데이터 변형
누락된 데이터를 처리하는 것 외에도
필터링, 정제, 변형도 매우 중요한 연산이다.
7.2.1 중복 제거하기
여러 가지 이유로 인해
DataFrame에서 중복된 행들을 발견할 수 있다. 예를 들어,
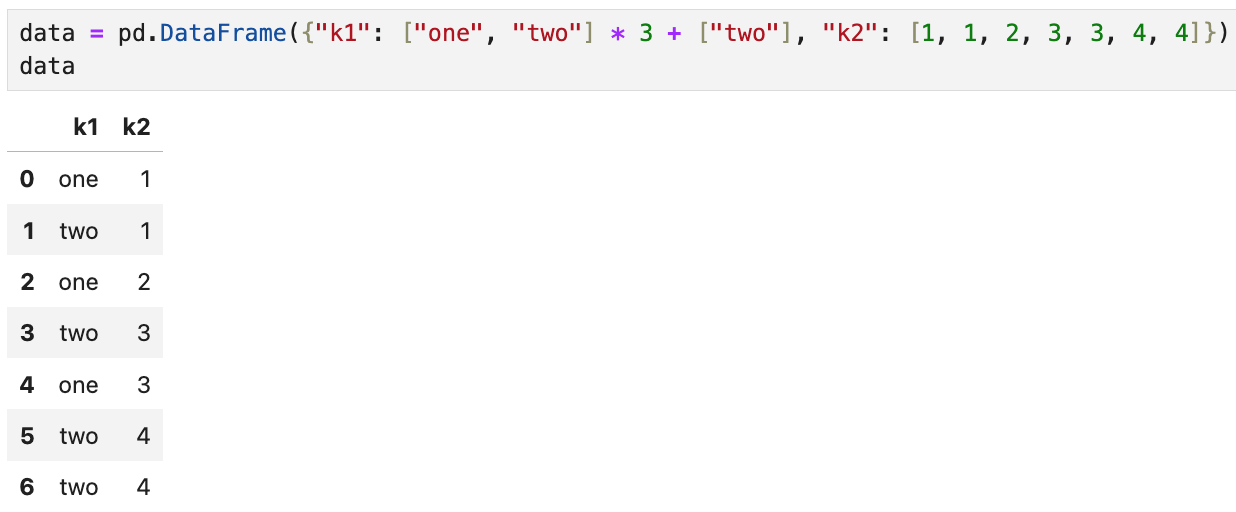
이렇게 생긴 데이터프레임이 있다고 하자.
여기서 duplicated 메서드를 쓰면 각 행이 중복인지 아닌지 여부를
불리언 Series로 반환한다. 즉,

결과는 이렇게 나온다.
똑같이 중복되는 조합이어도 먼저 나온 5행은 고유값으로 인정되고
뒤이어 나온 6행만 중복값으로 간주된다.
중복되는 값 2개가 모두 True로 나오는 게 아니라는 점 주의.
이제 drop_duplicates 메서드를 쓰면
duplicated의 연산 결과가 True인, 즉 중복된 행은 버려지고
중복되지 않는 고유 행들만 필터링되어 반환된다.

6행의 (two, 4)는 중복 행으로 간주되어 필터링된 것을 볼 수 있다.
이 두 메서드는 기본적으로 모든 열에 적용되는데,
중복의 기준을 부분집합처럼 지정할 수도 있다.
새로운 열을 하나 추가하고, k1열에 기반해 중복을 걸러보자.

data에 v1열이 새로 추가되었다.
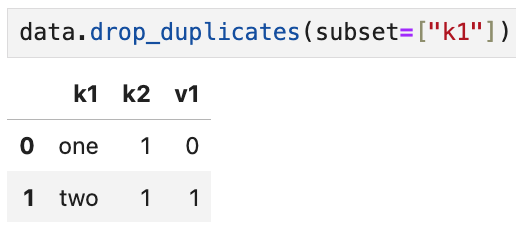
drop_duplicates 안에 인수로 subset을 주면
subset을 기준으로 중복 여부를 판별하게 된다.
위의 예에서는 기준이 k1 열이므로 최초에 나온 one, two를 제외하면
2행부터는 모두 (k1이 one 아니면 two이므로) 중복으로 간주되는 것.
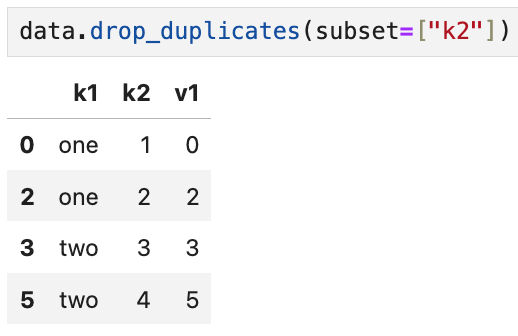
subset을 k2로 주면 k2 기준으로 중복을 판별한다.
1,2,3,4의 고유값들 중 첫 번째로 나왔던 0, 2, 3, 5번째 행만 유지되고
뒤이어 나온 행들은 중복으로 간주되어 필터링된다.

subset에 두 개 이상의 열을 넣어서
중복을 파악하고 제거할 수도 있다.
이 경우, subset에 판단하려는 열을 "리스트 형태로" 전달하면 된다.
data의 5행과 6행의 k1, k2열 조합이 모두 (two, 4)로 동일했으므로
6번째 행은 제외되고 5행까지의 결과만 반환된다.
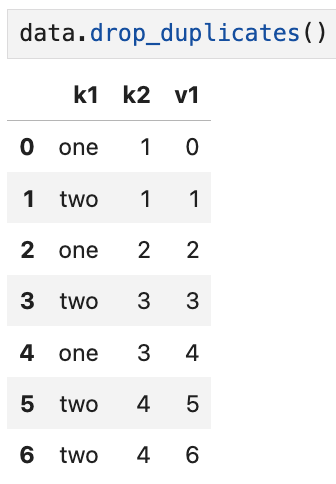
v1열을 추가하기 전에는
drop_duplicates만 적용해도 6행이 필터링되었으나,
이제 v1열이 추가된 덕분에 (two, 4, 5)와 (two, 4, 6)은
중복 행으로 간주되지 않아서 필터링되지 않는다.
duplicated나 drop_duplicates 모두 모든 열에 적용된다는 점을 기억할 것.
위에서 duplicated나 drop_duplicates 모두
기본적으로 처음 발견한 값을 유지하고
뒤이어 나오는 중복된 값을 중복으로 식별하고 제외한다고 했는데,
keep="last" 옵션을 넘기면 마지막으로 발견한 값을 반환한다. 예를 들어,

이렇게 되는 식이다.
예를 들어 시계열 데이터 중 중복 레코드가 끼어있을 때
가장 최신 데이터만 유지하고 싶을 때 이런 옵션을 쓸 수 있겠다.
기록 갱신처럼 가장 최신 값이 가장 신뢰할 만한 데이터일 때도 있다.
keep 인수의 디폴트는 first이고,
위에서 본 것처럼 last를 쓸 수도 있다.
False로 지정할 수도 있는데, 이렇게 하면 중복된 값이 모두 없어진다. 즉,
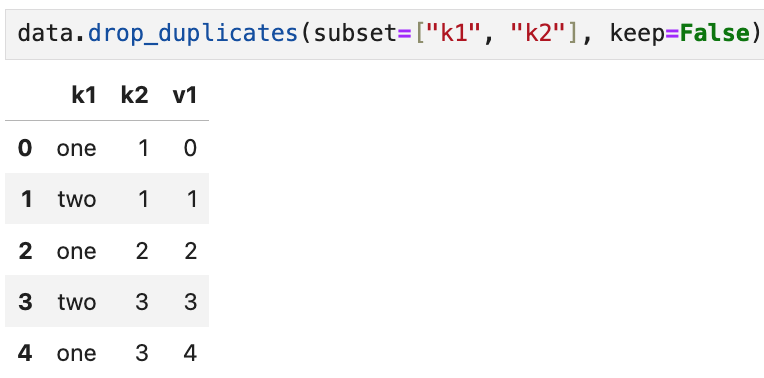
이렇게 하면 중복으로 간주된 5행과 6행의 데이터가 모두 필터링된다.
