4. 메모리 관리
컴퓨터의 주 목적: 프로그램 실행
프로그램 및 이 프로그램이 사용하는 자료는 실행 도중에 최소한 일부는 주기억장치에 있어야 함.
현대 컴퓨터 시스템은 실행 중에 여러 프로세스를 메모리에 올리고 관리함. 그러므로 여러 메모리 관리 스킴이 존재. 메모리 관리 스킴은 시스템의 하드웨어 설계와 같은 요소에 따라 결정. 대부분의 알고리듬은 하드웨어 종속적.
9. 주기억장치
여러 메모리 관리 방법. 원시적인 하드웨어적인 방법에서 페이징을 쓰는 방법까지 다룸. 각각 장단점 존재.
단원 목표
- 논리적 / 물리적 주소의 차이점 이해 및 주소 변환에서의 주기억장치 유닛(MMU)의 역할 이해
- 연속 메모리 할당을 위한 최초, 최적, 최악 적합 전략 적용
- 내부 및 외부 파편화의 차이 이해
- 변환 색인 버퍼(TLB)를 갖는 페이징 시스템에서 논리적 주소를 물리적 주소로 번역
- 계층적 페이징, 해시 페이징, 역 페이지 테이블 이해
- IA-32, x86-64, ARMv8 아키텍처의 주소 변환 이해
9.1. 배경
메모리는 거대한 바이트의 배열로 구성되며, 각 바이트는 자신만의 주소를 가짐. CPU는 프로그램 카운터의 값에 따라 메모리로부터 명령어를 가져옴. 이 명령어를 통해 추가적으로 특정 메모리 주소로부터 무언가를 불러오거나 저장을 할 수도 있음.
통상적인 명령어 실행 사이클을 예를 들어 보면 우선 메모리로부터 명령어를 가져온 다음, 명령어를 해독하여 메모리로부터 연산자 등을 가져올 수도 있을 것임. 명령어가 피연산자들에 대해 실행된 후엔 그 결과를 메모리에 저장할 수도 있음. 메모리 장치는 오로지 메모리 주소의 흐름만 볼 뿐임. 이게 어떻게 생성되는지(명령어 카운터, 인덱싱, 인다이렉션, 리터럴 주소 등) 혹은 얘네가 뭔지(명령어인지 자료인지) 궁금하지 않음. 그렇기에 프로그램이 어떻게 메모리 주소를 생성하는지는 무시해도 됨. 오로지 실행 중인 프로그램이 생성하는 메모리 주소의 연속이 궁금할 뿐임.
이제 메모리 관리에 핵심적인 내용 다룰 것: 기본 하드웨어, 기호적인(논리적인) 메모리 주소를 실제 물리 주소에 바인딩하기, 논리 및 물리 주소 구분.
컴파일 시나 로드 시에 주소 바인딩 시 논리 주소와 물리 주소가 동일함. 실행 시 주소 바인의 경우 둘이 다름. 이 경우 논리 주소를 가상 주소 virtual address라 부름.
9.1.1. 기본 하드웨어
주기억장치와 레지스터가 CPU가 직접 접근할 수 있는 유일한 다목적 기억장치임. 메모리 주소를 입력변수로 받는 기계 명령어는 있어도 디스크 주소를 받는 놈은 없음. 그러므로 실행 가능한 모든 명령어와 이 명령어가 사용할 모든 자료는 반드시 직접 접근 가능한 기억장치에 저장되어있어야함. 그렇지 않다면 CPU가 접근할 수 있도록 직접 접근 가능한 기억장치에 옮겨 놔야함.
레지스터는 보통 CPU 한 사이클에 접근 가능. 몇몇 CPU 코어는 명령어 해독과 레지스터에 있는 애들에 대한 간단한 연산 정도는 클락 틱마다 한 개 이상의 연산은 해줄 수 있음. 근데 주기억장치는 아님. 이건 메모리 버스를 통해 거래를 해줘야 함. 메모리 접근 완료하는데 CPU 사이클 여러 개가 쓰일 수도 있음. 보통 이럴 때 프로세서가 지연 stall을 해야할 수도 있음. 당장 실행 중인 명령어를 완료할 자료가 없으니까. 이건 메모리 접근의 주파수 때문에 참을 수 없는 상황임. 해결법은 CPU와 주기억장치 사이에 빠른 메모리를 추가하는 것으로, CPU 칩 안에 캐시 cache 같은 걸 추가함. CPU에 내장된 캐시를 관리하기 위해 하드웨어는 자동으로 운영체제 제어 없이 메모리 접근을 상당히 빠르게 해줌. (5.5.2 절에서 메모리 지연 상태에서 다중스레드 코어는 지연 상태의 스레드에서 다른 하드웨어 스레드로 바꿔줬었음.)
물리 메모리 접근 속도 뿐만 아니라 정확한 연산도 보장해야함. 올바른 시스템 연산을 위해선 운영체제를 사용자 프로세스로의 접근으로부터 보호해야함. 운영체제가 보통 CPU와 메모리 접근 간에는 딱히 개입을 안하기 때문임(성능 이슈로...). 하드웨어가 이를 여러 방법으로 처리함. 그중 하나를 소개함.
우선 각 프로세스가 구분된 메모리 공간을 가짐을 보장해야함. 프로세스 당 메모리 공간을 갖게 되면 프로세스끼리 보호를 해줄 수 있으며 동시성을 위해 여러 프로세스를 동시에 메모리에 올리기 위해선 제일 기초적인 과정임. 메모리 공간 나누려면 프로세스가 접근 가능한 합법 주소 범위를 결정하고 프로세스가 해당 범위만 접근하도록 보장해야함. 이 보호는 아래 그림에서처럼 보통 베이스와 리미트 두 레지스터로 제공 가능. 베이스 레지스터 base register란 최소 합법 물리 메모리 주소를 의미; 리미트 레지스터 limit register란 범위의 크기를 의미.
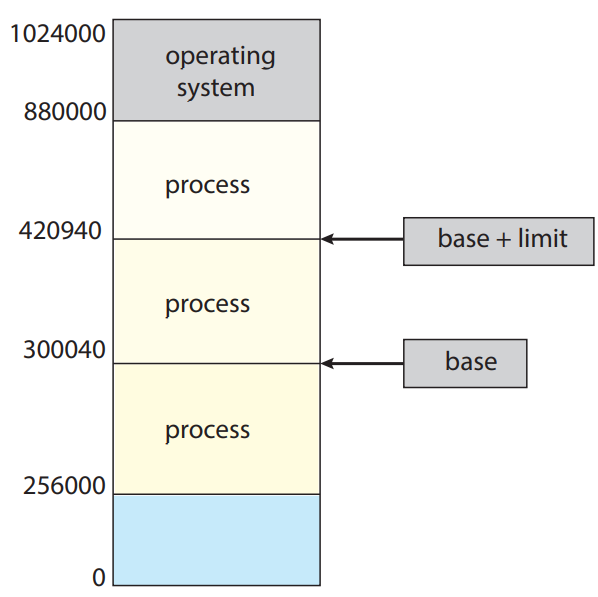
CPU 하드웨어가 사용자 모드에서 레지스터로 생성한 모든 주소를 비교해주는 것으로 메모리 공간 보호를 해줄 수 있음. 사용자 모드에서 운영체제 메모리나 다른 사용자의 메모리에 접근하면 운영체제에 트랩을 보내게 되며, 이를 치명적인 오류로 간주함. 아래 그림 참조. 이 스킴을 통해 사용자 프로그램이 (의도적이든 의도적이지 않든) 운영체제나 다른 사용자의 코드나 자료 구조를 수정하는 것을 방지해줌.
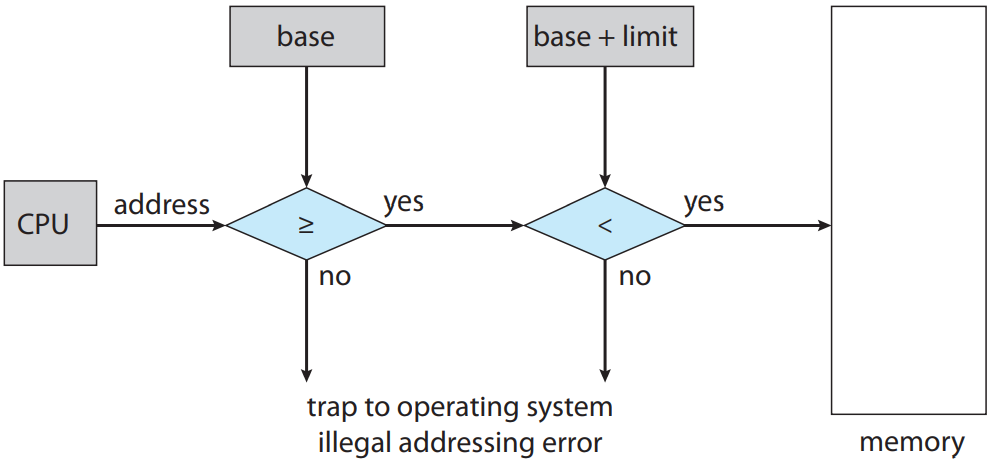
커널 모드에서 실행 중인 운영체제의 경우 운영체제 메모리는 사용자의 메모리는 전부 접근 가능함. 즉 제한이 없음. 이를 통해 운영체제가 사용자 프로그램을 사용자 메모리에 올릴 수 있도록 해주고, 오류 발생 시 이를 버리고, 시스템 호출로 매개변수에 접근 및 수정할 수 있게 해주고, 사용자 메모리로부터, 그리고 사용자 메모리로 입출력을 수행할 수 있게 해주는 등의 여러가지 서비스를 수행할 수 있게 해줌. 예를 들어 다중프로세서 시스템에서 운영체제가 반드시 문맥 교환을 수행해야할 때 한 프로세서의 상태를 레지스터에서 주기억장치로 저장해야 다음 프로세스의 문맥을 주기억장치에서 레지스터로 올릴 수 있음.
9.1.2. 주소 바인딩
보통 프로그램은 디스크에 이진 실행 가능한 파일로 저장이 됨. 실행하려면 우선 프로그램을 메모리에 올리고 프로세스의 문맥에 올려져야(2.5 절 참고) 실행 가능한 CPU에서 실행할 수 있음. 프로세스 실행 중에 메모리로부터 명령어 및 자료에 접근함. 나중에 종료되면 메모리는 다른 프로세스가 사용해야 되니 뺏김.
대부분의 시스템은 사용자 프로세스가 물리 메모리 아무데나 있게 해줄 수 있음. 그래서 컴퓨터의 주소 공간이 00000에서 실행하더라도 사용자 프로세스의 주소 공간에 00000에서 시작하는 것은 아닌 것임.
대부분의 경우 사용자 프로그램은 여러 단계를(몇 가지는 선택적인 단계일 수도) 거치고 나서야 실행됨. 아래 그림 참고. 주소는 여러 방법으로 표현 가능. 소스 프로그램에서의 주소는 보통 기호적임(변수 count 등). 컴파일러는 보통 이런 기호적인 주소를 위치를 바꿀 수 있는 주소("이 모듈의 시작점으로부터 14바이트 떨어져있는 곳" 등)로 바인딩을 함. 링커나 로더(2.5 절 참고)가 이후에 이 위치를 바꿀 수 있는 주소를 절대 주소(74014 등)로 바인딩해줌. 각 바인딩은 한 주소 공간으로부터 다른 주소 공간으로의 매핑임.
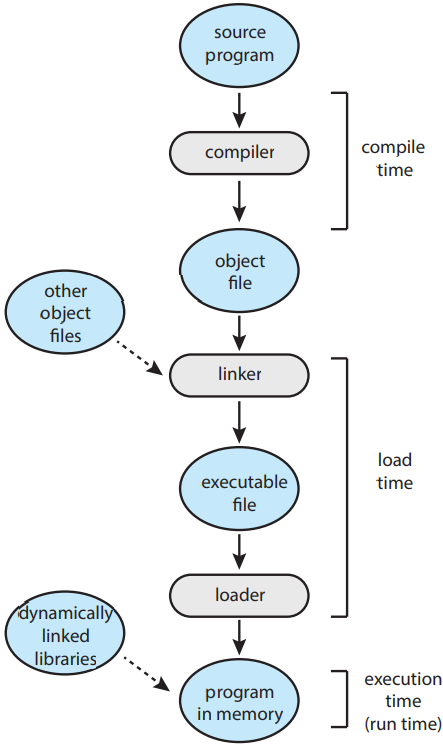
보통 명령어와 자료를 메모리 주소로 바인딩하는 것은 다음 중 아무 때나 일어날 수 있음:
- 컴파일 시 compile time. 컴파일 시 프로세스가 메모리 어디에 있을 지를 결정할 수 있다면 절대 코드 absolute code가 생성될 것임. 즉, 만약 사용자 프로세스가 위치 R에서부터 생길 것을 안다면, 생성된 컴파일러 코드는 해당 위치에서 시작할 것임. 나중에 시작 위치가 바뀐다면 코드를 재컴파일해야할 것임.
- 로드 시 load time. 컴파일 시에 프로세스가 메모리 어디에 위치할 지 모른다면 컴파일러는 반드시 재배치 가능한 코드 relocatable code를 생성해야 함. 이 경우 최종 바인딩은 로드 시까지로 지연됨. 시작 주소가 바뀌면 오로지 사용자 코드에 바뀐 값만 합쳐주어 다시 로드해주면 됨.
- 실행 시 execution time. 실행 중에 한 메모리 세그먼트에서 다른 세그먼트로 옮길 수 있다면 바인딩은 실행 시까지로 지연 가능함. 단, 특정 하드웨어에서만 가능함. 대부분의 운영체제가 이 방법을 사용함.
9.1.3. 논리적 주소 공간 vs 물리적 주소 공간
CPU에서 생성한 주소를 논리 주소 logical address라 부름. 반면에 메모리 장치에서 인식하는 주소, 즉 메모리의 메모리 주소 레지스터 memory-address register에 저장하는 주소를 물리 주소 physical address라 부름.
컴파일 시나 로드 시에 생성한 논리 주소는 물리 주소와 동일하지만, 실행 시에 생성한 논리 주소는 물리 주소와 다름. 이 경우 논리 주소를 가상 주소 virtual address라 부름. 앞으로 논리 주소와 가상 주소를 사실상 동일하게 부를 것임. 프로그램이 생성한 가상 주소 집합을 가상 주소 공간 logical address space라 부름. 반대로 물리 주소 집합을 물리 주소 공간 physical address space라 부름.
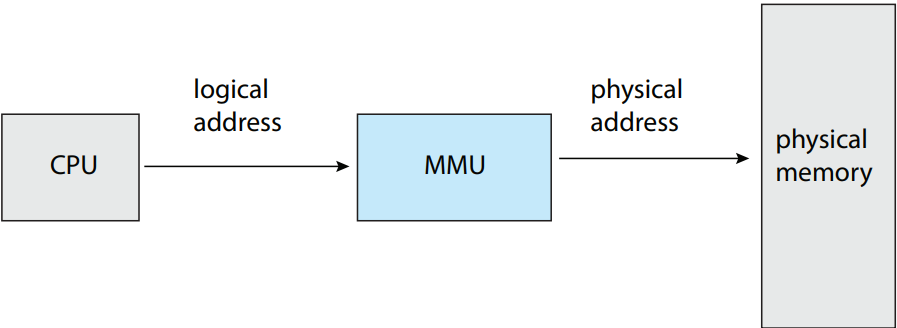
시행 시 가상 주소를 물리 주소로 매핑해주는 과정은 메모리 관리 장치 memory-management unit (MMU)라는 하드웨어 장치에서 담당함. 위의 그림 참고. 매핑 방법엔 여러 가지 방법이 있음. 여기서는 9.1.1 절에서 다룬 베이스 레지스터 스킴으로 일반화하여 단순한 MMU 스킴으로 이해. 베이스 레지스터를 이제는 재배치 레지스터 relocation register라 부를 것임. 재배치 레지스터의 값은 사용자 프로세스의 주소가 메모리에 보내질 때 사용자 프로세스가 생성한 모든 주소에 더해짐. 아래 그림 참고.
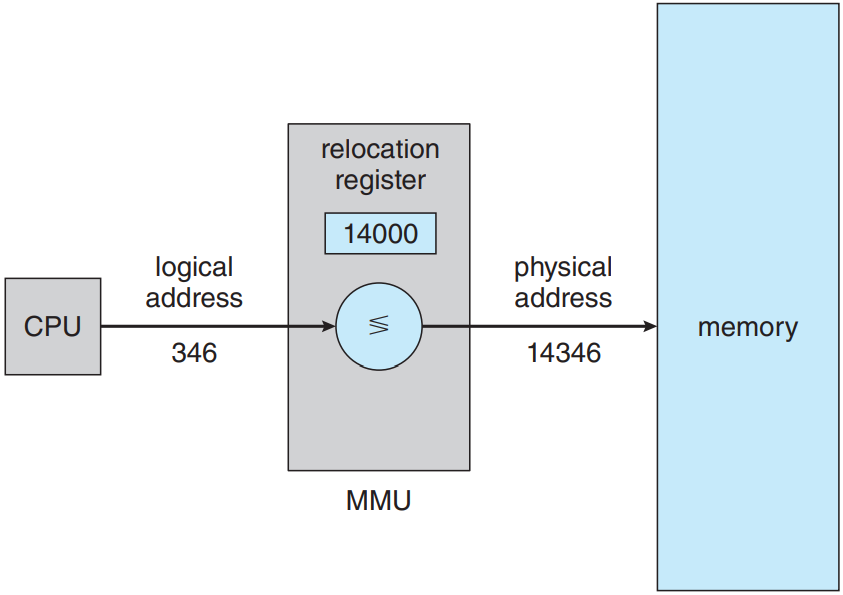
사용자 프로그램은 절대로 실제 물리 주소에 접근하지 않음. 프로그램이 346라는 위치에 포인터를 생성하고 메모리에 저장하고 조작하고 다른 주소와 비교는 할 수 있더라도, 전부 346라는 값을 갖고 처리를 할 뿐임. 오로지 메모리 주소로서 사용될 때(간접 로드 혹은 저장 등)만 베이스 레지스터에 의해 재배치될 뿐임. 사용자 프로그램은 가상 주소를 다룸. 메모리 매핑 하드웨어가 가상 주소를 물리 주소로 변환함. 참조한 메모리 주소의 최종 위치는 참조를 하기 전까지는 모르는 것임.
이제 두 가지 주소를 알아보았음: 가상 주소(0에서 max까지)와 물리 주소(R + 0에서 R + max까지. R은 베이스 값). 사용자 프로그램은 오로지 가상 주소만 생성하며, 프로세스가 0에서 max 사이의 메모리 위치에서 실행한다고 생각함. 허나 이 가상 주소는 사용하기 전에 반드시 물리 주소에 매핑되어야 함. 가상 메모리 공간이 물리 메모리 공간에 바인딩 되어있다는 개념이 올바른 메모리 관림의 핵심임.
9.1.4. 동적 적재
좀 더 메모리 공간을 효율적으로 사용하기 위해 동적 적재 dynamic loading를 사용할 수 있음. 동적 적재를 사용하면 호출하기 전까지는 루틴이 적재되지 않음. 모든 루틴은 디스크에 재배치 가능한 형태로 저장되어있음. 주프로그램이 메모리에 적재되어 실행이 됨. 이때 한 루틴이 다른 루틴을 호출하게 되면 호출자가 호출한 루틴들이 적재되어있는지 우선 확인함. 적재 안 되어있음 재배치 가능한 링킹 로더를 불러와 호출한 루틴들을 메모리에 적재하여 프로그램의 주소 테이플을 갱신하여 변화를 줌. 이후 제어권을 새롭게 적재한 루틴에 넘겨줌.
동적 적재의 장점은 루틴이 필요할 때만 적재된다는 점임. 특히 오류 루틴과 같은 매우 규모가 큰 코드를 가끔만 사용할 때 유용함.
동적 적재는 따로 운영체제의 특별한 지원을 필요로 하지는 않음. 이 방법으로 뽕을 뽑는 건 사용자의 몫임. 물론 운영체제가 동적 적재를 구현할 때 도움이 되는 라이브러리 루틴을 제공해주어 프로그래머를 도와줄 수는 있음.
9.1.5. 동적 링킹 및 공유 라이브러리
동적 링크 라이브러리 dynamically linked libraries (DLLs)란 사용자 프로그램이 실행될 때 링크된 시스템 라이브러리를 의미함(위에서 세번째 그림 참고). 몇몇 운영체제는 정적 링크 static linking만 지원하기도 함. 즉, 시스템 라이브러리가 마치 다른 오브젝트 모듈처럼 간주를 해서 이진 프로그램 이미지로 로더에 의해 합쳐짐. 동적 링크는 반대로 동적 로드와 유사함. 물론 로드와는 달리 링크가 실행 시에 행해짐. 이건 보통 표준 C 언어 라이브러리와 같은 시스템 라이브러리에서 사용함. 이 기능이 없다면 시스템의 프로그램은 적어도 사용한 언어 라이브러리(혹은 적어도 호출한 루틴들)의 복사본을 실행 이미지에 갖고 있어야함. 이러면 실행 이미지의 크기가 커질 뿐만 아니라 주기억장치의 용량을 낭비하기도 함. DLL의 두번째 장점으로는 이 라이브러리를 여러 프로세스가 공유할 수 있어 주기억장치에 DLL이 하나만 있어도 된다는 점임. 그래서 DLL을 공유 라이브러리라 부르기도 하며 Windows와 Linux 시스템에서 널리 사용함.
프로그램이 동적 라이브러리에 있는 루틴을 참조하면 로더가 DLL을 찾아내 필요 시 메모리에 적재를 한 다음 동적 라이브러리의 함수를 참조한 주소를 DLL이 저장된 메모리의 위치로 수정해줌.
동적 링크 라이브러리는 라이브러리 업데이트(버그 픽스 등)로 확장해줄 수 있음. 라이브러리는 또한 새로운 버전으로 교체도 가능하며, 해당 라이브러리를 참조한 프로그램은 자동으로 새 버전을 사용할 것임. 동적 링크가 없다면 이를 참조한 모든 프로그램들은 다시 링크를 해서 새 라이브러리에 접근권을 어덩야 함. 프로그램이 실수로 새로운, 호환 불가한 라이브러리를 호환할 수도 있기에 프로그램과 라이브러리에 버전 정보를 넣어줘야함. 메모리에 하나 이상의 버전을 적재해줄 수 있으며, 각 프로그램은 가진 버전 정보를 통해 어떤 라이브러리 복사본을 사용할지를 결정. 얼마 안 바뀐 경우 같은 버전 수를 사용하면 되겠지만, 변동사항이 크면 버전 수가 증가했을 것임. 이를 통해 호환성 보장 가능.
동적 적재와는 달리 동적 링크와 공유 라이브러리는 일반적으로 운영체제가 좀 도와줘야함. 메모리에 있는 프로세스가 서로 보호하고 있다면 운영체제가 한쪽이 필요한 루틴이 다른 쪽의 메모리 공간에 있를 확인할 수 있으며, 여러 프로세스가 같은 메모리 공간을 쓰도록 해줄 수 있음. 이 개념을 바탕으로 어떻게 여러 프로세스가 DLL을 공유하는 지를 9.3.4 절에서 볼 수 있음.
9.2. 연속 메모리 할당
운영체제와 여러 사용자 프로세스들은 반드시 주기억장치에 기억되어 있어야 함. 그러므로 가장 효율적으로 할당해야함. 여기서는 초기 방법 중 하나인 연속 메모리 할당만 설명함.
메모리는 보통 운영체제 영역이랑 사용자 프로세스 영역 둘로 구분. 운영체제의 주소를 더 낮은 걸로 줄 수도, 더 높은 걸로 줄 수도 있는데, 이건 인터럽트 벡터의 위치와 같은 요소에 의해 결정되는 거임. 근데 대부분의 운영체제(Linux, Windows 등)에서는 높은 메모리에 놓으니까 우리도 그렇다고 생각하고 논의할 것.
동시에 메모리에 여러 사용자 프로세스가 있게 해줘야함. 그러므로 메모리에 올라갈 프로세스들에게 어떻게 메모리를 할당해줄지를 결정해야함. 연속 메모리 할당 contiguous memory allocation을 사용할 경우 각 프로세스는 메모리의 어떤 단일 구역에 들어가게 되는데, 이때 이 구역은 다음 프로세스가 들어갈 구역에 연속임.
9.2.1. 메모리 보호
프로세스가 자기 메모리가 아닌 곳으로 접근 못하게 막아야함. 이거 이미 다뤘던 개념 두 개 섞으면 됨. 만약 시스템에 재배치 레지스터(9.1.3 절)라는 개념이랑 리미트 레지스터(9.1.1 절)라는 개념이 둘 다 있으면 보호 손쉽게 가능. 이러면 각 가상 주소는 반드시 리미트 레지스터의 범위 내에 존재해야함. MMU가 가상 주소에 재배치 레지스터를 더해줘서 동적으로 매핑을 해줌. 이 매핑된 주소는 메모리에 보내지게 됨.
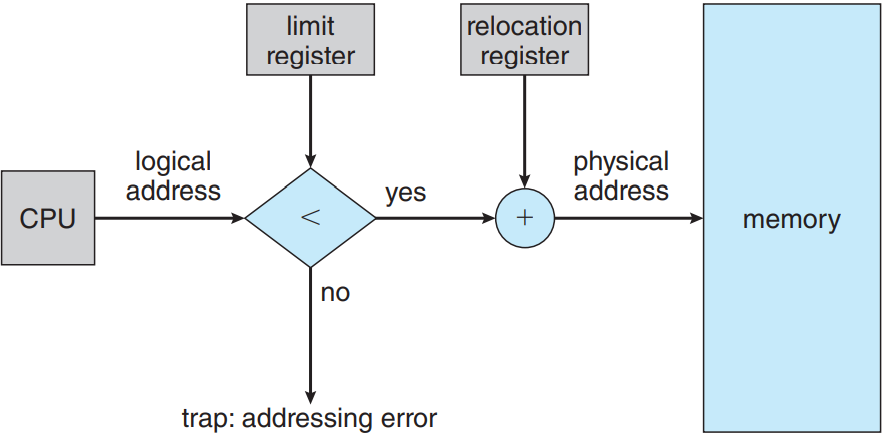
CPU 스케줄러가 실행할 프로세스를 선택하게 되면 디스패처가 문맥 교환의 일부 과정으로서 올바른 값의 재배치 레지스터랑 리미트 레지스터를 적재해줌. CPU가 생성한 모든 주소는 이 레지스터 값으로 확인하게 될테니 운영체제와 다른 사용자 프로그램과 자료가 현재 프로세스에 의해 수정되지 않도록 보호해줄 수 있음.
재배치 레지스터로 효과적으로 운영체제의 크기를 동적으로 바꿔줄 수 있음. 이게 중요한 이유가 있음. 만약 운영체제가 장치 드라이버를 위한 코드랑 버퍼 공간이 있다고 할 때, 장치 드라이버가 현재 사용 중이 아니라면 굳이 메모리에 올릴 이유가 없음. 필요할 때 메모리에 올리면 됨.
9.2.2. 메모리 할당
메모리 할당하는 가장 간단한 법은 프로세스를 메모리에 딱 넣을 수 있을 만큼의 크기로 분할하여 넣어주는 것임. 이런 가변 분할 variable partition 스킴에서는 운영체제가 메모리 중 어느 부분이 현재 사용 중인지를 기록해야함. 처음엔 전부 사용 가능한 상태일 것이고, 하나의 거대한 메모리 덩어리, 어떻게 보면 하나의 거대한 구멍 hole이라고 할 수 있음. 나중에 보면 알겠지만 메모리는 구멍이 송송 난 상태가 될 것임.
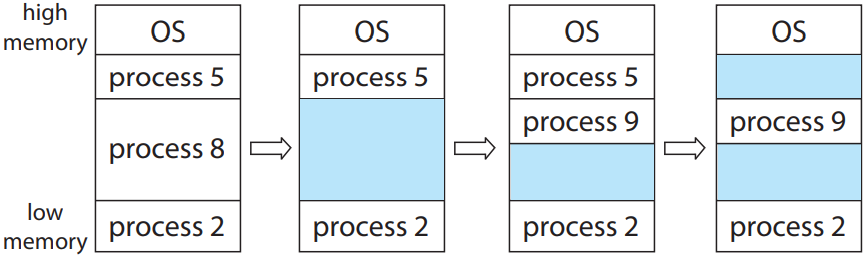
프로세스가 시스템에 들어오면 우선 운영체제가 프로세스별로 메모리가 얼마나 필요한지를 확인하고 메모리 할당을 결정해야함. 할당이 되면 메모리에 프로세스를 올려서 CPU를 얻기 위해 다른 프로세스들과 경쟁하게 만들어주면 됨. 프로세스 종료되면 메모리 반환할 것이고, 운영체제는 이걸 나중에 다른 애들한테 주거나 하면 됨.
만약 프로세스가 "메모리 줘(벅벅)"하는데 메모리가 충분하지 않다면?

그냥 프로세스 요청 거절하고 오류 메시지 주면 됨. 아니면 이런 프로세스를 대기 큐에 넣어주면 됨. 메모리 나중에 누가 반환해서 공간 나면 대기 큐 보고 프로세스 메모리에 올릴 만큼 공간 남았는지 판단해서 처리할 것임.
일반적으로는 메모리가 나중에 보면 여러 크기의 구멍으로 송송 뚫려있는 형태일 것임. 나중에 프로세스가 메모리 줘 응애하면 그 크기만큼의 구멍을 찾아줘야함. 충분히 큰 구멍이 있다면, 그 구멍을 딱 프로세스 크기만큼의 영역과 나머지 잉여 구멍 영역으로 이분해줘야함. 프로세스 종료되면 다시 원래 크기의 구멍으로 돌아가겠지.
이런 방법이 바로 일반적으로 동적 저장 공간 할당 문제 dynamic storage-allocation problem의 한 형태임. 동적 저장 공간 할당 문제란 주어진 구멍들 목록에서 크기 n만큼의 메모리를 요구하는 요청을 들어주는 방법을 찾는 문제임. 여러 해결책이 있음. 최초 적합 first-fit, 최적 적합 best-fit, 최악 적합 worst-fit 등이 가장 일반적으로 사용하는 방법임.
- 최초 적합. 메모리를 탐색해서 공간이 충분한 처음 구멍에 할당. 탐색 방법은 보통 앞에서부터 하거나 마지막으로 탐색했던 곳에서부터 시작함. 암튼 충분히 큰 구멍 찾으면 탐색 끝임.
- 최적 적합. 공간이 충분한 구멍들 중 가장 크기가 작은 구멍에 할당. 구멍들의 목록이 사전에 정렬되어있는거 아니면 목록 전부 탐색해야함. 잉여 구멍은 제일 작음.
- 최악 적합. 공간이 충분한 구멍들 중 가장 크기가 큰 구멍에 할당. 잉여 구멍은 제일 큰데, 이게 오히려 최적 적합보다 더 좋을 수도 있음.
실제 돌려보면 시간이나 기억 장치 효용 면에선 최초 적합이나 최적 적합이 최악 적합보다는 나음. 최초랑 최적 중에서 누가 더 확실하게 낫다고는 말 못하지만 일반적으로는 최초 적합이 더 빠름.
9.2.3. 파편화
최초 적합과 최적 적합 둘 다 외부 파편화 external fragmentation라는 문제가 생김. 프로세스가 메모리에 올라갔다 내려갔다하는 과정에서 큰 구멍이 여러 개의 더 작은 구멍들로 나뉘기 시작함. 즉, 실제 사용 가능한 메모리가 작은 구멍들이 나뉘어서 송송 뚫려있으니 연속된 메모리 크기는 얼마 안 됨. 최악의 경우엔 모든 프로세스 사이마다 구멍이 있는 경우임. 이럴 땐 공간이 충분해도 프로세스를 더 실행을 못 함.
최초 적합을 쓰냐, 최적 적합을 쓰냐가 파편화의 정도에 영향을 주기는 함(몇몇 시스템에선 최초 적합이 더 낫고, 또 다른 애들에선 최적 적합이 더 나음). 그리고 메모리를 할당할 때 큰 구멍을 프로세스를 할당할 메모리와 남은 구멍으로 나눌 때 구멍의 아래쪽 주소를 메모리에 주고 위쪽을 구멍으로 남길지, 그 반대로 할지도 파편화에 영향을 줌. 어쨋든 외부 파편화가 발생하기는 함.
기억장치 전체 크기와 평균 프로세스 크기에 따라 외부 파편화가 사소한 문제일 수도 있고 심각한 문제일 수도 있음. 최초 적합을 통계적으로 분석해보니 최적화를 해줘도 N 개의 블록을 할당하면 0.5 N 개의 블록이 파편화로 놀고 있는 메모리가 됨. 즉, 전체 메모리의 3분의 1이 놀고 있는 것임. 이걸 50퍼센트 규칙 50-percent rule이라 부름.

메모리 파편화는 외부 파편화 뿐만 아니라 내부 파편화도 존재함. 다중 분할 할당 스킴에서 18,464 바이트짜리 구멍이 있다고 가정. 근데 다음으로 들어올 프로세스가 18,462 바이트를 요구함. 만약 정확히 필요한만큼 할당해주면 2 바이트 크기의 구멍이 남음. 근데 이 구멍을 기억하는게 배보다 배꼽이 더 큰 상황이 되버림. 이걸 해결하기 위해서 물리 메모리를 고정 크기 블록으로 나눈 다음, 메모리를 할당할 땐 이 크기 단위로 할당을 하는 것임. 이러면 프로세스에 할당한 메모리가 본래 메모리보다 더 클 수도 있음. 이렇듯 크기 단위에 따라 할당한 메모리와 요구한 메모리 간의 차가 바로 내부 파편화 internal fragmentation임.
외부 파편화에 대한 해결책 중 하나는 압축 compaction임. 즉, 구멍이 생기면 내버려 두는게 아니라, 위치를 바꿔줘서 언제나 구멍은 하나만 존재하게 해주는 것임. 물론 이게 언제나 가능한 건 아님. 재배치가 정적이어서 어셈블리 단, 혹은 로드 시에 발생하면 압축이 불가능함. 주소가 동적으로 재배치되었다면 프로그램과 자료가 이사를 가도 주소(베이스 레지스터) 이전만 제대로 신고하면 상관 없으니까. 압축이 가능하면 우선 그 비용을 알아야 함. 가장 간단한 압축 알고리듬은 프로세스를 메모리의 한 쪽으로 몰고, 구멍은 반대쪽으로 모는 것임. 이러면 사용 가능한 메모리, 즉 구멍이 큰 거 하나가 생길 것임. 근데 이거 좀 비쌈.
다른 해결책으로는 가상 주소 공간이 비연속적일 수 있게 해주어 물리 메모리에 공간이 있는 곳마다 할당해주는 것임. 이 전략이 바로 페이징 paging으로, 컴퓨터 시스템에서 가장 일반적인 메모리 관리 기법임.
파편화는 자료의 블록을 관리할 때 언제나 발생하는 문제임. 나중에 기억 장치 관리(11 단원부터 15 단원까지)에서 좀 더 볼 것임.
9.3. 페이징
지금까지는 프로세스의 물리 주소 공간이 연속적이어야한다고 했지만, 페이징 paging 기법을 사용하면 비연속적이어도 됨. 페이징을 사용하면 메모리를 감염시키는 주범인 외부 파편화를 해결할 수 있으니 또다른 주범 압축도 필요 없음. 장점이 워낙 많다보니 여러 운영체제에서 여러 방법으로 페이징을 사용함. 페이징은 운영체제와 하드웨어가 좀 서로 협력해야 구현이 가능함.
9.3.1. 기본 방법
페이징 구현의 기본은 물리 메모리를 고정된 크기의 블록, 즉 프레임 frame으로 나누고, 가상 메모리를 이와 동일한 크기의 블록, 즉 페이지 page로 나누는 것임. 프로세스를 실행하려면 프로세스의 페이지를 프로세스가 있는 곳(파일 시스템이나 보조 기억 장치)에서 사용 가능한 메모리 프레임에 적재함. 보조 기억 장치는 메모리 프레임과 동일한 고정된 크기의 블록 혹은 여러 프레임의 군집으로 나뉘어짐. 이게 아이디어는 간단한데 이게 기능성이 매우 좋고, 다양하게 활용할 수 있음. 예를 들어 가상 주소 공간이 이제 물리 주소 공간이랑 분리되어있으니, 시스템이 264 바이트의 물리 메모리 밖에 없어도 프로세스가 가상 64비트 주소 공간을 가질 수도 있음.
CPU가 생성한 모든 주소는 페이지 수 page number(p)와 페이지 오프셋 page offset(d)로 나뉨:

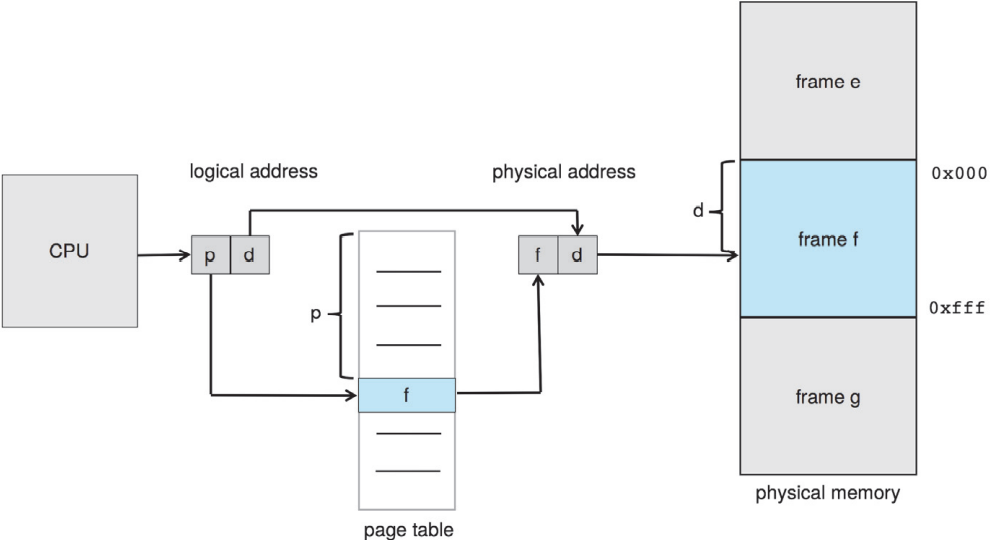
페이지 수는 프로세스 당 페이지 테이블 page table에 대응하는 색인으로 사용함. 위의 그림 참고. 페이지 테이블은 물리 메모리의 각 프레임의 베이스 주소를 갖고 있으며, 오프셋은 참조하는 프레임에서의 위치를 의미함. 즉, 프레임의 베이스 주소와 페이지 오프셋을 합쳐서 물리 메모리 주소를 알 수 있음. 메모리의 페이징 모델은 다음 그림을 참고.
MMU가 CPU가 생성한 가상 주소를 물리 주소로 변환할 때 다음 단계를 거침:
- 페이지 수 p 구하여 페이지 테이블의 색인으로 삼음
- 페이지 테이블에서 이 색인에 대응하는 프레임 수 f 구함
- 가상 주소의 페이지 수 p를 프레임 수 f로 교체
오프셋 d 자체는 바뀔 일이 없으므로 교체해줄 필요 없음. 프레임 수와 오프셋 두 개가 물리 주소를 구성함.
페이지 크기는(프레임 크기처럼) 하드웨어가 결정함. 페이지의 크기는 2의 제곱수고, 보통 한 페이지가 컴퓨터 아키텍처에 따라 4 KB에서 1 GB까지 있음. 2의 제곱수를 선택한데에는 연산의 편의성이란 이유가 있음. 가상 주소 공간의 크기가 2m이고, 페이지의 크기가 2n이라면 가상 주소의 고위 m-n번째 비트가 페이지 수가 되고, 저위 n 번째 비트가 페이지 오프셋이 되므로 가상 주소가 다음과 같이 됨:
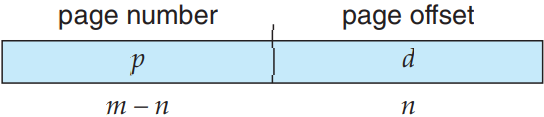
여기서 p가 페이지 테이블로의 색인이고 d가 페이지 내에서의 오프셋임.
좀 더 구체적인 예시로 이해:
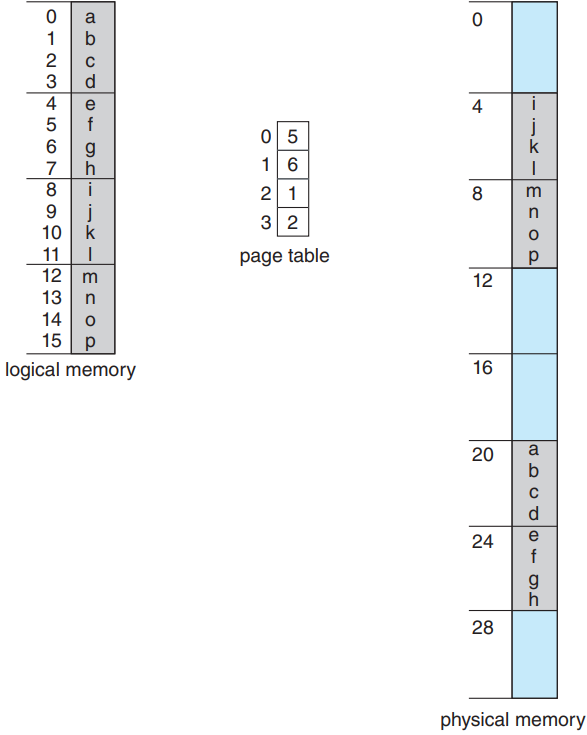
위의 그림에서 보듯, 가상 주소에서 n = 2, m = 4임. 페이지 크기가 4 바이트고 물리 메모리가 32 바이트(즉, 페이지 8 개)라면, 프로그래머가 바라보는 메모리가 어떻게 물리 메모리에 매핑되는지 이해하러 ㄱㄱ. 가상 주소 0은 곧 페이지 수가 0, 오프셋이 0임. 페이지 테이블로 들어가보니 0번 페이지는 프레임 5에 있음. 그러므로 가상 주소 0은 곧 물리 주소 20[= (5 × 4) + 0]에 있음. 가상 주소 3(페이지 수 0, 오프셋 3)은 물리 주소 23[= (5 × 4) + 3]에 있음. 가상주소 4는 페이지 수가 1, 오프셋이 0이므로 페이지 테이블에 의해 6번 프레임에 매핑이 되므로 물리 주소는 24[= (6 × 4) + 0]이 됨. 가상 주소 13은 물리 주소 9가 됨.
사실 보면 페이징 자체가 동적 재배치 기법임. 모든 가상 주소는 결국 어떤 물리 주소를 갖는 페이징 하드웨어에 종속적임. 페이징은 사실상 메모리의 각 프레임별로 베이스(혹은 재배치) 레지스터의 테이블을 사용하는 거랑 비슷한 것임.
페이징을 하면 외부 파편화가 없어짐. 빈 프레임은 결국 필요한 프로세스에게 할당이 되니까. 하지만 내부 파편화는 발생함. 이때 프레임은 유닛 단위로 할당이 됨. 만약 프로세스의 메모리 요구가 페이지의 범위를 벗어난다면 추가적으로 할당한 마지막 프레임은 가득 차있지 않게 될 것임. 즉, 페이지 크기가 2,048 바이트인데 프로세스가 72,766 바이트라면, 페이지 35 개에 추가적으로 1,086 바이트가 필요함. 여튼 프레임은 결국 36 개를 할당할텐데, 마지막 36 번째 프레임엔 2,048 - 1,08 = 962 바이트만큼의 내부 파편화가 발생함. 최악의 경우엔 n 개의 페이지에 추가적으로 1 바이트만 필요한데도 총 n + 1 개의 프레임을 할당받아 사실상 프레임 전체가 내부 파편화 상태인 경우도 발생함.
프로세스의 크기가 페이지와 무관하다면, 평균적으로 프로세스 당 절반의 페이지만큼 내부 파편화가 일어날 것이라고 예상할 수 있음. 이걸 봤을 땐 페이지의 크기를 줄여야한다고 생각할 수도 있음. 근데 페이지 테이블 한 개당 갖는 부담 자체가 사실 증가함. 오히려 페이지 크기가 커야 부담이 줄어듦. 게다가 디스크에서 입출력할 때 주고 받는 데이터량이 오히려 커야 더 효율적임(11 단원). 일반적으로 시간이 지나면서 프로세스, 자료, 주기억장치가 커질 수록 페이지 크기는 동일하게 증가해왔음. 요즘엔 4 KB나 8 KB 정도인데, 어떤 시스템에선 이보다 큰 페이지를 지원하기도 함. 어떤 CPU나 운영체제는 페이지 크기가 여러 가지를 갖는 경우도 있음. x86-64 시스템에서 Windows 10은 4 KB와 2 MB 페이지 크기를 지원함. Linux도 기본 크기(보통 4 KB)의 페이지와 아키텍처마다 크기가 다른 거대 페이지 huge page 두 가지를 지원함.
Linux 시스템에서 페이지 수 가져오기
Linux 시스템에서는 아키텍처에 따라 페이지 크기가 다름. 이걸 알 수 있는 방법이 여러 가지가 있는데, 한 가지 방법은 시스템 호출
getpagesize()를 쓰는 것임. 다른 방법으로는 명령줄에 다음 명령어 입력하면 됨:getconf PAGESIZE둘 다 페이지의 크기를 바이트 단위로 반환함.
주로 32-비트 CPU에서 각 페이지 테이블의 엔트리는 4 바이트인데, 이 크기도 달라질 수 있음. 32 비트 엔트리는 232 개의 물리 페이지 프레임 중 하나를 가리킬 것임. 만약 프레임 크기가 4 KB(212)라면 4 바이트 엔트리를 갖는 시스템에선 244 바이트(16 TB)의 물리 메모리 주소를 가리킬 수 있음. 물론 당연히 페이지 메모리 시스템의 물리 메모리의 크기는 프로세스의 최대 가상 크기와 다른 편임. 이후로 계속 보겠지만, 페이지 테이블 엔트리에 추가적인 정보를 더 저장해야함. 이 정보로 페이지 프레임의 주소를 구할 때 비트 수를 줄여줌. 즉, 32-비트 페이지 테이블 엔트리는 가용한 최대보다 덜 물리 메모리를 가리킬 수 있음.
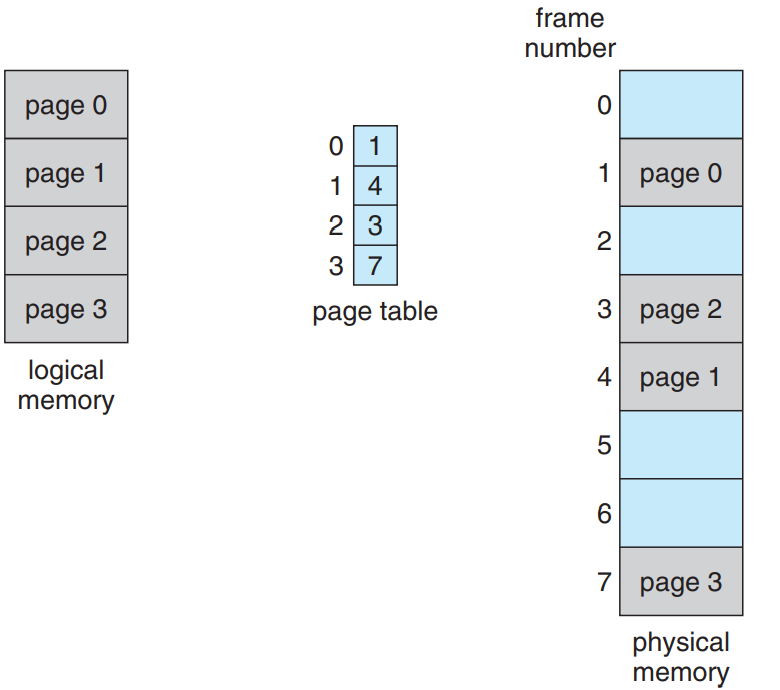
프로세스를 실행하려고 시스템에 올리면, 우선 프로세스의 크기를 페이지 단위로 먼저 확인해봄. 각 페이지는 프레임 하나에 대응하므로 n 개의 페이지를 할당하려면 최소한 n 개의 프레임이 메모리에 남아있어야 함. 페이지 하나 프레임에 적재하면 해당 프레임 수를 페이지 테이블에 기록해줌. 다음 그림 참고.

페이징에서 중요한 부분은 프로그래머가 메모리를 바라보는 그림과 실제 물리 메모리가 다르다는 점임. 프로그래머는 메모리가 마치 하나의 공간에 프로그램이 하나만 들어있다고 생각함. 실제로는 유저의 프로그램은 다른 프로그램과 함께 물리 메모리 여기 저기에 흩뿌려져있음. 이 프로그래머의 시선과 실제 물리 메모리의 차이점은 결국 주소 변환 하드웨어에 의해 좁혀짐. 가상 주소를 물리 주소로 변환해주는 것임. 프로그래머는 이에 대한 접근권이 없으며 운영체제가 이걸 제어함. 사용자 프로세스는 정의상 자기가 소유하지 않은 메모리에 접근할 수 없으므로 페이지 테이블 밖의 메모리 주소를 불러올 수 없음. 애초에 페이지 테이블에는 프로세스가 소유한 페이지만 있을테니.
운영체제가 물리 메모리를 관리하므로 물리 메모리의 할당 정보를 좀 알아야 함. 어떤 프레임이 할당되어있는지, 어떤 프레임은 사용 가능한지, 총 몇 개의 프레임이 있는지 등의 정보 말임. 이런 정보는 보통 프레임 테이블 frame table이라는 자료 구조를 시스템 전체에 하나만 두고 사용함. 프레임 테이블엔 각 물리 페이지 프레임마다 엔트리가 하나가 있어 이게 사용 중인지 비었는지, 그리고 사용 중이라면 어떤 프로세스의 페이지에서 사용 중인지를 기록해둠.
여기에 추가적으로 운영체제는 사용자 프로세스가 사용자 공간에서 연산을 하고 있으며, 모든 가상 주소는 물리 주소에 대응이 되도록 매핑이 되어있음을 보장해야함. 사용자가 시스템 호출(입출력 등)을 해서 매개변수로 주소(버퍼 등)를 주었다면, 이 주소는 반드시 올바른 물리 주소로 변환되어야 함. 운영체제는 프로세스마다 마치 명령어 카운터와 레지스터 복사본을 갖고 관리하듯, 페이지 테이블 또한 복사본을 갖고 있음. 이 복사본으로 운영체제가 가상 주소를 물리 주소에 직접 매핑을 해줘야할 때 사용함. 또한 프로세스가 CPU를 할당 받을 때 CPU 디스패처가 하드웨어 페이지 테이블을 정의할 때도 사용함. 그런 의미에서 페이징은 문맥 교환 시간을 길게 만듦.
9.3.2. 하드웨어 지원
페이지 테이블은 프로세스 별로 갖는 자료 구조이므로 페이지 테이블을 가리키는 포인터도 다른 레지스터 값이랑 같이 프로세스의 프로세스 제어 블록에 저장이 됨(명령어 포인터처럼). CPU 스케줄러가 프로세스를 실행하려고 선택하면 반드시 사용자 레지스터를 불러오고 적합한 하드웨어 페이지 테이블 값을 저장해뒀던 사용자 페이지 테이블로부터 불러올 것임.
페이지 테이블을 하드웨어적으로 구현하는 방법은 여러 가지가 있음. 가장 단순한 방법은 페이지 테이블을 고속의 하드웨어 레지스터로 구현하여 페이지 주소 변환을 매우 효율적으로 해주는 방법임. 근데 이러면 문맥 교환할 때 이 레지스터들도 일일이 교환해줘야하니 문맥 교환 시간이 늘 것임.
페이지 테이블이 충분히 작을 때(엔트리가 256개라든가 등)엔 레지스터로 해도 괜찮을 것임. 근데 요즘 CPU들은 더 큰 페이지 테이블(엔트리 220 개 등)을 지원함. 그러므로 이 경우 레지스터를 쓰는게 비현실적임. 대신 페이지 테이블을 주기억장치에 기억해두고, 페이지 테이플 베이스 레지스터 page-table base register (PTBR)가 이 테이블을 가리키게 만듦. 페이지 테이블을 바꾸려면 그냥 레지스터 값 하나만 바꾸면 되니 문맥 교환 시간이 그리 많이 늘지도 않음.
9.3.2.1. 변환 색인 버퍼
페이지 테이블을 주기억장치에 저장해두면 문맥 교환은 빨라질 수 있어도, 메모리 접근 시간이 느려질 수 있음. 만약 위치 i에 접근을 하고 싶다고 가정. 우선 i의 페이지 수를 통해 페이지 테이블의 몇번째 엔트리로 가야할지를 결정해야함. 이 작업에선 메모리 접근이 한 번만 필요함. 프레임 수를 얻게 될텐데, 여기에 페이지 오프셋으로 실제 주소를 얻어 실제 메모리로 갈 수 있게 됨. 즉, 결론적으로 자료에 접근하는데 총 메모리 접근을 두 번(페이지 테이블 엔트리에서 한 번, 실제 자료에 한 번)하게 됨. 그러므로 2의 배수로 메모리 접근 시간이 느려짐. 이거 말도 안되게 긴 것임.
가장 표준으로 일컫는 해결법은 변환 색인 버퍼 translation look-aside buffer (TLB)라는 특수한 작은 고속 룩업 하드웨어 캐시를 사용하는 것임. TLB는 고속의 연상associative 메모리임. TLB의 각 엔트리는 키(혹은 태그)와 값 두 가지로 나뉘어짐. 연상 메모리와 아이템이 주어진다면, 이 아이템을 동시에 모든 키와 비교를 함. 만약 아이템이 존재한다면 이에 대응하는 값을 반환함. TLB 룩업은 요즘 하드웨어에서 명령어 파이프라인의 일부분이라 탐색이 매우 빠름. 특히 성능에 페널티가 없음. 물론 파이프라인 단계에서 탐색을 실행해주려면 TLB가 매우 작아야함. 보통 32에서 1,024 개의 엔트리만 가질 수 있음. 몇몇 CPU에선 따로 명령어와 자료 주소 TLB를 구현함. 이러면 룩업이 여러 파이프라인 단계에서 사용 가능하니 사용 가능한 TLB 엔트리의 개수가 두 배가 됨. 이걸 통해 CPU 기술의 발전사를 볼 수 있음: TLB가 없던 시절에서 이제는 TLB가 여러 단계가 존재하는 시절로, 마치 다단계 캐시가 없던 시절과 유사하게 진화하고 있음.
TLB는 페이지 테이블과 함께 다음과 같이 사용함. TLB에는 페이지 테이블 엔트리 몇 개만 들어있음. CPU가 생성한 가상 주소에 대해 MMU가 우선 페이지 수가 TLB에 존재하는지 확인함. 만약 페이지 수가 존재한다면 프레임 수가 즉각적으로 사용할 수 있게 되어 메모리에 접근할 수 있게 됨. 위에서 언급했듯 이 단계는 CPU의 명령어 파이프라인의 일부이므로 페이징을 구현하지 않은 시스템에 비해 성능 저하가 없음.
만약 페이지수가 TLB에 없다면(TLB 미스 TLB miss라 부름) 주소 변환이 9.3.1 절에서 언급했던 단계대로 처리되어 페이지 테이블까지 가야함. 프레임 수를 얻은 후에는 이걸로 메모리에 접근하는 것임. 다음 그림 참고. 여기다가 페이지 수와 프레임 수를 TLB에 추가해주어 나중에 찾을 때 좀 더 빨리 찾을 수 있게 해줌.
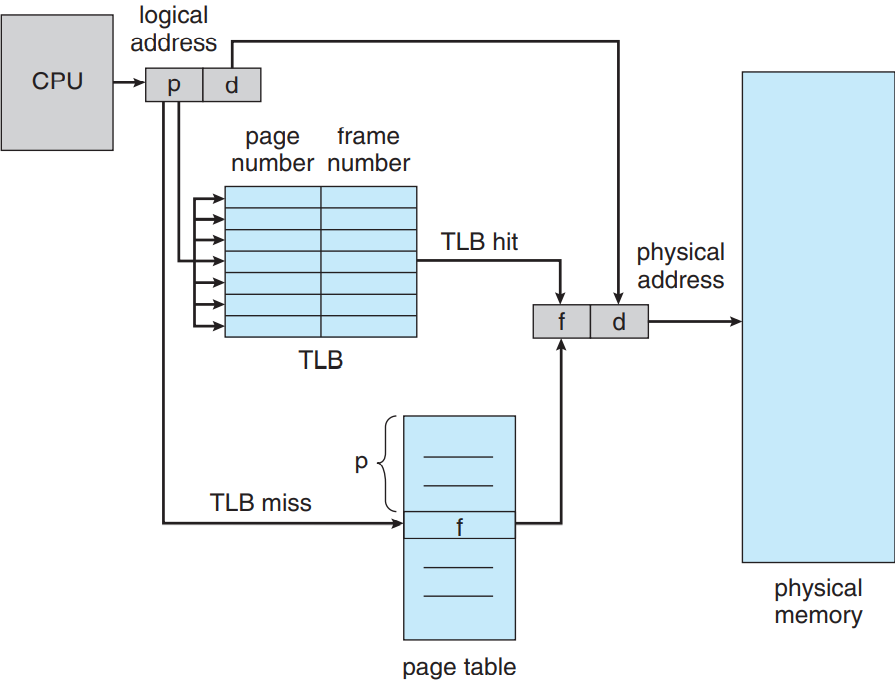
TLB가 이미 가득 차 있다면 기존 내역 하나 골라서 새로 넣을 걸로 교체해줘야함. 바꾸는 법은 최소 최근 사용(LRU) 정책이나 라운드 로빈, 심지어는 무작위 정책 등 정해서 하면 됨. 몇몇 CPU는 운영체제가 LRU 엔트리 교체에 영향을 줄 수 있게 해줄 수 있게 해주기도 하고, 몇몇 CPU는 아예 자기들이 알아서 처리하는 경우도 있음. 더 나아가 TLB는 특정 엔트리들을 고정 wired down하여 TLB에서 삭제가 불가능하게 해줄 수 있음. 일반적으로 중요 커널 코드에 대한 TLB 엔트리는 고정해줌.
몇몇 TLB는 주소 공간 식별자 adress-space identifier (ASIDs)를 각 TLB 엔트리에 저장해두기도 함. ASID는 각 프로세스를 고유한 식별자로 구분을 해주어 프로세스 별로 주소 공간 보호를 제공해줌. TLB가 가상 페이지 수를 해결하려고 할 때 현재 실행 중인 프로세스의 ASID가 현재 가상 페이지의 ASID와 같은지를 확인해줌. ASID가 서로 다르면 TLB 미스라고 간주함. 주소 공간 보호 뿐만 아니라 ASID를 통해 TLB가 동시에 여러 다른 프로세스에 대한 엔트리를 가질 수 있게 해줌. 만약 TLB가 서로 다른 ASID를 지원하지 않는다면 새 페이지 테이블을 선택할 때마다(예를 들어 문맥 교환 등) TLB는 반드시 씻어 없애 flush(혹은 삭제)주어 다음으로 실행할 프로세스가 잘못된 변환 정보를 사용하지 않도록 보장해줘야 함.
필요한 페이지 수를 TLB에서 찾을 비율을 히트율 hit ratio라 부름. 만약 메모리 접근에 10 ns가 걸린다면 매핑된 메모리 접근에서 만약 페이지 수가 TLB에 있다면 10 ns 정도 걸림. 만약 TLB에서 페이지 수를 찾지 못했다면 우선 페이지 테이블 메모리에 접근하여 프레임 수를 찾아내고(10 ns) 해당 메모리의 있는 바이트에 접근(10 ns)해야 하므로 총 20 ns가 걸림. (페이지 테이블 룩업이 메모리 접근 하나만 필요하다고 가정한 건데, 실제로는 더 걸림.) 유효 메모리 접근 시간 effective memory-access time을 계산하려면 확률로 그 경우에 가중치를 부여해야함:
유효 메모리 접근 시간 = 0.80 × 10 + 0.20 × 20 = 12 나노초
이 예제에서는 평균 메모리 접근 시간이 20% 정도 지연됨(10 ns에서 12 ns). 좀 더 현실적인 예시로 히트율이 99%라면,
유효 메모리 접근 시간 = 0.99 × 10 + 0.01 × 20 = 10.1 나노초
이므로, 평균 접근 시간이 겨우 1% 증가했음.
요즘 CPU엔 다단계 TLB를 제공함. 그래서 요즘 CPU에서 메모리 접근 시간 계산은 좀 더 복잡해짐. 예를 들어 인텔 코어 i7 CPU는 엔트리 128 개짜리 L1 명령어 TLB와 엔트리 64 개짜리 L1 데이터 TLB를 갖고 있음. 이 경우에 L1에서 미스가 날 경우 L2 엔트리 512 개짜리 TLB에서 엔트리 찾는데 CPU 여섯 사이클이 필요함. L2에서 미스날 경우 CPU가 페이지 테이블 엔트리까지 가서 필요한 프레임 주소를 찾아야 함. 이러면 수백 사이클이 필요하거나 운영체제로 인터럽트해서 대신 일을 하게 해야함.
이런 시스템에서 페이징 부담에 따른 성능을 완벽하게 분석하려면 각 TLB 단계마다 미스율도 알아야 함. 위에서 보았듯 하드웨어 기능이 메모리 성능에 상당한 영향을 미치게 됨. 어찌보면 운영체제를 개선하고 보니(페이징 등) 하드웨어가 이에 영향이 받은 것(TLB 등)임. TLB의 히트율의 영향은 10 단원에서 좀 더 알아볼 것임.
TLB는 하드웨어 기능이므로 운영체제와 운영체제 설계자 입장에서 그리 큰 문제는 아니지만 하드웨어별 TLB의 용도와 기능은 알아야함. 최적의 연산을 위해선 주어진 플랫폼에서의 운영체제는 반드시 해당 플랫폼의 TLB 설계에 특정하여 페이징을 구현해야함. 마찬가지로 TLB 설계가 변한다면(Intel CPU 세대 간 등) 이 기기를 사용하는 운영체제의 페이징 구현법도 바뀌어야 함.
9.3.3. 보호
페이지 환경에서 메모리 보호는 각 프레임 별에 대한 보호 비트로 처리 가능함. 일반적으로 이런 비트들은 페이지 테이블에 있음.
비트 하나로 페이지가 읽기 전용인지, 읽고 쓰기 둘 다 되는지를 표기해줄 수 있음. 메모리에 접근하려면 결국 페이지 테이블로 들어가 올바른 프레임 수를 얻어야 할텐데, 이때 동시에 보호 비트를 확인해서 읽기 전용 페이지에 쓰기를 해주고 있는지를 확인할 수 있음. 만약 읽기 전용 페이지를 쓰려고 하는 순간 하드웨어 트랩이 발생하여 운영체제로 보내짐(혹은 메모리 보호 위반).
이걸 좀 더 확장해서 세밀하게 보호를 제공해줄 수 있음. 하드웨어가 읽기 전용, 읽고 쓰기, 실행 전용 보호를 제공하게 해주거나, 각 접근 유형별로 비트를 따로 둬서 이런 접근의 조합을 써줄 수도 있음. 올바르지 않은 접근은 운영체제에 트랩을 하게 해주면 됨.
일반적으로 각 페이지 테이블에 엔트리에 추가적인 비트 하나를 추가해줌. 이 비트를 유무효 valid-invalid 비트라 부름. 이 비트가 유효 상태라면 여기에 대응하는 페이지는 프로세스의 가상 주소 공간에 있으므로 합법(유효)인 페이지라는 것임. 만약 비트가 무효 상태라면 페이지는 프로세스의 가상 주소 공간에 있는 것이 아님. 불법 주소는 이렇듯 유무효 비트로 트랩을 해줄 수 있음. 운영체제가 이 비트를 설정해주어 페이지의 접근권을 부여하는 것임.
예를 들어 14 비트 주소 공간(0 ~ 16,383)을 갖는 시스템에서 프로그램이 오로지 0에서 10,468 까지의 주소를 쓴다고 가정. 페이지 크기가 2 KB라면 아래 그림과 같은 상황이 될 것임. 페이지 0, 1, 2, 3, 4, 5의 주소는 페이지 테이블로 정상적으로 매핑이 될 것임. 페이지 6이가 7에 주소를 생성하려고 해봤자 유무효 비트가 무효 값이므로 컴퓨터가 운영체제에게 트랩을 보낼 것임(무효 페이지 참조).
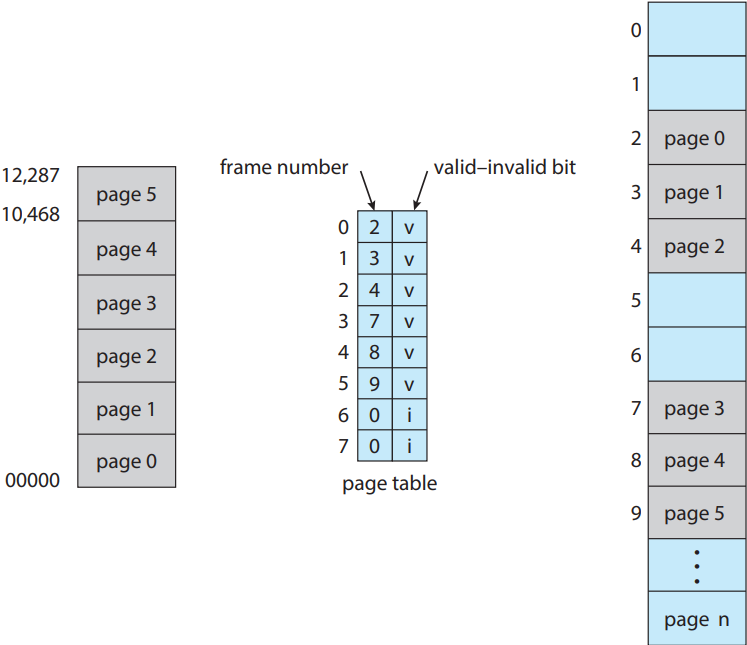
근데 이러면 문제가 생김. 프로그램이 오로지 주소 10,468 까지만 사용하므로, 이보다 큰 주소는 쓸 수 없어야 함. 허나 페이지 5로의 참조는 유효하다고 하니, 주소 12,287 까지도 접근이 가능하고, 12,288부터 16,383까지가 무효함. 이게 바로 2 KB의 페이지 크기로 페이징을 했을 때 내부 파편화에 의해 발생하는 문제임.
프로세스가 주소를 전부 다 차지하는 경우는 거의 없음. 사실상 내부분의 프로세스는 할당받은 주소 중 일부밖에 안 쓺. 그렇기에 주소 범위의 모든 페이지에 대응하는 엔트리를 전부 페이지 테이블에 만들어주는 건 불필요함. 어차피 거의 다 안 쓰고 메모리만 먹을 텐데. 몇몇 시스템에서는 페이지 테이블 길이 레지스터 page-table length register (PTLR)라는 하드웨어를 제공하여 페이지 테이블의 크기를 알려줌. 이 값을 바탕으로 가상 주소가 프로세스의 유효한 범위 내에 있는지를 알 수 있음. 범위 내에 없으면 운영체제에 트랩을 줌.
9.3.4. 공유 페이지
페이징의 장점 중 하나는 공동으로 사용하는 코드를 공유할 수 있다는 점임. 특히 멀티프로세싱 환경에서 매우 중요한 부분임. UNIX와 Linux에서 몇몇 시스템 호출에 대한 인터페이스를 제공해주는 표준 C 라이브러리가 대표적인 예시. 대부분의 Linux 시스템에선 대부분의 사용자 프로세스가 표준 C 라이브러리 libc를 필요로 하고 있음. 한 가지 방법으로는 각 프로세스의 메모리 공간에 libc 사본을 적재해두는 것임. 사용자 프로세스가 40 개고, libc 라이브러리의 크기가 2 MB라면 총 80 MB의 메모리 잡아 먹는 것임.
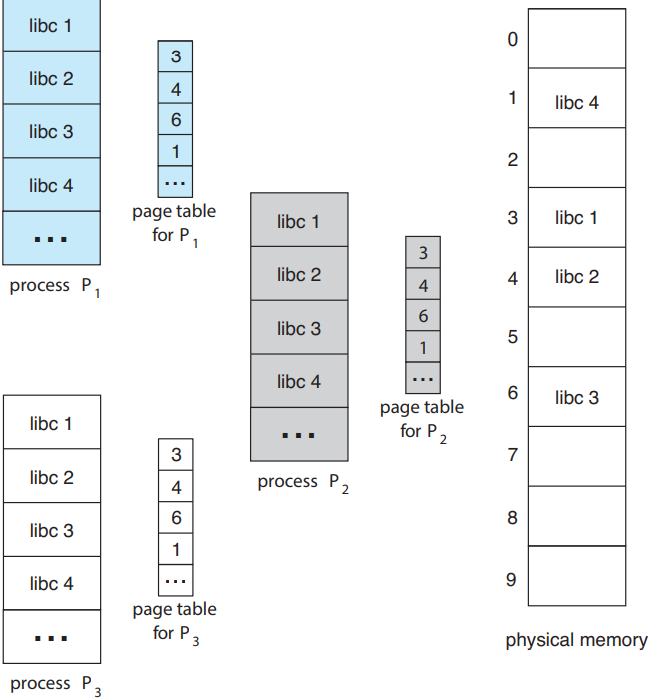
만약 코드가 재진입 가능 코드 reentrant code라면 공유가 가능해짐. 위 그림에서처럼 프로세스 세 개가 표준 C 라이브러리 libc를 공유 중이라고 가정. (libc 라이브러리가 페이지 네 개를 차지하는 것처럼 보이지만, 실제로는 더 차지함.) 재진입 가능한 코드는 스스로를 수정하지 않는 코드이므로 실행 도중에 절대 바뀌지 않음. 즉, 두 개 이상의 프로세스가 동시에 같은 코드를 실행할 수도 있음. 각 프로세스엔 프로세스 실행을 위한 레지스터랑 데이터 스토리지 사본이 따로 있기 때문임. 당연히 프로세스가 다르면 이 데이터도 다르겠지. 표준 C 라이브러리 사본도 딱 하나만 물리 메모리에 저장되어있을 것이고, 각 사용자 프로세스의 페이지 테이블이 동일한 libc의 물리 사본에 매핑을 하고 있을 것임. 그러므로 프로세스가 40 개여도 라이브러리 사본은 하나만 있으면 되므로 80 MB가 아니라 2 MB만 필요함.
libc와 같은 실시간 라이브러리 뿐만 아니라 컴파일러, 윈도우 시스템, 데이터베이스 시스템 등과 같이 자주 사용한 프로그램이라면 공유해줄 수 있음. 9.1.5 절에서 다룬 공유 라이브러리는 일반적으로 공유 페이지랑 같이 구현이되어있음. 공유를 하려면 코드가 반드시 재진입 가능해야함. 이런 공유 가능한 코드는 코드 단에서 읽기 전용임을 보장하는게 아니라, 운영체제 자체가 이걸 강제해줘야함.
프로세스 간 메모리 공유하는 건 4 단원에서 다뤘던 스레드 간의 작업이 주소 공간 공유하는 개념이랑 비슷함. 또한 3 단원에서 프로세스 간 통신 방법 중 하나인 공유 메모리도 생각 날 것임. 몇몇 운영체제는 공유 메모리를 공유 페이지로 구현하기도 함.
메모리를 페이지로 구조화하면 여러 프로세스가 동일한 물리 페이지를 공유할 수 있다는 장점 말고도 다른 장점 엄청 많음. 다른 장점은 10 단원에서 다룰 것임.
9.4. 페이지 테이블의 구조
페이지 테이블을 구조화하는 가장 일반적인 기법들을 알아볼 것.
9.4.1. 계층적 페이징
요즘 나오는 대부분의 컴퓨터 시스템은 매우 큰(232에서 264) 가상 주소 공간을 지원함. 이런 환경에서는 페이지 테이블 자체가 매우 커질 수 있음. 시스템이 32 비트 가상 주소 공간을 갖는다고 할 때, 페이지의 크기가 4 KB(212)라면, 페이지 테이블이 거의 백만 개가 넘는(220 = 232 / 212) 엔트리를 가질 수도 있음. 각 엔트리가 4 바이트 크기라고 가정한다면 각 프로세스는 페이지 테이블 하나만 해도 최대 4 MB가 필요할 수도 있음. 당연히 주기억장치에 페이지 테이블을 연속적으로 할당할 건 아닐 것임. 이걸 해결할 수 있는 간단한 방법으로는 페이지 테이블을 좀 더 작은 부분으로 나누는 것임. 여러 방법으로 나눌 수 있음.
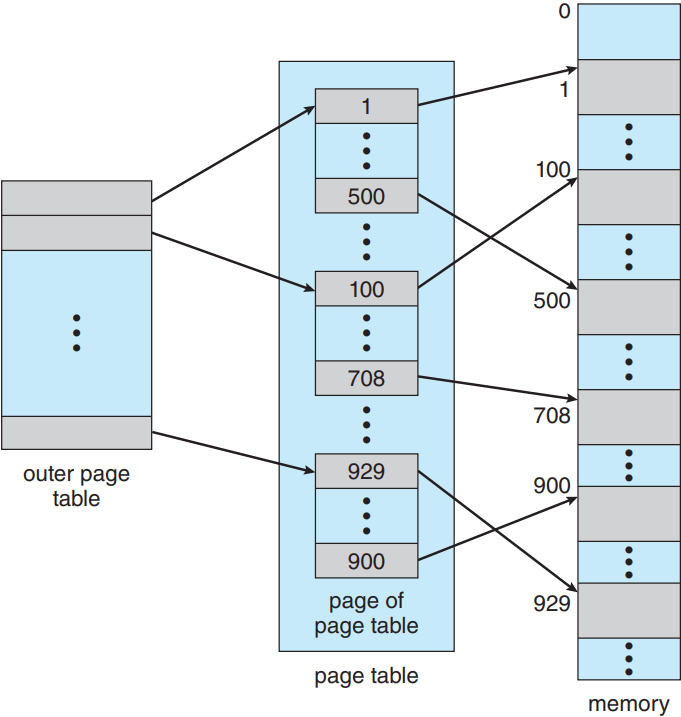
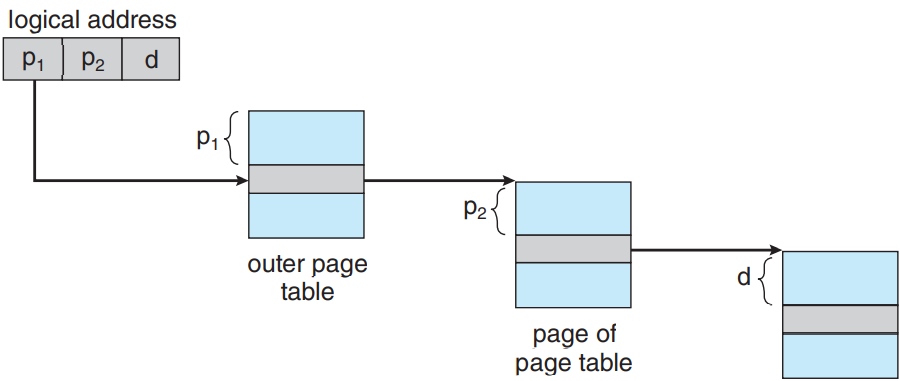
한 가지 방법은 이단계 페이징 알고리듬을 사용하는 것으로, 페이지 테이블 또한 페이징을 해주는 것임(위 그림 참고). 예를 들어 위에서 언급한 32 비트 가상 주소 공간과 4 KB 페이지 크기를 갖는 시스템의 경우, 가상 주소가 20 비트의 페이지 수와 12 비트의 오프셋으로 나뉠 것임. 여기서 페이지도 페이징을 해줄테니, 페이지 수는 10비트의 페이지 수와 10비트의 페이지 오프셋으로 나뉨:

여기서 p1가 외부 페이지 테이블로의 색인이고 p2가 페이지 내부의 페이지 테이블로의 오프셋임. 이 아키텍처에 대한 주소 변환 방법은 아래 그림과 같음. 주소 변환이 외부 페이지 테이블에서 안쪽으로 진행되므로 전방 매핑 forward-mapped 페이지 테이블이라고도 부름.
64 비트 가상 주소 공간을 갖는 시스템에서 이단계 페이징 스킴은 더 이상 적절하지 않음. 이걸 이해하려면 우선 페이지 크기가 4 KB(212)라 가정. 이 경우 페이지 테이블은 252 개의 엔트리를 가질 수도 있음. 이단계 페이징 스킴을 쓸 경우 내부 페이지 테이블은 한 페이지 길이, 즉 210 개의 4 바이트 엔트리를 갖게 될 것임. 그럼 주소는 다음과 같아짐:

외부 페이지 테이블은 242 개의 엔트리, 즉 244 바이트를 가질 것임. 당연히 이걸 또 해결하려면 외부 페이지를 더 작은 부분으로 나눠야함(몇몇 32 비트 프로세서에서 실제로 유연성과 효율성 때문에 이걸 구현하기도 했음.)
외부 페이지 테이블을 나누는 방법엔 여러 가지가 있음. 예를 들어 외부 페이지 테이블을 페이지해주어 삼단계 페이징 스킴을 써줄 수도 있음. 외부 페이지 테이블이 표준 크기 페이지(210 개의 엔트리, 혹은 212 바이트)라고 가정하더라도 64 비트 가상 주소는 좀 위험하게 생겼음:

이래도 외부 페이지 테이블의 크기가 234 바이트(16 GB)임.
다음 단계는 사단계 페이징 스킴으로, 이단계 외부 페이지 테이블도 페이징해주는 것임. 64 비트 UltraSPARC은 칠단계 페이징(메모리 접근에서 피해햐할 숫자)을 통해 각 가상 주소를 변환해줌. 이 예시로 보면 알겠지만 이래서 64 비트 아키텍처에서는 계층적 페이지 테이블이 적합하지 않음.
9.4.2. 해시 페이지 테이블
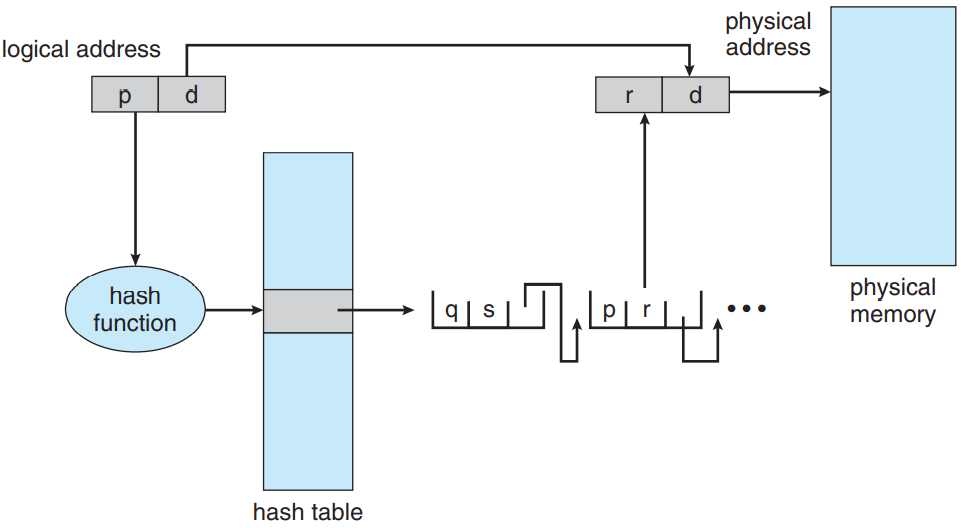
32 비트보다 긴 주소 공간을 처리하는 방법 중 하나로는 해시 페이지 테이블 hashed page table이 있음. 여기서 해시 값이 곧 가상 페이지 수가 되는 것임. 해시 테이블의 각 엔트리에는 (충돌 처리를 위해) 연결 리스트를 갖고 있음. 각 원소는 세 가지 부분으로 나뉨: (1) 가상 페이지 수, (2) 매핑된 페이지 프레임의 값, (3) 연결 리스트의 다음 원소를 가리키는 포인터.
알고리듬은 다음과 같음: 가상 주소의 가상 페이지 수를 해싱하여 해시 테이블에서 찾아봄. 가상 페이지 수를 연결리스트의 1번 원소와 비교함. 만약 둘이 같다면 해당하는 페이지 프레임(두번째 원소)를 통해 원하는 물리 주소를 반환함. 만약 같은 원소가 없다면 연결리스트의 다음 원소와 비교함. 이거의 반복임. 그림도 다음과 같음:
이걸 변형한 스킴으로 64 비트 주소 공간에서 좀 더 유용한 방법이 있음. 이 변형에선 군집 페이지 테이블 clustered page tables을 사용하는데, 해시 테이블의 각 엔트리가 페이지 하나가 아니라 여러 페이지(16 개 등)을 참조하는 점 빼고는 해시 페이지 테이블과 비슷함. 즉, 단일 페이지 테이블의 엔트리가 여러 물리 페이지 프레임에 매핑될 수 있음. 군집 페이지 테이블은 특히 메모리 참조가 연속적이지 않고 주소 공간 곳곳에 흩뿌려진 성긴 sparse 주소 공간에서 매우 유용함.
9.4.3. 역 페이지 테이블
각 프로세스엔 보통 대응하는 페이지 테이블이 존재함. 페이지 테이블엔 프로세스가 사용하는 페이지마다 대응하는 엔트리가 하나씩 존재함(혹은 각 가상 주소마다 한 슬롯. 가상 주소가 유효성과는 무관하게). 이건 매우 자연스러운 표현 방법임. 프로세스는 페이지를 페이지의 가상 주소로 참조하니까. 운영체제는 그럼 이걸 물리 메모리 주소로 변환해줄 것임. 테이블이 가상 주소로 정렬되어있을테니 운영체제는 테이블 어디에 대응하는 물리 주소 엔트리가 있는지를 해당 값을 직접 사용해서 계산해줄 수 있음. 이 방법의 단점으로는 각 페이지 테이블에 수백만 개의 엔트리를 갖고 있다는 점임. 이런 테이블은 단순히 사용 중인 물리 메모리 기록하는데만 상당한 양의 물리 메모리를 소비함.
이걸 해결하려면 역 페이지 테이블 inverted page table을 사용하면 됨. 역 페이지 테이블엔 메모리의 실제 페이지(혹은 프레임) 하나당 엔트리가 하나임. 각 엔트리는 실제 메모리 주소에 저장된 페이지의 가상 주소로 구성되어있으며, 프로세스나 누가 이 페이지를 소유하는지에 대한 정보는 없음. 즉, 시스템에 페이지 테이블이 딱 하나 개가 있으며, 물리 메모리의 각 페이지 별로 엔트리도 딱 하나만 존재함. 아래 그림이 역 페이지 테이블의 연산을 보여주는 그림임. 표준 페이지 테이블의 연산 그림과 비교해서 보셈. 역 페이지 테이블은 주로 주소 공간 식별자(9.3.2 절)를 페이지 테이블 엔트리마다 저장해줘야 함. 테이블이 보통 여러 개의 주소 공간을 물리 메모리에 매핑하기 때문임. 주소 공간 식별자를 저장함으로써 특정 프로세스의 가상 페이지가 대응하는 물리 페이지 프레임에 매핑이 될 수 있음. 역 페이지 테이블 사용하는 시스템으로는 64 비트 UltraSPARC와 PowerPC 등이 있음.
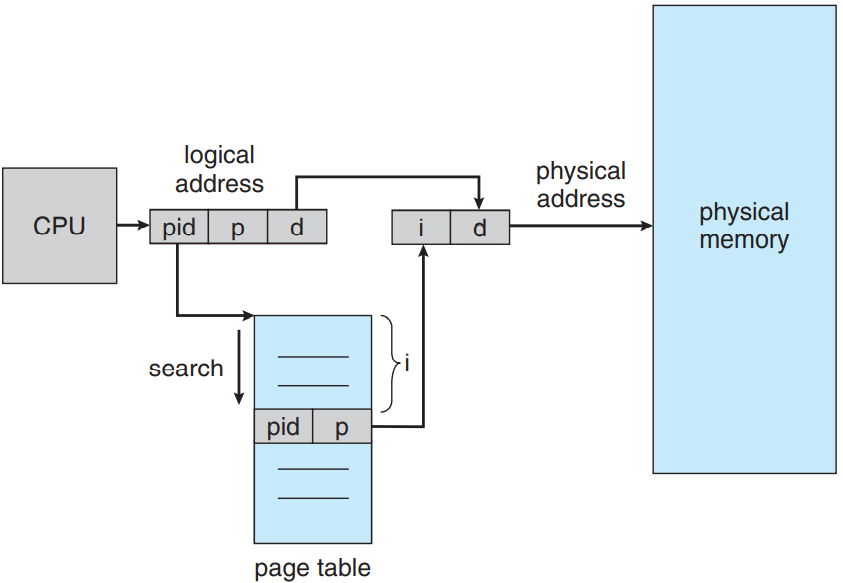
이걸 보이려면 IBM RT에서 사용했던 역 페이지 테이블을 단순화한 버전을 보면 됨. IBM이 역 페이지 테이블을 처음 사용했던 대기업임. IBM 시스템 38부터 RS/6000, 그리고 현재 IBM의 Power CPU에서까지 사용 중임. IBM RT의 경우 각 가상 주소는 세 가지로 구성됨:
<프로세스 아이디, 페이지 수, 오프셋>
각 역 페이지 테이블 엔트리엔 <프로세스 아이디, 페이지 수> 짝을 가짐. 여기서 프로세스 아이디가 주소 공간 식별자 역할을 함. 메모리 참조가 발생하면 가상 주소의 일부, 즉 <프로세스 아이디, 페이지 수>를 메모리 하위 시스템에 전달함. 역 페이지 테이블은 이를 보고 대응되는 엔트리를 찾음. 같은 친구가 i번째 엔트리에 있다고 가정하면 물리 주소 <i, 오프셋>이 생성됨. 대응되는 엔트리가 없다면 불법 주소 접근이 발생한 것임.
이러면 페이지 테이블 저장하는데 필요한 메모리량은 줄어들지만, 페이지 참조가 발생할 때 테이블을 탐색하는 시간이 증가함. 역 페이지 테이블이 물리 주소로 정렬되어있지만 룩업 자체는 가상 주소에 대해서 발생하므로 전체 테이블을 전부 탐색해야할 수도 있음. 이거 생각보다 오래 걸림. 이걸 해결하려면 9.4.2 절에서 언급했던 해시 테이블을 사용하면 됨. 당연히 해시 테이블을 사용하게 되면 그 절차에서 메모리 참조가 하나 더 추가가 되므로 가상 메모리 참조 한 번이 최소 두 번의 실제 메모리 읽기 연산(해시 테이블 엔트리 읽기 한 번, 페이지 테이블 읽기 한 번)이 수행됨.(TLB에서 먼저 탐색을 하고 나서 해시 테이블로 내려올테니 성능이 조금은 생각보다 더 괜찮긴 할 것임.)
역 페이지 테이블에서 발생하는 흥미로운 부분은 바로 공유 메모리임. 표준 페이징을 하면 각 프로세스가 자신만의 페이지 테이블이 있으므로 여러 가상 주소가 같은 물리 주소에 매핑 될 수 있었음. 역 페이지 테이블에선 이게 안 됨. 그러므로 임의의 순간에 반드시 한 가상 주소만 공유 물리 주소에 대응 될 수 있음. 메모리를 공유하는 다른 프로세스가 참조하는 순간 페이지 틀림이 발생하여 매핑을 다른 가상 주소로 교체해줄 것임.
9.4.4. Oracle SPARC Solaris
가상 메모리의 부담을 최소화하기 위해 현대적인 64 비트 CPU와 운영체제가 상당히 밀접하게 통합된 예시를 볼 것. SPARC CPU에서 도는 Solaris는 완전한 64 비트 운영체제이기에 다단계 페이지 테이블을 사용하여 물리 메모리를 전부 잡아먹지 않도록 가상 메모리 문제를 해결해야 했음. 방법은 좀 복잡하긴 한데, 결국 해시 페이지 테이블로 효율적으로 문제를 해결하긴 했음. 해시 테이블이 일단 두 가지임. 하나는 커널용, 하나는 사용자 프로세스용임. 각각 메모리 공간을 가상에서 물리 메모리로 매핑해주는 건 동일함. 각 해시 테이블 엔트리는 매핑된 가상 메모리의 연속된 영역을 의미함. 이게 페이지 별로 엔트리를 주는 것보다 더 효율적임.각 엔트리엔 베이스 주소와 해당 엔트리가 의미하는 페이지의 수가 들어있음.
만약 각 주소를 해시 테이블에서 찾아야 했다면 가상에서 물리 변환이 오래 걸릴 것이므로 CPU 자체에서 변환 테이블 엔트리(translation table entry. TTE)를 갖는 TLB를 구현해서 빠르게 하드웨어적으로 룩업을 할 수 있게 해줌. 이 TTE의 캐시가 변환 저장 버퍼(translation storage buffer. TSB) 안에 있음. 이 캐시 안에는 최근에 접근한 페이지의 엔트리를 포함하고 있음. 가상 주소 참조가 발생하면 하드웨어가 우선 TLB로 변환을 함. 만약 찾았는데 결과가 없으면 하드웨어가 내부 메모리 TSB로 넘어가서 룩업을 발생 시킨 가상 주소에 대응하는 TTE를 탐색함. 이것을 TLB 워크 TLB walk 기능이라 부르며, 이는 여러 현대적인 CPU에 존재함. 만약 TSB에 대응되는 상대가 있으면 CPU가 해당 TSB 엔트리를 복사하여 TLB에 넘겨주어 메모리 변환을 완료함. 만약 대응되는 상대가 없으면 커널이 인터럽트되어 해시 테이블에서 탐색을 함. 이후에 적합한 해시 테이블로부터 TTE를 생성하여 TSB에 저장해서 자동으로 CPU의 메모리 관리 장치가 TLB에 적재하도록 해줌. 최종적으로 인터럽트 처리자가 제어를 MMU에 넘겨주어 주소 변환을 완료한 다음 요청한 바이트 혹은 단어를 주기억장치에서 갖고 옴.
9.5. 스와핑
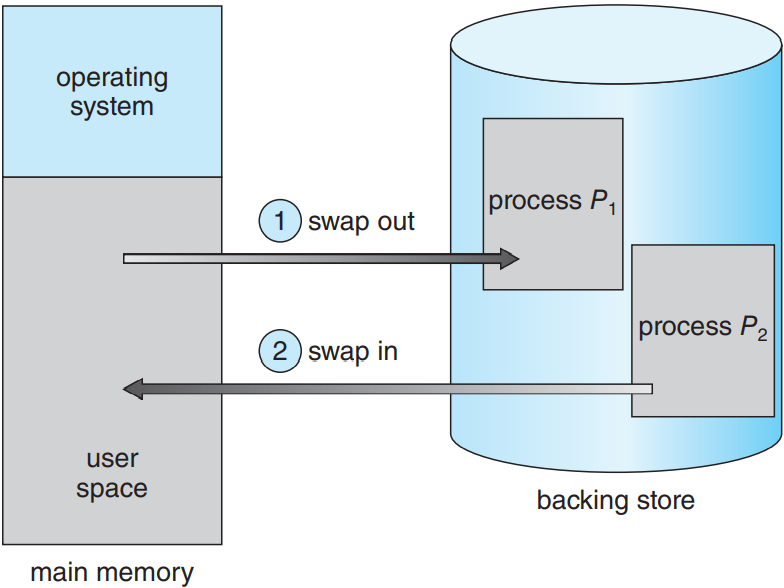
프로세스 명령어나 데이터는 반드시 메모리에 있어야 실행이 가능함. 근데 프로세스나 프로세스의 일부분을 잠깐 메모리 밖의 보조 스토리지 backing store로 스왑 swap을 해줬다가, 실행을 계속하려할 때 다시 올려줄 수 있음(다음 그림 참조). 스와핑을 통해 프로세스의 전체 물리 주소 공간이 시스템의 실제 물리 메모리를 초과할 수 있어 시스템의 다중프로그래밍의 차수를 높여줌.
9.5.1. 표준 스와핑
표준 스와핑은 프로세스 전체를 주기억장치에서 보조 스토리지로 옮기는 것임. 보통 보조 스토리지로는 빠른 보조 기억 장치를 사용함. 당연히 프로세스의 그 어떠한 부분이든 저장하고 빼올 수 있을 만큼 커야하며, 이 메모리 이미지에 직접 접근이 가능해야 함. 프로세스 전체나 일부분이 보조 스토리지로 스왑이 되면 프로세스와 연관된 자료 구조를 반드시 보조 스토리지에 써야 함. 멀티스레드 프로세스에선 스레드 별 자료 구조를 반드시 스왑해줘야함. 운영체제는 또한 스왑되어 나간 프로세스들에 대한 메타데이터를 갖고 있어야 함. 그래야 나중에 메모리로 스왑되어 들어올 때 복구해줄 수 있으니까.
표준 스와핑의 장점은 물리 메모리를 확장해주어 시스템이 실제 물리 메모리보다 더 많은 프로세스를 처리할 수 있게 됨. 특히 아무 것도 안하고 있거나 거의 아무 것도 안 하는 프로세스가 스와핑하기 제일 좋은 친구들임. 얘네를 스와핑해서 얻은 메모리를 좀 더 활발한 친구들에게 넘겨주면 되니까. 만약 비활성화된 프로세스가 다시 활성화되면 다시 스왑해서 들어오면 됨. 아래 그림 참고.
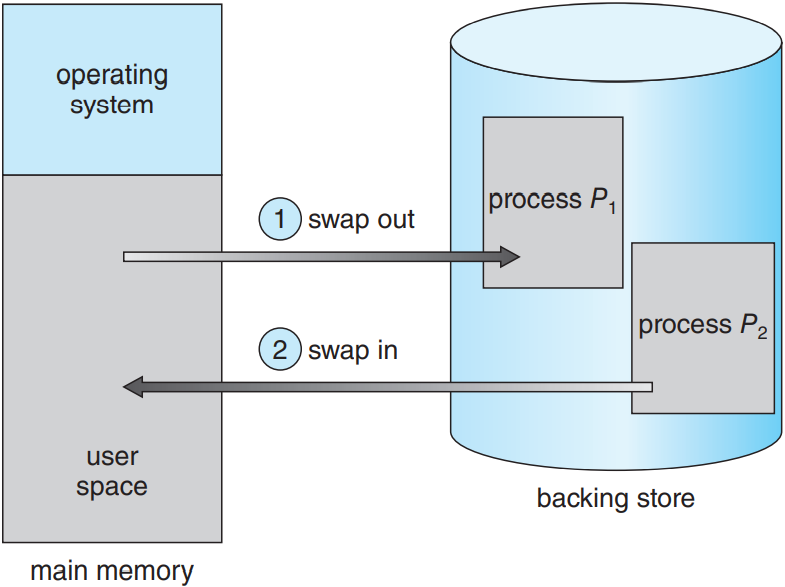
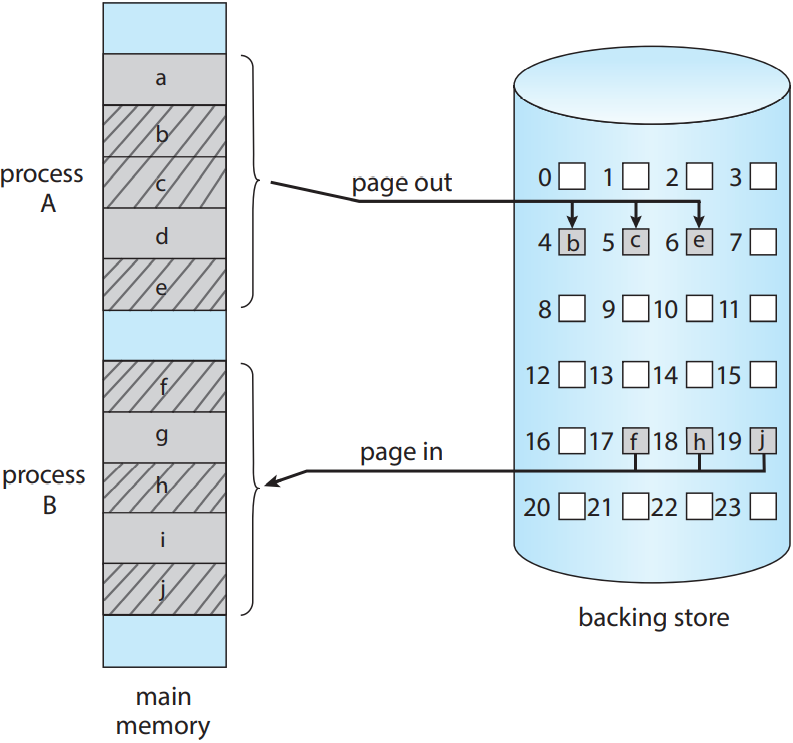
9.5.2. 페이징을 통한 스와핑
전통적인 UNIX 시스템에서는 표준 스와핑을 사용했으나, 요즘엔 거의 사용 안 함. 메모리와 보조 스토리지 간에 프로세스 전체를 옮기는 과정이 금지되었기 때문임.(예외 사항으로는 Solaris가 있음. 아직도 표준 스와핑 사용함. 물론 메모리가 극단적으로 적을 때와 같이 특수한 상황에서만 사용함.)
Linux나 Windows와 같은 대부분의 시스템에서는 프로세스 전체가 아니라 프로세스의 페이지를 스와핑하는 방법을 사용함. 이를 통해 물리 메모리를 확장하면서도 전체 프로세스를 스와핑하는 비용도 아낄 수 있음. 스와핑할 페이지 몇 개만 스와핑하면 되니까. 사실 스와핑이라는 표현도 이제는 일반적으로 기존 표준 스와핑을 지칭하고, 페이징으로 페이징을 통한 스와핑을 지칭함. 페이지 아웃 page out 연산이 페이지를 메모리에서 보조 스토리지로 옮기는 과정이고, 그 반대가 페이지 인 page in임. 페이징을 통한 스와핑은 다음 그림을 참고. 이 그림에선 프로세스 A와 B의 페이지의 부분집합이 각각 페이지 아웃 / 인 되고 있음. 10 단원에서 보겠지만, 페이징을 통한 스와핑은 가상 메모리와 짝짜꿍이 잘 맞음.
스와핑을 통한 시스템 성능
페이지 스와핑이 프로세스 전체를 스와핑하는 것보단 효율적이지만, 시스템이 어떤 방법이든 스와핑을 하고 있다는 것은 현재 사용 가능한 물리 메모리보다 더 많은 활성 프로세스가 있다는 뜻임. 이 경우 두 가지 방법으로 처리할 수 있음: (1) 프로세스 몇 개를 종료시키거나, (2) 더 많은 물리 메모리를 얻으면 됨.
9.5.3. 모바일 시스템에서의 스와핑
생략
9.6. 예시: Intel 32- 및 64-비트 아키텍처
인텔엔 여러 아키텍처가 있으므로 모든 칩에서의 메모리 구조를 설명할 수는 없거니와, CPU의 모든 디테일을 언급할 순 없음. 이건 컴퓨터 구조의 영역임. 여기서는 Intel CPU에서 사용하는 주된 메모리 관리 개념을 보도록 함.
9.6.1. IA-32 아키텍처
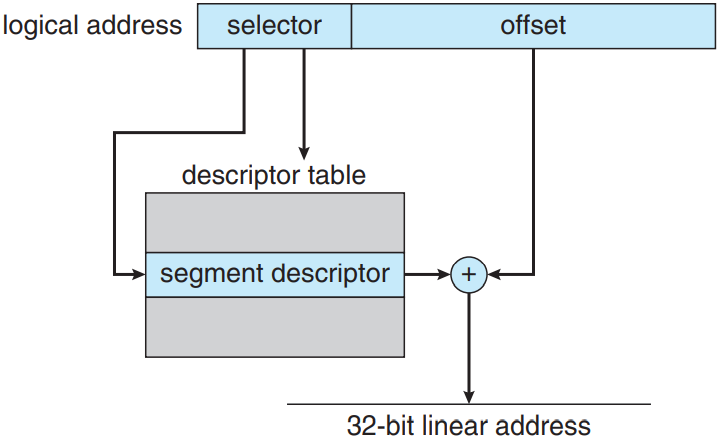
IA-32 시스템의 메모리 관리는 두 성분으로 나뉨. 바로 조각내기와 페이징임. 동작은 다음과 같음: CPU가 가상 주소를 생성하고 조각내기 장치에 이 주소를 부여함. 조각내기 장치는 각 가상 주소별로 선형 주소를 생성함. 선형 주소는 이후 페이지 유닛을 부여받아 주 기억장치로의 물리 주소를 생성함. 결국 조각내기 유닛과 페이지 유닛이 메모리 관리 장치(MMU)와 동일한 형태를 띠게 됨. 그림 참고.

9.6.1.1. IA-32 조각내기
IA-32 아키텍처에서 한 조각은 최대 4 GB가 될ㄹ 수 있으며, 프로세스 당 최대 조각 수는 16,000 개임. 프로세스의 가상 주소 공간은 두 부분으로 나뉨. 첫번째 부분은 해당 프로세스에만 해당하는 8,000 개의 조각이고, 두번째 부분은 프로세스 간 공유하는 8,000 개의 조각임. 첫번째 부분에 대한 정보는 지역 기술자 테이블 local descriptor table(LDT)에 기록되어있으며, 두번째 부분에 대한 정보는 전역 기술자 테이블 global descriptor table(GDT)에 저장되어 있음. 각 테이블의 엔트리는 8 바이트 조각 기술자로 이루어져있음. 각 엔트리의 기술자는 자신이 해당하는 조각에 대한 세부적인 정보, 즉 조각의 베이스 위치나 리미트 등의 정보를 갖고 있음.
가상 주소는 (선택자, 오프셋) 짝으로 구성되며, 선택자는 16 비트 숫자임:
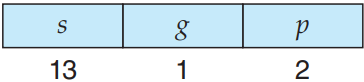
여기서 s가 조각 숫자를, g가 조각이 GDT인지 LDT인지를, p가 보호를 담당함. 오프셋은 현재 다루는 조각에서 몇번째 바이트인지를 의미하는 32 비트 숫자임.
기계에는 여섯 개의 조각 레지스터가 존재하여 한 프로세스가 임의의 순간에 여섯 개의 조각을 참조할 수 있도록 해줌. 또한 여섯 개의 8 바이트 초소형프로그램 레지스터를 통해 LDT나 GDT로부터 대응하는 기술자를 갖고 있게 함. 이러한 캐시를 통해 Pentium이 메모리 참조할 때마다 메모리 기술자를 읽어올 필요가 없었음.
IA-32의 선형 주소는 32 비트 정도의 길이를 가지며, 다음과 같이 구성됨. 조각 레지스터가 LDT 혹은 GDT로의 엔트리를 가리킴. 이때 이 조각에 대한 베이스와 리미트 정보로 선형 주소 linear address를 생성함. 우선 리미트로 주소의 유효성을 확인함. 만약 무효하다면 메모리 틀림이 생성되어 운영체제로 트랩을 보내게 됨. 유효하다면 오프셋의 값을 베이스에 더해주어 32 비트 선형 주소를 생성함. 아래 그림 참고. 다음 절에서는 페이지 장치가 선형 주소를 물리 주소로 어떻게 변환하는지를 다룸.
9.6.1.2. IA-32 페이징
IA-32 아키텍처는 페이즈 크기가 4 KB이거나 4 MB임. 4 KB 페이지의 경우 이단계 페이징 스킴을 사용하여 32 비트 선형 주소를 다음과 같이 구분함:
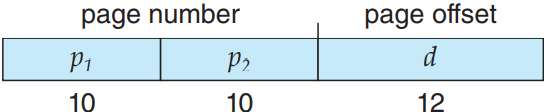
이 아키텍처에서의 주소 변환 스킴은 아래의 그림과 유사함.
IA-32 주소 변환은 다음 그림에서 좀 더 세부적으로 표현되어 있음.
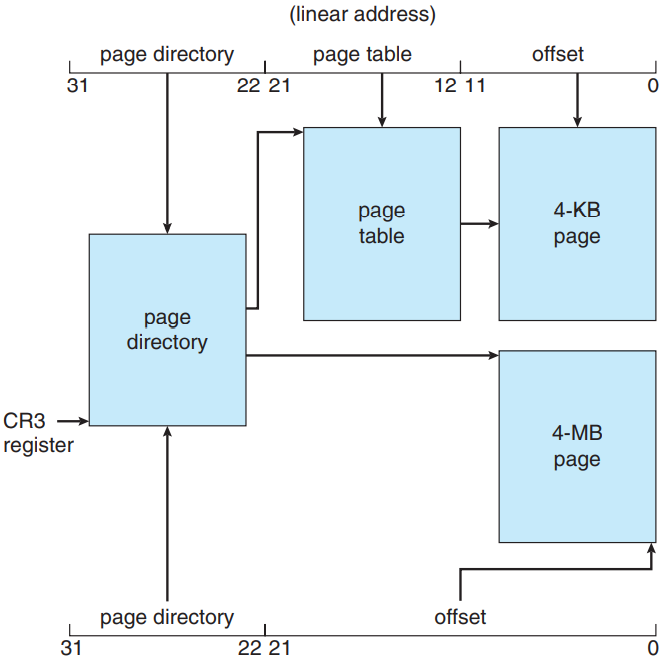
고위 10 번째 비트가 가장 외부의 페이지 테이블의 엔트리를 참조함. 이게 IA-32에서는 페이지 경로 page directory라 부름. (CR3 레지스터가 현재 프로세스의 페이지 경로를 가리킴.) 페이지 경로 엔트리는 내부 페이지 테이블을 가리킴. 이때 이 내부 페이지 테이블은 선형 주소의 제일 안쪽 10 개의 비트가 색인이 됨. 최종적으로 저위 0-11 비트가 페이지 테이블에서 4 KB 페이지를 가리키는 오프셋이 됨.
페이지 경로의 엔트리 중 하나는 Page_Size 플래그 값으로, 만약 설정이 되어 있다면 페이지 프레임의 크기가 표준 크기 4 KB가 아닌 4 MB라는 뜻임. 이 경우 페이지 경로는 내부 페이지 테이블을 거치지 않고 직접 4 MB 페이지 프레임을 가리킴. 이러면 선형 주소의 저위 22 비트는 4 MB 페이지 프레임의 오프셋이 됨.
물리 메모리의 효율성을 높이기 위해 IA-32 페이지 테이블을 디스크에 스왑해줄 수도 있음. 이 경우 페이지 경로에 무효 비트를 사용해서 엔트리가 가리키는 테이블이 메모리에 있는지 디스크에 있는지를 표현해줄 수 있음. 테이블이 디스크에 있으면 운영체제에서는 나머지 31비트로 테이블이 리스크 어디에 있는지를 표현해주면 됨. 나중에 필요하면 그거 보고 갖고 오면 됨.
슬슬 소프트웨어 개발자들이 32 비트 아키텍처가 갖는 4 GB 메모리라는 한계를 느끼기 시작하자 Intel이 페이지 주소 확장 page address extension (PAE)이라는 방법을 통해 32 비트 프로세서가 4 GB보다 큰 물리 주소 공간에 접근할 수 있도록 해줌. PAE의 차이점이라면 원래 페이징은 이단계 스킴이었는데, 이제는 삼단계 스킴이라는 것이고, 최상단 비트 두 개가 페이지 경로 포인터 테이블 page directory pointer table을 가리킨다는 것임. 아래 그림은 4 KB 페이지를 갖는 PAE 시스템임. (2 MB 페이지도 지원함.)
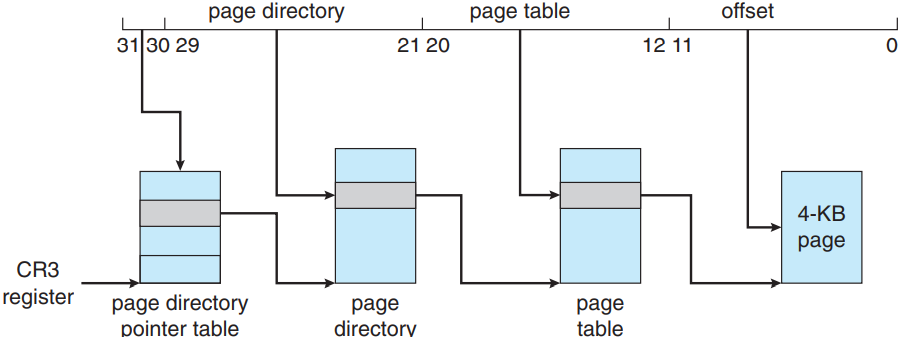
PAE는 여기에 더 나아가서 페이지 경로와 페이지 테이블 엔트리 크기를 32 비트에서 64 비트로 확장해주어 페이지 테이블과 페이지 프레임의 베이스 주소가 20에서 24 비트로 늘어나게 됨. 이걸 12 비트 오프셋에 합쳐주면 IA-32 + PAE 시스템의 주소 공간은 36 비트로 커져서 64 GB의 물리 주소를 표현할 수 있게 됨. 여기서 중요한 건 PAE를 사용하려면 운영체제가 이걸 지원해야한다는 것임. Linux랑 macOS 둘 다 PAE를 지원하는데, 32 비트 Windows 데스크탑 운영체제는 PAE를 활성화해도 4 GB의 물리 메모리만 지원함.
9.6.2. x86-64
Intel의 첫 64 비트 아키텍처는 IA-64(나중에 +이타니움 Itanium이라 불렀음)으로 시작했다가 널리 안 받아들여졌음. 반면에 AMD가 개발한 64 비트 아키텍처가 있는데, 이게 IA-32 명령어 집합을 바탕으로 만든 x86-64임. 이게 더 큰 가상 / 물리 주소 공간을 지원하고 여러 아키텍처적 장점을 가졌었음. 원래 전통적을 AMD는 Intel의 아키텍처에 기반해서 칩을 개발했는데, 이제는 Intel이 AMD의 x86-64 아키텍처를 따라가는 형태가 됨. 그런 의미에서 시중에서 부르는 AMD64나 Intel 64보다는 더 일반적인 용어인 x86-64로 부르기로 함.
64 비트 주소를 지원하면 무려 264 바이트만큼이나 주소를 매길 수 있는 메모리를 얻을 수 있음. 이거 1,600 경(16 엑사바이트)이 넘는 수임. 근데 애초에 현실적으로 이 메모리를 다 차지할 수 없어서 현재 설계에서는 주소를 표기할 땐 64 비트보다 덜 사용하게 됨. x86-64 아키텍처는 현재 48 비트 가상 주소에다가 사단계 페이징 계층을 바탕으로 4 KB, 2MB 혹은 1 GB 페이지 크기를 사용함. 선형 주소는 다음과 같음:
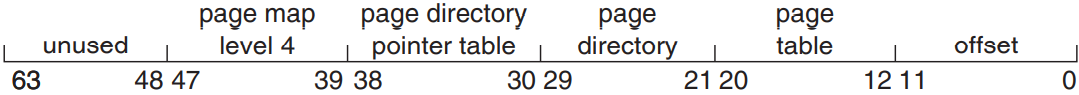
이렇게 주소를 사용하면 PAE를 사용할 수 있으니 가상 주소의 크기는 48 비트지만 52 비트 물리 주소(4,096 테라바이트)를 표현해줄 수 있음.
9.7. 예시: ARMv8 아키텍처
생략
9.8. 요약
- 메모리는 현대 컴퓨터 시스템 연산의 중심이며, 각 바이트마다 자신만의 주소를 갖는 거대한 바이트의 배열로 구성됨.
- 각 프로세스 별로 주소 공간을 할당하는 방법으로는 베이스와 리미트 레지스터를 사용하는 법이 있음. 베이스 레지스터라는 최소 사용 가능 물리 메모리 주소를 가지며, 리미트 레지스터는 범위의 크기를 의미.
- 기호적 주소 참조를 실제 물리 주소에 바인딩하는 과정은 다음 과정 중에 발생 가능:
- 컴파일
- 불러오기
- 실행 중
- CPU가 생성한 주소를 논리 주소라 부르며, 메모리 관리 장치(MMU)가 이를 메모리의 물리 주소로 변환해줌.
- 메모리 할당법 중 하나는 다양한 크기의 연속된 메모리의 일부분을 할당하는 법임. 이러한 분할은 세 가지 전략을 바탕으로 할당 가능:
- 최초 적합
- 최적 적합
- 최악 적합
- 현대 운영체제는 페이징 기법으로 메모리 관리함. 물리 메모리를 프레임이라는 고정 크기 블록으로 나눈 다음 논리 메모리를 페이지라는 동일한 크기의 블록으로 나눔.
- 페이징을 사용할 경우 논리 주소는 페이지 수와 페이지 오프셋 두 부분으로 나뉨. 페이지 수란 페이지를 갖는, 물리 메모리의 프레임을 갖는 프로세스 당 페이지 테이블에 대응이 되며, 오프셋이란 참조하는 프레임에서의 세부적인 위치를 의미함.
- 변환 색인 버퍼(TLB)란 페이지 테이블의 하드웨어 캐시를 의미함. 각 TLB의 내용은 페이지 수와 이에 대응하는 프레임을 가짐.
- 페이징 시스템에서 주소 변환할 때 TLB를 사용할 땐 논리 주소로부터 페이지 수를 가져오고 페이지를 위한 프레임이 TLB에 있는지를 확인함. 만약 그렇다면 프레임은 TLB로부터 얻을 수 있음. 그렇지 않다면 페이지 테이블로부터 가져와야함.
- 계층적 페이징은 논리 주소를 여러 부분으로 나누어 각각 페이지 테이블의 여러 레벨을 참조하게 함. 주소가 32비트를 넘어 확장하며 계층 레벨 수가 증가함. 이 문제를 해결하기 위해 해시 페이지 테이블 혹은 역 페이지 테이블을 사용함.
- 스와핑을 통해 시스템이 프로세스의 페이지를 디스크로 옮겨 다중프로그래밍의 차수를 증가시켜줌.
- Intel 32-비트 아키텍처는 두 단계의 페이지 테이블이 있으며 4-KB 혹은 4-MB 페이지 크기를 지원함. 이 아키텍처는 또한 페이지 주소 확장을 지원해 32-비트 프로세서가 4GB보다 큰 물리 주소 공간에 접근할 수 있도록 해줌. x86-64와 ARMv9 아키텍처는 계층적 페이징을 사용하는 64-비트 아키텍처임.
