데이터 집계
데이터 집계는 배열로부터 스칼라 값을 만들어내는
모든 데이터 변환 작업을 말한다. 앞선 예들에서
count, min, sum, mean 등을 통해 구한 모든 값들이 스칼라다.
직접 고안한 집계함수와
그룹 객체에 이미 정의된 메서드를 연결해서 사용하는 것도 가능하다.
예컨대 Series의 nsmallest 메서드는 요청받은 수만큼
데이터에서 가장 작은 값을 선택한다.
nsmallest가 명시적으로 groupby를 사용하는 것은 아니지만,
groupby가 Series를 분할한 다음 piece.nsmallest(n)을
분할된 조각(piece)에 대해 호출하고 결과를 모두 조합해 최종 결과 객체로 반환한다.
말만 들으면 역시 무슨 말인지 헷갈리니 예를 들어보자.
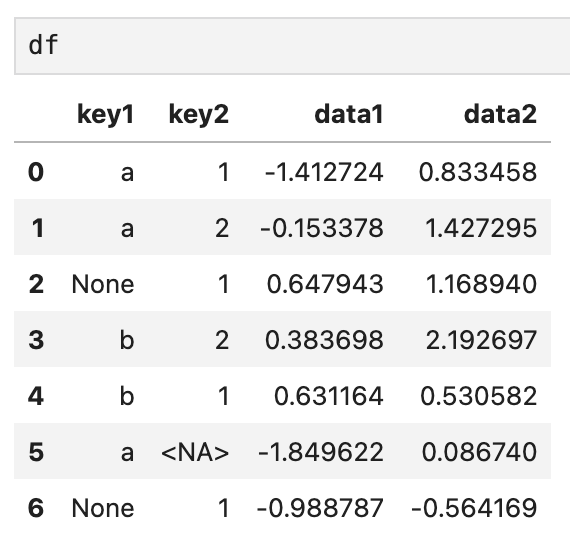
앞선 포스팅에서 살펴봤던 df를 다시 꺼내왔다.
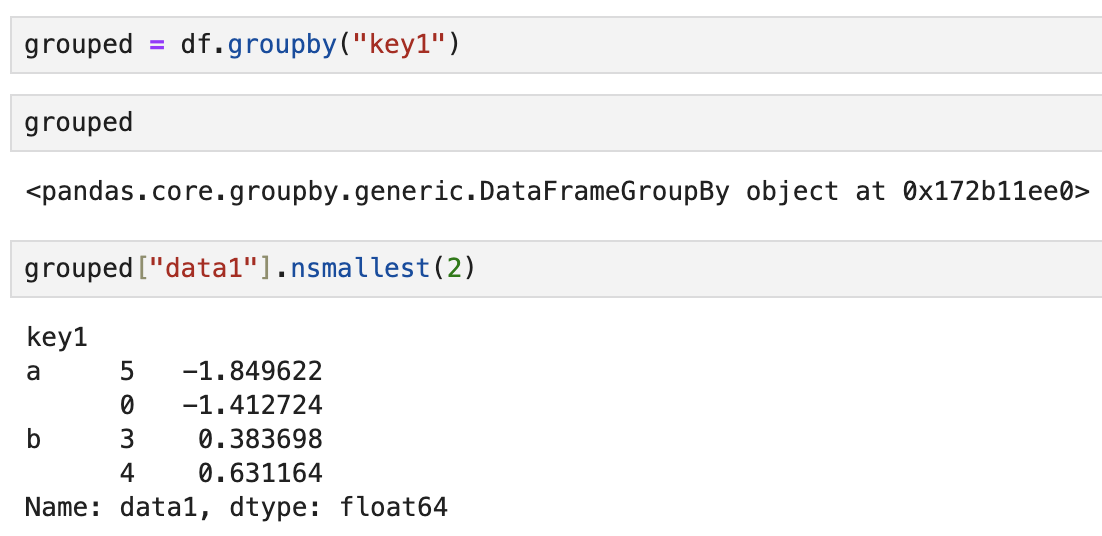
grouped 객체의 ["data1"] 열에 대해 가장 작은 값 2개를 집계한 결과다.
만약 자신이 생성한 함수를 사용하려면 배열의 aggregate나 agg 메서드에
해당 함수를 전달하면 된다. 즉,
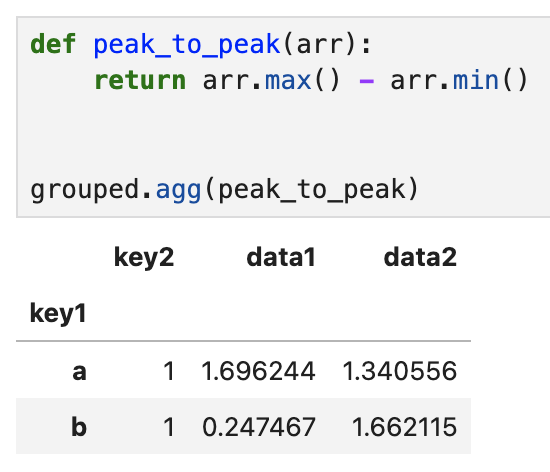
어떤 배열의 최대값에서 최소값을 빼 주는 함수 peak_to_peak가 있을 때,
grouped에 이 함수를 적용한 결과다.
이 때 grouped가 key1에 대해 그루핑된 결과인데
key2도 결과에 뜨고 + 그 결과값이 1로 고정된 이유는
key2 역시 수치형 컬럼이기 때문에 max-min이 계산되었고, 그 결과가 1로 모두 동일하기 때문.
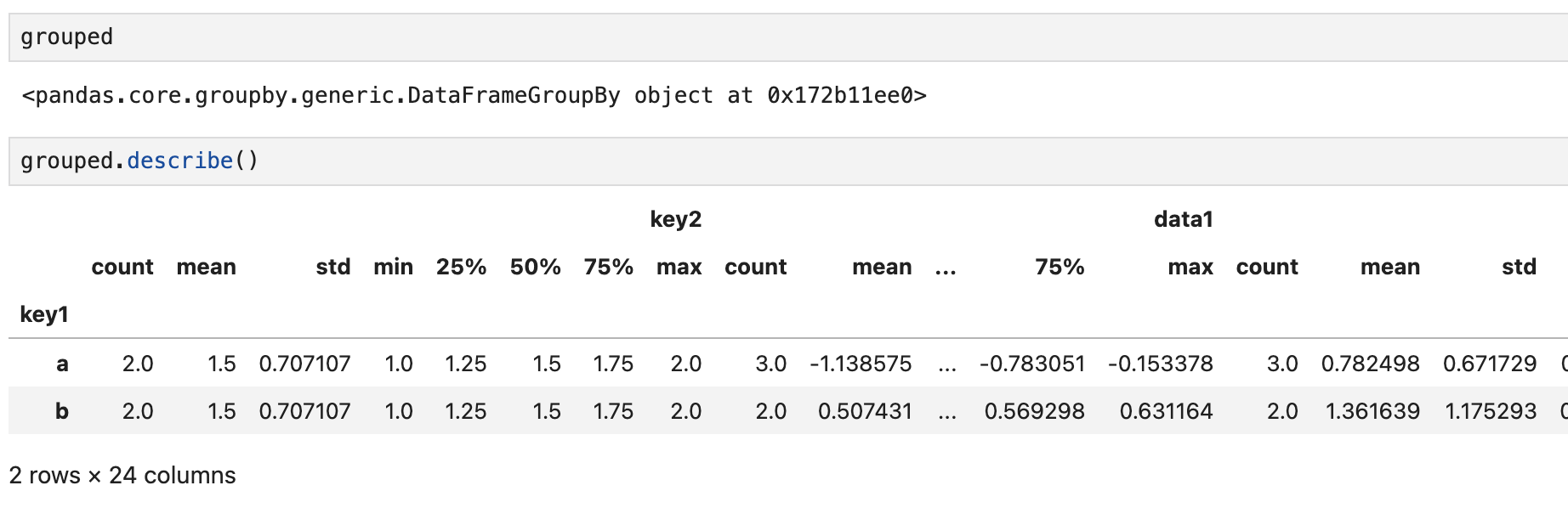
grouped 자체는 객체 속성 외에 아무것도 반환하지 않지만,
decribe 같은 메서드를 적용하면 데이터를 집계하지 않아도 잘 작동하는 것을 볼 수 있다.
