2. 프로세스 관리
4. 스레드와 동시성
모든 현대 운영체제에선 한 프로세스가 여러 스레드 제어 가능.
목표
- 스레드의 기본 성분, 스레드와 프로세스의 차이
- 멀티스레드 프로세스 설계의 주요 장점과 난관
- 스레드 풀, 포크-조인, 그랜드 센트럴 디스패치와 같은 여러 암시적 스레딩 방법
- 윈도우즈와 리눅스 운영체제의 스레드
- Pthread, 자바, 윈도우즈 스레딩 API를 통한 멀티스레딩 어플리케이션 설계
4.1. 개요
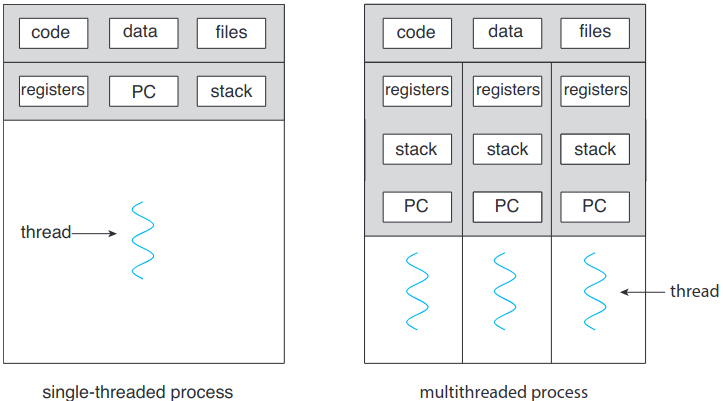
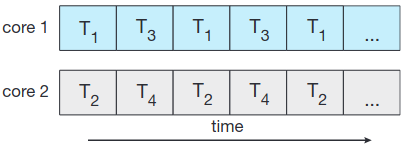
스레드는 CPU 활용의 기본 단위. 스레드 ID, 프로그램 카운터(PC), 레지스터 집합, 스택으로 구성됨. 코드 구역, 자료 구역과 기타 운영체제 자원들을 같은 프로세스 내 다른 스레드와 공유. 한 프로세스에 여러 스레드가 있으면 순간에 한 개 이상 작업 수행 가능. 아래 그림이 단일스레드 single-threaded 프로세스와 멀티스레드 multithreaded 프로세스의 차이.
4.1.1. 동기
요즘 현대적인 컴퓨터랑 모바일 장치에서 도는 소프트웨어 어플리케이션은 멀티스레딩을 함. 다음은 몇가지 예시:
- 여러 이미지에서 섬네일을 생성하는 어플리케이션은 각 스레드마다 각 이미지의 섬네일 생성
- 웹 브라우저는 이미지나 텍스트 출력용 스레드 하나에 네트워크에서 자료 가져오는 스레드 하나 사용할 수도
- 워드 프로세스는 그래픽 출력용 스레드, 사용자 키 입력 반응용 스레드, 철자와 문법 확인하는 스레드 세 가지 사용할 수도
어플리케이션은 다중 코어의 처리 능력을 활용하도록 설계될 수도. 여러 CPU에 부담 가는 작업을 여러 컴퓨터 코어에 병렬적으로 처리하게 해주기.
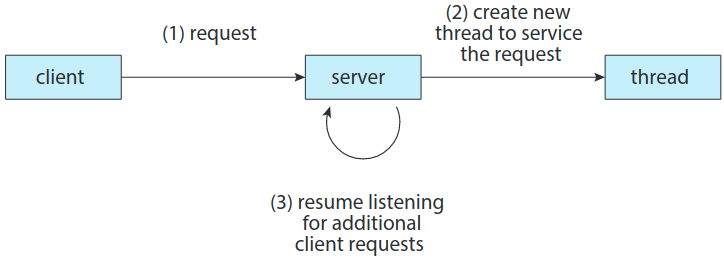
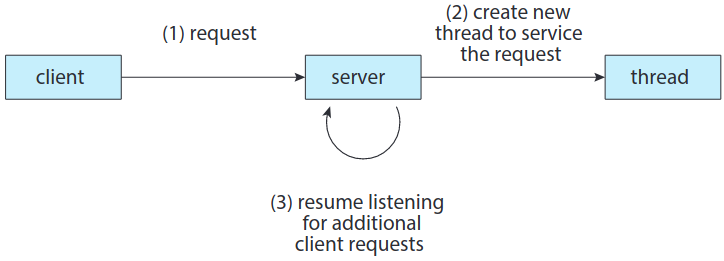
어떨 때에는 한 어플리케이션이 여러 비슷한 작업을 행해야 할 수도. 웹 서버가 예시.
서버가 우선 한 프로세스가 요청 처리하다가, 처리하는 도중 다른 요청 들어오면 해당 요청 처리하는 또다른 프로세스 만드는 방법도 있음. 이건 과거에 자주 사용했으나 프로세서 생성에 시간 걸리고 자원도 많이 먹었음. 멀티스레딩하는 게 더 나음. 스레드들은 듣기 상태 / 처리 상태. 첫번째 스레드가 처리 중이면 새로운 두번째 스레드 만들어서 듣게 만들기.
기본적인 정렬, 트리, 그래프 알고리듬 등에 멀티스레딩 도움이 됨. 데이터 마이닝, 그래픽스, 인공지능 등의 CPU 부담이 큰 현대적인 분야를 다루는 경우 병렬적 방법을 활용해 해법 설계.
암달의 법칙
암달의 법칙이란 연속(비병렬)과 병렬 성분을 갖는 어플리케이션에 연산 코어를 추가할 때 잠재적인 성능 향상을 구하는 공식. S가 N 개의 프로세서 코어를 갖는 시스템에 연속으로 실행될, 어플리케이션의 일부분이라면 공식은 다음과 같음:
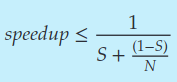
다음은 암달의 법칙을 여러 경우에 적용한 그래프:
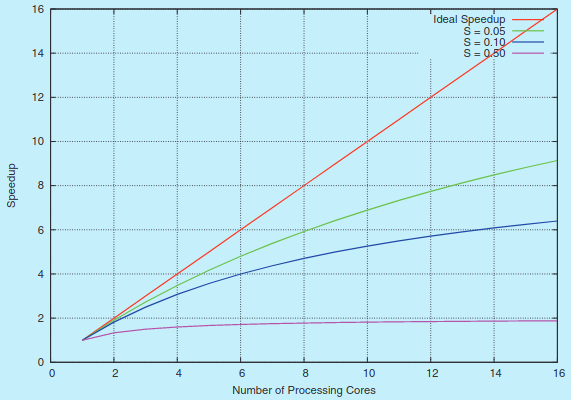
N이 무한대로 발산할 경우 속도 향상이 1/S에 수렴. 예를 들어 어플리케이션의 50%가 연속적으로 실행된다면 아무리 프로세서 코어를 추가해도 최대 속도 향상은 2.0 배. 이것이 암달의 법칙의 핵심: 어플리케이션의 연속적인 부분은 연산 코어를 추가하여 얻는 성능 향상과 반비례.
4.1.2. 장점
- 반응성 responsiveness. 일부가 긴 연산을 처리하고 있을 때도 사용자와 상호작용 가능해 반응성 향상. 특히 사용자 인터페이스 설계할 때 유용.
- 자원 공유 resource sharing. 프로세스에선 공유 메모리나 메시지 전달로 자원 공유. 이건 프로그래머가 명시적으로 구현해야함. 스레드는 애초에 기본적으로 속한 프로세스의 메모리와 자원을 공유함.
- 경제성 economy. 프로세스 생성에 해당하는 메모리 및 자원 할당은 비쌈. 스레드가 생성하고 스레드 간 문맥 교환하기에 더 경제적.
- 확장성 scalability. 스레드는 여러 프로세스 코어에 병렬로 돌 수 있어 다중프로세서 구조에서 더욱 이득.
4.2. 다중코어 프로그래밍
초기엔 단일 CPU 체제에서 다중 CPU 체제로. 나중엔 한 프로세서 칩에 다중 연산 코어. 여기서 각 코어는 운영체제에게 마치 서로 다른 CPU처럼 인식됨. 이게 다중코어 multicore 체제. 이때 멀티스레드 프로그래밍이 다중 연산 코어를 더 효율적으로 활용하고 동시성을 개선해줌. 연산 코어가 하나인 체제에서는 동시성이란 그저 교차되어 실행되는 스레드들. 다중 코어에서는 동시성이 실제 병렬적으로 돌 게 됨.

동시성 concurrency과 병렬성 parallelism은 서로 다른 것임. 동시체제란 하나 이상의 작업이 모두 진행되게 만드는 것. 반대로 병렬 체제는 동시에 한 개 이상의 작업을 수행할 수 있는 것. 동시성 없어도 병렬성이 가능. 과거엔 동시에 도는 것처럼 보여주려고 미친듯이 프로세스간 교체. 병렬 없는 동시임.
4.2.1. 프로그래밍 문제
트렌드가 다중코어 체제이다보니 시스템 설계자들이나 어플리케이션 프로그래머들이 다중 연산 코어를 잘 활용해야함. 운영체제 설계자는 다중 프로세서 코어를 잘 활용해 병렬적 실행을 가능케 해주는 스케줄링 알고리듬 작성해야. 어플리케이션 프로그래머는 존재하는 프로그래머를 수정하거나 새로운 프로그램을 설계할 때 멀티스레딩을 적용해야함.
일반적으로 다중코어체제에서 프로그래밍할 때 다섯 가지 문제가 있음:
- 작업 식별 identifying task. 어플리케이션에서 동시에 작업할 수 있게 서로 다른 부분으로 나눌 수 있는 영역을 찾기. 이상적으론 작업은 서로 독립적이므로 각자 다른 코어에서 병렬 실행 가능.
- 균형 balance. 병렬 처리할 작업이 같은 값에 같은 일을 수행해야 함을 보장해야함. 다른 작업에 비해 딱히 전체에 큰 영향을 주지 않는 작업은 굳이 따로 코어에 실행하기엔 수지가 안 맞을 지도.
- 자료 쪼개기 data splitting. 어플리케이션이 여러 작업으로 나뉘듯이 작업이 접근하고 수정할 자료도 서로 다른 코어로 나뉘어져 실행되야 함.
- 자료 의존성 data dependency. 한 작업이 접근할 자료는 두 개 이상의 작업 간의 의존성이 있는지 확인해야 함. 한 작업이 다른 작업의 자료에 의존하면 반드시 이 의존성에 따라 작업이 동기화됨을 보장해야 함.
- 테스트와 디버깅 testing and debugging. 프로그램이 다중 코어에서 병렬적으로 실행되면 여러 경우의 수 발생. 이런 동시 프로그램 테스트/디버그하는 건 단일스레드 어플리케이션 테스트/디버그하는 것보다 훨씬 어려움.
이런 문제들 때문에 다중코어 체제에서 소프트웨어 체제에는 새로운 설계법이 필요하다고 주장하기도.
4.2.2. 병렬의 종류
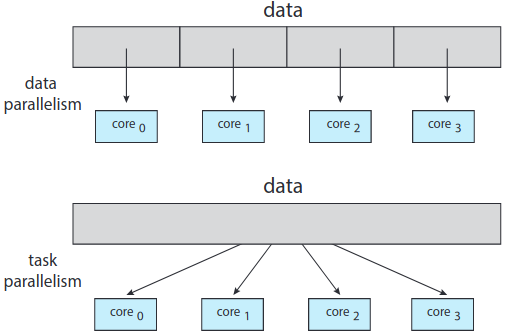
일반적으로 두 가지 종류의 병렬이 있음: 자료 병렬과 작업 병렬. 자료 병렬 data parallelism은 같은 자료의 부분집합을 다중 연산 코어에 분배하여 같은 연산을 각 코어에 수행하는 것.
작업 병렬 task parallelism은 자료가 아니라 작업(스레드)을 다중 연산 코어에 배분하는 행위. 각 스레드는 고유한 연산을 수행하고 있을 것. 같은 자료 혹은 다른 자료에 대해 서로 다른 스레드가 연산을 할 수도.
근본적으로 자료 병렬은 다중 코어에 자료 분산, 작업 병렬은 다중 코어에 작업 분산. 허나 둘이 상호 배타적인 것은 아니고, 두 전략을 혼합해서 사용할 수도 있음.
4.3. 멀티스레드 모델
스레드는 사용자 수준의 사용자 스레드 user thread나 커널 수준의 커널 스레드 kernel thread의 형태로 제공. 사용자 스레드는 커널 윗단을 지원되며 커널의 지원 없이 관리되지만, 커널 스레드는 운영체제에 의해 직접적으로 관리됨. 모든 현대적 운영체제, 윈도우즈, 리눅스, macOS 등은 커널 스레드 지원.
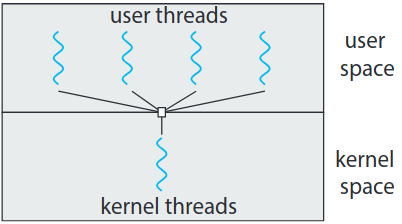
결국 위 그림처럼 사용자 스레드와 커널 스레드 간의 관계 반드시 존재해야. 세 가지 방법 있음: 다대일, 일대일, 다대다 모델.
4.3.1. 다대일 모델
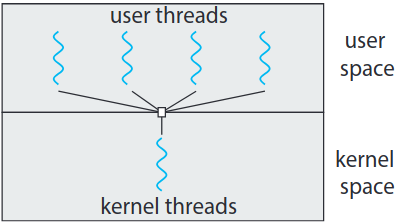
여러 사용자 수준 스레드를 하나의 커널 스레드에 매핑. 사용자 공간의 스레드 라이브러리에 의해 스레드 관리하므로 효율적. 스레드가 블락하는 시스템 호출할 경우 전체 프로세스가 블락됨.
한 순간에 한 스레드만 커널에 접근할 수 있으므로 다중 스레드는 병렬로 실행 불가. 그린 스레드 Green thread는 솔라리스 체제의 스레드 라이브러리로 Java 초기에 사용했던 라이브러로, 다대일 모델임. 요즘은 웬만한 컴퓨터 체제의 입구컷인 다중 프로세서 코어의 장점 활용이 불가해서 잘 안 함.
4.3.2. 일대일 모델
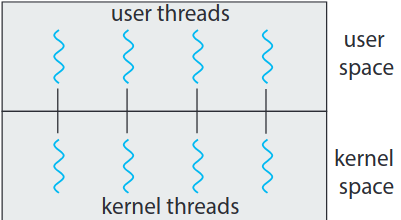
각 사용자 스레드를 하나의 커널 스레드에 매핑. 스레드가 블락하는 시스템 호출할 때 다른 스레드가 돌 수 있어 다대일 모델보다는 더 나은 동시성 제공. 유일한 단점이라면 사용자 스레드 생성에는 이에 대응하는 커널 스레드가 필요할텐데, 커널 스레드가 많아질 수록 시스템의 성능 좀먹음. 리눅스와 윈도우즈 운영체제가 일대일 모델 사용.
4.3.3. 다대다 모델

다대다 모델에서는 여러 사용자 수준 스레드를 더 적거나 같은 수의 커널 스레드에 멀티플렉스. 커널 스레드 개수는 특정 어플리케이션이나 기계에 따라 다름. 어플리케이션은 여덟 개의 프로세스 코어를 갖는 체제에서보다 코어 네 개인 체제보다 더 많은 커널 스레드 할당 받을 것.
이 설계가 동시성에 미치는 영향: 다대일에서는 개발자가 원하는 만큼 스레드를 만들 수는 있어도 병렬은 아님. 일대일은 동시성은 좋은데 과도하게 많은 스레드를 사용하지 않도록 개발자가 조심해야 함. 다대다는 이런 문제가 둘 다 없음. 원하는 만큼 스레드 생성해도 됨. 이 스레드에 대응하는 커널 스레드가 다중 프로세서에 병렬로 실행될 것. 한 스레드가 블락 시스템 호출을 수행하더라도 다른 스레드를 실행하도록 스케줄링 가능함.
다대다 모델의 변형도 존재. 2단계 모델 two-level model이라는 변형은 여러 사용자 스레드를 더 적거나 같은 수의 커널 스레드에 멀티플렉스하면서도 사용자 스레드가 커널에 바인드될 수 있는 경우임.
다대다를 가장 유연한 것처럼 그렸지만 실무에서 구현하기가 좀 까다로움. 게다가 프로세서 코어의 수가 늘어나면서 커널 스레드의 수를 제한하는것에 대한 중요도가 낮아지기 시작. 결과적으로 대부분의 운영체제는 일대일 모델 사용. 4.5절에서 보겠지만 몇몇 현대적인 동시 라이브러리는 다대다 모델을 사용하여 스레드를 매핑하는 작업을 지정해주는 개발자들이 존재하기도.
4.4. 스레드 라이브러리
스레드 라이브러리 thread library란 스레드 생성 및 관리 기능을 갖는 API. 두 가지 방법으로 구현. 하나는 라이브러리 자체를 커널 지원 없이 사용자 공간에서 완전하게 해주는 법. 모든 코드와 자료 구조가 사용자 공간에 존재. 이 라이브러리에서 함수 호출은 지역 함수 호출이지 시스템 호출이 아니라는 뜻.
두번째 접근법은 운영체제가 직접 지원하는 커널 수준 라이브러리를 구현하는 법. 코드와 자료 구조가 커널 공간에 존재. 여기서 함수 호출하면 보통 커널에 시스템 호출을 하게 됨.
아직까지 사용하는 대표적인 스레드 라이브러리 세 가지: POSIX Pthread, 윈도우즈, 자바. Pthread는 POSIX 표준의 스레드 확장판. 사용자 수준과 커널 수준 라이브러리 두 가지 가능. 윈도우즈 스레드 라이브러리는 윈도우즈 체제에서 사용 가능한 커널 수준 라이브러리. 자바 스레드 API는 자바 프로그램에서 직접 스레드 생성 및 관리 가능하게 해줌. JVM이 사실상 호스트 운영체제 위에서 돌기 때문에 자바 스레드 API는 보통 호스트 체제에서 사용 가능한 스레드 라이브러리를 바탕으로 구현됨. 즉, 윈도우즈에선 윈도우즈 API로, 유닉스, 리눅스, macOS 체제에서는 보통 Pthread로.
POSIX와 우니도우즈 스레딩에서는 임의의 자료를 전역으로 선언하여 같은 프로세스 내의 모든 스레드 간 공유 가능. 자바엔 전역 자료라는 개념이 없기에 스레드 간 자료 공유를 위해선 명시적으로 처리해줘야 함.
여러 스레드 스레스 생성할 때의 일반적으로 사용하는 두 가지 전략: 비동기 스레딩 asynchronous threading, 동기 스레딩 synchronous threading. 비동기 스레딩에서는 부모가 자식 스레드를 만들면 부모가 자기 하던거 계속해서 부모와 자식이 동시에, 독립적으로 돌게됨. 두 스레드가 독립적이므로 자료 공유도 최소임. 아래 그림처럼 멀티스레드 서버나 반응형 유저 인터페이스 설계할 때 보통 사용하는 전략.
동기 스레딩은 부모 스레드가 하나 이상의 자식 생성할 경우 자식들이 전부 종료될 때까지 대기하는 것. 보통 동기 스레딩에는 스레드 간 자료 공유가 상당히 발생.
4.4.1. Pthread
Pthread란 POSIX 표준(IEEE 1003.1c)에 해당하는 스레드 생성 및 동기에 대한 API 정의. 이것은 스레드의 구현 implementation이 아닌 명세 specification임. 운영체제 설계자는 자기가 구현하고 싶은 방법으로 명세에만 맞추어 구현하면 됨. 대부분의 경우 리눅스나 macOS와 같은 유닉스류 체제에서 구현해서 사용. 윈도우즈가 근본적으로 Pthread를 지원하지는 않으나 서드파티 구현이 존재하긴 함.
아래 코드 예시는 서로 다른 스레드에서 음수가 아닌 정수의 덧셈을 계산하는 멀티스레딩 프로그램을 프로그래밍할 때 Pthread API를 사용하는 기본적인 예시. 프로그램 시작하면 main()에서 단일스레드로 시작. 몇 가지 초기화한 다음에 runner() 함수에서 시작하는 두번째 스레드 생성. 둘 다 전역 자료 g_sum 공유.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
int g_sum; /* 스레드 간 공유할 자료 */
void* runner(void* param); /* 스레드가 이 함수를 호출함 */
int main(int argc, char* argv[])
{
pthread_t tid; /* 스레드 식별자 */
pthread_attr_t attr; /* 스레드 속성 집합 */
/* 스레드의 기본 속성 집합 */
pthread_attr_init(&attr);
/* 스레드 생성 */
pthread_create(&tid, &attr, runner, argv[1]);
/* 스레드 종료할 때까지 대기 */
pthread_join(tid, NULL);
printf("sum = %d∖n",sum);
}
/* 이 함수에서 스레드 실행 */
void* runner(void* param)
{
int i;
int upper = atoi(param);
g_sum = 0;
for (i = 1; i <= upper; i++)
sum += i;
}
pthread_exit(0);
}이 예시에서는 스레드 하나만 생성했지만 여러 스레드 생성하는 건 이제 흔한 일임. pthread_join() 함수로 여러 스레드를 대기하는 간단한 방법으로는 이 연산을 간단한 for 루프 안에 넣는 것임. 아래 예시처럼.
#define NUM_THREADS 10
/* 합병할 스레드의 배열 */
pthread_t workers[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; ++i) {
pthread_join(workers[i], NULL);
}4.4.2. 윈도우즈 스레드
Pthread랑 유사함. windows.h 헤더 추가해야함.
#include <windows.h>
#include <stdio.h>
DWORD g_Sum; /* 스레드 간 공유할 자료 */
/* 이 함수에서 스레드 실행됨 */
DWORD WINAPI Summation(LPVOID Param)
{
DWORD Upper = *(DWORD*)Param;
for (DWORD i = 1; i <= Upper; i++) {
g_Sum += i;
}
return 0;
}
int main(int argc, char* argv[])
{
DWORD ThreadId;
HANDLE ThreadHandle;
int Param;
Param = atoi(argv[1]);
/* 스레드 생성 */
ThreadHandle = CreateThread(
NULL, /* 기본 보안 속성 */
0, /* 기본 스택 크기 */
Summation, /* 스레드 함수 */
&Param, /* 스레드 함수 매개변수 */
0, /* 기본 생성 플래그 */
&ThreadId); /* 스레드 식별자 반환 */
/* 스레드 종료까지 대기 */
WaitForSingleObject(ThreadHandle, INFINITE);
/* 스레드 핸들 종료 */
CloseHandle(ThreadHandle);
printf("sum = %d∖n", g_Sum);
}여러 스레드 완료될 때까지 대시해야하는 경우 WaitForMultipleObjects() 함수 사용. 네 개의 매개변수 전달:
- 대기할 개체의 수
- 개체의 배열을 가리키는 포인터
- 모든 개체들이 신호를 보냈는지 여부에 해당하는 플래그
- 시간 제한 (혹은
INFINITE)
예를 들어 THandles가 크기 N인, 스레드 HANDLE 개체의 배열이라면 부모 스레드가 이 자식들을 전부 기다릴 때 다음과 같이 하면 됨:
WaitForMultipleObjects(N, THandles, TRUE, INFINITE);4.4.3. 자바 스레드
스레드는 자바 프로그램에서 프로그램 실행의 기초 모델. 모든 자바 프로그램은 최소한 하나의 제어하는 스레드가 존재.
명시적으로 스레드 생성하는 두 가지 방법 존재. 하나는 Thread 클래스 상속하여 run() 메서드 오버라이드하는 법. 다른 방법이자 더 흔하게 사용하는 법은 Runnable 인터페이스 상속하여 구현하는 것. public void run()이라는 하나의 추상 메서드만 정의해주면 됨:
class Task implements Runnable {
public void run() {
System.out.println("I am a thread.");
}
}자바에서 스레드 생성하려면 Thread 개체에 Runnable을 구현한 클래스의 한 개체를 전달해주어 생성한 뒤, start() 메서드를 호출하는 것:
Thread worker = new Thread(new Task());
worker.start();start() 호출하면 두 가지가 발생:
- JVM에 새 스레드를 위한 메모리 할당하고 초기화
run()메서드 호출하여 해당 스레드가 JVM에서 실행. (run()메서드를 직접 호출할 일은 없음. 대신start()를 호출해서run()을 호출하게 만들지.)
Pthread와 윈도우즈는 각각 pthread_join()과 WaitForSingleObject()로 스레드 대기. 자바에서 해당 기능과 유사한 것이 join() 메서드. (이놈 InterruptedException 던질 수도.)
try {
worker.join();
} catch (InterruptedException ie) {
}Pthread와 마찬가지로 여러 스레드 대기하려면 for문 사용하면 됨.
자바의 람다 표현식
1.8 버전부터 자바에 람다 표현식 추가해 스레드 생성이 좀 더 깔끔해짐. 따로
Runnable을 구현하는 클래스를 정의하는 대신 람다 표현식을 사용 가능:Runnable taks = () -> { System.out.println("I am a thread."); };
Thread worker = new Thread(task);
worker.start();
람다는 유사한 클로저 closure 함수처럼 함수형 프로그래밍 언어의 중요한 기능이고, 파이썬, C++, C#과 같은 비함수형 언어에도 사용 가능.
4.4.3.1. 자바 실행자 프레임워크
1.5 버전과 그 API부터 여러 동시성 기능을 제공해 개발자가 스레드 생성과 통신에 좀 더 제어권을 가질 수 있게 해줌. java.util.concurrent 패키지에서 사용 가능.
명시적으로 Thread 개체 생성하지 말고 Executer 인터페이스에서 구조화:
public interface Executor {
void execute(Runnable command);
}자바 개발자는 이제부터 Thread 개체 따로 생성해서 start() 메서드 호출하지 말고 다음과 같이 Executor 사용하면 됨:
Executor service = new Executor;
service.execute(new Task());Executor 프레임워크는 생산자-소비자 모델 기반. Runnable 인터페이스 구현한 작업이 생산물, 이걸 실행하는 스레드가 소비자. 장점으로는 스레드 생성과 실행을 구분할 뿐만ㅁ 아니라 동시 작업 간 통신도 가능.
윈도우즈와 Pthread에서 같은 프로세스 내 스레드 간 자료 공유는 전역으로 손쉽게 가능. 자바는 순수 개체 지향 언어라 전역 자료라는 개념이 없음. 그래서 java.util.concurrent 패키지의 Callable 인터페이스라는 Runnable과 유사하지만 결과가 반환될 수 있는 인터페이스 존재. Callable 작업이 반환한 개체가 바로 Future 개체. 이 기능을 활용한 코드:
import java.util.concurrent.*;
class Summation implements Callable<Integer> {
private int upper;
public Summation(int upper) {
this.upper = upper;
}
/* 이 메서드에서 스레드 실행 */
public Integer call() {
int sum = 0;
for (int i = 1; i <= upper; i++) {
sum += i;
}
return new Integer(sum);
}
}
public class Driver {
public static void main(String[] args) {
int upper = Integer.parseInt(args[0]);
ExecutorService pool = Executors.newSingleThreadExecutor();
Future<Integer> result = pool.submit(new Summation(upper));
try {
System.out.println("sum = " + result.get());
} catch (InterruptedException | ExecutionException ie) {
}
}
}단순히 스레드 생성하고 종료할 때 합병하는 것보다는 복잡해보임. 허나 이 정도의 복잡함을 제물로 몇 가지 이득을 챙길 수 있음. Callable과 Future를 통해 스레드가 결과를 반환하게 만들 수 있음. 게다가 스레드의 생성과 이들이 생산하는 결과와 분리를 해줄 수 있어 스레드가 종료되어 결과 받을 때까지 대기할 필요가 없음. 부모는 그저 결과를 사용 가능할 때까지 대기하기만 하면 됨. 이 프레임워크를 다른 기능과 결합해 여러 스레드를 관리하는 도구를 만들 수도 있음.
4.5. 암시적 스레딩
다중코어 프로세스가 성장함에 따라 수백, 수천 스레드 사용. 이게 간단하지 않음. 4.2 절에 언급한 문제들 뿐만 아니라 다른 추가적인 문제들도 있음. 6 단원과 8 단원에서 다룰 프로그램 정확성에 대한 문제.
이런 문제를 처리하고 동시와 병렬 어플리케이션 설계를 더 잘하기 위한 방법이 나옴. 이 전략을 암시적 스레딩 implicit threading이라 부름. 이 절에서 네 가지 방법을 살펴볼 것. 이 전략들은 보통 병렬로 돌 수 있는 스레드 말고 작업 task이 무엇인지를 식별해야함. 작업은 보통 함수고, 실시간 라이브러리 이걸 독립된 스레드에 매핑해서 보통 다대다 모델로 사용. 이 방법의 장점은 개발자가 오로지 병렬 작업이랑 스레드 생성과 관리에 대한 세부사항을 결정할 라이브러리가 무엇인지만 알면 됨.
4.5.1. 스레드 풀
4.1 절에서 언급한 멀티스레드 서버에도 아직 문제가 있음. 우선 스레드 생성에 걸리는 시간과 작업이 끝나면 스레드가 없어진다는 점. 두번째 문제가 더 문제될 수 있는데, 동시 요청을 받아 새 스레드에 서비스를 할 때, 현재 체제에 동시에 활성화될 수 있는 스레드의 개수에 한계가 없다는 점. 무제한이면 시스템 자원을 좀먹음. 해결 방법으로는 스레드 풀 thread pool을 사용하는 법.
스레드 풀의 기본 아이디어는 여러 스레드를 시작할 때 생성해 풀에 넣고, 일을 하기 전까지 가만히 앉아서 기다리게 함. 서버가 요청을 받으면 스레드 생성 말고 스레드 풀에 요청을 전송해 놀고 있던 스레드에게 일 할당. 놀고 있는 애가 있다면 요청을 주어 서비스. 만약 다 일하고 있다면 놀 애 나올 때까지 큐에서 대기. 스레드 풀은 풀에 전송된 작업이 비동기로 실행될 수 있을 때 잘 작동함.
스레드 풀의 장점:
- 이미 존재하는 스레드에 요청을 서비스하는 게 스레드 생성하는 것보다 더 빠름
- 임의의 순간에 존재할 수 있는 스레드의 개수를 한정시킴. 많은 수의 동시 스레드 지원 못하는 체제에서 중요
- 수행할 작업을 작업 생성 메커니즘과 분리해주어 작업 실행할 때 여러 전략 쓸 수 있게 함. 시간 딜레이나 정기적으로 작업을 실행하도록 스케줄링하는 등
풀의 스레드 개수는 경험적으로, 체제의 CPU 개수, 물리 메모리량, 동시 클라이언트 요청 예상 수 등에 따라 결정. 더 복잡한 스레드 풀 구조의 경우 사용 패턴에 따라 동적으로 개수 조절 가능. 이런 구조의 경우 작은 풀을 갖는 장점을 제공해 메모리 덜 먹고 시스템 로드도 적음. 구조 하나 더 논의하자면 애플의 그랜드 센트럴 디스패치가 있음.
윈도우즈 API의 경우 스레드 풀과 유관한 여러 함수 제공. Thread_Create() 함수와 유사하게 따로 스레드 실행하는 함수도 정의되어 있음:
DWORD WINAPI PoolFunction(PVOID Param)
{
/* 이 함수는 독립된 스레드로 실행 */
}PoolFunction()에 대한 포인터를 스레드 풀 API의 한 함수에 전달하면 풀의 한 스레드가 이 함수를 실행. 이런 스레드 풀 API의 한 함수가 QueueUserWorkItem() 함수로, 매개변수 세 개.
LPTHREAD_START_ROUTINE Function- 독립된 스레드를 실행할 함수를 가리킬 포인터PVOID Param-Function에 전달할 매개변수ULONG Flags- 스레드 풀이 어떻게 스레드를 생성하고 실행 관리하는지에 대한 플래그
함수 호출의 예시:
QueueUserWorkItem(&PoolFunction, NULL, 0);위의 함수는 스레드 풀의 스레드가 PoolFunction()을 프로그래머 대신 호출해줌. 여기서 플래그를 0으로 명시해주었기 때문에 매개변수 전달하지 않음.
다른 함수들로는 정기적으로 혹은 입출력 요청 끝날 때 함수 호출하는 기능 등이 있음.
안드로이드 스레드 풀
3.8.2.1 절에서 안드로이드 운영체제의 RPC를 다뤘음. 안드로이드가 AIDL로 클라이언트가 서버와 상호작용할 원격 인터페이스를 명시해주는 도구. AIDL은 스레드 풀을 제공함. 원격 서비스가 여러 동시 요청을 풀의 각기 다른 스레드에서 서비스.
4.5.1.1. 자바 스레드 풀
java.util.concurrent 패키지에 여러 스레드 풀 구조들에 대한 API 있음. 그 중 세가지 모델에 집중:
- 단일 스레드 실행자 -
newSingleThreadExecutor()- 크기 1인 풀 생성 - 고정 스레드 실행자 - '
newFixedThreadPool(int size)- 특정 개수의 스레드를 갖는 스레드 풀 생성 - 캐시 스레드 실행자 -
newCachedThreadPool()- 무한 개수 스레드 풀 생성. 여러 개체에서 스레드 재사용.
이미 4.4.3 절에서 자바 스레드 풀 사용해봤음.
스레드 풀은 Executors 클래스의 팩토리 메서드 중 하나로 생성 가능:
static ExecutorService newSingleThreadExecutor()static ExecutorService newFixedThreadPool(int size)static ExecutorService newCachedThreadPool()
각 팩토리 메서드는 ExecutorService 인터페이스 구현한 개체를 생성하고 반환. ExecutorService는 Executor 인터페이스 상속 받아 executr() 메서드 호출 가능. 스레드 풀 종료하는 메서드도 제공.
import java.util.concurrent.*;
public class ThreadPoolExample {
public static void main(String[] args) {
int numTasks = Integer.parseInt(args[0].trim());
/* 스레드 풀 생성 */
ExecutorService pool = Executors.newCachedThreadPool();
/* 풀의 스레드를 통해 각 작업 실행 */
for (int i = 0; i < numTasks; i++) {
pool.execute(new Task());
}
/* 모든 스레드 완료되면 풀 종료 */
pool.shutdown();
}
}위의 예시를 통해 캐시 스레드 풀 생성하고 execute() 메서드로 풀의 스레드에서 작업 실행. shutdown() 메서드 호출 시 스레드 풀은 추가적인 작업 무시하고 현재 존재하는 작업 전부 실행 완성되면 종료.
4.5.2. 포크 합병
4.4 절의 스레스 생성 전략을 보통 포크-합병 fork-join 모델이라 부름. 이 메서드로 메인 부모 스레드가 하나 이상의 자식 스레드를 생성(포크)하고 자식이 종료될 때까지 대기한 후 회수 가능하고 그 결과를 합칠 수 있을 때 합병함. 이런 동기화 모델을 명시적 스레드 생성이라 칭하지만 암시적 스레딩에도 사용될 수 있는 훌륭한 방법. 암시적 방법에서는 스레드를 포크 단계에서 직접 생성하지 않고, 병렬 작업을 지정함. 라이브러리가 생성할 스레드의 개수를 관리하고 스레드에 작업 할당의 책임을 짐. 이 포크-합병 모델이 라이브러리가 실제 생성할 스레드 개수를 정한다는 점에서 스레드 풀의 동기적 버전이라고도 볼 수 있음.
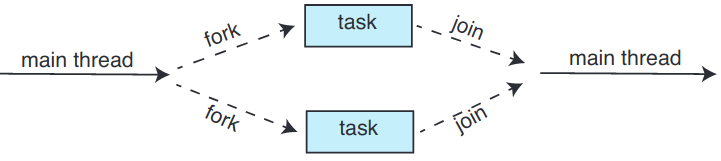
4.5.2.1. 자바의 포크 합병
1.7 버전 API에서 포크 합병 라이브러리 소개됨. 퀵 정렬, 합병 정렬과 같은 재귀적 분할정복 알고리듬에 사용하도록 설계됨. 독립된 작업이 분할 단계에 포크된 다음 원본 문제의 부분집합에 할당됨. 이 독립된 작업이 동시에 돌도록 알고리듬 설계해야 함. 작업에 할당될 문제를 추가적인 작업으로 나눌 필요 없이 직접 해결할 수 있을 만큼 크기가 충분이 작을 때가 올 것. 자바의 포크-합병 모델을 통한 일반적인 재귀 알고리듬은 다음과 같음:
Task(문제)
if 문제가 충분히 작을 때
직접 문제 해결
else
subtask1 = fork(new Task(문제의 부분 집합))
subtask2 = fork(new Task(문제의 부분 집합))
result1 = join(subtask1)
result2 = join(subtask2)
return 합친 결과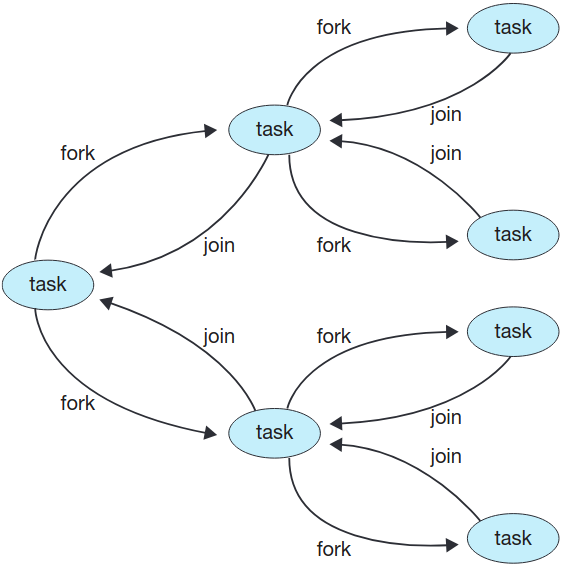
정수 배열의 모든 원소를 더하는 분할정복 알고리듬 설계하여 자바의 포크-합병 전략 이해해보기. 자바 API 1.7 버전부터 ForkJoinPool이라는 스레드 풀 등장해 ForkJoinTask라는 추상 기반 클래스 상속한 작업을 할당해줄 수 있음:
ForkJoinPool pool = new ForkJoinPool();
// 합칠 정수를 포함한 배열
int[] array = new int[SIZE];
SumTask task = new SumTask(0, SIZE - 1, array);
int sum = pool.invoke(task);완료되면 처음에 호출한 invoke()가 array의 합을 반환.
import java.util.concurrent.*;
public class SumTask extends RecursiveTask<Integer> {
static final int THRESHOLD = 1000;
private int begin;
private int end;
private int[] array;
public SumTask(int begin, int end, int[] array) {
this.begin = begin;
this.end = end;
this.array = array;
}
protected Integer compute() {
if (end - begin < THRESHOLD) {
int sum = 0;
for (int i = begin; i <= end; i++) {
sum += array[i];
}
return sum;
} else {
int mid = (begin + end) / 2;
SumTask leftTask = new SumTask(begin, mid, array);
SumTask rightTask = new SumTask(mid + 1, end, array);
leftTask.fork();
rightTask.fork();
return rightTask.join() + leftTask.join();
}
}
}여기서 SumTask가 포크-합병을 사용해 배열의 총합 구하는 분할정복 알고리듬 구현함. fork() 메서드로 작업 생성하고 compute() 메서드로 각 작업마다 연산이 처리됨. 지정받은 부분집합을 직접 연산할 수 있을 때까지 compute() 메서드 호출. join() 호출하면 작업 완료할 때까지 블락함. join() 반환할 때 compute()에서 연산한 결과 반환.
SumTask가 RecursiveTask 상속. 자바의 포크-합병 전략은 추상 기반 클래스 ForkJoinTask를 중심으로 구조화되어있음. RecursiveTask랑 RecursiveAction 클래스가 ForkJoinTask를 상속 받음. 둘 사이의 차이점이라면 전자는 결과를 반환(compute()이 명시한 특정 값을 통해)한다는 것이고, RecursiveAction은 결과를 반환하지 않는다는 것. 세 클래스 간의 관계를 UML 다이어그램으로 표현:
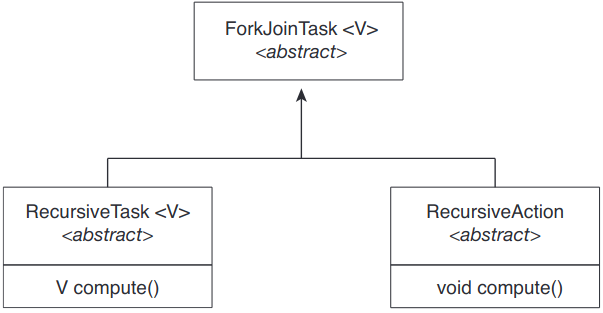
중요한 건 언제 문제가 추가적인 작업 만들 필요 없이 직접 해결해도 될만큼 "작다"는 것? 위의 예시에서는 THRESHOLD라는 임의의 값 1,000으로 설정. 실무에서는 여러 시도를 해보면서 값을 정해야함. 구현마다 값이 달라질 수 있으니.
자바의 포크-합병 모델에서 흥미로운 점은 라이브러리가 일꾼 스레드를 생성하고 이용 가능한 일꾼에게 작업을 고르게 배분할 때의 작업 관리 방법임. 어쩔 땐 스레드는 적은데 작업은 수천 개일 수도. ForkJoinPool의 각 스레드는 포크한 작업의 큐를 유지함. 큐가 비어있으면 작업 훔치기 work stealing 알고리듬으로 다른 스레드의 큐에서 작업을 훔쳐와 스레드 간의 업무 부담의 균형을 맞춤.
4.5.3. OpenMP
OpenMP란 공유 메모리 환경에서 병렬 프로그래밍을 제공하는 C, C++, FORTRAN으로 작성된 프로그램을 위한 컴파일러 지시자들과 API. OpenMP에서 병렬 영역 parallel region이란 병렬로 실행 가능한 코드 블록. 어플리케이션 개발자가 병렬 영역에 있는 코드에 컴파일러 지시어를 넣어주면 이 지시어들이 OpenMP 실시간 라이브러리를 주입하여 해당 영역을 병렬로 실행되게 해줌. 다음 C 프로그램이 그 예시:
#include <omp.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
/* 순차적 코드 */
#pragma omp parallel
{
printf("I am a parallel region.");
}
/* 순차적 코드 */
return 0;
}OpenMP가 지시어
`#pragma omp parallel`를 보는 순간 최대 체제의 프로세서 코어가 있는 만큼 스레드 생성. 듀얼코어 체제라면 스레드 두 개, 쿼드코어라면 스레드 네 개 등. 이 스레드는 병렬 영역을 동시에 실행. 각 스레드는 병렬 영역 벗어나면 종료됨.
코드 영역을 병렬로 실행할 수 있도록 추가적인 지시어 제공함. 루프 병렬화 등. 예를 들어 크기 N의 두 배열 a, b이 있을 때, 이 원소들의 합을 배열 c에 넣는다고 가정. 이걸 다음 코드로 for문을 병렬화하는 지시어를 넣어 병렬로 작업 실행 가능:
#pragma omp parallel for
for (i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}OpenMP가 지시자
#pragma omp parallel for보는 순간 for문의 작업을 스레드에 배분함.
병렬화를 위한 지시어 외에도 병렬화의 수준까지 정할 수 있게 해줌. 스레드의 개수를 직접 설정할 수 있음. 스레드 간 자료가 공유되는지, 사유재산인지 여부도 정할 수 있음. OpenMP는 리눅스, 윈도우즈, macOS 체제의 여러 오픈소스 / 상용 컴파일러에 적용 가능.
4.5.4. 그랜드 센트럴 디스패치
그랜드 센트럴 디스패치(GCD)란 macOS와 iOS 운영체제에 사용 중인 애플이 개발한 기술. 실시간 라이브러리, API, 언어 확장이 짬뽕되어 코드의 일부분(작업)을 병렬로 실행할 수 있게 해줌. OpenMP처럼 GCD가 대부분의 스레딩 부분을 관리해줌.
GCD는 작업을 파견 큐 dispatch queue에 넣어 실시간 실행을 위해 스케줄링함. 작업을 큐에서 제거하면 해당 작업을 GCD가 관리하는 스레드 풀 내에 사용 가능한 스레드에 할당. GCD의 두 가지 파견 큐: 연속 serial, 동시 concurrent.
연속 큐에 있는 작업은 선입선출 순으로 제거됨. 한 작업을 제거하면, 이 작업이 종료되어야 다음 작업 제거 가능. 각 프로세스엔 자신만의 연속 큐(메인 큐 main queue라 부름)를 가지며, 개발자는 특정 프로세스에 지역적인 연속 큐 추가 생성 가능. (이래서 연속 큐를 전용 파견 큐 private dispatch queue라 부르기도 하는 것.) 작업의 연속 실행을 보장할 때 유용.
동시 큐에 있는 작업도 선입선출로 제거되지만, 순간 여러 작업 제거 가능해 병렬로 작업 실행 가능. 여러 시스템 단의 동시 큐 존재(전역 파견 큐 global dispatch queue라 부르기도). 보통 네 가지 주요 서비스 품질 클래스로 나눔:
QOS_CLASS_USER_INTERACTIVE- 사용자 상호작용적 user-interactive 클래스. 사용자와 상호작용하는 작업을 의미. 반응형 사용자 인터페이스를 보장해야 할 때 등 사용. 이 클래스에 속하는 작업을 완료하는 데에는 적은 노동량만 들어가야 함.QOS_CLASS_USER_INITIATED- 사용자 개시 user-initiated 클래스. 작업이 반응형 사용자 인터페이스와 유관하다는 점에서 사용자 상호작용적 클래스와 유사하나 사용자 개시 클래스는 처리하는 데 더 오래 걸릴 수도. 파일이나 URL 열기 등이 사용자 개시 클래스. 사용자가 체제랑 계속해서 상호작용하려면 반드시 이 클래스에 해당하는 작업이 완료되어야하지만, 그렇다고 사용자 상호작용적 클래스만큼 빠르게 서비스할 필요 없음.QOS_CLASS_UTILITY- 효용 utility 클래스란 완료에는 오랜 시간이 걸리지만 당장 결과가 필요하지는 않은 작업을 의미. 자료 불러오기 등이 있음.QOS_CLASS_BACKGROUND- 배경 background 클래스란 사용자에게 보이지 않으며 빠르게 처리할 필요 없는 작업. 백업 등이 있음.
파견 큐에 전달된 작업은 여러 방법으로 표현 가능:
- C, C++, Objective-C 언어에서는 GCD가 블록 block이라 부르는 언어 확장 기능 제공. 블록이란 단순히 격리된 일 단위. 블록은 중괄호 {} 앞에 캐럿 ^을 넣으면 됨. 중괄호 안의 코드가 수행할 일의 단위. 예시:
^{ printf("I am a block"); } - 스위프트의 경우 클로저 closure로 작업 정의. 격리된 기능의 단위라는 점에서 블록과 유사. 문법적으로는 블록과 유사하나 캐럿이 없음.
사용자 개시 클래스를 위한 동시 큐를 얻어dispatch_async()함수로 작업을 큐에 넘기는 코드:
let queue = dispatch_get_global_queue
(QOS_CLASS_USER_INITIATED, 0)
dispatch_async(queue, { print("I am a closure") })내부적으론 GCD의 스레드 풀은 POSIX 스레드로 구성. GCD는 스레드의 수를 어플리케이션의 요구, 시스템 용량에 따라 동적으로 관리함. GCD는 애플이 Apache Commons 라이선스 아래에 배포한 libdispatch 라이브러리로 구현. 후에 FreeBSD 운영체제에 포팅됨.
4.5.5. 인텔 스레드 빌딩 블록
인텔 스레딩 빌딩 블록(TBB)이란 C++로 병렬 어플리케이션 설계를 지원하는 템플릿 라이브러리. 따른 특별한 컴파일러나 언어 지원 필요 없음. 병렬로 실행할 작업을 명시해주면 TBB 작업 스케줄러가 이 작업들을 내부의 스레드에 매핑해줌. 이를 균형 잡히게 로드해주고 캐시도 고려해주어 캐시 메모리에 있는 자료가 있는 작업에 우선순위를 주어 빠르게 실행되도록 해줌. 병렬 반복 구조, 원자 연산, 상호배타 라킹 등의 템플릿과 같은 풍부한 기능 제공. C++ STL의 스레드 보안 자료 구조와 같은 해시맵, 큐, 벡터와 같은 동시 자료 구조 제공.
반복 병렬을 예시로. Apply(float value) 함수 있다고 가정. float 값 갖는 크기 n 의 배열 v 있을 때:
for (int i = 0; i < n; ++i)
{
Apply(v[i]);
}개발자가 직접 배열 v의 여러 영역을 나눠주어 다중코어 체제에서 자료 병렬을 적용할 수 있음. 근데 이건 실제 하드웨어의 영향을 받아 특정 구조의 프로세서 코어 개수마다 재컴파일을 해야 함.
대신 TBB를 통해 parallel_for 템플릿을 사용:
parallel_for(range body)
범위 range란 반복할 원소의 범위(반복 공간 iteration space이라고도 부름). 본체 body란 원소의 부분범위에서 수행할 연산을 의미.
위의 연속된 for문을 TBB의 parallel_for 템플릿으로 재작성:
parallel_for(size_t(0), n, [=](size_t i) { Apply(v[i]); });루프의 각 반복을 독립된 "청크"로 나누어 이 청크에서 수행할 작업들을 생성. (원한다면 parallel_for 함수에 직접 청크의 크기를 명시해줄 수 있음.) 또한 스레드 몇 개를 생성하고 사용 가능한 스레드에 작업 할당. 자바의 포트-합병과 유사. 이 방법의 장점은 개발자가 병렬로 실행할 연산이 무엇인지 식별 가능하며, 일을 여러 작업으로 나누는 세부 사항은 라이브러리가 알아서 관리해준다는 것. 인텔 TBB는 윈도우즈, 리눅스, macOS에서 도는 상용 버전과 오픈소스 버전 둘 다 있음.
4.6. 스레딩 문제
4.6.1. fork()와 exec() 시스템 호출
멀티스레딩 프로그램에서는 의미가 좀 달라짐.
어떤 프로그램의 한 스레드가 fork() 호출 시 새 프로세스가 모든 스레드를 복사? 아니면 새 프로세스는 그냥 단일 스레드? 그래서 몇몇 유닉스 체제는 두 가지 fork() 존재.
exec() 시스템 호출은 보통 3 단원에서 설명한 방법과 동일하게 작동. 스레드가 exec() 호출할 시 매개변수에 명시된 프로그램이 모든 스레드를 포함한 전체 프로세스를 대체함.
어떤 fork()를 사용할지는 어플리케이션에 달림. exec()이 포크 후 즉시 호출된다면 모든 스레드를 복사할 필요 없음. exec()에 명시된 애가 프로세스를 대체할 거니까. 그 반대라면 모든 스레드를 복사해야 함.
4.6.2. 신호 처리
유닉스 체제에서 신호 signal란 프로세스에게 특정 이벤트가 발생했음을 알리는 것. 신호의 출처와 이벤트가 신호를 낸 이유에 따라 동기 / 비동기일 수도. 모든 신호는 동일한 패턴 따름:
- 특정 이벤트 발생에 따라 신호 발생
- 프로세스에 신호 전달
- 전달 받을 시 반드시 신호를 처리해야 함
동기 신호의 예시로는 비허가 메모리 접근과 0으로의 나눗셈 등. 동기 신호는 신호를 일으킨 연산이 속한 프로세스에 전달(그래서 동기라 부름).
실행 중인 프로세스 외부의 이벤트에 의해 신호 생성될 경우 해당 프로세스는 비동기적으로 신호 수신. 특정 키 입력(ctrl+c 등) 혹은 시간 제한에 의해 프로세스 종료될 경우 등. 보통 비동기 신호는 다른 프로세스에 전달.
신호는 두 가지 처리자에 의해 처리 handle될 수도:
- 기본 신호 처리자
- 사용자 정의 신호 처리자
모든 신호는 해당 신호를 처리할 때 커널이 실행할 기본 신호 처리자 default signal handler를 가짐. 이걸 사용자 정의 신호 처리자 user-define signal handler로 대체 가능. 신호 무시할 수도, 어떤 신호로 프로그램 종료 시킬 수도.
단일 스레드 프로그램에서 신호 처리하는 건 간단. 언제나 프로세스에 전달됨. 멀티스레드에선 시놓가 어디로 가야함?
- 신호가 적용되는 스레드에 신호 전달
- 프로세스의 모든 스레드에 신호 전달
- 프로세스의 특정 스레드에 신호 전달
- 신호 수신 받을 특정 스레드 할당
신호 전달 방법은 생성된 신호의 유형에 따라 다름. 예를 들어 동기 신호의 경우 신호를 일으킨 스레드에 전달해야 함. 비동기의 경우 명확하지 않음. 프로세스 종료하는 신호의 경우 모든 스레드에 전달.
신호 전달하는 표준 유닉스 함수:
kill(pid_t pid, int signal)특정 신호(signal)를 보낼 프로세스(pid) 명시. 대부분의 멀티스레드 유닉스 버전에선 스레드가 어떤 신호를 받고, 어떤 신호를 막을지를 정할 수 있게 해줌. 가끔 그래서 비동기 신호를 막지 않은 스레드에만 전달됨. 신호가 반드시 한 번만 처리되어야 하므로 보통 막지 않은 첫 스레드에만 전달됨. POSIX Pthread는 다음 함수를 통해 특정 스레드(tid)에 신호 전달:
pthread_kill(pthread_t tid, int signal)윈도우즈는 명시적으로 신호를 지원하진 않으나 비동기 프로시저 호출 asynchronous procedure call(APC)를 통해 에뮬레이트. APC 기능을 통해 사용자 스레드 특정 이벤트에 대한 노티 받으면 무슨 함수를 호출할지 명시해주게 해줌. 이름에서도 알 수 있듯 유닉스의 비동기 신호와 유사함. 유닉스는 반드시 멀티스레딩 환경에서 어떻게 신호를 처리할지를 처리해야하지만 APC 기능은 좀 더 단순함. 애초에 프로세스가 아니라 스레드에 전달됨.
4.6.3. 스레드 취소
스레드 취소 thread cancellatino란 완료 직전에 스레드를 종료시키는 것.
취소할 스레드를 목표 스레드 target thread라 부름. 목표 스레드를 취소하면 둘 중 한 가지 발생:
- 비동기 취소 asynchronous cancellation. 한 스레드가 즉시 목표 스레드를 종료시킴.
- 거치 취소 deferred cancellation. 목표 스레드가 정기적으로 종료해야하는지 여부를 확인하여 순서대로 취소할 수 있는 기회를 줌.
취소된 스레드에서 자원을 할당했거나 다른 스레드와 공유하는 자료를 갱신하는 도중에 취소가 되었을 때 문제가 발생. 특히 비동기 취소에서 더 큰 문제. 보통 운영체제가 취소된 스레드로부터 시스템 자원을 되찾지만, 모든 자원을 전부 되찾지는 않음.
거치 취소는 반대로 목표 스레드가 취소해야하는지 여부를 결정하는 플래그를 확인했을 때 취소가 가능. 이 확인을 안전하게 취소될 수 있는 순간에 수행할 수 있음.
Pthread에서 스레드 취소는 pthread_cancel() 함수. 매개변수로 목표 스레드 식별자 전달:
pthread_t tid;
/* 스레드 생성 */
pthread_create(&tid, 0, worker, NULL);
...
/* 스레드 취소 */
pthread_cancel(tid);
/* 스레드 종료될 때까지 대기 */
pthread_join(tid, NULL);pthread_cancel()은 단순히 목표 스레드를 취소해달라는 요청일 뿐임. 목표 스레드가 요청을 어떻게 처리하느냐에 따라 실제 취소가 어떻게 될지가 결정됨. Pthread는 세 가지 취소 모드 지원. 각 모드는 상태와 유형으로 정의됨. 스레드는 취소 상태와 유형을 API로 설정 가능.
| 모드 | 상태 | 유형 |
|---|---|---|
| 오프 | 비활성 | - |
| 거치 | 활성 | 거치 |
| 비동기 | 활성 | 비동기 |
위에서 보듯 Pthread의 스레드는 취소를 활성화/비활성화 가능. 비활성화했더라도 취소 요청이 사라지지는 않으므로 나중에 취소 활성화되면 해당 요청에 응답할 수 있음.
기본 취소 유형은 거치 취소. 허나 취소 자체는 스레드가 취소점 cancellation point에 도달했을 때 발생. POSIX와 표준 C 라이브러리에서 막는 시스템 호출 대부분이 취소점으로 정의되어있으며 리눅스 체제에서 man pthreads 명령어 호출하면 그 목록을 볼 수 있음. 예를 들어 read() 시스템 호출의 경우 read()로부터 입력을 기다리는 동안 막혀있던 스레드를 취소하도록하는 취소점임.
취소점을 설정하는 한 방법으로는 pthread_testcancel() 함수. 취소 요청이 존재할 경우 pthread_testcancel()은 반환하지 않고 스레드를 종료. 아니라면 반환을 하고 스레드는 계속해서 실행될 것. 추가적으로 Pthread는 스레드가 취소되면 정리 핸들러 cleanup handler를 호출함. 스레드가 얻은 모든 자원을 종료 직전 해제해줌.
거치 취소를 사용할 때 취소 요청에 반응하는 예시:
while (1) {
/* 작업 중 */
...
/* 취소 요청이 왔는지 확인 */
pthread_testcancel();
}이전에 언급한 문제 때문에 Pthread에서는 비동기 취소를 추천하지 않기에 다루지 않음. 리눅스 체제에서는 Pthread API를 통한 스레드 취소가 신호로 처리됨.
자바에서 스레드 취소는 Pthread의 거치 취소와 유사한 정책을 사용. 자바 스레드 취소하려면 interrupt() 메서드 호출해서 목표 스레드의 인터럽션 상태를 참으로 설정:
Thread worker;
...
/* 스레드의 인터럽션 상태를 설정 */
worker.interrupt();불리언 값을 반환하는 isInterrupt() 메서드로 인터럽션 상태를 확인 가능:
while (!Thread.currentThread().isInterrupted()) {
...
}4.6.4. 스레드-지역 저장소
프로세스의 스레드는 프로세스의 자료를 공유함. 허나 각 스레드가 특정 자료에 대한 복사본을 가져야할 수도. 이런 자료를 스레드-지역 저장소 thread-local storage(혹은 TLS)라 부름.
지역 변수와 이름이 헷갈릴 수도 있으나, 지역 변수는 함수 호출할 때 가시적인데 비해 TLS 자료는 함수 호출 전체에서 가시적임. 게다가 개발자가 스레드 생성에 아무런 제어가 없을 경우(스레드 풀과 같은 암시적 기술 등) 다른 방법이 필요함.
TLS는 어느 면에서 보면 static 자료와 유사. 차이점이 있다면 TLS 자료는 각 스레드에 대해 고유하다는 것. (사실 TLS는 보통 static로 선언함.) 대부분의 라이브러리와 컴파일러는 TLS 기능 지원함. 자바의 경우 ThreadLocal<T> 클래스에 set()과 get() 메서드 제공. Pthread의 경우 pthread_key_t 형으로 각 스레드에 특정한 키를 제공하여 TLS 자료 접근. 마이크로소프트의 C# 언어는 단순히 [ThreadStatic] 저장소 속성을 추가해주어 스레드-지역 자료 선언 가능. gcc 컴파일러의 경우 __thread 저장소 클래스 키워드 제공하여 TLS 자료 선언:
static __thread int threadID;4.6.5. 스케줄러 활성
마지막 문제로는 커널과 스레드 라이브러리 간의 통신이 있음. 이건 다대다나 2단계 모델에서 필요함. 이를 통해 최적의 성능을 위해 커널 스레드의 개수를 동적으로 조절할 수 있음.
다대다나 2단계 모델을 구현한 수많은 체제에서는 사용자와 커널 스레드 사이에 중간 자료 구조를 넣음. 보통 경량 프로세스 lightweight process 혹은 LWP라 부르는 자료 구조임. 사용자 스레드 라이브러리에서 LWP는 마치 어플리케이션이 사용자 스레드를 실행하다록 스케줄링할 수 있는 가상 프로세서처럼 보임. 각 LWP는 운영체제가 실제 프로세서에 실행하도록 스케줄링하는 커널 스레드에 연결됨. 커널 스레드가 막을 경우(입출력 연산이 완료될 때까지 대기하고 있다든가) LWP도 막음. 그럼 위로 올라가서 LWP에 달려있는 사용자 수준 스레드도 막음.
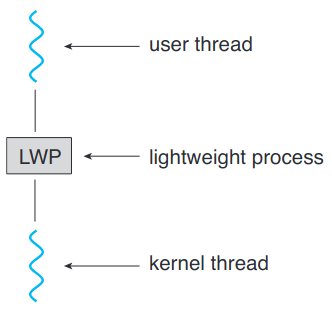
어플리케이션이 효율성을 위해 임의의 개수만큼의 LWP를 필요로 할 수도. 단일 프로세서에서 돌고 있는 CPU 제약 프로세스의 경우 스레드가 하나 밖에 돌 수 없으니 LWP도 한 개면 됨. 입출력 쪽 부담이 큰 어플리케이션의 경우 여러 LWP를 실행해야할 수도. 보통은 동시 막기 시스템 호출마다 필요함. 만약 LWP가 네 개인데 다섯번째 요청이 온다면 LWP 중 하나가 커널로부터 반환받을 때까지 대기.
사용자 스레드 라이브러리와 커널 간 통신 방법 중 하나가 스케줄러 활성 scheduler activation. 다음과 같이 작동: 커널이 어플리케이션에게 몇 개의 가상 프로세서(LWP) 제공하고 사용자 스레드를 이 가상 프로세서에 대해 스케줄링. 커널은 어플리케이션에게 특정 이벤트에 대해 노티를 줘야함. 이 프로시저를 업콜 upcall이라 부름. 업콜은 업콜 핸들러 upcall handler를 가진 스레드 라이브러리에 의해 처리하며, 가상 프로세서에서 반드시 실행되어야 함.
업콜이 발생하는 경우 중 하나는 어플리케이션 스레드가 막으려고 할 때. 이 경우 커널이 어플리케이션에 업콜을 보내 막으려는 스레드가 있으며, 해당 스레드가 무엇인지 알려줌. 그러면 커널은 어플리케이션에 새로운 가상 프로세서를 할당해줌. 어플리케이션은 새 가상 프로세서에 업콜 핸들러 실행하여 막는 스레드의 상태 저장하고 막는 스레드의 가상 프로세서의 소유권을 포기함. 업콜 핸들러는 이후에 새 가상 프로세서에 실행 가능한 또다른 스레드를 스케줄링함. 막는 스레드가 기다리던 이벤트가 발생할 경우 커널이 스레드 라이브러리에게 기존에 막던 스레드가 이제 실행 가능함을 알리는 업콜을 보냄. 이 이벤트를 받을 경우 업콜 핸들러는 또다시 가상 프로세서를 필요로 하기에 새 가상 프로세서를 할당하거나 사용자 스레드 중 하나를 획득하여 그 가상 프로세서의 업콜 핸들러 실행. 더 이상 막지 않는 스레드가 실행 가능함이라 표기한 이후 어플리케이션은 실행 가능한 스레드를 사용 가능한 가상 프로세서에서 실행되도록 스케줄링.
4.7. 운영체제 예시
4.7.1. 윈도우즈 스레드
윈도우즈 어플리케이션은 독립 프로세스로 돌며 각 프로세스는 하나 이상의 스레드 가질 수 있음.
스레드의 일반적인 성분:
- 스레드 식별용 고유한 스레드 ID
- 프로세서의 상태를 의미하는 레지스터 집합
- 프로그램 카운터
- 스레드가 사용자 모드에 실행 중일 때의 사용자 스택과 커널 모드에 실행 중일 때의 커널 스택
- 여러 실시간 라이브러리와 동적 링크 라이브러리가 사용하는 전용 저장소 영역
레지스터 집합, 스택, 전용 저장소 영역을 스레드의 문맥 context이라 부름.
스레드의 주요 자료 구조:
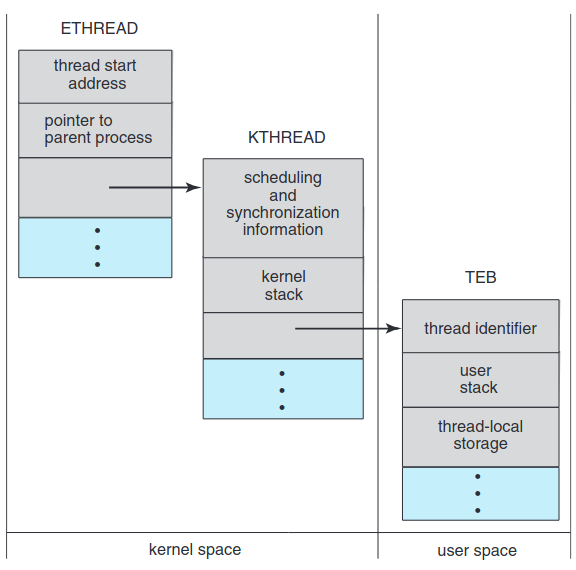
ETHREAD- 실행 스레드 블록KTHREAD- 커널 스레드 블록TEB- 스레드 환경 블록
ETHREAD의 핵심 성분은 스레드가 속한 프로세스를 가리키는 포인터와 스레드가 제어를 시작할 루틴의 주소. 자신에게 대응하는 KTHREAD에 해당하는 포인터도 가짐.
KTHREAD는 스레드의 스케줄링 및 동기화 정보, 커널 스택(스레드가 커널 모드에 돌 때)과 TEBㄹ을 가리키는 포인터 가짐.
ETHREAD와 KTHREAD는 전부 커널 공간에 존재. 즉, 커널만 접근 가능. TEB는 사용자 공간 자료 구조로, 스레드가 사용자 모드에 실행 중일 때 접근 가능. TEB는 스레드 식별자, 사용자 모드 스택, 스레드 지역 저장소 배열 포함.
4.7.2. 리눅스 스레드
3 단원에서 다뤘던 fork() 시스템 호출과 프로세스 복제용 전통적인 기능들 등 제공. clone() 시스템 호출과 같은 스레드 생성 기능도 제공. 프로세스와 스레드를 사실 구분하지 않으며, 프로그램의 흐름 제어를 논할 때 프로세스나 스레드 대신 작업이라는 표현 사용.
clone() 호출 시 부모와 자식 작업 간 어느 정도로 공유할지를 결정할 플래그를 전달. 이는 이 단원에서 언급한 스레드 생성 방법과 동일. 부모 작업이 대부분의 자원을 자식과 공유하니까. 허나 clone() 호출 때 아무 플래그도 세우지 않을 시 fork() 시스템 호출과 유사하게 작동.
| 플래그 | 의미 |
|---|---|
CLONE_FS | 파일 체제 정보 공유 |
CLONE_VM | 같은 메모리 공간 공유 |
CLONE_SIGHAND | 신호 핸들러 공유 |
CLONE_FILES | 열린 파일들 공유 |
리눅스 커널에서 작업의 의미 때문에 다양한 공유 방법이 가능. 고유한 커널 자료 구조(즉, struct task_struct)가 시스템의 각 작업마다 존재. 이 자료 구조는 작업을 위해 자료를 저장하기보다는 자료가 저장된 다른 자료구조에 대한 포인터를 갖고 있음. fork() 호출 시 새 작업이 생성될 때 부모 프로세스의 구조체의 자료를 복사 copy함. clone()의 경우 전달 받은 플래그에 따라 복사가 아닌 새 작업이 부모 작업의 자료구조를 가리킴 point.
clone() 시스템 호출의 유연성을 컨테이너 개념으로 확장 가능함. 1 단원에서 소개했던 가상화 개념임. 컨테이너란 여러 리눅스 시스템(컨테이너)를 한 리눅스 커널에서 서로 독립적으로 돌 수 있게 해준 가상화 기능임. clone()에 전달한 플래그가 프로세스나 스레드 기반 작업 생성 여부를 부모와 자식 간의 공유의 정도로 구분할 수 있듯이 리눅스 컨테이너를 생성할 수 있는 플래그를 clone()에 전달해줄 수 있음.
4.8. 요약
- 스레드는 CPU 활용의 기본 단위. 같은 프로세스 내의 스레드는 코드와 자료 등의 많은 프로세스 자원을 공유.
- 멀티스레드 어플리케이션의 네 가지 장점: (1) 반응성, (2) 자원 공유, (3) 경제성, (4) 확장성.
- 여러 스레드가 진행 중이면 동시성, 여러 스레드가 동시에 진행 중이면 병렬성. CPU 하나면 동시성만 가능하고 여러 CPU가 있는 다중 코어 체제에서만 병렬 가능.
- 멀티스레드 어플리케이션 설계에서 고려할 문제들: 일의 분할과 균형 잡기, 스레드 간 자료 분할하는 법, 자료 의존성 파악하기, 테스트 및 디버깅에 특히 어려움.
- 자료 병렬은 같은 자료의 부분집합을 서로 다른 연산 코어에 분산하여 코어마다 같은 연산 수행. 작업 병렬은 자료가 아닌 작업을 다중 코어에 분산. 각 작업은 고유한 연산 실행.
- 사용자 어플리케이션은 사용자 수준 스레드 생성하고, 궁극적으로 CPU에서 실행될 커널 스레드에 매핑. 다매일 모델은 여러 사용자 수준 스레드를 하나의 커널 스레드에 매핑. 일대일, 다대다 모델도 존재.
- 스레드 라이브러리는 스레드 생성 및 관리에 대한 API 제공. 세 가지 일반적인 스레드 라이브러리로는 윈도우즈, Pthread, 자바 스레딩이 있음. 윈도우즈는 윈도우즈 체제에서만, Pthread는 유닉스, 리눅스, macOS와 같은 POSIX와 호환 가능한 체제에서 사용 가능. 자바 스레드는 자바 가상 머신 지원하는 모든 체제에서 실행 가능.
- 암시적 스레딩은 스레드가 아닌 작업을 식별하고 언어나 API 프레임워크가 스레드를 생성 및 관리하도록 하는 것. 스레드 풀, 포크-합병 프레임워크, 그랜드 센트럴 디스패치와 같은 방법 존재. 암시적 스레딩은 동시 및 병렬 어플리케이션 개발하는 프로그래머들에게 흔한 기술이 되어가고 있음.
- 스레드는 비동기 혹은 거치 취소로 종료될 수 있음. 비동기 취소는 스레드가 갱신 중이더라도 즉시 취소. 거치 취소는 취소해야한다고 알리기는 하지만 순서에 따라 취소될 수 있게 해줌. 대부분의 경우 거치 취소가 비동기보다 더 선호되는 경향.
- 다른 운영체제와는 달리 리눅스는 프로세스와 스레드 구분하지 않고 작업이라고 총칭. 리눅스의
clone()시스템 호출을 통해 프로세스와 더 유사하게, 혹은 스레드와 더 유사하게 행동하는 작업을 생성.
