판다스 자료 구조
판다스를 잘 다루려면
대표적인 자료 구조 Series와 DataFrame에 익숙해질 필요가 있다.
이 두 가지 자료구조로 모든 문제를 해결할 수는 없지만
대부분의 데이터 업무에서 사용하기 쉽고 탄탄한 기반을 제공한다는 이점이 있다.
Series
Series의 정의와 기본 구조
Series는 1차원 배열 같은 자료구조다.
어떤 넘파이 자료형이라도 담을 수 있고,
색인Index이라고 불리는 배열의 데이터와 연관된 이름을 갖는다.
*앞으로는 '색인'과 '인덱스'라는 용어를 혼용할 예정
아래는 간단한 Series의 예시.
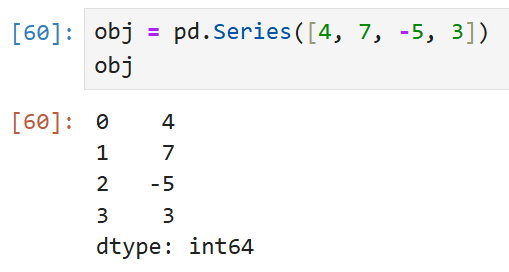
왼쪽에는 인덱스, 오른쪽에는 해당 인덱스의 값이 나온다.
뒤에서 다시 언급하겠지만 이 사례에서는 인덱스를 따로 지정하지 않았기 때문에
기본 인덱스인 0부터 n-1(n은 데이터의 길이)까지 인덱스가 자동으로 지정된다.

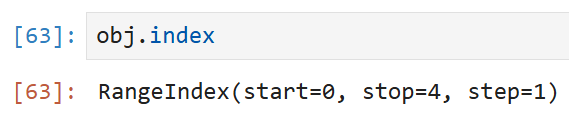
Series의 배열과 색인을 조회하려면
각각 array와 index 속성을 통해 확인할 수 있다.
index 속성에서 start는 시작하는 인덱스의 값,
stop은 index의 총 길이, 그리고 step은 인덱스가 1씩 커진다는 것을 의미한다.
Series에서 인덱스를 지정하는 경우
위의 예에서는 인덱스를 따로 명시하지 않았으므로
0부터 n-1까지 자동으로 인덱스가 매겨졌지만,
인덱스를 직접 지정해서 Series를 생성해야 할 때는 아래와 같이 하면 된다.
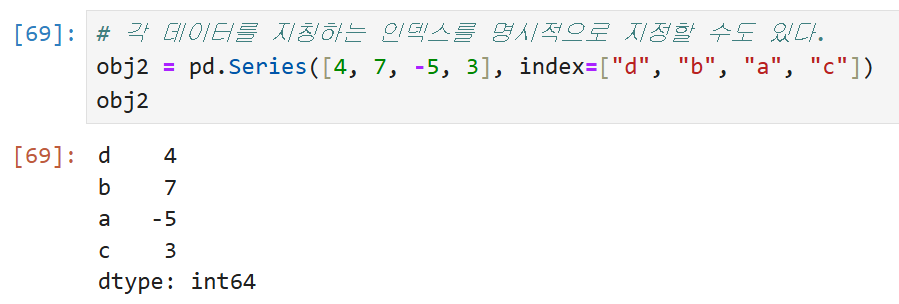

인덱스로 레이블(label)을 사용할 수 있다.
위의 obj2에서 인덱스 a에 해당하는 값은 -5이므로,
obj2["a"]를 호출하면 -5가 반환된다.

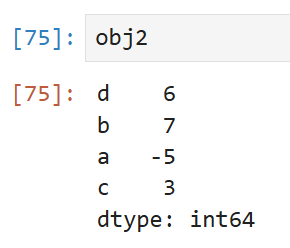
특정 인덱스를 지정해서 값을 변경하면 변경된 값이 적용된다.
최초 obj2에서 인덱스 d에 해당하는 값은 4였지만 이제는 6으로 변경된 것을 볼 수 있다.

인덱스에 정수가 아니라 문자열이 포함되어 있어도
인덱스의 배열로 알아서 해석된다.
obj2라는 Series에 있는 데이터를
인덱스 기준으로 자유롭게 순서를 변경해서 불러올 수 있다.
넘파이 array 연산을 수행해도 인덱스와 값의 연결은 유지된다
위에서 예로 들었던 obj2를 다시 보자.
여기서 불리언을 사용해 값을 걸러내도
인덱스와 값의 연결은 유지된다.
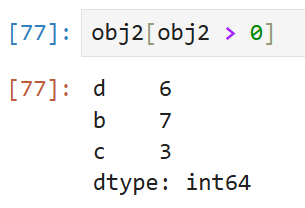
0보다 큰 경우에 해당하지 않는 인덱스 a와 그에 해당하는 값 -5는 제외되고,
나머지 데이터들만 원래 인덱스 배열에 맞게 정상적으로 출력되었다.
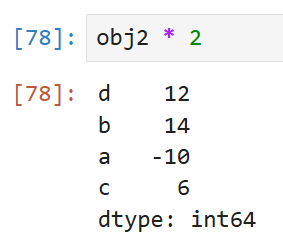
스칼라 곱셉을 수행하는 경우에도
인덱스와 값의 연결은 견고하게 유지된다.
넘파이의 수학 함수를 적용해도 마찬가지.
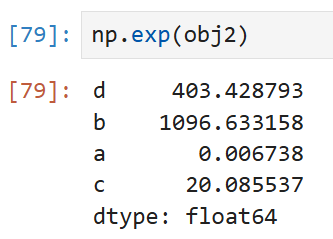
색인과 값의 연결이 유지된다는 것이 핵심이다.
파이썬 딕셔너리와 판다스 Series
Series를 일종의 정렬된 딕셔너리라고 이해할 수도 있다.
딕셔너리가 key와 value의 조합으로 이루어져 있듯이,
Series도 인덱스에 해당 데이터 값이 매핑되어 있으므로
구조상 딕셔너리와 비슷하다.
파이썬 딕셔너리가 필요한 곳에 판다스 Series를 쓸 수도 있다.
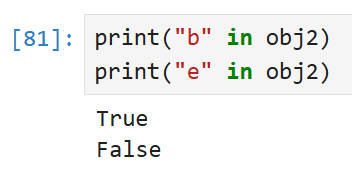
key(index) e에 해당하는 값은 obj2에 존재하지 않기 때문에 False가 뜬다.
파이썬 딕셔너리에 데이터를 저장해야 한다면
딕셔너리 객체로부터 Series를 생성할 수도 있다. 예를 들어,
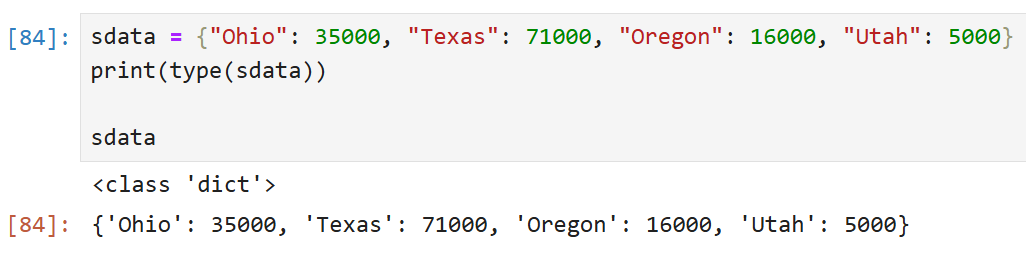
이런 파이썬 딕셔너리를 생성했다고 가정해 보자.
이걸 판다스 Series로 받으면 아래와 같은 형태로 바뀐다.
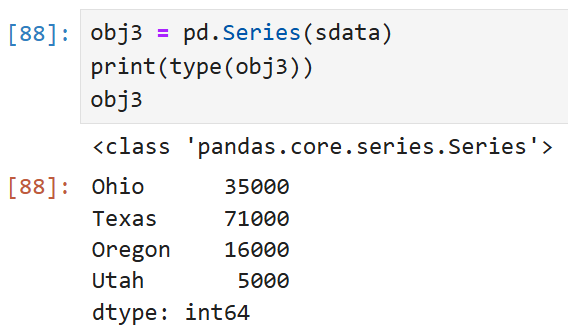
거꾸로, to_dict 메서드를 이용해서
판다스 Series를 파이썬 딕셔너리로 변환할 수도 있다.
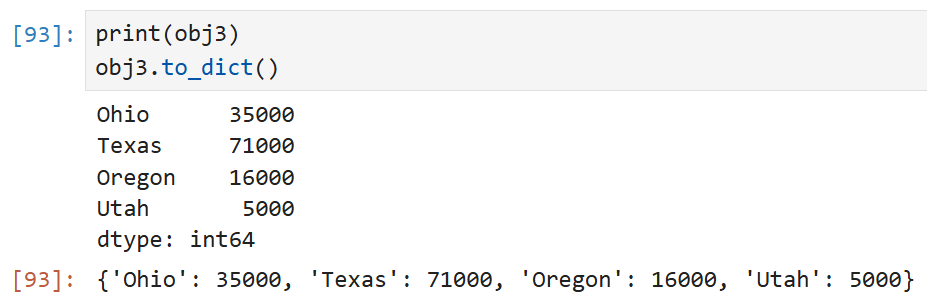
위의 결과가 Series인 obj3을 출력한 결과이고,
아래 결과는 to_dict를 이용해 obj3을 딕셔너리로 변경한 결과다.
(이름은 따로 안 정함)
딕셔너리만 갖고 Series를 생성하면
생성된 Series의 색인은 딕셔너리의 key에서 반환하는 값의 순서대로 들어간다.
위의 예에서 sdata 딕셔너리의 key 순서가
Ohio, Texas, Oregon, Utah 순으로 되어 있었으므로
그걸 그대로 Series로 변환한 결과물인 ojb3의 인덱스 역시
Ohio, Texas, Oregon, Utah 순으로 들어간다는 얘기.
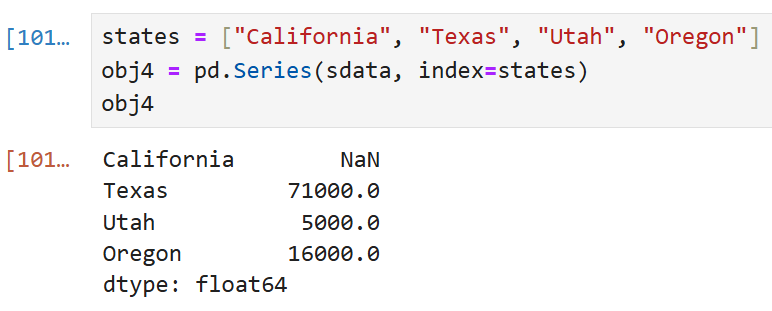
만약 인덱스를 직접 지정하고 싶다면 원하는 순서대로 인덱스를 넘길 수도 있다.

obj4의 인덱스는 states라는 리스트로부터 전달받는데,
sdata안에 California는 없었으므로 NaN으로 표시된다.
그 외의 나머지 값들은 인덱스에 따라 정상적으로 표시됨을 볼 수 있다.
물론 인덱스의 순서를 변경하거나 빼더라도
위에서 살펴본 바와 같이 인덱스와 값의 연결은 견고하게 유지된다.
Series 내의 누락된 데이터
판다스의 isnull과 notnull 함수는
누락된 데이터를 찾을 때 사용된다.

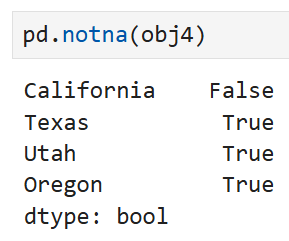
isna와 notna는 똑같은 불리언 함수인데 로직만 정반대다.
위의 예에서 California는 값이 없었으므로,
isna로 찾으면 True가 반환되고, notna, 즉 누락이 없는 값을 찾을 때는 False로 나온다.

isna를 pd.isna(obj4)로 쓸 수도 있지만
obj4.isna()처럼 인스턴트 메서드로 쓸 수도 있다.
Series끼리 연산에서의 데이터 정렬
Series의 유용한 기능 중 하나는
산술 연산을 할 때 인덱스와 레이블로 자동 정렬하는 기능이다.
예를 들어,
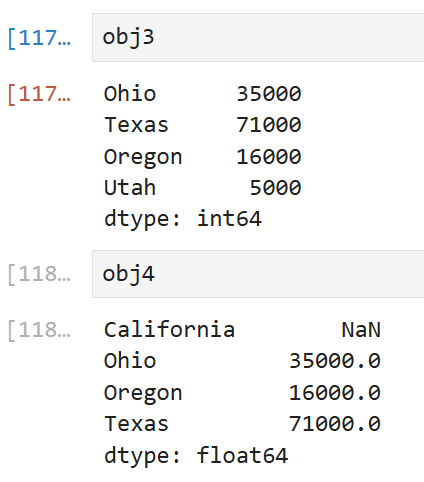
이렇게 생긴 두 개의 Series가 있다고 했을 때,
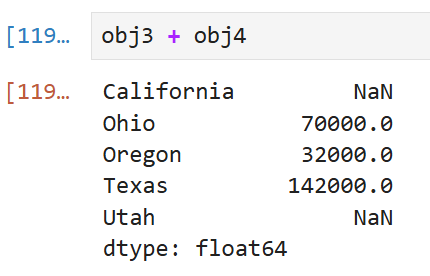
두 객체를 더한 obj3 + obj4의 결과는 위와 같이 나온다.
이 중 California는 obj4에서 아예 값이 없었으므로
합산 결과도 NaN이 나오는 게 직관적으로 이해하기 무리가 없는데,
ojb3에서의 Utah는 5000이라는 값이 있음에도
더한 결과에서도 NaN이 뜨는 게 직관적으로 이해가 되지 않을 수 있다.
나중에 별도의 포스팅에서 다룰 기회가 있겠지만,
이는 판다스의 자동 인덱스 정렬 및 alignment에 의한 결과다.
간단히 말해, 두 개의 Series끼리 연산을 할 때는
'공통으로 갖고 있는 인덱스'에 대해서만 연산이 수행된다.
Series의 name 속성
Series 객체 자체와 인덱스는 모두 name 속성을 가지며
이 속성은 판다스의 다른 기능들과 통합되어 있다. 예를 들어,
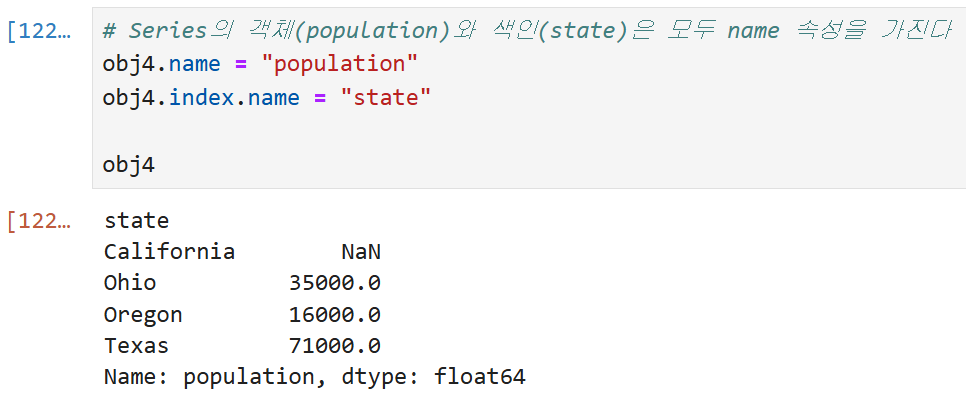
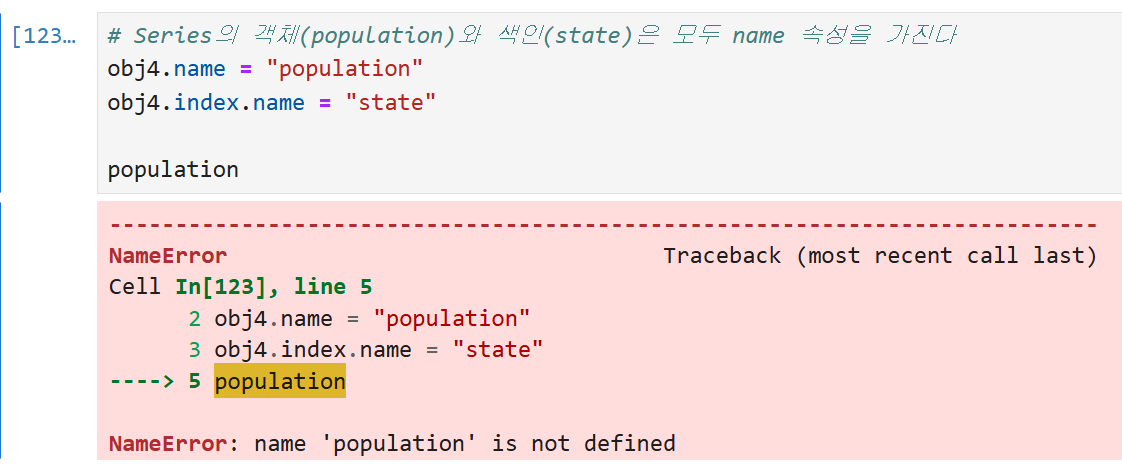
obj4라는 Series의 이름을 population,
ob4의 인덱스 이름을 state로 지정해 주고 obj4를 불러와 보면
state와 population이라는 이름이 붙어서 나오는 것을 볼 수 있다.
다만, 이렇게 이름을 지정해준다는 것이
population이라고만 쳤을 때 obj4가 출력된다는 뜻은 아니다.
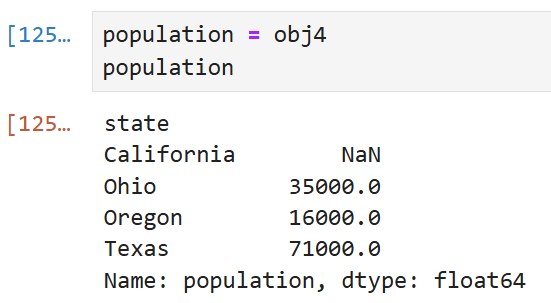
population을 이름으로 지정하고 싶으면 이렇게 해야 한다.
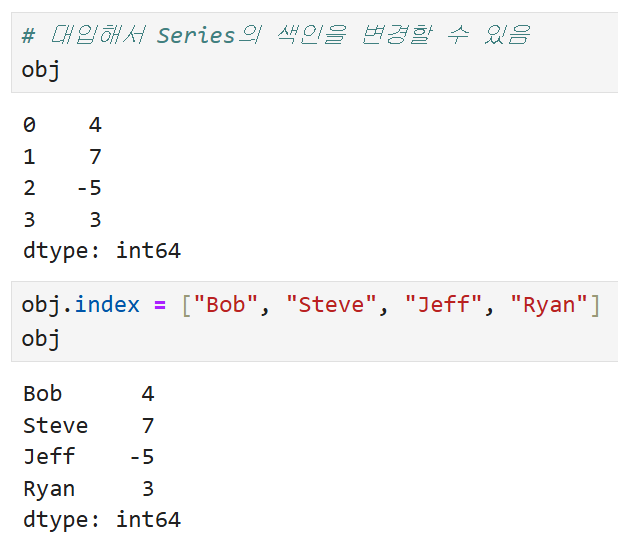
위에서 살펴본 바와 동일하게,
대입으로 Series의 색인을 변경하는 것도 가능하다.
DataFrame
DataFrame은 표 형식의 자료구조로,
엑셀이나 스프레드시트를 자주 보던 사람에게는 특히 친숙한 형태일 것이다.
DataFrame은 행과 열에 대한 인덱스(색인)를 가지며,
Series 객체를 여러 개 담고 있는 딕셔너리로 생각하면 편하다.
DataFrame의 기본 구조
여러 가지 방법으로 DataFrame을 생성할 수 있지만,
가장 흔한 방법은 동일한 길이의 리스트에 담긴 딕셔너리를 이용하거나
넘파이 배열을 이용하는 방식이다. 예를 들어,

위와 같은 형태의 data가 있다고 생각해 보자.
data는 파이썬 딕셔너리로, state, year, pop이 key이고
각각의 key에 해당하는 value들이 리스트 형태로 들어있는 구조다.
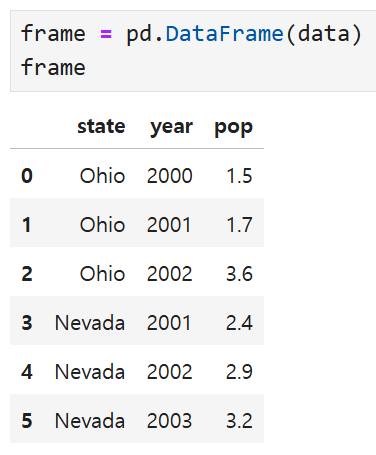
이 data를 DataFrame으로 바꾸면
인덱스는 Series와 동일한 방식으로 자동 할당되며 (물론 지정할 수도 있음)
열은 data의 순서, 즉 key의 순서에 따라 정렬되어 저장된다.
※ 주피터 노트북에서는 보기 편하게 html 표 형식으로 출력됨
위에서 "동일한 길이의 리스트에 담긴 딕셔너리"를 사용해야 한다고 했는데,
이 점에 특히 주의해야 한다.
만약 위의 data에서 각 value에 해당하는 리스트 중
값 하나라도 삭제해서 길이가 동일하지 않게 되면
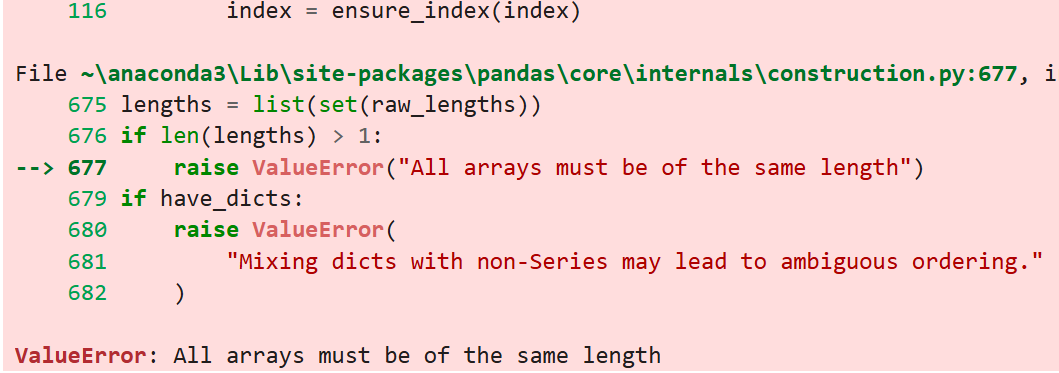
어쩌구저쩌구 시뻘건 에러창이 뜨는데,
제일 마지막 줄을 보면 '모든 배열은 길이가 같아야 함' 이라고 뜨는 것을 확인할 수 있다.
DataFrame 다루기
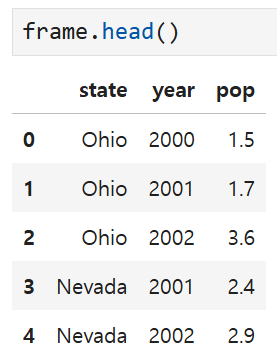
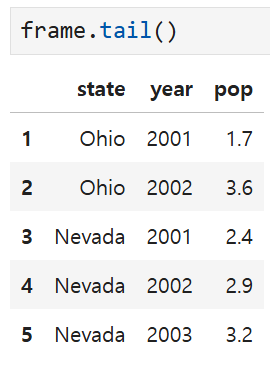
큰 DataFrame을 다룰 때는
head나 tail 메서드를 사용해 처음 5개, 혹은 마지막 5개 행만 출력할 수 있다.
물론 head나 tail 안에 인자를 넣어서
원하는 갯수만큼 출력하는 것도 가능하다.
columns를 원하는 순서대로 지정하면
해당 순서로 정렬된 DataFrame 객체가 생성된다
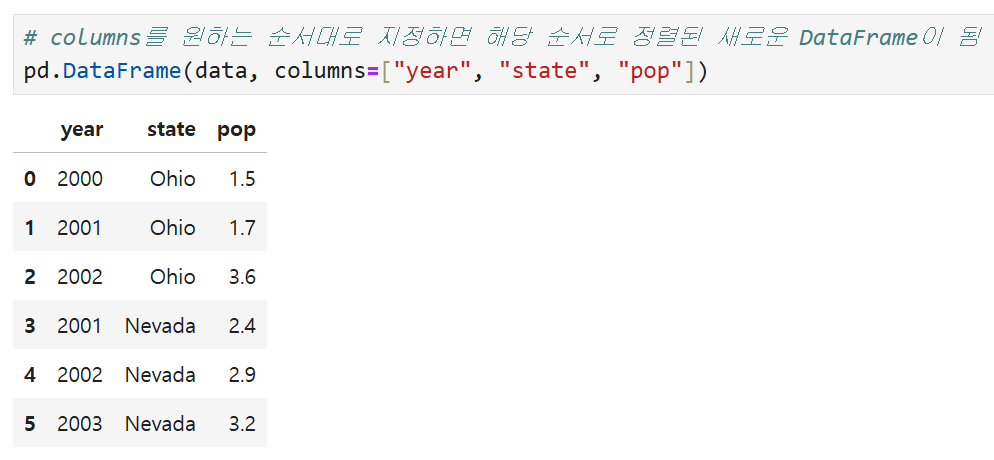
state, year, pop 순으로 정렬되어 있던 컬럼의 순서를
year, state, pop 순으로 변경하였다.
만약 DataFrame을 만들 때 기초가 됐던
딕셔너리(위의 예에서는 data)에 없는 값을 columns에 넘기면
결과에 결측치missing value가 표시된다.
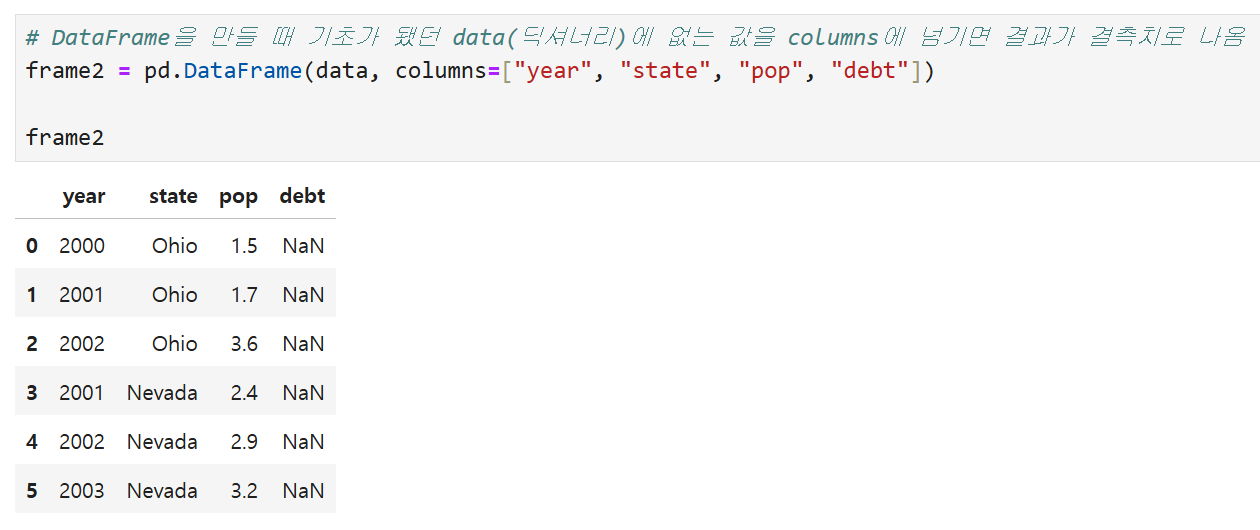
data에 없던 debt를 columns에 추가한 결과.
debt 컬럼에는 전부 NaN이 떠 있는 것을 볼 수 있다.
DataFrame의 열은
Series처럼 딕셔너리 형태의 표기법이나 점 표기법으로 접근할 수 있다.



columns 전체의 목록을 조회하거나
특정 컬럼(state)에 해당하는 행만 딕셔너리처럼 불러오거나
점 표기법으로 .year만 불러오는 것이 가능하다.
iloc나 loc 등으로 행에 접근하기
iloc나 loc에 대한 자세한 설명은 별도 포스팅 참고!
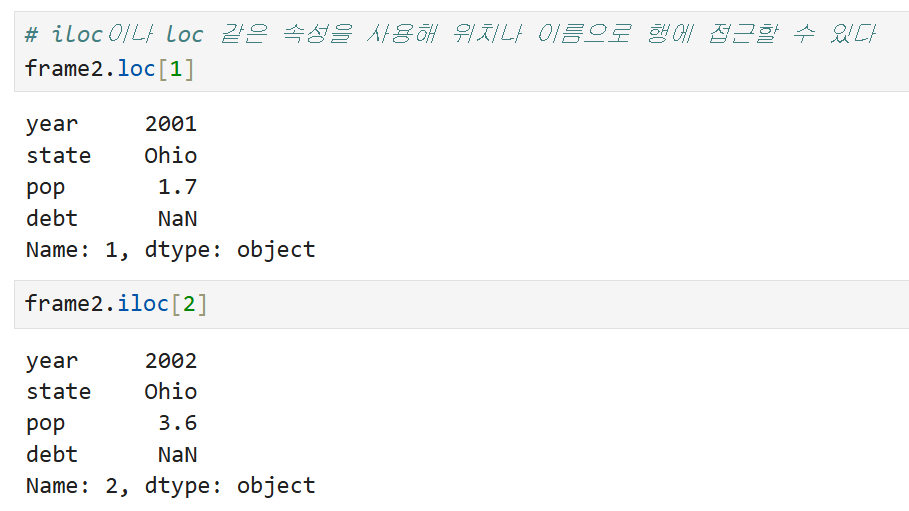
loc를 써서 1, 즉 두 번째 행에 해당하는 데이터를 불러오면
데이터가 저렇게 세로로 정렬되는 것을 확인할 수 있다.
iloc를 써서 2, 즉 세 번째 행에 해당하는 데이터를 불러와도 마찬가지.
이건 특정 행을 불러왔을 때 반환되는 데이터의 기본 형태가
Series이기 때문이다. Series가 기본적으로 세로 방향(1차원 배열)으로 정렬되기 때문에
iloc나 loc를 써서 하나의 행만 불러오면 세로로 보이게 되는 것.
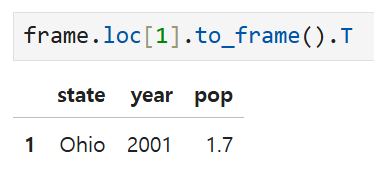
이게 싫으면 두 가지 방법이 있는데,
1. to_frame() 메서드를 사용하는 방법
대문자 T는 transpose의 약어로 행과 열을 뒤집는다는 의미다.
저걸 안 쓰면 똑같이 세로로 보임.
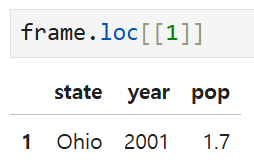
2. 슬라이싱을 사용해 반환값을 DataFrame으로 유지하는 방법
대괄호로 한 번 감싸면 Series, 두 번을 감싸면 DataFrame으로 반환된다.
열 수정하기
대입으로 곧바로 열을 수정할 수 있다.
예를 들어, 위에서 NaN으로 되어 있던 debt 열에
스칼라 값이나 배열 자체를 대입하는 것이 가능하다.
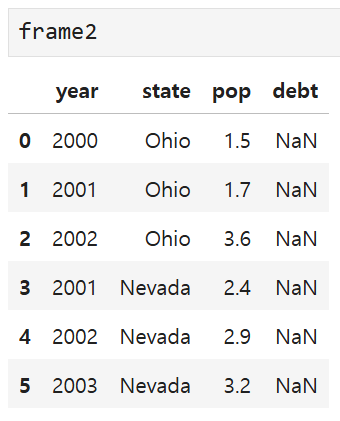
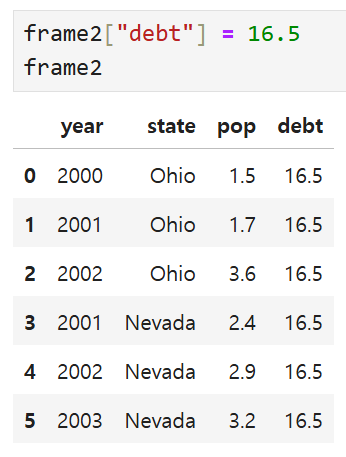
debt 열에 16.5라는 스칼라 값이 일괄적으로 추가되었다.
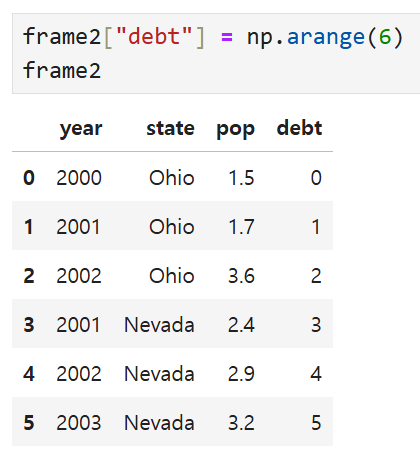
넘파이 배열을 넣어서 debt 열을 수정한 예시.
이 때도 역시나 배열의 길이가 맞아야 한다. (안 맞으면 오류 뜸)
리스트나 배열을 열에 대입할 때는
대입하려는 값의 길이가 DataFrame의 길이와 동일해야 한다.
Series를 대입하면 DataFrame의 색인에 맞추어 자동으로 값이 대입되며,
존재하지 않는 색인에는 결측치가 들어간다. 아래는 예시.
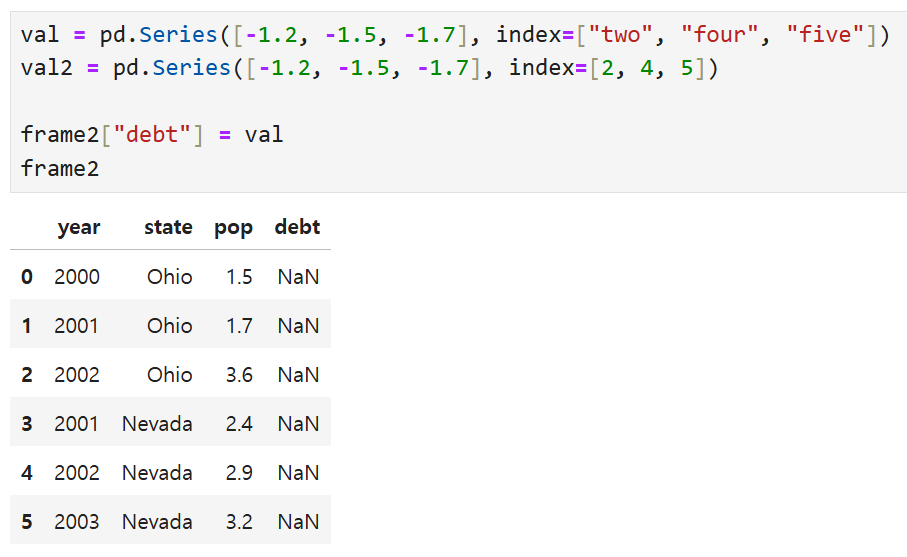
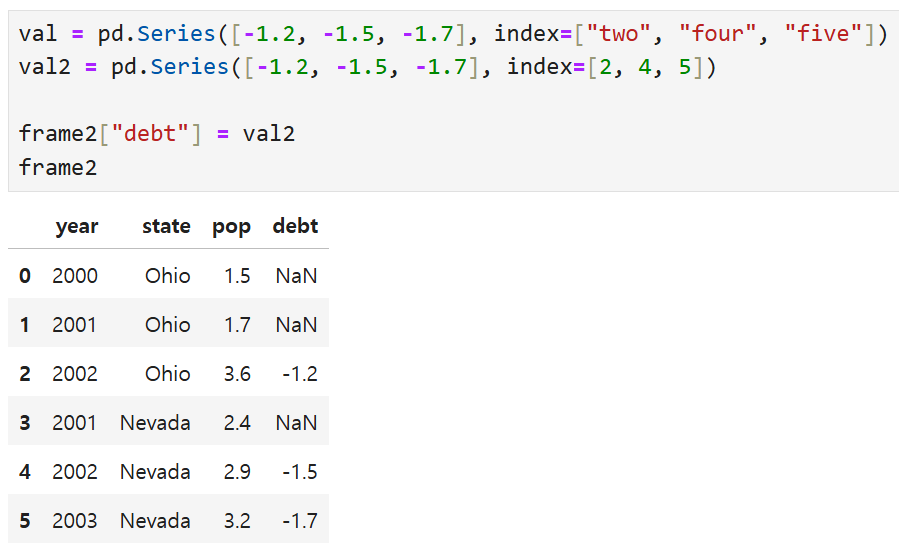
debt 열에 Series val을 넣을 때에는 일치하는 인덱스가 없으므로
여전히 모든 debt 열에 NaN이 뜨지만,
val2를 넣으면 일치하는 인덱스(2, 4, 5)에는 대응되는 값이 들어가고
나머지에만 NaN이 뜨는 것을 볼 수 있다.
존재하지 않는 열을 대입할 경우 새로운 열이 생성된다.
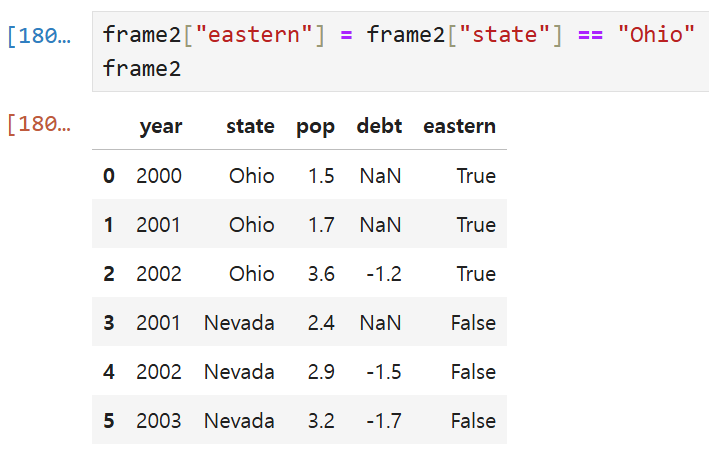
'frame2의 state 열의 값이 Ohio인지 여부'를 묻는 불리언 값이
eastern이라는 이름의 열로 새롭게 추가된 것을 볼 수 있다.
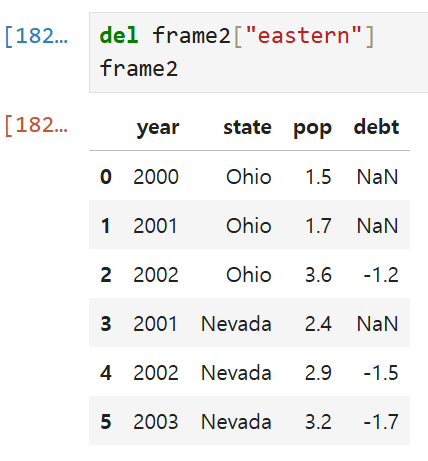
이미 만들어진 열을 삭제할 때에는]
예약어 del을 쓰고 DataFrame["지우려는 컬럼명"]을 적어주면 삭제된다.
이 때, DataFrame의 색인을 이용해 얻은 열은
내부 데이터에 대한 뷰일 뿐이며 복사가 일어나지 않는다.
즉, 열을 만들고 삭제하는 등의 액션이 원본 DataFrame에 곧바로 적용된다는 얘기.
따라서 안전하게 데이터를 조작하려면
copy 메서드를 써서 복사본을 만들어 두고 진행하자.
중첩된 딕셔너리로 DataFrame을 만드는 경우
중첩된 딕셔너리를 DataFrame에 넘기면
바깥에 있는 딕셔너리의 key가 열이 되고 안에 있는 key가 행이 된다.
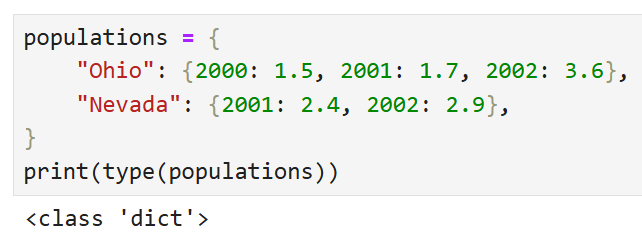
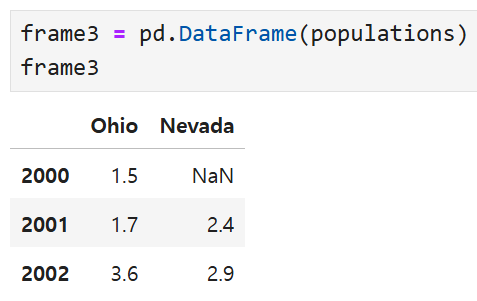
바깥에 있는 key인 Ohio와 Nevada가 열이 되고
안에 있는 key인 2000, 2001, 2002가 행이 된 모습을 볼 수 있다.
물론 가장 안쪽에 있는 value가 각 행/열에 해당하는 데이터가 된다.
이 때 넘파이 배열과 유사한 방법으로 데이터를 전치하는 것도 가능하다.
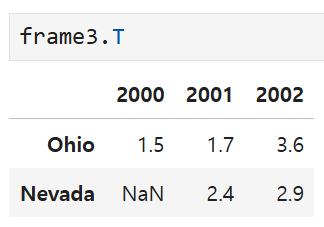
중첩된 딕셔너리를 써서 DataFrame을 생성할 때,
가만히 냅두면 안쪽에 있는 key가 행, 즉 결과의 인덱스가 되지만
인덱스를 직접 지정하면 지정한 인덱스로 DataFrame이 생성된다.
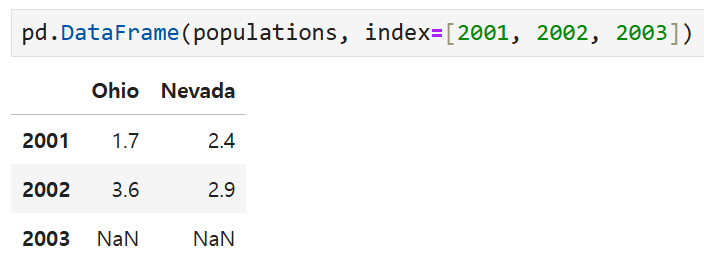
위의 populations에 안쪽 딕셔너리 키가 이미 있지만
DataFrame 생성 과정에서 인덱스를 직접 지정해 줌에 따라
2001, 2002, 2003으로 인덱스가 고정된 모습이다.
Ohio와 Nevada 모두에 2003에 해당하는 값이 없으므로 NaN이 뜨는 것.
DataFrame에서 데이터 잘라 담기(슬라이싱)
DataFrame에서 원하는 데이터를 잘라서 새로운 DataFrame을 만드는 것도 가능하다.
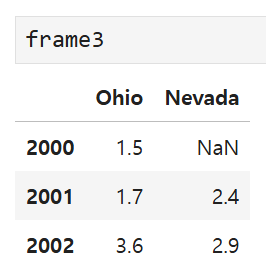
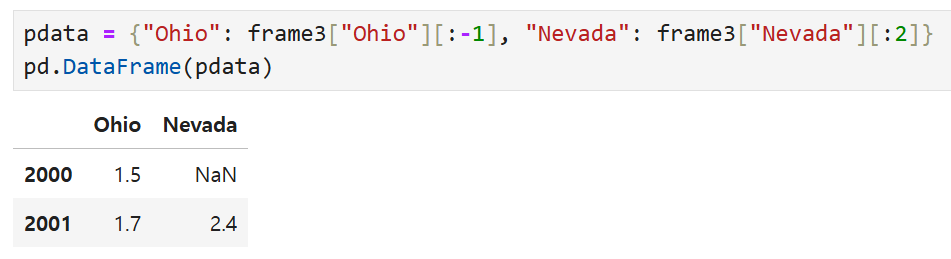
Ohio는 마지막 행을 제외한 모든 데이터 선택 + Nevada는 처음 두 행을 선택 (-1로 해도 결과가 같긴 함)
DataFrame의 name 속성
만약 DataFrame의 색인과 열에 name 속성이 설정되어 있다면
이 정보도 함께 출력된다. 예를 들어,
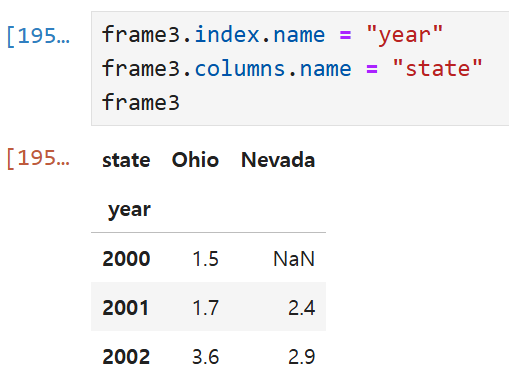
인덱스의 이름을 year, 열의 이름을 state라고 부여해 주면
frame3이라는 DataFrame을 부를 때 저 이름들도 같이 나오는 식.
Series와는 다르게 DataFrame에는 name 속성이 없다. (그래서 행과 열에 이름을 붙여주는 것)
Dataframe의 형태 변환
DataFrame의 to_numpy 메서드는
DataFrame에 포함된 데이터들을 2차원의 ndarray로 변환한다.
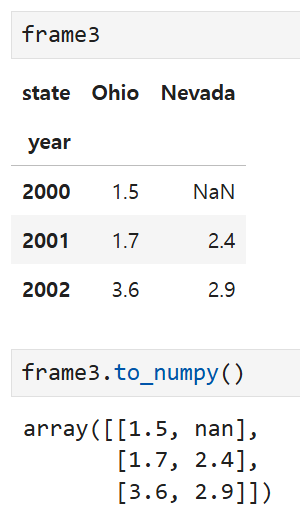
DataFrame의 열들이 서로 다른 자료형(정수, 문자, 실수 등)을 가질 경우
모든 열을 수용할 수 있는 가장 일반적인 자료형이 선택된다. 예를 들어,
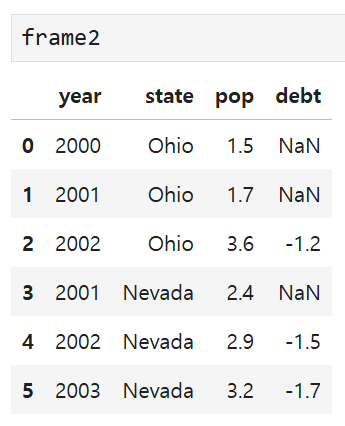
frame2에서 state는 문자, pop는 실수, year는 정수 등으로
자료형이 모두 다른데, 이렇게 생긴 DataFrame을 넘파이 배열로 바꾸면

이렇게 된다. 위의 경우 dtype = object 라고 되어 있는데,
이는 최소 공통 자료형의 순서가
문자열(object) > 실수(float) > 정수(int) > 논리(bool)에 따른 것이기 때문.
Index
판다스의 인덱스 객체는 축 레이블과
다른 메타데이터를 저장하는 객체다.
Series나 DataFrame을 생성할 때 사용하는 배열이나 다른 순차적인 레이블은
내부적으로 인덱스로 변환된다. 예를 들어,


위의 Series에서 인덱스만 따로 obj.index로 뽑아보면
인덱스만 뽑혀 나오는 것을 볼 수 있다.
인덱스의 성질
-
인덱스는 변경이 불가능하다.

위의 Series에서 1, 즉 2번째에 해당하는 index를 뽑아보면 b가 나오는데,
이걸 다른 값으로 대입해서 수정하는 것은 불가능하다. 즉,
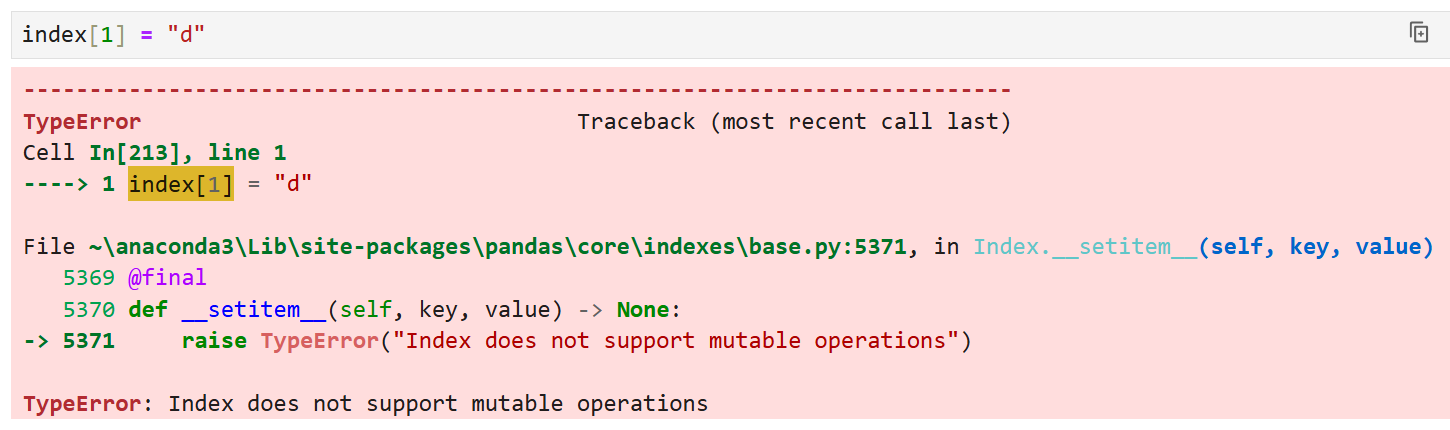
이렇게 맞바로 수정하는 것은 안 된다는 얘기.
인덱스는 mutable, 즉 가변 연산을 지원하지 않는다는 경고 메시지를 확인할 수 있다.
이러한 인덱스의 불변성 덕분에
자료구조 사이에서 색인을 안전하게 공유할 수 있다. 예를 들어,

obj의 인덱스가 labels냐는 불리언 타입의 질문에 True가 나옴을 볼 수 있다. -
배열ndarray과 유사하게, 인덱스 객체도 고정된 크기로 작동한다.
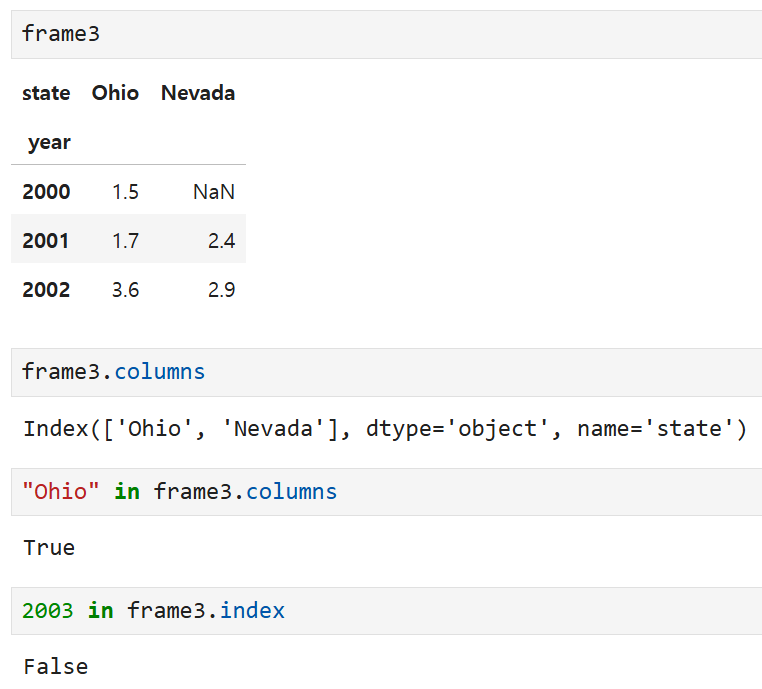
Ohio가 컬럼에 속해있냐는 물음에는 True가 뜨지만,
2003이라는 값이 인덱스에 속해있냐는 물음에는 False가 뜬다.
주어진 데이터를 벗어나는 인덱스는 정의될 수 없다. -
파이썬의 집합과는 다르게, 판다스의 인덱스는 중복을 허용한다.

여기서 foo라는 중복되는 값을 선택하면
해당 값을 인덱스로 갖는 모든 행이 선택된다.
