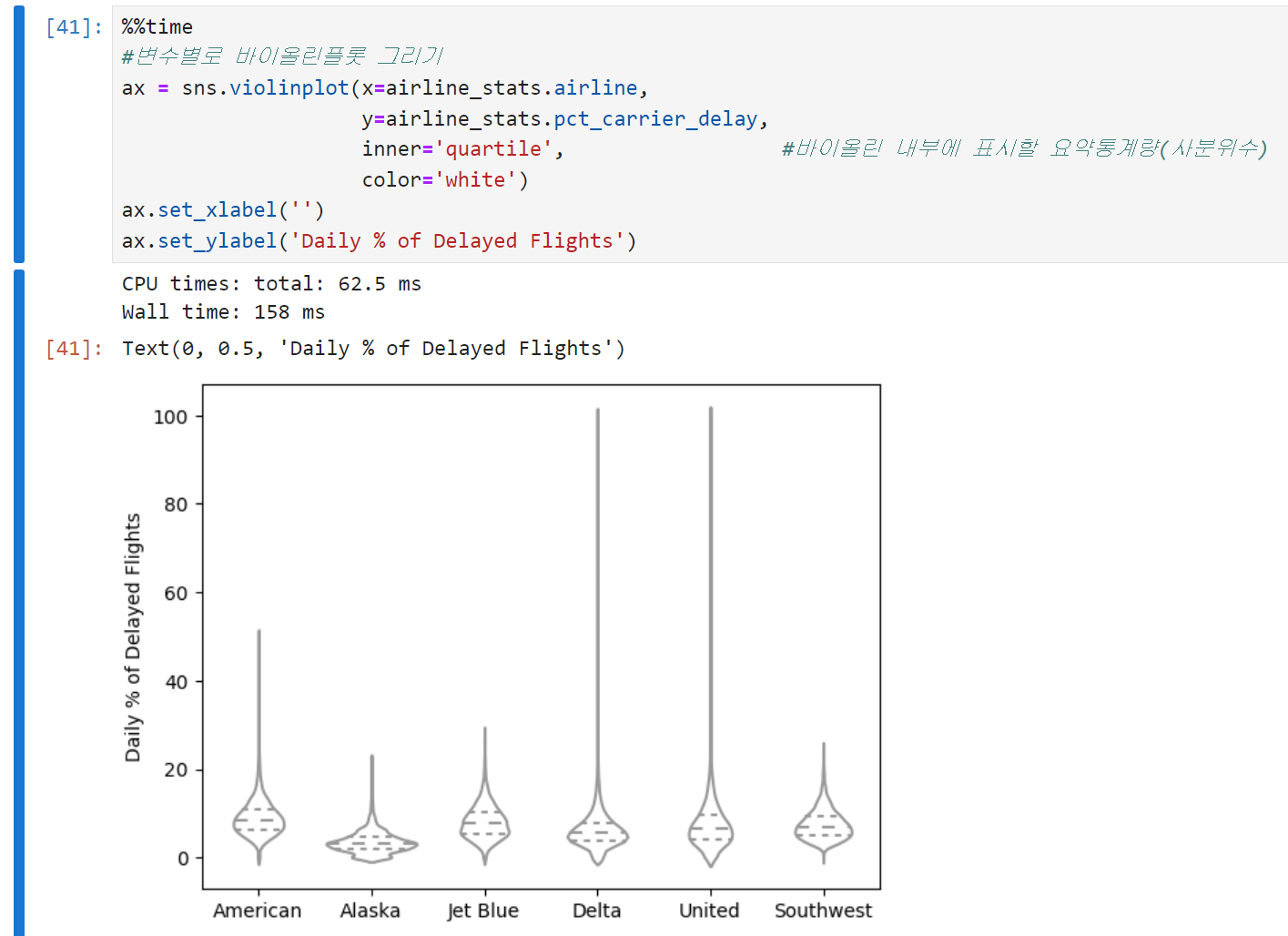
바이올린 플롯은 박스플롯을 보완한 형태로, y축을 따라 밀도추정 결과를 동시에 시각화한다. 박스플롯 상에는 드러나지 않는 데이터의 분포까지 볼 수 있다는 장점이 있는 반면, 박스플롯은 데이터의 이상치들을 좀 더 명확하게 보여준다.
- 알래스카 항공, 그리고 델타 항공이 0 근처에 데이터가 집중되어 있다.
- 바이올린 플롯도 커널밀도추정을 쓰기 때문에 데이터 밀도가 높은 구간은 곡선이 높고(즉, 가로로 볼록하고) 밀도가 낮은 구간은 곡선이 낮다.
다변수 시각화하기
-
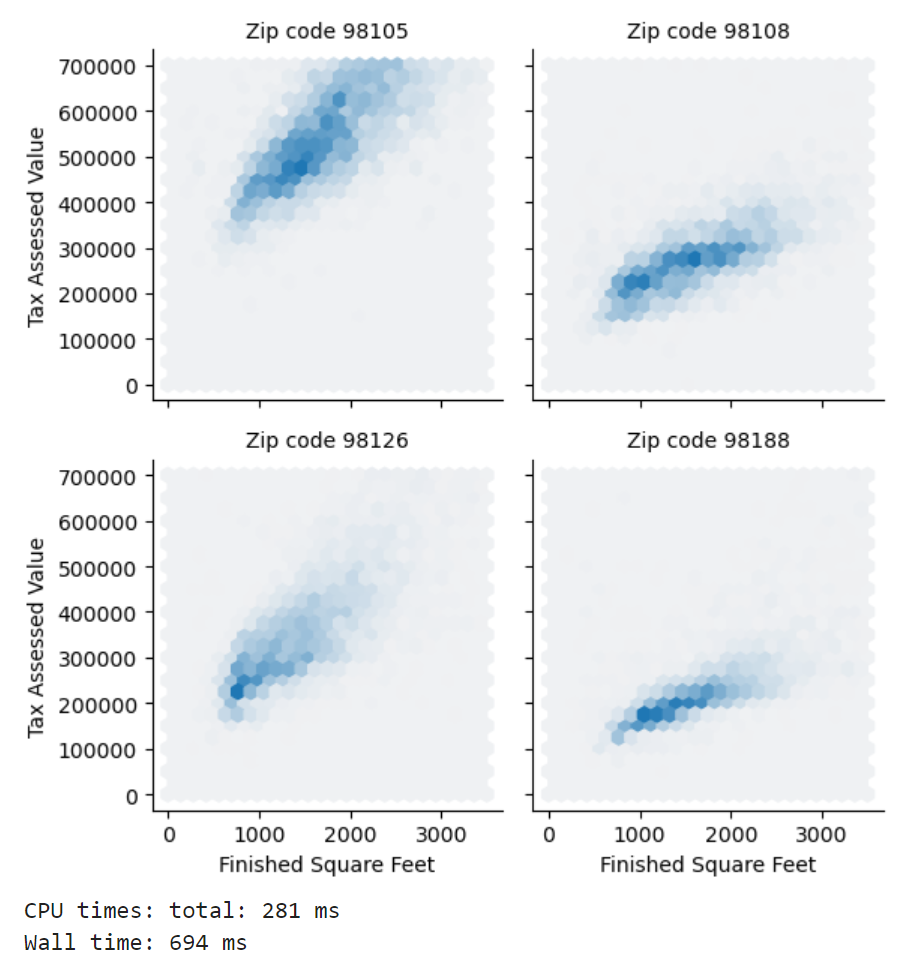
조건화conditioning라는 개념을 통해 두 변수 비교용 도표(산점도, 육각형 구간, 박스플롯)를 여러 변수를 비교하는 용도로 확장해서 그릴 수 있다. 아래는 주택 크기와 과세평가액 데이터를 다시 불러와서, 우편번호별로 데이터를 묶어서 도식화한 결과다. 어떤 우편번호에서의 평가액이 다른 두 군데보다 훨씬 높다는 사실을 알 수 있다. 코드가 다소 복잡함.

-
각 행의 왼쪽 차트가 오른쪽의 차트보다 대체로 동일한 입방피트에 대해 과세평가액을 높게 받고 있음을 한 눈에 볼 수 있다. 조건화 변수를 추가함으로써 변수를 통째로 시각화했을 때는 미처 드러나지 않았던 정보들이 더 잘 드러나는 효과를 볼 수 있다.
<세 줄 요약>
- 육각형 구간이나 등고선 도표는 데이터의 방대한 양에 압도되지는 않으면서도, 한 번에 두 수치형 변수를 시각적으로 검토할 때 유리한 도구
- 분할표는 두 범주형 변수의 도수를 확인하기 위한 대표적인 방법 (걍 피벗테이블 그린다고 생각해도 될 듯)
- 박스플롯이나 바이올린플롯은 범주형 변수와 수치형 변수 간의 관계를 도식화하기 위한 도구
EDA 파트 끝.
다음 파트는 <데이터와 표본분포>.
