이 글은 ML 모델 훈련과 추론 과정에 대한 주요 블로그 포스트 내용을 지속적으로 정리하여 제공합니다.
Easily Deploy and Manage Hundreds of LoRA Adapters with SageMaker Efficient Multi-Adapter Inference (2024.11.29, AWS)
Efficiently Train Models with Large Sequence Lengths Using Amazon SageMaker Model Parallel (2024.11.27, AWS)
2:4 Sparse Llama: Smaller Models for Efficient GPU Inference (2024.11.25)
Faster Text Generation with Self-Speculative Decoding (2024.11.20, HuggingFace)
We Ran Over Half a Million Evaluations on Quantized LLMs: Here's What We Found (2024.10.17)
- 양자화의 개요
- 8비트나 4비트로 정밀도를 낮춰 연산 비용 절감
- 추론 속도 향상 가능
- 정확도와 품질 유지 여부가 주요 관심사
- 검증 방법
- 50만 건 이상의 평가 수행
- 학술 데이터셋, 실제 작업, 수동 검사 등 포함
- Llama 3.1 모델 시리즈 대상 (8B, 70B, 405B 규모)
- 양자화 방식 3가지
- W8A8-INT
- 가중치와 활성화를 8비트 정수로 변환
- 엔비디아 A100 GPU 등 서버용
- 모델 크기 2배 압축, 1.8배 성능 향상
- W8A8-FP
- 8비트 부동소수점 방식 사용
- 최신 엔비디아 H100 GPU 지원
- 모델 크기 2배 압축, 1.8배 성능 향상
- W4A16-INT
- 가중치는 4비트 정수, 활성화는 16비트 유지
- 응답 시간이 중요한 경우에 적합
- 모델 크기 3.5배 압축, 2.4배 성능 향상
- W8A8-INT
- 평가 체계
- 학술 벤치마크
- OpenLLM 리더보드 v1, v2
- 질의응답, 추론 등 구조화된 작업 평가
- 실제 환경 벤치마크
- ArenaHard, HumanEval 등
- 실제 사용 환경과 유사한 시나리오 테스트
- 텍스트 유사도 평가
- ROUGE, BERTScore, STS 등 메트릭 활용
- 원본과 양자화 모델 출력 비교
- 학술 벤치마크
- 주요 연구 결과
- 학술 벤치마크
- 모든 양자화 방식에서 99% 이상 정확도 유지
- v2에서는 최소 96% 이상 성능 유지
- 실제 환경 테스트
- 채팅, 코딩 등에서 원본과 유사한 성능
- 큰 모델(70B, 405B)에서 특히 우수한 결과
- 텍스트 유사도
- 큰 모델에서 높은 텍스트 유사도 유지
- 작은 모델(8B)도 의미적 일관성 유지
- 학술 벤치마크
- 결론
- 양자화된 모델이 원본과 비슷한 정확도 유지
- 계산 비용과 추론 속도에서 큰 이점
- LLM 실제 배포에 필수적인 최적화 도구로 평가
Efficient Pre-Training of Llama 3-Like Model Architectures Using torchtitan on Amazon SageMaker (2024.10.08, AWS)
- 목적
- torchtitan 라이브러리를 사용하여 Meta Llama 3 유사 모델 구조의 사전 학습 가속화
- Amazon SageMaker에서 torchtitan을 활용한 효율적인 사전 학습 방법 소개
- torchtitan의 주요 특징
- FSDP2 (Fully Sharded Data Parallel 2) 지원
- torch.compile 통합
- FP8 (8비트 부동소수점) 연산 지원
- 텐서 병렬 처리
- 선택적 레이어 및 연산자 활성화 체크포인팅
- 분산 체크포인팅
- 주요 최적화 기술
- FSDP1에서 FSDP2로 전환: 더 유연하고 효율적인 매개변수 처리
- torch.compile 지원: JIT 컴파일을 통한 성능 향상
- FP8 선형 연산: 메모리 사용량 감소 및 성능 향상
- FP8 all-gather: 효율적인 다중 GPU 통신
- Amazon SageMaker를 활용한 사전 학습 과정
- 사용자 정의 이미지 준비 (torchtitan 포함)
- 학습 작업 설정 (p5.48xlarge 인스턴스 사용)
- c4 데이터셋을 사용한 Meta Llama 3 8B 모델 사전 학습
- 성능 결과
- 기준 대비 38.23% 성능 향상 달성
- torch.compile: 10.67% 속도 향상
- FP8 선형 연산: 33.19% 속도 향상
- FP8 all-gather: 38.23% 속도 향상
- 모든 최적화 단계에서 모델 정확도 유지
- 주요 이점
- 사전 학습 과정 간소화
- 분산 학습 설정 용이
- TensorBoard를 통한 실시간 모니터링
- 사용자 정의 컨테이너 지원
- 코드 샘플
Scalable Training Platform with Amazon SageMaker HyperPod for Innovation: a Video Generation Case Study (2024.09.26, AWS)
- Amazon SageMaker HyperPod 소개
- 대규모 훈련을 위한 목적 설계된 인프라
- 기초 모델(FM) 훈련을 위한 ML 인프라 구축 및 최적화의 부담 제거
- Slurm을 통한 사용자 지정 가능한 인터페이스 제공
- 원하는 인스턴스 유형과 수로 클러스터 프로비저닝 가능
- 워크로드 간 클러스터 유지 가능
- 비디오 생성 알고리즘의 복잡성
- 확산 모델 기반 접근법 사용
- 시간적 차원 추가로 인한 계산 요구사항 증가
- 반복적 노이즈 제거 프로세스
- 증가된 파라미터 수
- 고해상도 및 긴 시퀀스 처리 필요
- AnimateAnyone 알고리즘 아키텍처
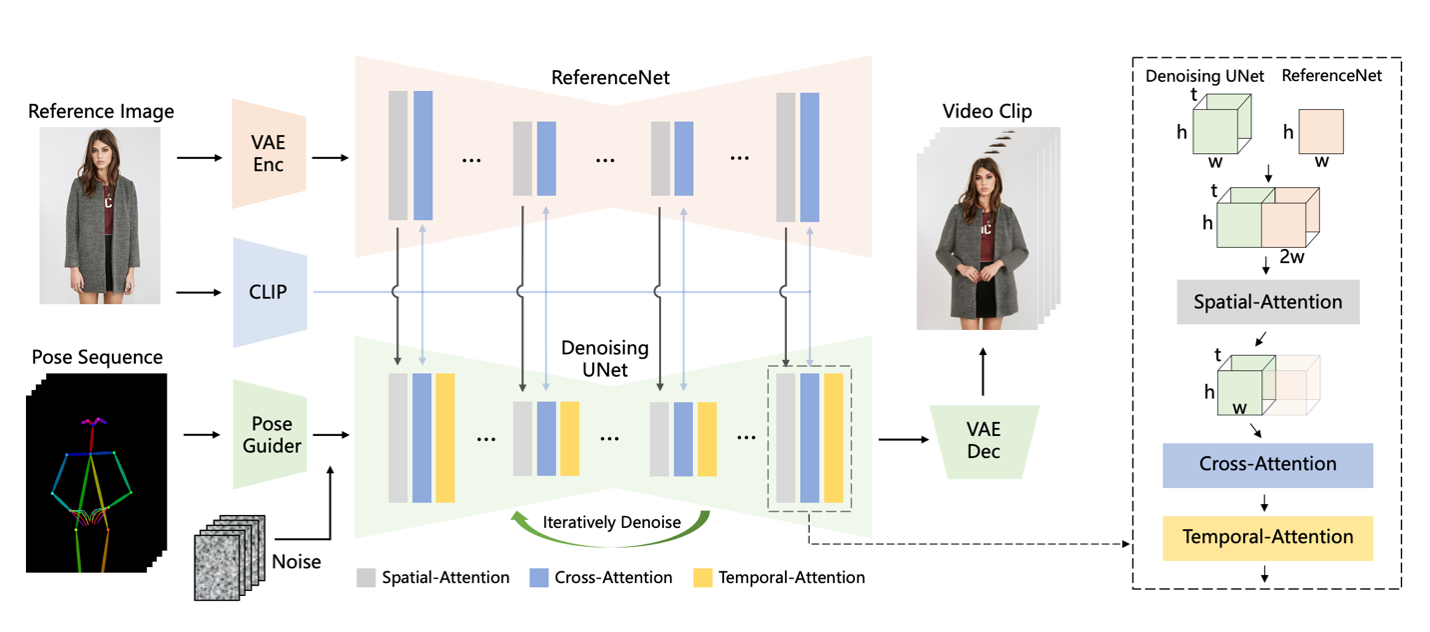
- ReferenceNet: 참조 이미지의 공간적 세부 사항 캡처
- Pose Guider: 포즈 제어 신호 통합
- Temporal Layer: 다중 프레임 관계 모델링
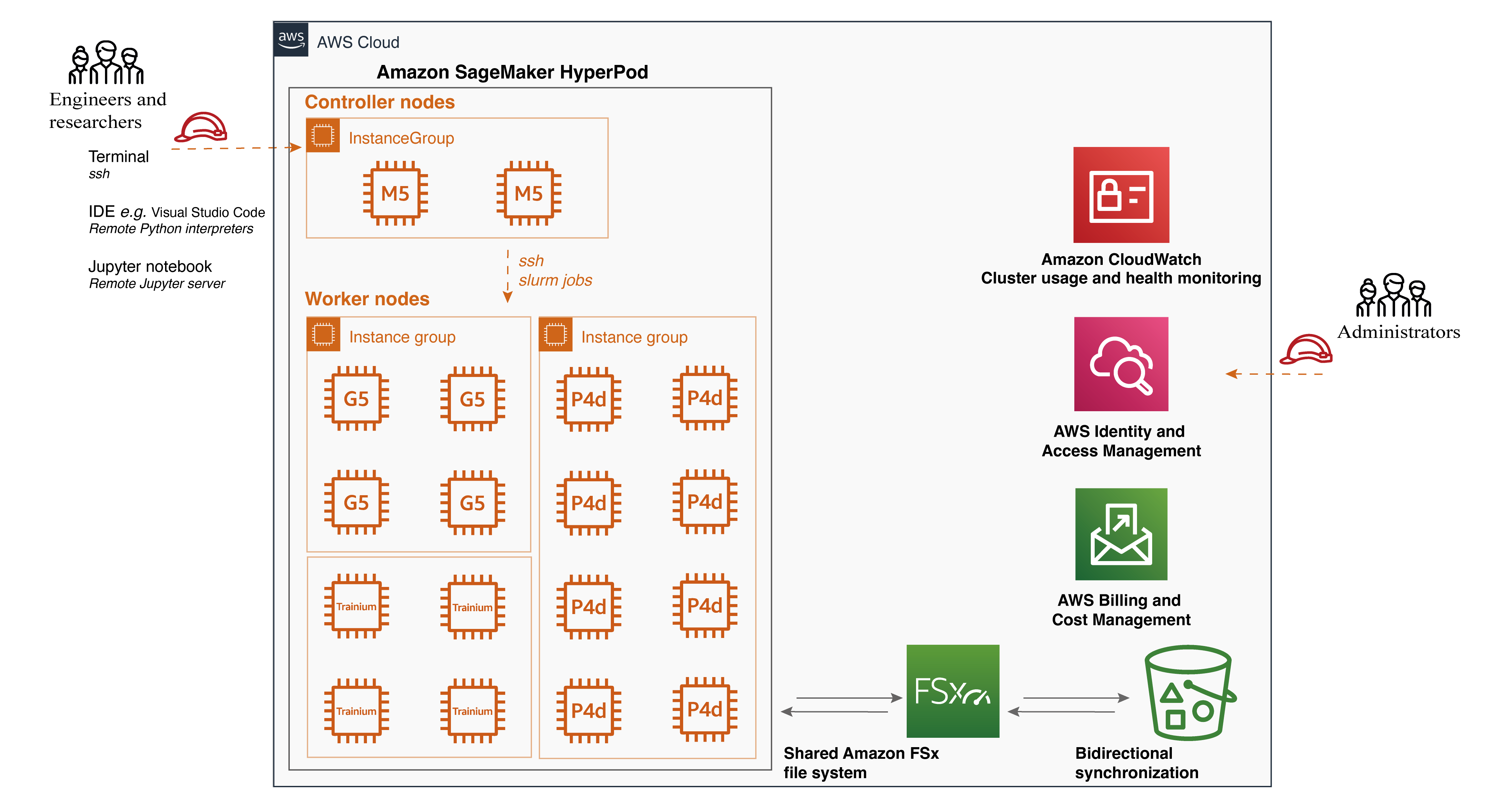
- SageMaker HyperPod 주요 기능
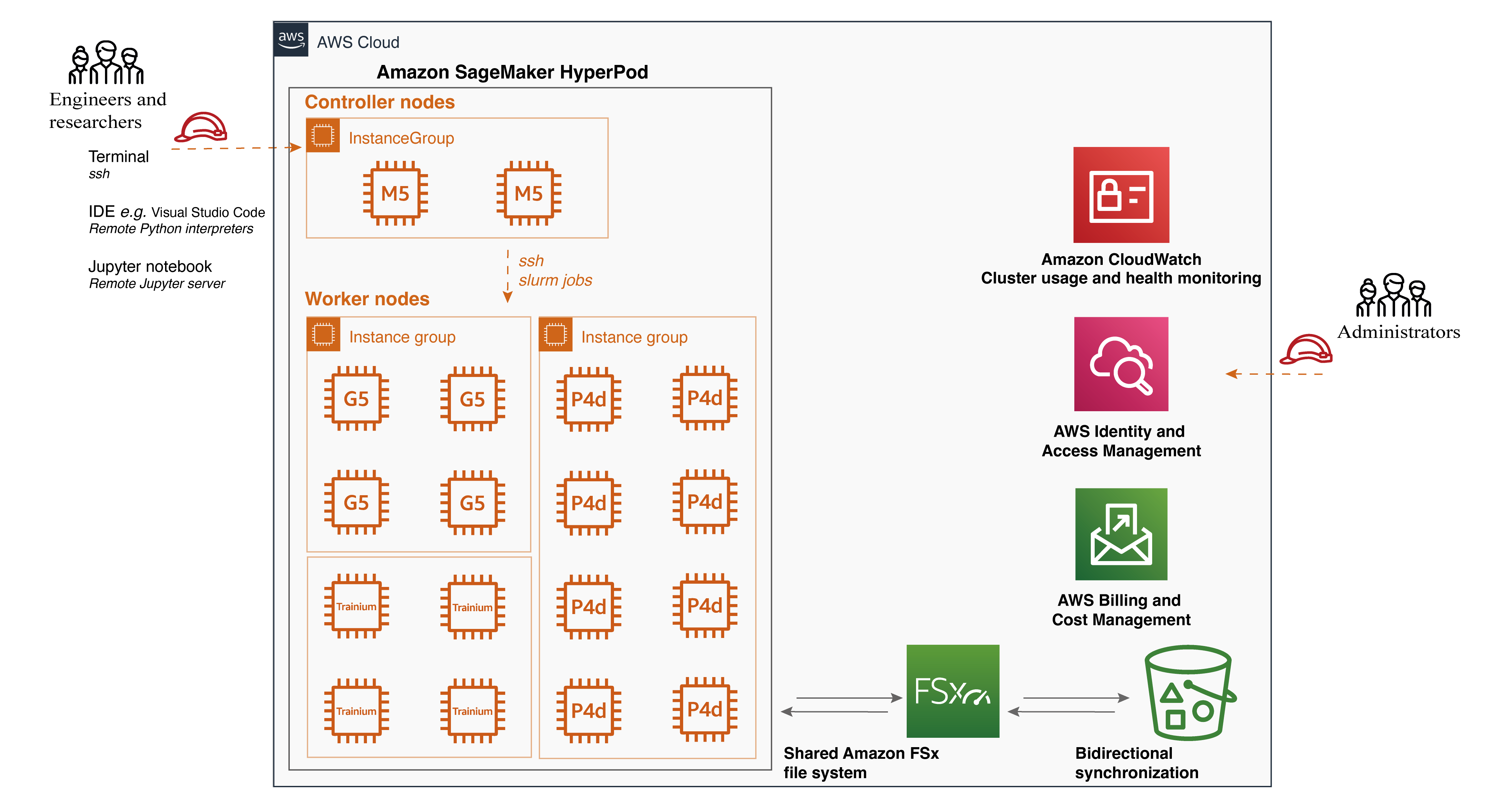
- 분산 훈련을 위한 목적 설계된 인프라
- Amazon FSx for Lustre와 같은 공유 파일 시스템 지원
- 라이프사이클 스크립트를 통한 사용자 지정 환경 구성
- Slurm 통합을 통한 작업 분배
- Visual Studio Code를 통한 SSH 연결 지원
- 클러스터 설정 및 알고리즘 실행
- provisioning_parameters.json 및 cluster-config.json 파일 준비
- Amazon FSx와 Amazon S3 간 양방향 동기화 설정
- conda 환경 생성 및 필요 라이브러리 설치
- AnimateAnyone 훈련 단계 (Stage 1 및 Stage 2) 실행
- Slurm을 통한 작업 스케줄링
- 다중 노드 GPU 설정으로 확장
- DeepSpeed 라이브러리 활용
- ZeRO (Zero Redundancy Optimizer) 최적화 기술 소개
- ZeRO Stage 1, 2, 3 설명
- Accelerate 라이브러리 활용
- 다양한 분산 구성에서 동일한 PyTorch 코드 실행 지원
- DeepSpeed와의 쉬운 통합
- DeepSpeed 라이브러리 활용
- 단일 노드 다중 GPU 및 다중 노드 다중 GPU 작업 실행 방법
- 클러스터 사용 모니터링
- Amazon Managed Service for Prometheus 및 Amazon Managed Grafana 통합
- 메트릭 내보내기 및 시각화
- 추론 및 배포 옵션
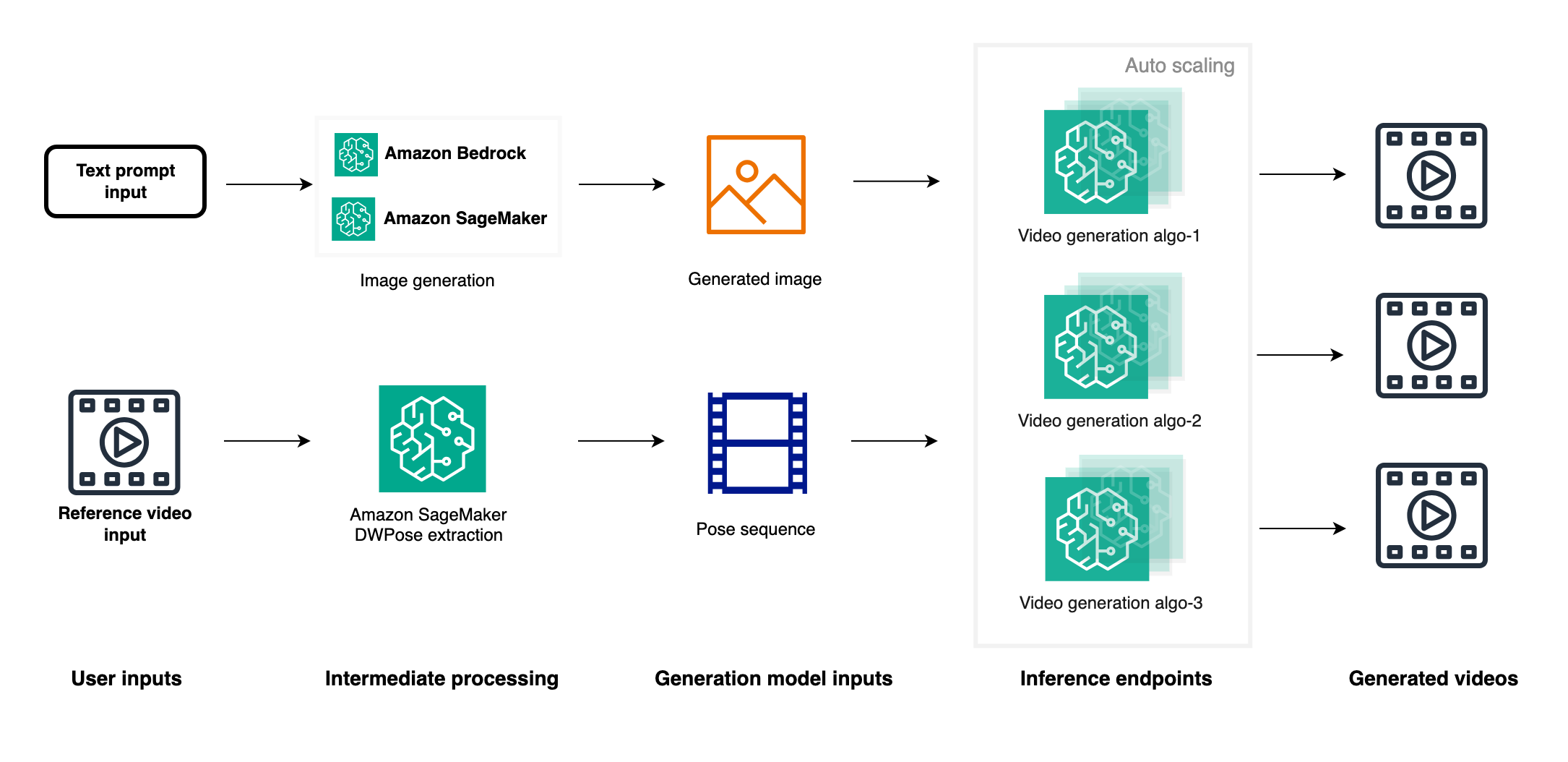
- ComfyUI와 같은 GUI 도구 사용
- Amazon SageMaker를 통한 추론 엔드포인트 배포
- 이미지 생성 API와 비디오 생성 엔드포인트 통합
- 자동 스케일링 및 병렬 비디오 생성 가능
- 최근 비디오 생성 연구 발전
- 코드 샘플, 워크샵
Fine-Tune Meta Llama 3.1 Models Using torchtune on Amazon SageMaker (2024.09.19, AWS)
Accelerate Pre-Training of Mistral’s Mathstral Model with Highly Resilient Clusters on Amazon SageMaker HyperPod (2024.09.18, AWS)
Fine-Tuning LLMs to 1.58bit: Extreme Quantization Made Easy (2024.09.18, HuggingFace)
Scaling Thomson Reuters’ Language Model Research with Amazon SageMaker HyperPod (2024.09.12, AWS)
파인 튜닝을 위한 LoRA의 강력한 대안, DoRA 살펴보기 (2024.08.28, Nvidia)
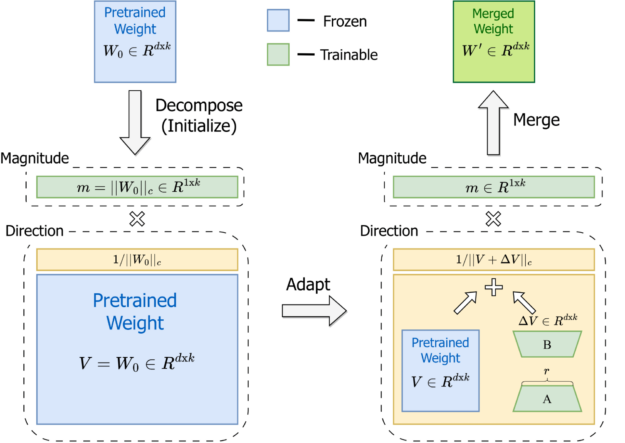
- DoRA의 기본 원리
- 사전 학습된 가중치를 크기와 방향 성분으로 분해
- 두 성분을 모두 파인 튜닝
- 방향 적응을 위해 LoRA 활용하여 효율적인 파인 튜닝 구현
- 추론 전 사전 학습된 가중치와 병합 가능, 추가 지연 시간 방지
- 학습 패턴 분석
- DoRA와 FT(전체 파인 튜닝)의 가중치 업데이트 패턴이 유사
- LoRA와 달리, 크기 변화 최소화 또는 방향 조정 극대화 가능
- 이러한 특성으로 인해 LoRA보다 우수한 학습 능력 보유
- 다양한 모델 및 태스크에 적용: LLM, VLM, 압축 인식 LLM (QDoRA), 텍스트-이미지 생성 (DreamBooth)
- 기술적 장점
- LoRA 및 변형과 호환 가능
- 추론 시 추가 오버헤드 없음 (사전 학습된 가중치와 병합 가능)
- 다양한 파인 튜닝 작업과 모델 아키텍처에 적용 가능
TensorRT-LLM 및 vLLM을 활용한 sLLM 추론 최적화 (2024.08.14, NC소프트)
- TensorRT-LLM과 vLLM을 활용한 sLLM(작은 규모 언어 모델) 추론 최적화 기법 소개
- 인-플라이트 배칭 (TensorRT-LLM과 vLLM 모두 지원)
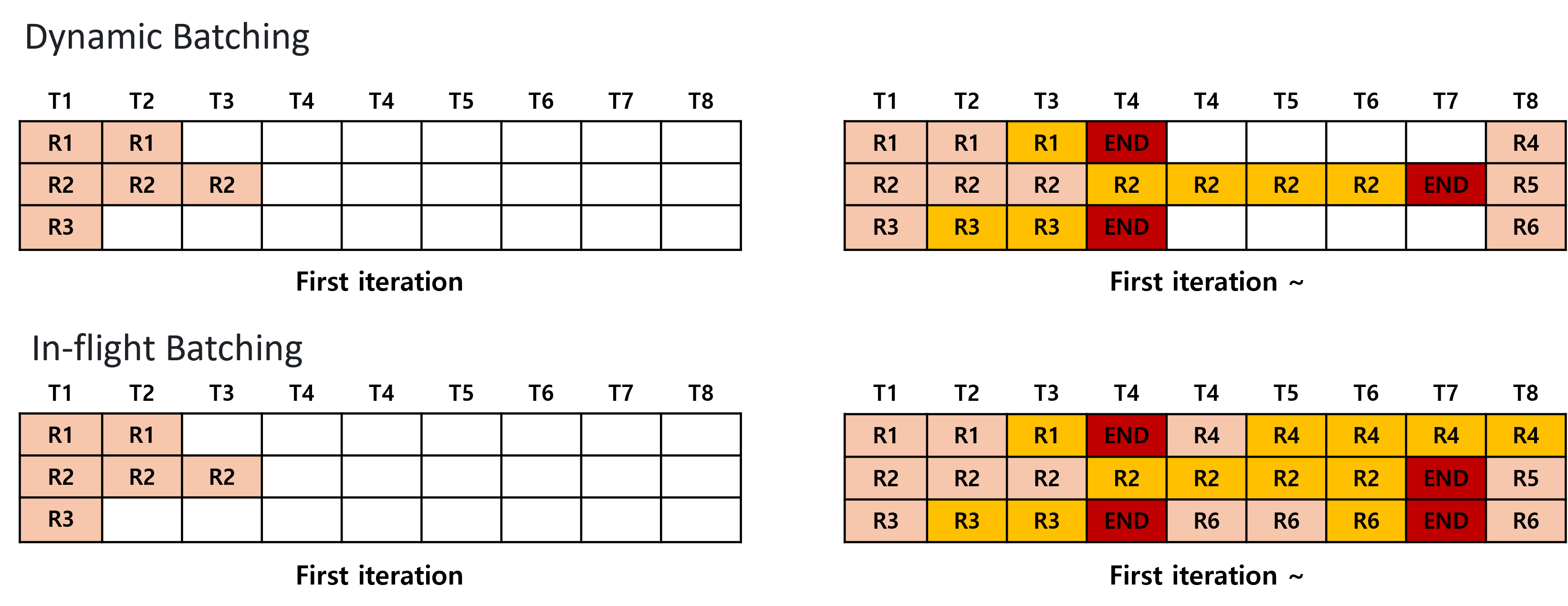
- 요청 단위가 아닌 반복 단위로 배치 처리
- 다이나믹 배칭에 비해 레이턴시 감소 및 GPU 활용도 향상
- 페이지드 어텐션 (TensorRT-LLM과 vLLM 모두 지원)
- KV 캐시를 작은 블록 단위로 나누어 비연속적 메모리 공간에 저장
- 메모리 사용 효율화로 더 큰 배치 크기 처리 가능
- TensorRT-LLM vs vLLM 성능 비교
- 낮은 트래픽에서는 비슷한 성능 → 높은 트래픽에서 TensorRT-LLM이 더 나은 레이턴시 성능 보임
- 모델 양자화 기법
- AWQ (Activation-aware Weight Quantization)
- 가중치만 양자화, 중요 채널 보호
- INT4 지원, 정확도 저하 거의 없음
- SmoothQuant
- 가중치와 활성화 값 모두 양자화
- INT8 지원, AWQ보다 큰 정확도 저하 발생
- INT8 KV 캐시
- 추가 정확도 저하 발생, 상황에 따라 성능 개선 또는 저하
- AWQ (Activation-aware Weight Quantization)
- 양자화 성능 테스트 결과
- 모델 크기 감소로 더 큰 배치 처리 가능
- 낮은 트래픽: AWQ가 더 낮은 레이턴시
- 높은 트래픽: SmoothQuant가 더 낮은 레이턴시
- SmoothQuant가 더 높은 TPS 달성
- 양자화 품질 테스트 결과
- AWQ: 정확도 저하 거의 없음
- SmoothQuant: 5% 정도의 정확도 저하 발생
- INT8 KV 캐시 사용 시 추가 정확도 저하
- 선택 고려사항
- vLLM: 다양한 환경 지원, 사용 간편
- TensorRT-LLM: NVIDIA GPU에 최적화, 더 나은 성능
- 양자화 기법: 정확도와 성능 요구사항에 따라 선택 필요
FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention (2024.08.07)

Sr. Data Scientist at AWS