판다스에서 특정 데이터를 선택하는 방법으로 loc과 iloc이 있다.
사용하는 '방법'에 대해서는 배웠지만
정확한 의미나 원리는 모르고 있었는데,
오늘 공부하다가 마주친 김에 한 번 정리하고 넘어가야겠다.
loc
loc는 location의 약어로,
판다스의 Series나 DataFrame에서 레이블 기반 인덱싱을 수행하는 속성(attribute)이다.
예를 들어 아래와 같은 데이터가 있다고 했을 때,

특정 행만 보고 싶을 때
x라는 레이블을 가진 데이터만 보고 싶다면
아래와 같이 loc["x"]로 쓸 수 있다.
(결과가 세로로 출력되는 것은 단일 행이라 Series로 변환됐기 때문)

특정 열만 보고 싶을 때
특정 열을 선택해서 보고 싶으면 아래와 같이 쓸 수 있다.
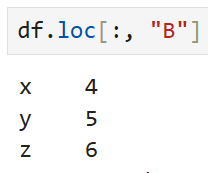
이 때 아무 것도 없이 그냥 df.loc["B"]라고 쓰면 오류가 뜨는데,
이것은 loc은 기본적으로 행 레이블을 찾도록 만들어졌기 때문이다.
즉, 행의 레이블은 x, y, z밖에 없는데
갑자기 B라는 행을 찾으라는 명령이 들어오니 오류가 나는 것.
따라서, 만약 loc를 써서 특정 열의 데이터를 찾으려면
먼저 :를 써서 행 전체를 선택해 준 후에 콤마(,)로 분리하고
그 뒤에 열(B)을 선택해야 한다.
(물론 특정 열의 데이터를 선택하는 더 간단한 방법은 그냥 df["B"]라고 쓰는 것)
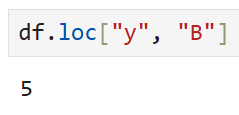
만약 y행 B열 데이터만 보고 싶으면
앞쪽 인자에 콜론 대신 "y"를 넣으면 된다.
결과는 그냥 해당 (행,열)에 해당하는 값이 나온다.
슬라이싱
loc를 써서 데이터를 슬라이싱할 때는
'시작할 행'부터 '찾으려는 행'까지 명시해 주면 된다.
이 때, 끝 값인 y도 포함된다는 점에 주의.

iloc
iloc는 integer-location의 약어로,
정수(integer) 위치를 기준으로 데이터를 선택하는 속성이다.
데이터는 위의 loc와 똑같은 데이터를 쓴다고 가정하고,
특정 행만 보고 싶을 때
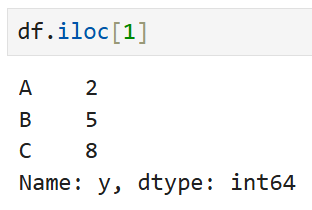
두 번째 행의 데이터만 보고 싶을 때에는
아래와 같이 iloc[1]로 표기해 주면 된다.
파이썬의 인덱싱 규칙에 따라 두 번째 행을 선택할 때 2가 아니라 1임에 주의.
특정 열만 보고 싶을 때
iloc도 loc와 마찬가지로 행 레이블을 찾는 것을
기본으로 만들어졌기 때문에, 특정 n번째 열의 데이터를 찾고 싶으면
먼저 '전체 행에 대하여~' 라는 말을 입력해 주어야 한다.
따라서, 예컨대 세 번째 열의 데이터만 보고 싶다면
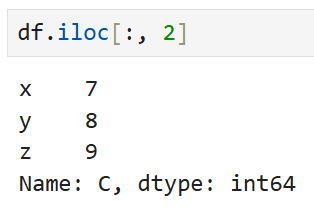
이렇게 쓰면 된다. 여기서도 마찬가지로
세 번째 열의 데이터를 보고 싶다면 3이 아니라 2를 넣음에 주의.
※ n번째의 무언가를 조회하고 싶다면 n이 아니라 n-1을 넣어야 한다.
슬라이싱
iloc의 슬라이싱은 loc와는 약간 다른데,
loc와 달리 iloc에서는 끝에 입력한 값이 포함되지 않는다.
예를 들어 첫 번째와 두 번째 행의 데이터만 잘라서 보고 싶다고 했을 때,

이렇게 입력해야 의도한 대로 두 번째 행까지 출력된다.
loc의 문법만 기억하고 있다가는 0,1,2
이렇게 3개 행이 출력되는 거 아닌가 헷갈릴 수 있다.
정확히 n번째의 무언가를 조회할 때는 n-1을 넣었지만
슬라이싱을 할 경우에는 의도한 대로 n을 넣어야 해서 지금도 많이 헷갈리는 부분.
한 가지 더 예를 들어서,
첫 번째부터 두 번째 '열'의 데이터만 잘라 보고 싶다고 하면
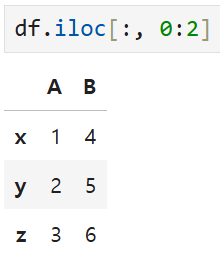
이렇게 되어야 하고,
첫 번째부터 두 번째의 행과 열의 데이터만 잘라서 보고 싶다 하면

이렇게 되어야 하는 것.
정리
loc와 iloc는 둘 다 기본적으로 데이터의 행 레이블을 찾도록 만들어진 속성이다.
다만 loc는 실제 행의 이름(레이블)을 기반으로,
iloc는 해당 행의 '정수 번째' 위치를 기반으로 찾는다는 점이 다르다.
데이터의 레이블이 명확하게 지정되어 있을 경우는 loc,
위치로 파악하는 정도로도 충분하다면 iloc를 사용하는 게 더 나을 것 같다.
아울러 loc의 슬라이싱에서는 범위 끝 값이 포함되지만
iloc의 슬라이싱에서는 범위 끝 값 직전까지만 포함된다는 점도 기억해 둘 것.
