
이 글은 ML 분산 학습에 대한 개인 학습 내용을 꾸준히 정리하여 올립니다.
Overview
Everything about Distributed Training and Efficient Finetuning
DeepSpeed
DeepSpeed's Bag of Tricks for Speed & Scale
- DeepSpeed의 주요 혁신 분야
- 대규모 훈련 실행 가능, 추론 지연 시간 감소, 모델 압축, ML 과학 연구 지원

- 대규모 훈련 실행 가능, 추론 지연 시간 감소, 모델 압축, ML 과학 연구 지원
- 순진한 데이터 병렬화(Naive Data Parallelism)의 문제점
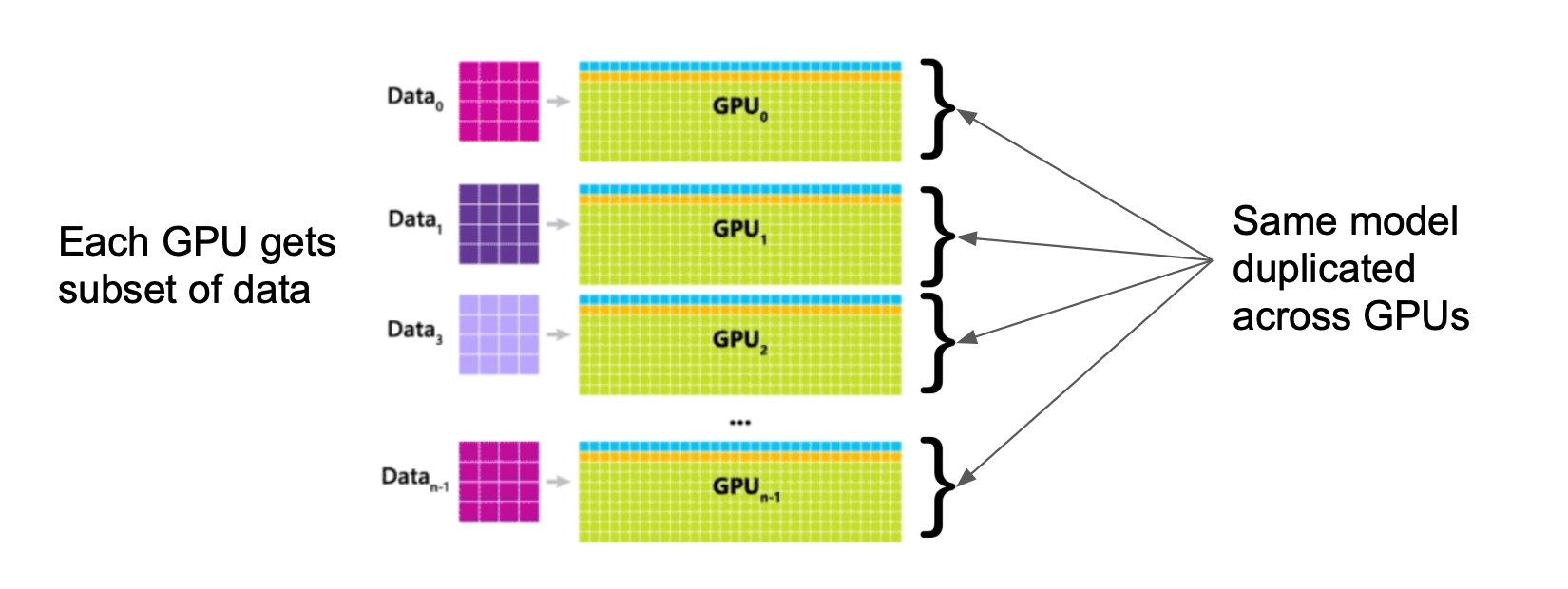
- 전체 모델을 각 워커에 복사해야 함
- 대규모 모델의 경우 단일 장치 메모리에 맞지 않음
- 메모리 병목 현상 해결 불가
- 순진한 모델 병렬화(Naive Model Parallelism)의 문제점
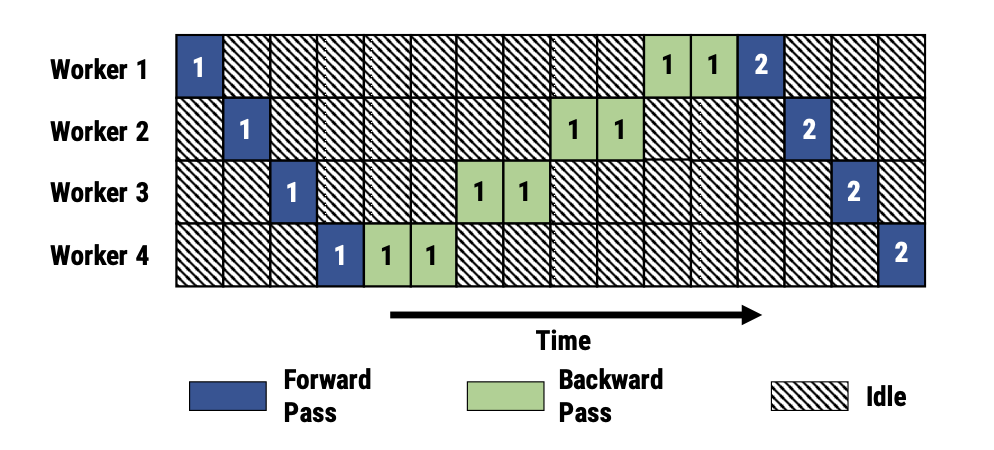
- 모델 아키텍처에 따라 효율적인 분할 방법이 다름
- 노드 간 통신이 학습 병목 현상 야기
- 대부분의 시간 동안 워커들이 유휴 상태로 대기
- DeepSpeed: 데이터 병렬화와 모델 병렬화의 장점 결합

- DeepSpeed의 핵심 기술
- 혼합 정밀도 학습 (Mixed Precision Training)
- FP16을 사용하여 순전파/역전파 수행
- FP32 옵티마이저 상태를 유지하여 정확도 보장
- 메모리 사용량 절반으로 감소 및 계산 속도 향상
- 가중치 업데이트 지연 (Delaying Weight Updates)
- 내부 루프에서 그래디언트 동기화를 외부로 이동
- 처리량 개선
- ZeRO (Zero Redundancy Optimizer) → 아래에 추가 설명
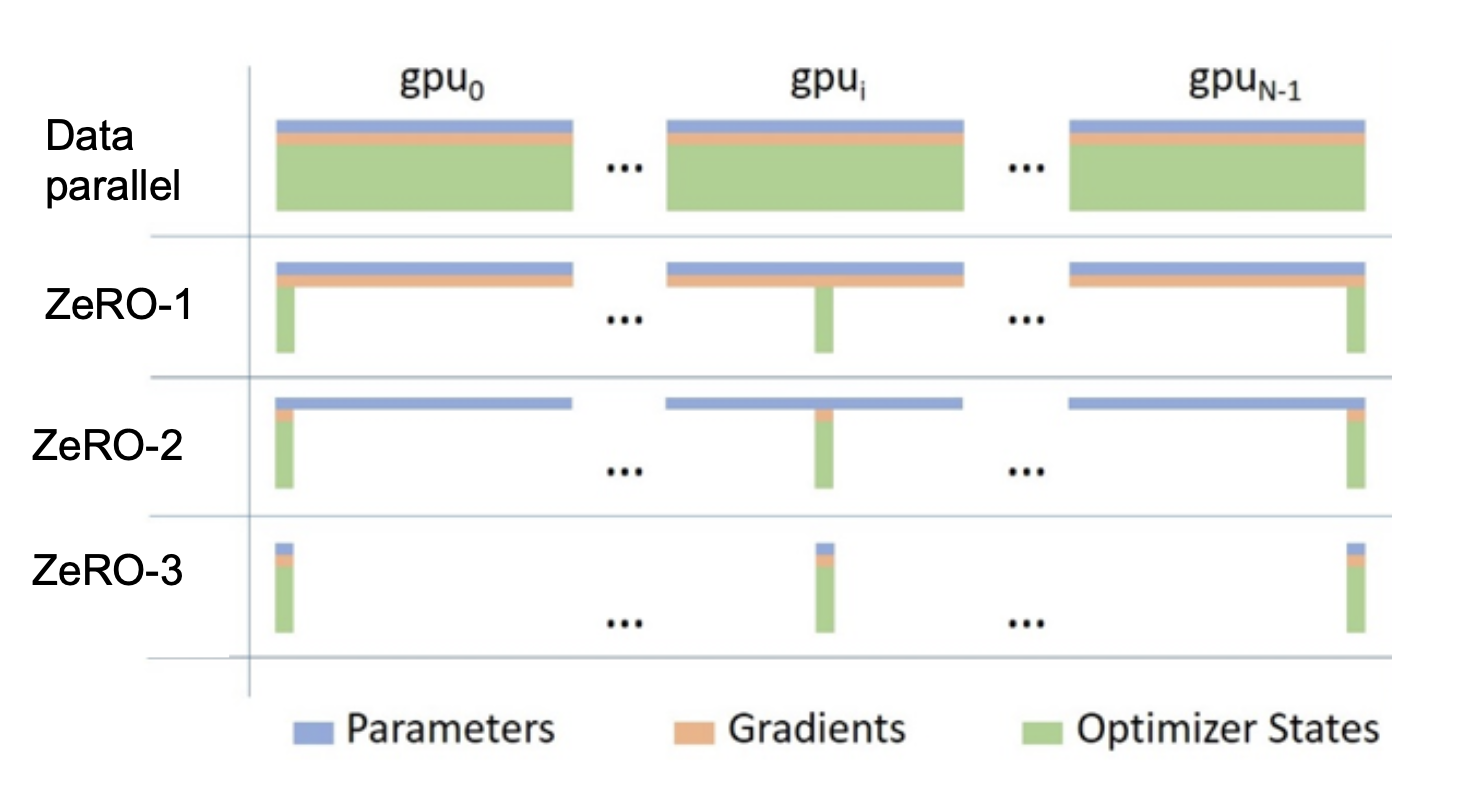
- 스테이지 1: 옵티마이저 상태값의 중복 제거
- 스테이지 2 & 3: 그래디언트와 파라미터의 중복 제거
- N개의 코어 사용 시 N × 메모리 사용량 감소
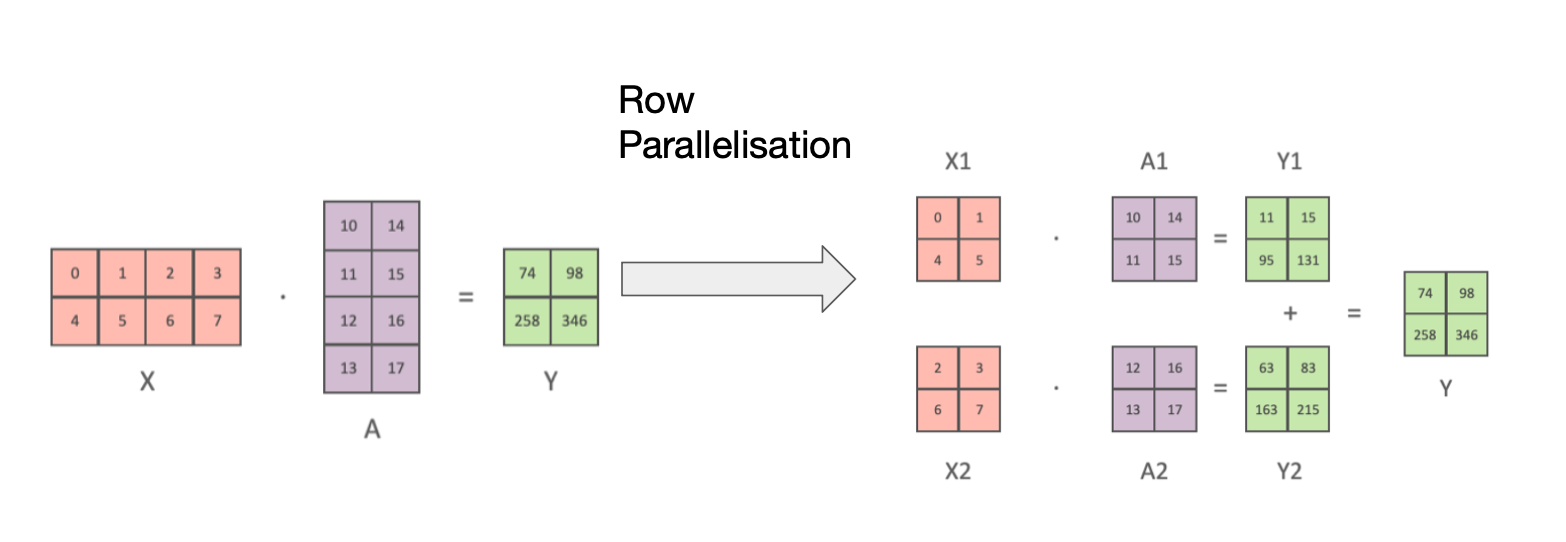
- 텐서 슬라이싱 (Tensor Slicing)
- 대형 행렬 곱셈을 여러 GPU에 분산
- 행 또는 열 기반 슬라이싱 사용
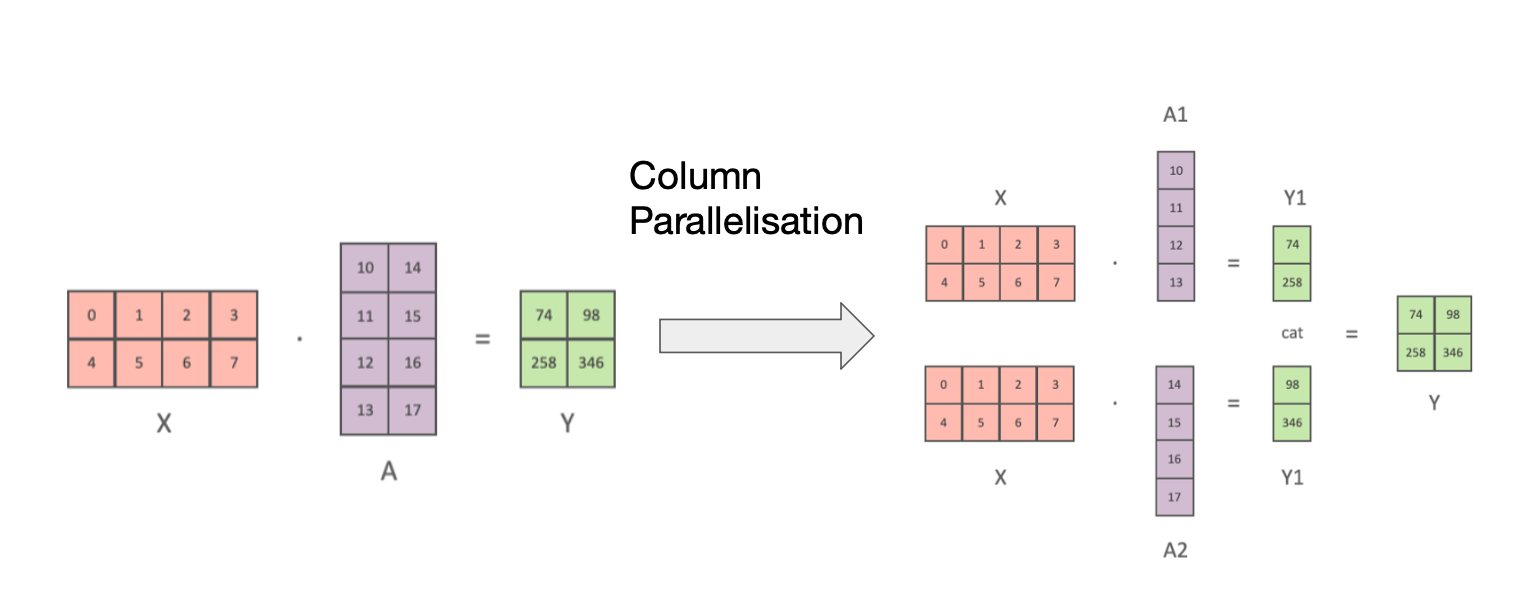
- 그래디언트 체크포인팅 (Gradient Checkpointing)
- 메모리와 계산 사이의 트레이드오프
- 중간 활성화 값을 저장하여 메모리 사용 감소
- 개발자 편의성 개선
- 프로파일링 및 모니터링 도구 제공
- 모델 체크포인팅 지원
- 혼합 정밀도 학습 (Mixed Precision Training)
- 구현 및 사용
- PyTorch 및 TensorFlow와 통합
- PyTorch에서 4줄의 코드 변경만으로 DeepSpeed 적용 가능
- HuggingFace의 Accelerate 라이브러리를 통해 백엔드 통합
- 성능 향상
- 대규모 모델 훈련 시간과 비용을 100배 이상 감소
- GPU 수 증가에 따른 초선형적(Superlinear) 확장성
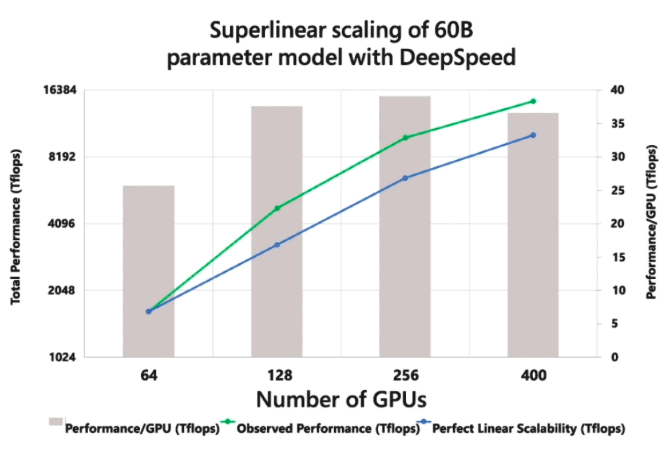
ZeRO 추가 설명
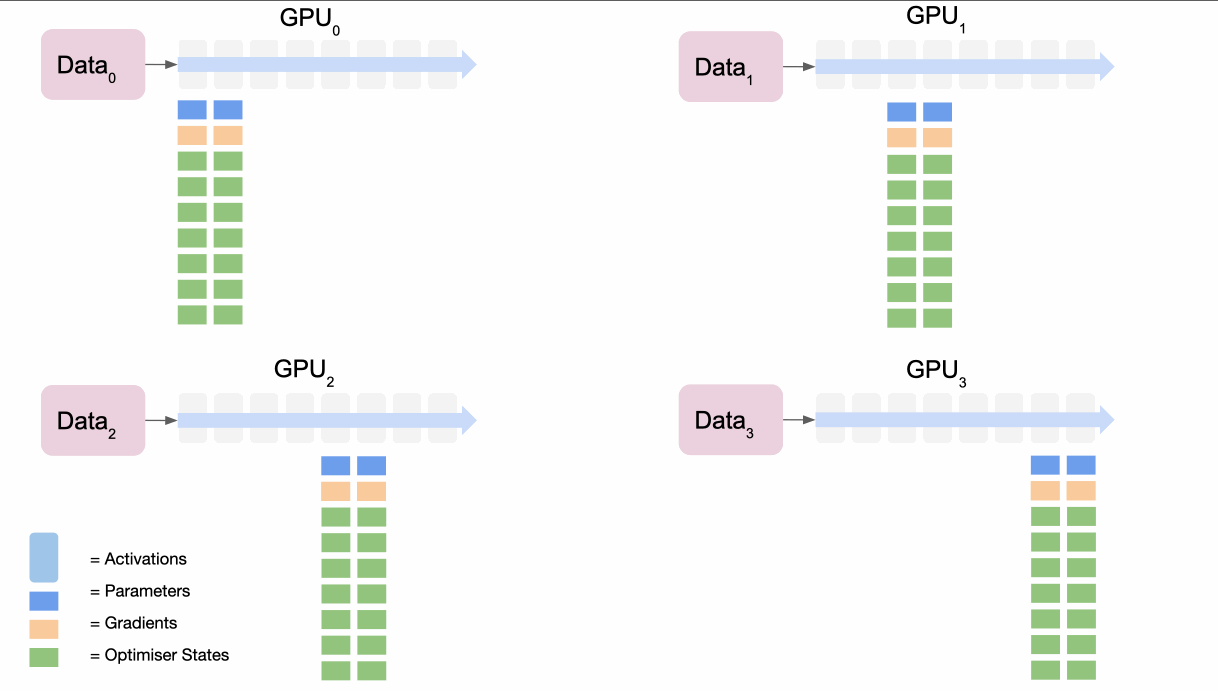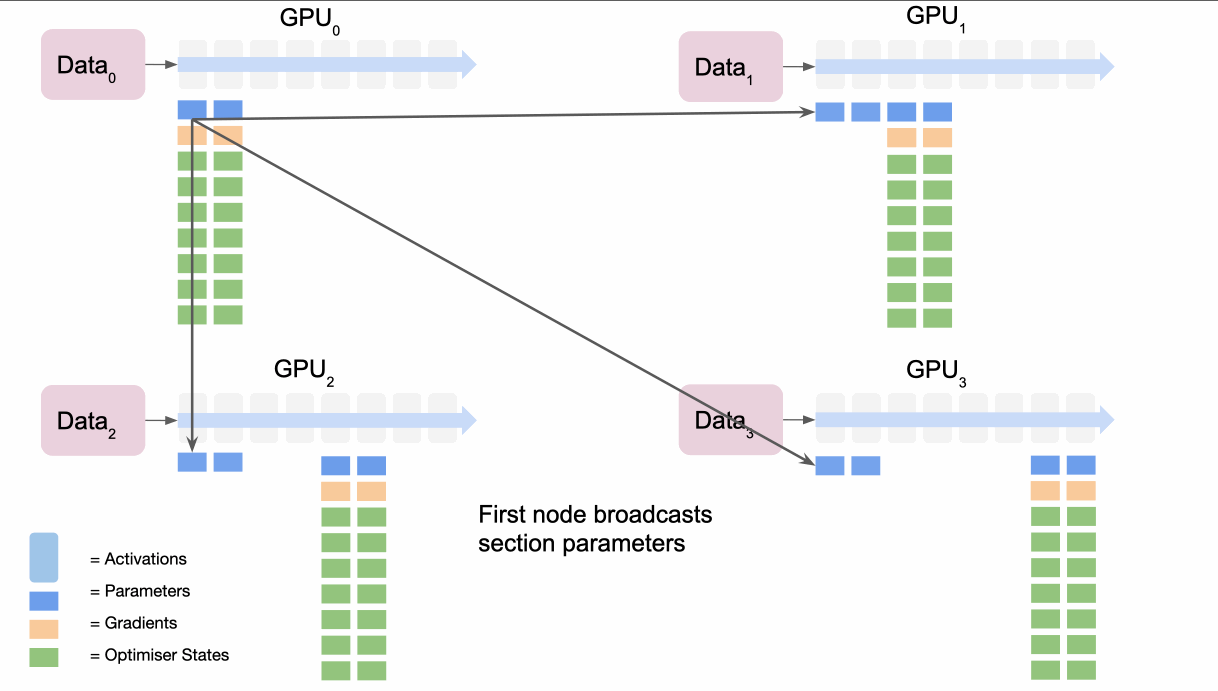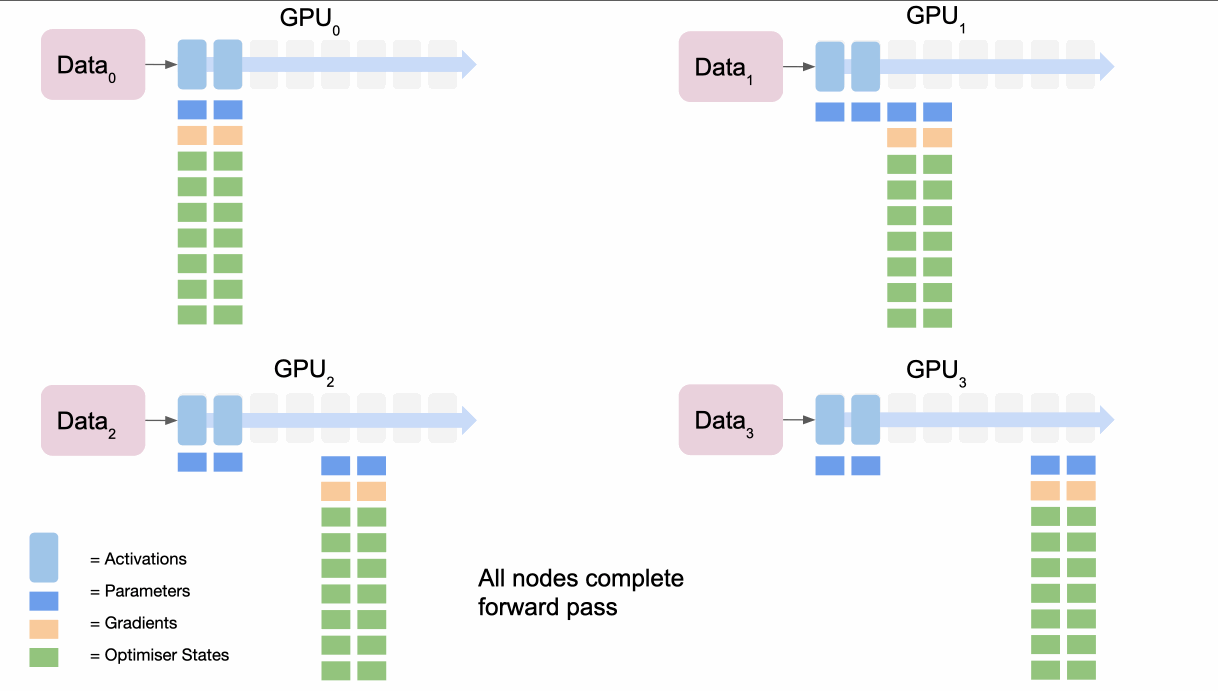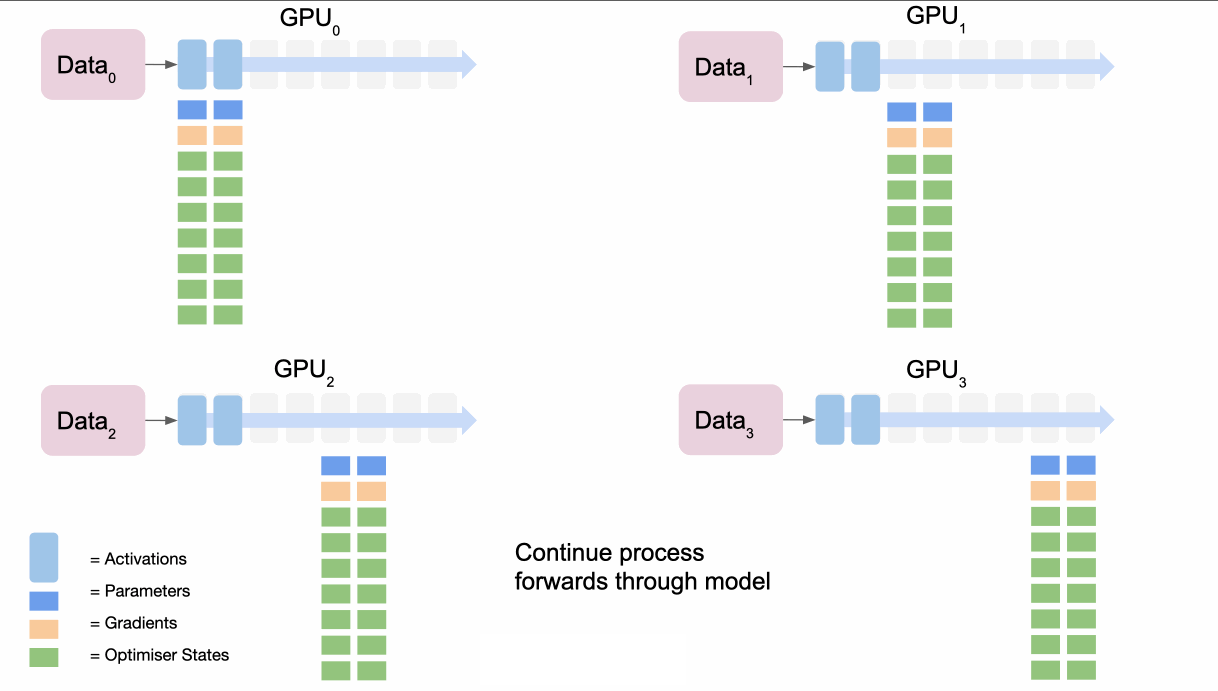
ZeRO 스테이지 1: 옵티마이저 상태값 분할
- 작동 원리
- 각 GPU는 전체 모델 파라미터와 그래디언트의 복사본을 유지합니다.
- 옵티마이저 상태값(예: Adam의 모멘텀과 분산)만 GPU 간에 분할됩니다. 각 GPU는 전체 파라미터 중 일부에 대해서만 옵티마이저 상태값을 저장합니다.
- 프로세스
- 순전파: 일반적인 데이터 병렬 처리와 동일합니다.
- 역전파
- 각 GPU는 자신의 데이터에 대해 손실과 그래디언트를 계산합니다.
- 마지막 GPU는 모든 GPU의 그래디언트를 수집하여 평균화합니다.
- 마지막 GPU는 자신이 보유한 옵티마이저 상태값을 사용하여 관련된 그래디언트를 업데이트합니다.
- 업데이트된 그래디언트를 모든 GPU에 브로드캐스트합니다.
- 그 다음 GPU로 이동하여 그래디언트 업데이트를 위와 같이 반복합니다.
- 이점
- 일반적으로 약 4배의 메모리 절감 효과가 있습니다.
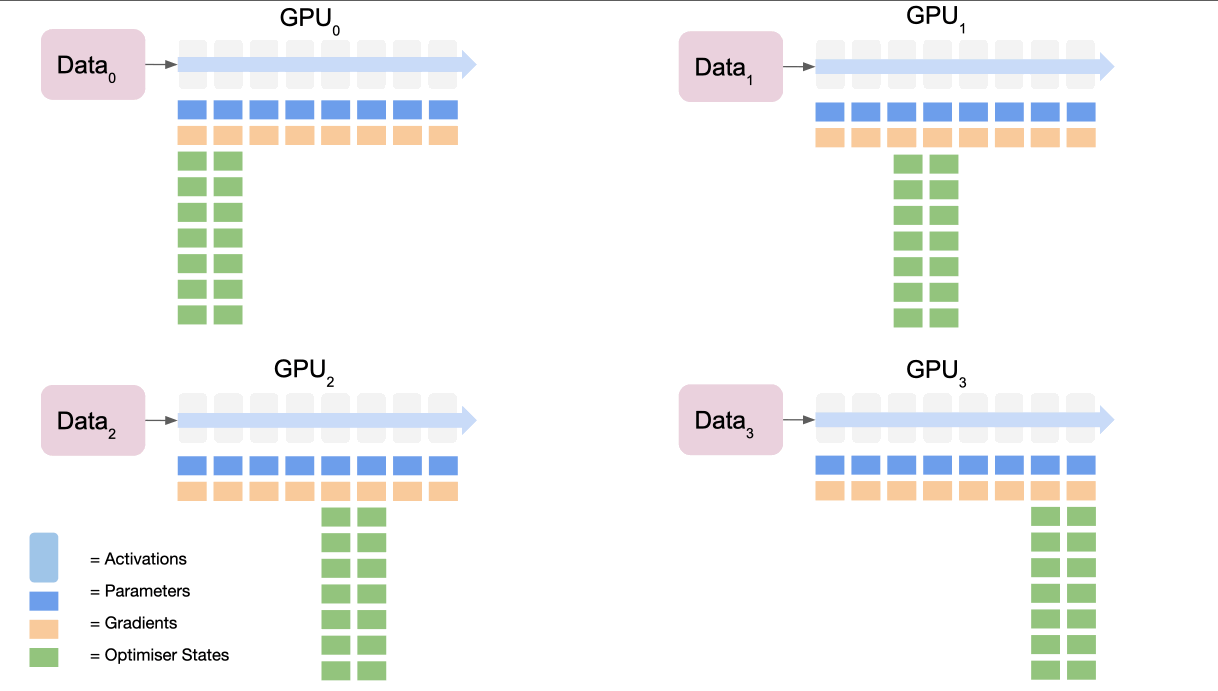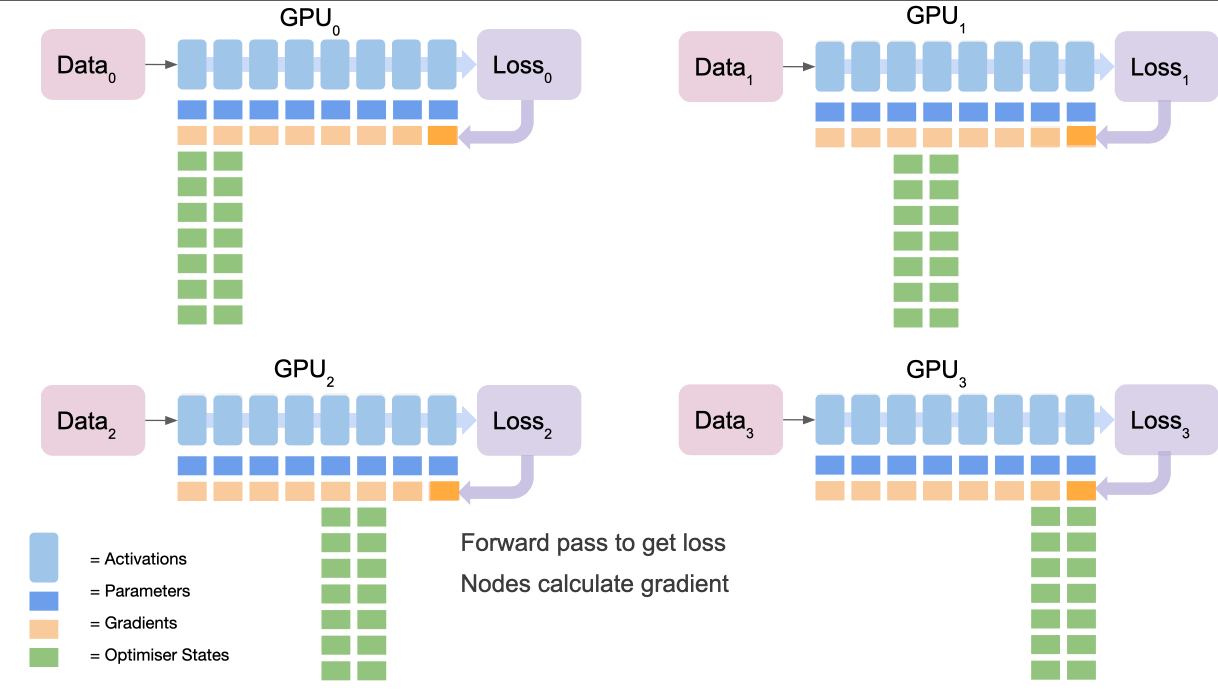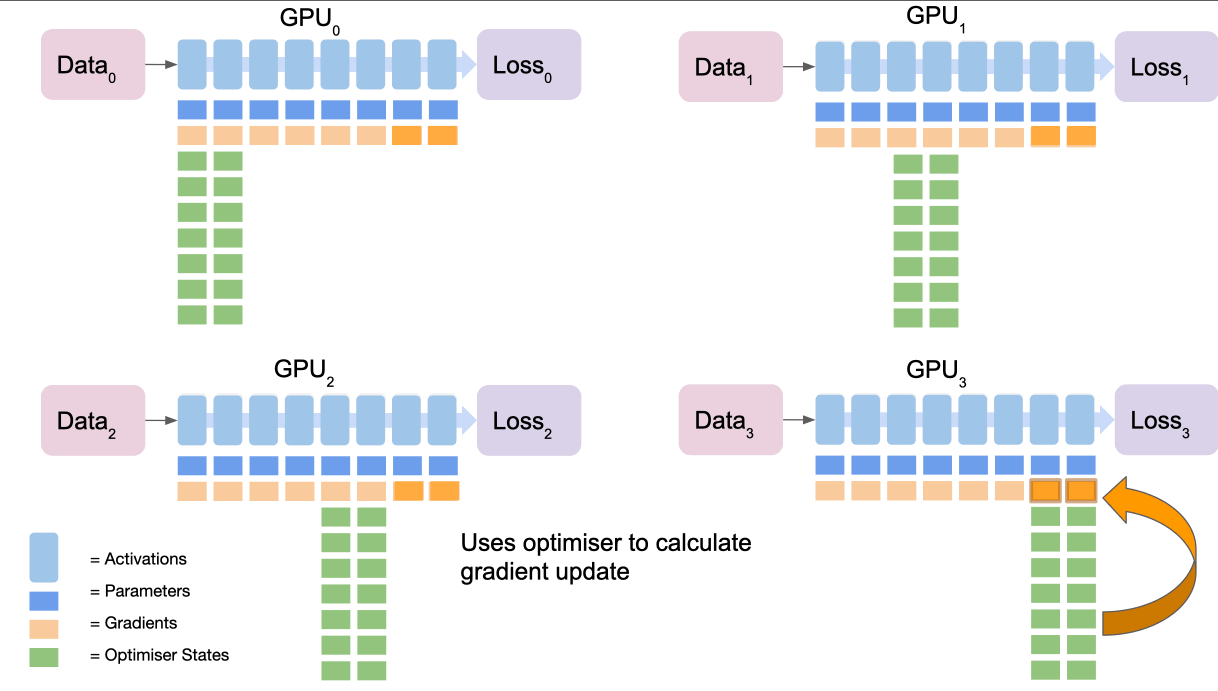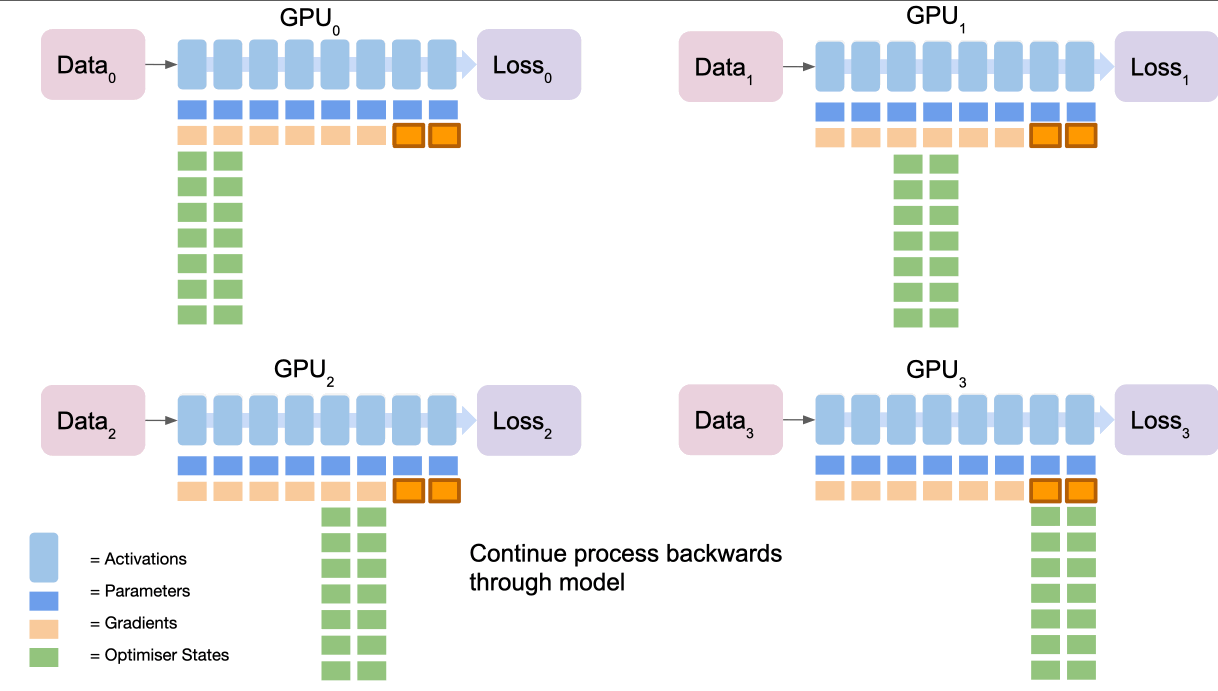
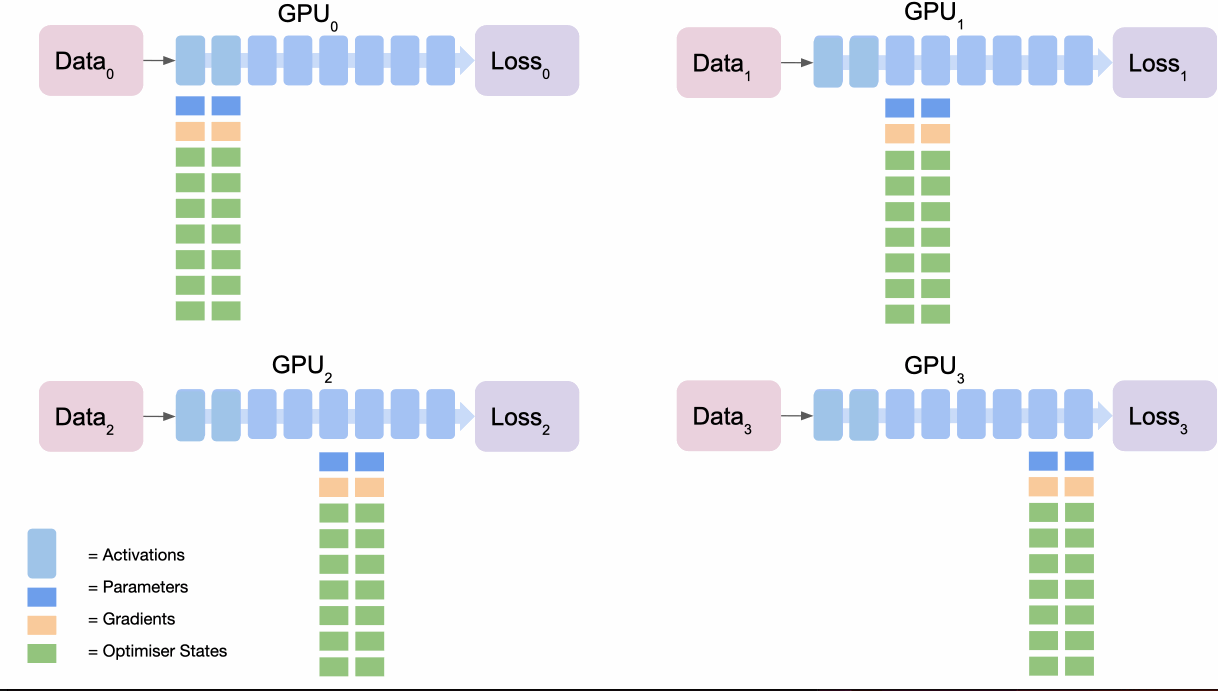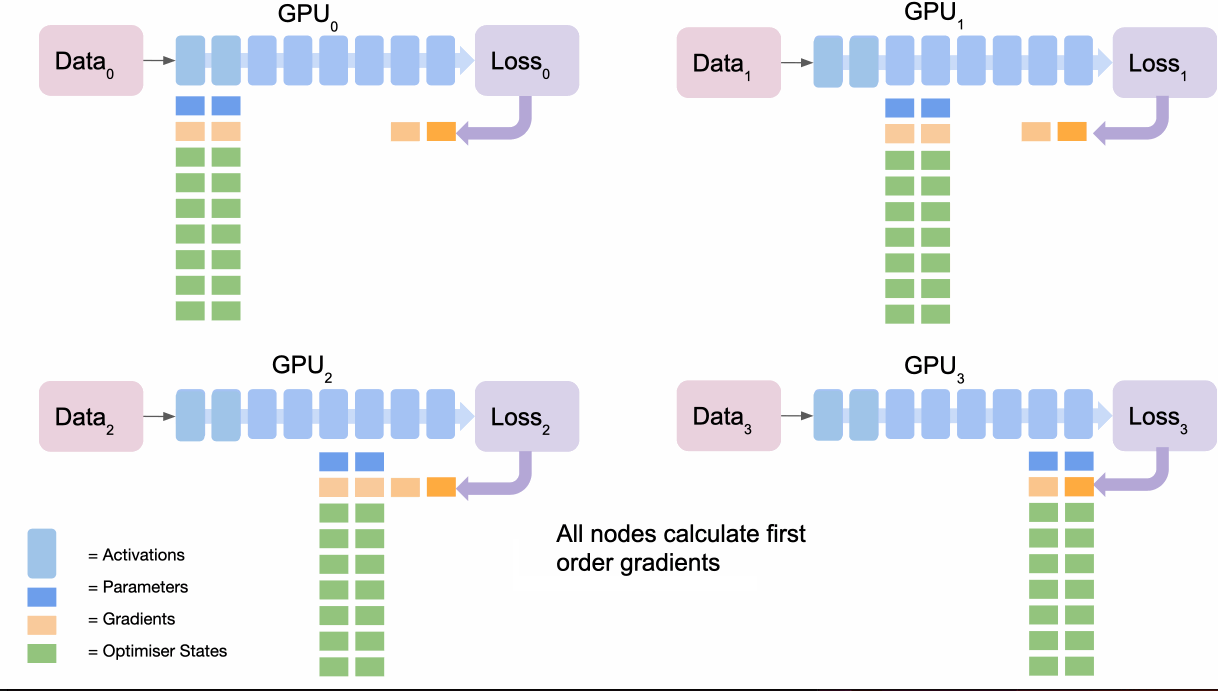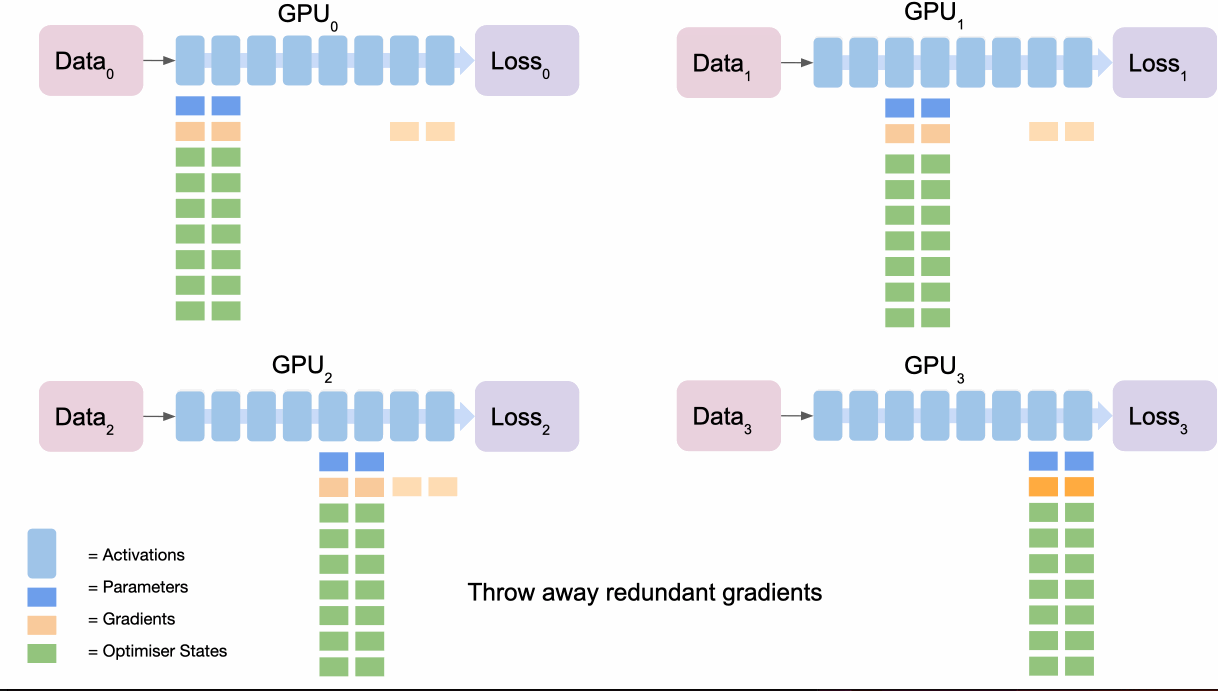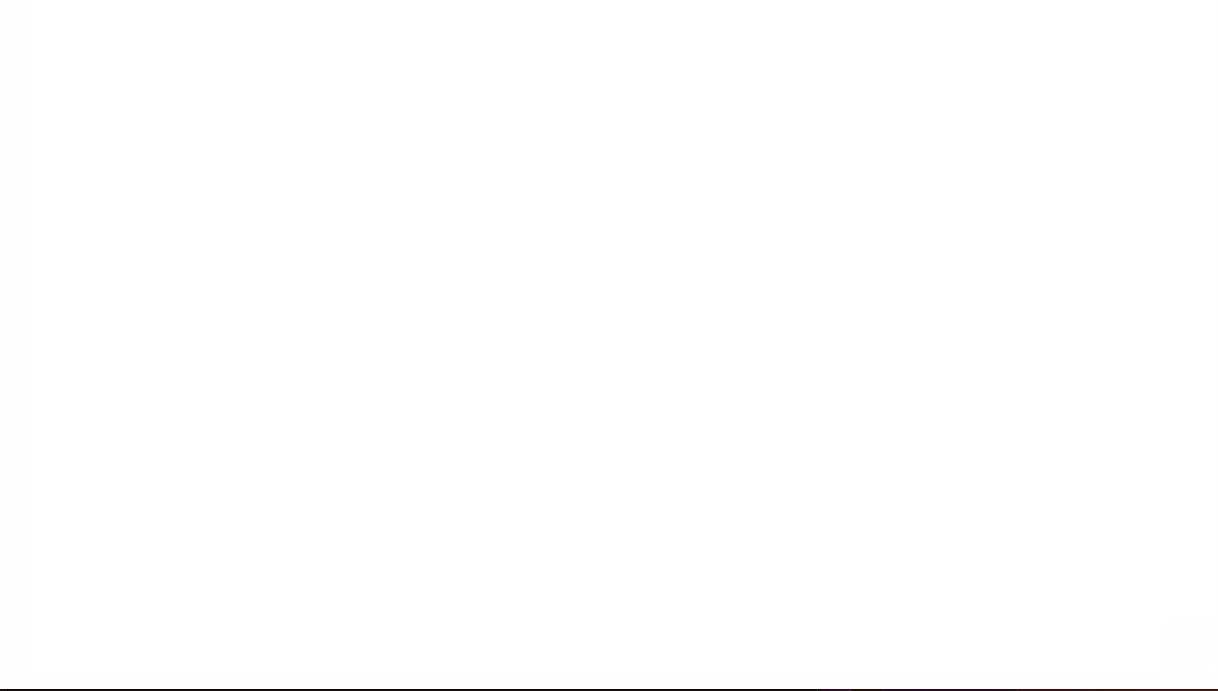
ZeRO 스테이지 2: 그래디언트 분할 + ZeRO 스테이지 3: 파라미터 분할
- 작동 원리
- 스테이지 1의 모든 최적화를 포함합니다. 스테이지 2는 그래디언트를 GPU 간에 분할하며 스테이지 3은 모델 파라미터를 GPU 간에 분할됩니다.
- 프로세스
- 순전파
1. 각 레이어의 계산 직전에 필요한 파라미터를 보유한 GPU가 다른 GPU들로 그것을 브로드캐스트합니다.
2. 계산 후 불필요한 파라미터는 메모리에서 해제됩니다.- 역전파
1. 마지막 GPU가 맡은 구간의 그래디언트를 브로드캐스트합니다.
2. 각 GPU는 자체 손실을 역전파하여 다음 그래디언트를 계산합니다.
3. 마지막 GPU는 모든 그래디언트를 누적, 평균을 내고, 옵티마이저로 업데이트를 계산한 후 결과를 브로드캐스트합니다.
4. 사용된 그래디언트는 해당 구간을 담당하지 않는 GPU에서는 폐기됩니다.
5. 이 과정을 다른 구간에 대해 반복하여 그라데이션 업데이트를 완료합니다.- 이점
- 메모리 사용량을 GPU 수에 비례하여 줄입니다.
종합적 이점
- 메모리 효율성: GPU 수에 거의 선형적으로 비례하여 메모리 사용량 감소
- 계산 효율성: 기존의 데이터 병렬성의 이점을 유지
- 통신 효율성: 분할을 통해 GPU 간 통신량 감소
- 확장성: 더 큰 모델과 배치 크기로 학습 가능
How to Use DeepSpeed on Amazon SageMaker
- DeepSpeed 사용 이유
- 대규모 언어 모델의 전체 파라미터 미세 조정에 필요한 대량의 GPU VRAM 문제 해결
- 모델 파라미터, 그래디언트, 옵티마이저 상태를 여러 GPU에 분산
- Amazon SageMaker 활용
- 가상 클러스터의 노드들을 고속 Infiniband 인터커넥트로 연결
- 사용자 정의 Docker 컨테이너로 DeepSpeed 사전 설치 환경 구성 가능
- SageMaker 실행 역할 설정
- SageMaker, CloudWatch, ECR, S3 접근 권한 필요 - 사용자 정의 Docker 이미지 준비 (openblitz/deepspeed)
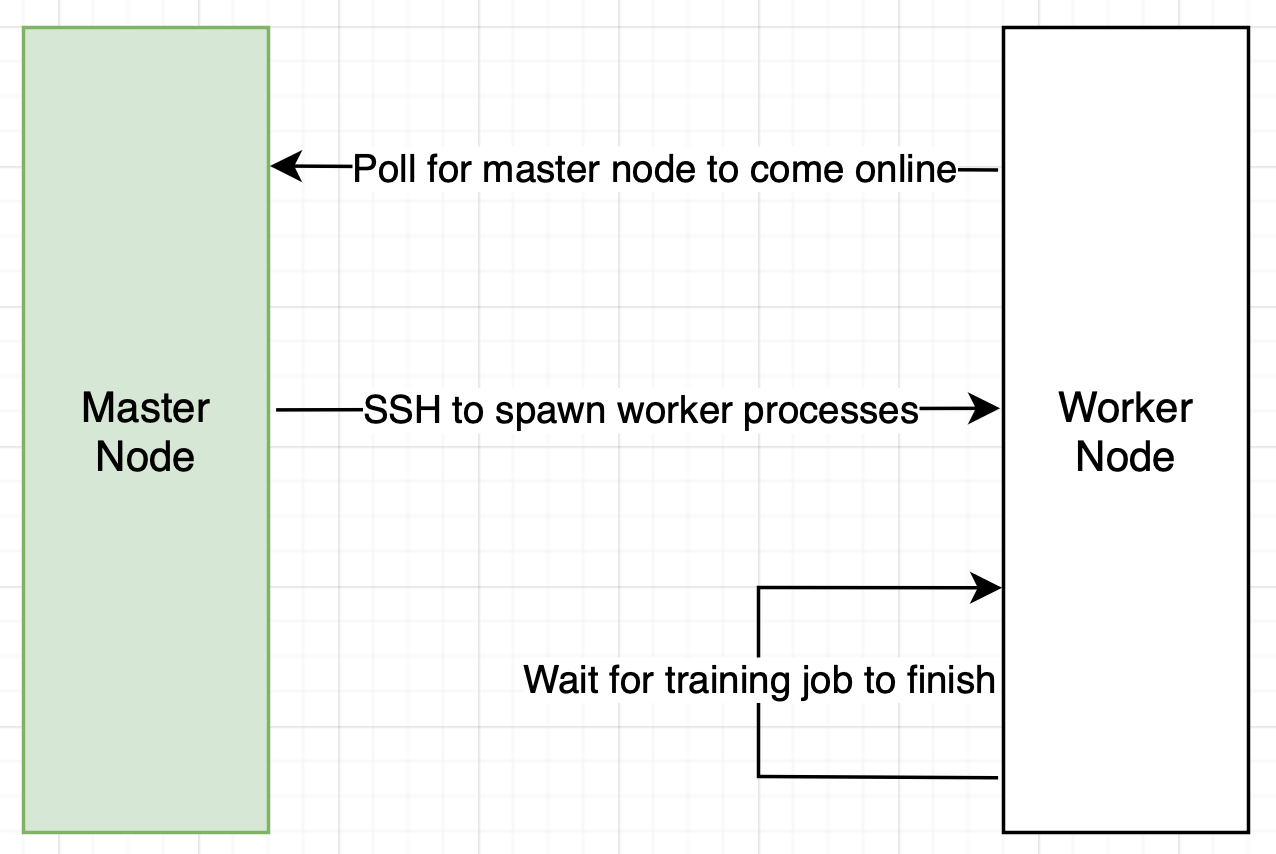
- sagemaker-training-toolkit 라이브러리 설치
- OpenMPI 세션 시작을 위한 설정
- 무암호 SSH 구성
- 훈련 스크립트 작성
- DeepSpeed 초기화를 위한 마스터 호스트 주소와 포트 지정
- 분산 샘플러를 사용한 데이터셋 로딩
- DeepSpeed 엔진으로 모델 래핑
- 학습 루프 구현 (전체 가중치 미세 조정)
- 모델 및 데이터셋 준비
- S3에 HuggingFace 모델 업로드 권장 (속도 향상)
- SageMaker가 S3에서 데이터셋과 모델을 다운로드하여 /opt/ml/input/data에 마운트
- 훈련 작업 시작
- SageMaker Python SDK의 CreateTrainingJob 엔드포인트 사용
- 인스턴스 유형, 하이퍼파라미터, 환경 변수 등 설정
- 주의사항
- 임시 디렉토리 사용 문제 해결을 위한 TMPDIR 환경 변수 설정
- 비루트 사용자 권한 문제로 인한 모델 저장 경로 조정
- 코드 샘플
ZeRO: Memory Optimizations toward Training Trillion Parameter Models
참고
- 논문
- 블로그
- ZeRO & DeepSpeed: New System Optimizations Enable Training Models with over 100 Billion Parameters
- ZeRO-2 & DeepSpeed: Shattering Barriers of Deep Learning Speed & Scale
- DeepSpeed: Extreme-Scale Model Training for Everyone
- DeepSpeed: Accelerating Large-Scale Model Inference and Training via System Optimizations and Compression
- DeepSpeed Powers 8x Larger MoE Model Training with High Performance
- DeepSpeed: Advancing MoE Inference and Training to Power Next-Generation AI Scale
- DeepSpeed ZeRO++: A Leap in Speed for LLM and Chat Model Training with 4X Less Communication

Sr. Data Scientist at AWS