EDA (탐색적 데이터 분석)
위치 추정
데이터를 살펴보는 가장 기본적인 방법은
각 변수들의 대표값Typical value을 구하는 것이다.
이는 곧 대부분의 값이 어디쯤에 위치하는지를 나타내는 추정값이다. (중심경향성)
평균
-
데이터를 요약할 때 가장 흔하게 쓰이는 대표값은 평균,
그 중에서도 산술평균인데, 산술평균은 모든 값의 총합을 값의 갯수로 나눈 값이다. -
산술평균은 계산하기 쉽고 사용하기 편리하다는 장점이 있지만,
데이터를 대표하는 가장 좋은 값은 아닐 수 있다. 예를 들어,
- 산술평균은 극단값의 영향을 쉽게 받는다.
- 위와 비슷한 맥락에서, 산술평균은 전체 데이터의 분포 상태를 반영하지 못한다. -
평균을 조금 변형한 값들 중 하나로 절사평균이 있다. 절사평균은 값들을 크기 순서대로 정렬한 후, 양 끝에서 일정 갯수의 값들을 삭제한 뒤 남은 값들을 가지고 구한 평균을 말한다.
- 절사평균은 정의상 극단값의 영향을 제거한다.
- 예를 들어, 국제 다이빙 대회에서는 5명의 심판이 매긴 점수 중 가장 높은 점수와 가장 낮은 점수를 제외한 나머지 3명의 점수를 평균한 값으로 최종 성적을 매긴다.
- 혹시 한 심판이 자국 선수에게 유리한 심사를 하더라도, 절사평균을 구하는 과정에 의해 이 심판이 전체 성적에 영향을 주기 어려워진다.
-
또 다른 종류의 평균으로 지정한 가중치를 곱한 x의 총합을 가중치의 총합으로 나눈 가중평균이 있다. 가중평균을 사용하게 된 2가지 중요한 이유로는
- 어떤 값들이 다른 값들에 비해 큰 변화량을 가질 때, 이런 관측값에 더 낮은 가중치를 줄 수 있다. 예컨대 여러 개의 센서에서 가져온 데이터의 평균을 구한다고 할 때, 한 센서의 정확도가 유난히 떨어진다면 그 센서에서 나온 데이터에서는 낮은 가중치를 주는 것이 합리적이다.
- 데이터를 수집할 때 서로 다른 대조군에 대해 항상 똑같은 수의 데이터가 얻어지지는 않는다. 이를 보정하기 위해 데이터가 부족한 소수 그룹에 대해 오히려 더 높은 가중치를 적용할 필요도 있을 것이다.
중간값과 로버스트 추정
-
데이터를 일렬로 정렬했을 때 한가운데에 위치하는 값을 중간값이라고 한다. 만약 데이터의 갯수가 짝수라면, 이 때의 중간값은 가운데 있는 두 값의 평균으로 한다.
-
모든 관측치를 다 사용하는 평균과 달리 중간값은 정렬된 데이터의 가운데에 있는 값들만으로 결정된다. 얼핏 보기에 불리할 것처럼 보이지만, 많은 경우 데이터에 민감한 평균보다는 중간값이 위치 추정에 더 유리하다.
-
가중평균을 사용하는 이유와 동일하게, 중간값을 구할 때도 가중 중간값을 쓸 수 있다. 가중 중간값은 단순히 가운데 위치한 값이 아닌, 어떤 위치를 기준으로 상위 절반의 가중치의 합이 하위 절반의 가중치의 합과 동일한 위치의 값이다.
-
중간값과 마찬가지로, 가중 중간값 역시 특잇값에 로버스트하다.
-
특잇값은 어떤 데이터 집합에서 다른 값들과 매우 멀리 떨어진 값인데, 몇 가지 관습적인 정의가 있긴 하지만 정확한 정의는 다소 주관적일 수 있다. (얼마나 멀리 떨어져야 특잇값으로 볼 것인지?)
- 특잇값은 데이터의 값 자체가 유효하지 않다거나 잘못되었다는 뜻이 아니다.
- 다만 데이터에 특잇값이 섞여있을 경우 평균은 잘못된 위치 추정을 할 수 있는 위험이 있는 반면, 중간값은 여전히 설득력 있는 결과를 줄 수 있을 것이다.
-
중간값만이 유일하게 로버스트한 위치 추정 방법은 아니다. 위에서 본 절사평균 역시 특잇값의 영향을 줄이기 위해 많이 사용된다. 절사평균은 특잇값에 대해 로버스트하지만, 위치 추정을 위해 (중간값보다는) 더 많은 데이터를 사용한다는 점에서 평균과 중간값의 절충안으로도 볼 수 있다.
코드 실습
-
기본 라이브러리와 데이터를 불러온다. 미국 각 주의 인구와 살인 비율을 보여주는 state 데이터를 사용했다. 라이브러리 중 scipy, wquantiles는 각각 절사평균과 가중 중간값을 구하기 위해 불러온 것이다.
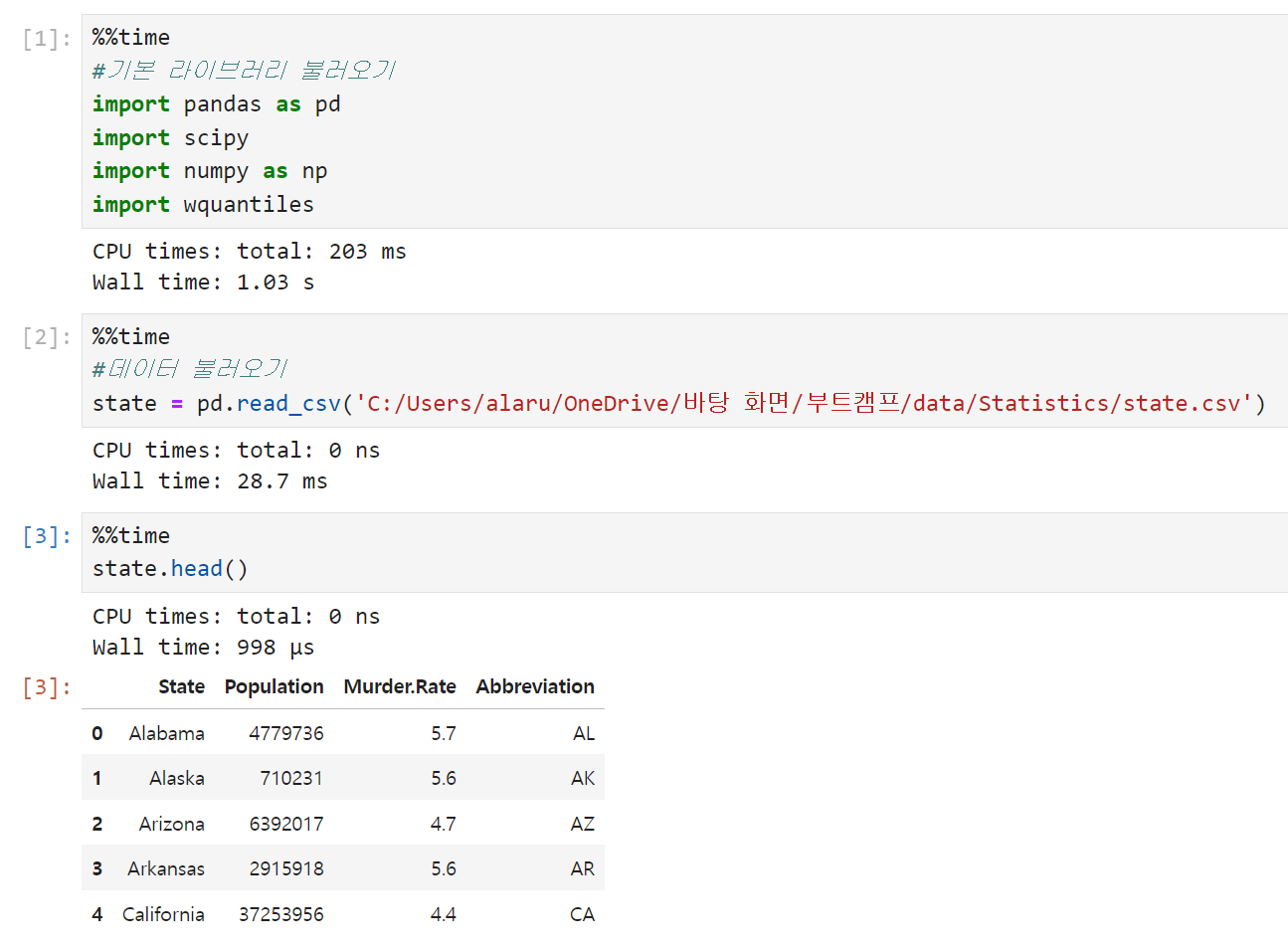
-
순서대로 산술평균, 절사평균, 중앙값을 구한 결과다. 산술평균과 중앙값을 비교했을 때 산술평균 쪽이 훨씬 큰 것으로 보아 인구(Population)에 큰 값들이 많이 포함되어 있을 거라고 추측해 볼 수 있다.
평균은 절사평균보다 크고, 절사평균은 중앙값보다 크다.
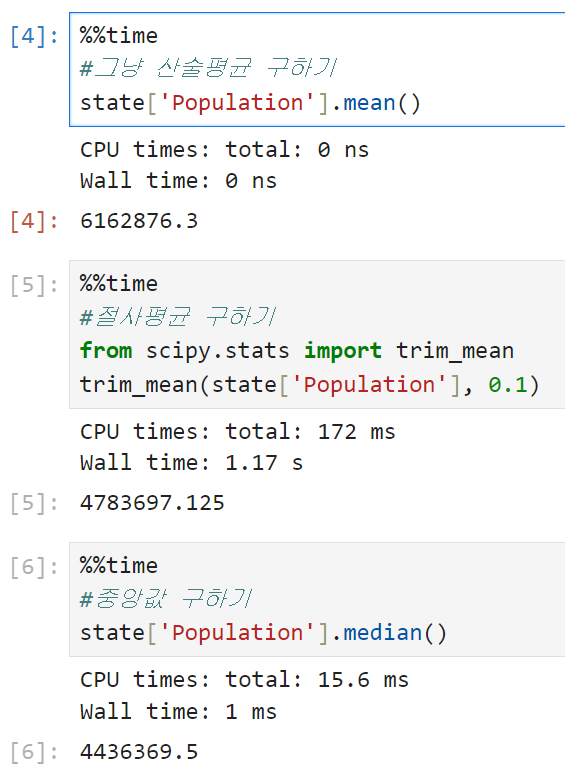
코드상에서 trim_mean은 절사평균을 나타내고, trim = 0.1의 파라미터는 위아래로 10%의 값을 제외하고 평균을 구한다는 의미다. trim 값을 0.05로 바꾸면 위아래로 5%의 값을 제외하고 계산된 평균이 나온다. -
미국 전체의 평균적인 살인율을 계산하려면 주마다 인구 수가 다른 점을 고려하기 위해 가중평균이나 가중 중간값을 사용해야 한다.
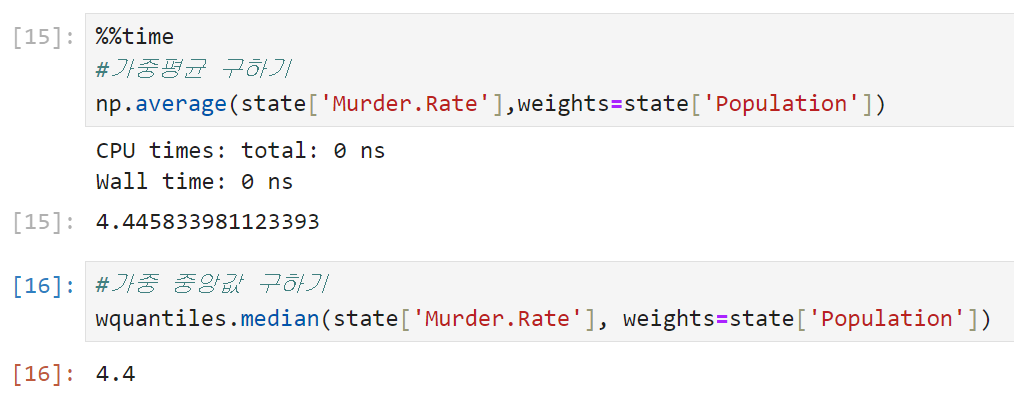
가중평균을 구하기 위해 넘파이, 가중 중간값을 구하기 위해 wquantiles를 사용한다.
이 경우에서는 가중평균과 가중 중앙값이 거의 비슷하다.
변이 추정
데이터의 특징을 요약하는 다양한 요소들 중 위치 외에 변이Variability가 있다. 변이는 데이터 값이 얼마나 밀집해 있는지, 혹은 퍼져 있는지를 나타내는 산포도Dispersion를 나타낸다.
위치를 추정하는 데 다양한 방법이 있었던 것처럼 (평균, 중앙값 등) 변이를 추정하는 데에도 다양한 방법이 있다.
편차
-
가장 대표적인 변이 추정 방법은 관측 데이터와 위치 추정값(e.g. 산술평균) 사이의 차이, 즉 편차를 이용하는 것이다.
-
변이를 측정하는 한 가지 방법은 이 편차들의 대푯값을 추정하는 것인데, 그렇다고 편차들을 단순 산술평균 내면 값이 0이 되어서 쓸 수 없게 된다.
-
따라서 편차를 활용하는 방법은 크게 2개로 나뉜다.
- (편차들을 단순 합하면 0이 되므로) 편차들의 절대값을 취해서 산술평균 낸 평균절대편차를 쓰거나
- 가장 유명한 변이 추정 방법인 분산과 표준편차를 쓰는 것
-
표준편차는 원래 데이터와 같은 스케일scale에 있기 때문에 분산보다 해석하기 훨씬 쉽다는 이점이 있다.
-
다만 분산, 표준편차, 평균절대편차 모두 특잇값과 극단값에 로버스트하지 않다는 약점이 있다. 특히 분산과 표준편차는 제곱편차를 쓰기 때문에 특잇값에 더욱 민감하다.
-
로버스트한 변이 추정값으로 중간값의 중위절대편차(MAD, Median Absolute Deviation)가 있다. 중위절대편차를 구하는 순서는 아래와 같다.
- 어떤 데이터 세트의 중앙값을 구한다.
- 각 데이터 값에서 중앙값을 뺀 후 절대값을 취한다. (이 값을 절대편차라고 부른다)
- 2에서 구한 절대편차들의 중앙값을 구한다.
백분위수
-
변이를 추정하는 또다른 방법은 정렬된 데이터가 얼마나 퍼져있는지를 보는 것인데, 가장 기본이 되는 측도는 가장 큰 값과 가장 작은 값의 차이를 나타내는 범위range다. 그러나 범위는 특잇값에 매우 민감하며 데이터의 변이를 측정하는 데 그렇게까지 유용하지 않다.
-
특잇값에 민감한 것을 피하기 위해 예컨대 범위의 양 끝에서 값들을 지운 후 범위를 다시 알아볼 수 있다. (마치 절사평균처럼) 좀 더 구체적으로 백분위수 사이의 차이를 가지고도 이런 추정을 해 볼 수 있다.
-
어떤 데이터에서 P번째 백분위수는 P퍼센트의 값이 그 값 혹은 그보다 작은 값을 갖고, (100-P)퍼센트의 값이 그 값 혹은 그보다 큰 값을 갖는 어떤 값을 의미한다. 쉽게 말해 25분위수라고 하면 하위25%의 값이 25분위수 밑에 깔리는 것이고, 75분위수는 그 밑으로 75%의 데이터가 깔리는 것이라고 이해하면 된다.
-
변이를 측정하는 가장 대표적인 방법은 사분위범위(IQR)라고 불리는, 25번째 백분위수와 75번째 백분위수의 차이를 보는 것이다. 박스플롯을 그렸을 때 박스의 아래쪽 경계가 Q1(25백분위수), 위쪽 경계가 Q3(75백분위수)다.
- 참고로 박스플롯에서 수염은 Q1-(1.5×IQR)과 Q3+(1.5×IQR)까지 그려진다.
- 이 수염들 바깥으로 나가는 값들이 일반적으로 이상치로 간주된다.
-
데이터 집합이 매우 클 경우 정확한 백분위수를 계산하기 위해 모든 값들을 오름차순으로 정렬하는 것은 많은 양의 연산을 필요로 한다. 이런 이유 때문에 다양한 머신러닝과 통계 소프트웨어들에서는 백분위수의 근삿값을 사용하는데, 이 근사 방법은 계산이 매우 빠르고 어느 정도 정확도가 보장되어 있어서 그냥 사용해도 무방하다.
- 참고로 numpy의 quantile은 선형보간법이라는 방법을 지원한다. 선형보간법이 뭔지는 나중에 따로 정리해 보기로.
코드 실습
-
위치 추정 실습 때 썼던 라이브러리와 데이터를 불러온다. 미국 각 주의 인구와 살인 비율을 보여주는 state 데이터다.
-
주별 인구의 표준편차를 구해 본다. 편차 4번 항목에 정리한 대로 표준편차는 원래 데이터와 같은 scale에 있어 해석이 편하다.
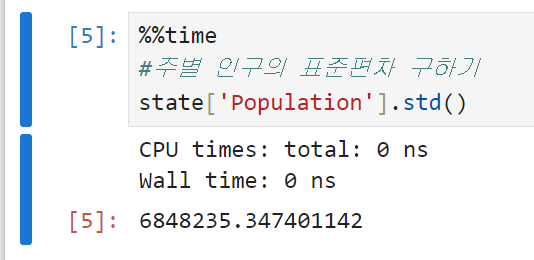
-
주별 인구의 IQR을 구해 본다.

-
주별 인구의 MAD, 즉 중위절대편차를 구해 본다. robust.scale.mad 함수를 쓰기 위해서는 Statsmodel이라는 라이브러리를 설치하고 불러와야 한다. 앞으로는 sm으로 통일해서 사용할 예정.
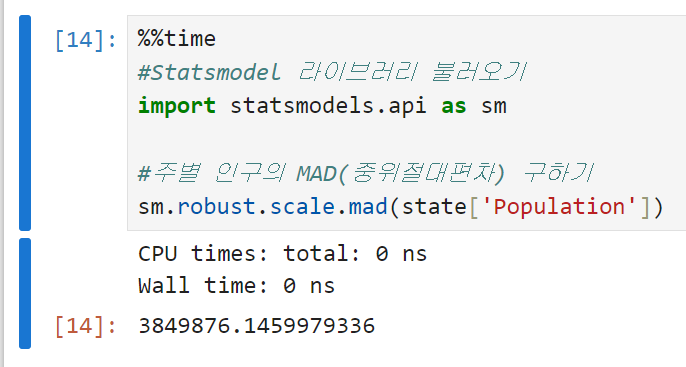
표준편차(6,848,235)가 MAD(3,849,876)의 거의 두 배에 가까울 정도로 크다.
표준편차는 산출과정에서 제곱편차를 쓰는 관계로
특잇값에 취약하기 때문에 딱히 놀라운 결과는 아니다.
세 줄 요약
- 분산과 표준편차는 가장 보편적으로 널리 사용되는 변이 측정 방법이다
- 이 두 수치 모두 특잇값에 민감하다. (즉, 로버스트하지 않다)
- 중간값과 백분위수(분위수)로부터 평균절대편차나 중간값의 중위절대편차(MAD)를 구하는 것이 좀 더 로버스트하다.
백분위수, 상자그림(Box plot)
-
데이터의 전체 분포를 알아보는 데에도 백분위수는 유용하다. 주로 사분위수Quantile나 십분위수Decile이 공식적으로 사용되는데, 이 중에서도 사분위수는 꼬리 부분, 즉 외측 범위를 묘사하는 데 유용하다.
-
주별 살인율의 백분위수를 각각 구해보면, 5% 백분위수는 1.6% 정도인 데 비해 95% 백분위수는 6.5%에 달한다. 중간값을 보면 10만명 당 4건 꼴로 살인이 발생하는 것을 알 수 있다.
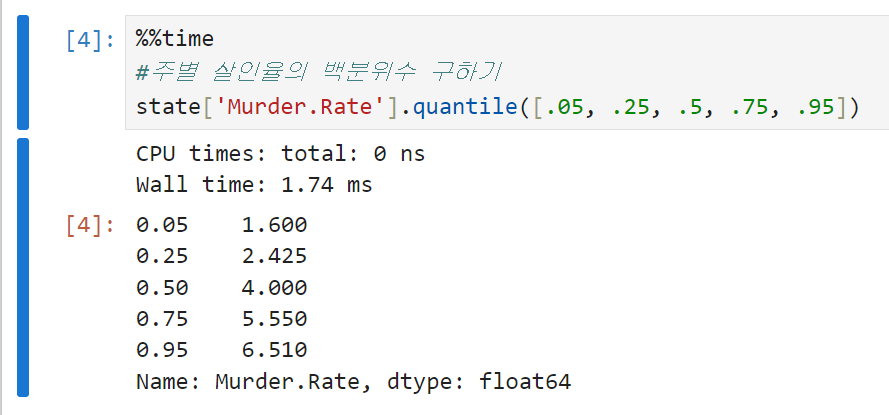
-
이 백분위수를 시각적으로 표현해 데이터의 분산도를 손쉽게 파악할 수 있게 만든 것이 투키에 의해 처음 소개된 상자그림(Box plot)이다. 실제로 의사소통을 할 때는 주로 박스플롯이라고 얘기했던 듯. 박스플롯으로 주별 인구를 나타낸 결과는 아래와 같다.
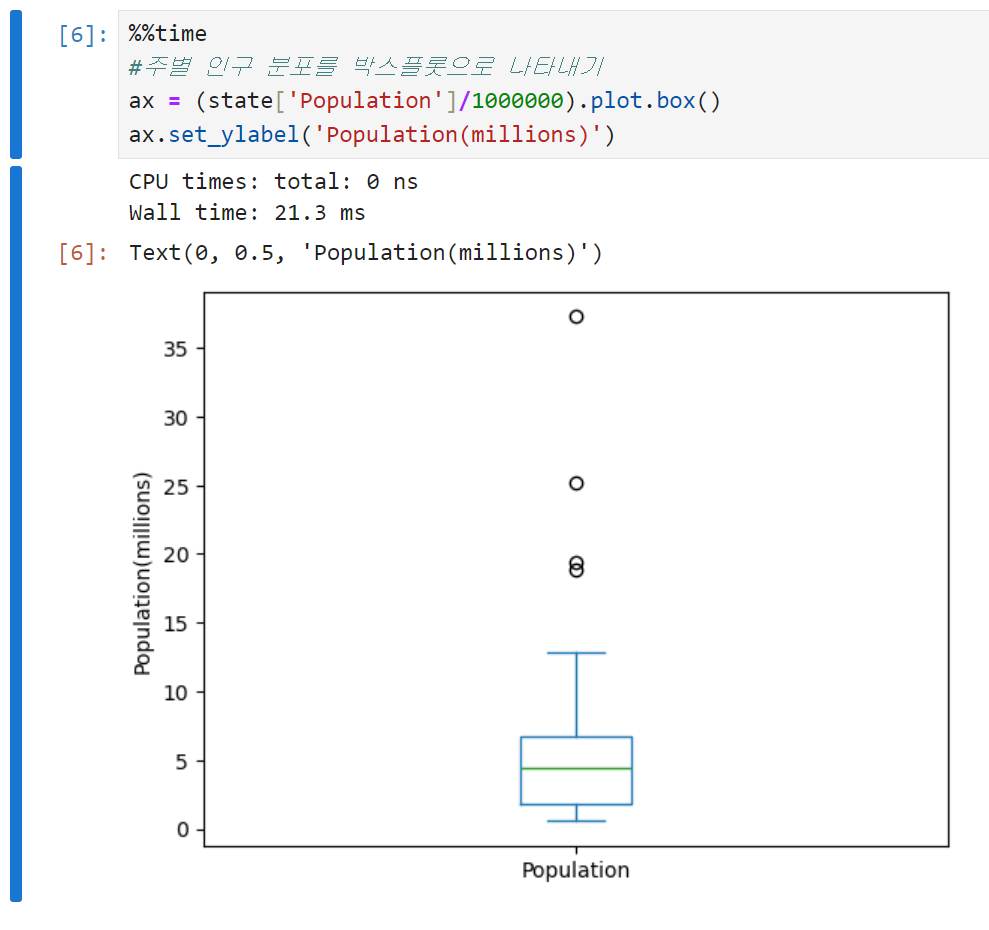
-
박스플롯 읽는 법은 크게 아래와 같다.
-
중간값은 상자 안의 초록색 수평선으로 표시된다. 주별 인구의 중간값이 약 500만 정도 된다는 걸 바로 알 수 있다.
-
상자의 위쪽과 아래쪽 경계는 각각 75%백분위수, 25%백분위수를 의미한다. 박스 경계가 걸쳐져 있는 범위를 보면 75%와 25% 백분위수의 차이, 즉 주 절반 정도가 200만에서 700만 정도에 분포한다는 것을 알 수 있다.
-
위아래로 뻗어있는 수염Whisker은 각각 Q1-1.5×IQR, Q3+1.5×IQR까지다. IQR의 150% 범위까지는 허용하되, 그 범위를 넘어가는 값은 이상치(특잇값)로 간주된다. 이상치는 하나의 점 또는 원으로 표시된다.
-
도수분포표, 히스토그램
-
도수분포표는 변수의 범위를 동일한 크기의 구간으로 나눈 다음, 각 구간마다 몇 개의 변숫값이 존재하는지를 나타내기 위해 사용한다. 판다스에서 cut 함수를 쓰면 각 구간에 매핑하는 시리즈를 만들 수 있다. (이 때 sort_index()를 써서 출력 순서를 제어하지 않으면 빈도수를 기준으로 내림차순 정렬되기 때문에 구간이 꼬이게 됨)
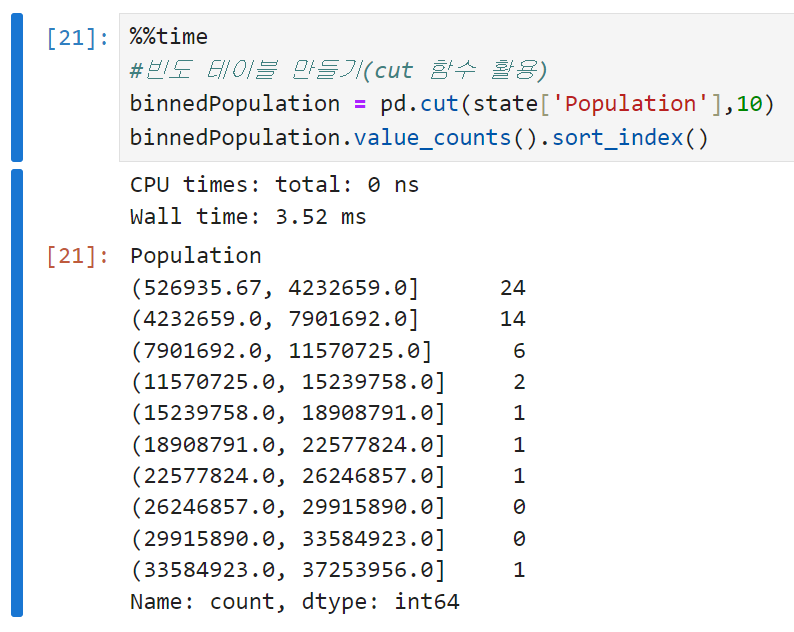
-
도수분포표와 백분위수 모두 구간을 나눠서 데이터를 살펴보는 접근법이다. 다만,
- 백분위수(사분위수, 십분위수)는 각 구간에 같은 수의 데이터가 포함되도록, 즉 구간의 크기를 다르게 나누는 방법이고
- 도수분포표는 구간의 크기가 같도록, 즉 구간 안에 다른 갯수의 데이터가 들어오게 하는 방법이라는 차이가 있다.
-
위에서 만든 도수분포표를 시각화하면 히스토그램이 된다. x축에는 구간 정보만 표시하고 y축에는 해당 구간별 데이터의 갯수를 표시한다.
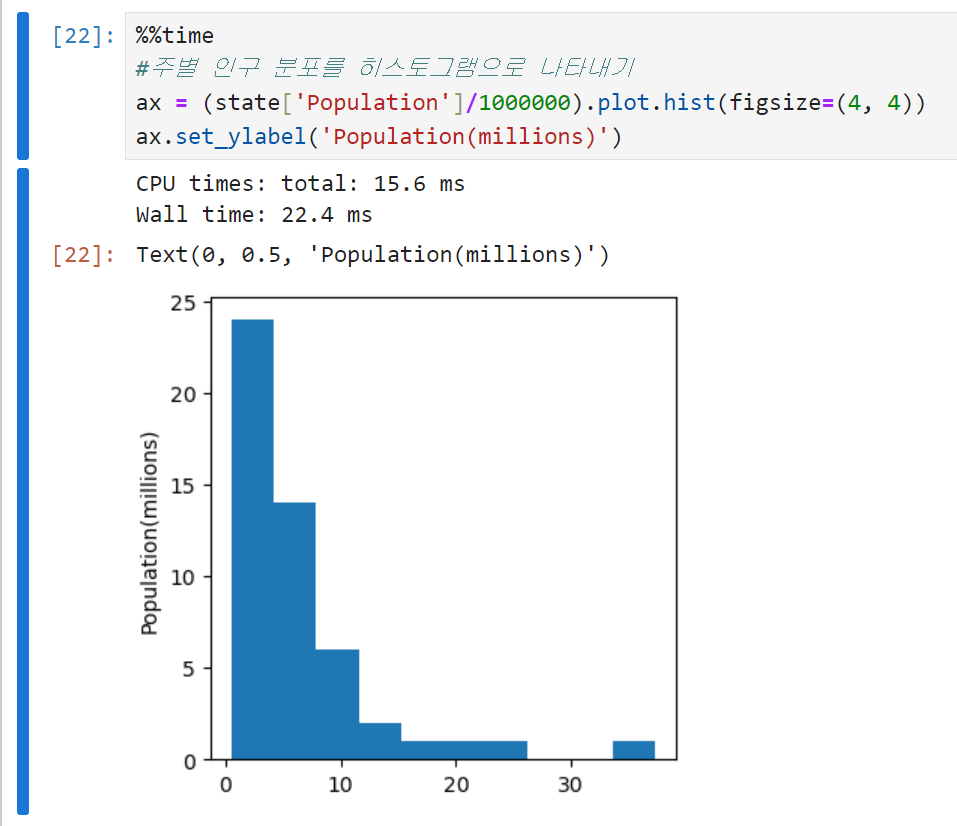
-
보통 히스토그램에는 아래의 정보가 담겨 있다.
- 그래프에 빈 구간들이 있을 수 있다. (구간의 크기를 조금씩 바꿔보는 것도 방법임. bins 인수로 조절할 수 있음)
- 각 구간은 동일한 크기를 갖는다.
- 구간의 수(크기)는 사용자가 결정할 수 있다.
- 빈 구간이 있지 않은 이상, 각 막대는 공간 없이 서로 붙어있다.
밀도 그림과 추정
-
밀도 그림은 데이터의 분포를 연속된 선으로 보여준다. 좀 더 부드러운 버전의 히스토그램이라고 생각하면 될 듯. 밀도는 커널밀도추정을 통해 데이터로부터 직접 계산한다.
-
판다스에서는 밀도 그림을 생성하기 위해 density 메서드를 제공한다. 아래는 코드와 출력 결과 예시.
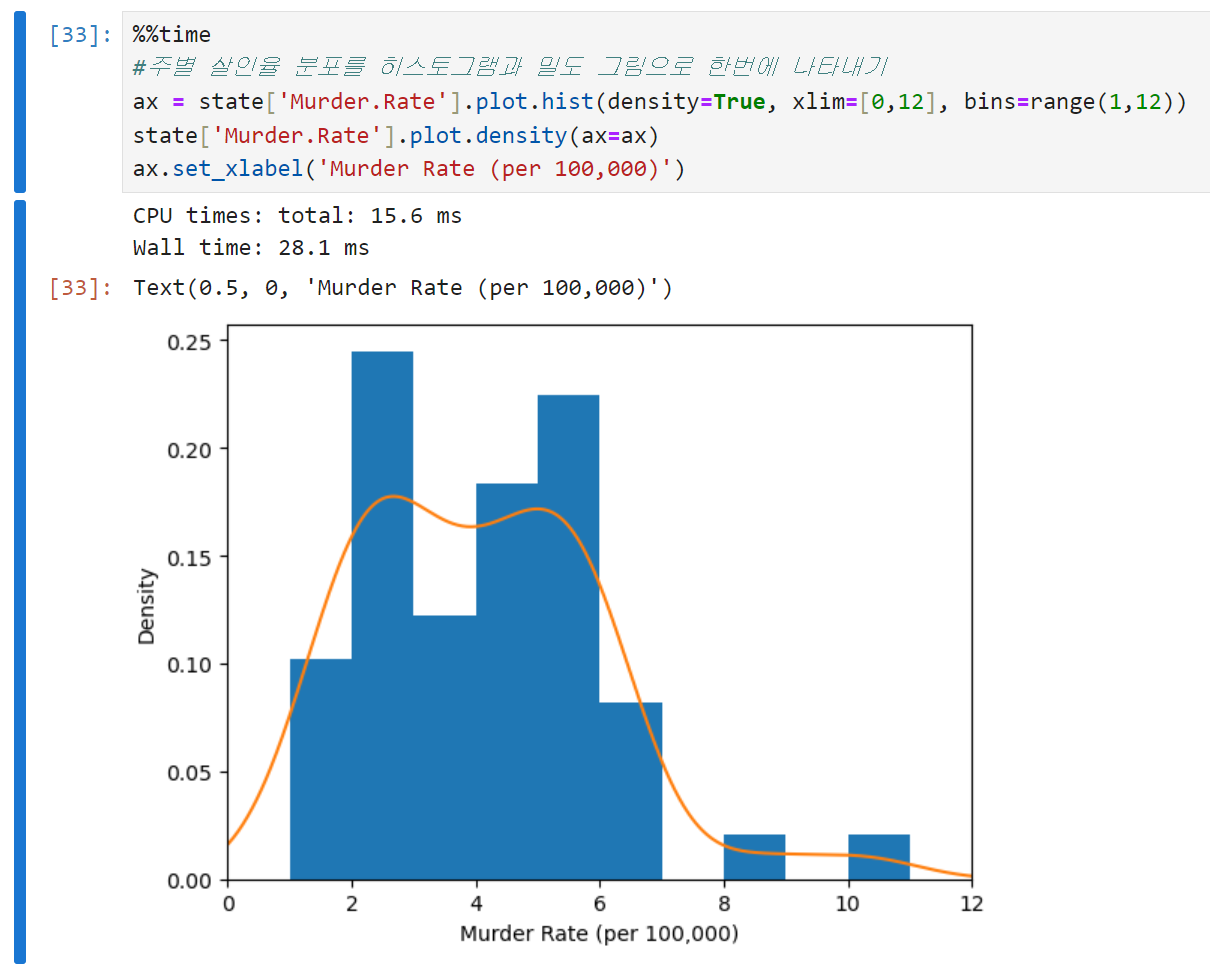
-
각 코드의 의미는 아래와 같다.
- density = True
밀도 그림을 그리기 위해 설정한 인수. 히스토그램을 정규화한다고 보면 된다. 여기서 density를 False로 바꾸면 밀도 그림을 그리지 못한다. 히스토그램의 y축 단위가 바뀐다는 점에도 유의. - xlim = [0,12]
x축의 범위를 0에서 12까지로 제한한다는 의미. 꼭 얼마로 해야 한다는 정답은 없지만, 데이터의 분포를 가장 잘 표현할 수 있는 값을 찾아주는 것이 바람직. - bins = range(1,12)
히스토그램의 구간(bin)을 1에서 11까지 정수로 지정한다. 만약 저 인수를 range(1,5)로 바꾸면 5를 넘어가는 구간에서는 출력되지 않는다. - density(ax=ax)
density plot을 히스토그램(ax)과 겹치기 위해 설정한 인수. 같은 그래프에 밀도 그림을 추가하기 위해 설정해 주었다.
- density = True
-
위에서 그렸던 히스토그램과의 가장 큰 차이는 y축의 스케일. 밀도 그림에서는 갯수가 아닌 비율을 나타낸다. (density=True) 밀도 곡선 아래의 총 면적은 1이고, 구간의 갯수 대신 x축의 두 점 사이의 곡선 아래 면적을 계산한다.
세 줄 요약
- 도수 히스토그램은 y축에 횟수를, x축에 변숫값들을 표시하고 한 눈에 데이터의 분포를 볼 수 있게 만든 것이다. 이 히스토그램에 보이는 횟수들을 표 형태로 나타내면 도수분포표가 된다.
- 박스플롯에서 상자의 위와 아래 경계는 각각 75%, 25% 백분위수를 의미하며, 이 역시 데이터의 분포를 한눈에 파악할 수 있게 한다.
- 밀도 그림은 히스토그램의 부드러운 버전이라고 할 수 있다. 데이터로부터 이 차트를 얻기 위해서는 어떤 함수를 구해야 하는데, 가능한 추정 방법은 여러 가지가 있다.
이진 데이터와 범주 데이터
-
이진변수나 변수가 몇 개 안 되는 범주형 변수를 분석하는 것은 그렇게 어렵지 않다. 중요한 범주의 비율이 어느 정도 되는지 알아보면 되기 때문.
-
막대도표(보통 '바 차트'라고 많이들 부른다)는 가장 흔한 시각화 방법으로, x축에 각 범주들을 놓고 y축에 이에 대응하는 횟수나 비율을 표시한다. 아래는 코드 예시. (데이터 불러오기까지의 과정은 생략)
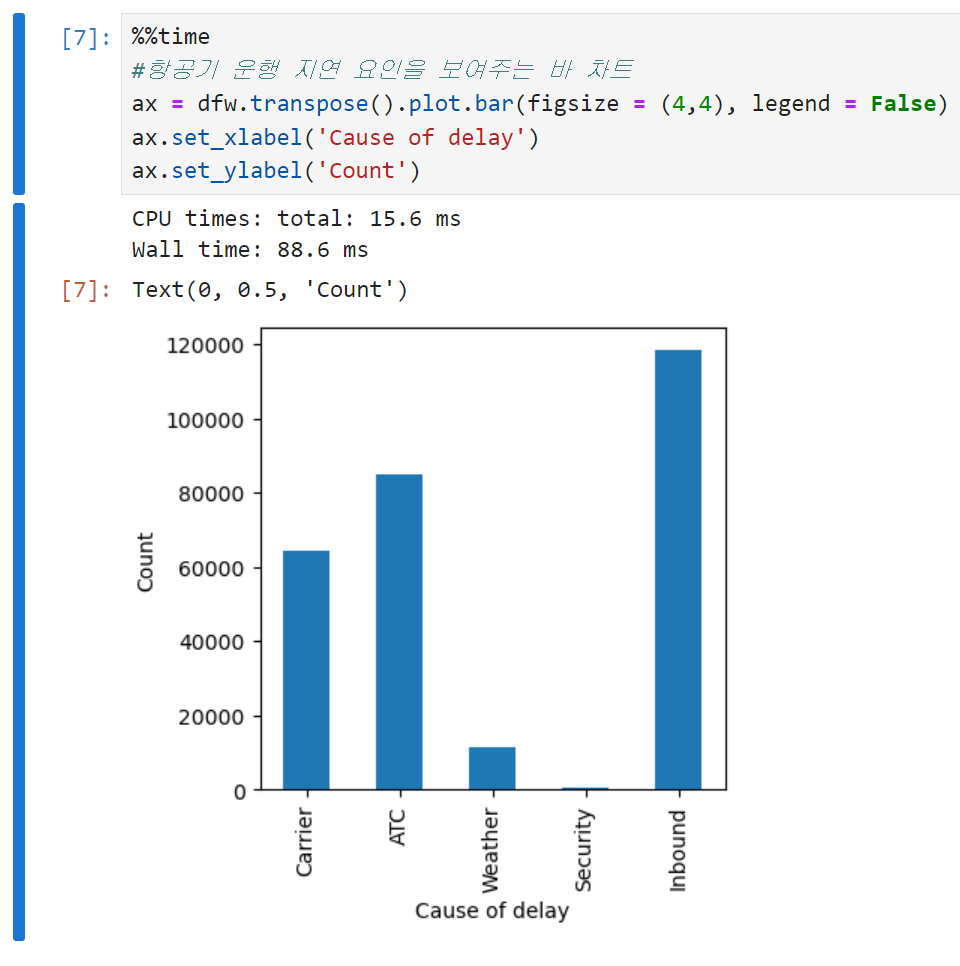
-
바 차트는 히스토그램과 매우 유사하긴 하지만, 히스토그램은 x축에 수치적으로 나타낼 수 있는 하나의 변수의 값이 오는 반면 바 차트의 x축은 각 요인변수factored variables의 서로 다른 범주들을 나타낸다. 히스토그램의 막대들이 붙어 있고 중간에 틈이 있으면 그 부분에 해당하는 값들이 존재하지 않는다는 것을 의미하는 것에 반해, 바 차트에서 각 막대들은 서로 떨어져 있다.
-
바 차트 대신 파이 차트를 사용하기도 하지만, 통계학자나 데이터 시각화 전문가들은 파이 차트가 시각적으로 효과적이지 않다는 이유로 잘 사용하지 않는다고 한다. 이건 아직 내가 감당할 수 있는 이야기는 아니어서 그런갑다 하고 넘기기로.
- 다만 아래 이미지를 보면 왜 이런 이야기가 나왔는지 대충 짐작은 된다.
파이차트"만" 보고 파란색이 연두색보다 큰 경우가 정확히 어디인지 짚을 수 있을지?
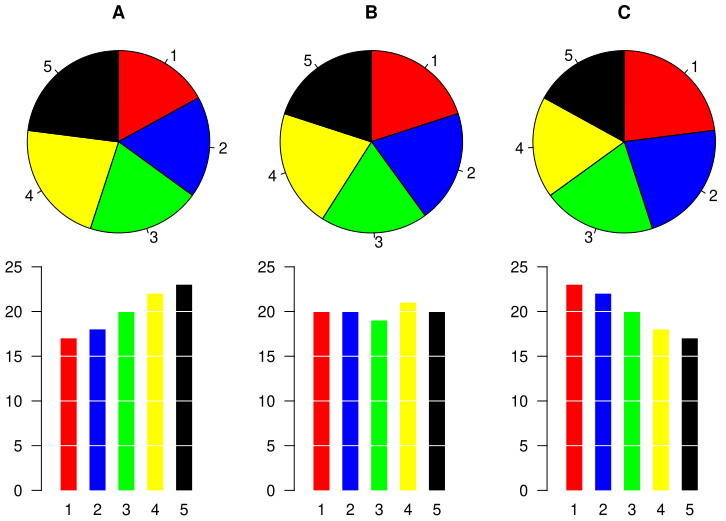
- 다만 아래 이미지를 보면 왜 이런 이야기가 나왔는지 대충 짐작은 된다.
최빈값
- 최빈값이란 데이터에서 가장 자주 등장하는 값, 혹은 값들을 말한다. 범주형 데이터를 분석하는 데 간단히 사용되지만, 수치 데이터에는 잘 사용되지 않는다.
기댓값
- 기댓값이란 확률변수가 가질 수 있는 각 값에 그 값이 나타날 확률을 가중치로 곱하여 모두 더한 값으로, 말하자면 가중치로 확률을 쓰는 가중평균이다. 예를 들어 동전 하나를 던져서 앞면이 나오면 1만원을 얻고 뒷면이 나오면 5천원을 잃는 게임이 있다고 했을 때, 이 게임에 참여함으로써 얻을 수 있는 수익의 기댓값은 (1/2×10,000) + (1/2×-5,000) = 2,500이다.
확률
- 어떤 사건이 발생할 확률이란, 상황이 수없이 반복될 경우 사건이 발생할 비율을 의미한다. 여기서의 핵심은 '수없이 반복될 경우'.
참고 : 오해를 일으킬 수 있는 그래프
상관관계
-
모델링 프로젝트에서 EDA라고 하면 예측값들 간의, 혹은 예측값과 목푯값의 상관관계를 조사하는 것을 빼놓을 수 없다. 일반적으로 상관관계의 측정량으로는 상관계수(a.k.a 피어슨 상관계수)라는 표준화된 방식이 많이 쓰인다. 상관계수는 변수 1과 2의 각각의 평균으로부터 편차들을 서로 곱한 값들의 평균을 각 변수의 표준편차의 곱으로 나눠서 구할 수 있다.
-
다만 변수들이 선형적인 관계를 갖지 않을 경우에는 상관관계가 더 이상 유용한 측정 지표가 아니다.
-
상관관계를 나타내는 상관행렬을 이용해 여러 가지 변수들 사이의 관계를 시각화하는 데 사용할 수 있다. 상관행렬은 행렬의 대각원소가 모두 1이라는 것(자기 자신과 상관계수는 1), 그리고 대각원소의 위아래로 대칭이라는 특징을 갖는다. 아래는 통신사 주식 수익 사이의 상관관계를 보여주는 상관행렬의 예시.
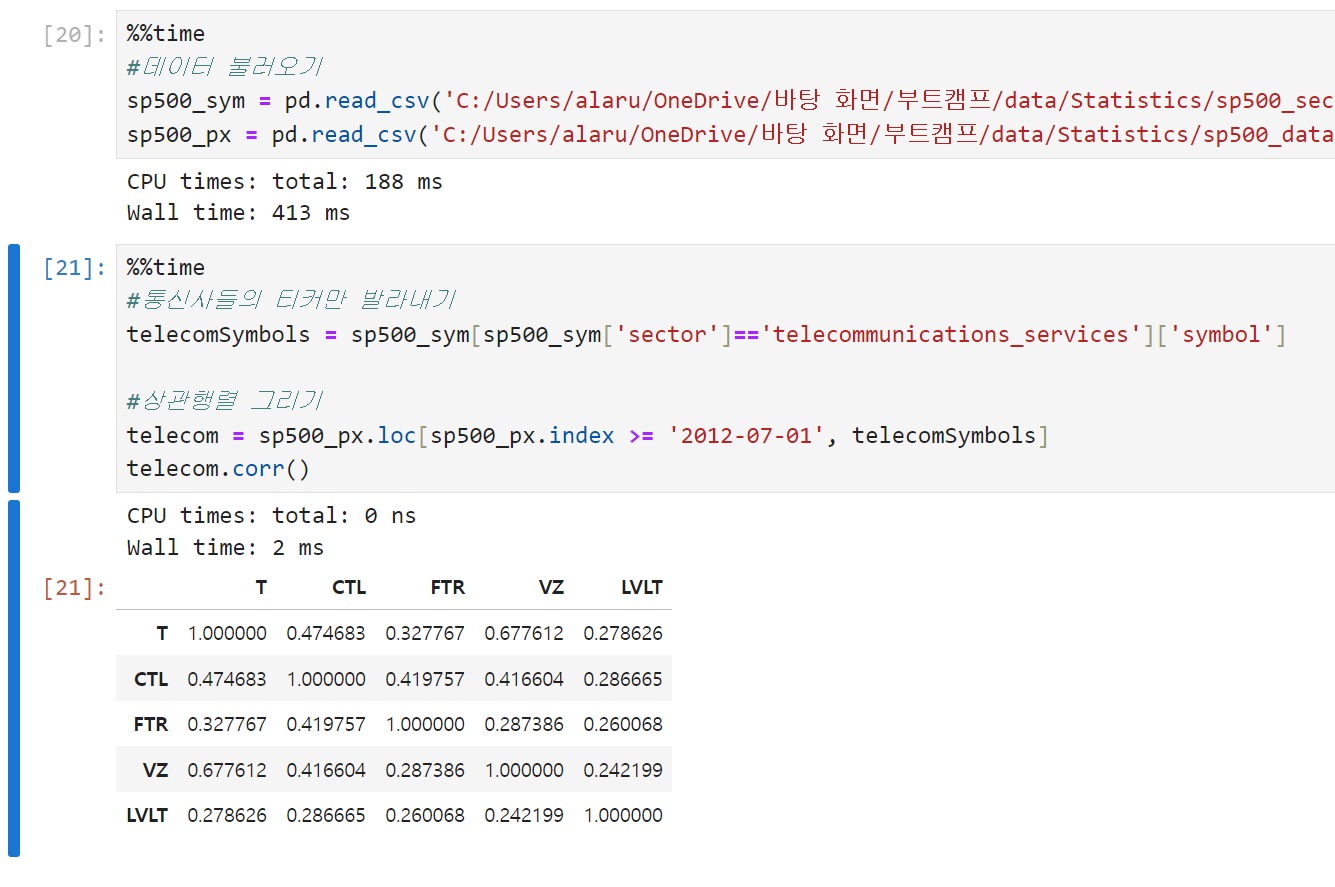
-
상관계수 자체를 시각화해서 볼 수도 있다. 아래는 seaborn의 heatmap을 이용해 시각화한 예시.
- seaborn의 히트맵을 쓰고 싶으면 sns.heatmap을 쓰면 된다.
- 코드 위쪽에서 구했던 etfs의 각 컬럼끼리의 상관계수, 즉 etfs.corr()이 히트맵을 그릴 대상이 된다.
- vmin = -1, vmax = 1은 히트맵의 색상 범위를 -1에서 1 사이로 지정하겠다는 뜻이다.
- cmap은 히트맵의 색상 팔레트를 정하는 인자인데, 여기서는 seaborn의 diverging_palette를 사용해 양의 상관관계와 음의 상관관계를 다른 색으로 구분하였다. 숫자 20은 한 쪽 끝 색상의 색조(hue)값이고, 빨간 계통의 색이다. 여기서는 -1쪽으로 갈수록 빨간색으로 표시된다. 숫자 220은 반대쪽 끝 색상의 색조(hue)값이고, 파란 계통의 색이다. 여기서는 1 쪽으로 갈수록 파란색으로 표시된다.
- as_cmap = True라는 것은 팔레트를 Matplotlib과 호환되는 색으로 바꾸겠다는 의미다. 이 값을 False로 바꾸면 색이 뭉개지면서 몇몇 색이 합쳐지고, 구분이 어려워지게 된다.
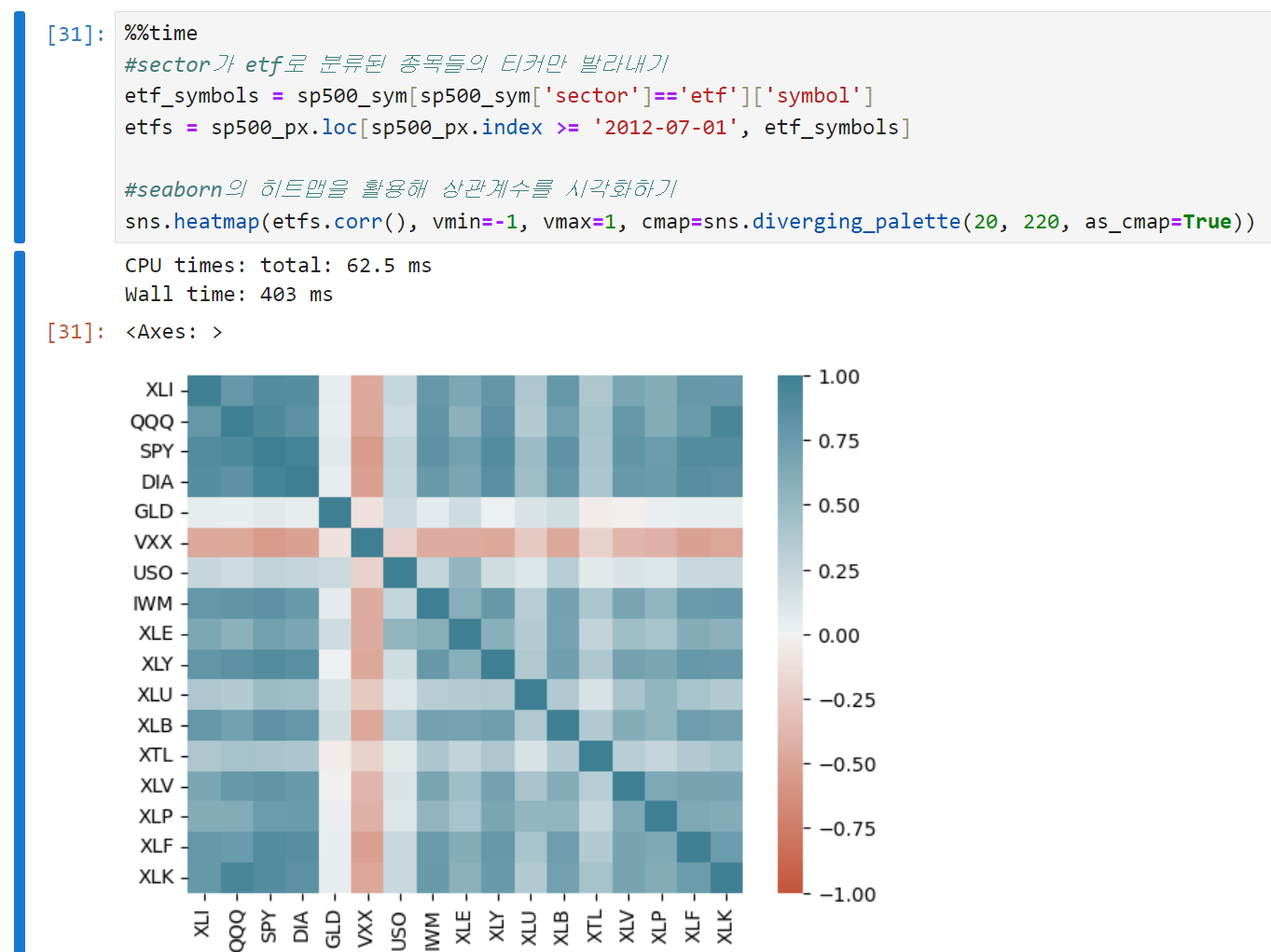
-
평균이나 표준편차와 마찬가지로, 상관계수는 데이터의 특잇값에 민감하다. 클래식한 상관계수(피어슨)를 대체할 수 있는 다른 형태의 상관계수가 있긴 하지만, EDA에는 주로 피어슨 상관계수나 혹은 이것의 로버스트한 다른 버전들이 사용된다. 아예 소프트웨어 패키지에서 로버스트한 방법들을 제공하기도 하는데, 사이킷런의 모듈 sklearn.covariance에 있는 메서드들이 그 예시다.
공분산을 또 보게 되다니 -
시각화 자체에 조금 더 많은 정보를 담을 수도 있다. 아래는 ETF 수익 간의 상관관계를 나타낸 차트인데, 타원의 색깔과 방향, 그리고 너비로 상관관계의 강도를 표현한다. 선이 얇고 진할수록 더 강한 관계성을 나타낸다. (코드는 너무 길어서 생략) 예를 들어, S$P500(SPY)과 다우존스 지수(DIA)는 상당히 강한 양의 상관관계를 갖는다. (파란색 + 우상향 + 얇음)
반대로, 금(GLD)이나 유가(USO) 등과 관련된 안정적인 ETF들은 주식 중심의 다른 ETF들과 약한, 혹은 음의 상관관계를 보인다. (빨간색 + 좌상향 + 두꺼움)
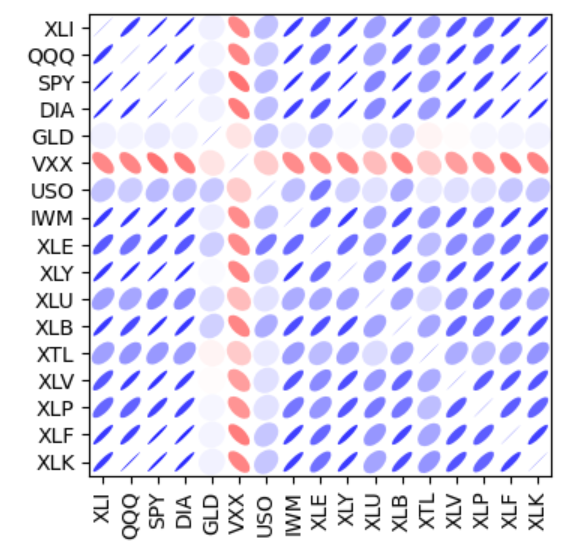
산점도(Scatter Plot)
-
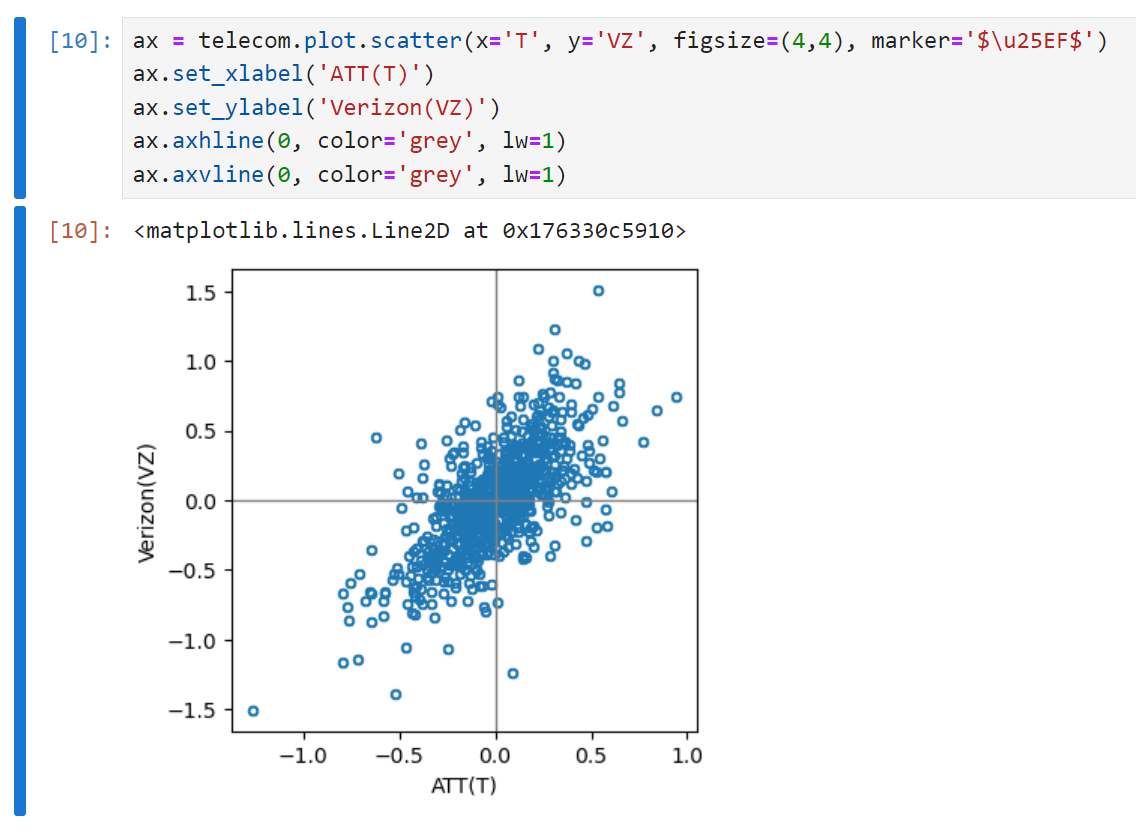
두 변수 사이의 관계를 시각화하는 가장 기본적인 방법은 산점도를 그려보는 것이다. 아래는 AT&T와 버라이즌의 일간 수익 사이의 상관관계를 산점도로 그린 예시다.
-
marker = '\u25EF' : 각 데이터 포인트를 원형 기호로 나타내겠다는 표시로, \u25EF는 유니코드 원 기호를 의미한다.
-
axhline : ax(축)의 h(수평) line(선)을 긋겠다는 의미. 값을 0이 아니라 다른 값으로 바꾸면 수평선이 올라간다. 색상은 회색, lw는 line weight, 선의 굵기를 의미한다.
-
axvline : 축의 수직선을 긋겠다는 의미. 나머지는 위와 동일하다.
-
-
산점도를 보면 두 수익은 0 주변에 모여있긴 하지만 강한 양의 상관성을 보임을 알 수 있다. 두 주식은 거의 매일 함께 오르거나, 함께 떨어지는 모습을 보인다. 한 주식이 올라갈 때 한 주식은 떨어지는 경우(2, 4사분면)는 상대적으로 드물다.
두 개 이상의 변수 탐색 (다변량분석)
- 평균이나 분산처럼 익숙한 추정값들은 한 번에 하나의 변수를 다룬다. (일변량분석)
상관분석은 한 번에 두 변수를 비교할 때 중요한 방법이다. (이변량분석)
셋 이상의 변수를 다룰 때는 조금 더 복잡한 분석 방법을 사용한다. (다변량분석)
육각형 구간, 등고선
-
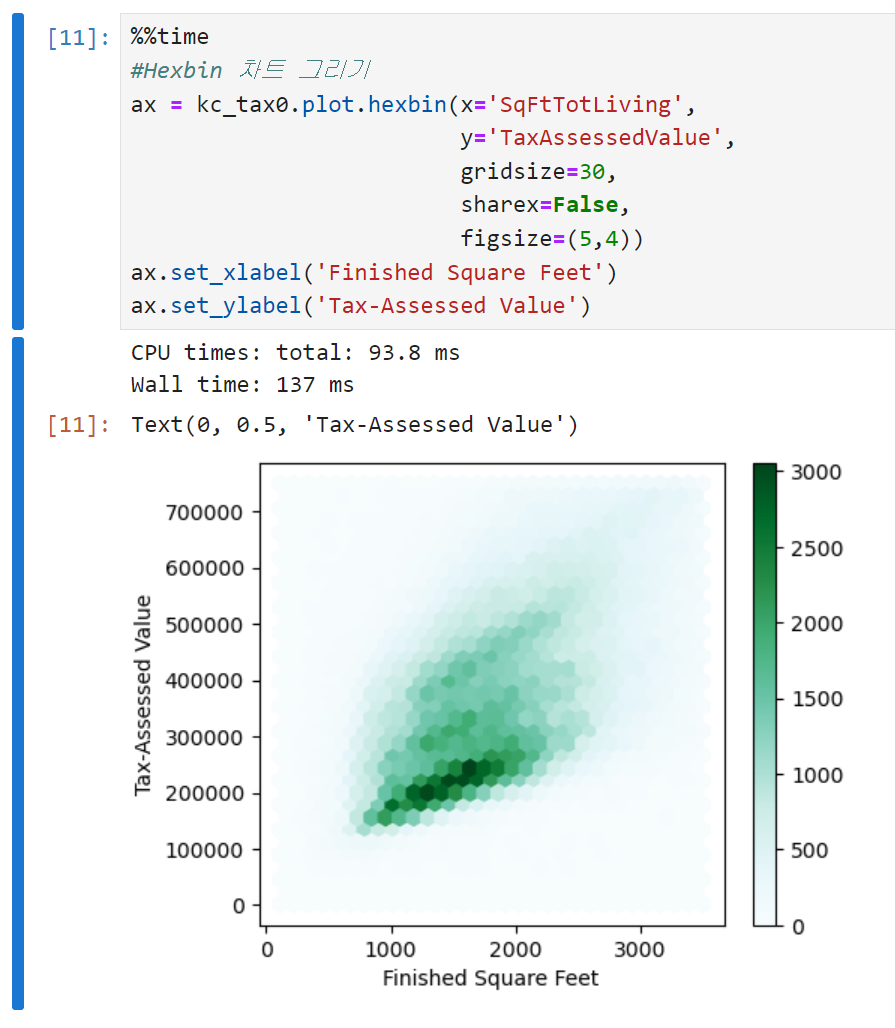
산점도는 데이터의 갯수가 상대적으로 적을 때는 유용한 방법이지만, 수십만, 혹은 수백만의 레코드를 나타내려면 점들이 너무 밀집되어 있어 알아보기 어려운 단점이 있다. 따라서 이런 상황에서는 다른 형태의 시각화 방법을 사용해야 하는데, 육각형 구간 그림이 그 방법 중 하나다.
-
아래는 워싱턴 주 킹 카운티의 주택 시설에 대한 과세 평가 금액 정보를 담고 있는 데이터다. 데이터의 주요 부분에 집중하기 위해 아주 비싸거나 너무 작은, 혹은 너무 큰 주택들은 데이터프레임에서 제거한다.
-
육각형 구간 그림을 그리는 코드는 아래와 같다.
- gridsize : 육각형의 크기를 결정하는 인수
- sharex=False : 두 개의 변수가 x축을 공유할지를 묻는 인자다. 이 경우는 y축에 들어갈 값이 세금평가가치밖에 없으므로 False로 설정하는 것이 큰 의미는 없는데, 만약 저걸 True로 설정하고 서브플롯이 들어가면 두 개의 서로 다른 y에 대해 x축을 공유하게 된다.
-
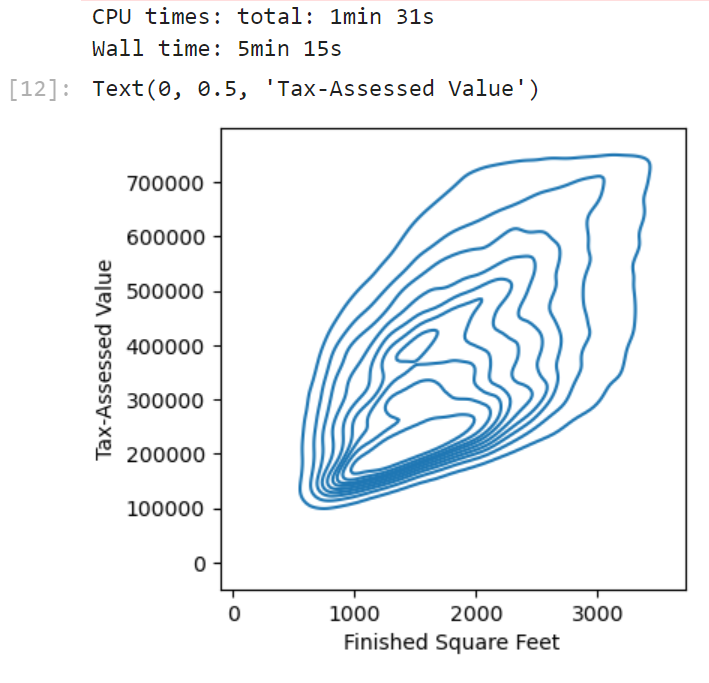
산점도 위에 등고선을 표시하는 방법도 있다. 등고선은 x축, y축의 두 변수로 이루어진 지형에서의 등고선을 말한다. 등고선 위의 점들은 밀도가 같고, 꼭대기 쪽으로 갈수록 밀도가 높아진다. 여기서도 seaborn 라이브러리의 커널밀도추정 함수를 이용했다. 문제는 코드의 실행시간이 말도 안 되게 오래 걸린다는 것. (5분 15초ㄷㄷ) 체감상 머신러닝 프로젝트 때 그리드서치 했을 때보다 오래 걸리는 듯. 함부로 그리면 안 되겠다.

범주형 변수 vs 범주형 변수
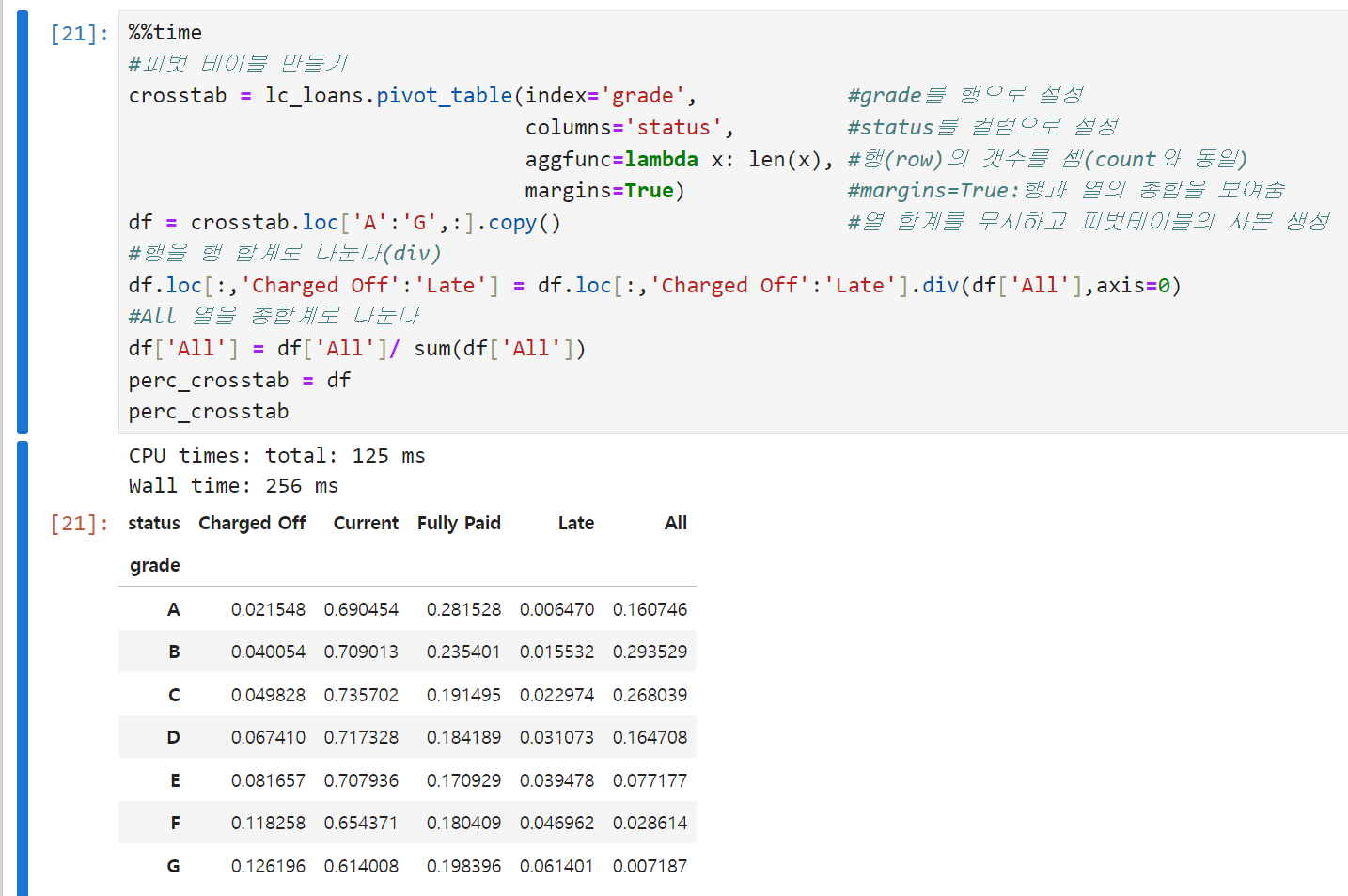
- 분할표는 두 범주형 변수를 요약하는 데 효과적인 방법으로, 범주별 빈도수를 기록한 표다. 엑셀의 피벗테이블이라고 생각하면 편하다. 아래 예시는 개인대출 등급과 대출 결과를 나타내는 분할표인데, 등급은 A(높음)부터 G(낮음)까지다. 높은 등급의 대출일수록 낮은 등급에 비해 연체late나 삭제charged off 비율이 낮다는 것을 알 수 있다. 다만 표를 '읽어야' 한다는 점에서 다른 시각화 방식보다는 불리할 수도 있을 듯.
범주형 변수 vs 수치형 변수
-
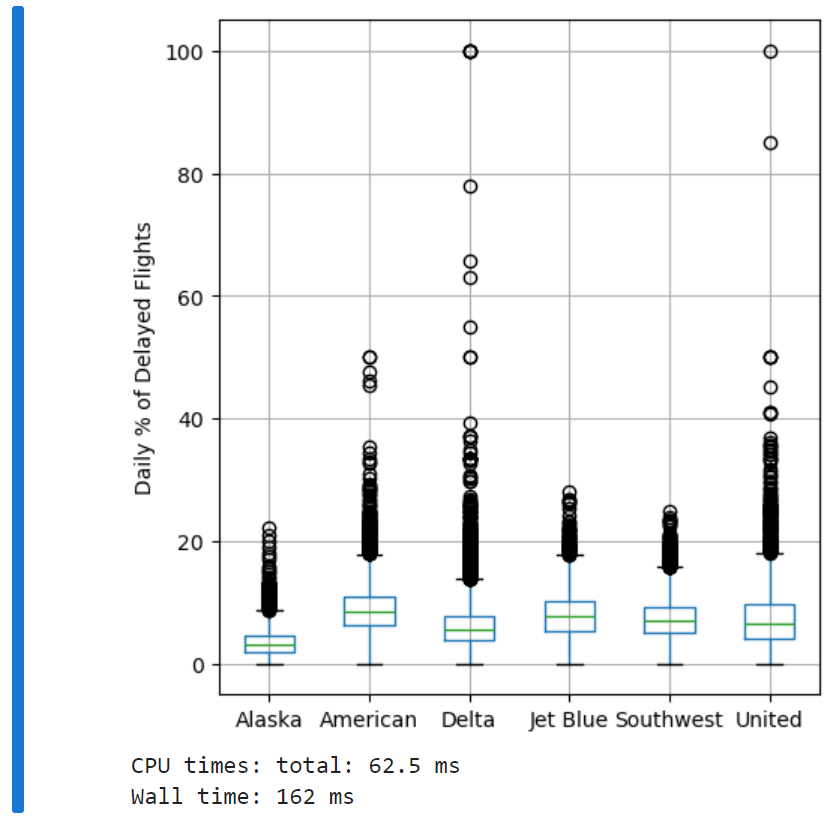
박스플롯 복습. 알래스카 항공의 지연이 가장 적었던 반면, 아메리카 항공의 지연이 가장 많았던 걸로 보인다. (박스플롯의 위아래 너비가 가장 높은 구간에 걸쳐 있음) 심지어 알래스카 항공의 상위 사분위수보다 아메리칸 항공의 하위 사분위수가 더 크다.

-
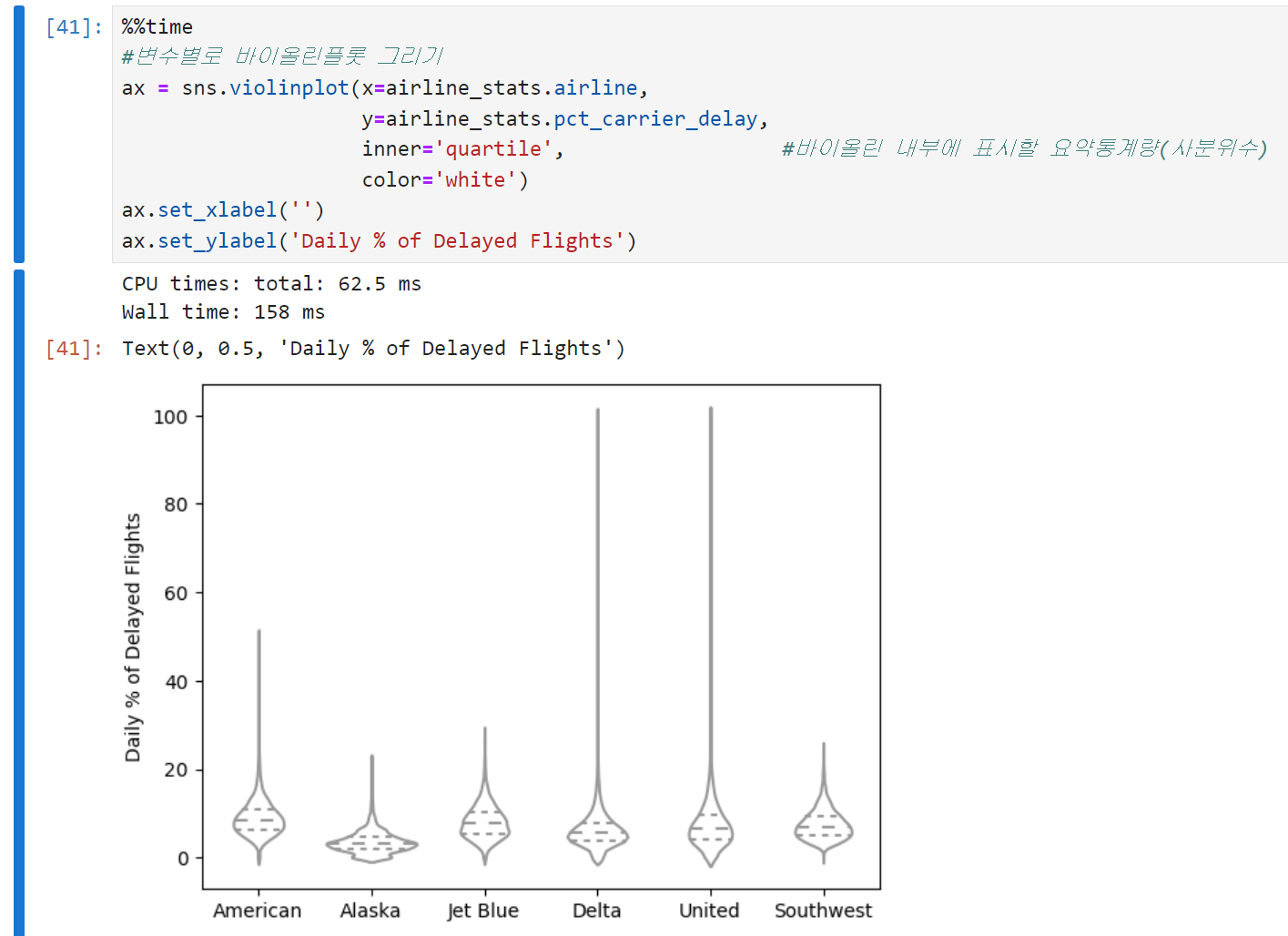
바이올린 플롯은 박스플롯을 보완한 형태로, y축을 따라 밀도추정 결과를 동시에 시각화한다. 박스플롯 상에는 드러나지 않는 데이터의 분포까지 볼 수 있다는 장점이 있는 반면, 박스플롯은 데이터의 이상치들을 좀 더 명확하게 보여준다.
- 알래스카 항공, 그리고 델타 항공이 0 근처에 데이터가 집중되어 있다.
- 바이올린 플롯도 커널밀도추정을 쓰기 때문에 데이터 밀도가 높은 구간은 곡선이 높고(즉, 가로로 볼록하고) 밀도가 낮은 구간은 곡선이 낮다.
다변수 시각화하기
-
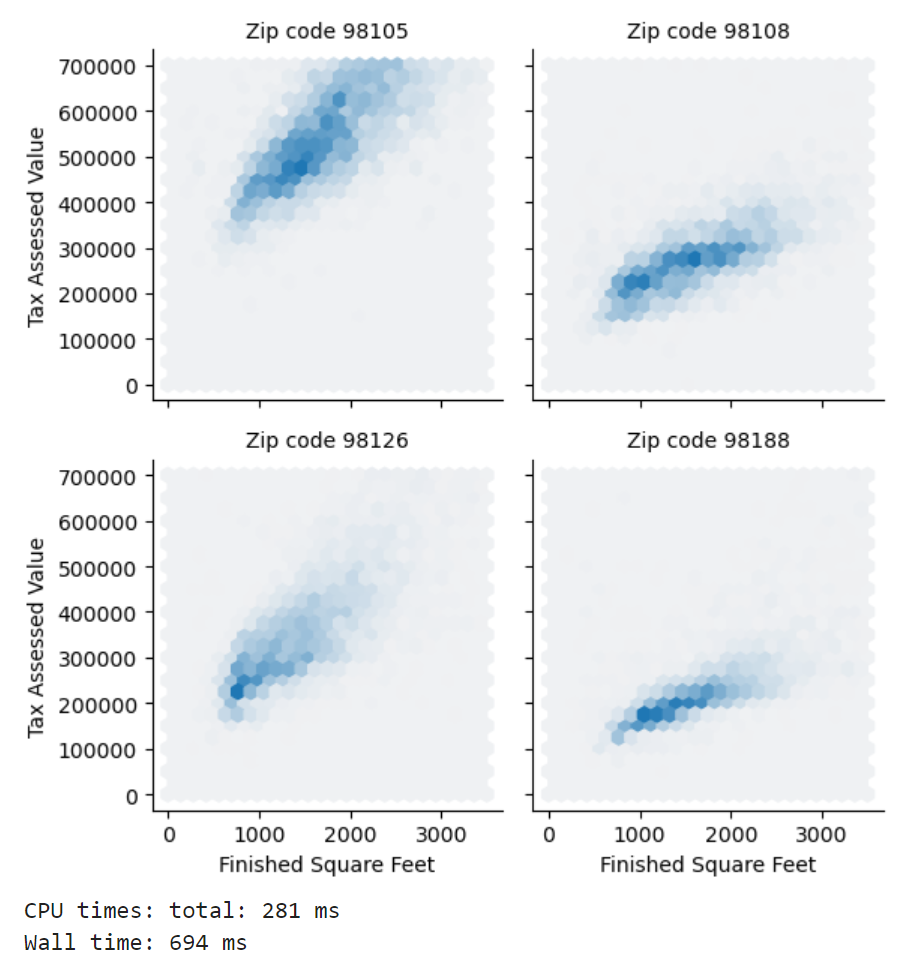
조건화conditioning라는 개념을 통해 두 변수 비교용 도표(산점도, 육각형 구간, 박스플롯)를 여러 변수를 비교하는 용도로 확장해서 그릴 수 있다. 아래는 주택 크기와 과세평가액 데이터를 다시 불러와서, 우편번호별로 데이터를 묶어서 도식화한 결과다. 어떤 우편번호에서의 평가액이 다른 두 군데보다 훨씬 높다는 사실을 알 수 있다. 코드가 다소 복잡함.

-
각 행의 왼쪽 차트가 오른쪽의 차트보다 대체로 동일한 입방피트에 대해 과세평가액을 높게 받고 있음을 한 눈에 볼 수 있다. 조건화 변수를 추가함으로써 변수를 통째로 시각화했을 때는 미처 드러나지 않았던 정보들이 더 잘 드러나는 효과를 볼 수 있다.
<세 줄 요약>
- 육각형 구간이나 등고선 도표는 데이터의 방대한 양에 압도되지는 않으면서도, 한 번에 두 수치형 변수를 시각적으로 검토할 때 유리한 도구
- 분할표는 두 범주형 변수의 도수를 확인하기 위한 대표적인 방법 (걍 피벗테이블 그린다고 생각해도 될 듯)
- 박스플롯이나 바이올린플롯은 범주형 변수와 수치형 변수 간의 관계를 도식화하기 위한 도구
