이 글은 자연어 처리와 언어 모델에 대한 주요 블로그 포스트 내용을 지속적으로 정리하여 제공합니다.
Introducing DRIFT Search: Combining Global and Local Search Methods to Improve Quality and Efficiency (2024.10.31, Microsoft)
- GraphRAG 기본 구조
- 인덱싱 엔진
- 문서를 작은 청크로 분할
- 엔티티와 관계가 포함된 지식 그래프 생성
- 그래프 내 커뮤니티 식별
- 글로벌 데이터 구조를 나타내는 "커뮤니티 리포트" 생성
- 쿼리 엔진 모드
- 글로벌 검색
- 전체 데이터셋 범위의 쿼리 처리
- 다양한 소스의 정보 통합
- 리소스 집약적
- 로컬 검색
- 입력과 밀접한 소수의 문서에서 검색
- 타겟팅된 쿼리에 최적화
- 글로벌 검색
- 인덱싱 엔진
- DRIFT 검색 작동 방식

- 프라이머(Primer) 단계
- 쿼리와 상위 K개의 관련 커뮤니티 리포트 비교
- HyDE(Hypothetical Document Embeddings) 사용
- 초기 답변과 후속 질문 생성
- 높은 수준의 추상화 활용
- 팔로업(Follow-Up) 단계
- 로컬 검색 변형을 사용한 후속 질문 실행
- 중간 답변과 추가 후속 질문 생성
- 현재 2회 반복으로 설정된 종료 기준
- 지식 그래프 내에서 특정 정보로 이동
- 출력 계층(Output Hierarchy) 단계
- 원래 쿼리 관련성 기준으로 순위가 매겨진 질문/답변 계층 구조
- 중간 답변들의 맵-리듀스 방식 집계
- 모든 답변에 동일한 가중치 적용
- 프라이머(Primer) 단계
- 성능 평가
- AP 뉴스 기사 5K+ 데이터셋으로 테스트
- 50개의 "로컬" 질문으로 평가
- 주요 평가 지표:
- 포괄성: 78% 향상
- 답변 다양성: 81% 향상
- 향후 연구 방향
- 개선된 글로벌 검색 통합
- 단일 쿼리 인터페이스 개발
- 보상 모델 기반 종료 로직 개선
- 쿼리 라우터와 경량 글로벌 검색 활용
- 강점
- 글로벌 통찰과 로컬 상세 정보의 동적 결합
- 인덱싱 페르소나와 다른 쿼리도 처리 가능
- 넓은 범위와 깊이 있는 정보 모두 제공
Introducing SimpleQA (2024.10.30, OpenAI)
- 벤치마크 주요 특징
- 짧은 사실 기반 질문에 대한 응답 정확도 측정
- 총 4,326개의 질문으로 구성
- GPT-4o 기준 40% 미만의 정답률로 최신 모델에도 도전적
- 간단하고 빠른 평가가 가능하도록 설계
- 데이터셋 구축 과정
- AI 트레이너들이 웹 검색을 통해 질문/답변 생성
- 질문 선정 기준
- 단일하고 명확한 답변 존재
- 시간 경과에 따른 답변 변화 없음
- GPT-3.5나 GPT-4o에서 환각 현상 유발
- 품질 검증 절차
- 2명의 독립적인 AI 트레이너가 각 질문에 답변
- 두 트레이너의 답변이 일치하는 경우만 포함
- 제3의 트레이너가 1,000개 샘플 검증 (94.4% 일치)
- 추정 오류율: 약 3%
- 주제 분포
- 과학기술, 정치, 예술, 지리, 스포츠, 음악, TV 프로그램, 역사, 비디오 게임, 기타
- 평가 방법
- ChatGPT 기반 분류기 사용
- 3가지 등급
- 정답과 완전히 일치
- 정답과 모순
- 답변 시도하지 않음
- 보정(Calibration) 측정
- 두 가지 방식으로 측정
- 직접적 신뢰도 표현
- 모델이 답변과 함께 신뢰도 백분율 제시
- 더 큰 모델이 더 나은 보정 보임
- 전반적으로 신뢰도 과대 추정 경향
- 반복 응답 분석
- 동일 질문 100회 반복
- 응답 빈도와 정확도 상관관계 분석
- o1-preview가 가장 우수한 보정 보임
- 직접적 신뢰도 표현
- 두 가지 방식으로 측정
- 한계점
- 단일 답변이 있는 짧은 사실 질문으로 제한
- 긴 응답에서의 사실성과의 상관관계는 미확인
NVIDIA NeMo Curator로 처리된 Zyda-2 오픈 5T 토큰 데이터 세트로 정확도 높은 LLM 훈련하기 (2024.10.25, Nvidia)
- 데이터셋 특성 (Zyda-2)
- 5T 토큰 규모의 대규모 사전 훈련 데이터셋
- Zyda-1 대비 5배 증가된 크기
- 기존 고품질 데이터셋들을 결합 (DCLM, FineWeb-edu, Dolma, Zyda-1)
- 일반적인 언어 능력에 중점을 둔 데이터셋 (코드/수학보다는 언어 중심)
- 데이터 처리 기술
- NVIDIA NeMo Curator를 활용한 GPU 가속 데이터 처리
- 주요 처리 단계:
- LSH 민해싱 기반 퍼지 중복 제거 적용
- DCLM 데이터셋에서 13% 중복 데이터 제거 성공
- 품질 분류기 모델을 통한 데이터 필터링
- Dolma-CC: 25% 고품질 데이터 선별
- Zyda-1: 17% 고품질 데이터 선별
- 강력한 교차 중복 제거 수행
- LSH 민해싱 기반 퍼지 중복 제거 적용
- 성능 개선 지표
- 데이터 처리 효율성
- TCO(총소유비용) 50% 절감
- 처리 시간 90% 단축 (3주 → 2일)
- 평가 메트릭스:
- MMLU, Hellaswag, Piqa, Winogrande, Arc-Easy, Arc-Challenge 종합 평가
- 기존 오픈소스 언어 모델링 데이터셋 대비 우수한 성능 달성
- 데이터 처리 효율성
- 모델 구현 세부사항
- Zamba2-2.7B 파라미터 모델로 어닐링 연구 수행
- Zamba2-7B 하이브리드 모델 개발
- 7B 파라미터 규모
- 리더보드에서 프론티어 모델 대비 우수한 성능 달성
- NVIDIA NIM 마이크로서비스로 패키징되어 배포 용이성 확보
- 기술적 인프라
- RAPIDS 라이브러리 활용
- cuDF, cuML, cuGraph 등 GPU 가속 라이브러리 사용
- 100TB 이상 데이터 처리 가능한 확장성
- 데이터 품질 향상 기술
- 정확도 검증
- 퍼지/시맨틱 중복 제거
- 분류기 모델 적용
- 합성 데이터 생성 지원
- RAPIDS 라이브러리 활용
From RAG to Fabric: Lessons Learned from Building Real-World RAGs at GenAIIC – Part 1 (2024.10.24, AWS)
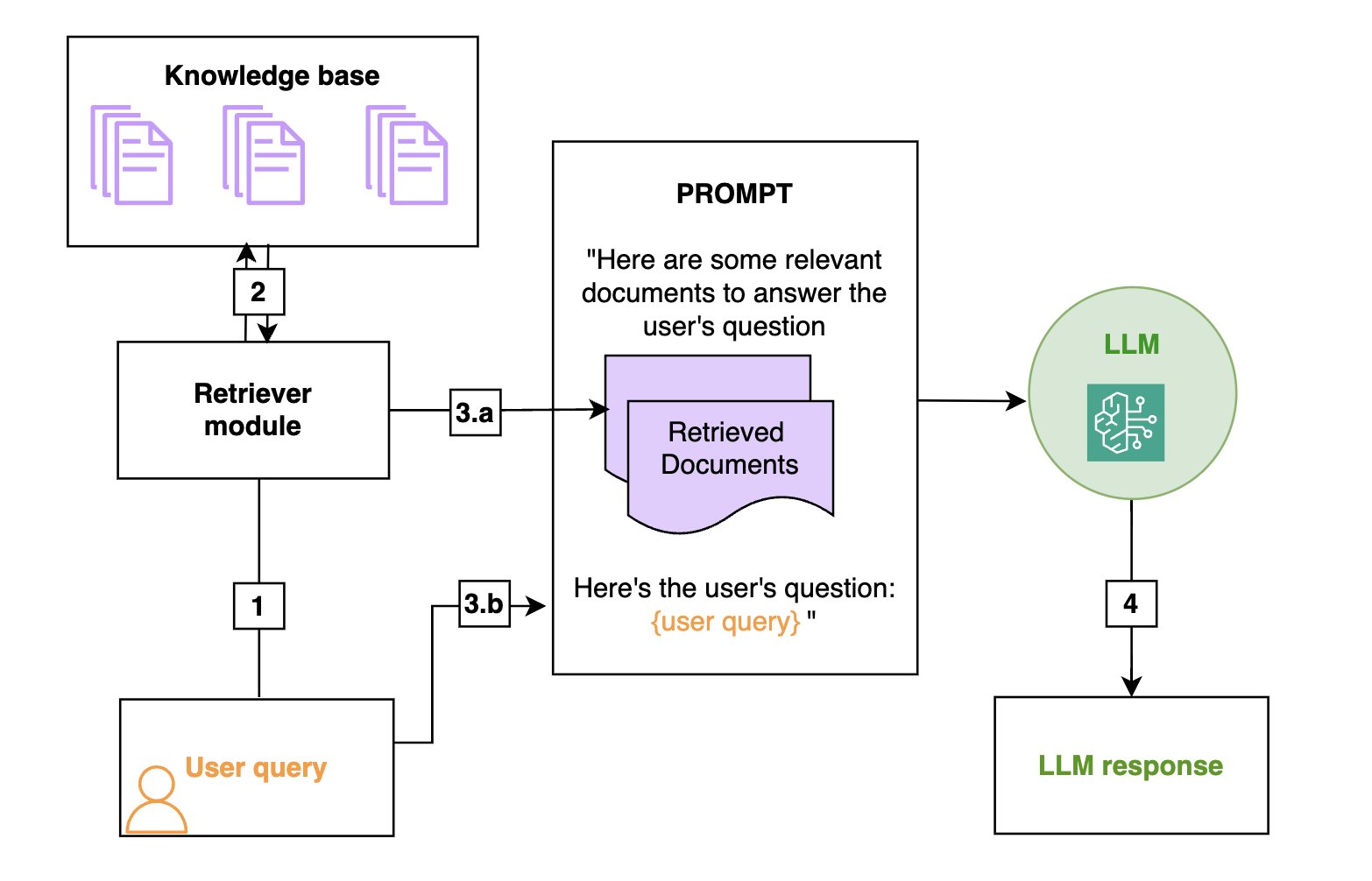
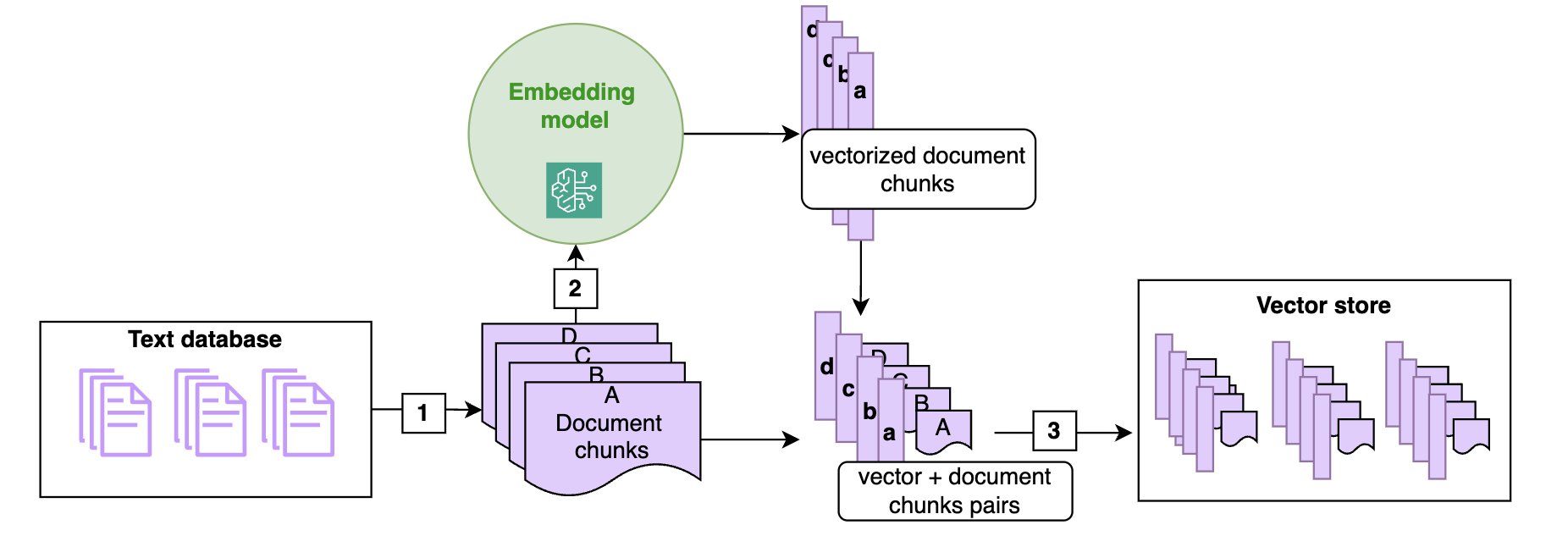
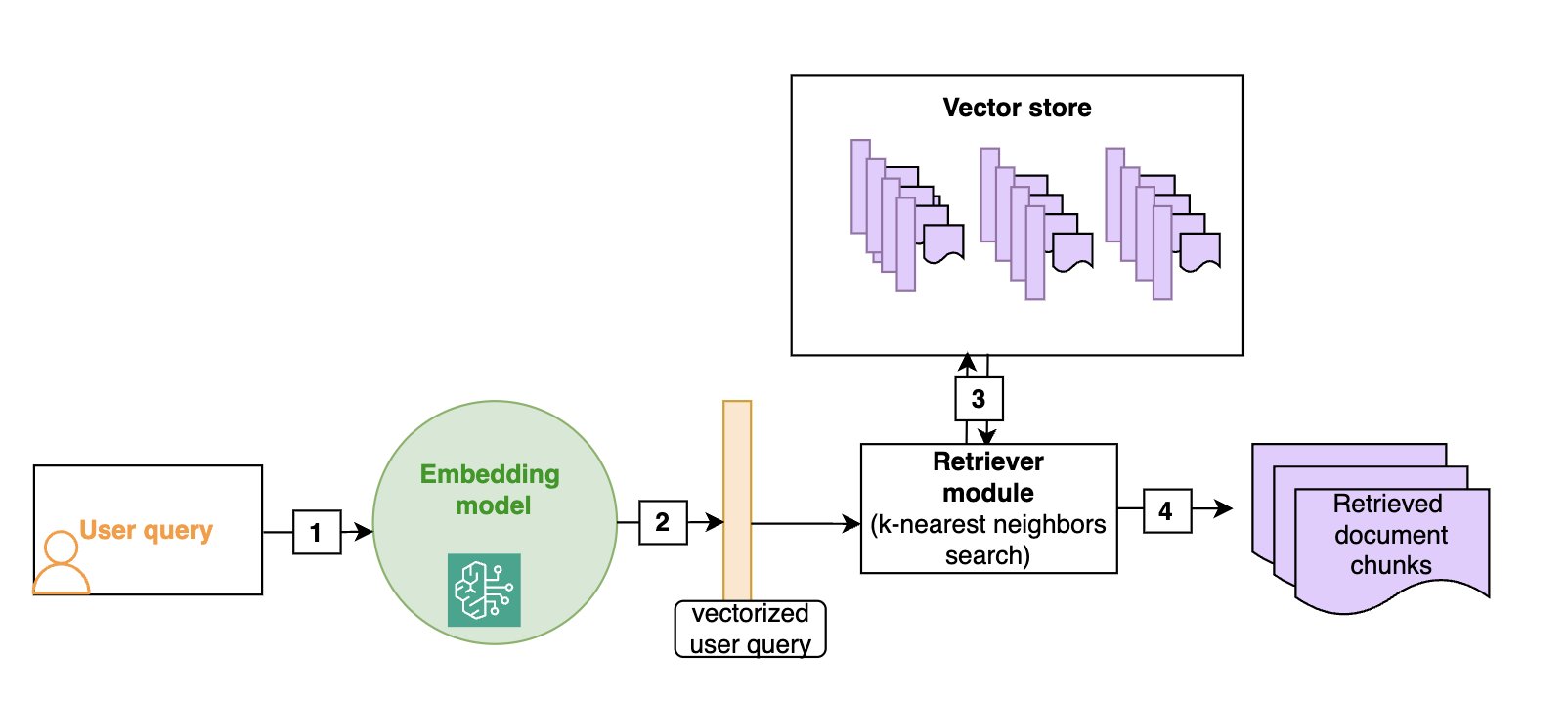
- RAG 핵심 아키텍처
- 기본 프로세스
- 검색
- 사용자 질문 기반 지식베이스 검색
- OpenSearch 인덱스 활용
- 벡터 저장소에서 관련 문서 추출
- 증강
- 검색된 정보를 LLM 프롬프트에 추가
- 사용자 쿼리와 함께 컨텍스트 제공
- 생성
- 증강된 프롬프트 기반 답변 생성
- LLM이 제공된 정보만 활용하도록 제한
- 검색
- 기본 프로세스
- 문서 처리 파이프라인
- 문서 인제스트 과정
- 청킹 전략
- 문서를 관리 가능한 크기로 분할
- 섹션 기반 청킹: HTML/Markdown 구조 활용
- 청크 크기와 오버랩 최적화
- 컨텍스트 유지를 위한 계층적 청킹
- 벡터 임베딩
- Amazon Titan 임베딩 모델 사용
- 8,192 토큰 컨텍스트 윈도우
- 시맨틱 유사도 기반 벡터화
- 메타데이터 처리
- 문서 제목, 날짜, 저자 등 추가 정보 저장
- 검색 필터링에 활용
- OpenSearch 인덱스에 메타데이터 필드 추가
- 청킹 전략
- 문서 인제스트 과정
- 검색 최적화 기술
- 하이브리드 검색 구현
search_query = { "query": { "bool": { "should": [ # 시맨틱 검색 { "function_score": { "query": {"knn": {...}}, "weight": semantic_weight } }, # 키워드 검색 { "function_score": { "query": {"match": {...}}, "weight": keyword_weight } } ] } } } - 스몰-투-라지 검색
- 구현 방식
- 초기 관련 청크 검색
- 인접 청크 추가 검색
- 전체 문서 컨텍스트 제공
- 청크 번호 및 문서명 추적
- 구현 방식
- 하이브리드 검색 구현
- 쿼리 최적화 기법
- 쿼리 재작성
query_rewriting_prompt = """ Rewrite the query as a json with the following keys: - rewritten_query: semantic search용 쿼리 - keywords: 검색 엔진용 키워드 - product_name: 필터링용 제품명 """ - 메타데이터 필터링
- 구현 예시
search_query['query']['bool']['must'].append({ "match_phrase": { "product_name": product_name } })
- 구현 예시
- 쿼리 재작성
- 응답 생성 최적화
- 할루시네이션 방지
- 프롬프트 가드레일
- 문서 기반 답변만 허용
- 불확실성 명시 지시
- 인용구 생성 요구
- 프롬프트 가드레일
- 인용 시스템
- JSON 포맷 인용
{ "document_name": "doc_0", "quote": "실제 인용 텍스트" } - 인라인 인용
- 답변 내 직접 인용구 포함
- 소스 문서 참조 제공
- JSON 포맷 인용
- 할루시네이션 방지
- 평가 지표
- 검색 성능 지표
- k 상위 정확도
- 평균 상호 순위 (MRR)
- 재현율
- 정밀도
- 응답 품질 평가
- 전문가 평가
- LLM-as-Judge 평가
- 인용구 정확도 검증
- 자동화된 평가 프레임워크 (Ragas, LlamaIndex, RefChecker)
- 검색 성능 지표
A Deepdive into Aya Expanse: Advancing the Frontier of Multilinguality (2024.10.24, HuggingFace)
- 모델 개요
- Aya Expanse 모델 패밀리 출시
- 8B 및 32B 파라미터 버전 제공
- 다국어 성능에서 SOTA 달성
- 오픈 웨이트로 공개
- Aya Expanse 모델 패밀리 출시
- 성능 벤치마크
- Aya Expanse 32B
- Gemma 2 27B, Mistral 8x22B, Llama 3.1 70B 대비 우수한 성능
- 2배 큰 모델(70B)보다 높은 성능 달성
- Aya Expanse 8B
- Gemma 2 9B, Llama 3.1 8B, Ministral 8B 대비 60.4-70.6% 승률
- 23개 언어로 번역된 Arena-Hard-Auto 데이터셋 평가
- Aya Expanse 32B
- 핵심 기술 컴포넌트
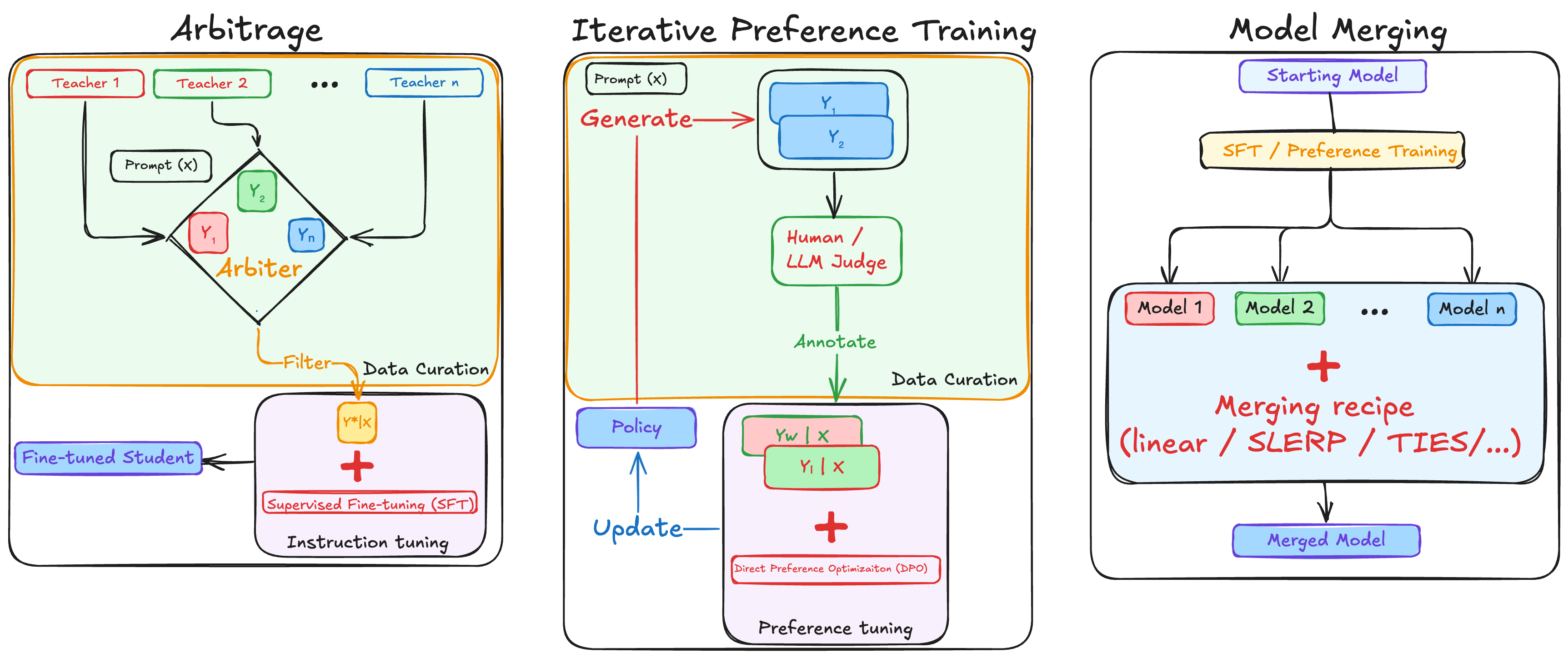
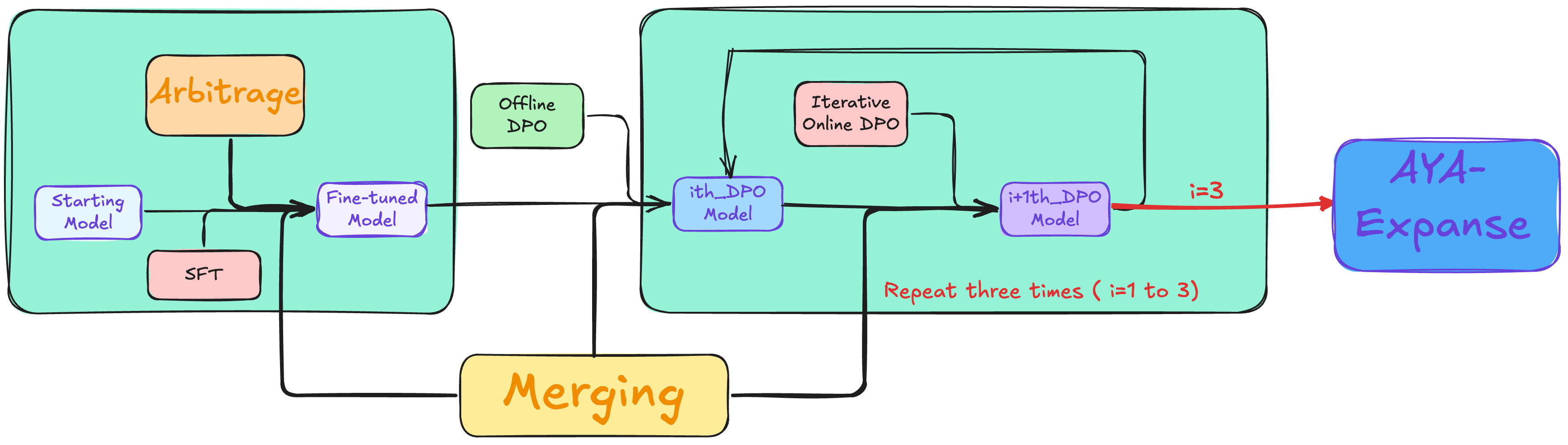
- 데이터 아비트라지(Arbitrage) 기술
- 다수의 교사 모델 풀에서 전략적 샘플링
- 내부 보상 모델(RM)을 사용한 최적 생성 선택
- 언어별 그룹화된 모델 풀 활용
- Gemma 2 9B 대비 9.1% 성능 향상 달성
- 글로벌 선호도 학습
- 오프라인-온라인 혼합 선호도 학습 접근
- 다국어 선호도 데이터 쌍 생성 기술 도입
- 3회 반복 DPO(Direct Preference Optimization) 수행
- Gemma 2 9B 대비 7.1% 추가 성능 향상
- 모델 병합 전략
- 가중 선형 평균화 방식 채택
- 다양한 병합 기법 실험 (SLERP, TIES-merging, DARE-TIES)
- 언어군별 체크포인트 다양성 최적화
- 공유 언어(영어, 스페인어, 프랑스어) 포함
- 35B 스케일에서 8B 대비 3배 높은 병합 이득
- 데이터 아비트라지(Arbitrage) 기술
- 기술적 특징
- 합성 데이터 생성시 모델 붕괴 방지
- 저자원 언어에 대한 특별한 고려
- 교차 언어 전이학습 활용
- 다단계 최적화 파이프라인 구현
- 데이터 혼합과 모델 병합의 균형 조정
Can We Make Any Smaller Opensource LLM Models Smarter Than Human? (2024.10.04)
- 연구 목적
- 오픈소스 LLM 모델을 개선하여 폐쇄형 모델과 경쟁
- Claude Sonnet 3.5와 같은 현재 SOTA 모델을 OpenAI의 O1-preview와 O1 mini 수준으로 개선
- LLM의 추론 능력 개선 방법
- 동적 사고 사슬 (Dynamic Chain of Thoughts)
- 반영 (Reflection)
- 언어적 강화 학습 (Verbal Reinforcement)
- 새로운 프롬프팅 패러다임
- <thinking> 태그: 다양한 접근 방식 탐색
- <step> 태그: 해결 과정을 단계별로 나누기
- <count> 태그: 남은 단계 수 표시
- <reflection> 태그: 진행 상황 평가
- <reward> 태그: 품질 점수 부여 (0.0-1.0)
- 수학 문제: LaTeX 사용, 상세한 증명 제공
- <answer> 태그: 최종 답변 요약
- 벤치마크 평가
- JEE Advanced와 UPSC 예비 시험 문제 사용
- IMO 2023 문제 사용
- Putnam 수학 경진대회 문제 사용 (2013-2023년)
- 평가 도구
- Streamlit 기반 웹 앱
- Groq API (오픈소스 모델용)
- 기타 API (GPT-4O, O1, Claude 등 폐쇄형 모델용)
- 주요 결과
- Claude Sonnet 3.5가 새 프롬프팅 기법으로 O1 모델 능가
- Llama 3.1 8b 모델 성능 크게 향상
- IMO 2023 문제에서 Claude Sonnet이 첫 시도에 50% 정답률 달성
- Putnam 문제에서 Llama 3.1 70B, Claude Sonnet, O1 mini가 14문제 해결 (O1은 13문제)
- 관찰된 LLM 능력
- 자체 시뮬레이션 생성 가능
- 복잡한 수학 문제 해결에 50단계 이상의 내부 추론 과정 사용
- MCQ 형식 문제에 더 강함
- Claude Sonnet 3.5가 7개 문제에 약 100만 토큰 사용
- 결론
- LLM에게 지식 활용 방법을 가르치는 것이 중요
- 이러한 추론 능력은 다양한 분야의 워크플로우 자동화에 활용 가능
- 작은 오픈소스 모델을 대형 언어 모델의 대체제로 활용 가능
Llama 3.2: Revolutionizing Edge AI and Vision with Open, Customizable Models (2024.09.24, Meta)
- 모델 구성
- 비전 LLM: 11B와 90B 파라미터 모델
- 경량 텍스트 전용 모델: 1B와 3B 파라미터 모델
- 사전 학습 및 명령어 튜닝 버전 모두 제공
- 경량 모델 (1B, 3B) 특징
- 128K 토큰의 컨텍스트 길이 지원
- 엣지 및 모바일 기기에서 사용 가능
- 요약, 지시 따르기, 재작성 작업에서 동급 최고 성능
- Qualcomm, MediaTek 하드웨어 및 Arm 프로세서에 최적화
- 비전 모델 (11B, 90B) 특징
- 해당 텍스트 모델의 대체 가능
- 이미지 이해 작업에서 Claude 3 Haiku와 같은 폐쇄 모델 능가
- 사전 학습 및 정렬된 모델 모두 제공
- torchtune을 사용한 맞춤형 애플리케이션 미세 조정 가능
- torchchat을 사용한 로컬 배포 가능
- 비전 모델 아키텍처
- 사전 학습된 이미지 인코더를 언어 모델에 통합하는 어댑터 가중치 추가
- 크로스 어텐션 레이어를 통해 이미지 인코더 표현을 언어 모델에 제공
- 이미지-텍스트 쌍으로 어댑터 학습
- 언어 모델 매개변수는 유지하여 텍스트 전용 기능 보존
- 비전 모델 학습 파이프라인
- Llama 3.1 텍스트 모델에서 시작
- 이미지 어댑터 및 인코더 추가
- 대규모 노이즈 (이미지, 텍스트) 쌍 데이터로 사전 학습
- 중규모 고품질 도메인 내 및 지식 강화 (이미지, 텍스트) 쌍 데이터로 학습
- 지도 미세 조정, 거부 샘플링, 직접 선호도 최적화를 통한 정렬
- 경량 모델 개발 방법
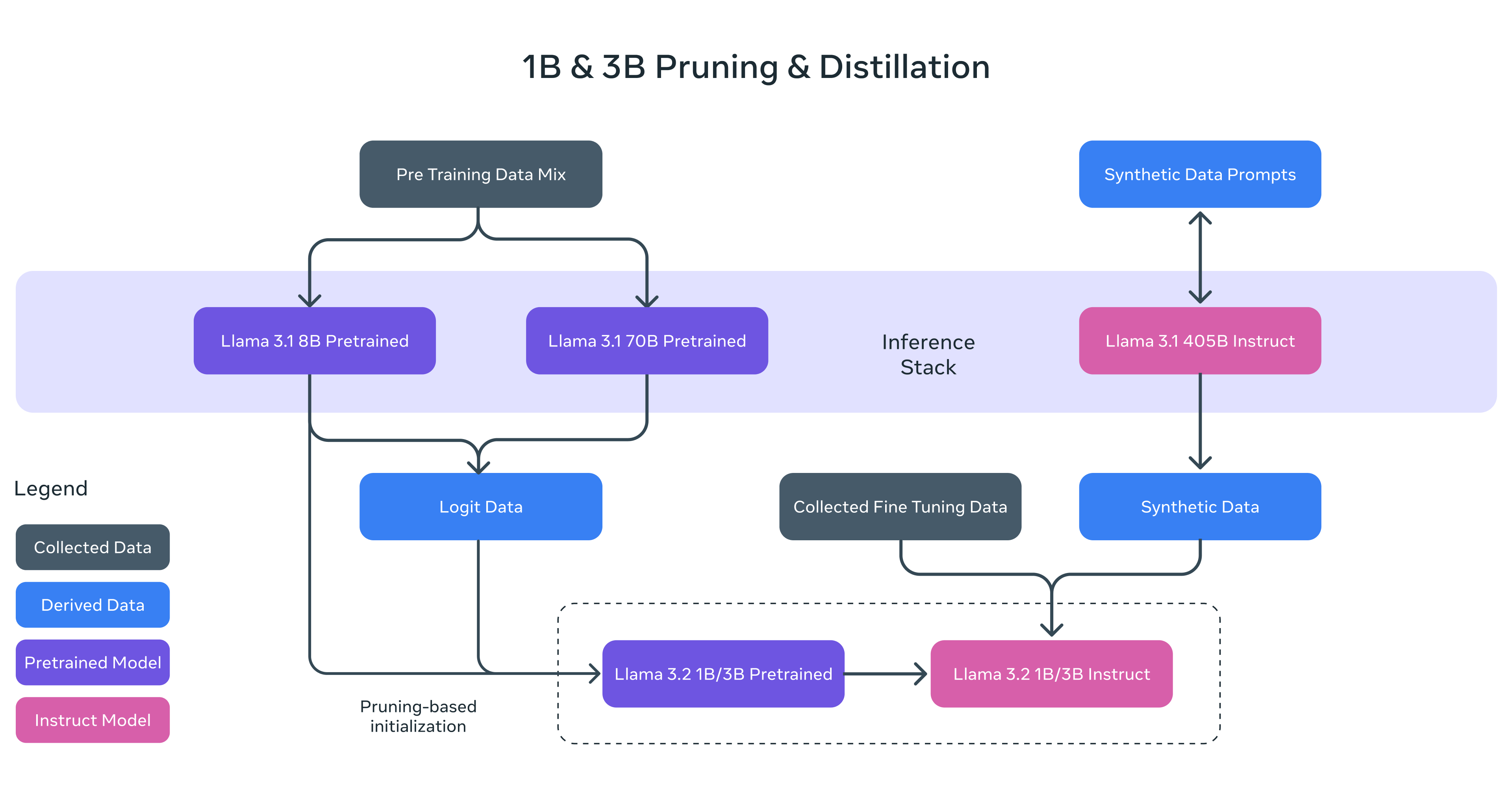
- 가지치기(Pruning): Llama 3.1 8B 모델에서 구조화된 가지치기 적용
- 지식 증류(Knowledge distillation): Llama 3.1 8B 및 70B 모델의 로짓을 사전 학습 단계에 활용
- Llama Stack
- 추론, 도구 사용, RAG에 대한 API 참조 구현
- 다양한 환경(온프레미스, 클라우드, 단일 노드, 온디바이스)에서 일관된 경험 제공
- CLI, 다국어 클라이언트 코드, Docker 컨테이너 제공
- 다양한 배포 옵션 (단일 노드, 클라우드, 온디바이스, 온프레미스)
- 안전성 개선
- Llama Guard 3 11B Vision: 텍스트+이미지 입력 프롬프트 및 출력 응답 필터링
- Llama Guard 3 1B: 1B 모델 기반, 크기 2,858MB에서 438MB로 최적화
Generate Synthetic Data for Evaluating RAG Systems Using Amazon Bedrock (2024.09.23, AWS)
- RAG 시스템 평가
- 실제 사용자 질문-답변 쌍을 사용한 평가의 중요성 강조
- 평가 데이터셋 구성요소: 사용자 질문 리스트, 해당 답변 리스트, 각 질문에 대한 관련 컨텍스트
- Amazon Bedrock을 활용한 합성 데이터 생성
- Anthropic Claude 모델 사용
- 단일 API를 통해 다양한 기초 모델(FMs) 접근 가능
- 데이터 준비 및 처리
- LangChain의 PyPDFDirectoryLoader를 사용하여 PDF 문서 로드
- RecursiveCharacterTextSplitter로 문서를 청크로 분할 (chunk_size=1500, chunk_overlap=100)
- Amazon Bedrock 설정
- boto3 클라이언트 사용하여 Bedrock 런타임 설정
- Claude 3 Haiku 모델 선택 (비용 및 성능 효율성 고려)
- 추론 파라미터 설정: max_tokens=4096, temperature=0.2
- LangChain을 이용한 프롬프트 엔지니어링
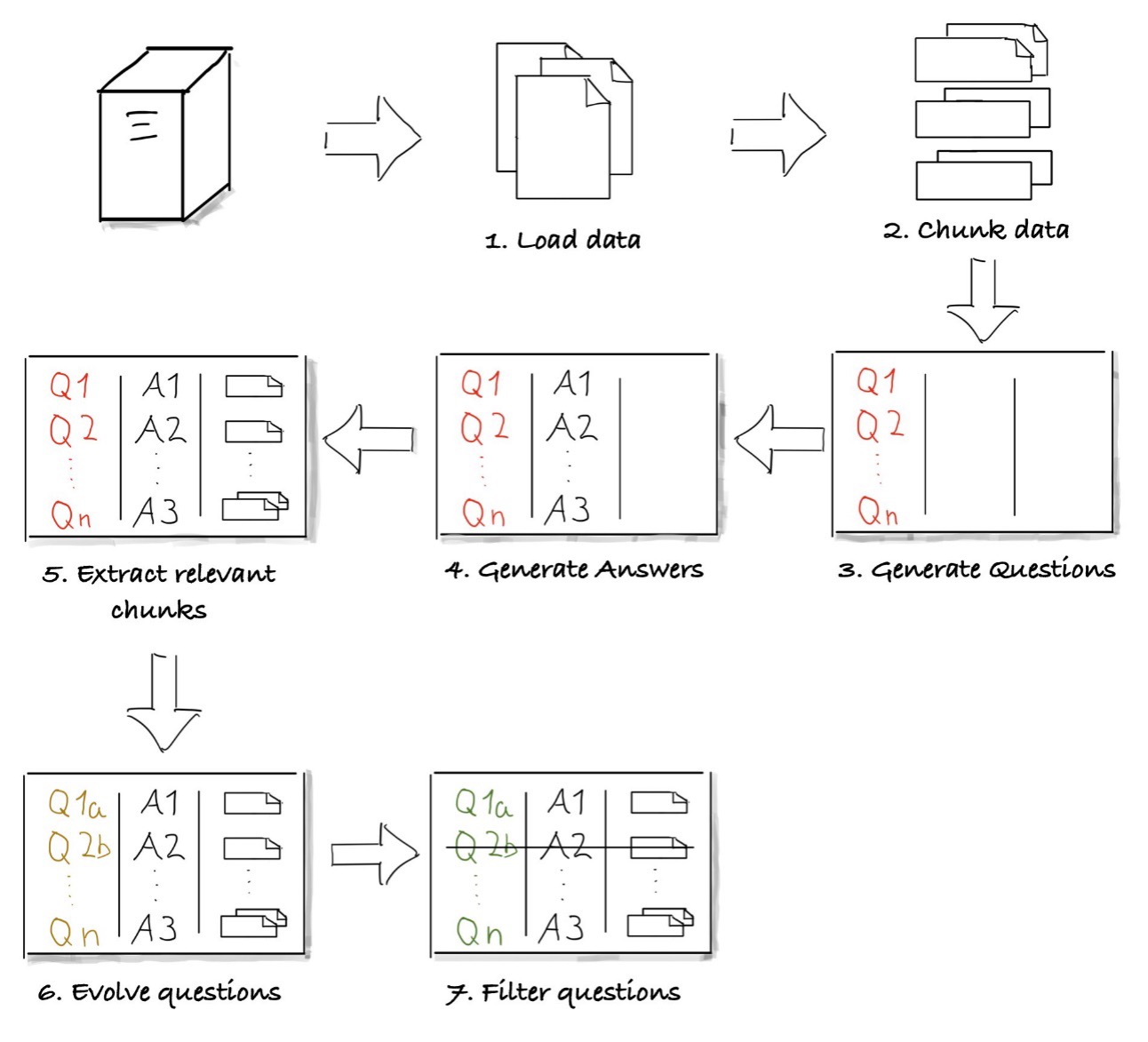
- PromptTemplate 클래스를 사용하여 다양한 프롬프트 템플릿 생성
- 초기 질문 생성
- 답변 생성
- 관련 컨텍스트 추출
- 질문 개선
- PromptTemplate 클래스를 사용하여 다양한 프롬프트 템플릿 생성
- 자동화된 데이터셋 생성 프로세스
- 모든 문서 청크에 대해 반복하여 질문, 답변, 관련 문장, 개선된 질문 생성
- pandas DataFrame을 사용하여 결과 저장
- 비평 에이전트(Critique Agents) 구현
- 질문의 관련성과 답변의 근거 평가
- 1-5 척도의 평가 시스템 사용
- groundedness_check_prompt_template와 relevance_check_prompt_template 구현
- 성능 및 비용 고려사항
- Claude 3 Haiku 사용 시 평균 처리 시간: 2.6초/세트
- 1,000개 질문-답변 세트 생성 비용: 약 $2.80 USD
- 모범 사례 권장사항
- 실제 데이터와 합성 데이터 결합
- RAG 생성에 사용된 것과 다른 LLM 선택
- 강력한 품질 보증 메커니즘 구현
- 반복적인 개선 프로세스
- 도메인 특화 커스터마이제이션 (예: PEFT 또는 RLHF를 통한 미세 조정)
- 코드 샘플
Introducing Contextual Retrieval (2024.09.20, Anthropic)
- Contextual Retrieval 소개
- RAG(Retrieval-Augmented Generation)의 검색 단계를 개선하는 방법
- 두 가지 하위 기술 사용: Contextual Embeddings와 Contextual BM25
- 실패한 검색 수를 49% 감소시킴 (재순위화와 결합 시 67% 감소)
- 전통적인 RAG의 한계
- 문서를 작은 청크로 분할하여 컨텍스트 손실 발생
- 개별 청크가 충분한 컨텍스트를 갖지 못해 정확한 정보 검색 어려움
- Contextual Retrieval 구현
- 각 청크에 특정 설명 컨텍스트를 추가하여 임베딩 및 BM25 인덱스 생성
- Claude 3 Haiku를 사용하여 각 청크에 대한 컨텍스트 자동 생성
- 생성된 컨텍스트(50-100 토큰)를 청크에 추가 후 임베딩 및 BM25 인덱스 생성
- 성능 개선
- Contextual Embeddings: top-20 청크 검색 실패율 35% 감소
- Contextual Embeddings + Contextual BM25: 실패율 49% 감소
- 구현 시 고려사항
- 청크 경계 설정
- 임베딩 모델 선택 (Gemini와 Voyage 임베딩이 효과적)
- 도메인별 맞춤 컨텍스트 생성 프롬프트 사용
- 최적의 청크 수 결정 (실험 결과 20개가 가장 효과적)
- 재순위화(Reranking) 기법
- 초기 검색 결과에서 가장 관련성 높은 청크만 선별
- 구현 단계: 초기 검색 → 재순위화 모델 적용 → 상위 K개 청크 선택 → 최종 결과 생성
- Contextual Retrieval과 결합 시 top-20 청크 검색 실패율 67% 감소
- 비용 및 지연 시간 고려사항
- 재순위화로 인한 약간의 지연 시간 추가
- 더 많은 청크 재순위화 vs. 낮은 지연 시간 및 비용 간의 트레이드오프 존재
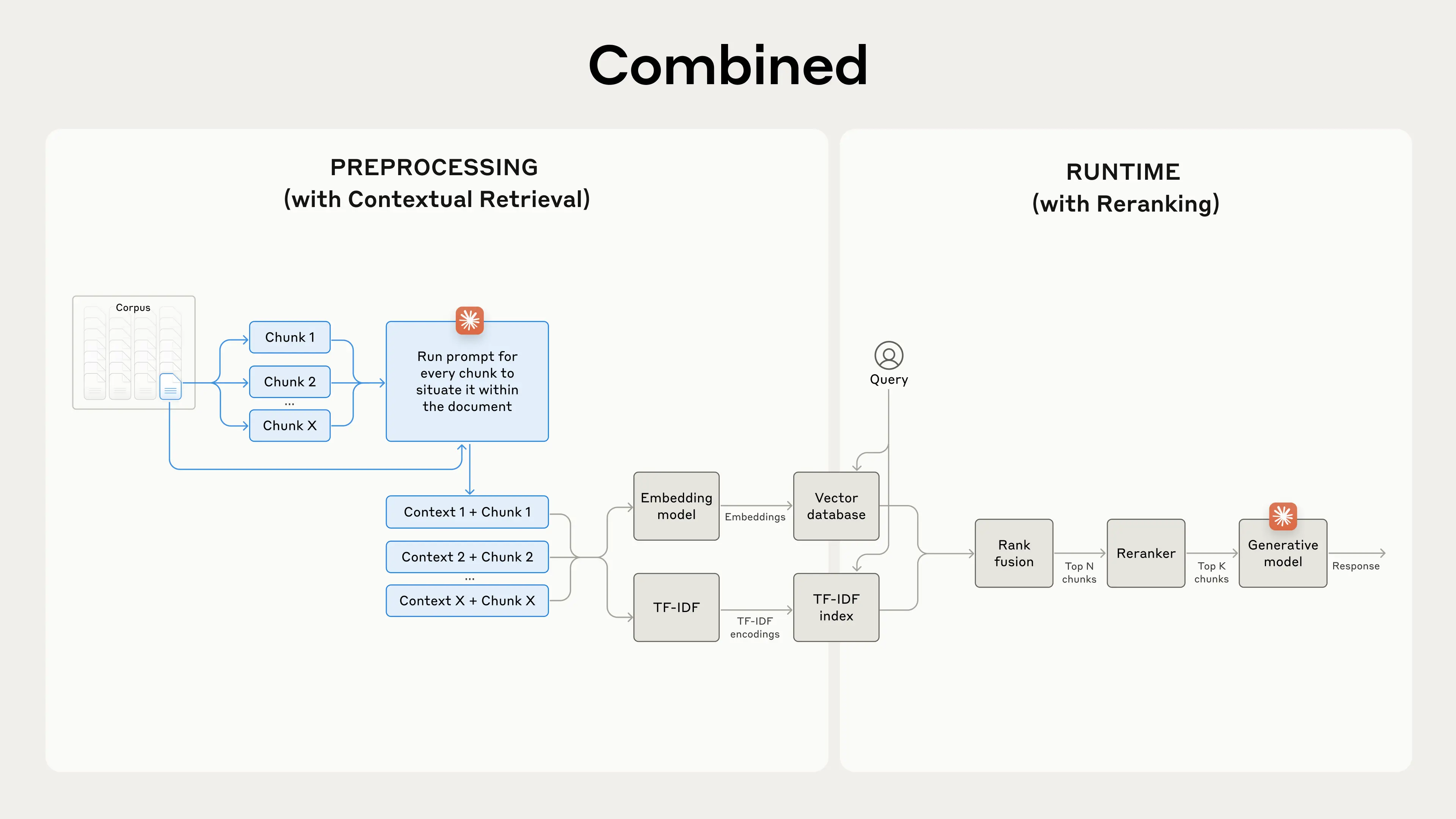
- 실험 결과 요약
- Embeddings + BM25가 단독 임베딩보다 효과적
- Voyage와 Gemini 임베딩이 가장 우수한 성능
- 모델에 top-20 청크 전달이 가장 효과적
- 청크에 컨텍스트 추가가 검색 정확도 크게 향상
- 재순위화 적용이 더 나은 성능 제공
- 모든 기법 결합 시 최대 성능 개선 달성 (Contextual Embeddings + Contextual BM25 + 재순위화 + 20개 청크)
- 코드 샘플
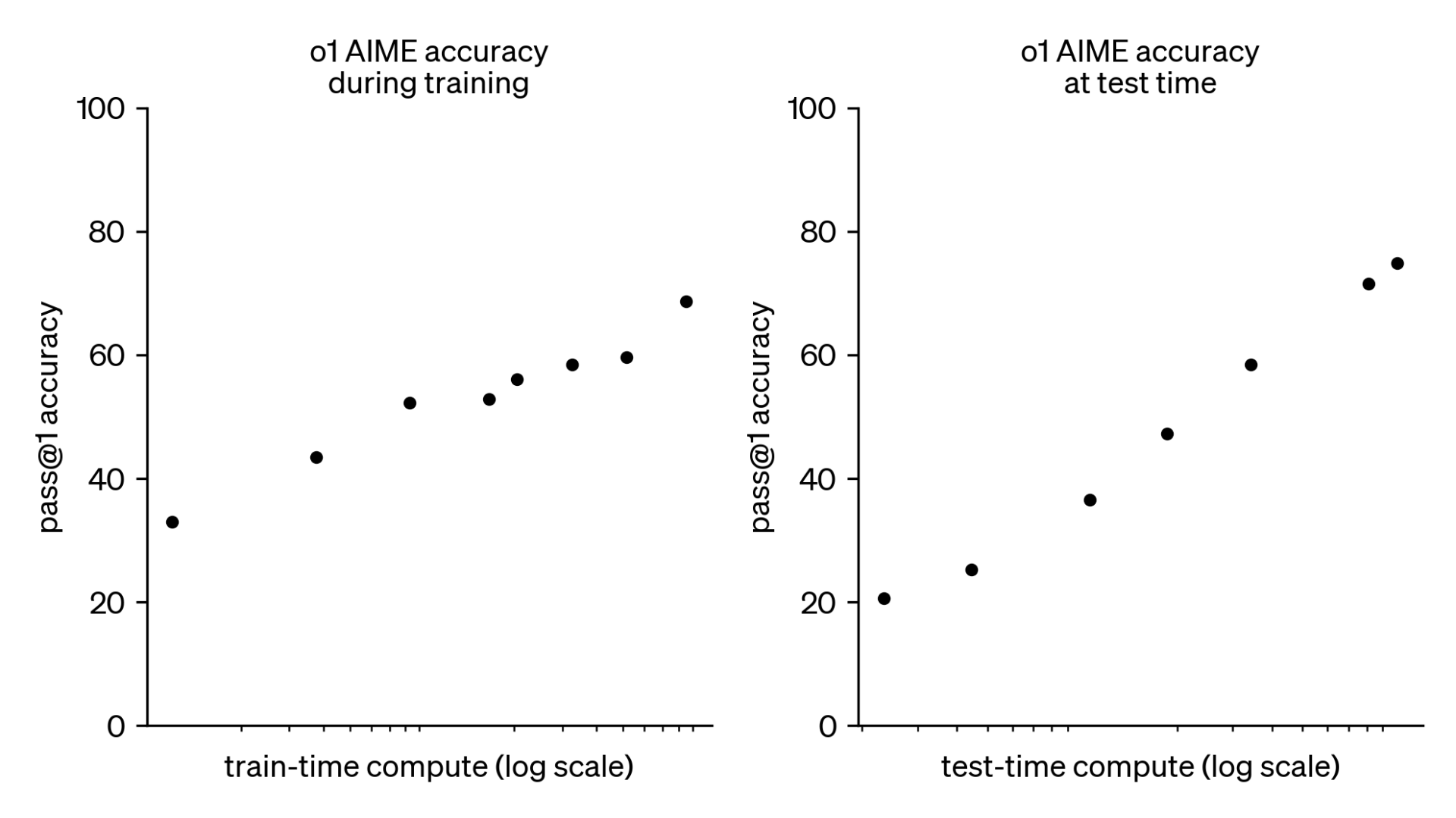
Learning to Reason with LLMs (2024.09.12, OpenAI)
- 모델 아키텍처
- OpenAI o1은 강화학습으로 훈련된 새로운 대규모 언어 모델
- 복잡한 추론 능력에 중점을 둠
- 응답하기 전에 내부적으로 생각의 사슬을 길게 생성
- 훈련 방식
- 대규모 강화학습 알고리즘 사용
- 생각의 사슬을 활용하여 생산적으로 사고하도록 모델 훈련
- 매우 데이터 효율적인 훈련 과정
- 더 많은 RL 훈련(훈련 시간 계산)과 더 많은 추론 시간(테스트 시간 계산)으로 성능 향상
- 생각의 사슬을 통한 추론
- 모델이 RL을 통해 생각의 사슬을 개선하고 전략을 정제하는 법을 학습
- 실수를 인식하고 수정
- 복잡한 단계를 더 간단한 단계로 분해
- 현재 접근법이 작동하지 않을 때 다른 접근법 시도
- 안전성과 정렬
- 모델이 생성하는 생각의 사슬에 안전 정책 통합
- 탈옥에 대한 평가와 가장 어려운 내부 안전 벤치마크에서 성능 향상
- 생각의 사슬 추론이 안전성 평가 전반에 걸쳐 능력 향상에 기여
- 코딩 능력
- 숨겨진 생각의 사슬
- 내부 추론 과정을 사용자에게 직접 보여주지 않음
- 향후 모델의 생각 과정 모니터링 가능성
- 최종 답변에서 생각의 사슬의 유용한 아이디어를 재현하도록 모델 훈련
Align Meta Llama 3 to Human Preferences with DPO, Amazon SageMaker Studio, and Amazon SageMaker Ground Truth (2024.09.09, AWS)
GraphRAG Auto-Tuning Provides Rapid Adaptation to New Domains (2024.09.09, Microsoft)
Ground Truth Curation and Metric Interpretation Best Practices for Evaluating Generative AI Question Answering Using FMEval (2024.09.06, AWS)
Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge) (2024.08.18)
New LLM Pre-training and Post-Training Paradigms (2024.08.17)
1. Alibaba의 Qwen 2
- 모델 개요
- 0.5B, 1.5B, 7B, 72B 파라미터의 일반 모델과 57B 파라미터의 MoE 모델 제공
- 30개 언어 지원으로 우수한 다국어 능력
- 151,642 토큰의 대규모 어휘 사용
- 사전 학습
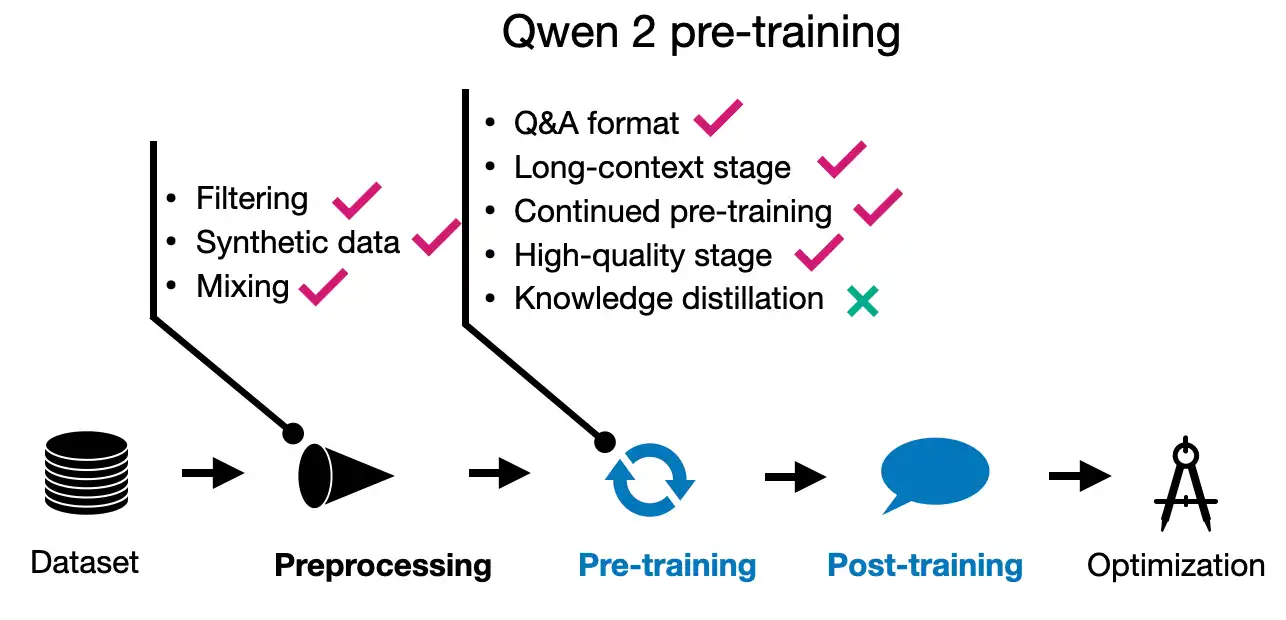
- 7조 토큰으로 학습 (0.5B 모델은 12조 토큰)
- 데이터 필터링과 믹싱 개선에 중점
- 이전 Qwen 모델로 추가 사전 학습 데이터 합성
- 2단계 학습: 일반 사전 학습 후 긴 컨텍스트 학습 (4,096 → 32,768 토큰)
- 사후 학습
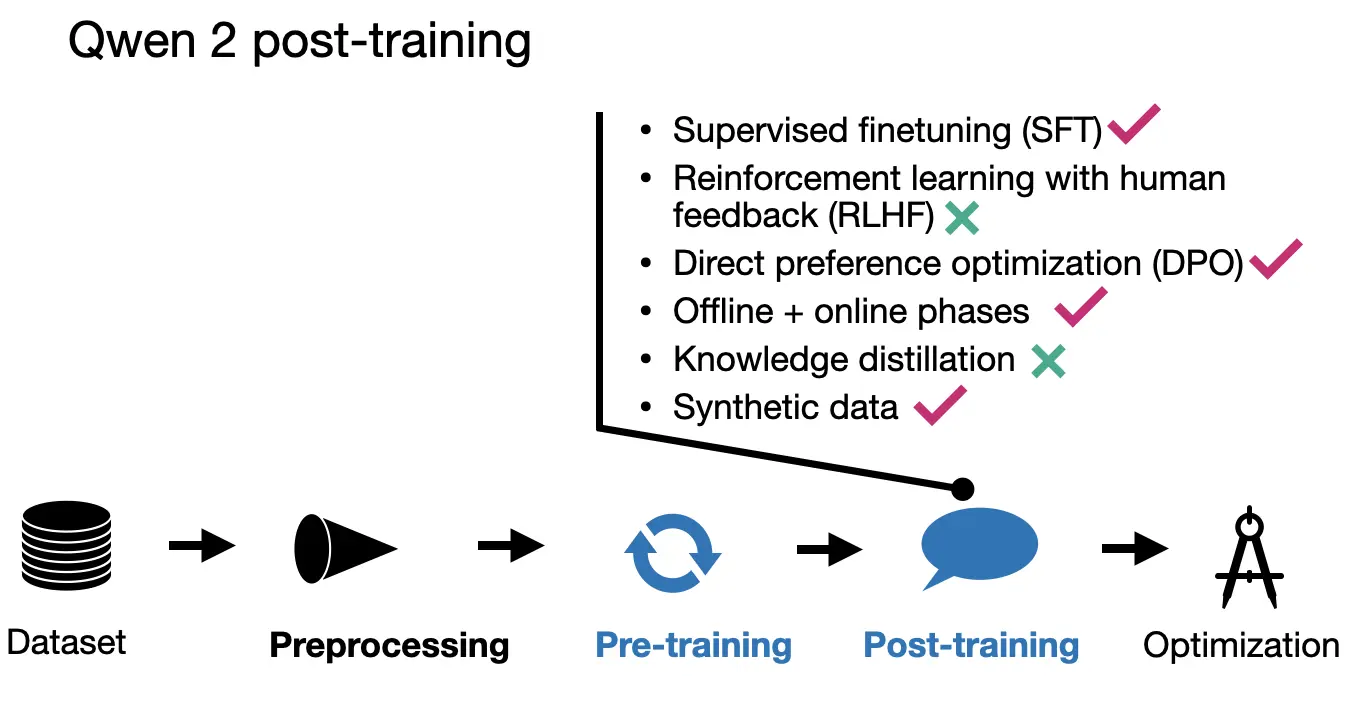
- SFT(50만 예제, 2 에폭) 후 DPO 적용
- 2단계 정렬: 오프라인 DPO와 온라인 보상 모델 사용
- 인간 라벨링과 합성 데이터 혼합 사용
2. Apple의 AFM (Apple Foundation Models)
- 모델 개요
- 3B 파라미터 온디바이스 모델과 서버용 대형 모델 개발
- 채팅, 수학, 코딩 작업 지원
- 사전 학습
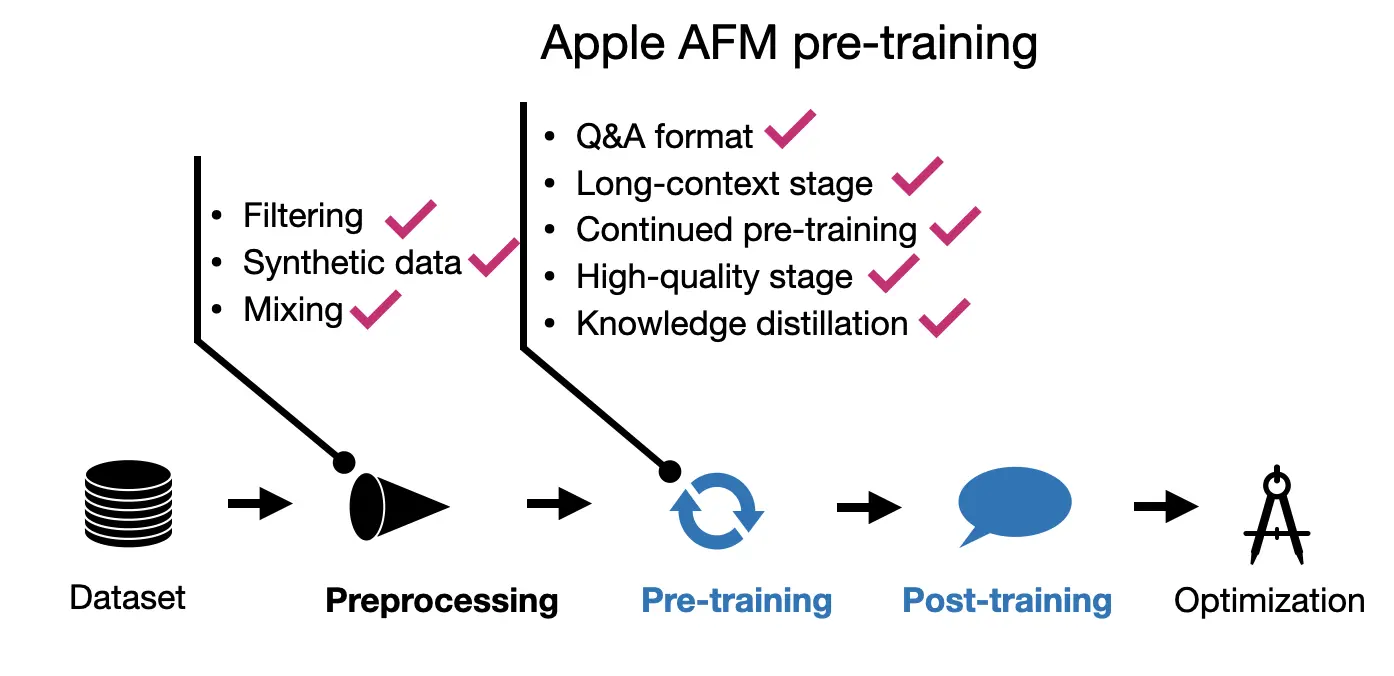

- 3단계 접근
1) 코어 사전 학습 (6.3조 토큰, 4096 토큰 시퀀스 길이)
2) 지속 사전 학습 (1조 토큰, 8,192 토큰으로 컨텍스트 확장)
3) 컨텍스트 확장 (1000억 토큰, 32,768 토큰으로 확장) - 온디바이스 모델은 6.4B 모델에서 지식 증류로 학습
- 3단계 접근
- 사후 학습
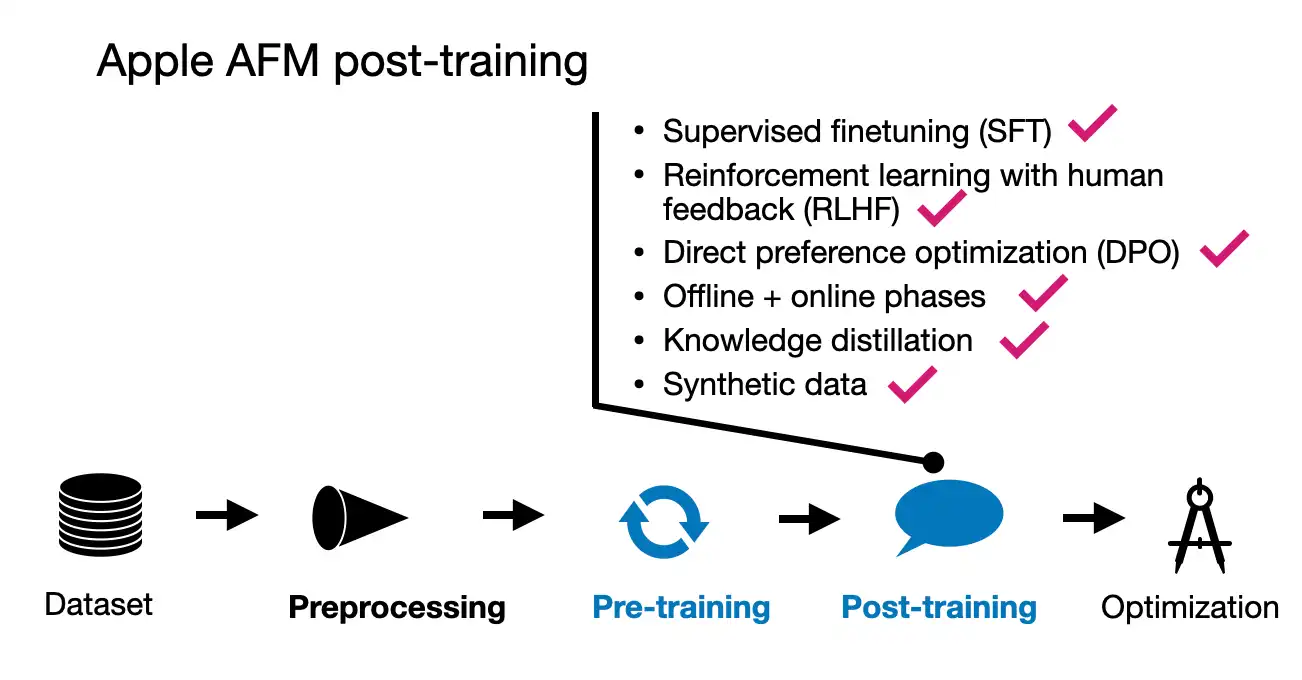
- SFT 후 여러 라운드의 RLHF 적용
- iTeC (Rejection Sampling with Teacher Committee) 알고리즘 도입
- Mirror Descent Policy Optimization을 이용한 RLHF 적용
3. Google의 Gemma 2
- 모델 개요
- 2B, 9B, 27B 파라미터 모델 제공
- 256k 토큰의 대규모 어휘 사용
- 슬라이딩 윈도우 어텐션 사용
- 사전 학습
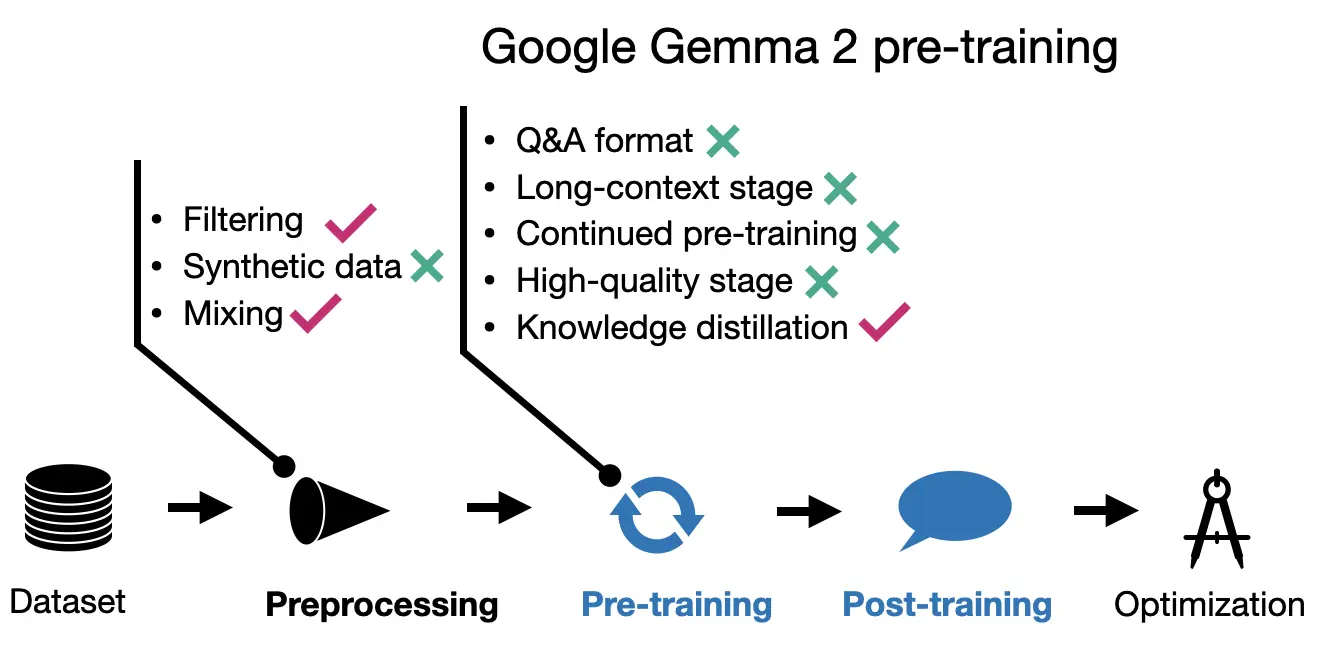
- 27B 모델: 13조 토큰으로 학습
- 9B 모델: 8조 토큰, 2B 모델: 2조 토큰으로 학습
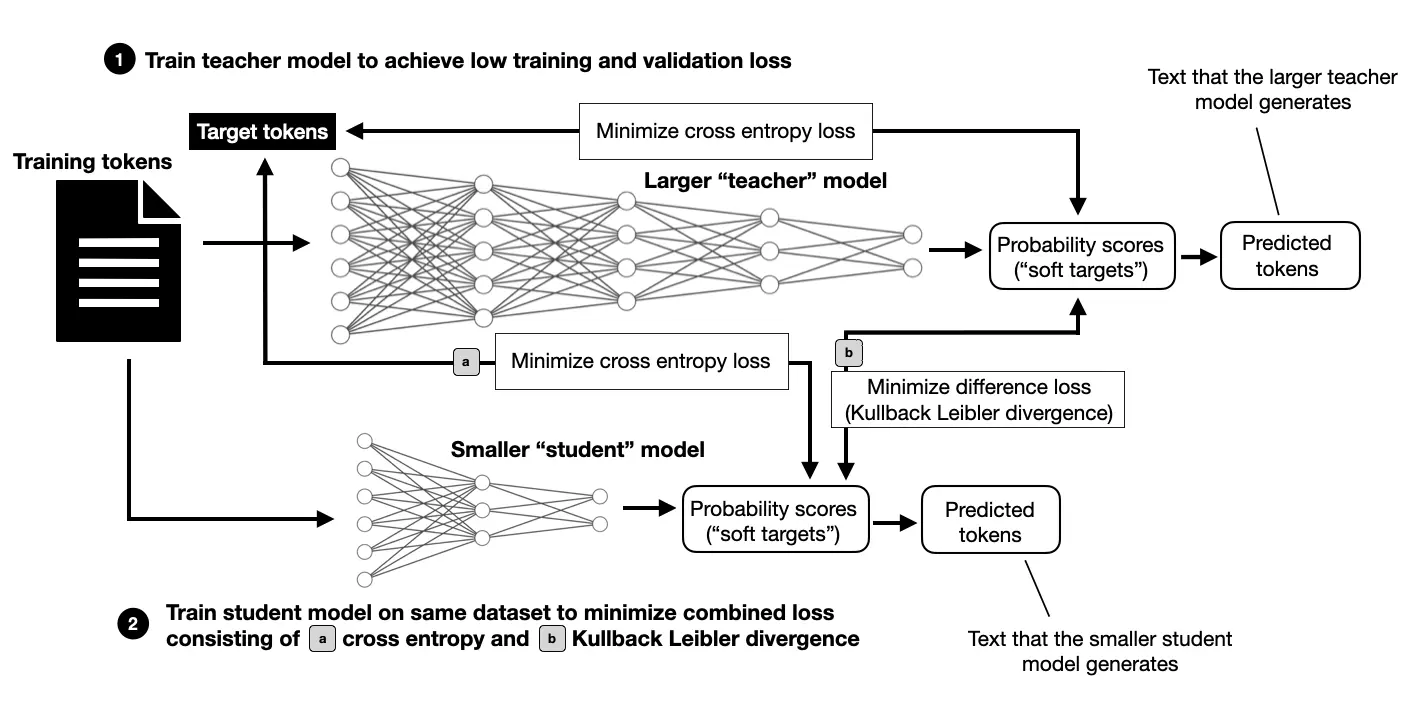
- 작은 모델들은 지식 증류 기법 적용
- 데이터 믹스 최적화에 중점
- 사후 학습
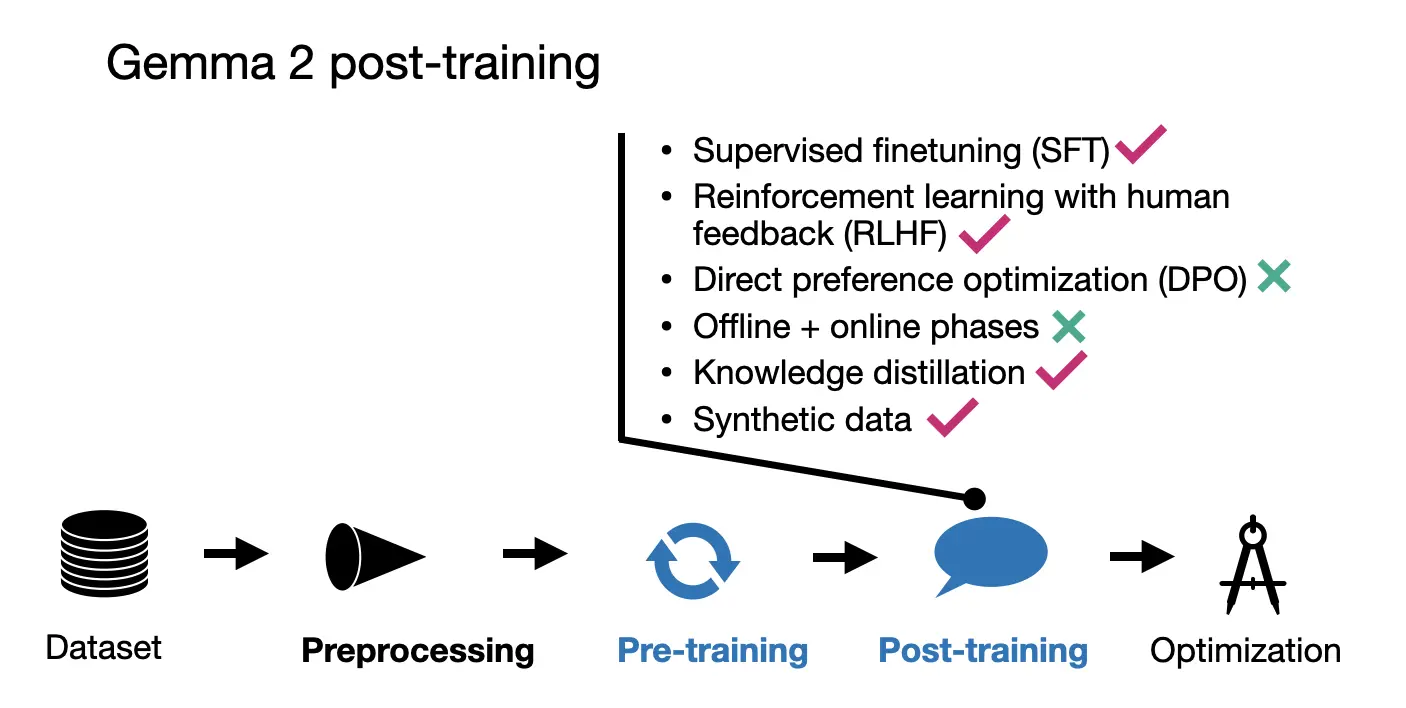
- SFT와 RLHF 단계 적용
- SFT에서도 지식 증류 적용
- RLHF에서 정책 모델보다 10배 큰 보상 모델 사용
- WARP 방식의 모델 평균화 적용
4. Meta AI의 Llama 3.1
- 모델 개요
- 8B, 70B, 405B 파라미터 모델 제공
- 128k 토큰 어휘 사용 (OpenAI의 tiktoken 토크나이저 활용)
- 사전 학습
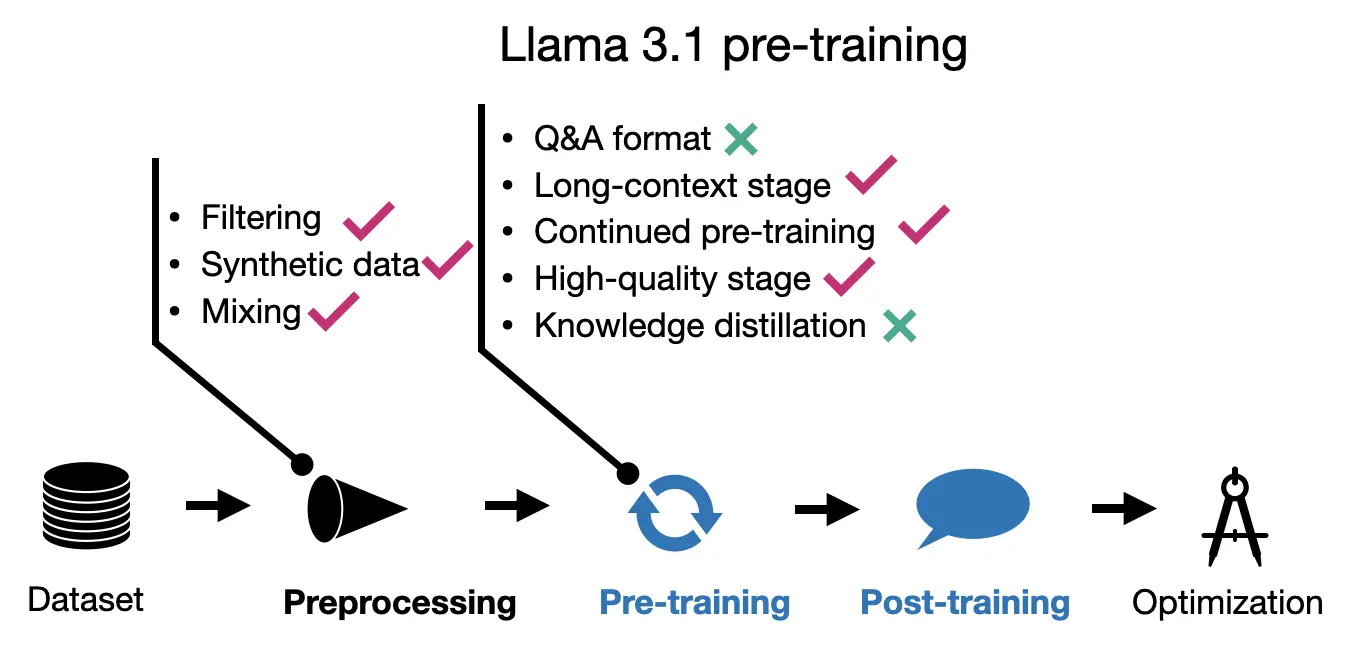
- 15.6조 토큰으로 학습 (Llama 2의 1.8조 토큰에서 대폭 증가)
- 3단계 접근:
1) 표준 사전 학습 (8k 컨텍스트 윈도우)
2) 컨텍스트 확장 (6단계에 걸쳐 8k → 128k 토큰으로 확장)
3) 고품질 데이터로 미세 조정 (40M 토큰 사용)
- 사후 학습
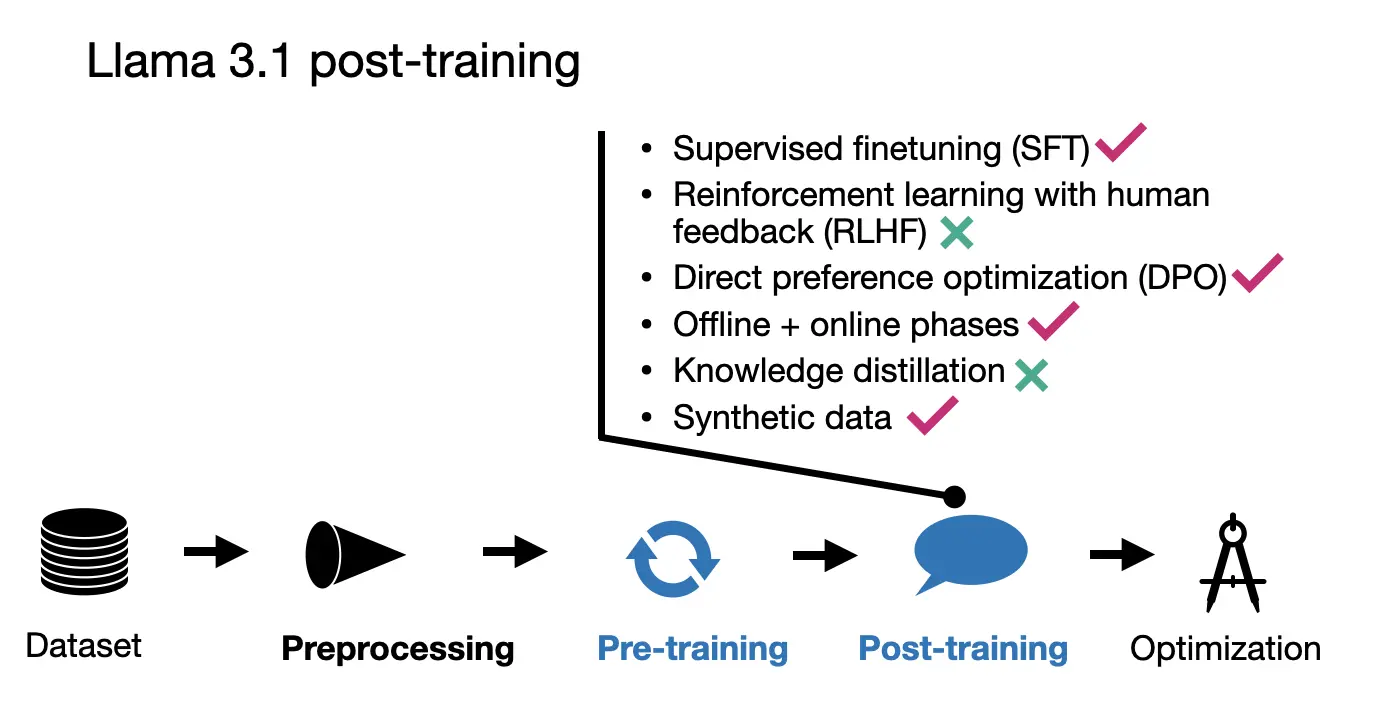
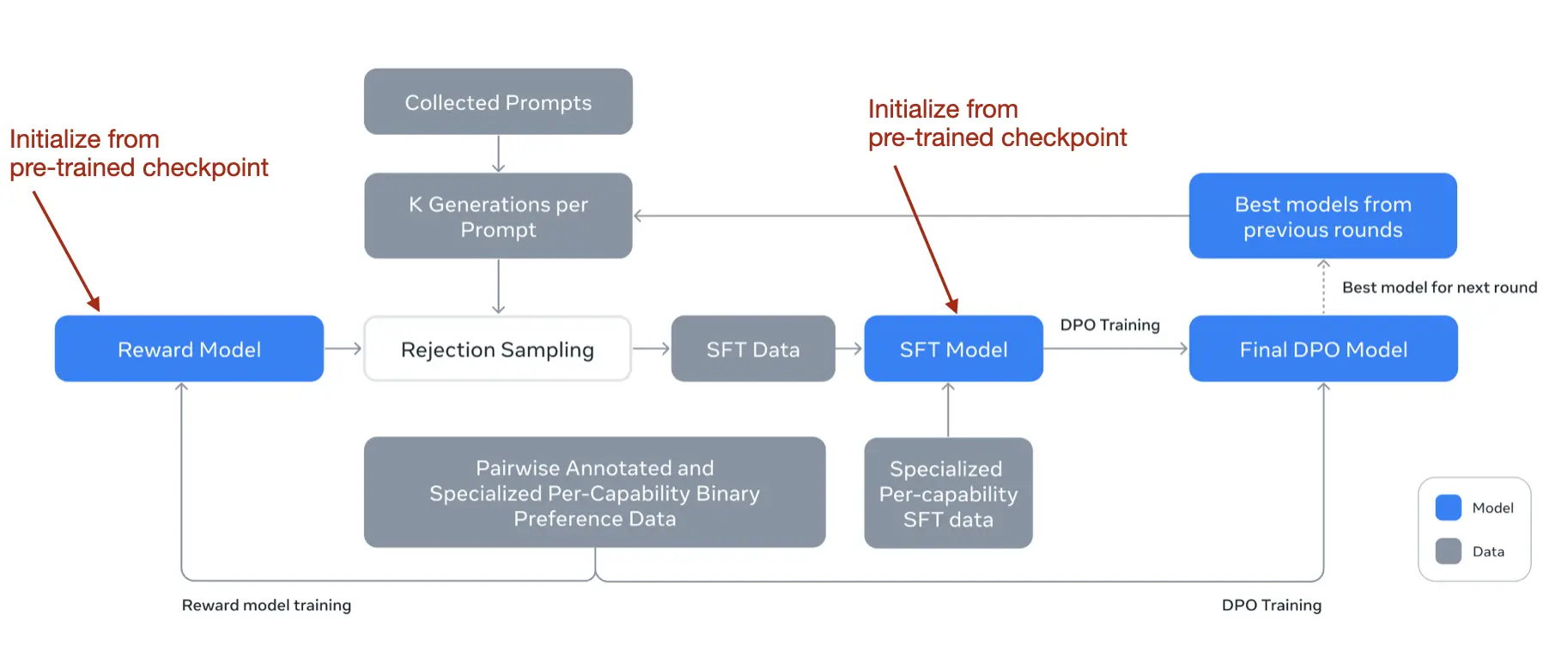
- SFT, 거부 샘플링, DPO 조합 사용
- SFT와 DPO를 여러 라운드 반복 적용
- 인간 생성 및 합성 데이터 혼합 사용
- 모든 단계(SFT, DPO, 보상 모델)에서 모델 평균화 기법 적용


Tool Use, Unified (2024.08.12, HuggingFace)
- 통합된 도구 사용 API
- Mistral, Cohere, NousResearch, Llama 등 여러 모델 패밀리에서 동일한 코드로 도구 사용 가능
- 모델 간 코드 이식성 향상
- Transformers 라이브러리의 도구 호출 지원
- 도구 호출을 쉽게 만드는 헬퍼 기능 추가
- 전체 도구 사용 프로세스에 대한 문서화 및 예제 제공
- 채팅 템플릿 확장
- 기존 채팅 템플릿 시스템을 도구 사용까지 확장
- Jinja 템플릿을 사용하여 모델별 포맷팅 처리
- 도구 정의 및 전달 방식
- JSON 스키마 또는 Python 함수로 도구 정의 가능
- Python 함수를 자동으로 JSON 스키마로 변환
- 함수 이름, 타입 힌트, 문서 문자열을 활용한 스키마 생성
- 채팅에 도구 호출 추가
- 도구 호출과 응답을 별도의 메시지로 채팅 기록에 추가
- 도구 호출은 assistant 메시지의 필드로 포함
- 도구 응답은 별도의 tool 역할 메시지로 추가
- 응답 형식의 비통일성 문제
- 모델마다 도구 호출 출력 형식이 다를 수 있음
- 사용자가 수동으로 파싱하여 통일된 형식으로 변환해야 함
- 향후 이 부분의 개선 계획 언급
- 코드 샘플
신뢰성 있는 문서를 골라주기 위한 Liner Ranker (2024.07.15, Liner)
- LLM의 환각 문제로 인해 신뢰성 저하 가능성 있음 → RAG 기술은 관련 문서를 찾아 답변을 생성하는 방식으로 문제 해결 → 라이너는 문서의 관련도를 점수화하고 리랭킹 방법 도입
- 학습 데이터셋 구축
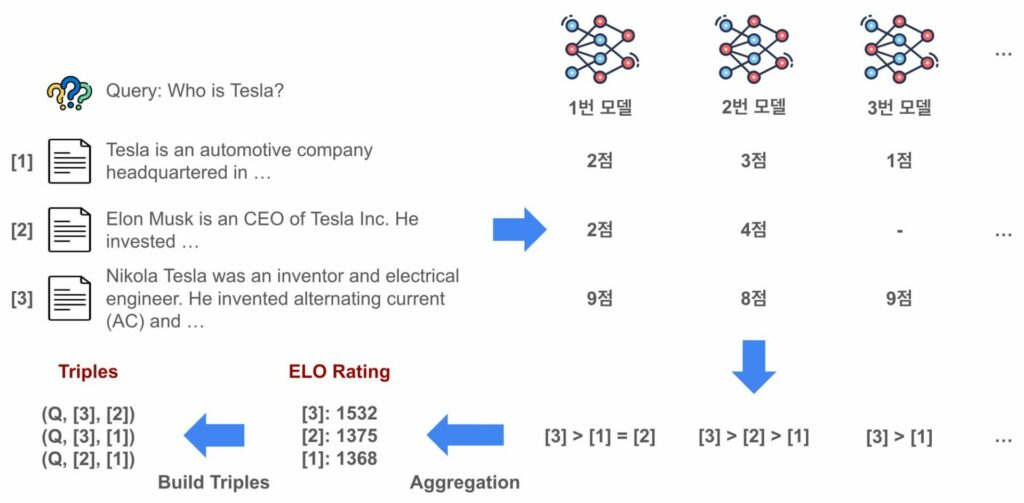
- LLM 기반의 자동-레이블링 기법을 활용하여 문서 관련도 점수 평가, 다양한 모델로 종합적으로 레이블링하여 편향 최소화 및 품질 향상
- ELO 레이팅 방식을 통해 문서의 우열관계 결정
- 랭커 모델 학습
- 메타의 LLAMA 3-8B 모델 사용
- ELO 레이팅으로부터 질문, 관련도가 높은 문서, 관련도가 낮은 문서로 구성된 트리플 데이터 구축
- 브래들리-테리 모델 적용: 양성 레이블의 문서가 음성 레이블의 문서보다 관련도가 높을 확률 계산
- 크로스 엔트로피 손실을 통해 모델 학습 진행
- 성능 향상 기법
- 적응형 마진: ELO 레이팅 차이를 기반으로 마진 값을 다르게 설정하여 성능 향상
- 레이어 별 가지치기: 상부 레이어 제거를 통해 모델의 효율성 향상
- 최종 학습 및 평가
- FSDP 적용: A100 80GB 8대의 서버에서 학습 진행
- MTEB와 BEIR 벤치마크 평가: MTEB와 BEIR 벤치마크를 통해 모델 성능 평가
Improve RAG Accuracy with Fine-Tuned Embedding Models on Amazon SageMaker (2024.07.11, AWS)
- RAG 정확도 향상을 위한 임베딩 모델 미세 조정의 필요성
- 일반적인 사전 학습 임베딩 모델의 한계점 극복
- 도메인 특화 개념과 뉘앙스를 더 정확히 표현
- Amazon SageMaker를 이용한 임베딩 모델 미세 조정 과정
- 데이터 준비
- 훈련 스크립트 작성
- 모델 훈련
- SageMaker 엔드포인트로 배포
- 사용된 기술 및 도구
- Sentence Transformers 라이브러리
- all-MiniLM-L6-v2 사전 학습 모델
- MultipleNegativesRankingLoss 손실 함수
- Amazon Bedrock FAQs 데이터셋
- 코드 구현 상세
- JSON 파일에서 훈련 데이터 로드
- DataLoader를 사용한 배치 처리
- model.fit() 메서드를 통한 미세 조정
- 미세 조정된 모델 저장
- 추론을 위한 엔드포인트 배포
- inference.py 스크립트 작성 (model_fn, predict_fn 함수 구현)
- 모델과 스크립트를 tarball로 패키징
- S3에 모델 업로드
- HuggingFaceModel 클래스를 사용한 SageMaker 엔드포인트 배포
- 성능 평가
- 코사인 유사도를 사용한 원본 모델과 미세 조정 모델 비교
- 도메인 특화 문장에서 미세 조정 모델의 우수한 성능 확인
- 기술적 고려사항
- 이폭(Epochs) 설정의 중요성 (과적합 방지)
- 토큰화, 임베딩 계산, 평균 풀링, 정규화 등의 처리 과정
- SageMaker의 IAM 역할 및 권한 설정
- 코드 샘플
LLM Evaluation Doesn't Need to be Complicated (2024.07.11)
- LLM을 평가자로 사용하는 기술적 방법
- 명확한 평가 지표 정의 (예: 3점 가산 시스템)
- 단계별 CoT 평가 프로세스 구현
- 퓨-샷 예시를 프롬프트에 포함
- JSON 등 구조화된 출력 스키마 정의
- RAG 애플리케이션 평가 구현
- AsyncOpenAI 클라이언트 사용으로 병렬 평가 수행 → 평가 데이터셋 로드 및 처리 → 평가 결과의 자동 파싱 및 지표 계산
- 기술적 한계 고려사항
- LLM의 편향 (LLM 생성 텍스트 선호 가능성), 프롬프트와 평가 기준의 유연성 제한, 평가자 LLM의 컨텍스트 윈도우 크기 제약
- 평가 시스템 최적화
- 인간이 라벨링한 퓨-샷 예시로 LLM 평가자 조정
- 반복적인 접근 방식을 통한 평가 시스템 개선
- 지속적인 데이터 모니터링 및 평가 수행
- 구현 시 고려사항
- 평가 프롬프트의 세밀한 설계, 평가 기준의 명확한 정의, 구조화된 출력 형식 사용으로 자동화 용이성 확보, 병렬 처리를 통한 평가 속도 향상

Sr. Data Scientist at AWS
1개의 댓글
Jonas Kim
2024년 9월 15일
- Under the Hood: the Tech Behind the First Agent from LinkedIn, Hiring Assistant (2024.10.29, LinkedIn)
- AlignEval: Building an App to Make Evals Easy, Fun, and Automated (2024.10.27)
- How Planview Built a Scalable AI Assistant for Portfolio and Project Management Using Amazon Bedrock (2024.10.25)
- LLM, 더 저렴하게, 더 빠르게, 더 똑똑하게 (2024.09.09, 카카오)
- Enhancing LinkedIn’s Security Posture Management with AI-Driven Insights (2024.08.20, LinkedIn)
- Data Flywheels for LLM Applications (2024.07.01)
- Your AI Product Needs Evals (2024.03.29)
- Levels of Complexity: RAG Applications (2024.02.28)
답글 달기