아무리 사소하더라도 배움이 없는 날은 없다.
SQL 코드카타
오늘 leetcode를 들어갔더니 이런 배지를 줬다.
총 100일 출첵을 찍으면 주는 거라고ㅎㅎ

문제 링크
concat과 substring_index를 조합하는 문제.
SELECT Concat('#', Substring_index(Substring_index(tweet, '#', -1), ' ', 1)) AS
"HASHTAG",
Count(*) AS
"HASHTAG_COUNT"
FROM tweets
GROUP BY 1
ORDER BY 2 DESC,
1 DESC
LIMIT 3;문제 링크
7일 연속으로 올린 포스팅의 최대 갯수를 구해야 하기 때문에
단순히 week(post_date)나 1부터 7일, 8일에서 14일 처럼 기계적으로 끊으면 안 된다.
이 때문에 count over를 써서 먼저 avg_weekly_posts도 구해야 하고
중간에 range between도 써야하는 등 나름 중간 연산을 거칠 게 많은 것.
WITH a
AS
(
SELECT *,
count(*) over(partition BY user_id)/4 AS "avg_weekly_posts"
FROM posts
WHERE post_date BETWEEN '2024-02-01' AND '2024-02-28' ),
b
AS
(
SELECT *,
count(post_id) over(partition BY user_id ORDER BY post_date range BETWEEN INTERVAL 6 day preceding AND current row) AS "max_7day_posts"
FROM a )
SELECT DISTINCT user_id ,
max(max_7day_posts) AS "max_7day_posts" ,
avg_weekly_posts
FROM b
WHERE max_7day_posts >= 2*avg_weekly_posts
GROUP BY 1
ORDER BY 1;문제 링크
위에서 풀었던 해시태그 찾기의 심화버전.
이번에는 해시태그가 한 tweet 안에 2개 들어가있기 때문에
문자열을 다루는 방식이 조금 더 복잡해진다.
처음에 제출했던 쿼리는 이거였는데,
이건 테스트 케이스에서만 정답이었고 막상 제출하니 오답이 떴다.
WITH first_tag
AS
(
SELECT concat('#',substring_index(substring_index(substring_index(tweet,'#',-2),'#',1),' ',1)) AS "hashtag"
FROM tweets),
second_tag
AS
(
SELECT substring_index(substring_index(tweet,'#',-2),' ',-1) AS "hashtag"
FROM tweets),
result
AS
(
SELECT hashtag
FROM first_tag
UNION ALL
SELECT hashtag
FROM second_tag)
SELECT hashtag,
count(*) AS "count"
FROM result
GROUP BY 1
ORDER BY 2 DESC,
1 DESC
LIMIT 3;해시태그가 2개인 경우만 상정하고 작성한 쿼리였는데,
한 tweet 안에 해시태그 3개인 경우를 커버할 수 없기 때문.
third_tag를 만들어 풀 수도 있겠지만
그렇게 되면 해시태그가 4개인 경우를 커버할 수 없게 된다.
뭐가 됐든 근본적인 해결책은 아니라는 얘기.
결국은 이것도 recursive CTE를 만들어서 해결할 수밖에 없을 듯했다.
#이 나오면 무조건 그 뒤에 있는 놈을 떼어다가 해시태그처럼 인식하게 만들어야
한 tweet 안에 몇 개가 있든 모든 케이스를 다 커버할 수 있다.
우선 아래 쿼리를 실행해서 #뒤에 붙은 놈을 hashtag로 인식하고
regexp_replace를 써서 해시태그 제외한 나머지 부분을 tweet으로 지정했다.
SELECT REGEXP_SUBSTR (tweet, "#[^\\s]+") AS hashtag,
REGEXP_REPLACE(tweet, "#[^\\s]+", "", 1, 1) AS tweet
FROM Tweets실행한 결과는 아래와 같다.

성공적으로 첫 번째 해시태그가 뜯어져 나왔다.
두 번째 tweet의 경우 문장 중간에 해시태그가 들어가 있었음에도
깔끔하게 떨어져나온 것을 확인할 수 있다.
이제 recursive CTE를 써서 이 작업을 모든 #붙은 놈들한테 다 해주면 된다.
WITH RECURSIVE tags AS (
SELECT REGEXP_SUBSTR (tweet, "#[^\\s]+") AS hashtag,
REGEXP_REPLACE(tweet, "#[^\\s]+", "", 1, 1) AS tweet
FROM Tweets
UNION ALL
SELECT REGEXP_SUBSTR (tweet, "#[^\\s]+") AS hashtag,
REGEXP_REPLACE(tweet, "#[^\\s]+", "", 1, 1) AS tweet
FROM tags
WHERE hashtag IS NOT NULL
)
select *
from tags
order by 2이 쿼리를 실행해 보면 아래와 같은 결과가 나온다.
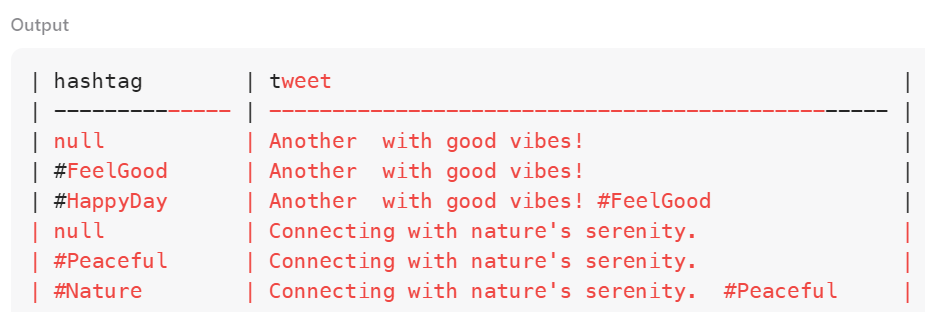
CTE가 반복되면서 최초 tweet으로부터 하나씩 해시태그를 떼어내고 있다.
이제 본 쿼리를 작성해 주면 끝.
WITH recursive tags
AS
(
SELECT regexp_substr (tweet, "#[^\\s]+") AS hashtag,
regexp_replace(tweet, "#[^\\s]+", "", 1, 1) AS tweet
FROM tweets
UNION ALL
SELECT regexp_substr (tweet, "#[^\\s]+") AS hashtag,
regexp_replace(tweet, "#[^\\s]+", "", 1, 1) AS tweet
FROM tags
WHERE hashtag IS NOT NULL )
SELECT hashtag,
count(*) AS count
FROM tags
WHERE hashtag IS NOT NULL
GROUP BY hashtag
ORDER BY count DESC,
hashtag DESC
LIMIT 3;recursive CTE가 이런 형태로도 작동할 수 있다는 걸 처음 알았다.
지금까지는 주로 집계함수나 window함수+recursive CTE조합을 많이 썼는데
이렇게 해시태그를 날리는 작업도 반복 실행할 수 있다.
굉장히 어렵지만 좋은 문제였다. 나중에 또 풀어보기로.
문제 링크
지난 수요일에 풀었던 코드카타의 medium 버전이다.
역시 recursive CTE를 써서 금요일만 잘 끌어올 수 있다면
특별히 어려울 건 없다. 중간에 cross join을 쓰는 것 정도?
WITH recursive friday
AS
(
SELECT row_number() over() AS "row_num",
'2023-11-03' AS "pdate"
UNION ALL
SELECT row_num+1,
date_add(pdate, INTERVAL 7 day)
FROM friday
WHERE pdate <= '2023-11-17'),
result
AS
(
SELECT u.membership,
purchase_date,
sum(amount_spend) AS "total_amount"
FROM users u
LEFT JOIN purchases p
ON u.user_id = p.user_id
WHERE membership IN ('Premium',
'VIP')
GROUP BY 1,
2),
temp
AS
(
SELECT DISTINCT row_num AS "week_of_month",
membership,
pdate
FROM friday,
result
ORDER BY 1,
2)
SELECT t.week_of_month,
t.membership,
ifnull(total_amount,0) AS "total_amount"
FROM temp t
LEFT JOIN result r
ON t.pdate = r.purchase_date
AND t.membership = r.membership
ORDER BY 1,
2;문제 링크
sec_to_time 함수를 처음 써 봤다.
초를 시간으로 바꿔주는 함수인데,
이걸 쓸 때 주의사항은 이것만 달랑 쓰면 안 되고
date_format으로 감싸서 내가 원하는 형태의 시간으로 바꿔줘야 한다는 것.
date_format의 인자 중 '%T'의 형태로 쓰면
알아서 24시간 포맷으로 바꿔준다. (hh:mm:ss의 형태로)
이 두 가지만 알고 있다면 나머지는 간단함.
WITH a
AS (SELECT c2.id,
type,
duration AS "total",
Rank()
OVER(
partition BY type
ORDER BY duration DESC) AS "ranking"
FROM calls c1
LEFT JOIN contacts c2
ON c1.contact_id = c2.id)
SELECT c.first_name,
a.type,
Date_format(Sec_to_time(total), '%T') AS "duration_formatted"
FROM a
LEFT JOIN contacts c
ON a.id = c.id
WHERE ranking <= 3
ORDER BY 2,
3 DESC,
1 DESC; 