
이 글은 LangChain, LangGraph, 프롬프트 엔지니어링와 RAG에 대한 개인 학습 내용을 꾸준히 정리하여 올립니다.
LangChain
다음은 테디노트님의 랭체인 한국어 튜토리얼을 기반으로 개인적으로 학습한 내용을 요약 및 정리한 글입니다.
13. LangChain Expression Language (LCEL)
RunnablePassthrough
- RunnablePassthrough
- 데이터를 그대로 전달하는 역할을 하는 클래스
- invoke() 메서드를 통해 입력된 데이터를 변경 없이 반환
- 주요 사용 시나리오
◦ 데이터 변환이 불필요한 경우
◦ 파이프라인의 특정 단계를 건너뛰어야 할 때
◦ 디버깅이나 테스트를 위한 데이터 흐름 모니터링 - Runnable 인터페이스 구현으로 다른 Runnable 객체와 함께 사용 가능
Runnable 구조(그래프) 검토
- Runnable 구조(그래프) 검토
- chain.get_graph() 메서드로 실행 그래프 반환
- 그래프의 노드와 엣지 확인 가능
- 그래프 ASCII 형식 출력 기능
RunnableLambda
- RunnableLambda
- 사용자 정의 함수를 실행할 수 있는 기능 제공
- 주요 특징
◦ 개발자가 자신만의 함수를 정의하고 실행 가능
◦ 데이터 전처리, 계산, 외부 API 상호작용 등에 활용 - 주의사항
◦ 사용자 정의 함수는 단일 인자만 받을 수 있음
◦ 여러 인수가 필요한 경우 래퍼 함수 작성 필요
- RunnableConfig 인자 활용
- 콜백, 태그, 기타 구성 정보를 중첩된 실행에 전달 가능
LLM 체인 라우팅(RunnableLambda, RunnableBranch)
- RunnableBranch
- 입력에 따라 동적으로 로직을 라우팅하는 도구
- 주요 특징
◦ 입력 데이터 특성에 기반한 다양한 처리 경로 정의 가능
◦ 복잡한 의사 결정 트리를 간단하고 직관적으로 구현
◦ 코드의 가독성, 유지보수성, 모듈화, 재사용성 향상
◦ 런타임에 동적으로 분기 조건 평가 및 처리 루틴 선택
- 라우팅 구현 방법
- RunnableLambda에서 조건부로 실행 가능한 객체 반환 (권장)
- RunnableBranch 사용
RunnableParallel
- RunnableParallel
- 입력 및 출력 조작에 유용한 도구
- 여러 Runnable을 병렬로 실행하고 출력을 맵으로 반환
- 주요 특징
◦ 시퀀스 내에서 한 Runnable의 출력을 다음 Runnable의 입력 형식에 맞게 조작
◦ 자동 유형 변환 처리
◦ 병렬 처리를 통한 실행 시간 최적화
동적 속성 지정(configurable_fields, configurable_alternatives)
- 동적 속성 지정
- 런타임에 체인 내부 구성을 변경할 수 있는 기능
- 두 가지 주요 방식
- configurable_fields: 실행 가능한 객체의 특정 필드 구성
- configurable_alternatives: 특정 실행 가능한 객체에 대한 대안 나열
- configurable_fields 활용
- ConfigurableField를 사용하여 동적 속성 정의
- with_config() 메서드를 통한 동적 구성
- 설정 저장 및 재사용
- 구성된 체인을 별도의 객체로 저장하여 재사용 가능
RunnableWithMessageHistory
- RunnableWithMessageHistory
- 메시지 기록(메모리)을 특정 유형의 작업(체인)에 추가하는 기능
- 대화형 애플리케이션이나 복잡한 데이터 처리 작업에서 이전 메시지의 맥락을 유지하는 데 유용
- 실제 활용 예시
∘ 대화형 챗봇 개발
∘ 복잡한 데이터 처리
∘ 상태 관리가 필요한 애플리케이션
• 메시지 기록 구현 방법 - 인메모리 ChatMessageHistory 사용
∘ 메모리 내에서 메시지 기록 관리
∘ 빠른 접근 속도, 애플리케이션 재시작 시 메시지 기록 소실 - RedisChatMessageHistory 사용
∘ Redis를 활용한 영구적 저장소
∘ 분산 환경에서 안정적으로 메시지 기록 관리 가능
- RunnableWithMessageHistory 설정
- runnable: BaseChatMessageHistory와 상호작용하는 객체
- get_session_history: 메시지 기록을 관리하는 호출 가능한 객체
- input_messages_key: 사용자 쿼리 입력 지정 키
- history_messages_key: 대화 기록 지정 키
- 대화 스레드 관리
- session_id를 사용하여 각 대화 스레드 별로 관리
- invoke() 시 config={"configurable": {"session_id": "세션ID입력"}} 코드 필요
- 다양한 입출력 형식 지원
- Messages 객체 입력, dict 형태 출력
- Messages 객체 입력, Messages 객체 출력
- 단일 키를 가진 Dict로 모든 메시지 입출력 처리
- 영구 저장소(Persistent storage) 활용
- Redis를 사용한 메시지 기록의 영구 저장 예시 제공
사용자 정의 제네레이터(generator)
- 사용자 정의 제네레이터
- LCEL 파이프라인에서 yield 키워드를 사용하는 함수를 통해 구현
- 시그니처: Iterator[Input] -> Iterator[Output] (비동기의 경우 AsyncIterator 사용)
- 주요 용도:
∘ 사용자 정의 출력 파서 구현
∘ 이전 단계의 출력을 수정하면서 스트리밍 기능 유지 - 예시: 쉼표로 구분된 목록에 대한 사용자 정의 출력 파서 구현
- 비동기(Asynchronous) 제네레이터 지원
- async def와 async for를 사용하여 비동기 제네레이터 함수 구현 가능
- 비동기 스트리밍 처리에 유용
Runtime Arguments 바인딩
- Runtime Arguments 바인딩
- Runnable 시퀀스 내에서 이전 Runnable의 출력이나 사용자 입력에 포함되지 않은 상수 인자를 전달할 때 사용
- Runnable.bind() 메서드를 통해 구현
- 주요 활용 사례:
∘ OpenAI Functions 기능 연결
∘ OpenAI tools 연결
폴백(fallback) 모델 지정
- 폴백 모델 지정
- LLM API 오류, 모델 출력 품질 저하 등의 문제에 대처하기 위한 기능
- with_fallbacks() 메서드를 사용하여 대체 모델 설정
- 특정 오류에 대해서만 fallback이 작동하도록 설정 가능
- 여러 fallback 모델 순차적 지정
- 여러 개의 대체 모델을 순차적으로 시도할 수 있음
- 첫 번째 모델 실패 시 다음 모델로 자동 전환
14. 체인(Chains)
- 체인 생성
- 이전의 7단계 과정을 하나로 묶어 RAG 파이프라인을 완성하는 단계
- LCEL 문법을 사용하여 체인 생성
문서 요약
- 주요 요약 방식
- Stuff: 모든 문서를 단일 프롬프트로 넣는 간단한 방식
- Map-reduce: 각 문서를 개별 요약 후 최종 요약으로 병합
- Refine: 문서를 순회하며 반복적으로 답변 업데이트
- Map-Reduce 방식
- Map 단계: 각 청크를 병렬로 요약
- Reduce 단계: 요약들을 하나의 최종 요약으로 통합
- 대규모 문서 처리에 유용하며 언어 모델의 토큰 제한 우회 가능

- Map-Refine 방식
- Map 단계: 문서를 작은 청크로 나누어 개별 요약 생성
- Refine 단계: 요약들을 순차적으로 처리하며 최종 요약 개선
- 문서의 순서를 유지하면서 점진적으로 요약 개선 가능

- Chain of Density (CoD) 기법
- GPT-4를 사용한 요약 생성 개선 기법
- 초기에 엔티티가 적은 요약 생성 후 누락된 중요 엔티티 반복 통합
- 정보 밀도와 가독성의 균형 조절
- 추상화와 정보 융합 개선
- Clustering-Map-Refine 방식
- 긴 문서의 효율적 요약을 위한 방법
- 문서를 N개 클러스터로 나누고 각 클러스터의 대표 문서 선정
- Map-Reduce 또는 Map-Refine 방식으로 요약 진행
- 비용 효율적이며 만족스러운 결과 도출 가능
SQL
- SQL 쿼리 생성 및 실행
create_sql_query_chain을 사용하여 SQL 쿼리 생성 체인 구축- SQLite 데이터베이스 연결 및 테이블 정보 확인
- ChatOpenAI 모델(gpt-3.5-turbo)을 사용하여 LLM 객체 생성
- 생성된 쿼리를
QuerySQLDataBaseTool로 실행
- 답변 생성 개선
- LCEL 문법을 사용하여 자연스러운 답변 생성
PromptTemplate,RunnablePassthrough,itemgetter등을 활용한 체인 구성
- SQL Agent 사용
create_sql_agent로 SQL Agent 생성- 복잡한 쿼리 실행 및 결과 해석 가능
구조화된 출력 체인(with_structered_output)
- 구조화된 출력 체인 구현
Quiz클래스를 정의하여 4지선다형 퀴즈 구조화ChatOpenAI(gpt-4o 모델)과ChatPromptTemplate을 사용하여 퀴즈 생성with_structured_output메서드로 구조화된 출력 생성
17. LangGraph
LangGraph 에 자주 등장하는 Python 문법이해
-
TypedDict와 타입 시스템
-
TypedDict의 특징
-
엄격한 타입 체크
class Person(TypedDict): name: str age: int job: str- 런타임이 아닌 개발 시점에서 타입 검사
- 각 키에 대한 타입 명시 필수
- IDE의 타입 체크 및 자동완성 지원
-
일반 dict와의 차이점
# TypedDict typed_dict: Person = {"name": "셜리", "age": 25, "job": "디자이너"} typed_dict["age"] = "35" # 타입 체커가 오류 감지 # 일반 dict sample_dict: Dict[str, str] = { "name": "테디", "age": "30", # 문자열 허용 "job": "개발자" }- 타입 불일치 시 IDE에서 즉시 오류 표시
- 정의되지 않은 키 추가 시 오류 발생
- 코드의 안정성과 유지보수성 향상
-
-
-
Annotated와 메타데이터
-
기본 구문
from typing import Annotated name: Annotated[str, "사용자 이름"] age: Annotated[int, "사용자 나이 (0-150)"] -
Pydantic과의 통합
class Employee(BaseModel): id: Annotated[int, Field(..., description="직원 ID")] name: Annotated[str, Field(..., min_length=3, max_length=50)] salary: Annotated[float, Field(gt=0, lt=10000)]- 필드 유효성 검사 규칙 정의
- 문서화와 메타데이터 추가
- 복잡한 데이터 모델 구현
-
LangGraph를 활용한 챗봇 구축 / LangGraph를 활용한 Agent 구축
-
LangGraph 상태 관리
- State 클래스 정의
class State(TypedDict): messages: Annotated[list, add_messages]add_messages리듀서로 메시지 누적- 상태 변화 추적 및 관리
- 타입 안정성 보장
- add_messages 동작 원리
def add_messages(left: list, right: list) -> list: # 기존 메시지와 새 메시지 병합 # 동일 ID의 메시지는 새 메시지로 대체 return merged_messages- 메시지 중복 방지
- 순서 보장
- 상태 일관성 유지
- State 클래스 정의
-
노드 시스템
-
기본 노드 구현
def chatbot(state: State): answer = llm_with_tools.invoke(state["messages"]) return {"messages": [answer]}- 상태 기반 처리
- 결과값 타입 검증
- 메시지 처리 로직 캡슐화
-
도구 노드 구현
class BasicToolNode: def __init__(self, tools: list) -> None: self.tools_list = {tool.name: tool for tool in tools} def __call__(self, inputs: dict): message = inputs.get("messages", [])[-1] outputs = [] for tool_call in message.tool_calls: tool_result = self.tools_list[tool_call["name"]].invoke( tool_call["args"] ) outputs.append( ToolMessage( content=json.dumps(tool_result), name=tool_call["name"], tool_call_id=tool_call["id"], ) ) return {"messages": outputs}- 도구 호출 관리
- 결과 변환 및 포맷팅
- 에러 처리
-
-
조건부 라우팅 시스템
- 라우터 함수 구현
def route_tools(state: State): if messages := state.get("messages", []): ai_message = messages[-1] if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0: return "tools" return END- 상태 기반 분기 처리
- 도구 호출 감지
- 실행 흐름 제어
- 조건부 엣지 설정
graph_builder.add_conditional_edges( source="chatbot", path=route_tools, path_map={"tools": "tools", END: END}, )- 동적 라우팅 구성
- 복잡한 실행 흐름 관리
- 종료 조건 처리
- 라우터 함수 구현
-
그래프 구성 및 실행
-
그래프 빌더 설정
graph_builder = StateGraph(State) graph_builder.add_node("chatbot", chatbot) graph_builder.add_node("tools", tool_node) graph_builder.add_edge(START, "chatbot") graph_builder.add_edge("tools", "chatbot")- 노드 간 연결 구성
- 실행 순서 정의
- 그래프 구조 최적화
-
실행 및 스트리밍
graph = graph_builder.compile() for event in graph.stream({"messages": [("user", question)]}): for key, value in event.items(): print(f"\nSTEP: {key}\n") display_message_tree(value["messages"][-1])- 이벤트 기반 실행
- 단계별 결과 모니터링
- 메시지 트리 시각화
-
-
도구 통합
-
도구 설정
from langchain_teddynote.tools.tavily import TavilySearch tool = TavilySearch(max_results=3) tools = [tool] llm_with_tools = llm.bind_tools(tools)- 외부 API 통합
- 도구 설정 최적화
- LLM 바인딩
-
도구 실행 결과 처리
tool_result = self.tools_list[tool_call["name"]].invoke(tool_call["args"]) tool_message = ToolMessage( content=json.dumps(tool_result), name=tool_call["name"], tool_call_id=tool_call["id"] )- 결과 직렬화
- 메시지 변환
- 에러 핸들링
-
LangGraph
From Basics to Advanced: Exploring LangGraph
- 기본 아키텍처와 동작 원리
- 그래프 구조
- StateGraph 클래스 기반 구현
builder = StateGraph(AgentState) builder.add_node("router", router_node) builder.add_edge('router', END) graph = builder.compile(checkpointer=memory) - 상태 관리
- TypedDict를 통한 상태 정의
class AgentState(TypedDict): messages: Annotated[list[AnyMessage], operator.add] question: str answer: str feedback: str - 상태 업데이트 메커니즘
- operator.add로 메시지 누적
- 노드별 독립적 상태 접근/수정
- 체크포인팅을 통한 상태 지속성
- 주요 컴포넌트 상세 분석
- 노드 타입
- LLM 노드
def llm_node(state: AgentState): messages = state['messages'] response = model.invoke(messages) return {'messages': [response]}- 도구 실행 노드
def tool_node(state: AgentState): tool_calls = state['messages'][-1].tool_calls results = [tool.invoke(call.args) for call in tool_calls] return {'messages': results}- 라우팅 노드
def route_node(state: AgentState): return state['question_type'] - 조건부 엣지 구현
builder.add_conditional_edges( "router", route_question, { 'DATABASE': 'database_expert', 'LANGCHAIN': 'langchain_expert', 'GENERAL': 'general_assistant' } )
- 고급 기능 구현
- 지속성(Persistence) 시스템
from langgraph.checkpoint.sqlite import SqliteSaver memory = SqliteSaver.from_conn_string(":memory:") graph = builder.compile(checkpointer=memory) - 스트리밍 처리
for event in graph.stream({ 'question': question, }, thread): for v in event.values(): v['messages'][-1].pretty_print()
- 멀티 에이전트 시스템 구현
-
라우터 에이전트
def router_node(state: MultiAgentState): messages = [ SystemMessage(content=question_category_prompt), HumanMessage(content=state['question']) ] response = model.invoke(messages) return {"question_type": response.content} -
전문가 에이전트 구현
# SQL 전문가 def sql_expert_node(state: MultiAgentState): sql_agent = create_react_agent(model, [execute_sql], state_modifier = sql_expert_system_prompt) messages = [HumanMessage(content=state['question'])] result = sql_agent.invoke({"messages": messages}) return {'answer': result['messages'][-1].content} # 검색 전문가 def search_expert_node(state: MultiAgentState): search_agent = create_react_agent(model, [tavily_tool], state_modifier = search_expert_system_prompt) return {'answer': result['messages'][-1].content}
- 휴먼 인 더 루프(Human-in-the-Loop) 구현
-
기본 구현
def human_feedback_node(state: MultiAgentState): pass builder.compile(checkpointer=memory, interrupt_before=['human']) -
고급 구현 (에이전트 기반)
from langchain_community.tools import HumanInputRun human_tool = HumanInputRun() editor_agent = create_react_agent(model, [human_tool])
- 성능 최적화와 모범 사례
- 상태 관리 최적화
- 메시지 히스토리 트리밍
- 요약을 통한 컨텍스트 압축
- 스레드별 독립적 메모리 관리
- 에러 처리
try: result = tool.invoke(args) except Exception as e: return {'error': str(e)}
- 실제 응용 시나리오
- 고객 지원 시스템
- 질문 분류
- 전문가 라우팅
- 사람 검토/승인
- 답변 편집/개선
- 데이터 분석 워크플로우
- SQL 쿼리 실행
- 결과 분석
- 보고서 생성
LangGraph 가이드북
Part 1. 랭그래프 LangGraph 기초
1-1. 랭그래프 LangGraph 소개 / 1-2. LangGraph 환경 설정 및 기본 사용법
- LangGraph의 핵심 기술적 특징
- 상태 기반 그래프 구조를 사용하여 AI 워크플로우를 구현
- 노드와 엣지로 구성된 유연한 그래프 구조 제공
- 상태 관리를 위한 체크포인팅 기능 지원
- 복잡한 시스템을 위한 서브그래프 모듈화 기능
- LangGraph vs LangChain 기술적 차이점
- 구조적 차이
- LangGraph: 그래프 기반으로 복잡한 워크플로우 구현
- LangChain: 선형적인 체인 및 에이전트 기반 구조
- 상태 관리 방식
- LangGraph: 명시적이고 세밀한 상태 제어 가능
- LangChain: 암시적이고 자동화된 상태 관리
- 구조적 차이
- 기술적 확장성
- 다양한 LLM 모델과의 통합 가능
- 맞춤형 워크플로우 구현을 위한 유연한 그래프 구조
- 모듈화된 서브그래프를 통한 시스템 확장성
- 체크포인팅을 통한 장기 실행 태스크 지원
- 개발 환경 주의사항
- 모델 버전 관리 필요 (각 LLM 제공자의 최신 버전 확인)
- API 한도 및 사용량 모니터링 필요
- 적절한 온도(temperature) 및 토큰 제한 설정 중요
- 각 모델의 특성에 따른 최적화 고려 필요
1-3. StateGraph 이해하기
-
LangGraph의 핵심 구성 요소
- StateGraph가 기본 구조로 사용되며 노드와 엣지로 구성된 방향성 그래프 형태
- 세 가지 주요 구성 요소
- State: 상태 관리를 위한 공유 데이터 구조
- Nodes: 실제 작업을 수행하는 Python 함수들
- Edges: 노드 간 연결과 전이 조건을 정의
-
State (상태) 관리 특징
- TypedDict 또는 Pydantic BaseModel을 사용하여 상태 스키마 정의
- 모든 노드가 공유하는 중앙 집중식 상태 관리 시스템
- 그래프 실행 중 지속적으로 업데이트되는 동적 상태 객체
-
Node (노드) 구현 세부사항
- 각 노드는 Python 함수로 구현
- 함수 시그니처: 현재 상태를 입력으로 받아 업데이트된 상태를 반환
- add_node() 메서드를 통해 그래프에 노드 추가
- 병렬 실행 가능한 구조 지원
-
Edge (엣지) 특성
- START와 END라는 특별한 상수로 그래프의 시작과 종료 지점 정의
- add_edge() 메서드로 노드 간 연결 설정
- 조건부 엣지를 통한 동적 플로우 제어 가능
- 상태 전달을 위한 통로 역할
-
실행 메커니즘
- 슈퍼스텝(Superstep) 개념으로 실행
- 활성화된 노드들의 병렬 실행
- 메시지 기반 노드 활성화/비활성화
- 그래프 실행 과정
- StateGraph 인스턴스 생성
- compile() 메서드로 실행 가능한 형태로 변환
- invoke() 메서드로 초기 상태와 함께 실행
- 모든 노드 비활성화 시 종료
- 슈퍼스텝(Superstep) 개념으로 실행
-
기술적 특징
- 재귀적 실행 지원으로 반복 작업 처리 가능
- 체크포인터를 통한 상태 저장 및 복구 기능
- 타입 힌팅을 통한 안전한 상태 관리
- LangChain 문법 구조 준용
-
구현 예시 코드 구조
from typing import TypedDict from langgraph.graph import StateGraph, START, END class MyState(TypedDict): counter: int graph = StateGraph(MyState) def increment(state): return {"counter": state["counter"] + 1} graph.add_node("increment", increment) graph.add_edge(START, "increment") graph.add_edge("increment", END) app = graph.compile() result = app.invoke({"counter": 0})
Prompt Engineering & RAG
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval (2024)
Implementing Advanced Prompt Engineering with Amazon Bedrock (2024, AWS)
- COSTAR 프롬프트 프레임워크: Context, Objective, Style, Tone, Audience, Response로 구성된 체계적 프롬프트 작성법
- Chain-of-Thought (CoT) 프롬프팅: 복잡한 문제를 단계별로 해결, 제로 샷과 퓨 샷 접근법 포함
- Tree of Thoughts (ToT) 프롬프팅: 문제를 트리 구조의 하위 문제로 분해하여 해결
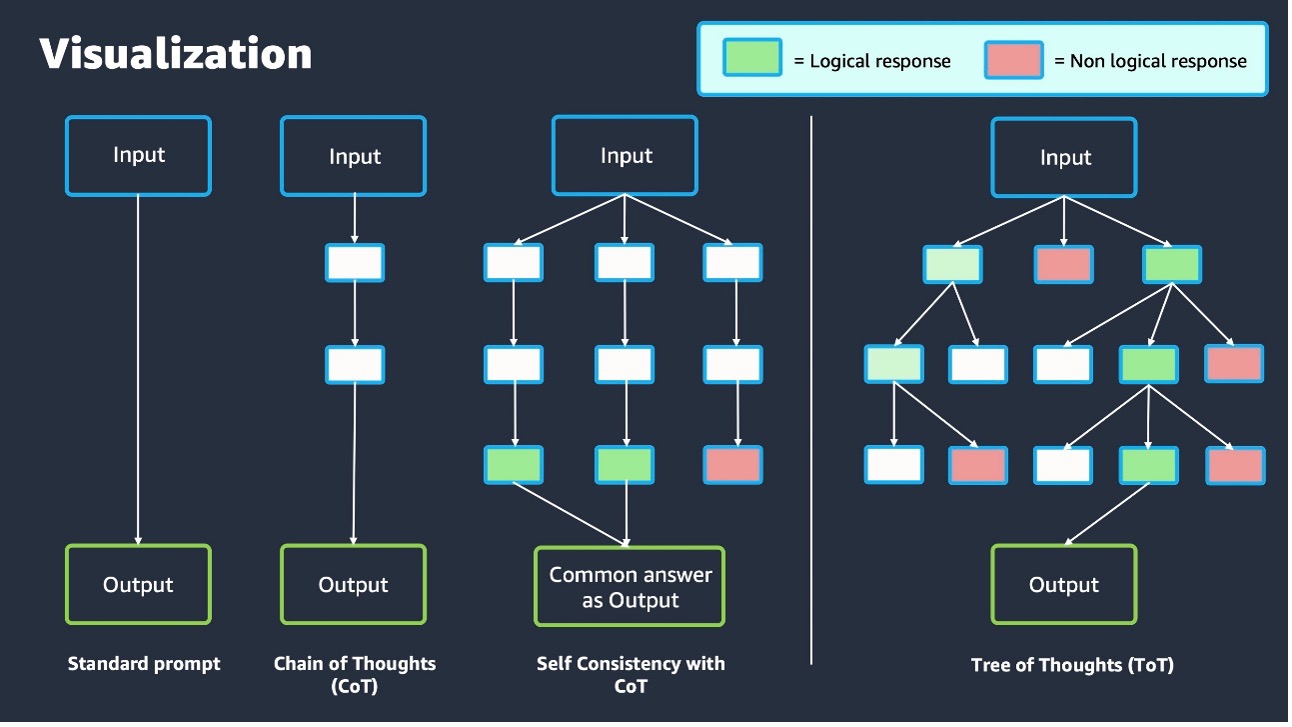
- 프롬프트 체이닝: 여러 모델을 연결하여 복잡한 작업 수행, Amazon Bedrock의 Prompt Flows 활용
- 프롬프트 카탈로그: 재사용 가능한 프롬프트 템플릿 모음, Amazon Bedrock의 Prompt Management 기능 사용
- 보안 기법: Amazon Bedrock의 Guardrails, 고유 구분자 사용, 위협 탐지 지침 등으로 프롬프트 공격 방어
- 프롬프트 엔지니어링 모범 사례: 충분한 컨텍스트 제공, 단순성과 복잡성의 균형, 반복적 실험 등
- 전체 워크플로: 사용자 입력부터 최종 출력까지의 프로세스와 각 단계의 보안 조치 설명
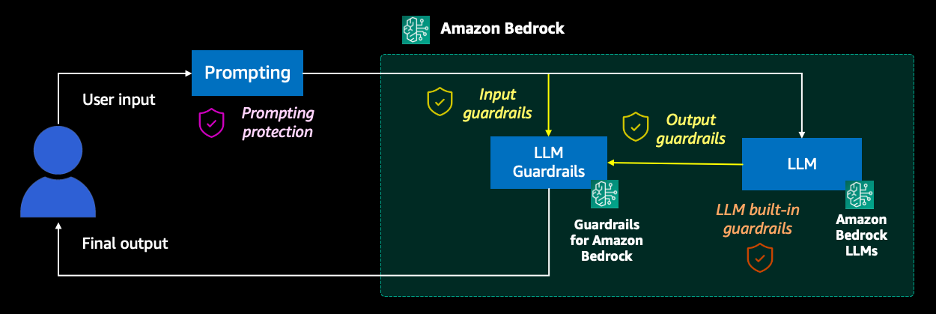
- 코드 샘플
참고
- LangChain (Code, Docs)
- LangGraph (Code, Docs)
- A Complete LangChain Guide

Sr. Data Scientist at AWS