운영체제 수업 1주차 내용은 운영체제 개요로, 운영체제의 정의, 컴퓨팅 시스템 구조, 운영체제 구조, 운영체제가 제공하는 서비스 종류 등에 대해서 다룬다.
1. 개요
- 운영체제
- 정의: 컴퓨터 하드웨어와 컴퓨터 사용자 간의 중간 단계.
- 목적: 사용자가 프로그램을 편하고 효율적으로 실행할 수 있도록 하는 환경 제공
1. 서론
운영체제의 핵심 역할 중 하나는 CPU, 메모리, 입출력 장치와 기억 장치와 같은 컴퓨터 하드웨어 자원을 프로그램에 할당하는 것
- 목표
- 컴퓨터 시스템의 일반적인 조직과 인터럽트의 역할
- 현대 다중 프로세서 컴퓨터 시스템의 성분
- 사용자 모드에서 커널 모드로의 전환
- 운영체제가 다양한 컴퓨팅 환경에서 어떻게 사용되는 지
- 무료 / 오픈소스 운영체제 예시
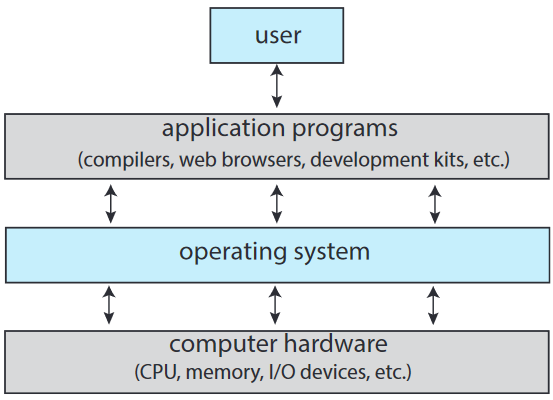
1.1. 운영체제가 하는 일
- 컴퓨터 시스템 Computer System
- 사용자 User
- 하드웨어 Hardware
- 시스템의 기본 컴퓨팅 자원을 제공
- CPU
- 메모리
- 입출력 장치 등
- 어플리케이션 프로그램 Application Program
- 사용자의 컴퓨팅 문제를 이 자원들을 통해 해결하는 법이 정의되어 있음
- 아래아 한글
- 엑셀
- 컴파일러
- 웹 브라우저 등
- 운영체제 Operating System
- 하드웨어를 제어하여 다양한 사용자들의 다양한 어플리케이션 프로그램에서 사용할 수 있도록 협조함
또다른 분류:
- 컴퓨터 시스템
- 하드웨어
- 소프트웨어
- 데이터
위의 분류에서 운영체제는 컴퓨터 시스템의 연산에서 이 자원들의 사용하는 방법을 제공함.
운영체제는 그 자체로는 유용한 함수를 제공하지 않지만, 프로그램들이 유용하게 사용할 수 있는 환경을 제공.
1.1.1. 사용자 입장
인터페이스에 따라 입장이 달라짐. 대부분의 경우 한 사용자가 자원을 독점하는 형태(모니터, 키보드, 마우스)의 시스템. 사용자의 업무 능률을 극대화하는 목적. 이 경우 운영체제는 사용 편의성 ease of use에 집중하며, 자원 활용 resource utilization에는 신경 X.
모바일의 경우 네트워크로 연결된 장치. 사용자 인터페이스 상으론 터치 스크린 touch screen 제공. 애플의 시리 Siri와 같은 음성 인식 voice recognition 인터페이스도 제공.
임베디드 컴퓨터 embedded computer의 경우 인터페이스가 아예 없거나 적음. 애초에 사용자의 개입 없이도 실행될 수 있도록 설계됨.
1.1.2. 시스템 입장
시스템 입장에서 운영체제란 하드웨어와 가장 밀접한 프로그램. 즉, 자원 할당자 resource allocator로 볼 수 있음.
또다른 시각으로 보면 운영체제는 사용자 프로그램과 특히나 여러 입출력 장치를 제어하여 오류와 컴퓨터의 오용을 방지하는 제어 프로그램 control program임.
1.1.3. 운영체제 정의하기
운영체제는 컴퓨터의 수많은 설계와 역할 때문에 많은 역할과 기능 가짐.
군사적 목적의 컴퓨터가 대중화되면서 운영체제 등장. 60년대 무어의 법칙 Moore's Law에 의해 18개월마다 트랜지스터 두 배가 된다고 예측하며, 이는 정확히 들어 맞음. 기능도 크기와 함께 늘어남.
컴퓨터 시스템의 핵심 목표는 프로그램 실행을 통해 사용자의 문제를 손쉽게 해결해주는 것. 이를 위해선 하드웨어와 어플리이션 프로그램이 필요. 이때 어플리케이션이 하드웨어를 제어해야함. 이때 공통된 기능을 제어하고 자원을 할당하는 역할을 하나의 소프트웨어로 묶은 것이 운영체제.
운영체제는 컴퓨터에서 언제나 실행되는 프로그램이며, 커널 kernel이라고도 부름. 커널과 함께 시스템 프로그램과 어플리케이션 프로그램 두 가지가 있음. 시스템 프로그램은 운영체제와 연관되어있으나 커널의 일부분은 아님.
기능이 너무 많아도 문제임. 마소는 윈도우즈에 기능이 너무 많다고 미 사법부한테 고소당해 유죄 판결 나옴.
모바일의 경우 기능 엄청 많음. 코어 커널 뿐만 아니라 미들웨어 middleware라고 어플리케이션 개발자들에게 몇 가지 추가적인 서비스를 제공하는 소프트웨어 프레임워크들이 들어감.
요약:
- 운영체제
- 언제나 실행되는 커널
- 어플리케이션 개발의 편의와 기능 제공을 위한 미들웨어 프레임워크
- 시스템 관리하는 데에 도움을 주는 시스템 프로그램
본 서적은 일반적인 목적의 운영체제 커널에 해당하는 내용을 주로 다룸.
운영체제를 공부하는 이유
거의 모든 코드는 운영체제 위에서 동작하기 때문.
1.2. 컴퓨터 시스템 조직
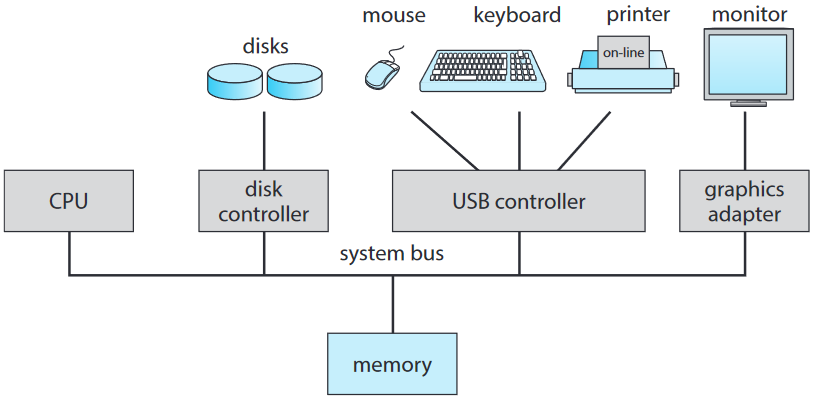
현대 범용 컴퓨터 시스템은 한 개 이상 CPU와 공통 버스 bus에 연결된 여러 장치 제어자들을 갖고 있음. 버스란 성분과 공유 메모리 간의 접근을 제공. 장치 제어자는 대부에 로컬 버퍼 저장소와 특수 목적 레지스터 집합을 갖고 있음. 장치 제어자는 제어의 대상이 되는 주변 장치와 자신의 로컬 버퍼 저장소 간에 데이터 수송 담당.
보통 운영체제는 각 장치 제어자 별로 장치 드라이버 device driver를 갖고 있음. 장치 드라이버는 장치 제어자를 이해하고 운영체제에게 본인의 장치에 대한 균일한 인터페이스 제공. (장치 드라이버를 통해 장치의 기능을 운영체제에 호환되는 형식으로 제공한다는 의미인듯?) CPU와 장치 제어자는 병렬로 실행 가능, 메모리 갖고 서로 경쟁.
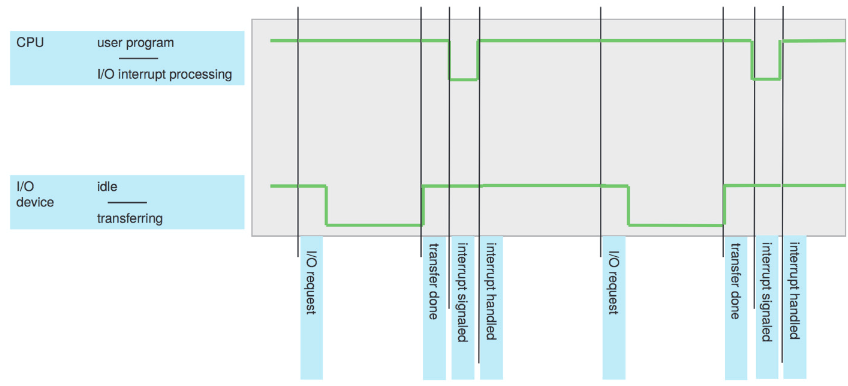
1.2.1. 인터럽트
컴퓨터 연산 예시 (입출력):
1. 장치 드라이버가 장치 제어자에서 적합한 레지스터 불러옴
2. 장치 제어자가 그 다음 이 레지스터의 내용물을 보고 무슨 액션(키보드에서 문자 읽기 등)을 해야 할지 결정
3. 제어자가 장치에서 자기 로컬 버퍼로 데이터 옮김
4. 데이터 옮긴 후 장치 제어자가 장치 드라이버에게 연산 끝났다고 알림
5. 장치 제어자는 운영체제의 다른 부분에 제어권을 줌. 만약 연산이 읽기였다면 아마 데이터나 데이터를 가리키는 포인터를 반환했을 수도. 다른 연산의 경우 "쓰기 성공" 혹은 "장치 바쁨"과 같은 상태 정보 전달.
이때 제어자가 장치 드라이버에게 연산이 끝났음을 알리는 것이 인터럽트 interrupt
1.2.1.1. 개요
하드웨어는 CPU한테 신호를 주로 시스템 버스(버스는 많은데, 시스템 버스가 주요 성분 간의 통신로임)를 통해 보내는 식으로 언제나 인터럽트 발생 시킬 수 있음. 인터럽트는 다른 용도로 사용할 수도 있으며 운영체제와 하드웨어가 상호작용하는 핵심.
CPU가 인터럽트되면 지금 하고 있던 거 멈추고 즉시 실행을 고정된 위치로 바꿈. 고정된 위치는 주로 인터럽트가 위치한 서비스 루틴의 시작 주소. (함수 포인터 같은 거라고 생각하면 될 듯?) 인터럽트 서비스 루틴 실행 다 끝나면 CPU는 중단됐던 연산 재시작함.
인터럽트는 컴퓨터 구조의 핵심 부분. 인터럽트는 반드시 제어를 알맞는 인터럽트 서비스 루틴으로 전환하게 해야 함. 이거 처리하는 무식한 방법으로는 인터럽트 정보 확인하는 루틴을 돌리는 것. 이 루틴은 인터럽트의 핸들러를 호출할 것. 근데 인터럽트는 자주 발생하니 빠르게 처리해야하니까 인터럽트 루틴에 대한 포인터 테이블로 속도를 처리. 인터럽트 루틴은 테이블로 간접적으로 호출하니 중간의 루틴 필요 없음. 이 포인터들은 메모리 낮은 곳(첫 100 정도)에 위치. 이걸 인터럽트 벡터 interrupt vector에 고유한 색인을 가져서 인터럽트 요청에 대해 인터럽트 서비스 루틴의 주소를 제공. 윈도우즈랑 리눅스가 이렇게 함.
인터럽트 루틴이 레지스터 값을 수정하는 식으로 프로세서 상태를 수정할 수도 있으니 명시적으로 현재 상태를 저장해두고 나중에 복원해야 함. 인터럽트가 서비스될 때 저장된 반환 주소를 프로그램 카운터에 불러오고, 인터럽트된 연산이 마치 인터럽트가 발생한 적 없는 것처럼 재시작이 됨.
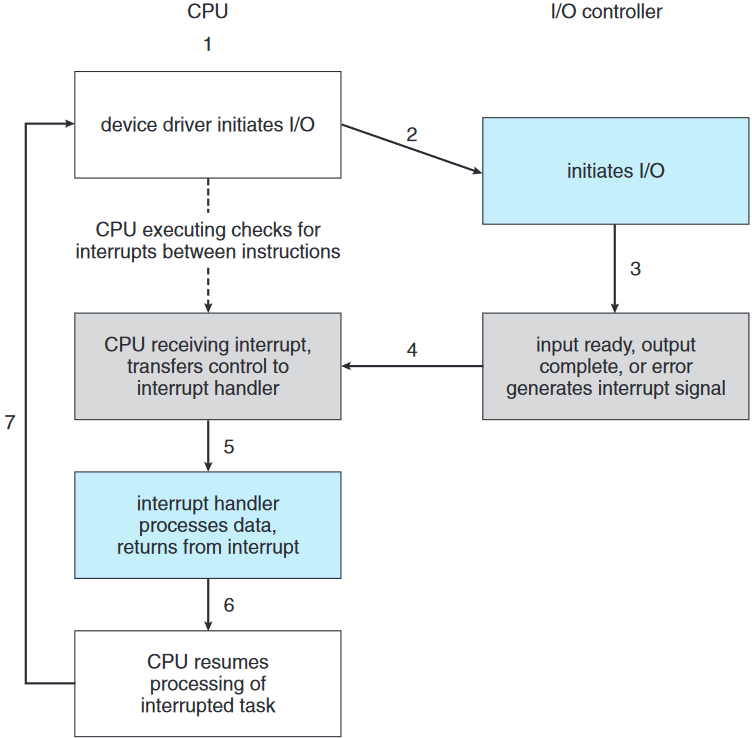
1.2.1.2. 구현
- CPU 하드웨어에는 CPU가 매 지시 실행 후에 확인하는 인터럽트-요청 선 interrupt-request line이 존재.
- CPU가 제어자가 인터럽트-요청 선에 신호가 왔음을 탐지하면 인터럽트 숫자를 색인 삼아 인터럽트 벡터를 통해 인터럽트-처리자 루틴 interrupt-handler routine로 도약함.
- 도약한 주소 실행
- 인터럽트 처리자가 연산에 따라 바뀔 수도 있는 모든 상태를 저장
- 인터럽트 처리자가 인터럽트의 원인을 파악하고 필요한 처리를 수행한 후 상태를 복원한 후
return_from_interrupt지시를 실행하여 인터럽트 이전의 실행 상태로 CPU를 복원함
- 장치 제어자가 인터럽트 요청 선에 신호를 전달하여 인터럽트가 발생함 raise.
- CPU가 인터럽트를 받고 catch 이 신호를 인터럽트 처리자에 발송 dispatch함.
- 인터럽트 처리자가 장치의 서비스를 해주어 인터럽트를 처리 clear함.
현대 운영체제는 더 복잡한 인터럽트 처리 기능이 필요:
- 중요한 프로세스 처리 중 인터럽트 처리의 지연 기능
- 장치에 알맞은 인터럽트 처리자에 발송하는 효율적인 방법
- 운영체제가 우선 순위에 따라 처리 가능한 다계층 인터럽트
현대 컴퓨터 하드웨어에서 이런 기능은 CPU와 인터럽트-제어자 하드웨어 interrupt-controller hardware가 제공.
CPU의 인터럽트 요청 선
- 마스크 불가 인터럽트 nonmaskable interrupt
- 복원 불가한 메모리 오류와 같은 경우에 사용
- 마스크 가능 인터럽트 maskable interrupt
- 인터럽트 받아서는 안되는 중요한 지시의 연속을 수행 중일 때 CPU가 끌 수 있음
- 장치 제어자가 서비스 요청할 때 사용
실제로는 컴퓨터가 인터럽트 벡터보다 더 많은 장치(인터럽트 처리자)를 갖고 있음. 인터럽트 체이닝interrupt chaining을 통한 해법. 인터럽트 벡터의 각 원소가 인터럽트 처리자 목록의 시작부분을 가리킴. 인터럽트가 발생하면 해당 목록에 있는 처리자를 요청에 따른 서비스를 찾을 때까지 하나 하나 호출. 거대한 인터럽트 테이블에 의한 오버헤드와 하나의 인터럽트 처리자로의 발송에 따른 비효율성 간의 절충안이라 보면 됨.
아래 그림은 인텔 프로세서의 인터럽트 벡터 설계. 0 ~ 31는 마스크 불가, 여러 오류 조건 신호임. 32부터 255은 마스크 가능이며, 장치가 생성한 인터럽트 용도로 사용.
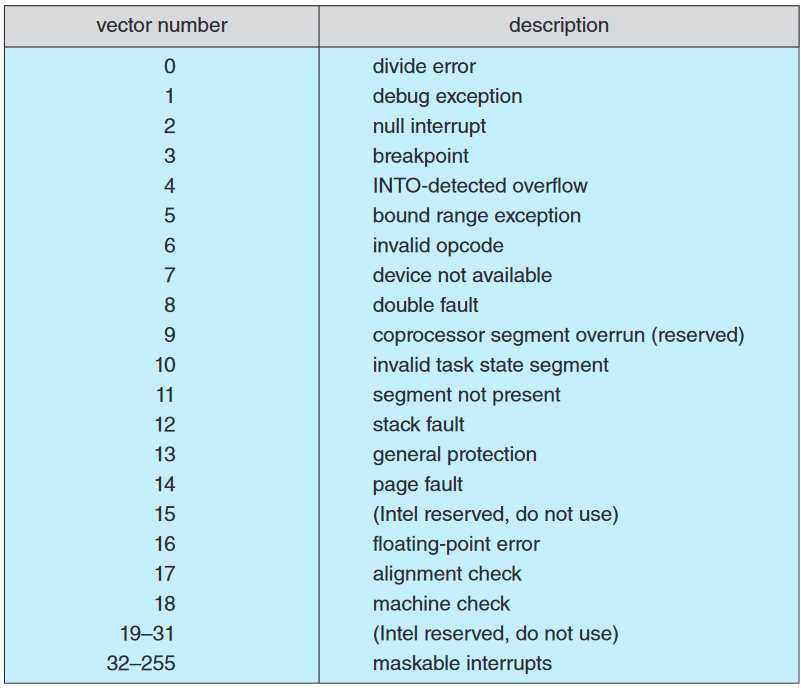
인터럽트 우선 순위 레벨 interrupt priority level 시스템을 통해 CPU가 우선 순위 낮은 인터럽트의 처리를 모든 인터럽트를 마스킹시키지 않고도 지연시킬 수 있어 우선 순위가 높은 인터럽트를 낮은 인터럽트보다 먼저 처리하게 해줌.
요약:
- 현대 운영체제는 비동기 이벤트를 처리하려고 인터럽트를 사용.
- 장치 제어자와 하드웨어 결함 인터럽트 발생 가능
- 현대 컴퓨터는 인터럽트 우선 순위 시스템 사용
- 인터럽트는 시간이 중요한 프로세스에 주로 사용하기에 효율적인 인터럽트 처리가 좋은 시스템 성능을 보임
1.2.2. 저장 구조
CPU는 오로지 메모리에서부터 지시어를 불러올 수 있음 -> 모든 프로그램은 메모리에 우선 존재해야 함. 범용 컴퓨터는 프로그램을 재작성 가능 메모리, 즉 주메모리(임의 접근 기억 장치 random-access memory 혹은 램 RAM)에서 돈다. 주메모리는 동적 램dynamic random-access memory(DRAM)이라는 반도체 기술 사용
컴퓨터 전원 킬 때 처음으로 실행되는 프로그램은 부트스트랩 프로그램 bootstrap program으로, 얘가 운영체제를 불러옴. 램은 휘발성 volatile이기 때문에 전원 끄면 메모리 다 잃어버림. 여기에 부트스트랩 프로그램 저장 못하고, 소거 및 프로그램 가능 읽기용 기억 장치(EEPROM)나 다른 펌웨어 firmware 기억 장치처럼 쓰기는 자주 안하면서 비휘발성인 메모리를 사용.
기억 장치의 정의 및 표기
컴퓨터 기억 장치의 기본 단위는 비트 bit. 바이트 byte는 8 비트로, 기억 장치의 한 청크 중 편하게 사용할 수 있는 것 중 가장 작은 단위. 워드 word는 컴퓨터 구조에 네이티브한 데이터 단위. 1 개 이상 바이트로 구성. 64 비트 레지스터와 64 비트 메모리 주소를 갖는 컴퓨터는 64 비트(8 바이트) 워드. 다음으로 1,024 바이트의 킬로바이트 kilobyte 혹은 KB, 1,0242 바이트의 메가바이트 megabyte 혹은 MB, 1,0243 바이트의 기가바이트 gigabyte 혹은 GB, 1,0244 바이트의 테라바이트 terabyte 혹은 TB, 1,0245 바이트의 페타바이트 petabyte 혹은 PB. 네트워크는 바이트 말고 비트 단위로 함.
모든 메모리는 바이트의 배열. 각 바이트는 주소를 가짐. 특정 메모리 주소에 대한 load 혹은 store 명령어의 연속을 통해 상호작용. load는 바이트나 워드를 주메모리에서 CPU 내부 레지스터로 옮김. store 명령어는 레지스터의 내용을 주메모리로 옮김. 명시적 load랑 store 말고도 CPU가 가종으로 명령어를 프로그램 카운터에 저장된 위치에서 실행을 위해 주메모리에서 뺌.
폰 노이만 구조 von Neumann architecture를 갖는 시스템에서의 실행 사이클과 같은 일반적인 명령어는 우선
- 메모리에서 명령어를 가져온 다음 명령어 레지스터 instruction register에 저장
- 이를 복호화 해서 피연산자를 메모리에서 가져와서 일종의 내부 레지스터에 저장.
- 피연산자에 명령어 처리 후 결과가 메모리에 저장될 수도
메모리 유닛은 메모리 주소의 흐름 밖에 못 봄. 어떻게 생성되는지(명령어 카운터, 색인, 역참조, 리터럴 주소 등) 어디에 사용할 건지(명령어 혹은 데이터)는 모름. 그러니까 프로그램에서 메모리 주소가 어떻게 생성되는지 몰라도 됨.
대부분의 시스템에서 주메모리에 데이터를 영구적으로 갖지 못하는 이유:
- 모든 프로그램과 데이터를 영구적으로 저장하기엔 주메모리가 너무 작음
- 주메모리는 휘발성임
그래서 보조 기억 장치 secondary storage가 주메모리의 확장판으로 존재. 영구적으로 더 많은 데이터 저장할 수 있어야 함.
가장 흔하게 사용하는 게 하드 디스크 드라이브 hard-disk drive(HDD)와 비휘발성 메모리 장치 nonvolatile memory(NVM) device. 주메모리보다 더 느려서 컴퓨터 시스템에서 보조 기억 장치 관리법이 핵심 중요 포인트임.
물론 레지스터, 주메모리, 보조 기억 장치는 하나의 설계법일 뿐. CD-ROM, 블루레이 등 많음. 너무 크고, 너무 느려서 특수한 상황에서만 사용하는 장치가 예비 기억 장치 tertiary storage. 각 기억 장치별로 데이터 저장, 나중에 가져올 때까지 잡아두는 기본 기능 필요.
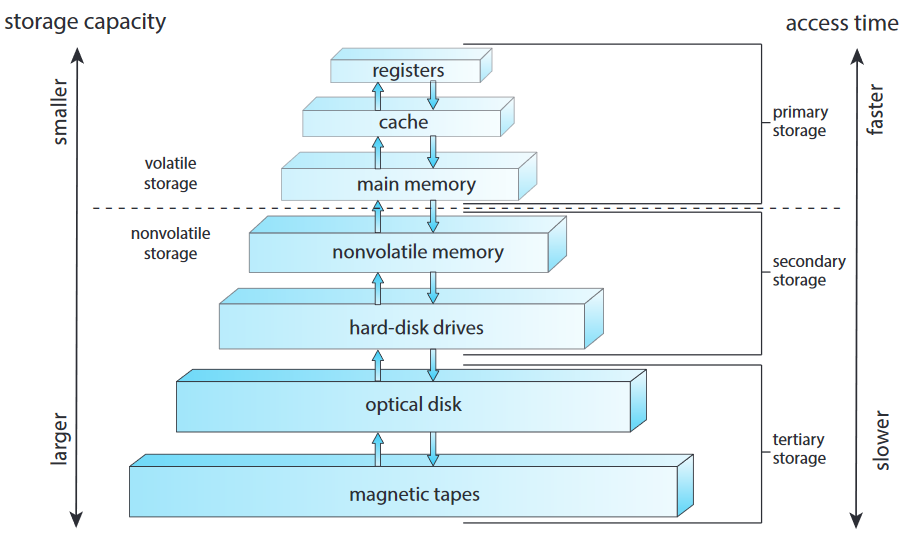
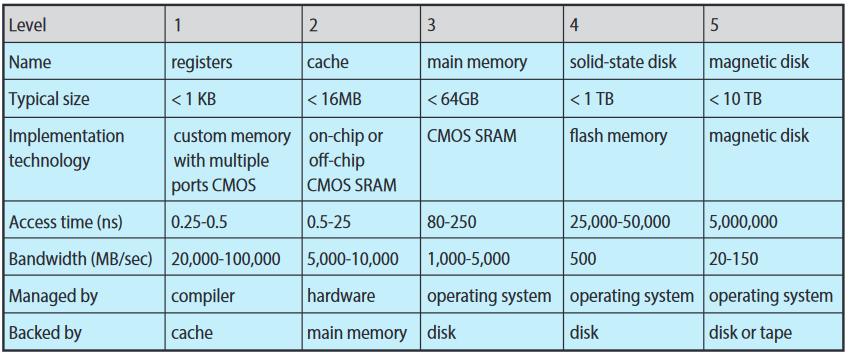
위 그림에서 처럼 보통 용량 / 속도 간의 트레이드오프 있음. CPU에 가까울 수록 용량은 적고 속도는 빠름.
상위 4 계층은 반도체 메모리 semiconductor memory임. 4번째의 NVM 메모리는 보통 하드디스크보단 빠름. 가장 흔한 NVM 메모리는 플래시 메모리로 모바일 장치에서 자주 사용하는데, 요즘은 노트북, 데탑, 서버에도 사용.
- 휘발성 기억 장치를 보통 **메모리 memory**라 칭함.
- 비휘발성 기억 장치는 **NVS**라 칭함.
- 기계적. HDD, 광메모리, 홀로그래픽 기억 장치, 자기 테이프 등
- 전자적. 플래시 메모리, FRAM, NRAM, SSD 등. NVM이라 칭함.
- 보통 기계적 기억 장치가 전자적 기억 장치보다 더 용량이 크고 바이트 당 가격도 낮음
기억 장치에서 데이터 간 거리가 멀어 두 성분 간 접근 시간이 있거나 전환율이 존재할 때 캐시를 설치해서 성능을 향상시킬 수도 있음.
1.2.3. 입출력 구조
운영체제 코드의 대부분 입출력 담당. 신뢰성에 대한 중요도나 시스템의 성능, 그리고 장치 별로 너무 다양하기 때문임.
인터럽트 주도적 입출력은 작은 데이터 옮기기엔 괜찮은데 NVS 입출력 같은 무거운 데이터를 옮기면 오버헤드가 커짐. 이거 해결하려고 직접 메모리 접근 direct memory access(DMA) 사용함. 입출력 장치를 위한 버퍼, 포인터, 카운터 다 설정하면 장치 제어자가 CPU 개입 없이 주메모리와 장치에서, 혹은 주메모리와 장치로 직접 데이터 블록 전체를 전달함. 블록 당 인터럽트가 하나만 생겨 굳이 속도 느린 장치에서 바이트 별로 인터럽트 발생할 필요 없이 장치 드라이버에게 연산이 끝났음을 알리면 됨. 장치 제어자가 이거 하는 동안 CPU는 자기 할 거 하면 됨.
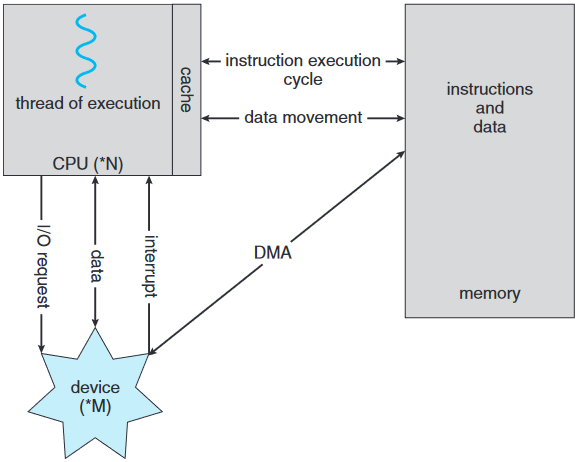
고성능 시스템은 스위치 대신 버스 구조 사용함. 여기선 여러 성분이 자기들끼리 동시에 소통 가능. 공유된 버스에서 사이클 두고 싸우는 게 아님. 이 경우엔 DMA가 훨씬 더 효율적으로 작동.
1.3. 컴퓨터 시스템 구조
컴퓨터 시스템 성분의 정의
모든 시스템은 가상적으로 다중코어이므로 CPU는 컴퓨터 시스템의 단일 연산 유닛을 칭하며, CPU 위에 하나 혹은 하나 이상의 코어를 가질 땐 코어 혹은 다중 코어로 각각 칭함.
- CPU - 명령어 실행하는 하드웨어
- 프로세서 - 한 개 이상 CPU를 포함하는 물리적 칩
- 코어 - CPU의 기본 연산 유닛
- 다중 코어 - 같은 CPU 내의 다중 연산 코어를 포함
- 다중 프로세서 - 다중 프로세서를 포함
1.3.1. 단일 프로세서 시스템
몇년 전까지만 해도 프로세서 코어 한 개만 있는 CPU 한 개 사용. 코어 core는 명령어와 지역적으로 데이터 저장용 레지스터를 실행하는 성분. 코어 있는 메인 CPU 하나면 범용 명령어 집합(프로세스의 명령어들 포함) 실행 가능.
특정 목적 프로세스는 한정된 명령어 집합에서 돌고, 프로세스를 처리하지 않음. 가끔 운영체제가 다음 작업이 뭔지 알려주고 그들의 상태를 모니터링하는 식으로 관리해줌. 메인 CPU의 작업 부담을 덜어주는 것. 가끔은 하드웨어에 박힌 저수준 성분이라 운영체제가 이런 프로세서랑 통신할 수 없음. 지들 맘대로 알아서 작업을 수행함. 이런 특수 목적 마이크로프로세서는 흔함. 그렇다고 단일 프로세서가 다중 프로세서가 되는 건 아님. 범용 CPU가 하나고, 거기에 프로세스 코어가 하나면, 단일 프로세서 시스템임. 물론 이 정의에 따르면 요즘엔 단일 프로세서 시스템 매우 적음.
1.3.2. 다중 프로세서 시스템
요즘은 컴퓨터, 모바일, 서버 다 다중 프로세서 시스템 multiprocessor system임. 전통적으로는 단일 코어 CPU에 프로세스 두 개 이상인 시스템을 칭함. 프로세서는 컴퓨터 버스, 가끔 시계, 메모리, 보조 장치를 공유함. 다중 프로세서 시스템의 최고 장점은 향상된 처리율. 프로세서 N 개라고 해서 N 만큼 증가하진 않고 그보단 덜 증가함. 다중 프로세서가 한 작업에 대해 협력하면 모든 부분이 제대로 작동하도록 유지하는 곳에 오버헤드가 발생함. 여기에 공유 자원에 대한 경쟁 때문에 프로세서 추가한 거에 비해 이득이 좀 덜하긴 함.
가장 흔한 다중 프로세스 시스템은 대칭 다중 프로세싱 symmetric multiprocessing (SMP)임. 각 동교 CPU 프로세서가 운영체제 함수와 사용자 프로세스를 전부 포함한 모든 작업을 수행함. CPU 별로 레지스터와 개인(혹은 로컬) 캐시 보유. 허나 모든 프로세서는 시스템 버스 위의 물리 메모리를 공유함.
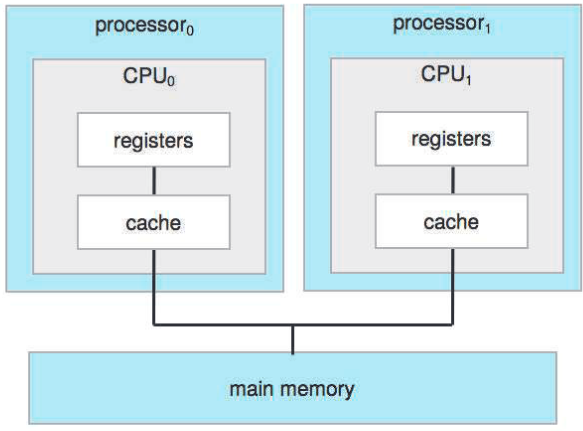
이 모델의 장점: CPU가 N 개면 N 개의 프로세스를 동시에 실행하면서 눈에 띄는 성능 저하가 없음. 허나 CPU 간 분리되어있기에 하나가 부하가 걸렸을 때 하나는 놀고 있어서 비효율적일 수도. 이건 서로 공유하는 자료 구조가 있으면 방지할 수 있음. 이 경우 프로세스나 자원이 여러 프로세서들이 동적으로 공유될 수 있어서 프로세스 간 업무 부하량이 낮아짐.
다중 프로세서의 정의는 이제 다중 코어 multicore 시스템을 포함. 칩 하나에 컴퓨팅 코어가 여러 개 있는 경우임. 단일 코어 다중 칩보다는 다중 코어 단일 칩이 더 효율적임. 칩 내부 통신이 칩 간 통신이 더 빠름. 전기도 덜 먹음.
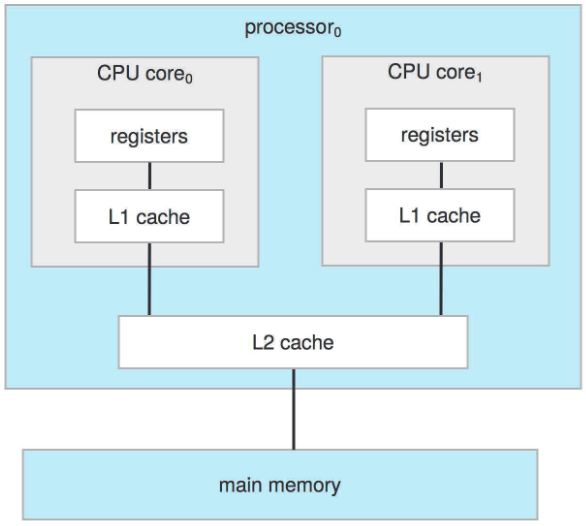
위의 단일 칩의 듀얼 코어 설계의 경우 코어 당 레지스터 집합이랑 레벨 1, 즉 L1 캐시라 부르는 로컬 캐시를 가짐. 칩에는 로컬인데 코어끼리는 공유하는 레벨 2 캐시인 L2 캐시도 존재. 대부분의 구조가 이 접근법을 사용. 로컬이랑 공유 캐시의 혼용으로 로컬 저수준 캐시는 고수준 캐시보다 더 작고 빠름. 구조적인 부분 말고도 N 개의 코어를 갖는 다중 코어 프로세서는 운영체제에게 N 개의 표준 CPU로 인식이 됨. 그래서 운영체제 설계자들이랑 어플리케이션 프로그래머들은 프로세싱 코어 효율적으로 써야함. 윈도우즈, 맥OS, 리눅스, 안드로이드, iOS 전부 다중 코어 SMP 시스템 지원함.
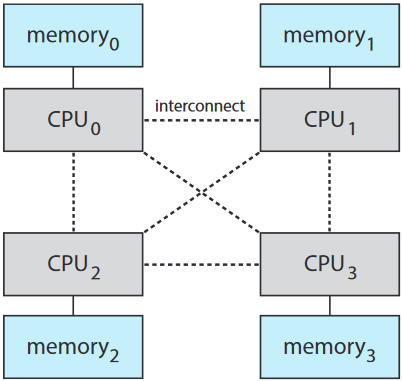
CPU를 너무 많이 추가하면 시스템 버스의 경쟁이 심화되어 병목 현상이 발생해 성능이 떨어짐. 대체 접근법으로는 각 CPU(혹은 CPU 그룹)마다 작고 빠른 로컬 버스를 통해 자신들의 로컬 메모리에 접근하도록 해주는 방법. CPU들은 공유 시스템 인터커넥트 shared system interconnect로 연결 되어있어 모든 CPU가 하나의 물리 주소 공간을 공유. 이 방법은 비균일 메모리 접근 non-uniform memory access 혹은 NUMA라 부름. CPU가 자기 로컬 메모리 접근하니 빠르고 시스템 인터커넥트 간 경쟁도 없음. NUMA에선 좀 더 효율적으로 프로세서 확장 가능.
단점은 CPU가 시스템 인터커넥트를 통해 원격 메모리에 접근 해야할 때의 지연 속도에 의한 성능 저하. 세심한 CPU 스케줄링으로 이런 거 최소화해야 함. NUMA의 확장성 때문에 서버나 고성능 컴퓨팅 시스템에 인기 얻고 있음.
PC 마더보드
CPU, DRAM 소켓, PCIe 버스 슬롯, 입출력 커넥터 등을 포함한 프로세서 소켓으로 구성됨. 젤 싼 범용 CPU도 다중 코어를 가짐. 몇몇 마더보드는 다중 프로세서 소켓 갖고 있음. 고오급 컴퓨터는 NUMA 시스템처럼 한 개 이상의 시스템 보드 지원함.
블레이드 서버 blade server는 다중 프로세서 보드 / 입출력 보드, 네트워크 보드가 같은 새시chassis에 있는 시스템. 기존의 것과의 차이점은 각 블레이드 프로세서 보드는 독립적으로 부팅되며 각자의 운영체제를 실행함. 몇몇 블레이드 서버 보드도 다중 프로세스일 수 있음. 기본적으로 이런 서버는 여러 개의 독립적인 다중 프로세서 시스템으로 구성됨.
1.3.3. 클러스터형 시스템
클러스터형 시스템 clustered system은 다중 프로세서 시스템의 한 유형. 여러 CPU를 하나로 묶음. 두 개 이상의 개별 시스템(노드)이 서로 연결된 형태로 구성된다는 점에서 다중 프로세서와 다름. 각 노드는 보통 다중 코어 시스템. 이런 시스템은 결합도가 낮다 loosely coupled고 함. 클러스터의 정의는 확실히 정해진 것이 없음. 일반적으로 받아들어진 정의는 클러스터형 컴퓨터는 기억 장치를 공유하며 근거리 통신망 LAN이나 InfiniBand와 같이 더 빠른 인터커넥트에 의해 연결되어있다는 것.
클러스터형은 보통 고가용성 서비스 high-availability service, 즉 군집 내의 하나 이상의 시스템이 실패하더라도 지속되어야하는 서비스를 제공할 때 사용. 일반적으로 시스템에 중복 수준 추가하면 고가용성 얻음. 클러스터 소프트웨어의 계층이 클러스터 노드에서 실행됨. 각 노드는 다른 노드 한 개 이상을 (네트워크를 통해) 모니터링. 모니터링의 대상이 되는 기계가 실패하면 모니터링하는 기계가 그 저장소의 권한을 위임 받아 실패한 어플리케이션을 재시작함. 사용자와 어플리케이션의 클라이언트는 잠깐 서비스가 중단된 것처럼 보일 뿐.
고가용성은 신뢰성을 제공. 살아남은 하드웨어의 수준에 비례하여 서비스를 제공하는 능력을 우아한 성능 저하 graceful degradation이라 부름. 더 나아가서 고장 허용 fault tolerant이라고 부르기도 함. 한 성분이 실패하더라도 연산은 지속되기 때문. 고장 허용은 실패를 탐지하고 분석하고, 가능하다면 해결하는 메커니즘을 필요로 함.
클러스터링은 비대칭 / 대칭적으로 구조화. 비대칭 클러스터링 asymmetric clustering의 경우 한 기계가 상시 대기 모드 hot-standby mode에 있고 다른 하나는 어플리케이션 실행 중. 상시 대기 모드에 있는 기계는 활성화된 서버만 모니터링함. 서버 실패하면 상시 대기 중인 호스트가 활성화 서버가 됨. 대칭 클러스터링symmetric clustering의 경우 두 개 이상의 호스트가 어플리케이션을 실행하고 서로를 모니터링. 이게 더 효율적이지만, 한 개 이상의 어플리케이션이 실행 가능해야 함.
클러스터는 여러 컴퓨터 시스템이 네트워크로 연결되어있어 고성능 컴퓨팅 high-performance computing 환경을 제공함. 근데 이 이득을 지원하도록 어플리케이션이 작성되어있어야 함. 이는 병렬화 parallelization라는 기술을 통해 프로그램을 컴퓨터의 개별 코어나 클러스터 내 개별 컴퓨터에서 병렬로 실행될 분리된 성분으로 나눠야 함. 보통 이런 어플리케이션은 클러스터의 각 컴퓨팅 노드가 문제의 일부를 해결하고, 노드의 모든 해결이 최종 해답으로 합쳐지는 형태.
다른 클러스터로는 병렬 클러스터, 광역 통신망 위의 클러스터링 등이 있음. 병렬 클러스터는 여러 호스트가 공유 기억 장치의 동일 데이터에 접근할 수 있도록 해줌. 대부분 운영체제는 여러 호스트가 동시에 데이터에 접근하는 부분에 대한 지원이 미비해서 병렬 클러스터는 소프트웨어의 특별한 버전과 어플리케이션의 특수한 릴리즈판을 사용해야 함. 공유 접근 제공하려면 시스템은 접근 권한이랑 로킹locking을 주어 충돌 연산이 발생하지 않음을 보장해야 함. 이를 분산 록 관리자 distributed lock manager(DLM)라 부름.
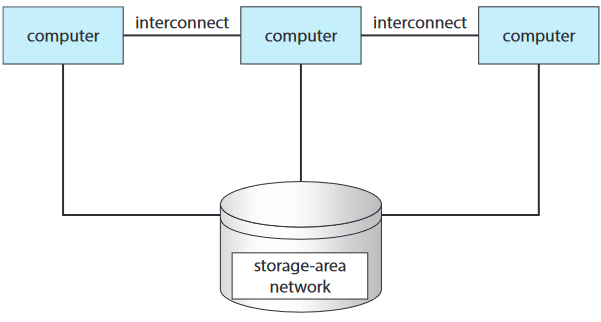
클러스터 기술에 대한 개선점으로 기억 장치 영역 네트워크 storage-area networks(SAN)가 있음. 다중 시스템이 기억 장치의 풀에 붙어 있는 형태. 어플리케이션과 어플의 데이터가 SAN에 저장되어 있으면 클러스터 소프트웨어가 어플리케이션이 해당 SAN에 붙어있는 아무 호스트한테 할당할 수 있음. 데이터베이스 클러스터의 경우 열댓명의 호스트가 같은 데이터베이스 공유 가능해 성능 및 신뢰성 증가.
하둡
간단한 저가형 하드웨어 성분으로 이루어진 클러스터형 시스템에서 큰 데이터 집합(빅데이터 big data라고도 부름)에 대한 분산 처리에 사용하는 오픈소스 소프트웨어 프레임워크. 확장성에 대비해서 설계되어있음. 클러스터의 노드에 작업 할당, 노드 간 통신 마련하여 병렬 연산 관리하여 결과 처리 및 합침. 노드의 실패 탐지 및 관리도 처리하여 효율적이고 상당히 신뢰성 있는 분산 컴퓨팅 서비스. 세 가지 성분으로 구성:리눅스에서 돔. PHP, Perl, Python와 같은 스크립트 언어로 하둡 어플리케이션 개발 가능. 자바 제일 많이 사용. MapReduce 지원하는 몇 가지 자바 라이브러리 존재.
- 분산 컴퓨팅 노드의 데이터와 파일 관리하는 분산 파일 시스템
- YARN(또다른 자원 협상가) 프레임워크를 통해 클러스터 내 자원 및 클러스터 내 노드 작업 스케줄링 관리.
- MapReduce 시스템을 통한 클러스터 내 노드에서 데이터 병렬 처리.
1.4. 운영체제 연산
운영체제는 프로그램이 실행되는 환경 제공.
컴퓨터가 실행되려면 초기 프로그램, 혹은 부트스트랩 프로그램 필요. 이런 건 간단해야 함. 컴퓨터 하드웨어의 펌웨어 안에 저장. CPU 레지스터부터 장치 제어자, 메모리까지 시스템의 모든 걸 초기화. 부트스트랩이 운영체제 불러오고 실행하려면 운영체제 커널을 찾아 메모리에 불러와야함.
부트 시 커널 외의 시스템 프로그램에 의해 제공된 서비스들이 메모리에 불러와져 시스템 데몬 system daemon이 됨. 얘네는 커널이 도는 내내 같이 돔. 리눅스에서 첫번째 시스템 프로그램은 "systemd"으로, 여러 데몬 시작시킴. 이 단계 다음엔 시스템 부팅 끝. 앞으로 일어날 이벤트 기다림.
할 거 없으면 그냥 운영체제는 기다림. 이벤트는 거의 언제나 인터럽트에 의해 신호가 옴. 다른 형태의 인터럽트로는 트랩 trap(혹은 예외 exception)이 있음. 이건 소프트웨어에서 생성한 인터럽트로 오류(0으로 나누기, 잘못된 메모리 접근 등)나 사용자 프로그램의 특정한 요청에 의해 시스템 호출 system call을 통해 운영체제 서비스가 실행되어 발생함.
1.4.1. 멀티프로그래밍과 멀티태스킹
운영체제의 핵심 중 하나는 여러 프로그램을 실행할 수 있는 능력. 멀티프로그래밍 multiprogramming은 CPU 효용성을 높이고 만족도를 높임. 멀티프로그램형 시스템에서 프로그램 실행을 프로세스 process라 부름.
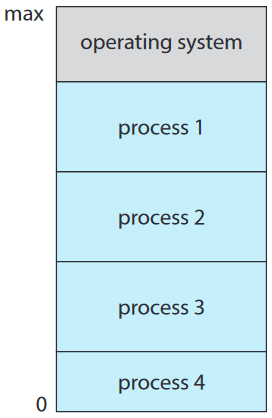
아이디어:
- 운영체제는 여러 프로세스를 메모리에 동시에 보관
- 이 중 하나를 골라서 실행
- 이 프로세스는 필연적으로 어떤 작업(입출력 등)을 기다릴 것
- 멀티프로그램형이 아닌 시스템에선 CPU는 아무 것도 안 함. 멀티프로그램형 시스템에서는 운영 체제가 단순히 다른 프로세스로 스위치하여 실행하면 됨.
- 이 프로세스가 또 기다려야하면 CPU는 또다른 프로세스로 스위치함.
- 언젠가 첫번째 프로세스의 기다림이 끝나면 CPU를 다시 돌려 받을 것.
- CPU는 절대 심심할 틈이 없을 것.
변호사 생각하면 됨.
멀티태스킹 multitasking은 멀티프로그래밍의 논리적 확장. CPU가 여러 프로세스를 엄청 빠르게 스위칭하여 빠른 응답 시간 response time을 제공. 프로세스가 실행할 때 보통 끝나거나 입출력을 수행할 때 시간이 얼마 안 걸리기 때문임. 그리고 입출력도 보통 사람 수준의 속도에서 실행되서 처리되는데 오래 걸린다고 봐야 함.
여러 프로세스가 동시에 메모리에 있으면 메모리 관리가 필수. 몇몇 프로세스가 동시에 실행되려면 다음에 어떤 프로세스를 실행할지도 결정해야 함. 이게 CPU 스케줄링 CPU scheduling임. 다중 프로세스를 동시에 실행하려면 서로에 운영체제의 모든 단계에서 영향을 주는 거에 제한을 줘야 함. 이건 프로세스 스케줄링, 디스크 기억 장치, 메모리 관리를 포함함.
멀티태스킹 시스템은 합리적인 응답 시간 보장해야 함. 보통 가상 메모리 virtual memory로 메모리에 완전하게 있지 않은 프로세스를 실행할 수 있게 해줌. 이러면 실제 물리 메모리 physical memory보다 큰 프로그램 실행할 수 있게 해준다는 장점이 있음. 주메모리를 더 크고 균일된 배열의 기억 장치로 만들어 사용자가 주메모리를 보는 논리 메모리 logical memory와 분리함. 그래서 프로그래머는 메모리 기억 장치 한계점에 대한 고민을 할 필요가 없음.
멀티프로그래밍 / 멀티태스킹 시스템은 파일 시스템이 필수. 파일 시스템은 보조 기억 장치에 있으니 기억 장치 관리도 필수. 게다가 자원에 대한 부적절한 사용으로부터 막아야 함. 올바른 순서로 실행을 보장하기 위해선 시스템에서 프로세스 동기화와 통신에 대한 메커니즘 필요. 그리고 데드락에 갇히지 않게 해야 함.
1.4.2. 이중모드와 다중모드 연산
운영체제와 사용자는 컴퓨터 시스템의 하드웨어와 소프트웨어 자원을 공유하므로 잘못된(사악한) 프로그램이 다른 프로그램이나 운영체제가 잘못된 방향으로 실행되게 만들면 안됨을 보장해야 함. 즉, 운영체제 시스템 코드와 사용자 정의 코드를 구분해야 함.
최소한 사용자 모드 user mode와 커널 모드 kernel mode(감독자 모드 supervisor mode, 시스템 모드 system mode, 특권 모드 privileged mode라 부르기도)는 구분해야 함. 하드웨어에 모드 비트 mode bit라 불리는 비트를 추가해 현재 모드가 커널(0)인지 사용자(1)인지 구분.
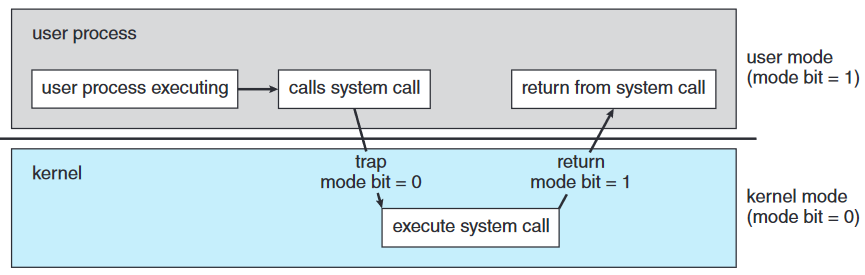
시스템 부팅 시 하드웨어는 커널 모드로 시작. 운영체제 로딩되고 유저 어플리케이션을 유저 모드에서 실행. 트랩이나 인터럽트 발생할 때마다 하드웨어는 유저 모드에서 커널 모드로 바뀜.
듀얼 모드에선 운영체제와 다른 사용자를 잘못된 사용자로부터 막는 보호가 존재. 피해를 줄 수 있는 기계 명령어를 특권 명령어 privileged instruction로 따로 명명함. 얘네는 오로지 커널 모드에서 실행하도록 함. 유저 모드에서 이 명령어 실행하려고 하면 하드웨어가 이거 무시하고 운영체제에 트랩 줌.
인텔은 네 개의 보호 링 protection ring이 존재. 링 0이 커널 모드, 링 3이 사용자 모드. ARMv8은 7 개의 모드 가짐. 가상화 지원하는 CPU는 가상 기계 관리자 virtual machine manager(VMM)가 시스템 제어할 때를 위한 모드가 따로 있음.
운영체제의 초기 제어권에서는 명령어가 커널 모드에서 실행 됨. 제어권이 사용자 어플리케이션으로 넘어가면 모드가 유저 모드로 됨. 나중에 인터럽트 / 트랩 / 시스템 호출로 다시 커널 모드로 돌아감. 마소 윈도우즈, 유닉스, 리눅스 전부 이 듀얼 모드 기능으로 운영체제 보호함.
시스템 호출은 사용자 프로그램이 운영체제에게 대신 운영체제 전용 작업을 해달라고 부탁하는 것. 사용하는 프로세서에 따라 시스템 호출은 다양한 방법으로 호출됨. 보통 인터럽트 벡터의 특정 위치로의 트랩의 형태. 포괄적인 trap 명령어로 실행될 수 있으나 몇몇은 특정 syscall 명령어가 있음.
시스템 호출이 실행되면 보통 하드웨어가 소프트웨어 인터럽트로 간주함. 제어가 인터럽트 벡터에서 운영체제의 서비스 루틴으로 넘어가고 모드 비트가 커널 모드로 바뀜. 시스템 호출 서비스 루틴은 운영체제의 일부. 커널이 인터럽트 명령어 보고 무슨 시스템 호출인지 확인. 사용자 프로그램이 요청하는 서비스의 유형이 무엇인지에 대한 매개변수가 있음. 레지스터, 스택, 혹은 메모리(레지스터에 메모리를 가리키는 포인터의 형태로)를 통해 추가 요청 정보가 올 수도 있음. 커널은 매개변수가 올바른지 확인하고 요청 실행하여 시스템 호출 후의 명령에 제어를 반환함.
이런 오류는 보통 운영체제가 처리함. 사용자 프로그램에서 트랩 발생 시 운영체제가 해당 프로그램 비정상 종료시킴. 이건 사용자 요청 비정상 종료와 같은 코드로 처리됨. 적절한 오류 메시지 주고, 프로그램의 메모리는 덤프함. 메모리 덤프는 보통 파일에 적어두어 사용자나 프로그래머가 확인할 수 있도록 해줌.
1.4.3. 타이머
운영체제가 CPU에 대한 제어권을 유지함을 보장해야 함. 사용자 프로그램이 무한 루프에 빠지거나 시스템 서비스 호출 실패해서 운영체제에 제어권을 반환하지 못하는 일이 발생하면 안됨. 이래서 타이머 timer가 필요. 특정 시점 이후(1/60초 등으로 고정하거나 1 ms에서 1초 사이로 가변적으로 가능) 인터럽트 발생 시킴. 일반적으로 가변 타이머 variable timer를 고정율 시계와 카운터로 구현함. 운영체제가 카운터 세팅해놓고, 시계의 한 틱마다 카운터를 감소시켜 카운터가 0이 되는 순간 인터럽트가 발생함.
타이머가 인터럽트 시키면 제어권이 자동으로 운영체제로 넘어감. 이걸 오류로 판단할 수도, 시간을 더 줄 수도 있음. 타이머의 내용을 수정하는 명령어는 당연히 특권임.
리눅스 타이머
리눅스의 커널 설정 매개변수HZ는 타이머 인터럽트의 빈도를 의미함. 값이 250라면 초당 250 번 인터럽트, 혹은 4 ms 당 인터럽트 한 번.HZ값은 실행 중 커널의 설정, 기계 유형과 구조에 따라 다름. 관련성 있는 커널 변수는jiffies로 시스템 부팅 이후 타이머 인터럽트가 몇 번이나 발생했는지를 의미.
1.5. 자원 관리
운영체제는 자원 관리자 resource manager.
1.5.1. 프로세스 관리
프로세스는 작업을 끝내려면 특정 자원들이 필요. 보통 실행 중에 할당이 됨. 이런 프로세스가 생성될 때 얻는 물리적 / 논리적 자원 말고도 여러 초기화 데이터(입력)이 같이 전달될 수도 있음. 프로세스가 끝나면 운영체제는 재사용 가능한 자원은 다 다시 돌려 받을 것.
프로그램 자체는 프로세스가 아님. 프로그램은 수동적인 존재, 프로세스는 능동적인 존재. 단일 스레드 프로세스는 다음에 실행할 명령어를 알려주는 프로그램 카운터 program counter를 하나 가짐. 이런 프로세스의 실행은 반드시 순차적이어야 함. CPU는 프로세스가 끝날 때까지 프로세스의 한 명령어를 순서대로 실행함. 두 프로세스가 같은 프로그램에 있더라도 둘은 서로 다른 실행 시퀀스임. 멀티스레드 프로세스는 여러 프로그램 카운터가 있어 각 스레드마다프로그램 카운터 갖고 있음.
프로세스는 시스템에서 작업의 단위. 시스템은 프로세스의 집합으로 구성됨. 이중 몇 개는 운영체제 프로세스(시스템 코드를 실행)이고, 나머지는 사용자 프로세스임. 전부 단일 CPU 코어를 멀티플렉싱하여 동시에 실행되거나 다중 CPU 코어로 병렬로 실행될 수 있음.
운영체제의 프로세스 관리할 때의 역할:
- 사용자와 시스템 프로세스 생성 및 소멸
- CPU에서 프로세스와 스레드 스케줄링
- 프로레스 중단 및 재개
- 프로세스 동기화 메커니즘 제공
- 프로세스 간 통신 메커니즘 제공
1.5.2. 메모리 관리
현대 컴퓨터 시스템의 연산의 중심이 주메모리. 주메모리는 거대한 바이트의 배열. 각 바이트엔 주소가 있음. 주메모리는 고속으로 접근 가능한 CPU와 입출력 장치가 공유하는 데이터의 저장소. (폰 노이만 구조에서) CPU는 명령어 꺼내기 사이클 때 명령어를 주메모리에서 읽고 데이터 꺼내기 사이클에서 주메모리에서의 데이터를 읽거나 씀.
프로그램 실행하려면 절대 주소에 매핑되어 메모리에 불러와져야함. 프로그램 실행 중 프로그램 명령어와 데이터에 대한 절대 주소를 생성해 메모리에서 불러옴. 프로그램 종료 시 메모리 공간은 다시 가용 공간으로 만들어줌.
CPU의 효용성과 사용자에 대한 컴퓨터의 반응성을 둘 다 높이기 위해 범용 컴퓨터는 반드시 몇몇 프로그램을 메모리에 유지해야 하므로 메모리 관리가 필요함. 여러 접근법이 존재하며 알고리듬 별 효과는 상황에 따라 다름. 그래서 선택할 때 특히 시스템의 하드웨어 설계를 고려해야 함.
운영체제는 메모리 관리에 대해 다음 역할을 가짐:
- 현재 어떤 메모리가 어떤 프로세스에 의해 사용 중인지 추적
- 필요에 따라 메모리 공간 할당 및 해제
- 어떤 프로세스(혹은 프로세스의 일부)와 데이터가 메모리에 들어 가고 나와야 하는지 결정
1.5.3. 파일 시스템 관리
컴퓨터 시스템의 편의성을 위해 정보 기억 장치에 대해 균일한 / 논리적인 시점을 제공. 기억 장치의 물리적 속성를 추상화하여 논리적인 기억 장치 단위 파일 file을 정의. 파일을 물리적인 미디어에 매핑하고 기억 장치를 통해 파일에 접근.
파일 관리는 운영체제에서 가장 시각적인 성분. 흔히 보조 장치와 같은 물리 미디어는 디스크 드라이브와 같은 장치에 의해 제어되어 각자 속도, 용량, 데이터 전환율, 접근법(순차적, 임의 등)과 같은 개별적 특징이 있음
파일은 생성자에 의해 정의된 유관된 정보의 집합. 보통 파일은 프로그램과 데이터를 표현함. 데이터 파일은 숫자적, 문자적, 영숫자적, 이진수적일 수 있음. 파일에는 서식이 없을 수도(텍스트 등), 있을 수도(mp3 등) 있음. 파일이라는 개념은 상당히 일반적인 개념.
파일이라는 추상적 개념을 대용량 기억 장치 미디어와 이를 제어하는 장치를 관리함으로 구현함. 보통 경로로 보기 쉽게 조직화함. 여러 사용자가 파일에 접근할 땐 어떤 사용자가 어떻게 파일에 접근(읽기/쓰기/첨가 등)할 수 있는 지에 대한 제어가 필요.
운영체제의 파일 관리 역할:
- 파일 생성 및 소멸
- 경로 생성 및 소멸
- 파일 및 경로 조작을 위한 기초 요소 지원
- 대용량 기억 장치에 파일 매핑
- 안정적(비휘발성) 기억 장치 미디어에 파일 백업
1.5.4. 대용량 기억 장치 관리
대부분의 프로그램은 HDD나 NVM과 같은 보조 기억 장치에 저장되어 있다가 메모리에 불러와짐. 프로그램은 장치를 프로세스의 출발지이자 도착지로 사용함. 그러므로 보조 기억 장치는 컴퓨터 시스템에서 매우 중요. 운영체제의 역할:
- 마운팅 및 언마운팅
- 빈 공간 관리
- 기억 장치 할당
- 디스크 스케줄링
- 분할
- 보호
보조 기억 장치를 자주, 확장적으로 사용하므로 성능이 중요. 얘네 하위 시스템과 이 하위 시스템을 조작하는 알고리듬의 성능에 따라 컴퓨터의 속도가 결정되기도.
보조 기억 장치보다 느리면서 더 싼 용도들도 있음. 백업 등.
예비 기억 장치는 시스템 성능에 딱히 영향을 주지는 않지만 관리는 해야 함. 몇몇 운영체제는 지들이 처리하고, 몇몇은 어플리케이션 프로그램에게 맡기는 경우가 있음. 운영체제가 제공할 수 있는 기능으로는 장치의 미디어 마운팅 및 언마운팅, 프로세스의 확장적 사용을 위한 기억 장치 할당 및 해제, 보조 기억 장치에서 예비 기억 장치로 데이터 마이그레이션 등이 있음.
1.5.5. 캐시 관리
캐싱 caching은 컴퓨터 시스템의 중요 요소. 정보는 보통 어떤 기억 장치 시스템에 있음. 이걸 사용하려면 더 빠른 기억 장치 시스템인 캐시에 임시로 복사함. 특정 정보가 필요하면 우선 이게 캐시에 있는지 확인함. 있으면 캐시에서, 없으면 원래 가져온 곳에서 정보 가져오고 동시에 캐시에 복사. 나중에 쓸 수도 있으니.
추가적으로 내부 프로그램 가능한 레지스터는 주메모리에게 고속 캐시를 제공. 프로그래머(혹은 컴파일러)는 이 레지스터 할당과 레지스터 대체 알고리듬으로 어떤 정보를 레지스터에 보관하고 어떤 건 주메모리에 보관할지 결정.
다른 캐시들은 하드웨어 별로 구현되어있음. 대표적으로 다음 실행할 것으로 예상되는 명령어를 보관하는 명령어 캐시가 있음. 비슷한 이유로 대부분의 시스템은 하나 이상의 고속 데이터 캐시가 메모리 계층에 존재함.
캐시는 유한하기에 캐시 관리 cache management는 중요한 설계 문제. 캐시 크기 설정과 대체 정책이 성능을 좌우함.
서로 다른 기억 장치 계층 간 정보 옮기기는 하드웨어 설계와 운영체제 소프트웨어에 따라 명시적 / 암시적일 수 있음. 보통 캐시에서 CPU와 레지스터로 데이터 옮기기는 하드웨어 기능임. 반대로 디스크에서 메모리로 옮기는 건 운영체제가 제어함.
계층적 기억 장치 구조에선 같은 데이터가 서로 다른 계층에서 등장할 수 있음. 만약 디스크에서 A라는 값을 받아 연산을 한다면 레지스터까지 갔다가 연산 후 바뀐 값을 반대 순서로 전달.

멀티태스킹에서는 여러 프로세스가 A에 접근하려 할 때 제일 최신 A 값을 받을 수 있도록 보장해야 함.
다중프로세서 환경에선 더 복잡해짐. 내부 레지스터 유지에서 더 나아가 각 CPU가 로컬 캐시를 갖고 있음. A의 복사본이 여러 캐시에 동시에 존재할 수도 있음. 여러 CPU가 병렬적으로 실행될 수 있어 한 캐시에서의 A의 갱신 값이 즉시 A가 있는 다른 캐시에 반영되어야 함. 이게 캐시 일관성 cache coherency이고, 하드웨어가 처리할 문제임.
분산 환경에선 더욱 복잡해짐. 같은 파일의 복사본이 서로 다른 프로그램에 등장함. 이게 동시에 접근 및 갱신이 가능해서 몇몇 분산 시스템은 복사본이 어딘 가에서 갱신되는 순간 다른 복사본들은 되는 대로 바로 갱신됨.
1.5.6. 입출력 시스템 관리
유닉스는 입출력 장치의 세부 사항들을 운영체제로부터 입출력 하위체제 I/O subsystem의 형태로 숨겨둠. 입출력 하위체제는 몇가지 성분으로 이루어짐:
- 버퍼링, 캐싱, 스풀링을 포함한 메모리 관리 성분
- 일반적인 장치 드라이버 인터페이스
- 특정 하드웨어 장치를 위한 드라이버
오로지 장치 드라이버만 장치의 세부 사항을 알고 있음.
1.6. 보안 및 보호
한 컴퓨터 시스템에 사용자가 많고 다중 프로세스가 동시 실행이 가능하다면 오로지 운영체제로부터 권한을 받은 프로세스만이 자원에 대한 메커니즘이 가능하도록 해줘야 함.
보호 protection는 컴퓨터 시스템에서 정의한 자원에 대한 접근 권한을 프로세스나 사용자에게 주는 것을 제어하는 메커니즘. 이 메커니즘은 반드시 시행할 제어가 무엇인지 특정하고 제어를 강제해야 함.
보호를 통해 성분체제 간 잠재적 오류를 탐지하여 신뢰성 향상. 보호되지 않은 자원은 승인 되지 않거나 권한이 없는 사용자에 의해 사용 / 오용될 수 있음.
보호에서 더 나아가 자신의 인증 정보가 도둑 맞았은 경우도 처리해야 함. 외부 / 내부 공격으로부터 시스템을 방어하는 것이 바로 보안 security. 몇 가지 공격에 대한 예방은 몇몇 시스템에서의 운영체제의 기능이기도, 몇몇 시스세템에서는 정책이나 추가적인 소프트웨어에 맡기기도.
보호 / 보안은 사용자를 구분할 줄 알아야 함. 대부분의 운영체제는 사용자 식별자 user identifier (사용자 ID user ID)로 구분. 윈도우즈의 경우 보안 ID security ID (SID)라 부름. 고유한 숫자 ID로 시스템에 사용자가 로그인할 때 사용. 사용자의 프로세스와 스레드에도 적용.
개인 사용자 뿐만 아니라 그룹을 지어줄 수도 있음. 그룹 기능은 시스템 내에 그룹 이름과 그룹 식별자 group identifer 목록을 두어서 구현. 이것도 각 프로세스와 스레드에 적용.
여기에 더 나아가서 확대 특권 escalate privilege로 추가적인 권한을 요할 수도 있음. 유닉스의 경우 setuid 속성으로 프로그램이 현재 사용자 ID가 아니라 파일의 소유자의 사용자 ID로 실행되게 함. 프로세스는 이 효과적 UID effective UID로 실행되며 추가 특권이 꺼지거나 프로그램이 종료될 때까지 실행됨.
1.7. 가상화
가상화 virtualization는 하나의 컴퓨터의 하드웨어를 여러 다른 실행 환경으로 추상화해주어 각 환경이 각자 서로 다른 컴퓨터에서 실행되는 것처럼 만들어주는 기술. 마치 서로 다른 운영체제가 동시에 도는 환경들이라 생각함면 됨. 가상 기계 virtual machine의 사용자는 마치 단일 운영체제에서 프로세스 동시에 실행할 때 스위치하듯이 이 서로 다른 운영체제 간을 스위치 할 수 있음.
가상화를 통해 운영체제가 다른 운영체제 위에서 마치 어플리케이션처럼 돌아가게 해줌.
가상화 소프트웨어는 에뮬레이션와 하나로 묶을 수 있음. 에뮬레이션 emulation은 컴퓨터 하드웨어를 소프트웨어에서 시뮬레이션하는 것을 의미함. 보통 원본 CPU 유형이 타겟 CPU 유형과 다를 때 사용. 이 개념을 운영체제에 확장 해 한 플랫폼을 위한 운영체제가 다른 곳에서 돌 수 있게 만들 수 있음. 하지만 네이티브 코드에 비해 에뮬레이션된 코드는 더 느림.
운영체제는 반대로 특정 CPU에 네이티브하게 컴파일된 운영체제가 같은 CPU에 네이티브하게 컴파일된 다른 운영체제 위에서 도는 것임. VMWare의 경우 윈도우즈에 어플리케이션의 형태로 도는 새로운 가상화 기술 도입. 이 어플리케이션은 한 개 이상의 손님 guest 복사본의 윈도우즈나 네이티브 x86 운영체제가 각자 어플리케이션을 실행하는 형태로 실행됨. 윈도우즈가 호스트 host 운영체제고, VMWare 어플리케이션이 가상 기계 관리자 virtual machine manager (VMM)임. VMM이 손님 운영체제 실행하고 자원 관리하고 손님들끼리 보호함.
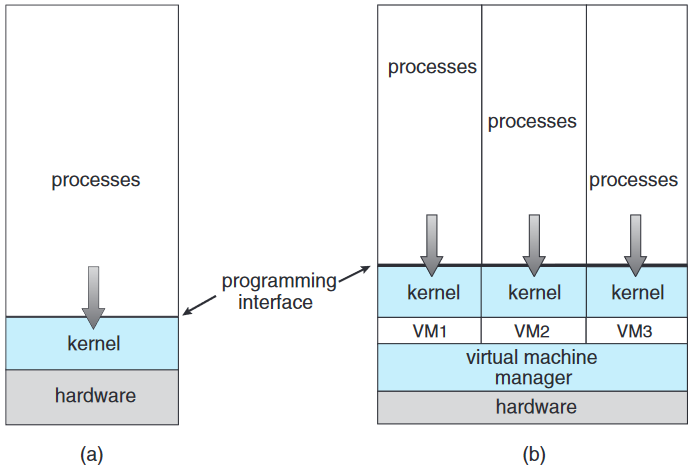
요즘엔 VMM들 자체가 호스트 운영체제가 되기도 함.
1.8. 분산 체계
분산 체계란 시스템이 유지하는 다양한 자원에 대한 접근을 사용자에게 주도록 네트워킹 된 물리적으로 분리된, 이종일 수도 있는 컴퓨터 시스템의 집합. 공유 자원에 대한 접근은 연산 속도, 기능, 데이터 사용성, 신뢰성을 향상. 일반적으로 두 개의 모드를 섞어 사용, 예를 들어 FTP와 NFS. 분산 체계를 만드는 프로토콜에 따라 시스템의 효용성과 대중성이 결정.
네트워크 network는 단순하게 말하면 두 개 이상의 시스템 간의 통신 경로. 분산 체계의 기능은 네트워크에 의존. 사용하는 프로토콜, 노드 간 거리, 전송 미디어에 따라 네트워크가 달라짐. 가장 흔한 네트워크 프로토콜이 TCP/IP로, 인터넷의 근간 구조가 됨. 대부분의 운영체제는 TCP/IP를 지원. 네트워크 프로토콜은 인터페이스 장치(예를 들면 네트워크 어댑터)와 이를 관리할 장치 드라이버, 그리고 데이터를 처리할 소프트웨어가 있어야 함.
노드 간 거리에 따라 네트워크 구분 가능. 근거리 통신망 local-area network (LAN)은 방, 건물, 캠퍼스 안의 컴퓨터 간 연결. 광역 통신망 wide-area network (WAN)은 건물, 도시, 나라를 연결. 거대 도시 통신망 metropolitan-area network (MAN)의 경우 도시 내의 건물 간 연결. 블루투스와 802.11 장치와 같은 무선 기술은 개인 간 통신망 personal-area network (PAN)을 형성.
컴퓨터가 통신을 할 때마다 네트워크를 사용하거나 생성함. 성능과 신뢰도는 천차만별.
네트워크 운영체제 network operating system은 네트워크 전역에 파일이나 서로 다른 컴퓨터의 서로 다른 프로세스 간에 메시지를 교환할 수 있는 통신 계획 등을 공유함. 네트워크 운영체제를 갖는 컴퓨터는 네트워크의 모든 다른 컴퓨터와 독립적으로 작동. 물론 네트워크가 존재함은 인식함. 분산 운영체제는 좀 덜 독립적임. 서로 다른 컴퓨터가 밀접하게 통신을 해서 마치 하나의 운영체제가 네트워크를 제어하는 것처럼 착각을 일으킴.
1.9. 커널 자료구조
1.9.1. 리스트, 스택, 큐
리스트 list는 순차적으로 데이터 값을 저장함. 리스트를 구현하는 가장 흔한 구조가 연결 리스트 linked list. 연결 리스트의 종류:

- 단일 연결 리스트 singly linked list. 각 아이템은 자기 후임자를 가리킴.

- 이중 연결 리스트 doubly linked list. 각 아이템이 전임자나 후임자를 가리킴.

- 원형 연결 리스트 circularly linked list. 리스트의 마지막 원소가 null이 아니라 첫번째 원소를 가리킴.
스택 stack은 후입선출 LIFO를 사용하는 자료 구조. 원소 추가 및 삭제는 각각 푸시와 팝이라 부름.
큐 queue는 반대로 선입선출 FIFO를 사용하는 자료 구조.
1.9.2. 트리
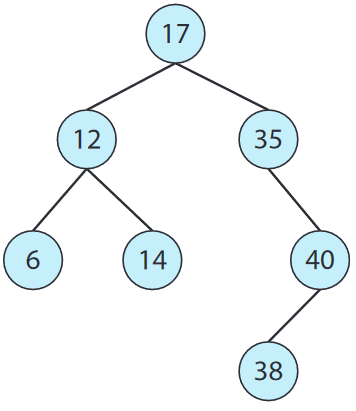
트리 tree는 자료를 계층적으로 표현할 때 사용하는 자료구조. 일반 트리 general tree에서는 부모의 자녀 개수에 한계가 없으나, 이진 트리 binary tree에서는 부모가 최대 두 명의 자녀를 가질 수 있어 각각 왼쪽 자식과 오른쪽 자식이라 부른다. 이진 탐색 트리 binary search tree는 여기에 더 나아가 왼쪽 자식 <= 오른쪽 자식이라는 순서를 만족해야 한다. 이진 탐색 트리에서 원소를 찾는 최악의 성능은 O(n)으로, 이를 처리하기 위해 균형 이진 탐색 트리 balanced binary search tree를 사용. 여기서는 n 개의 원소를 갖는 트리는 최대 log n 개의 층을 가지므로 최악의 경우 성능은 O(log n)이다. 리눅스는 레드 블랙 트리 red-black tree라 알려진 균형 이진 탐색 트리를 CPU-스케줄링 알고리듬에 사용.
1.9.3. 해시 함수와 맵
해시 함수 hash function는 자료를 입력으로 받아 자료에 대해 수리적 연산을 하여 숫자값을 반환함. 이 값은 테이블(보통 배열)에 대한 색인으로 활용하여 빠르게 자료 얻을 수 있음. 크기 n의 리스트는 데이터 탐색에 O(n) 번의 비교가 필요하나 해시 함수는 구현 방법에 따라 O(1) 수준의 성능을 냄. 이 때문에 운영체제에서 널리 애용됨.
서로 다른 값의 해시 값이 같을 경우 해시 충돌이 발생하는데, 이는 해당 위치에 연결 리스트를 두어 같은 해시 값은 같은 연결 리스트에 있도록 하여 해결.
해시 함수를 통해 해시 맵 hash map(혹은 맵)을 구현 가능. [키:값] 짝과 해시 함수 사용.
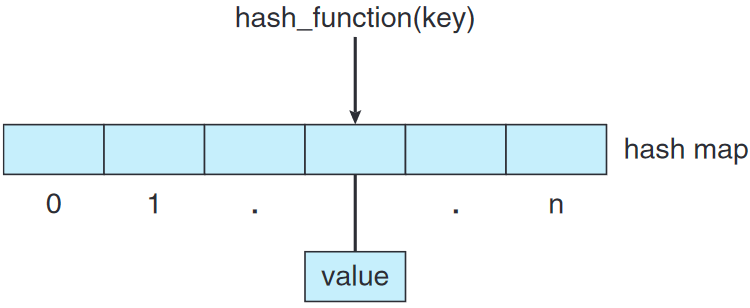
1.9.4. 비트맵
비트맵 bitmap이란 n 개의 이진수의 연속체로 n 개의 원소의 상태를 표기. 비트맵의 i 번째 수는 곧 i 번째 자원을 의미.
공간 효율성 생각하면 지림. 중간 크기의 디스크 드라이브가 수천 개의 독립 유닛, 즉 디스크 블록 disk block으로 나뉠 수도 있는데, 비트맵을 사용해서 각 디스크 블록의 사용 가능성을 표기 가능.
리눅스 커널 자료 구조
리눅스 커널에 사용한 자료 구조는 커널 소스 코드에 있음. 추가 파일<linux/list.h>에 연결 리스트 자료 구조 있음. 리눅스의 큐는kfifo라는 이름을 갖고 있으며 소스 코드의kernel경로에 있는kfifo.c파일에 구현부가 있음. 리눅스는 레드 블랙 트리를 활용한 균형 이진 탐색 트리도 추가 파일<linux/rbtree.h>갖고 있음.
1.10. 컴퓨팅 환경
1.10.1. 전통적인 컴퓨팅
요즘엔 회사가 포털 portal을 설립하여 내부 서버에 웹 접근을 줌. 네트워크 컴퓨터 network computer(혹은 소형 클라이언트 thin client)는 웹 기반 컴퓨팅을 하는 터미널로, 보안이 필요하거나 유지보수가 용이해야하는 환경에서 전통적인 워크스테이션을 대체하고 있음. 모바일 장치는 무선 네트워크 wireless network랑 셀룰러 데이터 네트워크에 연결해서 회사의 웹 포털 사용 가능.
요즘 집에서도 빠른 네트워크 연결 속도가 낮은 가격에 제공됨. 그래서 방화벽 firewall을 통해 네트워크를 보안이 뚫리지 않도록 보호함.
20세기 중후반에는 시스템들이 배치식 혹은 대화식 체계를 가졌음. 배치식은 작업을 한 뭉텅이로, 파일이나 다른 자료로 부터 입력을 미리 받아서 처리함. 대화식은 사용자로부터 입력을 받을 때까지 기다림. 컴퓨팅 자원 사용을 최적화하려고 여러 사용자가 시스템 내에서 시간을 공유함. 이 시간 공유 체계는 타이머와 스케줄링 알고리듬을 통해 CPU 내에서 프로세스를 빠르게 순회하여 각 사용자에게 자원을 공유함.
요즘엔 전통적인 시간 공유 체계 거의 없음. 갇은 스케줄링 기술이 아직 데탑, 노트북, 서버나 모바일에서도 쓰긴 하는데 보통 모든 프로세스가 같은 사용자(혹은 하나의 사용자와 운영체제)가 소유함. 사용자 프로세스와 시스템 프로세스는 각자 컴퓨터 시간의 일부를 빠르게 받도록 관리함.
1.10.2. 모바일 컴퓨팅
모바일 컴퓨팅 mobile computing이란 휴대용 기기 컴퓨터를 의미. 휴대적이면서 가볍다는 물리적 특징.
요즘은 데탑 / 노트북에도 없는 기능까지 추가됨(GPS 등). 이런 것의 대표적인 사례가 증강 현실.
온라인 서비스 접근하려고 대부분 IEEE 표준 802.11 무선 혹은 셀룰러 데이터 네트워크 사용. 전기 먹는 거 줄여야해서 더 작고, 더 느리고, 프로세싱 코어 적은 프로세서 사용.
모바일 컴퓨팅은 애플 iOS Apple iOS와 구글 안드로이드 Google Android 둘이서 독점함.
1.10.3. 클라이언트-서버 컴퓨팅
요즘 네트워크 구조는 서버 시스템 server system이 클라이언트 시스템 client system의 요구를 만족하는 방향으로 되어있음. 이러한 클라이언트-서버 client-server 시스템은 특수화된 분산 시스템임.
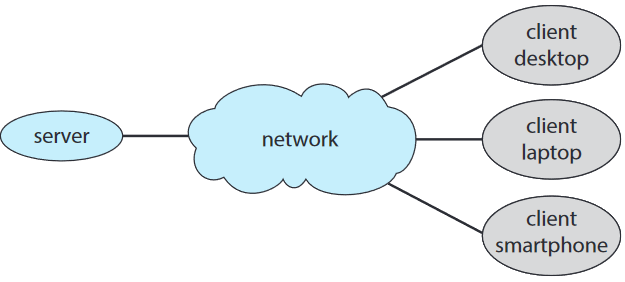
서버 시스템은 연산 서버와 파일 서버 두 가지로 구분 가능:
- 연산-서버 시스템 compute-server system은 클라이언트가 어떤 작업에 대한 요청을 보낼 수 있는 인터페이스 제공. 이에 대한 반응으로 서버는 해당 작업을 실행하고 결과를 클라이언트에게 반환함.
- 파일-서버 시스템 file-server system은 클라이언트가 파일을 생성하고, 갱신하고, 읽고, 쓸 수 있도록 하는 인터페이스 제공.
1.10.4. 개인 간 통신 컴퓨팅
또다른 분산 시스템. 모델, 클라이언트, 서버는 서로 구분되지 않음. 모든 노드는 개인으로, 각각 서비스를 요청하는 지 여부에 따라 클라이언트로서, 또는 서버로서 작동 가능. 클라이언트-서버 시스템에서는 서버가 병목점인데 개인 간 통신 시스템에서는 서비스가 여러 노드를 통해 네트워크에 분산될 수 있음.
우선 노드는 개인들로 이루어진 네트워크에 합류해야 개인 간 통신에 참여 가능. 이후에 서비스를 제공하거나 요청 가능. 어떤 서비스가 가능하고, 처리되는지는 일반적으로 두 가지 방법으로 알 수 있음:
- 노드가 네트워크에 합류하면 자신의 서비스를 네트워크의 중앙 룩업 서비스에 등록. 특정 서비스가 필요한 임의의 노드는 우선 이 중앙 룩업 서비스를 통해 어떤 노드가 해당 서비스를 제공하는지 찾아야 함. 나머지 통신은 클라이언트와 서비스 제공자 간이 전부임.
- 이를 대체하는 계획으로는 중앙 룩업 서비스 대신 클라이언트로서 행동하는 개인이 네트워크 내의 모든 노드에게 서비스에 대한 요청을 방송하게 하는 것. 해당 서비스를 갖는 노드(혹은 노드들)가 이에 반응을 함. 이 접근법을 위해선 발견 프로토콜이 반드시 제공되어야 개인이 네트워크 내에서 원하는 서비스를 제공하는 다른 개인을 발견할 수 있게 해줌.
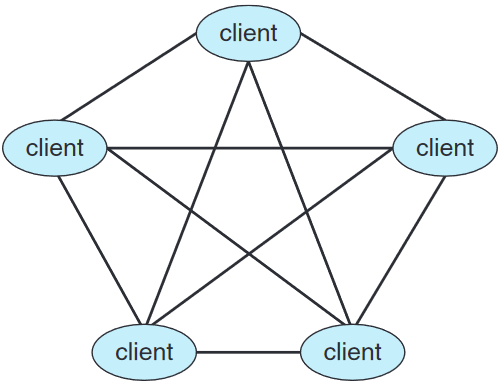
스카이프가 한 예시. 인터넷을 통해 음성 통화 / 영상 통화 / 텍스트 메시지를 인터넷 전화 voice over IP (VoIP)라는 기술로 주고 받을 수 있음.
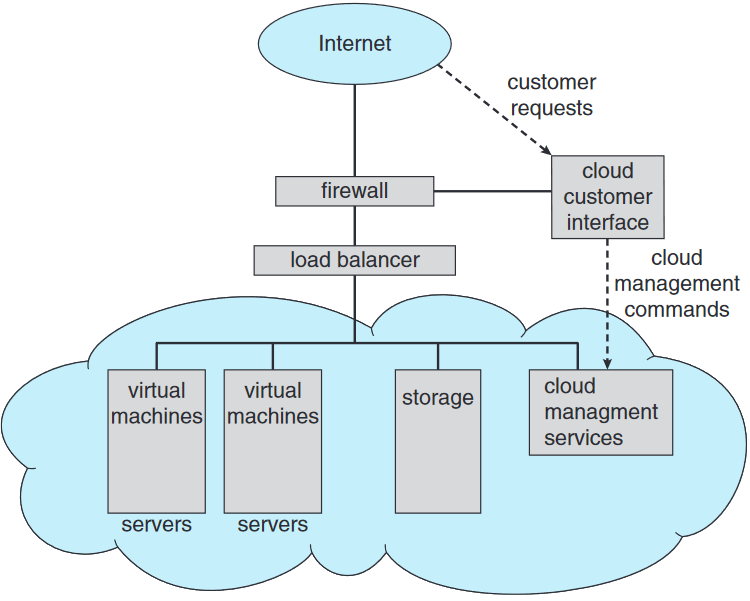
1.10.5. 클라우드 컴퓨팅
클라우드 컴퓨팅 cloud computing은 컴퓨팅, 기억 장치, 심지어 어플리케이션을 서비스로서 네트워크를 통해 제공할 수 있는 컴퓨팅. 가상화의 논리적 확장 버전이라 생각하면 됨. 기능의 기반이 가상화임. 클라우드 컴퓨팅의 여러 유형:
- 공공 클라우드 public cloud. 돈만 있으면 누구나 인터넷을 통해 서비스를 사용할 수 있는 클라우드.
- 사적 클라우드 private cloud. 회사의 사적 목적을 위해 사용하는 클라우드.
- 혼합형 클라우드 hybrid cloud. 공공과 사적 클라우드 성분을 둘 다 포함하는 클라우드.
- 서비스로서의 소프트웨어 SaaS. 인터넷을 통해 사용 가능한 하나 이상의 어플리케이션
- 서비스로서의 플랫폼 PaaS. 인터넷을 통해 어플리케이션 용도로 사용 가능한 소프트웨어 스택.
- 서비스로서의 인프라 IaaS. 인터넷을 통해 사용 가능한 서버 혹은 기억 장치.
이 유형이 서로 섞일 수 있긴 함.
클라우드 인프라 내에서도 여러 전통적인 운영체제가 있긴 함. 이거 말고도 VMM을 통해 사용자 프로세스가 실행될 가상 기계를 관리함. 더 나아가 VMM 자체가 WMwar vCloud Director나 Eucalyptus와 같은 클라우드 관리 도구에 의해 관리됨. 클라우드 내의 자원을 관리하고 클라우드 성분에게 인터페이스 제공.
1.10.6. 실시간 임베디드 시스템
임베디드 시스템은 현존하는 최다 컴퓨터 유형. 특정 목적을 가짐. 인터페이스 없거나 최소한이고, 대부분의 시간을 하드웨어 장치 모니터링하고 관리하는데 사용.
범용 운영체제 위에서 특정 목적 어플리케이션이 돌아갈 수도 있고, 특정 목적의 임베딩된 운영체제가 돌 수도 있고, 운영체제 없이 특정 용도 지향 집적회로 ASIC가 돌 수도 있음.
이걸로 IoT 가능.
임베디드 시스템은 거의 언제나 실시간 운영체제 real-time operating system이 돌고 있음. 얘는 프로세서의 연산이나 자료의 흐름에 대한 시간 소요를 엄격하게 관리할 때 사용. 그래서 전용 어플리케이션에 대한 제어 장치에 사용. 특정 목적에 사용한다 이 말이야.
실시간 시스템은 잘 정의된 고정 시간 제약을 가짐. 프로세스는 반드시 정의된 제약 내에서 돌아가야함. 안 그러면 시스템이 실패함. 예를 들어 로봇 팔이 자기가 만들던 차에 충돌한 다음에 멈추도록 하지는 않을 거란 말이지. 실시간 시스템은 오로지 시간 제약 내에 올바른 결과가 나올 때만 올바르게 작동함. 빠른 속도 내에 반응하는 것이 미덕인 전통적인 노트북과 비교해보면...
1.11. 무료 및 오픈소스 운영체제
무료 운영체제 free operating system나 오픈소스 운영체제 open-source operating system 둘 다 컴파일된 이진 코드가 아닌 소스코드의 형태로 제공됨. 둘이 뜻이 다름. 무료 소프트웨어(free/libre software라고도 부름)는 소스코드만 볼 수 있음. 즉, 상업 목적으로 못 쓰고, 재배포랑 수정 안된다는 라이선스가 있음. 오픈소스는 근데 그런 라이선스가 없을수도 있음. 마소 윈도우즈가 대표적인 클로즈드 소스 closed-source임. 윈도우즈는 특허 소프트웨어 proprietary software라서 마소가 소유하고, 그 사용을 제한하고, 소스 코드를 보호함. 애플의 macOS는 약간 혼용임. 오픈소스 커널인 Darwin이 있긴 한데 특허가 있는 클로즈드 소스 성분들도 있음.
소스코드가 있으면 이진 코드를 생성해서 시스템에서 실행 가능. 이 반대가 역공학 reverse engineering. 운영체제를 소스코드로 배우면 운영체제를 직접 수정하고 컴파일해서 수정 사항 확인 가능. 이거 좋은 공부법이거든요.
오픈소스 운영체제는 클로즈드 소스보다 보는 눈이 더 많아서 도 안전하다고 주장함. 물론 오픈소스는 버그가 있는데, 오픈소스 추종자들은 오픈소스를 보는 여러 눈이 이를 파악하고 빠르게 고칠 수 있다고 하긴 함. 이걸로 수익은 지원 계약이나 이 소프트웨어가 도는 하드웨어 판매로 올릴 수 있긴 함.
1.11.1. 역사
원래 소프트웨어는 소스코드랑 동봉된 형태.
나중에 바이너리 형태로만 배포해서 경쟁자들로부터 소스코드와 아이디어를 보호. 운영체제는 1980년대까지 특허 소프트웨어가 일반적임.
1.11.2. 무료 운영체제
1984년 리차드 스톨맨이 UNIX와 호환 가능한 운영체제인 GNU(GNU's Not Unix!) 개발. 여기서 무료는 공짜라는 뜻이 아니라 맘대로 쓰세요라는 뜻.
- 프로그램 맘대로 쓰세요
- 소스코드 맘대로 공부하시고 수정하세요
- 복사본을 주시든 파시든하세요
- 수정본을 주시든 파시든하세요
나중에 프리 소프트웨어 재단 Free Software Foundation (FSF) 설립.
FSF는 저작권으로 "카피레프트"라는 라이선스 만듦. 카피레트는 아무나 네 가지 자유를 바탕으로 복사본 가질 수 있게 함. GNU 공용 라이선스 GNU General Public License (GPL)은 이러한 무료 소프트웨어를 배포하는 일반적인 라이선스 중 하나.
1.11.3. GNU/리눅스
GNU/리눅스 GNU/Linux의 경우. 1991년엔 GNU 운영체제 거의 완성. 다른 건 다 됐는데 GNU 커널이 완성이 안 됨. 1991년에 핀란드 학생 리너스 토발즈가 GNU 컴파일러랑 도구를 사용해 기초적인 UNIX와 유사한 커널을 전세계에 배포함. 매주 "리눅스" 운영체제 업데이트를 함. 리눅스는 무료 소프트웨어는 아니었는데 1992년부터 GPL 라이선스 하에 재배포하여 무료 소프트웨어가 됨.
GNU 도구와 리눅스 커널을 가진 수백 가지의 고유한 배포판 distribution이 생김. PCLinuxOS처럼 시스템의 부트 디스크에 설치할 필요 없이 CD-ROM에서 바로 부팅될 수 있는 운영체제인 라이브 CD live CD도 그 중 하나. PCLinuxOS Supergamer DVD의 경우 그래픽 드라이버랑 게임을 포함한 라이브 DVD live DVD.
다음 방법으로 윈도우즈에서 리눅스 돌릴 수 있음:
- 무료 Virtualbox VMM 도구 다운로드하여 시스템에 설치
- 운영체제 CD와 같은 설치 이미지나 좀 더 빠르게 설치하여 실행할 수 있는 사전에 빌드된 운영체제 이미지 선택하여 설치. 이런 이미지들은 보통 사전 설치된 운영체제랑 어플리케이션, 그리고 GNU/Linux의 몇 가지를 포함함.
- Virtualbox로 가상 기계 부팅.
Virtualbox 말고는 Qemu라는 무료 프로그램 있음. qemu-img 명령어로 Virtualbox 이미지를 Qemu 이미지로 치환해서 손쉽게 불러오기 가능.
1.11.4. BSD 유닉스
BSD 유닉스 BSD Unix는 리눅스보다 더 길고 복잡한 역사를 가짐. 1978년도에 AT&T의 유닉스의 파생형으로 시작. 캘리포니아 대학 버클리 캠퍼스(UCB)에서 소스코드랑 바이너리 형태로 배포. AT&T의 라이선스 때문에 오픈소스는 아님. 나중에 1994년에 오픈소스이면서 완전한 기능을 갖춘 4.4BSD-lite이 출시됨.
리눅스처럼 여러 배포판 존재. 위에 리눅스에서 설명한 것처럼 Virtualbox로 사용 가능. 배포판의 소스코드는 /usr/src에 저장되어 있음. 커널 소스코드는 usr/src/sys에 있음. FreeBSD 커널의 가상 메모리 구현 코드는 /usr/src/sys/vm에 있음. 물론 온라인에서 소스 코드 직접 찾아 봐도 됨.
대부분의 오픈소스 프로젝트는 버전 관리 시스템 version control system 사용함. 이 경우엔 "서브버전" 사용. 버전 관리 시스템을 사용하면 "풀"로 소스코드 트리 전체를 자기 컴퓨터로 갖고 올 수 있고 "푸시"로 수정된 버전을 다른 사람들이 풀 할 수 있도록 저장소에 올릴 수 있음. 다른 버전 관리 시스템으로는 GNU/Linux에서 사용하는 깃 git이 있음.
macOS의 핵심 커널 성분인 Darwin은 BSD랑 UNIX 기반으로 오픈소스임. 커널을 포함한 패키지는 "xnu"라는 이름으로 시작함. 또한 여러 개발자 도구, 문서, 지원을 제공함.
1.11.5. 솔라리스
솔라리스 Solaris는 Sun Microsystems의 상용 UNIX 기반 운영체제. 원래 Sun의 SunOS라는 BSD UNIX 기반 운영체제가 있었는데, 1991년에 기반을 AT&T의 시스템 V UNIX로 옮김. 2005년에 대부분의 솔라리스 코드를 OpenSolaris 프로젝트의 일환으로 오픈소스화함. 근데 2009년에 오라클이 Sun 인수하면서 앞으로 미래가 불투명해짐.
OpenSolaris를 바탕으로 기능을 확장한 몇몇 그룹들이 있으며, 이를 프로젝트 Illumos라 부름.
1.11.6. 학습의 한 도구로서의 오픈소스 체제
무료 소프트웨어 운동 덕에 수많은 프로그래머들이 운영체제를 포함한 수천개의 오픈소스 프로젝트를 만들게 함. freshmeat이나 distrowatch와 같은 곳에서 그러한 프로젝트를 찾아볼 수 있음. 오픈소스로 학생들이 소스코드 보면서 공부 가능. 프로그램 수정하고, 테스트하고, 버그 찾고 수정하며, 좀 더 성숙하고, 기능이 완전한 운영체제, 컴파일러, 도구, 사용자 인터페이스와 같은 프로그램 등을 탐험 가능. 과거의 프로젝트 보면서 지식 얻고 새로운 프로젝트 만들 때 도움 받을 수도.
오픈소스의 또다른 장점은 다양성.
운영체제 공부
지금까지 운영체제 공부하기에 이토록 흥미롭고도 쉬운 시기가 없었음. 과거에는 문서나 운영체제 직접 작동해보면서 해결했던 궁금증이 이제는 오픈소스로 직접 소스코드 보면서 해결 가능.
이젠 상용화되지 않은 운영체제들도 여럿 오픈소스로 되어 시스템이 CPU, 메모리, 기억 장치 자원이 더 적었을 시절 어떻게 돌았는지 이해 가능. 완벽하진 않은데 오픈소스 운영체제들이 뭐뭐 있는지도 인터넷에서 확인 가능.
가상화가 이제 대세라서 하나의 핵심 시스템 위에 여러 운영체제 돌릴 수 있음.
특정 하드웨어에 대한 시뮬레이터도 돌릴 수 있어서 요즘 컴퓨터랑 요즘 운영체제 위에서 "네이티브" 하드웨어에 운영체제 돌릴 수도 있음.
오픈소스 운영체제 덕에 학생이 운영체제 개발자 되기 편해짐. 몇 가지 지식과 노력, 그리고 인터넷만 있으면 새로운 운영체제 배포판도 만들 수 있음.
1.12. 요약
- 운영체제는 컴퓨터 하드웨어 관리하는 소프트웨어. 어플리케이션 프로그램이 실행될 환경 제공.
- 인터럽트는 하드웨어가 운영체제와 상호작용하는 핵심 방법. 하드웨어 장치가 CPU에 신호를 보내 처리해야할 이벤트가 있음을 인터럽트를 발생시킴. 인터럽트는 인터럽트 처리자에 의해 처리.
- 컴퓨터가 프로그램 실행하려면 주메모리에 프로그램이 있어야함. 주메모리는 프로세서가 직접 접근할 수 있는 유일한 대용량 기억 장치.
- 주메모리는 휘발성 기억 장치로 전원을 끄거나 전력을 놓치면 저장 내용 다 잃음.
- 비휘발성 기억 장치는 주메모리의 확장으로 많은 양의 자료를 영구적으로 가질 수 있음.
- 가장 일반적인 비휘발성 기억 장치는 하드 디스크로 프로그램과 자료 둘 다 저장 가능.
- 컴퓨터 시스템의 여러 기억 장치 시스템은 속도와 비용에 따라 계층으로 구분 가능. 높은 계층일수록 비싸지만 빠르고, 아래 계층일수록 가격은 낮아지지만 접근 시간은 올라감.
- 요즘 컴퓨터 구조는 다중 프로세스 시스템으로, CPU가 여러 컴퓨팅 코어 가짐.
- CPU에서 최고의 효용을 뽑으려면 요즘 운영체제는 멀티프로그래밍을 통해 동시에 메모리에서 여러 작업이 가능하여 CPU가 언제나 실행할 작업이 있도록 보장.
- 멀티태스킹은 멀티프로그래밍의 확장으로 CPU 스케줄링 알고리듬이 프로세스 간 빠르게 왔다 갔다 하여 유저에게 빠른 응답 속도 제공.
- 사용자 프로그램이 시스템 연산에 간섭 못 하도록 시스템 하드웨어는 사용자 모드와 커널 모드 두 가지로 나뉨.
- 특권 있는 명령어들은 오로지 커널 모드에서 실행 가능.
- 운영체제의 작업 단위의 근간은 프로세스. 프로세스 관리란 프로세스 생성 및 삭제와 프로레스가 서로 통신하고 동기화하는 메커니즘을 의미.
- 운영체제는 메모리 중 어떤 게 사용 중이고 어떤 게 사용 중이 아닌지, 누가 사용 중인지 여부 추적하여 메모리 관리. 동적 할당 및 메모리 공간 해제의 역할.
- 기억 장치 공간은 운영체제가 관리. 파일 및 경로를 통해 대용량 기억 장치의 공간을 관리할 파일 시스템을 의미.
- 운영체제는 운영체제 자체와 사용자를 보호하고 보안을 제공할 메커니즘 필요. 보호는 컴퓨터 시스템의 자원에 대한 프로세스나 사용자의 접근을 제어함.
- 가상화는 컴퓨터의 하드웨어를 서로 다른 여러 실행 환경으로 추상화하는 것.
- 운영체제에서는 리스트, 스택, 큐, 트리, 맵과 같은 자료구조 사용.
- 컴퓨팅은 전통적인 컴퓨팅, 모바일 컴퓨팅, 클라이언트-서버 컴퓨팅, 개인 간 통신 컴퓨팅, 클라우드 컴퓨팅, 실시간 임베디드 시스템과 같은 여러 환경에서 발생.
- 무료 및 오픈소스 운영체제는 소스코드 형태로 제공. 무료 소프트웨어는 비상업적 용도로 사용, 재배포, 수정 가능한 라이선스.
