7.2.4 축 색인 이름 바꾸기
Series의 값처럼 축 이름도
함수나 새롭게 바꿀 값을 이용해 변형할 수 있다.
새로운 자료구조를 만들지 않고도 그 자리에서 바로 변형이 가능하다.
예를 들어,

이렇게 생긴 데이터프레임이 있다고 하자.
Series와 마찬가지로, 축 색인에도 map 메서드가 있다.
따라서,

위와 같은 함수를 만들어서 data의 인덱스에 적용(data.index.map)하면
index의 값들 중 앞의 네 글자까지(:4)가 모두 대문자로 바뀐다.
New York의 경우는 띄어쓰기 때문에 'NEW '까지만 노출되는 것.
이렇게 대문자로 변경된 축 이름을 DataFrame의 인덱스에 바로 대입할 수 있다. 즉,
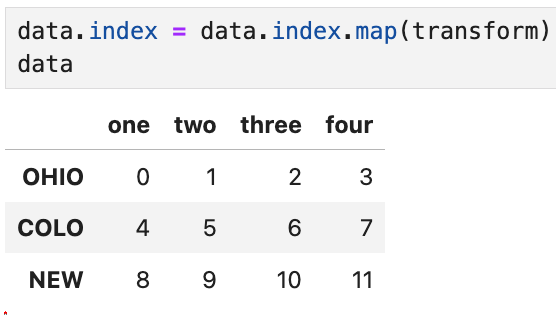
새로운 data.index는 data.index.map(transform)으로 대체되었다.
원래 객체를 변경하지 않고
새로운 객체를 생성하려면 rename 메서드를 이용한다. 예를 들어,

이 코드를 실행하면
index는 (위의 함수가 실행된 결과가 남아있으므로)
4글자짜리 대문자로 되어 있던 상태에서 첫 글자만 대문자가 되고
나머지는 소문자로 바뀐다. (str.title)
컬럼은 str.upper에 의해 전부 대문자로 바뀌었다. (ONE, TWO...)
다만 이 코드를 실행해도 원본 data는 여전히 그대로 유지된다.
만약 새로운 데이터프레임을 다른 이름으로 저장했다가 활용하고 싶다면
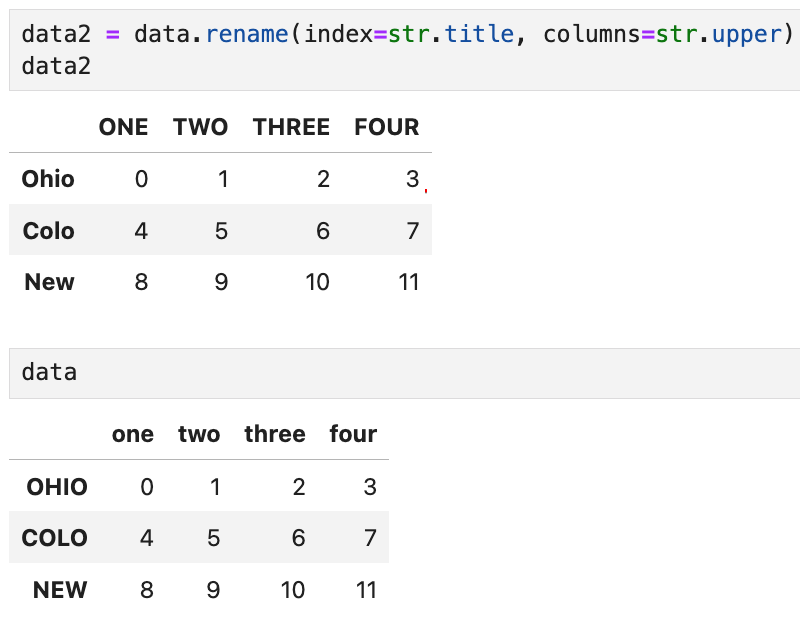
이렇게 별도의 이름을 선언해서 저장해 주면 된다.
rename 메서드를 쓸 때,
딕셔너리 형태의 객체를 이용해 축 이름 중 일부만 변경할 수도 있다.
예를 들면
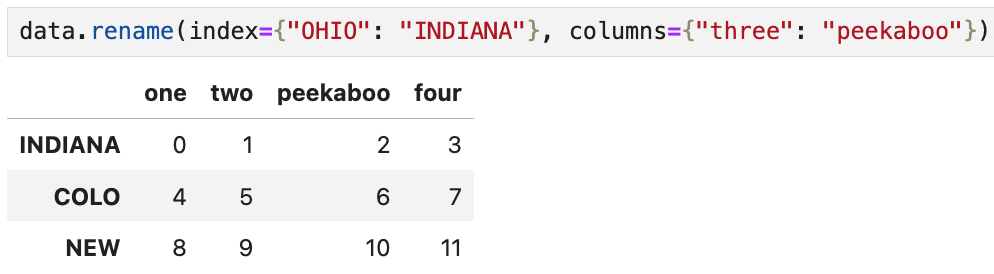
이렇게 행과 열의 이름을 각각 하나씩만 변경할 수도 있다.
행의 축 OHIO가 INDIANA로,
열의 축 three가 peekaboo로 각각 변경된 것을 확인할 수 있다.
