이 글은 컴퓨터 비전과 이미지 생성 모델에 대한 주요 블로그 포스트 내용을 지속적으로 정리하여 제공합니다.
이미지도 찰떡같이 이해하는 카카오의 멀티모달 언어모델 Kanana-v 알아보기 (2024.12.05, 카카오)
Diffusion Meets Flow Matching: Two Sides of the Same Coin (2024.12.02)
SmolVLM - Small Yet Mighty Vision Language Model (2024.11.26, HuggingFace)
Airbnb’s AI-Powered Photo Tour Using Vision Transformer (2024.11.14, Airbnb)
나만의 프로필 이미지 생성 모델 개발기 (2024.11.14, 카카오)
- 데이터셋 구성 및 전처리
- SISI(Single Identity, Single Image): 한 인물당 한 장의 이미지
- SIMI(Single Identity, Multi Image): 한 인물당 여러 장의 이미지
- 얼굴이 이미지 상단에 위치하고 적절한 신체 부분이 포함되도록 전처리
- 이미지-텍스트 페어 데이터셋 구성
- 백본 모델 개발
- HG-DPO(Direct Preference Optimization) 방법론 적용
- Pickscore와 Aesthetic score 기반 이미지 품질 평가 모델 활용
- 대규모 데이터셋으로 파인 튜닝 진행
- 인물 초상화 생성에 특화된 성능 확보
- 모델 아키텍처
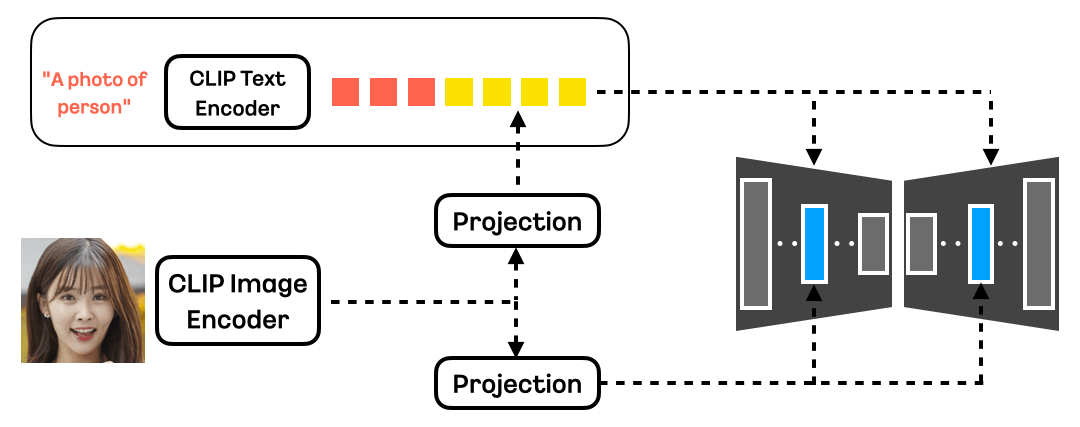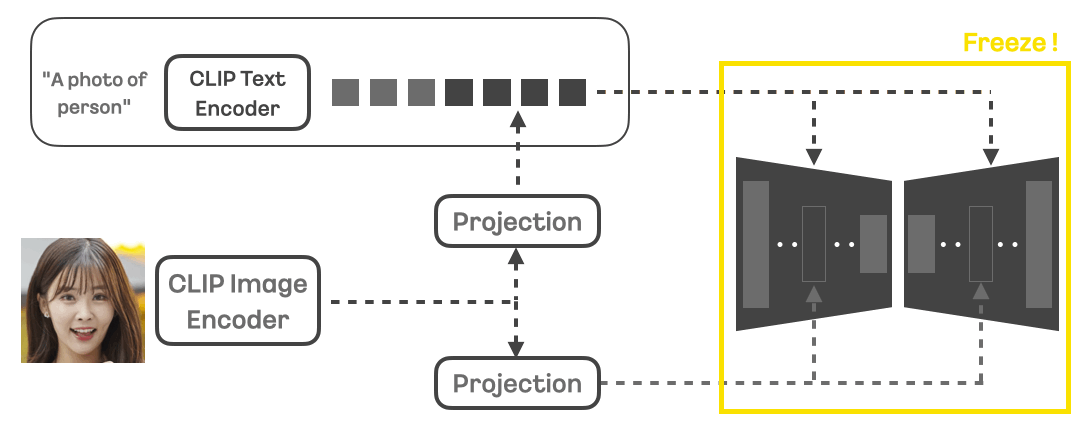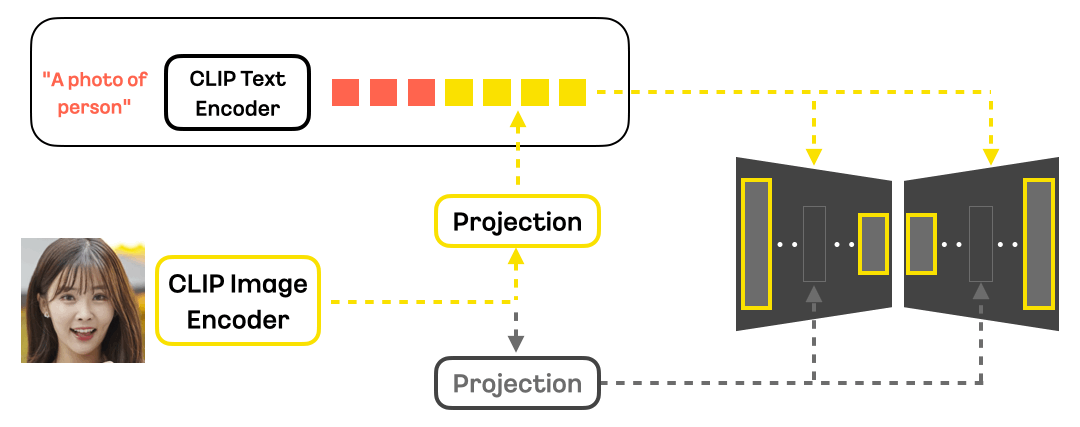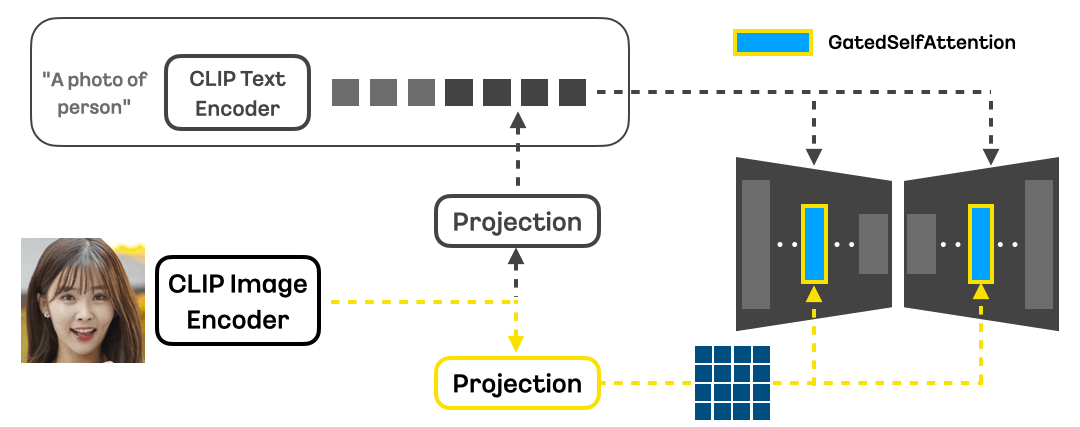
- 기본 백본 모델과 ID 모듈로 구성
- Instantbooth 연구 방법 기반으로 ID 모듈 재설계
- CLIP 이미지 인코더를 통한 얼굴 정보 추출
- 글로벌 임베딩과 패치 임베딩을 통한 2단계 특징 추출
- 새로운 어텐션 모듈을 통한 픽셀 레벨 유사도 정보 주입
- 학습 방법
- 디퓨전 손실 함수와 아이덴티티 손실 함수 동시 사용
- 수백만 장의 학습 데이터 활용
- 얼굴의 전반적 정보와 세부 정보를 분리하여 학습
- 안전성 확보
- 비가시성 워터마크 기술 적용
- 얼굴 위변조 탐지 기술 구현
- 부적절 단어 및 특정 인물 필터링 시스템 도입
- 모델 버전
- 나노(Nano): 빠른 생성 속도 최적화 버전
- 에센스(Essence): 고해상도 품질 최적화 버전
- HG-DPO 적용 여부에 따른 성능 차이 검증
- 생성 성능
- 약 30초 내외의 이미지 생성 속도
- 4가지 스타일(애니메이션, 크레파스, 클레이, 색종이) 지원
- 자연스러운 얼굴 유사도 유지
- 배경과 포즈의 실사적 표현 구현
Understanding Multimodal LLMs (2024.11.03)
- 멀티모달 LLM의 주요 두 가지 접근 방식
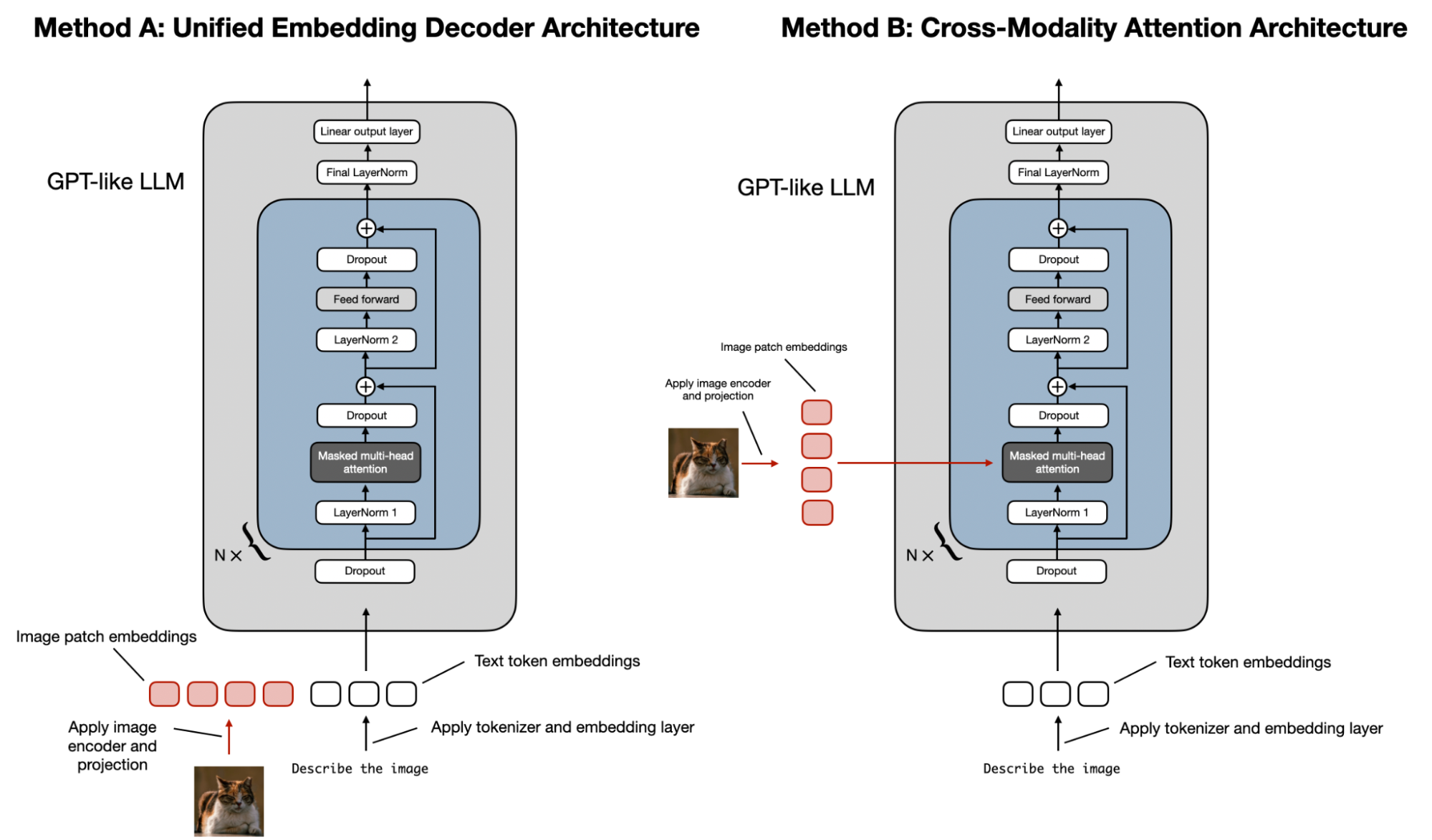
- A. 통합 임베딩 디코더 구조
- 일반 LLM 디코더 모델 사용
- 이미지를 텍스트 토큰과 동일한 크기의 임베딩으로 변환
- 텍스트와 이미지 토큰을 연결하여 처리
- 구현이 더 쉽고 단순함
- B. 크로스 모달리티 어텐션 구조
- 크로스 어텐션 메커니즘으로 이미지와 텍스트 임베딩 통합
- 입력 컨텍스트에 이미지 토큰 부담이 적음
- 원본 LLM의 텍스트 성능 유지 가능
- 계산 효율성이 더 높음
- A. 통합 임베딩 디코더 구조
- 이미지 인코딩 과정
- 이미지를 패치로 분할
- 비전 트랜스포머(ViT)로 패치 인코딩
- 선형 프로젝션으로 임베딩 차원 맞춤
- CLIP이나 OpenCLIP 같은 사전학습 모델 주로 사용
- Fuyu처럼 직접 패치 임베딩 학습하는 방식도 존재
- 학습 단계와 컴포넌트
- 이미지 인코더
- 보통 CLIP 사용
- 대부분 학습 과정에서 가중치 동결
- 프로젝터/커넥터
- 선형 레이어나 작은 MLP
- 이미지-텍스트 임베딩 차원 정렬
- 사전 훈련 시 주로 이 부분만 학습
- LLM 파트
- 사전 훈련 시 보통 가중치 동결
- 명령어 미세조정 시 동결 해제
- 이미지 인코더
- 최근 주요 모델들의 특징
- Llama 3.2: 크로스 어텐션 방식, 자체 ViT 사용
- Molmo: 디코더 방식, CLIP 사용, 통합 학습 파이프라인
- NVLM: 세 가지 방식 모두 구현하여 비교
- Qwen2-VL: 다양한 해상도 처리 가능한 "단순 동적 해상도" 도입
- Pixtral: 자체 이미지 인코더 학습
- Baichuan-Omni: 3단계 학습 프로세스 적용
- Janus: 이미지 이해와 생성을 통합한 프레임워크
CinePile 2.0 - Making Stronger Datasets with Adversarial Refinement (2024.10.23, HuggingFace)
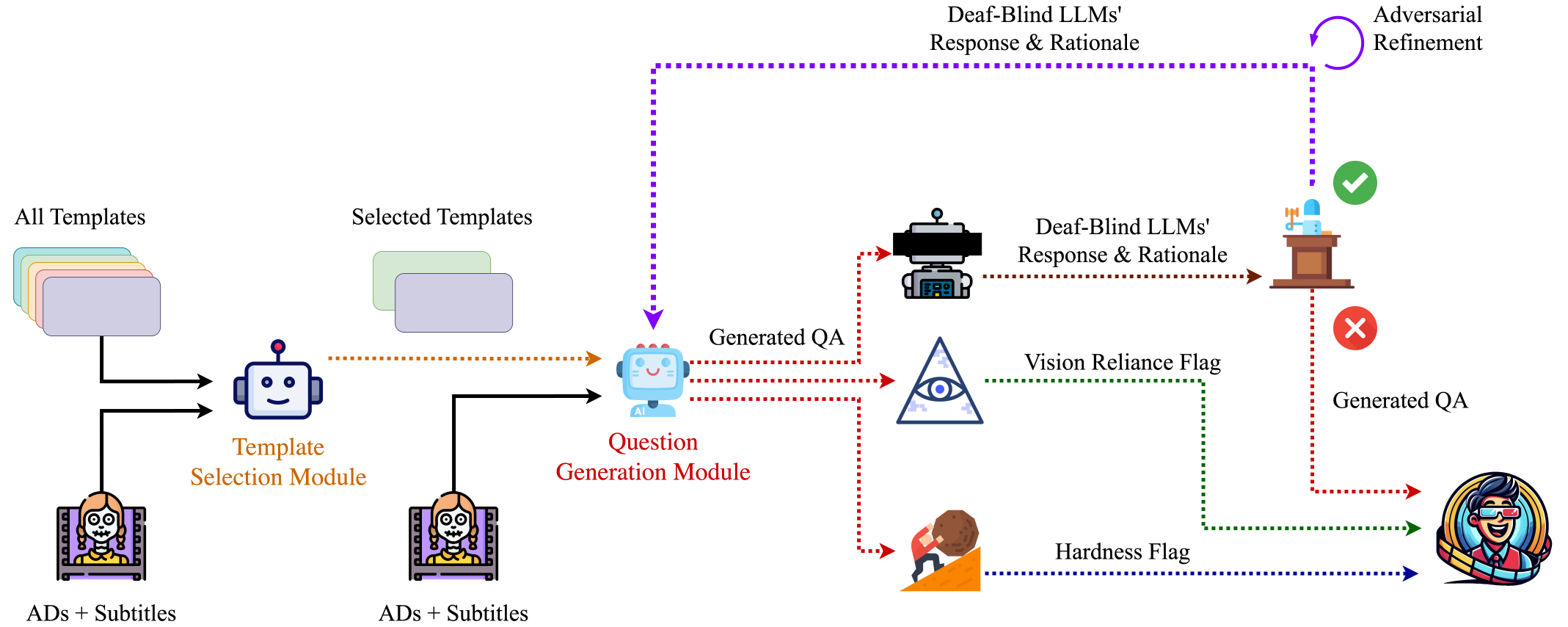
- CinePile 개요
- 긴 비디오 QA 데이터셋
- 규모
- 300,000 학습 샘플
- 5,000 테스트 샘플
- 주요 특징
- 다양한 질문 카테고리 (시간적 이해, 플롯 분석, 캐릭터 역학 등)
- 높은 난이도 (인간이 상용 비전 모델보다 25%, 오픈소스보다 65% 우수)
- 데이터셋 생성 프로세스
- 템플릿 생성
- WhereIsAI/UAE-Large-V1 모델로 텍스트 유사도 기반 클러스터링
- GPT-4를 사용한 템플릿 및 프로토타입 질문 생성
- 주요 카테고리:
- 캐릭터 및 관계 역학(CRD)
- 내러티브 및 플롯 분석(NPA)
- 설정 및 기술 분석(STA)
- 시간적 요소(TEMP)
- 주제 탐구(TH)
- 질문 생성 파이프라인
- Gemini 1.0 Pro로 적절한 템플릿 선택
- 언어 모델을 통한 장면별 질문 생성
- 타임스탬프 포함으로 환각 방지
- MCQ 디스트랙터 생성
- 비디오당 약 32개 질문 생성
- 템플릿 생성
- 적대적 개선 방법론
- 프로세스
- Deaf-Blind LLM이 질문과 답변만으로 예측
- 예측 근거 제공
- 질문-생성 모델이 암시적 단서 제거
- 5회까지 반복 수행
- 사용 모델
- Deaf-Blind LLM: LLaMA 3.1 70B
- 질문 수정: GPT-4
- 품질 관리
- 답변 순서 5가지 순열 테스트
- 3/5 이상 정답 시 퇴화로 판단
- 테스트셋 90.24%, 학습셋 90.94% 개선 달성
- 프로세스
- 성능 평가
- 상용 모델 성능
- Gemini 1.5 Pro: 최고 성능
- 설정/기술 분석 우수
- 시각 기반 질문 강점
- GPT 기반 모델
- 내러티브/플롯 분석 우수
- Gemini 1.5 Flash: 58.75% 정확도
- Gemini 1.5 Pro: 최고 성능
- 오픈소스 모델 성능
- LLaVa-One Vision: 49.34% 정확도
- 소형 모델 경쟁력
- LLaVa-OV (7B)
- MiniCPM-V 2.6 (8B)
- InternVL2 (26B) 대비 우수
- 상용 모델 성능
- 기술적 개선점
- 적대적 개선 파이프라인 공개
- 퇴화 질문 식별 코드 공개
- 하드-스플릿에서 15-20% 정확도 하락
- 지속적인 리더보드 운영
- 코드 리포지토리
Simplifying, Stabilizing, and Scaling Continuous-Time Consistency Models (2024.10.23, OpenAI)
- 모델 개요 (sCM)
- 확산 모델의 샘플링 속도 문제 해결을 위한 새로운 접근법
- 2단계 샘플링으로 최고 수준의 디퓨전 모델과 비슷한 품질 달성
- 1.5B 파라미터 규모로 ImageNet 512×512 해상도 학습
- 성능 특징
- 샘플링 속도
- 단일 A100 GPU에서 0.11초만에 샘플 생성
- 기존 대비 약 50배 빠른 월-클락 속도
- 유효 샘플링 연산량 90% 이상 감소
- 품질 평가
- FID(Fréchet Inception Distance) 스코어 사용
- 선도적인 디퓨전 모델과 비교 가능한 품질 달성
- 교사 모델 대비 10% 미만의 상대적 FID 차이
- 샘플링 속도
- 기술적 구조
- 샘플링 방식
- 기존 디퓨전 모델: 수십~수백 단계의 순차적 디노이징
- sCM: 노이즈에서 바로 노이즈 없는 샘플로 변환
- 2단계 샘플링으로 고품질 결과 생성
- 스케일링 특성
- 모델 크기 증가에 따른 비례적 성능 향상
- 교사 디퓨전 모델과의 FID 비율 일관성 유지
- 샘플링 단계 증가로 품질 격차 추가 감소
- 학습 방법
- 사전 학습된 확산 모델에서 지식 증류
- 연속 시간 일관성 모델의 안정화된 학습
- 대규모 데이터셋에 대한 확장성 개선
- 샘플링 방식
- 한계점
- 사전 학습된 디퓨전 모델 의존성
- 교사 모델과의 일관된 품질 격차 존재
- FID 메트릭의 제한적 평가 특성
- 적용 가능성
- 실시간 생성 AI 애플리케이션
- 이미지/오디오/비디오 도메인
- 시스템 최적화를 통한 추가 가속 가능성
FineVideo: Behind the Scenes (2024.09.23, HuggingFace)
- FineVideo 데이터셋 구축 과정
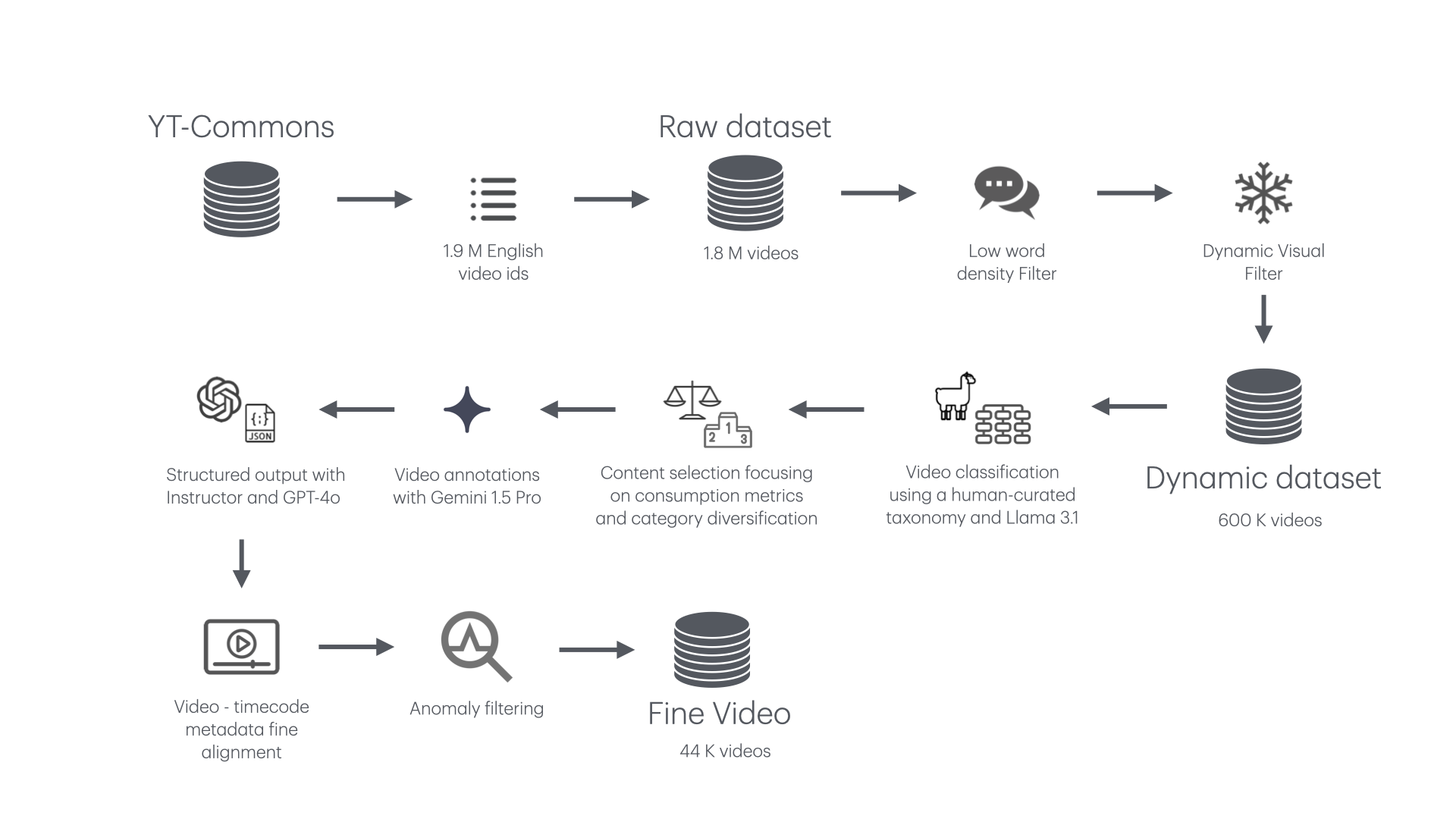
- YouTube-Commons에서 영어 컨텐츠 필터링 (1.9M 비디오)
- 메타데이터 수집 (언어, 자막, 제목, 설명 등)
- 두 가지 비디오 다운로드 방식 시도
- Video2dataset 오픈소스 프로젝트 (프록시 기능 추가)
- 클라우드 배치 작업 (Google Cloud, AWS)
- 동적 컨텐츠 선별
- 단어 밀도 필터링: 0.5 단어/초 미만 제거
- 시각적 역동성 필터링: FFMPEG의 Freezedetect 필터 활용
- 40% 이상 정적 세그먼트 포함 비디오 제거
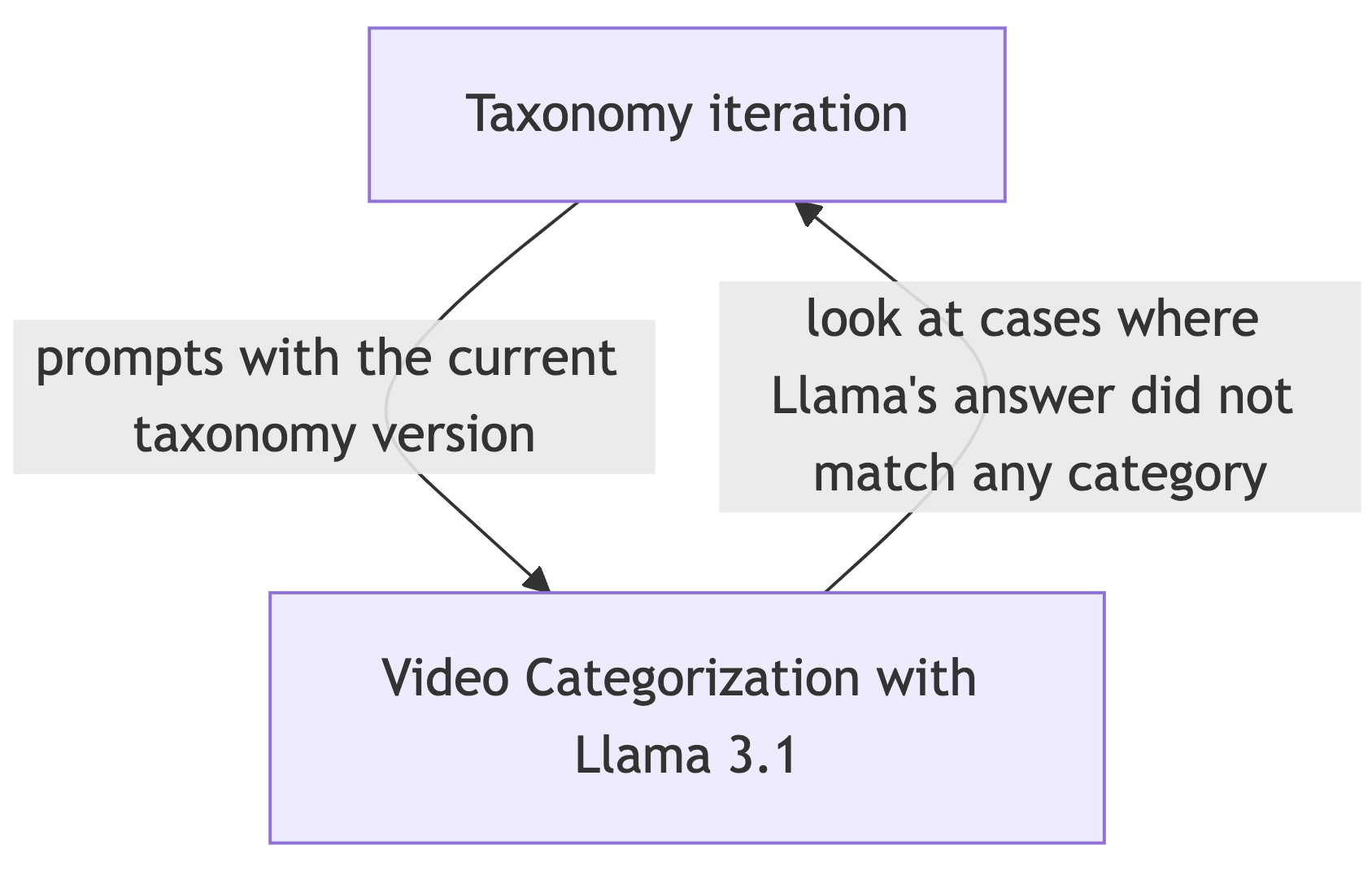
- 비디오 카테고리화
- 커스텀 분류체계 (126개 세부 카테고리) 개발
- Llama 3.1 70B 모델로 컨텐츠 주석 처리
- 분류체계와 주석 처리 간 피드백 루프 구현
- 설명 메타데이터 생성
- Gemini 1.5 Pro 활용
- 10분 이상 비디오 제외 (품질 저하 방지)
- 자유 형식 텍스트 생성 후 구조화된 출력으로 변환
- 컨텐츠 선택 알고리즘
- 카테고리 균형, 사용자 참여도, 채널 대표성 고려
- 4,000시간 목표 컨텐츠 선정
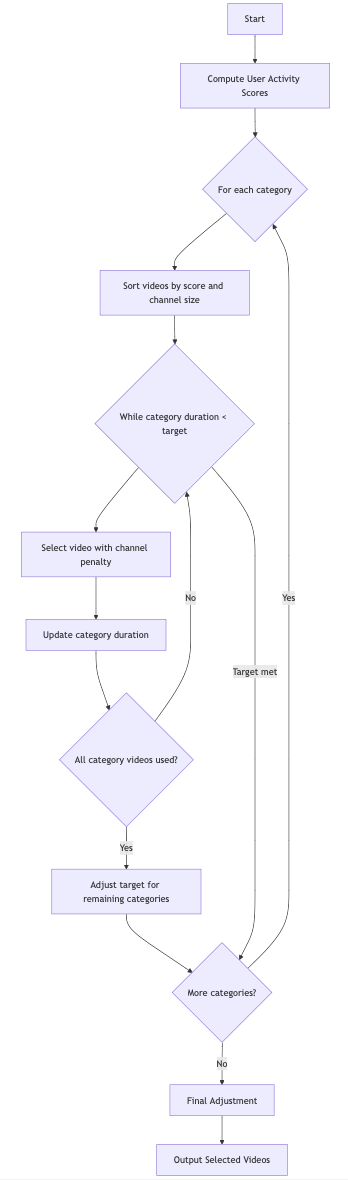
- 구조화된 데이터 생성
- Gemini 1.5 Pro로 자유 형식 텍스트 생성
- Instructor 라이브러리와 GPT-4를 사용해 구조화된 스키마로 변환
- 미세 조정 및 이상 필터링
- 시간 도메인 데이터와 비디오 정렬
- 장면 경계 정확도 확인
- 부분적으로 잘못 주석 처리된 비디오 제거 (0.5% 미만)
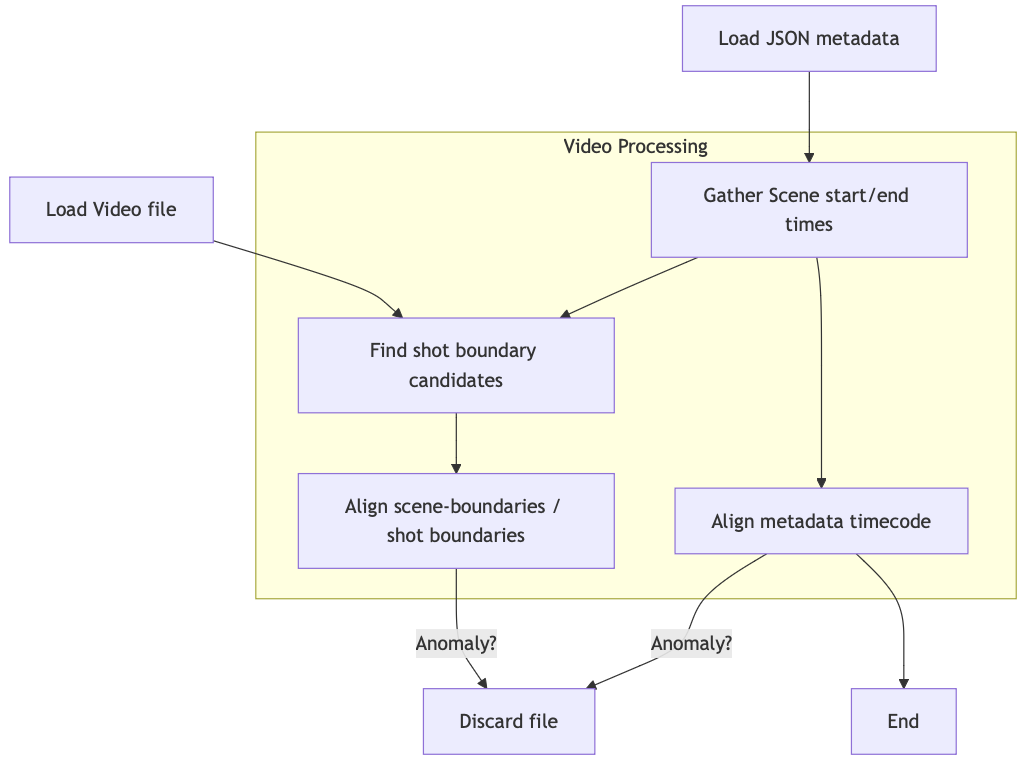
- 사용된 주요 기술/도구
- 대규모 언어 모델: Llama 3.1 70B, Gemini 1.5 Pro, GPT-4
- 비디오 처리: FFMPEG
- 클라우드 서비스: Google Cloud, AWS
- 라이브러리: Video2dataset, Instructor, Pydantic
- 서빙: Text Generation Inference (TGI)
- 코드 리포지토리
Announcing Pixtral 12B (2024.09.17, Mistral AI)
VARCO-MLLM 한국어 잘하는 멀티모달 모델 (2024.09.12, NC소프트)
- MLLM 학습 단계
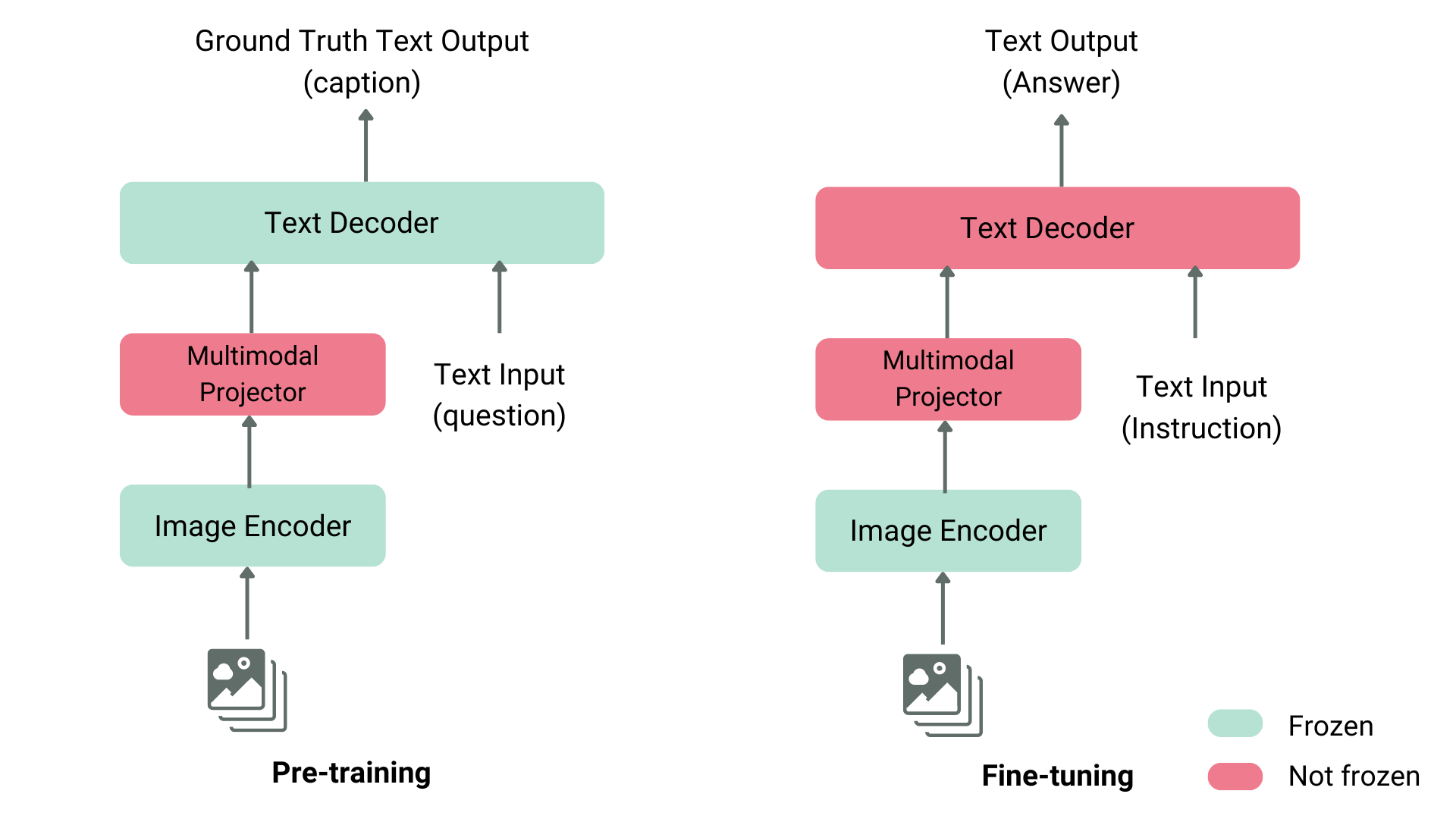
- 사전 학습 단계 (Pre-training)
- 이미지-텍스트 입력으로 텍스트 출력(캡션) 생성
- 이미지 인코더와 텍스트 디코더는 Frozen 상태
- 프로젝터만 학습됨
- 미세 조정 단계 (Fine-tuning)
- 텍스트 입력에 지시사항 포함, 출력은 그에 맞는 답변 생성
- 텍스트 디코더를 Not frozen으로 설정하여 학습
- 일부 방법론에서는 이미지 인코더도 Not frozen으로 설정
- 사전 학습 단계 (Pre-training)
- 좋은 MLLM을 만들기 위한 3가지 요소
- Data

- 균형, 다양성, 품질을 갖춘 데이터셋 필요
- 중복 제거, 데이터 균형 맞추기, 부적절한 캡션 제거, 표현 개선 등의 방법 사용
- 다양성은 모델의 제로샷 학습 능력 향상에 중요
- Grounding
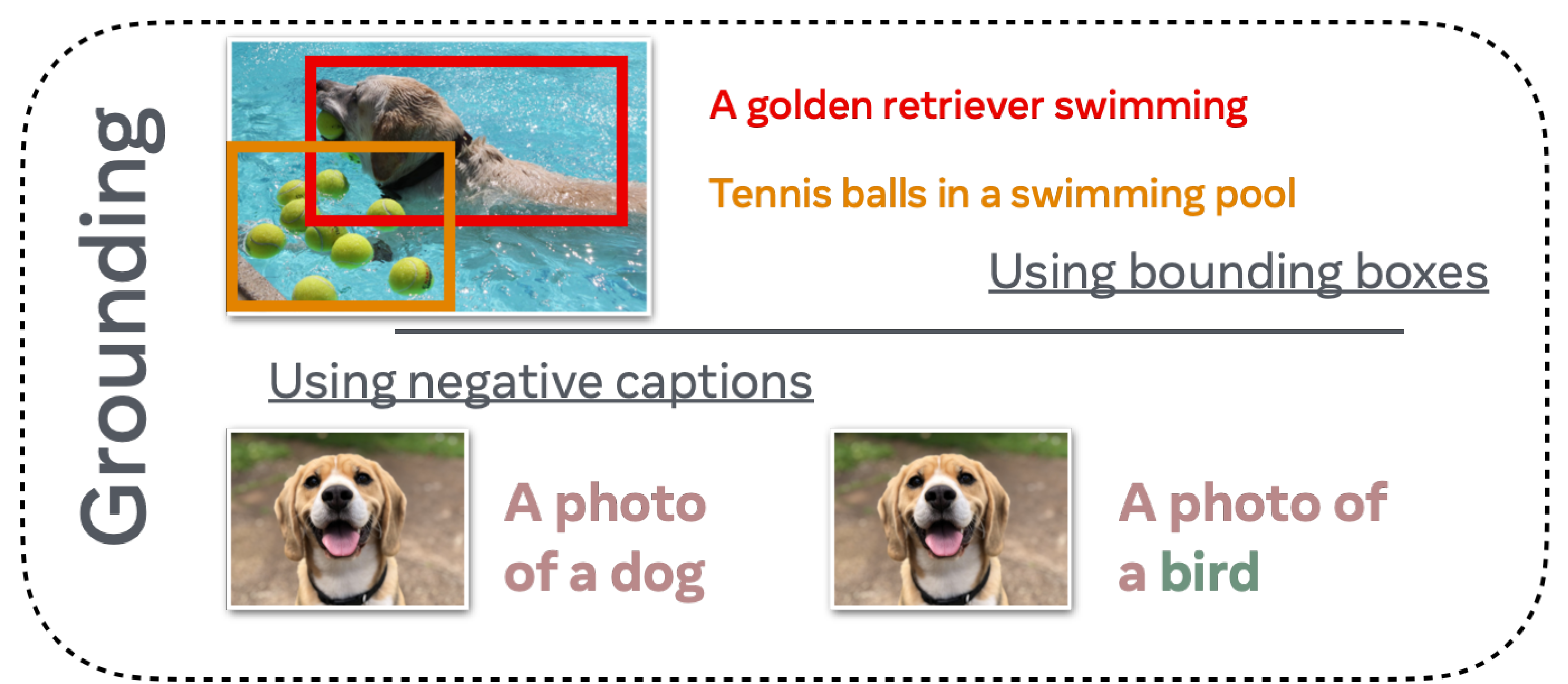
- 텍스트와 이미지 사이의 관계를 정확히 이해하고 연결하는 능력
- 이미지 내 특정 영역을 정확히 식별하고 설명할 수 있어야 함
- Alignment

- MLLM의 출력을 인간의 의도와 선호도에 맞추는 과정
- 자연스러운 대화와 상황에 맞는 적절한 응답 생성 가능
- 윤리적 문제나 안전성 문제에 대한 신중한 대응 가능
- Data
- VARCO-MLLM의 주요 특징
- 이미지 내 문자 인식 및 처리 능력
- 영어, 숫자뿐만 아니라 한글도 이해 가능
- 인식한 텍스트와 내재된 지식을 결합하여 풍부한 정보 제공
- 이미지 내 객체 위치 식별 능력
- 객체들의 BBOX 좌표값 생성 가능
- 컴퓨터 비전 태스크에 활용 가능
- 모달리티 유연성
- 텍스트-이미지 멀티모달 입력뿐만 아니라 텍스트 또는 이미지 단일 모달리티 입력도 처리 가능
- 높은 추론 능력으로 복잡한 질문에 체계적인 응답 제공
- 멀티턴 대화 처리 능력 보유
LAVE: Zero-Shot VQA Evaluation on Docmatix with LLMs - Do We Still Need Fine-Tuning? (2024.07.25, HuggingFace)
- LAVE: 제로샷 VQA 평가를 위한 새로운 지표
- LLM을 사용하여 모델의 답변 정확도를 1-3 척도로 평가, 기존 메트릭(CIDER, BLEU, ANLS)보다 OOD 설정에 더 적합
- 평가 과정
- MPLUGDocOwl1.5를 기준 모델로 사용
- Llama-2-Chat-7b로 답변 평가 수행
- 200개의 Docmatix 테스트 샘플 사용
- 주요 발견
- LAVE 메트릭 사용 시 약 50% 정확도 향상
- 기존 지표가 제로샷 평가에 과도하게 엄격할 수 있음을 시사
Docmatix - A Huge Dataset for Document Visual Question Answering (2024.07.18, HuggingFace)
- Docmatix 소개: 대규모 문서 시각적 질의응답(DocVQA) 데이터셋
- 배경: Idefics2 모델 개발 중 DocVQA 데이터셋의 한계를 극복하기 위해 생성
- 데이터셋 규모
- 240만 개의 이미지, 950만 개의 질문-답변(Q/A) 쌍
- 130만 개의 PDF 문서에서 파생
- 생성 과정
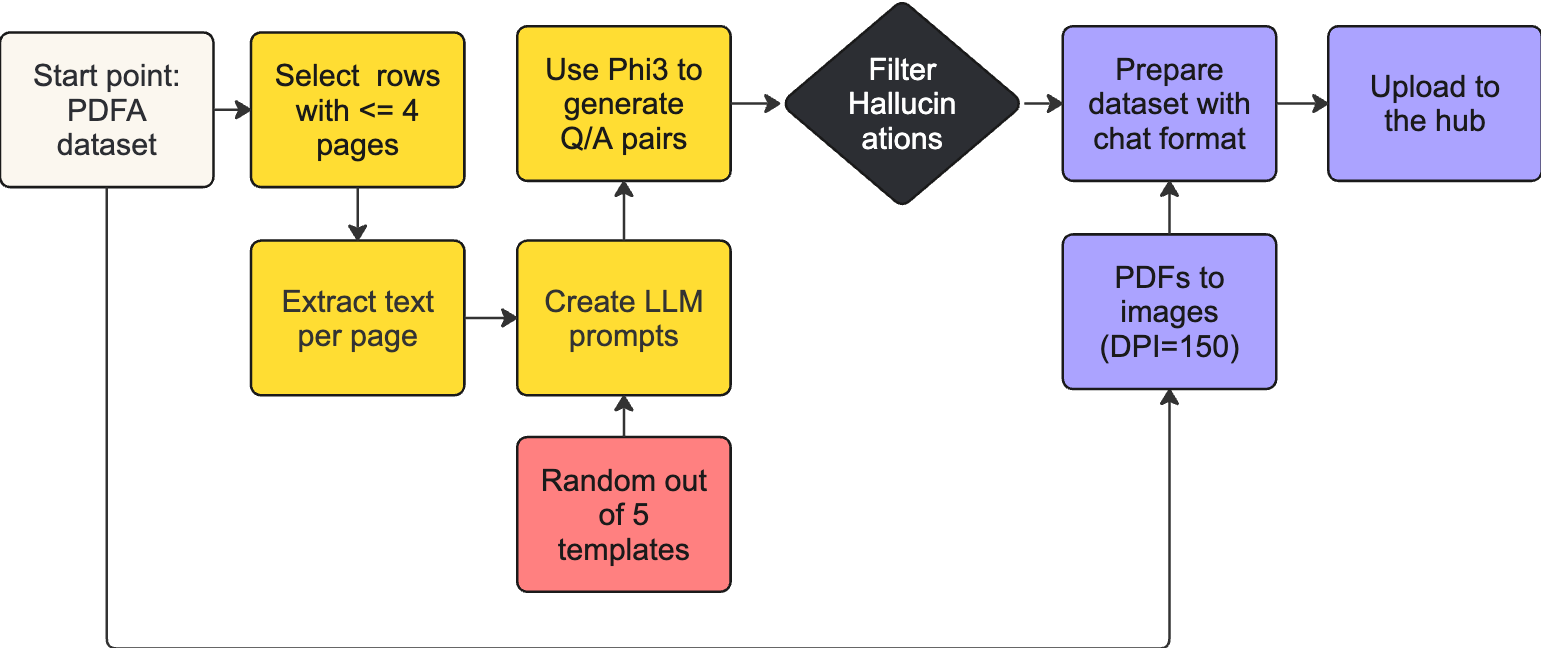
- PDFA 데이터셋의 전사 사용
- Phi-3-small 모델로 Q/A 쌍 생성
- 품질 필터링을 통해 15% 환각 Q/A 쌍 제거
- PDF를 150 dpi 해상도로 이미지 변환
- 최적화: 페이지당 약 4개의 Q/A 쌍 생성, 질문의 다양성 유지
- 성능 평가
- Docmatix에서 훈련한 모델이 성능 20% 향상
- Docmatix에서 미세 조정된 Florence-2 모델이 Idefics2 모델보다 5% 낮은 성능
Preference Optimization for Vision Language Models with TRL (2024.07.10, HuggingFace)
- RLAIF-V-Dataset(DPO 선호도 데이터셋) 준비
- 데이터 포맷팅 (이미지 크기 조정)
- GPU VRAM 필요 크기 계산: (훈련 대상 및 참조 모델 + 그래디언트 + 옵티마이저 상태값 + 활성화 값?) × 정밀도
- 메모리 최적화: 양자화(bfloat16) + LoRA + 배치 크기 조정 및 그래디언트 누적 기법 적용
- Idefics2-8b 모델 훈련 및 결과 분석(정확도, 보상 마진), 평가(AMBER 벤치마크 통한 환각 감소 측정)
- 타 모델(Llava 1.5, PaliGemma)로의 확장

Sr. Data Scientist at AWS
1개의 댓글
Jonas Kim
2024년 9월 15일
- Introducing Multimodal TextImage Augmentation for Document Images (2024.08.06, HuggingFace)
답글 달기