MLOps
Behind the Platform: the Journey to Create the LinkedIn GenAI Application Tech Stack (2024.11.26, LinkedIn)
Automation Platform v2: Improving Conversational AI at Airbnb (2024.10.30, Airbnb)
- 기존 v1의 한계점
- 사전 정의된 워크플로우로 인한 유연성 부족
- 수동 워크플로우 생성으로 인한 확장성 문제
- 시간 소모적이고 오류 발생 가능성 높음
- v2 주요 아키텍처 구성
- LLM 워크플로우 처리 과정
- 사용자 질의 수신
- 컨텍스트 정보 수집 (채팅 기록, 사용자 ID 등)
- 프롬프트 조립 및 LLM 전송
- 도구 실행 및 서비스 호출
- 결과 반환 및 대화 기록
- 생각의 사슬(Chain of Thought) 워크플로우
- 주요 구성요소
- CoT IO 핸들러: 프롬프트 조립, 데이터 처리
- 도구 관리자: 실행 관리, 재시도, 속도 제한
- LLM 어댑터: 다양한 LLM 통합 지원
- 프로세스
- 컨텍스트 준비
- 논리적 추론 루프 실행
- 도구 실행 및 결과 처리
- 주요 구성요소
- 컨텍스트 관리
- 정적/동적 컨텍스트 선언 지원
- 주요 구성요소
- 컨텍스트 로더: 다양한 소스에서 정보 수집
- 런타임 컨텍스트 관리자: 실시간 컨텍스트 관리
- 가드레일 프레임워크
- 목적: LLM 출력 모니터링 및 안전성 보장
- 특징
- 병렬 실행 가능
- 다양한 기술 스택 활용
- 콘텐츠 모더레이션
- 도구 실행 제한
- LLM 워크플로우 처리 과정
- 추가 기능
- 플레이그라운드: 프롬프트 반복 테스트
- LLM 중심 모니터링: 지연시간, 토큰 사용량 추적
- 도구 관리 기능: 등록, 배포, 실행, 모니터링
- 장점
- 전통적 워크플로우와 LLM 결합
- 자연스러운 대화 경험 제공
- 유연한 쿼리 해석 능력
- 개발자 도구와의 원활한 통합
- 향후 계획
- 다양한 AI 에이전트 프레임워크 탐색
- 생각의 사슬 도구 기능 확장
- LLM 애플리케이션 시뮬레이션 연구
Accelerating Coupang’s AI Journey with LLMs (2024.10.15, Coupang)
- ML 모델 유형
- 추천 시스템 모델: 메인 피드, 검색, 광고에서 사용
- 사용자 상호작용 데이터 활용 (클릭, 조회, 구매, 장바구니)
- 사람이 레이블링한 관련성 판단 데이터 사용
- 콘텐츠 이해 모델
- 상품 카탈로그 데이터 (텍스트, 이미지) 처리
- 사용자 생성 콘텐츠 (리뷰, 검색어) 분석
- 사용자/판매자 데이터 활용
- 예측 모델
- 100+ 물류센터 운영을 위한 예측
- 가격책정, 물류, 배송 최적화
- 통계 기반에서 딥러닝으로 진화 중
- 추천 시스템 모델: 메인 피드, 검색, 광고에서 사용
- LLM 주요 응용 분야
- 이미지 & 언어 이해
- 비전-언어 트랜스포머 모델로 통합 임베딩 생성
- 한국어-대만어 상품명 번역
- 이미지 품질 개선
- 리뷰 요약
- 키워드 생성
- 대규모 약한 레이블 생성
- 다국어(영어, 한국어, 대만어) 레이블 생성
- 인간 수준의 레이블링 품질 달성
- 새로운 분야 모델 학습을 위한 초기 데이터 제공
- 카테고리화 & 속성 추출
- 단일 LLM으로 전체 카테고리 처리
- 상품 데이터의 깊은 이해를 통한 정확도 향상
- 이미지 & 언어 이해
- 모델 아키텍처 선택
- 주로 사용된 모델
- Qwen, LLAMA, T5, Phi, Polyglot (NLP 작업용)
- CLIP (이미지-텍스트 멀티모달)
- TrOCR (텍스트 인식)
- 3B-20B 파라미터 규모 선호 (효율성과 품질의 균형)
- 주로 사용된 모델
- LLM 활용 패턴
- 인 컨텍스트 학습 (ICL)
- 프롬프트 기반 작업 수행
- 빠른 프로토타이핑에 적합
- 검색 증강 생성 (RAG)
- 외부 지식베이스 활용
- 실시간 처리의 어려움 존재
- 지도 학습 기반 미세조정 (SFT)
- 도메인 특화 데이터로 추가 학습
- 기본 LLM 성능 향상
- 지속 사전 학습 (CPT)
- 대규모 데이터셋으로 추가 사전학습
- 리소스 집약적이나 최고 성능 달성
- 인 컨텍스트 학습 (ICL)
- 개발 인프라 및 도구
- 탐색 단계
- Apache Zeppelin 노트북
- Spark on Kubernetes
- GPU/멀티-GPU Jupyter 노트북
- 모델 학습
- Polyaxon on Kubernetes
- PyTorch 분산 학습
- 모델 병렬화 훈련
- 프로덕션 배포
- Ray + vLLM 추론 파이프라인
- 모델 경량화(증류)
- 임베딩 추출 방식
- 탐색 단계
- 인프라 최적화
- GPU 리소스 관리
- A100-80GB: 대규모 모델 학습
- A10G-24GB: 테스트 및 경량 학습
- 하이브리드 & 멀티리전 AI 클러스터 구축
- 프레임워크
- DeepSpeed Zero: 모델 병렬화
- Nvidia Triton: 실시간 추론
- Ray + vLLM: 배치 추론
- GPU 리소스 관리
Ray Batch Inference at Pinterest (2024.10.11, Pinterest)
- 목적
- Pinterest에서 Ray™를 이용한 오프라인 배치 추론 구현 방법 소개
- Ray 기반 배치 추론 솔루션의 성능 향상 사례 공유
- Ray 배치 추론의 주요 특징
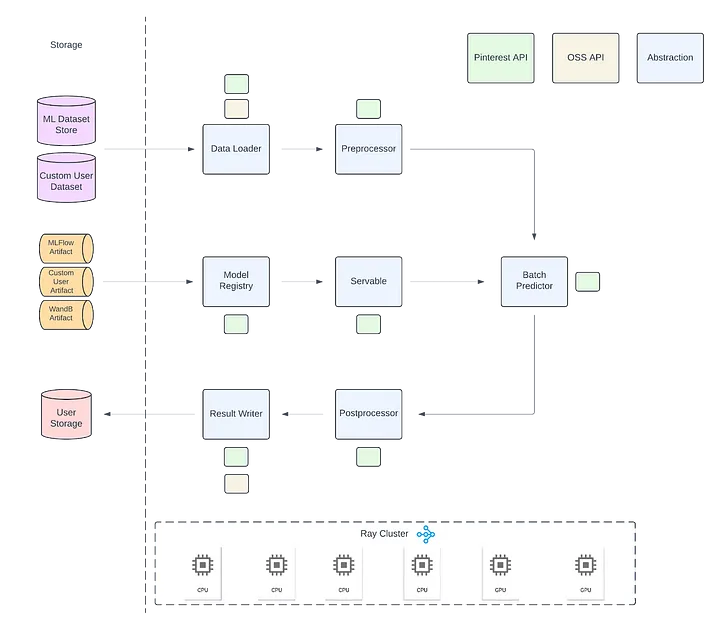
- 스트리밍 실행: 데이터 로딩, 추론, 결과 쓰기 단계의 병렬 처리
- 이기종 클러스터 지원: CPU와 GPU 자원의 독립적 확장 가능
- 훈련 프레임워크 독립성: PyTorch, TensorFlow 등 다양한 ML 프레임워크 지원
- 작업 구성: 더 큰 ML 워크로드의 일부로 배치 추론 포함 가능
- 구현 상세
- Ray Data의 map_batches 함수를 사용한 데이터셋 변환
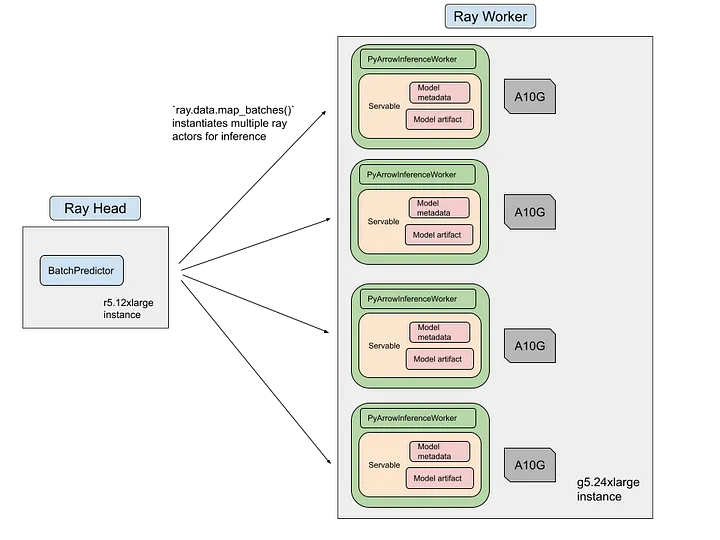
- Ray 액터를 사용한 모델 가중치 로딩 및 추론 수행
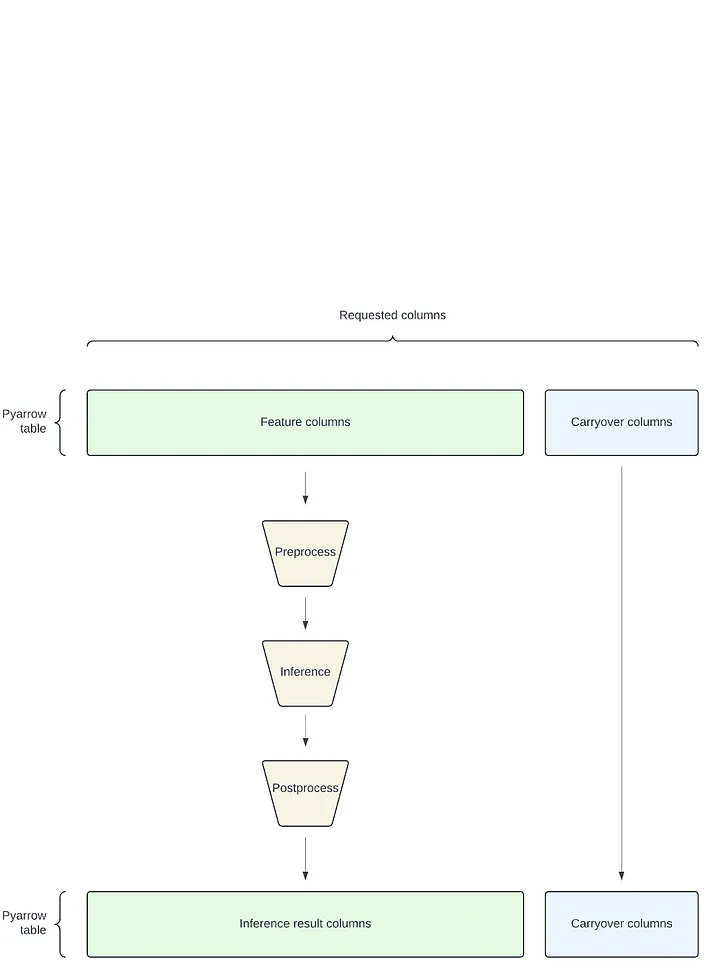
- Pyarrow 테이블을 이용한 효율적인 캐리오버 컬럼 처리
- 다중 모델 추론 지원: 단일 Ray 작업에서 여러 모델 추론 가능
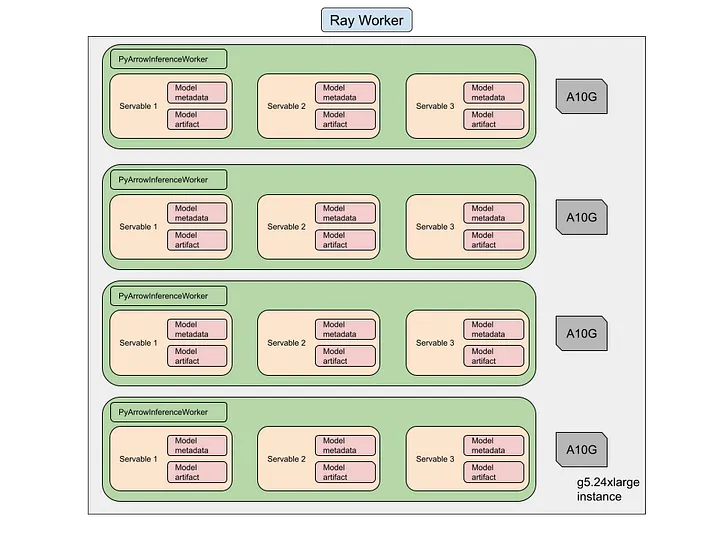
- 분산 누산기(Accumulators) 구현: 평가 메트릭 계산 최적화
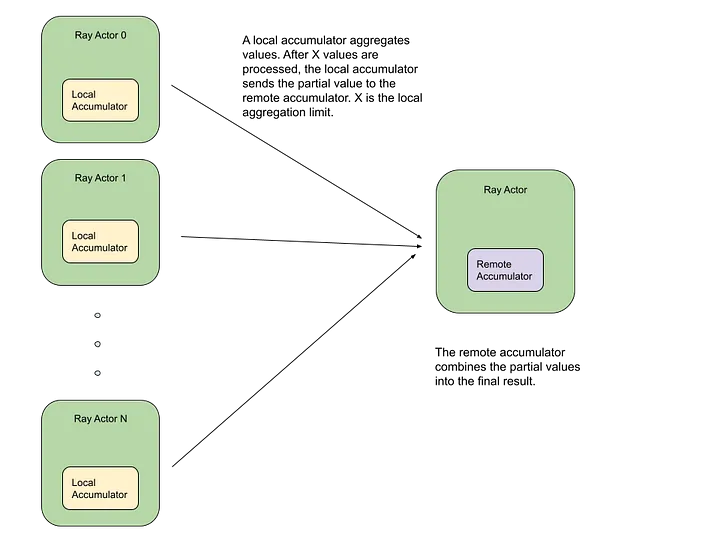
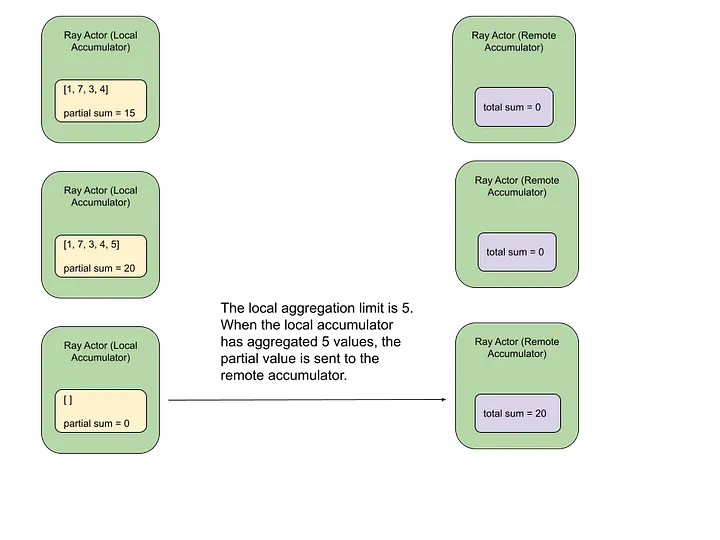
- LLM 추론 지원: vLLM™ 통합
- Ray Data의 map_batches 함수를 사용한 데이터셋 변환
- 주요 성과
- 관련 핀(p2p) 팀: TorchDataloader에서 Ray로 마이그레이션 후 4.5배 처리량 향상, 25% 비용 감소
- 검색 품질 팀: Spark™에서 Ray™로 마이그레이션 후 연간 비용 30배 이상 감소
- 성능 향상 요인
- 이기종 Ray 클러스터 활용으로 데이터 로딩 병목 현상 해소
- GPU 리소스 활용으로 추론 단계 처리량 개선
- 다중 모델 추론 기능으로 데이터 읽기 비용 감소
- 향후 계획
- KubeRay 통합: 배치 추론 및 훈련 작업의 자동 확장 지원
- Ray Tune 적용
- Ray™에서 데이터 로더 성능 개선
- 내결함성 있는 Ray 배치 추론 및 훈련 구현
- Ray™를 이용한 특성 중요도 계산
생성형 AI 기반 실시간 검색 결과 재순위화 1편 - 서빙 시스템 아키텍처, 생성형 AI 기반 실시간 검색 결과 재순위화 2편 - LLM 서빙 (2024.09.24, 네이버)
- 재순위화 서빙 시스템의 주요 요구사항
- MSA 구조에서 적절한 응답 시간 SLO 달성
- 고부하 상황에서 서버 보호
- 빠른 응답 시간 내 검색 결과 반환
- 주요 문제와 해결 방향
- 검색 서버에 대한 높은 검색 요청 부하
- 재순위화 과정에서의 시간 소요
- 원격 캐시를 활용한 검색 서버 요청량 최적화
- Nxcache라는 고가용성 원격 캐시 클러스터 도입
- Cache-Control 헤더를 이용한 중복 요청 처리
- 캐시를 통한 검색 결과 재사용으로 검색 서버 부하 감소
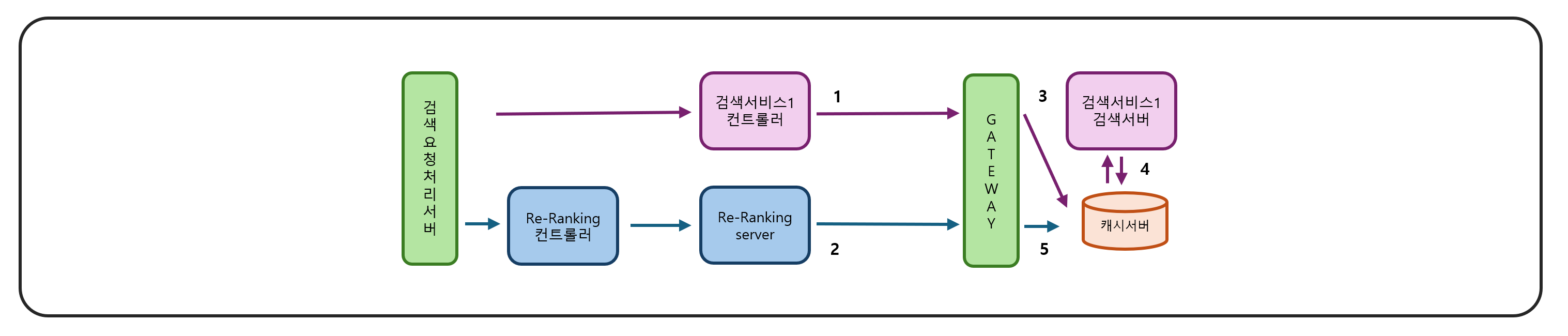
- 병렬 비동기 호출을 통한 응답 시간 최적화
- 모든 검색 서버를 동시에 비동기적으로 호출
- 가장 오래 걸리는 서버의 처리 시간에 바운드됨
- 제한 시간 초과 시 '결과 없음' 반환
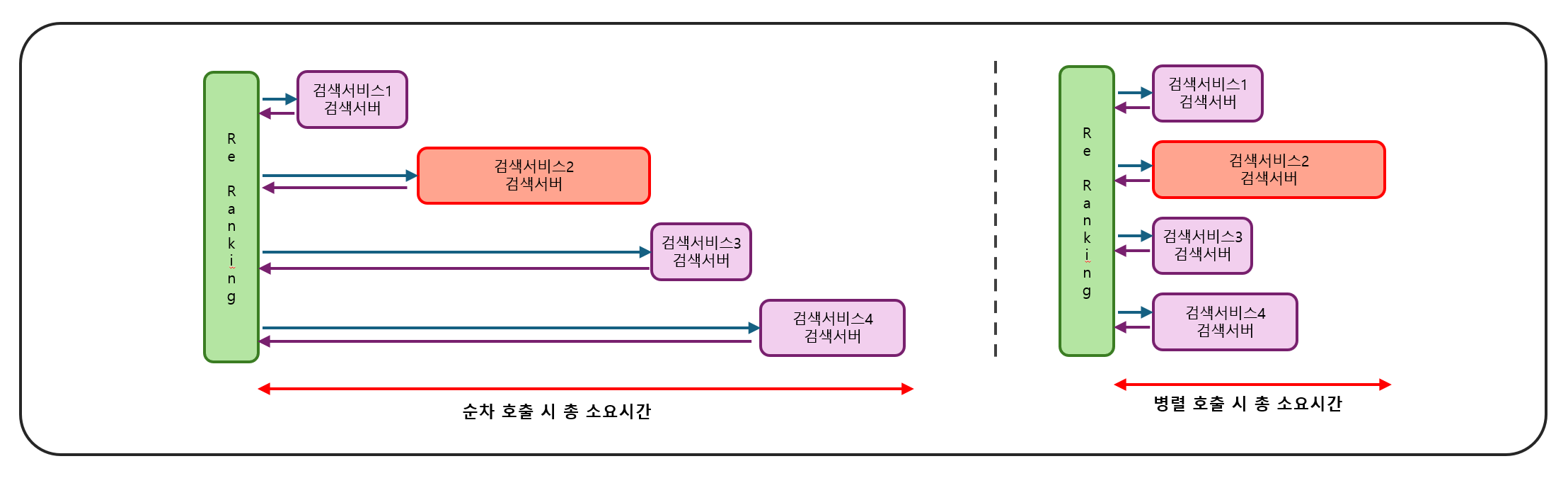
- MSA 환경에서의 병렬 호출 시 고려사항
- 서버 간 순서나 의존 관계
- 중복 요청 방지
- 서버별 중요도에 따른 호출 전략 수립
- OpenTelemetry를 통한 프로파일링 및 모니터링
- 고부하 상황에서의 시스템 보호 전략
- 재순위화 서버로의 요청량 최적화
- 캐시 도입 및 적절한 캐시 만료 시간 설정
- 재순위화 서버로 유입되는 요청량 줄이기
- 캐시 활용: 재순위화 결과 캐싱
- 디그러데이션 모드: LLM 대신 선형 모델 사용
- 스로틀링 모드: 허용량 초과 시 '결과 없음' 반환
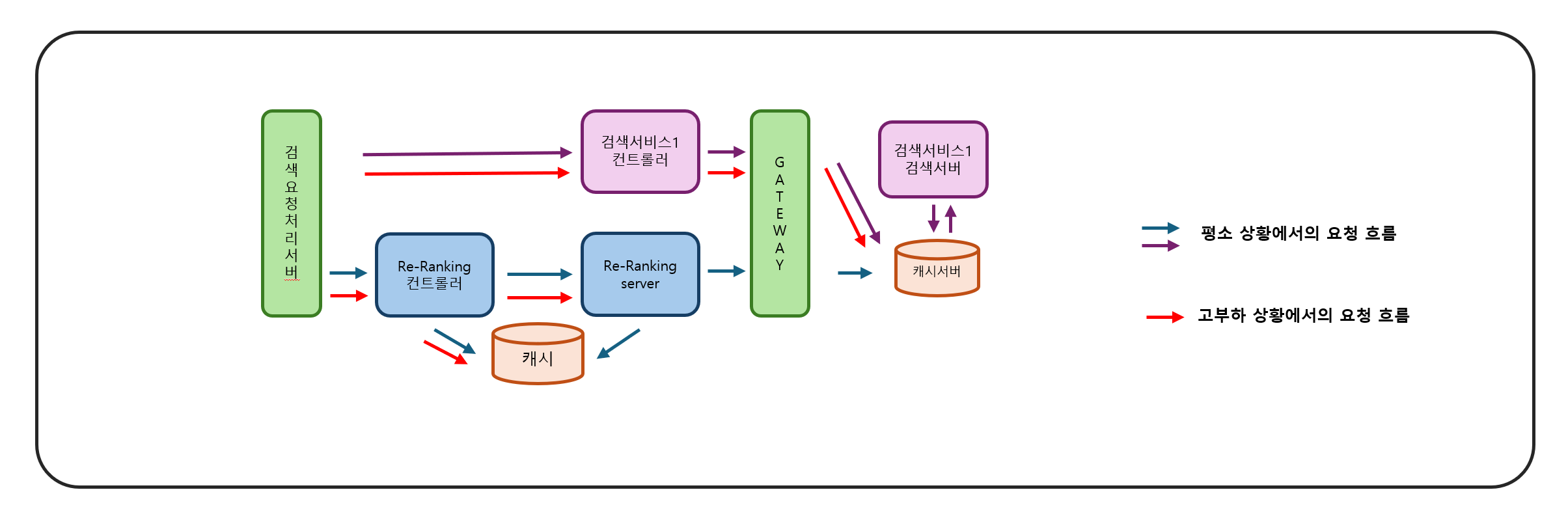
- 재순위화 서버로의 요청량 최적화
- LLM 서빙의 주요 요구사항
- 모델 품질 유지
- GPU 리소스 최적화
- 응답 속도 개선
- 안정적인 서빙
- GPU 서빙 프레임워크 선택
- 검토한 프레임워크: TorchServe, TEI, TensorRT-LLM (TRT-LLM)

- 최종 선택: TRT-LLM
- 장점: Triton과 통합 용이, 최고의 처리량과 응답 속도
- Triton 기능 활용: 동적 배치, REST API 등
- CUDA 커널 레벨 최적화
- 검토한 프레임워크: TorchServe, TEI, TensorRT-LLM (TRT-LLM)
- LLM 모델 추론 성능 최적화
- 양자화: fp32에서 bfp16으로 변환, 처리량 약 2배 증가
- 배치 크기 조절: 입력량을 기준으로 설정, 최대 배치 크기는 2배로 설정
- 동적 배치 미사용: 초기 성능 저하 방지
- 성능 측정 및 최적화 도구
- Triton의 Model Analyzer: 모델 설정 최적화
- Performance Analyzer: 요청량에 따른 성능 측정
- 주요 모니터링 지표
- 처리량
- p99 응답 속도
- GPU 사용률
- 운영 및 배포 환경
- AiSuite 클러스터 및 KServe 활용
- 맞춤형 모니터링 대시보드 구성
- Triton 관련 지표 활용 (배치 크기, queue duration 등)
- Pod별 지표 측정으로 이상 동작 감지
- 관찰 가능성(Observability) 개선
- OpenTelemetry 도입
- 각 단계별 연산 시간 요청별 확인 가능
- 안정적 운영을 위한 전략
- GPU 사용률 기반 최대 가용량 설정
- 사용량 제한(rate limit) 적용
- 과도한 요청 시 'Too Many Requests' 응답
- 향후 계획
- Kubeflow 파이프라인 개발: 배포, 학습, 파인튜닝 자동화
- LLM을 이용한 자동 평가 과정 개선
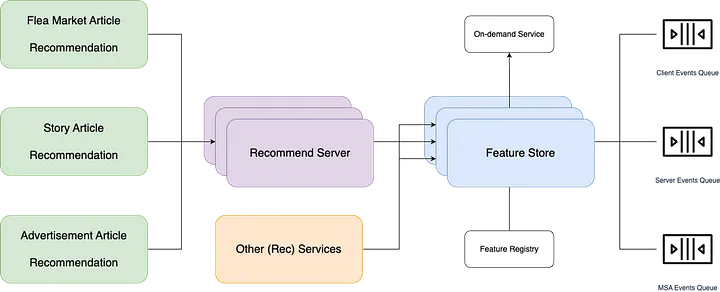
추천 시스템의 심장, Feature Store 이야기 (1)—혼란 속의 질서 찾기: Feature Store를 구축하다 (2024.08.20, 당근)
- Feature Store 개발 배경
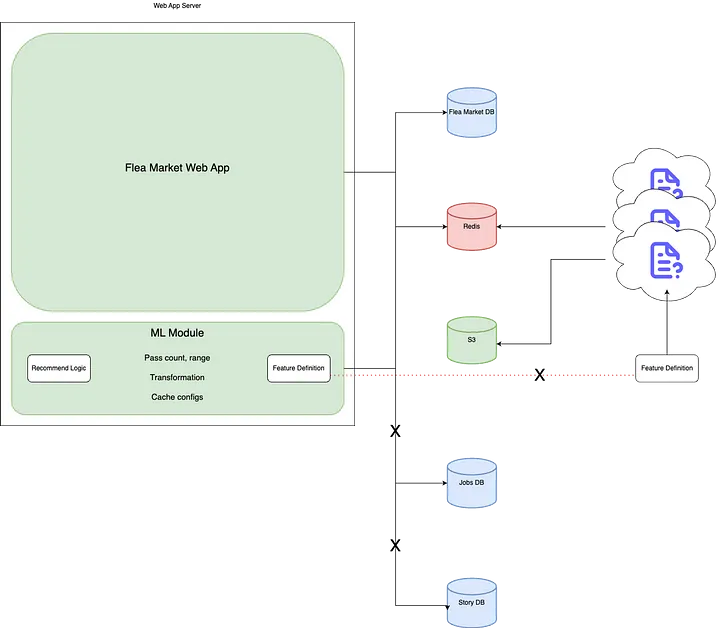
- 기존 추천 시스템의 한계 극복 필요성
- 피처 관리와 서빙의 중앙화 요구
- 주요 요구사항
- 실시간 피처 업데이트
- 다양한 타입의 피처 지원 (action, static)
- 유연한 쿼리 기능 (조회 기간, 개수 등 파라미터화)
- 높은 처리량 (1.5k+ rps 서빙, 400+ wps 수집)
- 아키텍처 설계
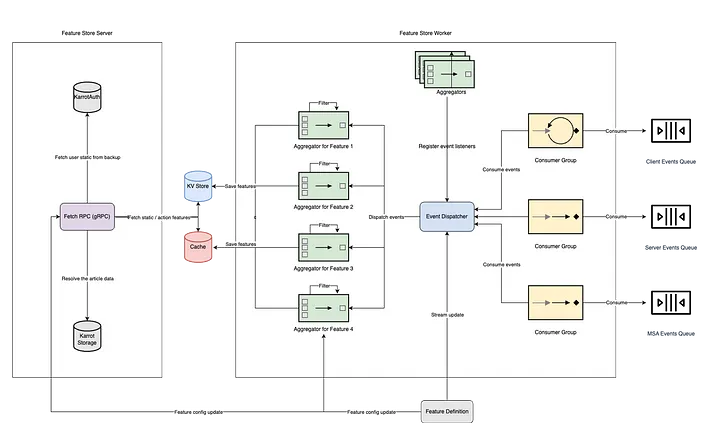
- 3가지 주요 컴포넌트: Feature 레지스트리, 서빙 서버, 수집 워커
- 스트림 기반 실시간 데이터 수집 (Stream Ingestion)
- 캐시 서버 도입으로 빠른 응답 시간 확보
- 데이터 모델링
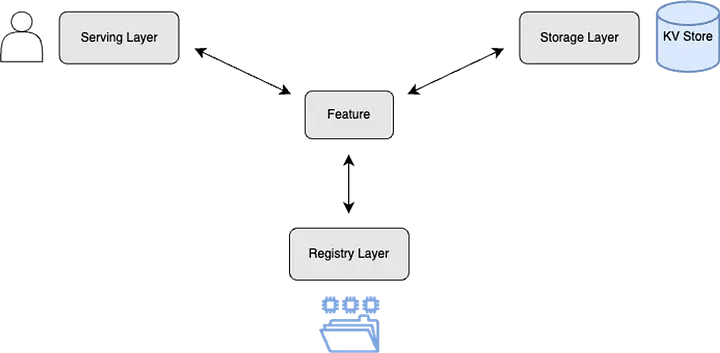
- 복합키 설계: (<prefix>#<entity_id>#<feature_name>, <timestamp or null>)
- Action 피처와 Static 피처 구분
- Redis Sorted Set 활용한 캐시 설계
- 피처 정의 스키마
- YAML 기반의 피처 정의 포맷
- 이벤트 소스, 필터, 필드 추출 등 상세 설정 가능
- API 설계
- GraphQL 채택으로 유연한 쿼리 지원
- 동적 피처 선택 및 파라미터 지정 가능
- 기술 스택 선택
- DB: Amazon DynamoDB (완전 관리형, 높은 확장성)
- Cache: Amazon ElastiCache (Redis)
- Queue: Kinesis, Kafka (MSK), 후에 PubSub으로 일부 전환
- Remote Config: Central Dogma (오픈소스 원격 설정 저장소)
- 성능 및 확장성
- 초기 4개 피처에서 70개 이상으로 확장
- 피크 기준 약 130K/s 요청량, 4M/s 피처 서빙량 달성
- 추후 개선 사항
- 성능 한계 극복을 위한 Feature Platform (v2) 개발 언급
- 리소스 사용량 감소 및 레이턴시 약 50% 개선
Building a Generative AI Platform (2024.07.25)
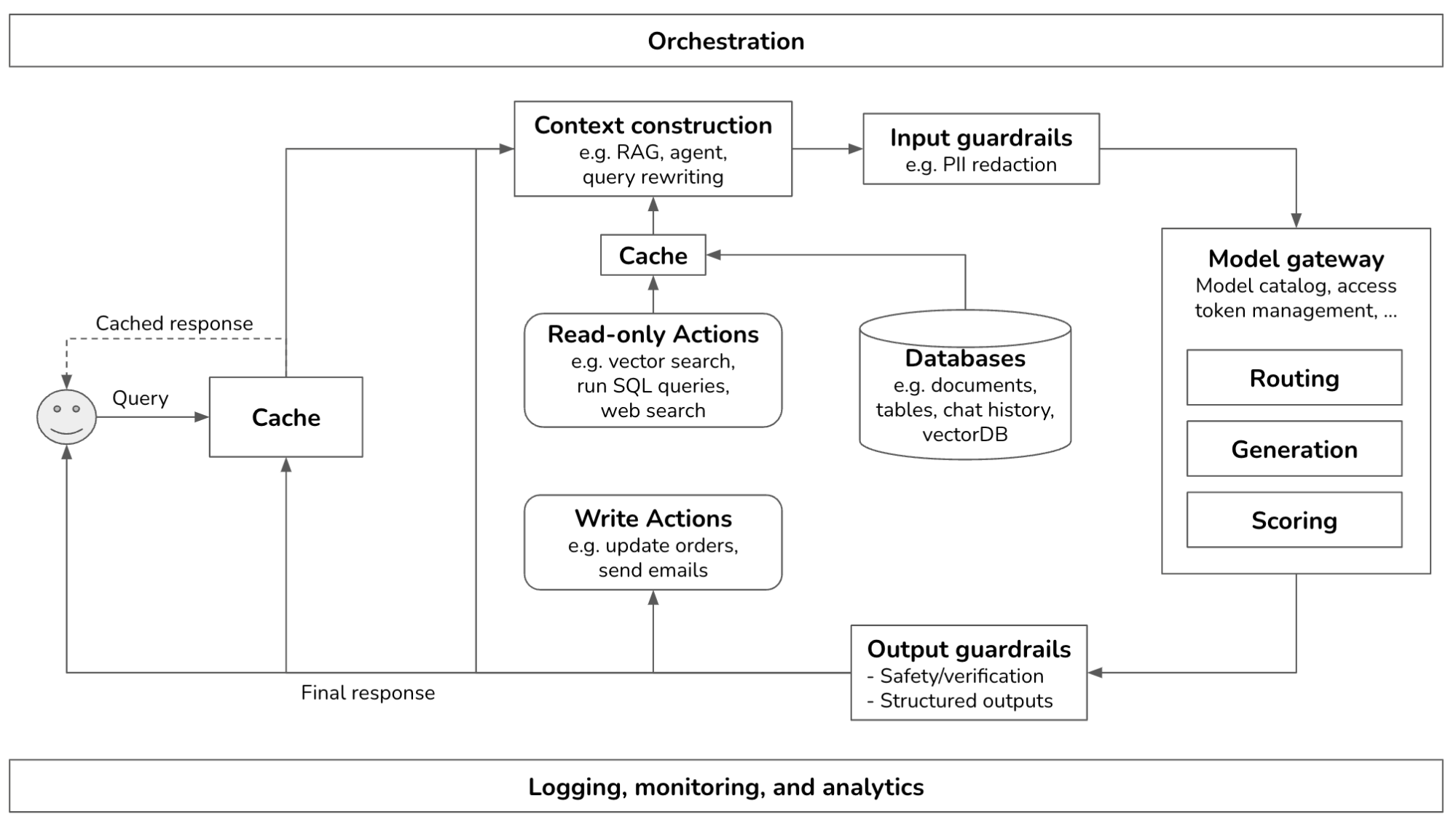
- 컨텍스트 강화
- 외부 데이터 소스 및 도구 접근
- RAG 구현: 키워드 vs. 임베딩 기반 검색
- 가드레일
- 입력 보호: 개인정보 유출 방지, 잘못된 프롬프트 실행 차단
- 출력 보호: 응답 품질 평가, 실패 모드 정책 지정
- 모델 라우터 및 게이트웨이
- 라우터: 쿼리별 최적 모델 선택
- 게이트웨이: 통합 모델 접근, 접근 제어, 비용 관리
- 캐시 구현
- 프롬프트 캐시: 중복 텍스트 세그먼트 재사용
- 정확한 캐시: 정확히 일치하는 항목 저장 및 재사용
- 시맨틱 캐시: 유사 질의 재사용
- 복잡한 로직 및 쓰기 작업
- 조건부 모델 출력 전달
- 데이터 쓰기 작업 구현 (예: 이메일 작성, 주문 처리)
- 관찰 가능성 구현
- 지표: 모델 성능 평가 (정확성, 독성, 환각률 등)
- 로그: 시스템 동작 기록
- 추적: 질의 처리 과정 상세 기록
- AI 파이프라인 오케스트레이션
- 컴포넌트 정의: 모델, 데이터베이스, 액션 등
- 체이닝: 쿼리 처리 단계 정의 (처리, 검색, 프롬프트 생성, 응답 생성, 평가 등)

Sr. Data Scientist at AWS