- SQL(Structured Query Language) : 데이터베이스 시스템에서 자료를 처리하는 용도로 사용되는 구조적 데이터 질의 언어. 데이터베이스에 요청(Query)을 날려서 원하는 데이터를 가져오는 것을 도와주는 언어.
- 데이터베이스(db=database) : 여러 사람들이 같이 사용할 목적으로 데이터를 담는 통. 어느 한 조직의 여러 응용 프로그램들이 공유하는 관련 데이터들의 모임. 서로 관련성을 가지며 중복이 없는 데이터의 집합.
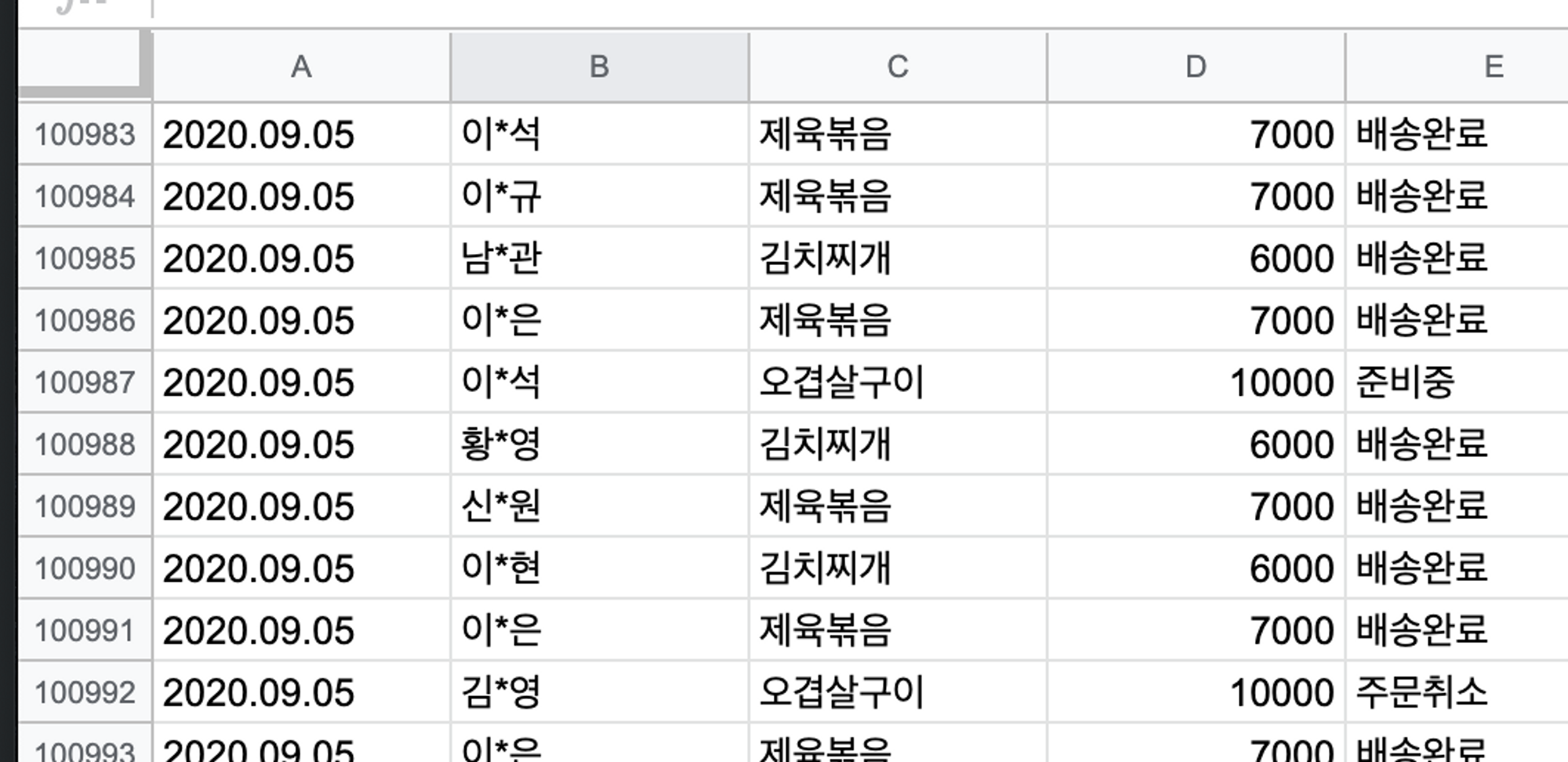
- db ex1) 고객 주문 내역을 엑셀로 정리할 경우 필요한 정보를 찾는데 시간이 걸린다는 점, 데이터가 많아지면 처리도 느려진다는 점 등 비효율적임
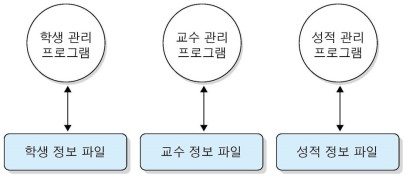
- db ex2) 한 대학에서 학생 관리 프로그램, 교수 관리 프로그램, 성적 관리 프로그램의 3개의 응용 프로그램을 갖추고 있다고 하자. 각각의 응용 프로그램들은 개별적인 파일을 이용한다. 이런 경우의 파일에는 많은 정보가 중복 저장되어 있다. 그렇기 때문에 중복된 정보가 수정되면 관련된 모든 파일을 수정해야 하는 불편함이 있다. 예를 들어, 한 학생이 자퇴하게 되면 학생 정보 파일뿐만 아니라 교수 정보 파일, 성적 정보 파일도 수정해야 한다.
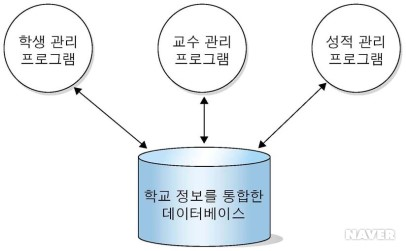
이런 문제점을 해결하기 위해 나온 개념이 데이터베이스이다. 엄청나게 많은 양의 데이터를 효과적으로 저장할 수 있고, 수정/사용하기 위한 데이터를 신속하게 찾을 수 있다.
[네이버 지식백과] 데이터베이스 (컴퓨터 개론, 2013. 3. 10., 김종훈, 김종진)
-
데이터베이스 기능
C (Create): 데이터의 생성
R (Read): 저장된 데이터를 읽어오는 것
U (Update): 저장된 데이터를 변경
D (Delete): 저장된 데이터를 삭제 -
SQL의 기능
데이터를 읽어오는 과정인 "R (Read)"를 엄청나게 편하게 만들어줌. 그리고, 데이터를 손쉽고 깔끔하게 정리/분석하는 기능도 지원.
쿼리(Query)문
쿼리(Query) : 질의. 데이터베이스에 명령을 내리는 것.
Select 쿼리문
Select 쿼리문 : 데이터베이스에서 '데이터를 선택해서 가져오겠다'는 의미
1. 어떤 테이블에서
테이블은 데이터를 구조화하고 저장하는 데이터베이스의 기본 단위. 테이블은 행(row)과 열(column)로 구성되며, 각 열은 특정한 데이터 유형과 속성을 가지는 필드(Field)를 나타낸다. 테이블은 데이터베이스 내에서 고유한 이름을 가지며, 데이터를 효율적으로 관리하기 위해 사용된다.
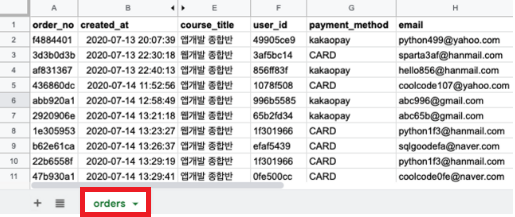
이런 형태의 값이 데이터베이스에 담기면, orders라는 이름의 테이블이 됨.
2. 어떤 필드의 데이터를 가져올지
필드는 테이블의 열(Column)로서, 테이블 내에서 특정한 유형의 데이터를 저장하는 데 사용된다. 필드는 데이터베이스의 스키마에 따라 데이터의 형식과 속성을 정의한다. 각 필드는 데이터베이스 내에서 고유한 이름을 가지며, 해당 열이 저장하는 데이터의 의미를 나타낸다.
- 스키마
스키마는 데이터베이스 내의 테이블, 필드, 제약 조건 등을 포함한 모든 객체들의 논리적인 설계와 구조. 즉, 스키마는 데이터베이스의 '계획서'
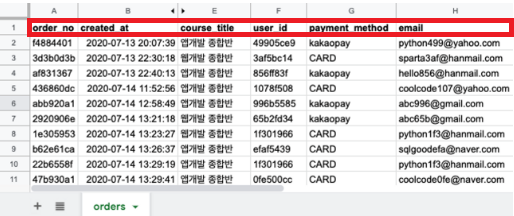
SQL 쿼리문을 사용하여 테이블과 필드를 생성하고 관리할 수 있으며, 이를 통해 데이터베이스 내에서 구조화된 데이터를 저장하고 검색할 수 있다. (예시. orders 테이블의 created_at, course_title, payment_method, email 필드를 가져와줘)
Select 쿼리문 연습
1. 데이터베이스의 테이블 보기 (스파르타 데이터베이스)
show tables;SQL문 실행 : Ctrl + Enter
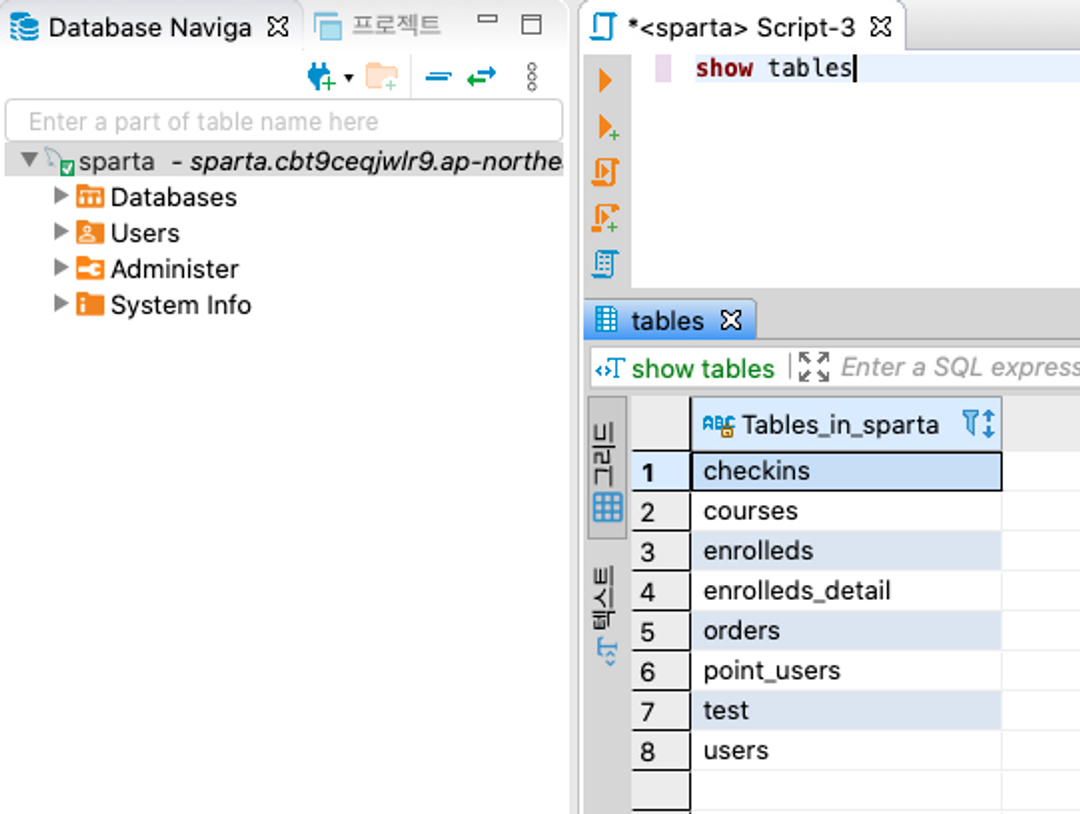
2. 테이블의 데이터 가져와보기 (orders 테이블)
select * from orders; // *은 모든 필드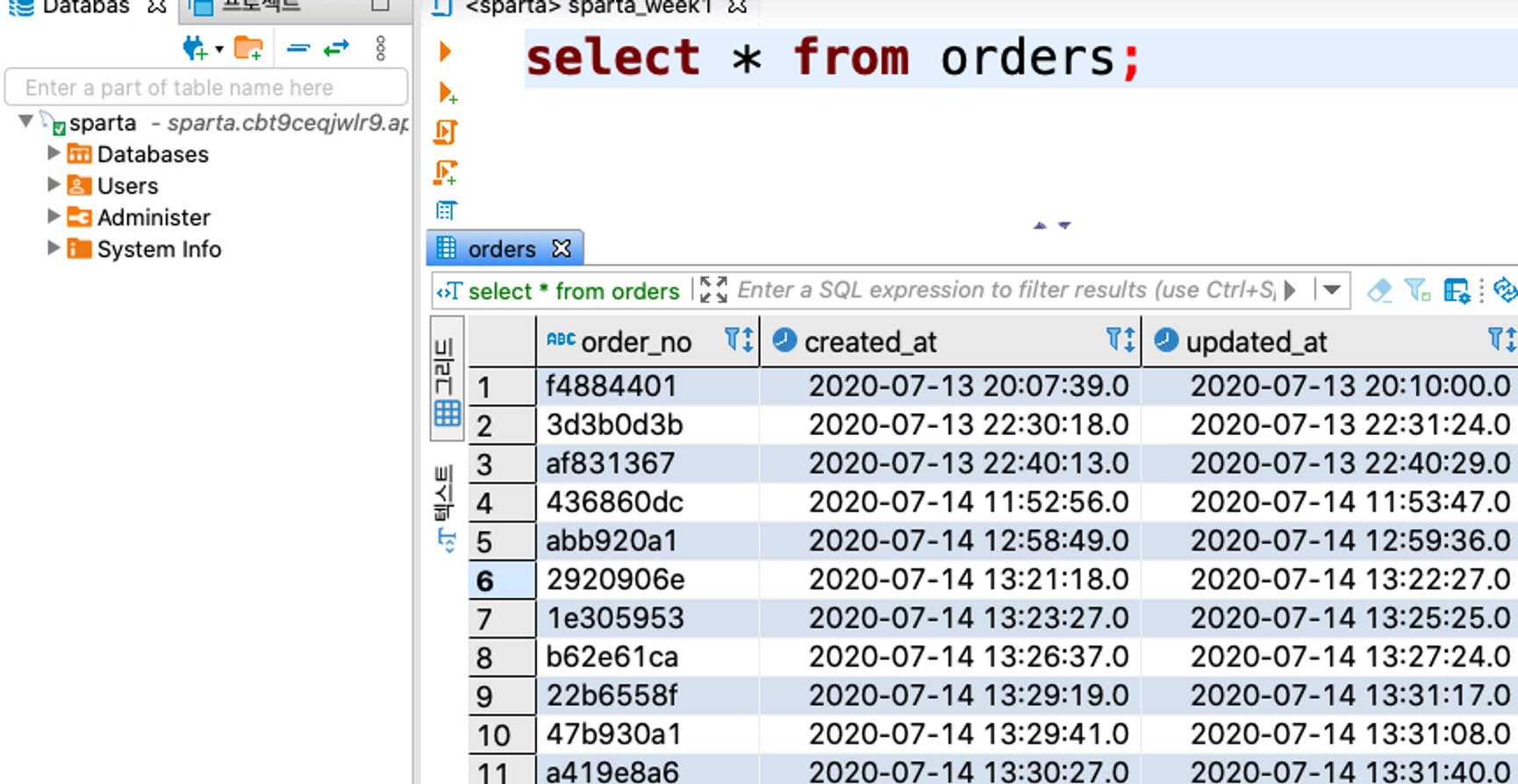
3. 테이블의 특정 필드만 가져와보기 (orders 테이블)
select created_at, course_title, payment_method, email from orders; 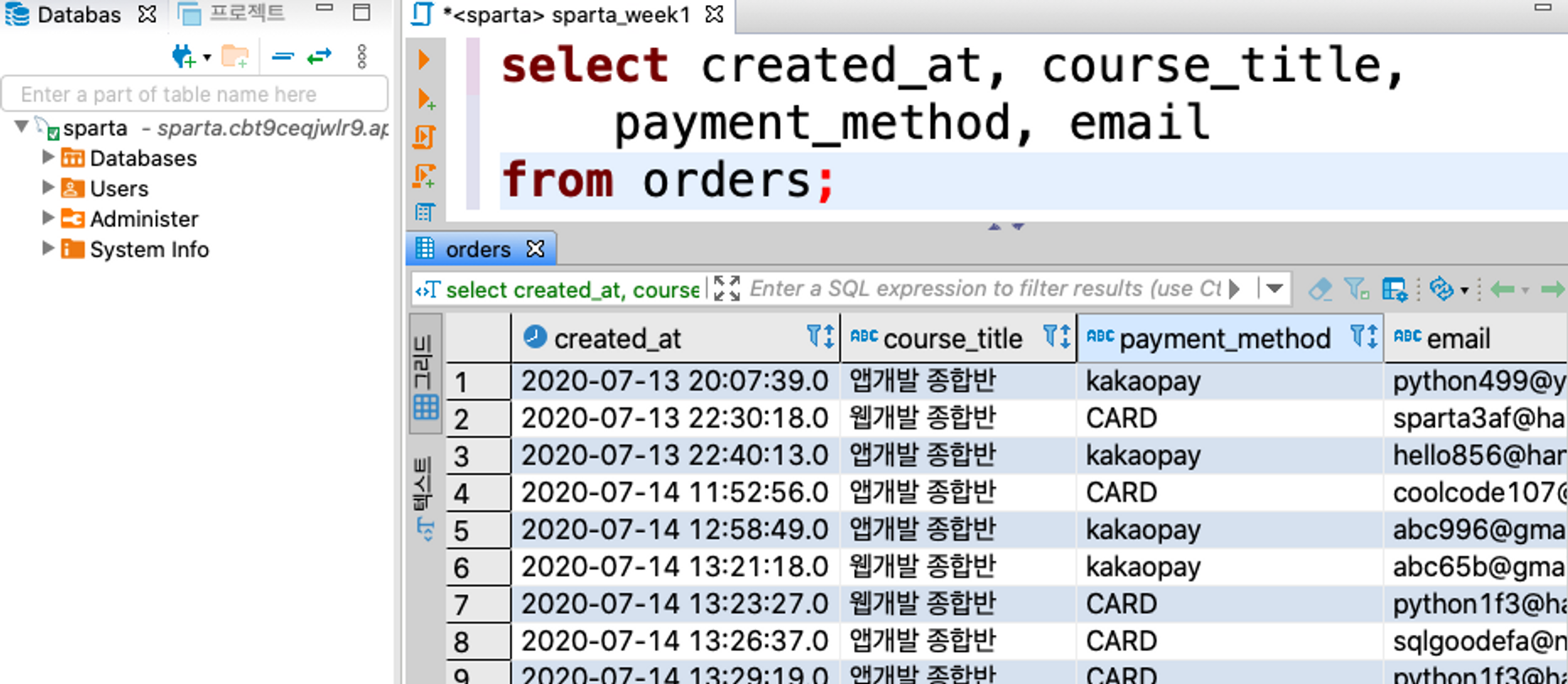
Select 쿼리문 : Where 절
Where 절 : Select 쿼리문으로 가져올 데이터에 조건을 걸어주는 것을 의미
ex1) orders 테이블에서 결제수단이 카카오페이인 데이터만 가져와줘!
select * from orders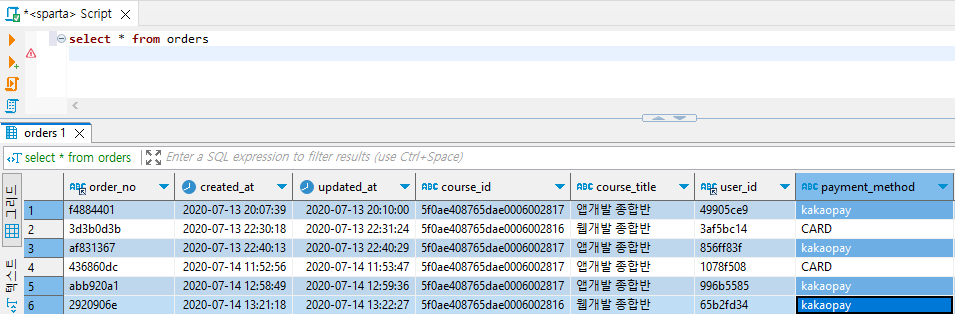
select * from orders where payment_method = 'kakaopay'
// 'kakaopay'에 따옴표가 없으면 문자열이 아니라는 뜻으로 테이블명이나 필드명으로 인식하고 오류가 날 수도 있다.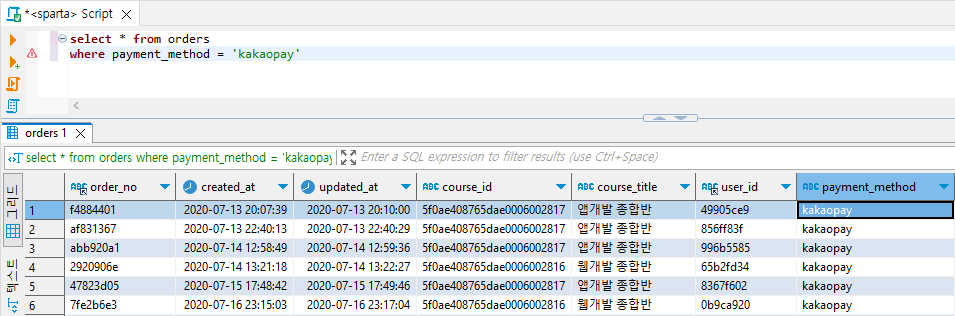
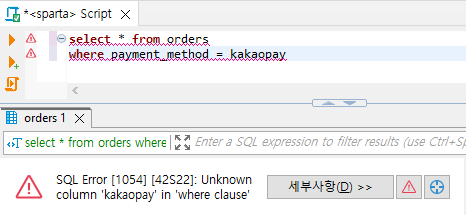
Where 절에 있는 kakaopay라는 컬럼은 없다는 뜻. 여기서 컬럼은 필드. kakaopay에 따옴표가 없으니 글자를 컬럼(필드명)으로 인식함.
ex2) point_users 테이블에서 포인트가 5000점 이상인 데이터만 가져와줘!
select * from point_users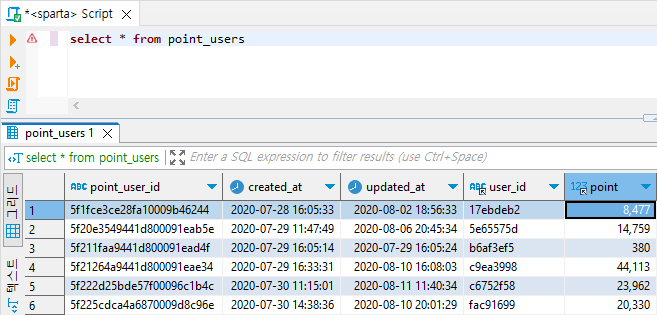
select * from point_users
where point >= 5000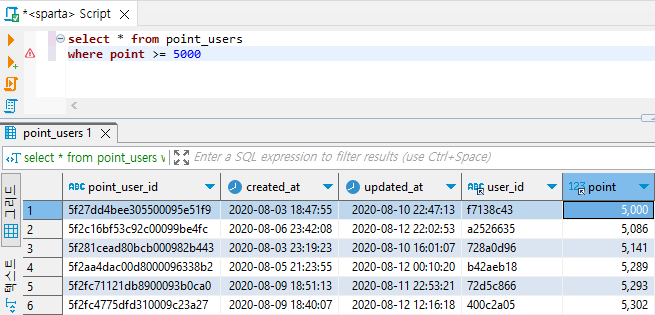
ex3) orders 테이블에서 주문한 강의가 웹개발 종합반이면서, 결제수단이 카드인 데이터만 가져와줘!
select * from orders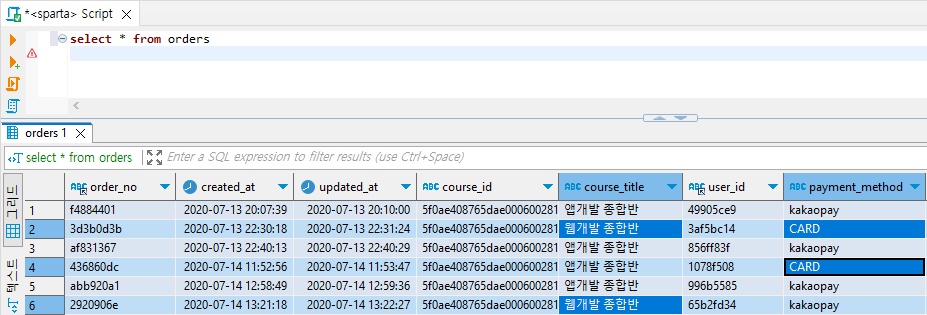
select * from orders
where course_title = '웹개발 종합반'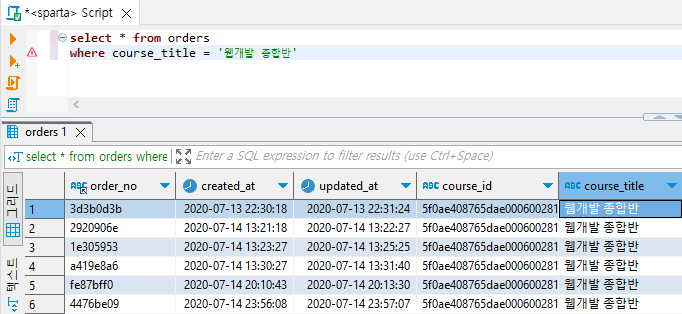
select * from orders
where course_title = '웹개발 종합반' and payment_method = 'CARD'
// 여러 조건을 걸어주기 위해서는 and 를 넣어서 원하는 조건을 계속 추가해주면 된다.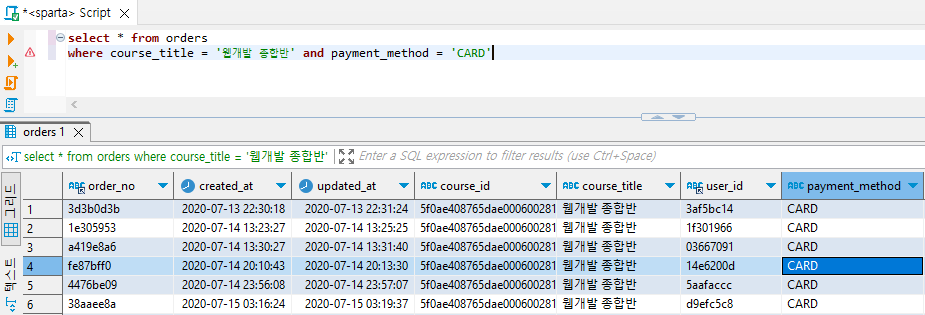
ex4) 포인트가 20000점보다 많은 유저만 뽑아보기
select * from point_users
where point > 20000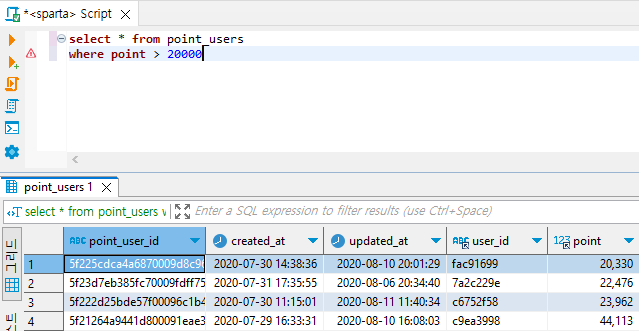
ex5) 성이 황씨인 유저만 뽑아보기
select * from users
where name = '황**'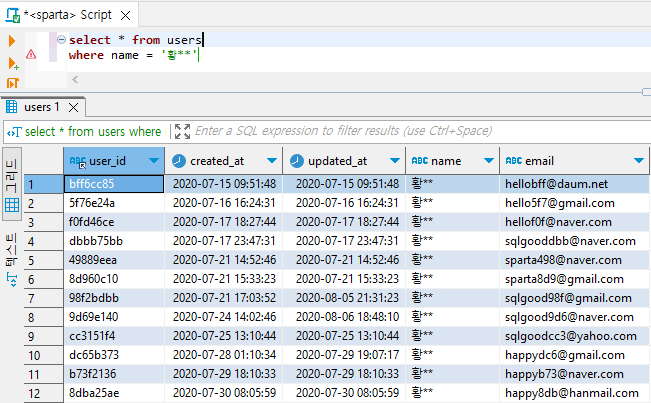
[쿼리 작성 꿀팁🍯]
1. show tables로 어떤 테이블이 있는지 살펴보기
2. 제일 원하는 정보가 있을 것 같은 테이블에 select from 테이블명 쿼리 날려보기
3. 원하는 정보가 없으면 다른 테이블에도 2)를 해보기
4. 테이블을 찾았다! 조건을 걸 필드를 찾기
5. select from 테이블명 where 조건 이렇게 쿼리 완성!
Where 절과 자주 같이쓰는 문법
1. '같지 않음' 조건 (!=)
ex) '웹개발 종합반'을 제외한 주문데이터
select * from orders
where course_title != "웹개발 종합반";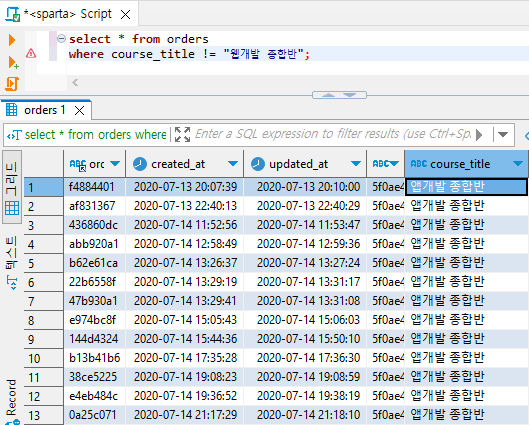
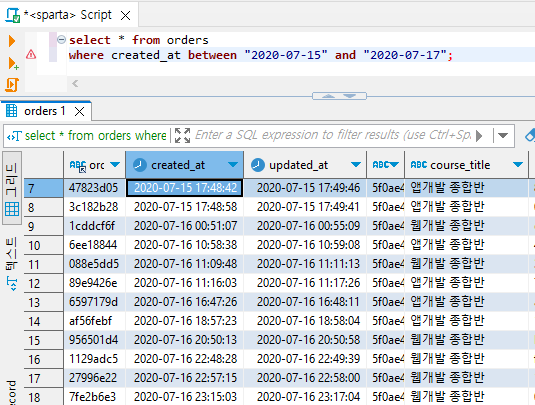
2. '범위' 조건 (between)
ex) 7월 15일, 7월 16일(7월 17일 전까지)의 주문데이터
select * from orders
where created_at between "2020-07-15" and "2020-07-17";
3. 포함' 조건 (in)
ex) 1, 3주차 사람들의 '오늘의 다짐' 데이터
select * from checkins
where week in (1, 3);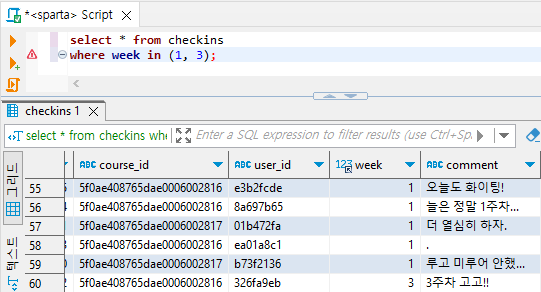
4. '패턴' (문자열 규칙) 조건 (like)
ex) 다음 (daum) 이메일을 사용하는 유저
select * from users
where email like '%daum.net';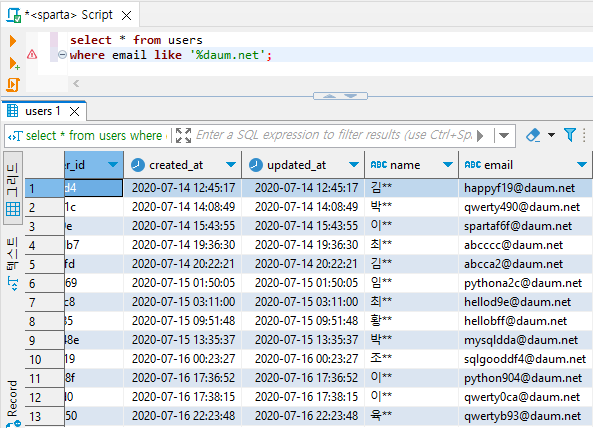
[꿀팁🍯] Like의 다양한 사용법
4-1. email 필드값이 a로 시작하는 모든 데이터
select * from users where email like 'a%':4-2. email 필드값이 a로 끝나는 모든 데이터
select * from users where email like '%a'4-3. email 필드값에 co를 포함하는 모든 데이터
select * from users where email like '%co%'4-4. email 필드값이 a로 시작하고 o로 끝나는 모든 데이터
select * from users where email like 'a%o'
5. 일부 데이터만 가져오기 (Limit)
테이블에 어떤 데이터가 들어있나 잠깐 보려고 할 때 일부 데이터만 가져오는 기능
select * from orders
where payment_method = "kakaopay"
limit 5; // 맨 뒤에 limit을 써주고 몇 개 출력할지 숫자를 적어주면 끝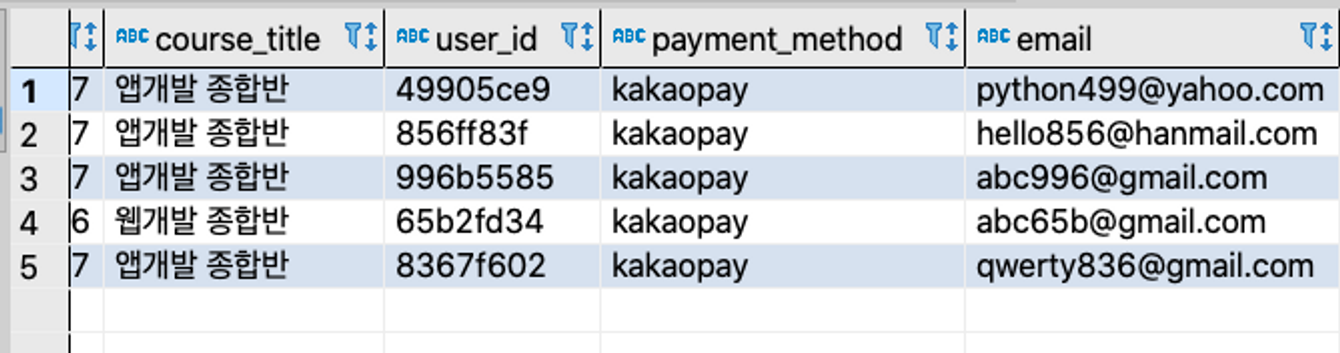
6. 중복 데이터는 제외하고 가져오기 (Distinct)
- 결제 수단 종류만 궁금할 때
select distinct(payment_method) from orders;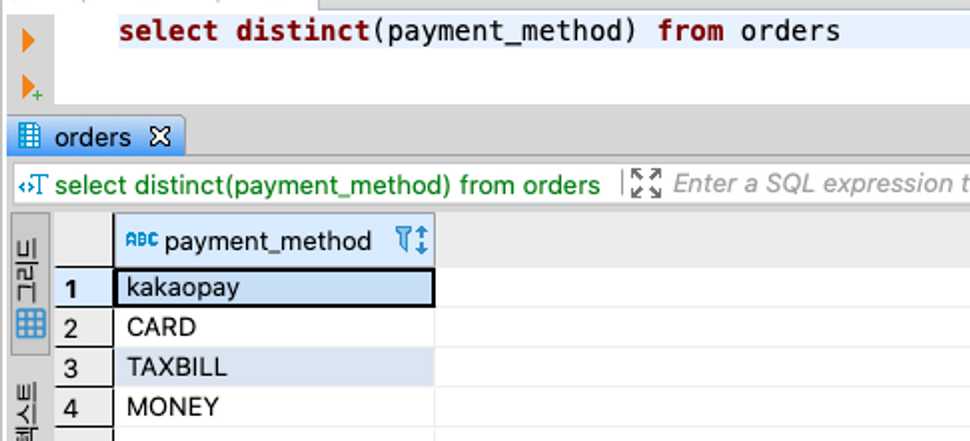
7. 몇 개인지 숫자 세보기 (Count)
- 결제가 총 몇 건인지 궁금할 때
select count(*) from orders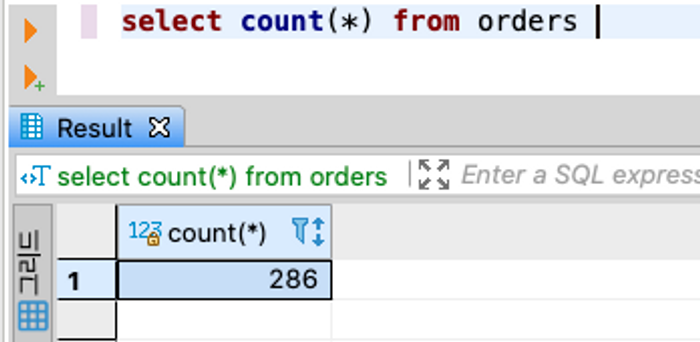
6,7 응용 예제 1) 스파르타 회원 분들의 성(family name)이 몇 개인지
SELECT count(distinct(name)) from users;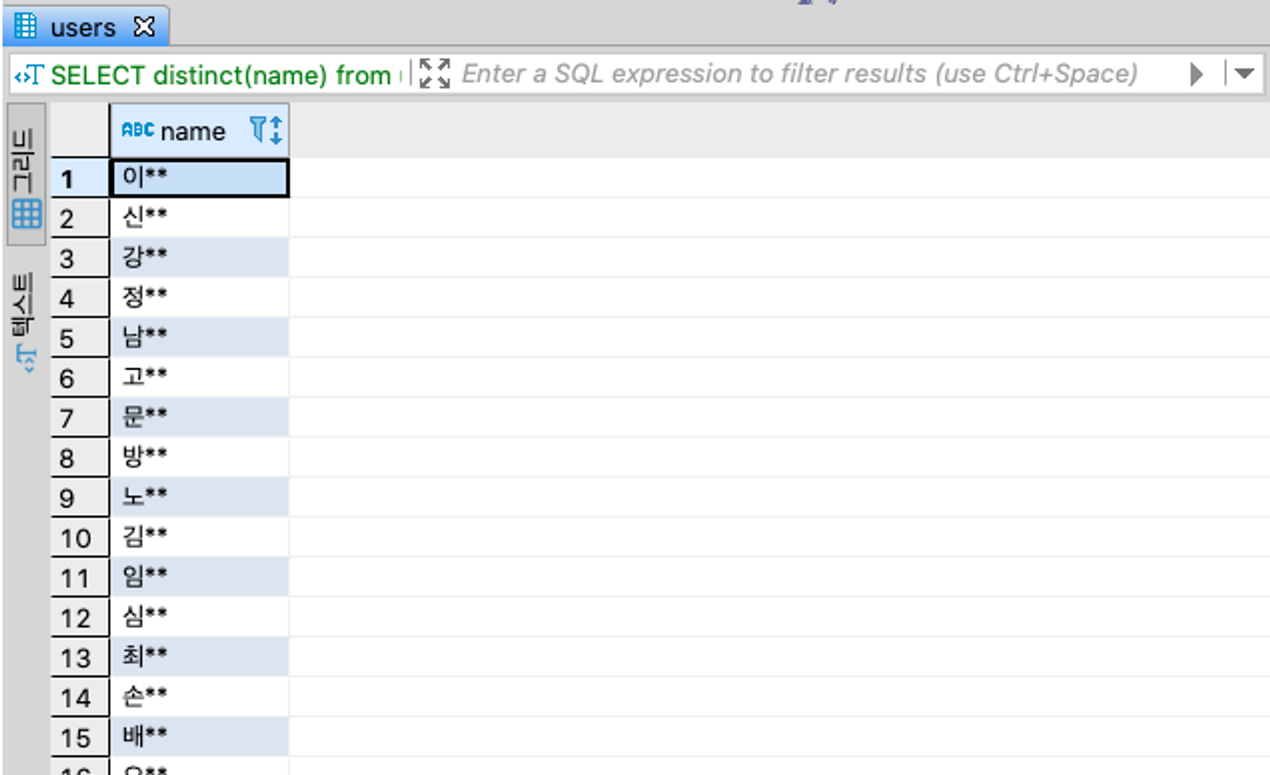
6,7 응용 예제 2) 음식 주문이 있었던 식당이 몇 곳인지
select count(distinct(restaurant_name)) from food_orders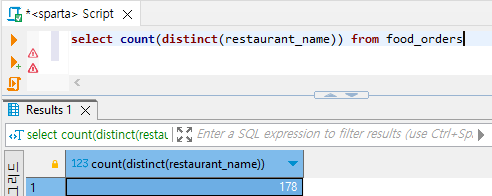
ex1) 결제수단이 CARD가 아닌 주문데이터만 추출
select * from orders
where payment_method != 'card'ex2) 20000~30000 포인트 보유하고 있는 유저만 추출
select * from point_users
where point between '20000' and '30000'ex3) 이메일이 s로 시작하고 com로 끝나는 유저만 추출
select * from users
where email like 's%com'
ex4) 이메일이 s로 시작하고 com로 끝나면서 성이 이씨인 유저만 추출
select * from users
where email like 's%com' and name = '이**'ex5) 성이 남씨인 유저의 이메일만 추출
select email from users
where name="남**"ex6) Gmail을 사용하는 2020/07/12~13에 가입한 유저를 추출
select * from users
where created_at between "2020-07-12" and "2020-07-14"
and email like "%gmail.com";ex7) Gmail을 사용하는 2020/07/12~13에 가입한 유저의 수
select count(*) from users
where created_at between "2020-07-12" and "2020-07-14"
and email like "%gmail.com";ex8) naver 이메일을 사용하면서, 웹개발 종합반을 신청했고 결제는 kakaopay로 이뤄진 주문데이터
where payment_method = 'kakaopay'
and course_title ='웹개발 종합반'
and email like '%naver.com'에러
에러 메시지 해석해보기 1)
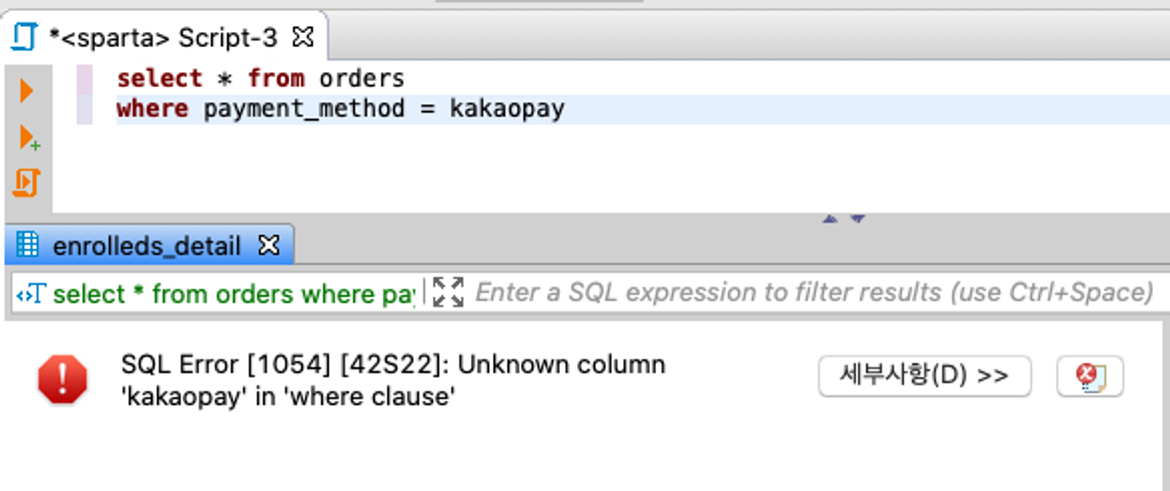
→ kakaopay라는 글자가 '컬럼(필드)' 이름으로 인식되어서 발생한 에러
→ Where 절에는 kakaopay라는 컬럼(필드)가 없음.
select * from orders
where payment_method = "kakaopay"→ 글자를 ''로 감싸면 변수가 아닌, 문자열(값)로 인식하겠다는 의미
→ 결제수단이 kakaopay라는 값을 가진 데이터만 불러오기 위해서는, kakaopay를 문자열(값)으로 지정해줘야함.
에러 메시지 해석해보기 2)
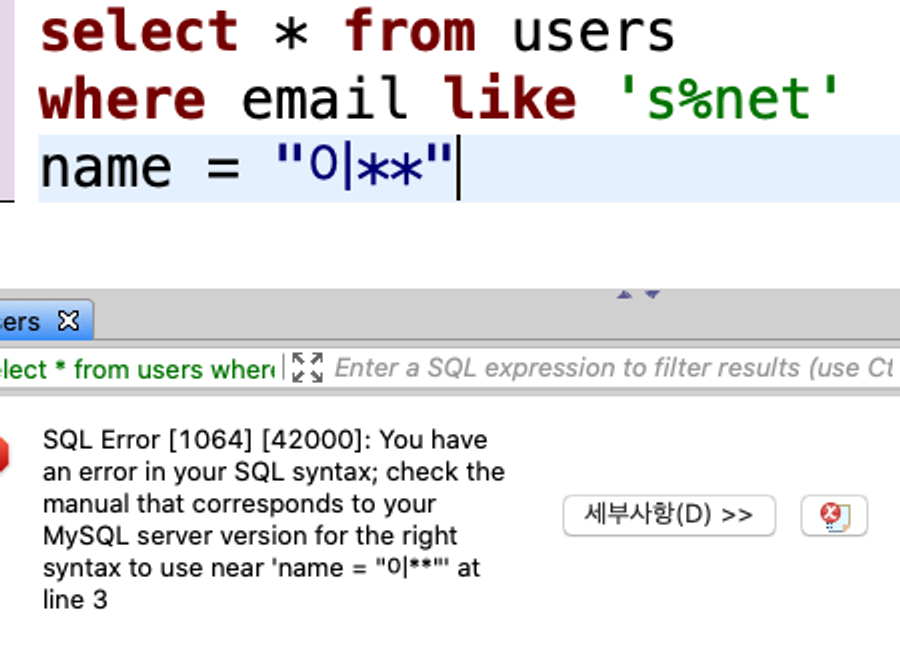
→ SQL 구문 에러
→ 조건을 여러 개 붙일 때는 where 다음 조건 부터는 and로 조건을 붙여준다.
select * from users
where email like 's%net'
and name = "이**"데이터분석의 목적 : 쌓여있는 날것의 데이터 → 의미를 갖는 '정보'로의 변환
1) 데이터베이스 테이블에 저장된 데이터 : 쌓여있는 날것의 데이터
2) 의미있는 '정보' : 가장 많은 Like를 받은 사람의 이름, 전체 신청자수, 평균 연령
3) 범주 (category)로 정보들을 묶음으로써 의미있는 통계 데이터 도출이 가능하다. 예) 과목별 신청자 평균 연령, 과목별 신청자수, 성씨별 회원수 등
4) 쿼리 예시 - 과목별 신청자 수
select count(*) from orders
where course_title = "앱개발 종합반";select count(*) from orders
where course_title = "웹개발 종합반";총 두 개의 과목이 있으니, 두 개의 쿼리를 각각 작성해야함.
만약, 성씨별 회원수를 구하고 싶을 때, 스파르타 회원의 성씨가 총 54개니까 54개의 쿼리를 작성한다면 너무 비효율적임.
5) Group by : 동일한 범주를 갖는 데이터를 하나로 묶어서, 범주별 통계를 내준다.
select name, count(*) from users
group by name;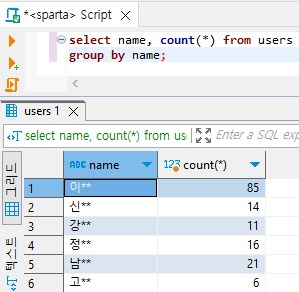
6) Order by : 깔끔하게 데이터를 정렬
select name, count(*) from users
group by name
order by count(*) desc;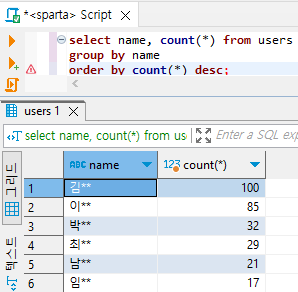
범주의 통계를 내주는 Group by
1) 성씨별 회원수(name | count)
- 일단 users 테이블에서 모든 데이터를 불러온다.
(select * from users : 일단 출력해놓고 데이터를 보자)- name이라는 필드에서 같은 값(동일한 성씨)을 갖는 데이터를 group by로 하나로 합쳐준다.
(group by name)- 이름과 group by로 해당 이름(동일한 성씨)끼리 합쳐진 데이터의 수를 골라 출력한다.
(select name, count(*) users
select * from users
group by name;
# 강씨 데이터가 한 곳으로 모이고, 경씨 데이터가 한 곳으로 모이는 식
# 묶은 데이터를 '이름 | 갯수'라는 통계치로 출력해달라는 명령어를 select에 넣어주면 된다.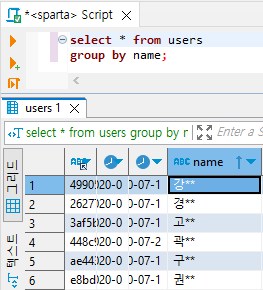
select count(*) from users
group by name;
# 성씨별 데이터 수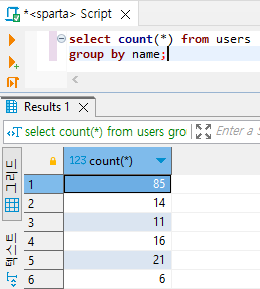
select name, count(*) from users
group by name;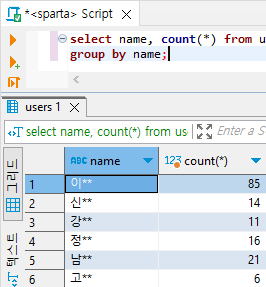
> 2) '신'씨 회원이 몇 명인지 살펴보기
select * from users
where name = '신**'
# 신씨 데이터만 보기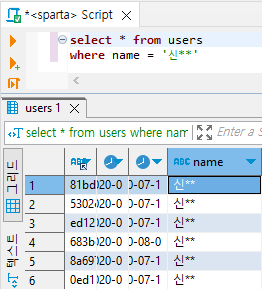
select name, count(*) from users
group by name
# 신씨 데이터 갯수 확인 가능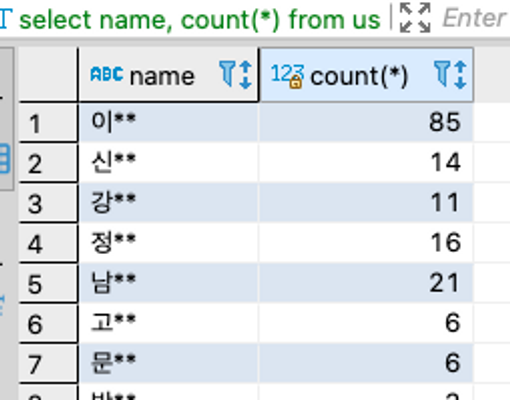
select name, count(*) from users
where name = '신**'
group by name;
# users에서 데이터를 가져와서 | name으로 데이터를 합쳐주고 | name이 '신**'인 데이터의 name과 count를 출력하라.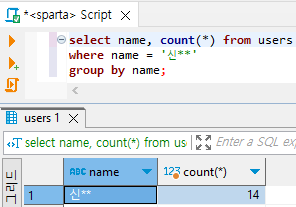
통계 : 최대 / 최소 / 평균 / 개수
Group by 기능 : 동일한 범주를 갖는 데이터를 하나로 묶어서, 범주별 통계를 내줌.
1) 사용할 테이블 알아보기! (checkins 테이블)
select * from checkins limit 10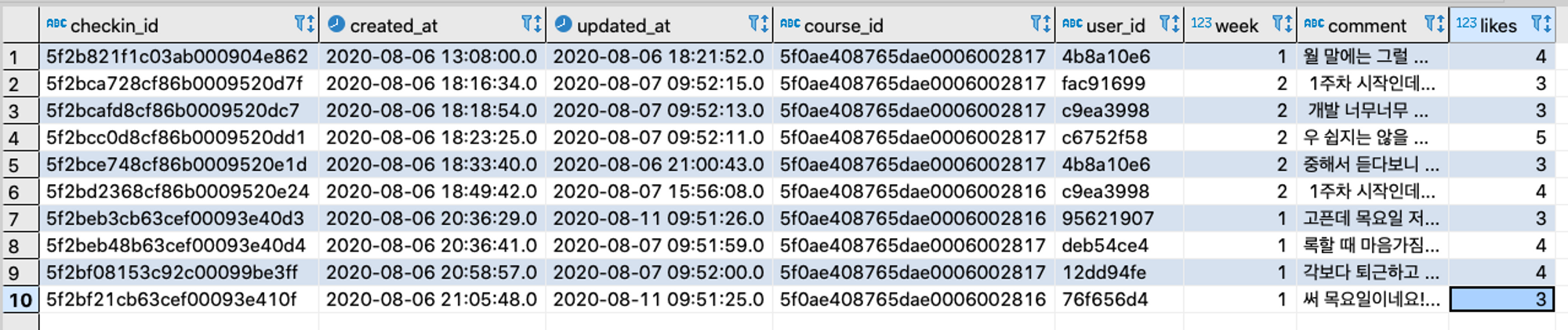
2) 동일한 범주의 개수 구하기 (count(*))
# 주차별 '오늘의 다짐' 개수 구하기
select week, count(*) from checkins
group by week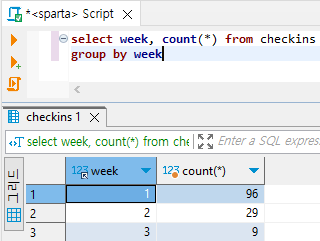
# where 문으로 동일한지 검증해보기
select * from checkins
where week = 1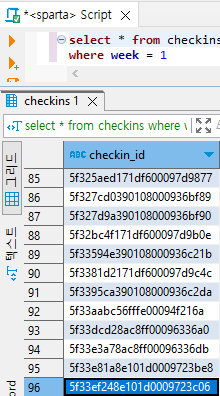
select 범주별로 세어주고 싶은 필드명, count(*) from 테이블명
group by 범주별로 세어주고 싶은 필드명;3) 동일한 범주에서의 최솟값 구하기 (min(필드명))
# 주차별 '오늘의 다짐'의 좋아요 최솟값 구하기
select week, min(likes) from checkins
group by week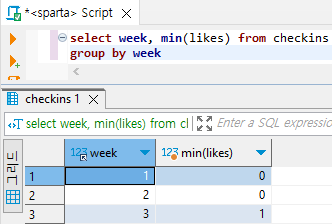
select 범주가 담긴 필드명, min(최솟값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;4) 동일한 범주에서의 최댓값 구하기 (max(필드명))
# 주차별 '오늘의 다짐'의 좋아요 최댓값 구하기
select week, max(likes) from checkins
group by week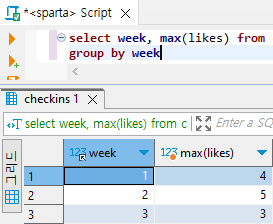
select 범주가 담긴 필드명, max(최댓값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;5) 동일한 범주의 평균 구하기 (avg(필드명))
# 주차별 '오늘의 다짐'의 좋아요 평균값 구하기
select week, avg(likes) from checkins
group by week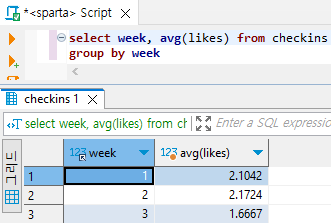
# 평균값의 소수점 제한두기 round (A, 소수점 자리수)
select week, round(avg(likes), 2) from checkins
group by week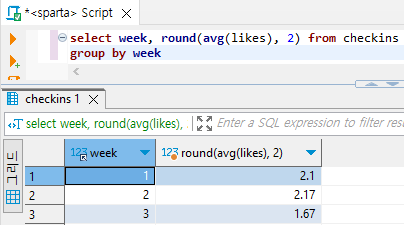
select 범주가 담긴 필드명, avg(평균값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;6) 동일한 범주의 합계 구하기 (sum(필드명))
# 주차별 '오늘의 다짐'의 좋아요 합계 구하기
select week, sum(likes) from checkins
group by week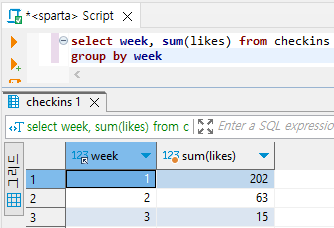
select 범주가 담긴 필드명, sum(합계를 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;Order by 기능 : 정렬 (정렬은 항상 데이터를 다 뽑은 후 마지막으로 한다.)
1) 성씨별 회원수 데이터 정렬하기 (name | count(*))
select name, count(*) from users
group by name;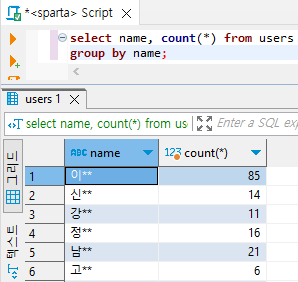
# 결과의 개수 오름차순으로 정렬 (asc : ascending(오름차순) 기본값이라 안 써줘도 됨.)
select name, count(*) from users
group by name
order by count(*)
# users에서 데이터를 가져와서 | name으로 데이터를 합쳐주고(묶어주고) | name과 count(*)를 출력한다. | 다 출력한 후에 정렬해준다.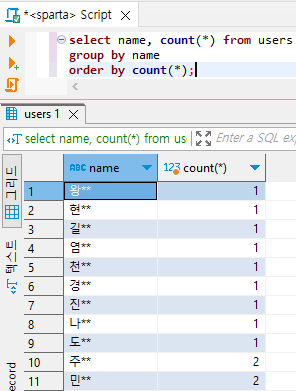
# 결과의 개수 내림차순으로 정렬 (desc : descending(내림차순))
select name, count(*) from users
group by name
order by count(*) desc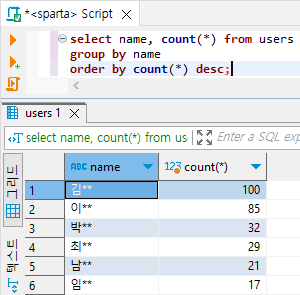
select * from 테이블명
order by 정렬의 기준이 될 필드명;2) 주차별 '오늘의 다짐'의 좋아요 많은 순으로 정렬하기
select * from checkins
order by likes desc;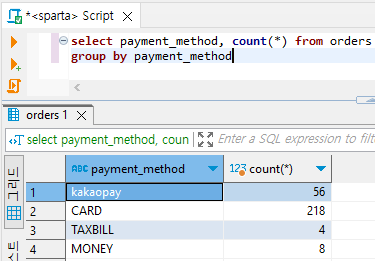
select * from 테이블명
order by 정렬의 기준이 될 필드명;Where와 Group by, Order by 함께 사용해보기 : Where절로 조건이 하나 추가되고, 그 이후에 Group by, Order by가 실행되는 것
ex) 웹개발 종합반의 결제수단별 주문건수 세어보기
# 결제수단별 주문건수 세어보기
select payment_method, count(*) from orders
group by payment_method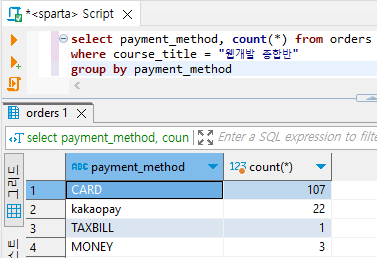
# 조건 '웹개발 종합반' 추가
select payment_method, count(*) from orders
where course_title = "웹개발 종합반"
group by payment_method
# [순서]
1. orders 테이블에서 주문 데이터를 읽어오고
2. 웹개발 종합반 데이터만 남기고
3. 결제수단(범주) 별로 그룹화하고
4. 결제수단별 주문건수를 세어준다!
위 쿼리가 실행되는 순서: from → where → group by → select 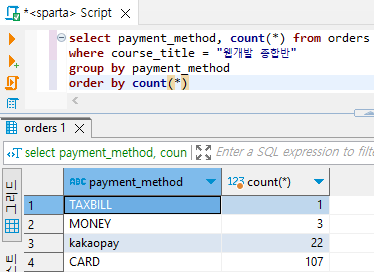
# order by는 결과물을 정렬해주는 것이기 때문에 맨 나중에 실행
select payment_method, count(*) from orders
where course_title = "웹개발 종합반"
group by payment_method
order by count(*)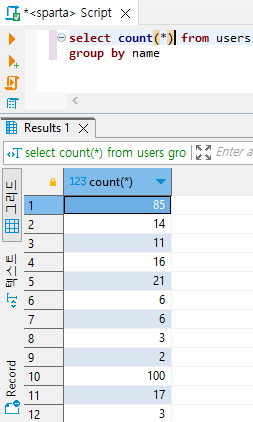
에러
select * from users
group by name
# 강씨 데이터가 한 곳으로 모이고, 경씨 데이터가 한 곳으로 모이는 식
# 범주별로 묶어달라는 명령어 (group by)는 작성했지만 출력되기를 원하는 통계치를 입력하지 않아서 이렇게 나옴.
# '어떤 통계치'(이름 | 갯수)로 출력해달라는 명령어 추가
# 내가 원하는 통계치 : count
select count(*) from users
group by name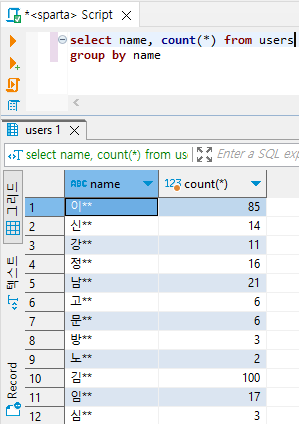
# 내가 원하는 통계치 : '해당 범주' | count
select name, count(*) from users
group by name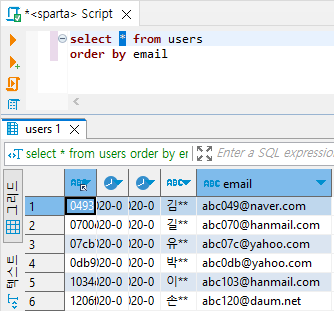
Order by, Group by 연습
1) Order by 연습
- 문자열을 기준으로 정렬
# email 알파벳 문자열을 기준으로 정렬
select * from users
order by email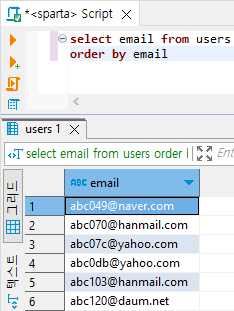
# email 통계치 출력, email 알파벳 정렬
select email from users
order by email 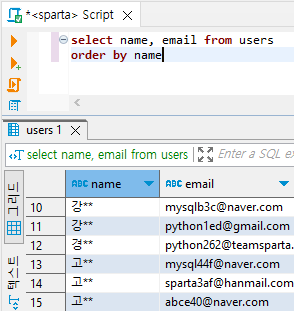
# name | email 통계치 출력, name 한글 정렬
select name, email from users
order by name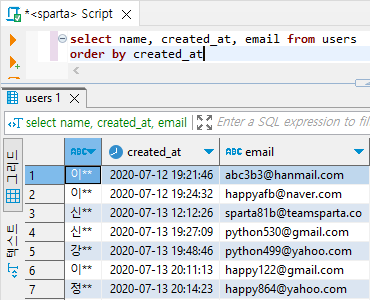
- 시간을 기준으로 정렬
# 이름, 가입 시기, email 통계치 출력 | 계정 생성 시점 순서 정렬
select name, created_at, email from users
order by created_at
# 최근순으로 보려면 desc를 붙여주면 된다.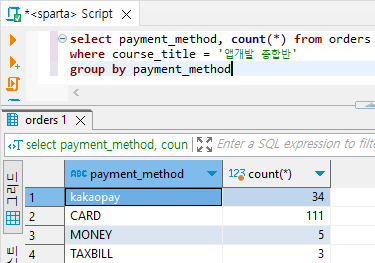
2) Group by 연습
- 앱개발 종합반의 결제수단별 주문건수 세어보기
select payment_method, count(*) from orders
where course_title = '앱개발 종합반'
group by payment_method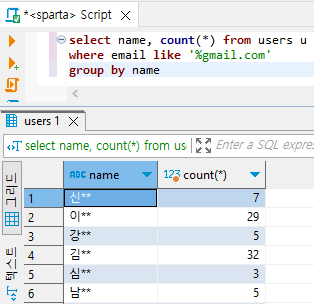
- Gmail 을 사용하는 성씨별 회원수 세어보기 (like)
select name, count(*) from users
where email like '%gmail.com'
group by name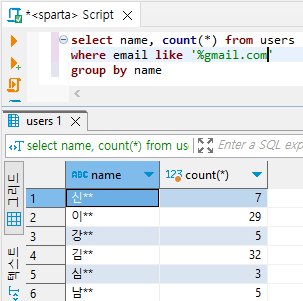
- course_id별 '오늘의 다짐'에 달린 평균 like 개수 구해보기
select course_id, round(avg(likes),1) from checkins
group by course_id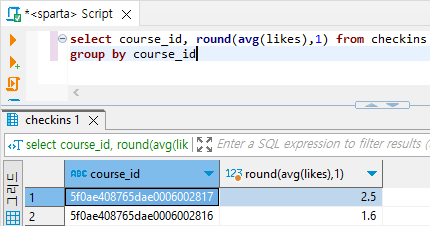
쿼리 작성 요령
1) show tables로 어떤 테이블이 있는지 살펴보기
2) 제일 원하는 정보가 있을 것 같은 테이블에 select * from 테이블명 limit 10 쿼리 날려보기
3) 원하는 정보가 없으면 다른 테이블에도 2)를 해보기
4) 테이블을 찾았다! 범주를 나눠서 보고싶은 필드를 찾기
5) 범주별로 통계를 보고싶은 필드를 찾기
6) SQL 쿼리 작성하기!
별칭 기능: Alias (쿼리문이 길어지면서 햇갈리는 것을 방지하기 위해 사용)
## 앱개발 종합반 주문데이터
select * from orders
where course_title = '앱개발 종합반'
# course_title이 어느 테이블의 필드인지 쉽게 알기 위해 별칭을 추가해준다.
select * from orders o
where o.course_title = '앱개발 종합반'
select * from orders as o
where o.course_title = '앱개발 종합반'
# orders 테이블의 별칭 = o, o.course_title = o의 필드## 결제수단별 '앱개발 종합반' 주문건수 데이터
select payment_method, count(*) from orders o
where o.course_title = '앱개발 종합반'
group by payment_method
# 출력될 필드에 별칭을 붙이는 것도 가능하다.
select payment_method, count(*) as cnt from orders o
where o.course_title = '앱개발 종합반'
group by payment_method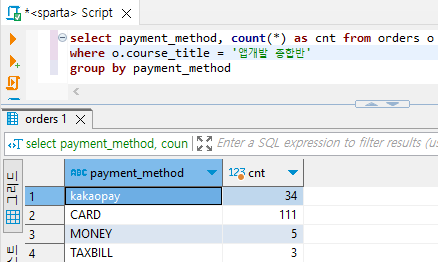
- 숙제 : 네이버 이메일을 사용하여 앱개발 종합반을 신청한 주문의 결제수단별 주문건수 세어보기
select payment_method, count(*) as cnt from orders o
where o.course_title = '앱개발 종합반'
and email like '%naver.com'
group by payment_method
order by count(*) desc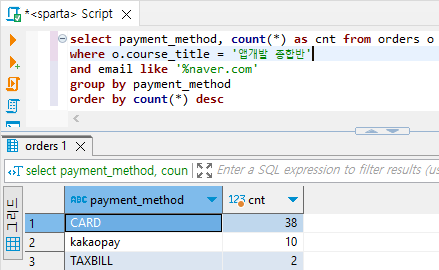
Join
ex) 오늘의 다짐 이벤트: 오늘의 다짐을 남겨준 10명 추첨해서 기프티콘 지급
checkins 테이블
users 테이블
user_id라는 공통된 필드가 있으니 checkins 테이블의 user_id를 가지고 users 테이블에서 where 문으로 찾아보면 해당 오늘의 다짐 작성자의 회원 정보를 확인할 수 있다.
모든 작성자의 정보를 이런 식으로 쿼리를 날려서 알아낼 수는 있지만 시간 낭비이기 때문에 이것을 join으로 해결할 것이다.
[꿀팁!]
한 테이블에 모든 정보를 담을 수도 있겠지만, 불필요하게 테이블의 크기가 커져 불편하기 때문에 데이터를 종류별로 쪼개 다른 테이블에 담아놓고 연결이 필요한 경우 연결할 수 있도록 만들어놓는다.users와 checkins 테이블에 동시에 존재하는 user_id 같은 필드를 두 테이블을 연결시켜주는 열쇠라는 의미로 'key'라고 부른다.
1) Join 이란?
여러 테이블의 공통된 정보 (key값)를 기준으로 테이블을 연결해서 한 테이블처럼 보는 것
예를 들어, users 테이블과 orders 테이블을 연결해서 한 눈에 보고 싶을 때를 대비해서 user_id 필드처럼 동일한 이름과 정보가 담긴 필드를 두 테이블에 똑같이 담아놓는다. 이런 필드를 두 테이블을 연결시켜주는 열쇠라는 의미로 'key'라고 부른다.
2) Join의 종류: Left Join, Inner Join
- Left Join
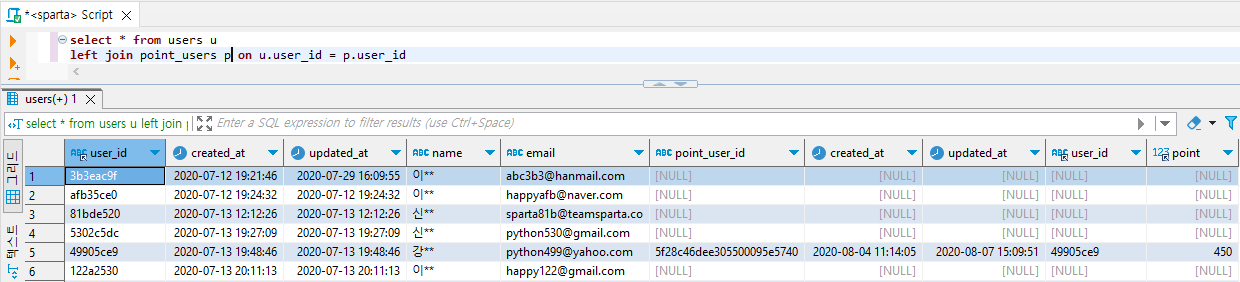
select * from users u
left join point_users p
on u.user_id = p.user_id
Null : 해당 데이터의 user_id 필드값이 point_users 테이블에 존재하지 않는 경우 (회원이지만 수강을 등록/시작하지 않아 포인트를 획득하지 않은 회원인 경우)
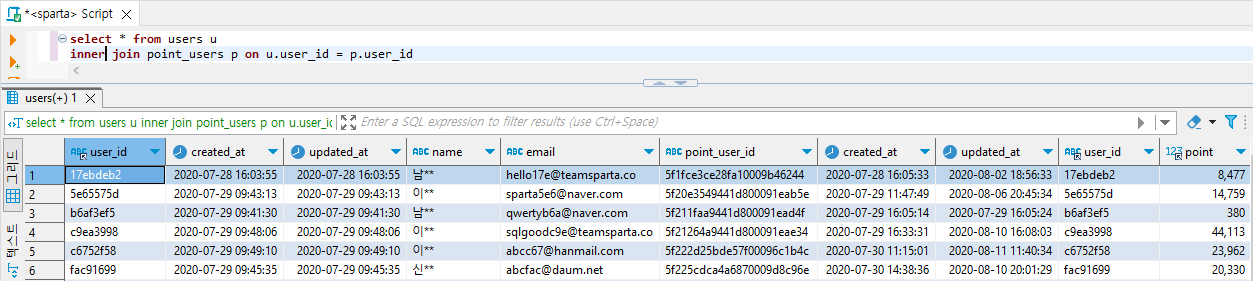
- Inner Join
select * from users u
inner join point_users p
on u.user_id = p.user_id
교집합 데이터들 즉 두 테이블 모두 가지고 있는 데이터만 출력했기 때문에 빈 필드의 데이터는 없다.
3) Join 연습
- 주문 정보에 유저 정보를 연결
# orders 테이블에 users 테이블 연결해보기 (key = user_id)
select o.order_no, u.user_id, u.name, u.email from orders o
inner join users u
on o.user_id = u.user_id
# inner join이 비교적 쉽다.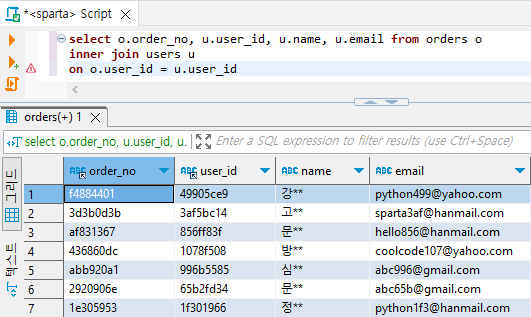
- '오늘의 다짐' 테이블에 유저 정보를 연결
# checkins 테이블에 users 테이블 연결해보기 (key = user_id)
select u.user_id, c.comment, c.updated_at from checkins c # from 연결의 기준이 되고싶은 테이블
inner join users u # Join 붙이고 싶은 테이블
on c.user_id = u.user_id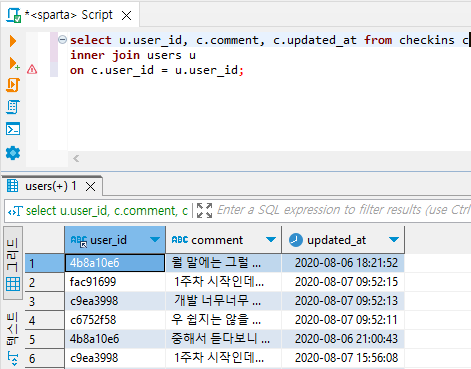
- '수강 등록' 테이블에 과목 정보를 연결
# enrolleds 테이블에 courses 테이블 연결해보기 (key = course_id)
select e.user_id, c.title from enrolleds e
inner join courses c on e.course_id = c.course_id
위 쿼리가 실행되는 순서: from → join → select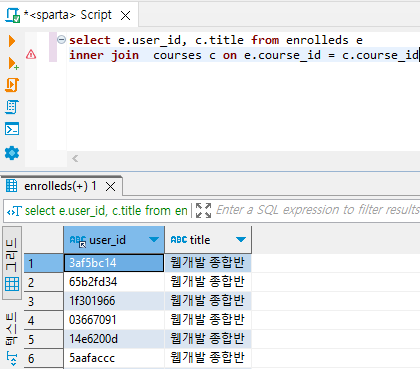
- from enrolleds: enrolleds 테이블 데이터 전체를 가져온다.
- inner join courses on e.course_id = c.course_id: courses를 enrolleds 테이블에 붙이는데, enrolleds 테이블의 course_id와 동일한 course_id를 갖는 courses의 테이블을 붙인다.
- select * : 붙여진 모든 데이터를 출력한다.
- '오늘의 다짐' 정보에 과목 정보를 연결해 과목별 '오늘의 다짐' 갯수 세어보기
checkins 테이블에 courses 테이블 연결 (key = course_id)
select count(*) from checkins ck
inner join courses cs on ck.course_id = cs.course_id과목별 오늘의 다짐 갯수 통계치 내보기
select ck.user_id, ck.course_id, cs.title, count(*) from checkins ck
inner join courses cs on ck.course_id = cs.course_id
group by ck.course_id # 이미 한 테이블로 합쳐진 것으로 보고 ck.title로 묶어도 된다.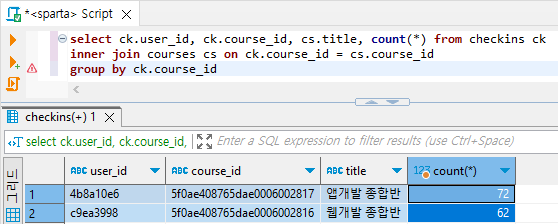
- 유저의 포인트 정보가 담긴 테이블에 유저 정보를 연결해서, 많은 포인트를 얻은 순서대로 유저의 데이터를 뽑아보기
# point_users 테이블에 users 테이블 연결 (key = user_id)
select * from point_users p
inner join users u on p.user_id = u.user_id# 많은 포인트를 얻은 순서대로 유저 데이터 정렬
select u.user_id, u.name, p.point from point_users p
inner join users u on p.user_id = u.user_id
order by p.point desc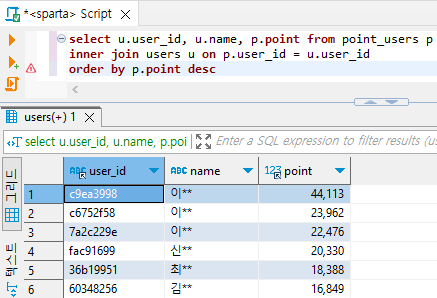
- 주문 정보에 유저 정보를 연결해 네이버 이메일을 사용하는 유저 중, 성씨별 주문건수를 세어보기
orders 테이블에 users 테이블 연결 (key = user_id)
select * from orders o
inner join users u on o.user_id = u.user_id# 네이버 이메일을 사용하는 유저 중, 성씨별 주문건수를 세어보기
select u.name, u.email, count(u.name) as cnt_name from orders o
inner join users u on o.user_id = u.user_id
where u.email like '%naver.com'
group by u.name
order by cnt_name desc
위 쿼리가 실행되는 순서: from → join → where → group by → select → order by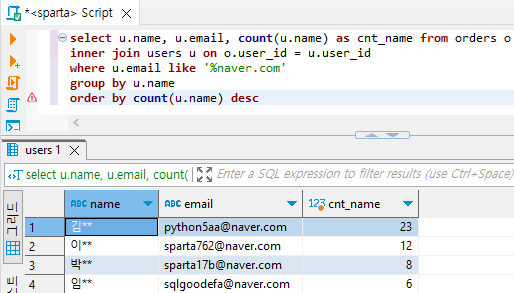
- from orders o: orders 테이블 데이터 전체를 가져오고 o라는 별칭을 붙인다.
- inner join users u on o.user_id = u.user_id : users 테이블을 orders 테이블에 붙이는데, orders 테이블의 user_id와 동일한 user_id를 갖는 users 테이블 데이터를 붙인다. (*users 테이블에 u라는 별칭을 붙인다)
- where u.email like '%naver.com': users 테이블 email 필드값이 naver.com으로 끝나는 값만 가져온다.
- group by u.name: users 테이블의 name값이 같은 값들을 뭉쳐준다.
- select u.name, count(u.name) as count_name : users 테이블의 name필드와 name 필드를 기준으로 뭉쳐진 갯수를 세어서 출력해준다.
- order by count(u.name) desc : name 필드를 기준으로 뭉쳐진 갯수를 내림차순으로 내려준다.
- 결제 수단 별 유저 포인트의 평균값 구해보기
# point_users 테이블에 orders 테이블 붙이기 (key = user_id)
select * from point_users p
inner join orders o on p.user_id = o.user_id# 결제 수단 별 유저 포인트의 평균값 구해보기
select o.payment_method, round(avg(p.point),0) from point_users p # round에 0은 반올림
inner join orders o on p.user_id = o.user_id
group by o.payment_method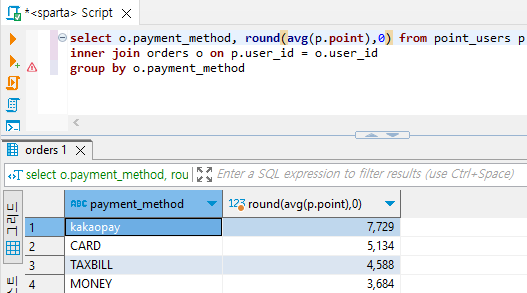
- 결제하고 시작하지 않은 유저들을 성씨별로 세어보기
# enrolleds 테이블에 users 테이블 붙이기 (key = user_id)
select * from enrolleds e
inner join users u on e.user_id = u.user_id# 결제하고 시작하지 않은 유저들을 성씨별로 세어보기
select u.name, count(u.name) as cnt_name from enrolleds e
inner join users u on e.user_id = u.user_id
where e.is_registered = 0
group by u.name
order by cnt_name desc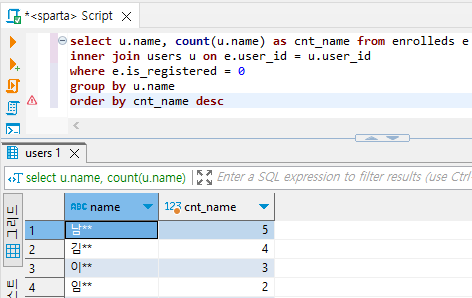
- 과목별로 시작하지 않은 유저들을 세어보기
# courses 테이블에 enrolleds 테이블 붙이기 (key = course_id)
select * from courses c
inner join enrolleds e on c. # 과목별로 시작하지 않은 유저들을 세어보기
select c.course_id, c.title, count(*) as cnt_notstart from courses c
inner join enrolleds e on c.course_id = e.course_id
where e.is_registered = 0
group by c.course_id # e.course_id랑 같음.
order by cnt_notstart desc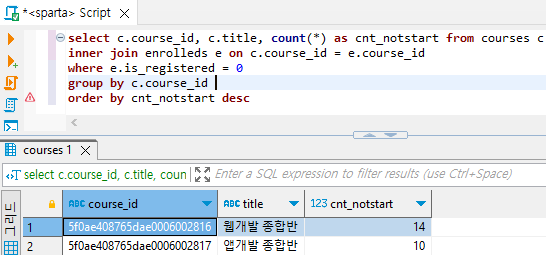
- 웹개발, 앱개발 종합반의 week 별 체크인 수를 세어보기
# courses 테이블에 checkins 테이블 붙이기 (key = course_id)
select * from courses cs
inner join checkins ck on cs.course_id = ck.course_id# 웹개발, 앱개발 종합반의 week 별 체크인 수를 세어보기
select cs.title, ck.week, count(*) as cnt from courses cs
inner join checkins ck on cs.course_id = ck.course_id
group by cs.title, ck.week
order by cs.title, ck.week, cnt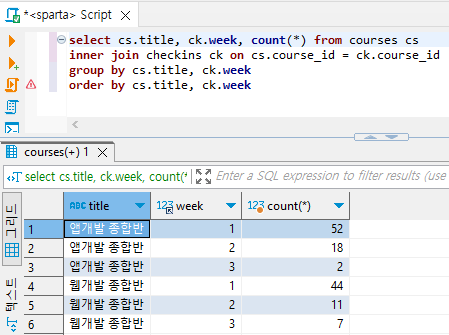
- 위 예제에서 8월 1일 이후에 구매한 고객들만 뽑아내기
# courses 테이블에 checkins 테이블을 붙인 곳에 checkins 테이블에 orders 테이블 붙이기 (key = course_id)
select * from courses cs
inner join checkins ck on cs.course_id = ck.course_id
inner join orders o on ck.user_id = o.user_id# 8월 1일 이후에 구매한 고객들만 뽑아내기
select cs.title, ck.week, count(*) as cnt from courses cs
inner join checkins ck on cs.course_id = ck.course_id
inner join orders o on ck.user_id = o.user_id
where o.created_at >= '2020-08-01'
group by cs.title, ck.week
order by cs.title, ck.week 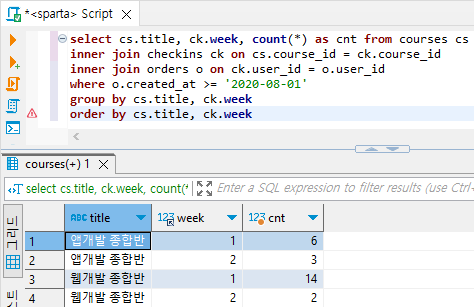
Left join : 한 곳에는 있고 다른 곳에는 없는 것을 통계낼 때
- 유저 중에, 포인트가 없는 사람(=즉, 시작하지 않은 사람들)의 통계
# users 테이블에 point_users 테이블 붙이기 (key = user_id)
select * from users u
left join point_users p on u.user_id = p.user_id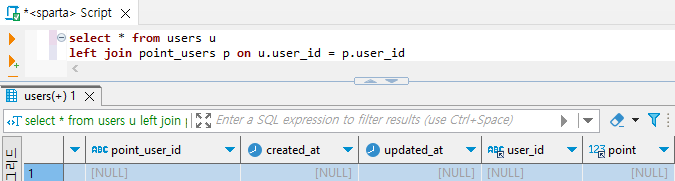
# 유저 중에, 포인트가 없는 사람(=즉, 시작하지 않은 사람들)의 통계 = NULL 값인 데이터만 뽑아보자
select u.name, count(*) as cnt from users u
left join point_users p on u.user_id = p.user_id
where p.point_user_id is NULL # NULL 값이 들어있는 필드 아무거나 넣어도 된다.
group by u.name # users 테이블에만 name 필드가 있어서 그냥 name만 써도 된다.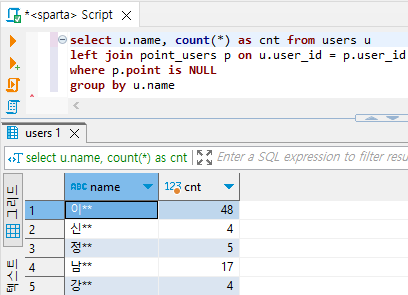
# 유저 중에, 시작한 사람들의 통계 = NULL 값이 아닌 데이터만 뽑아보자
select u.name, count(*) as cnt from users u
left join point_users p on u.user_id = p.user_id
where p.point_user_id is not NULL # NULL 값이 들어있는 필드 아무거나 넣어도 된다.
group by u.name 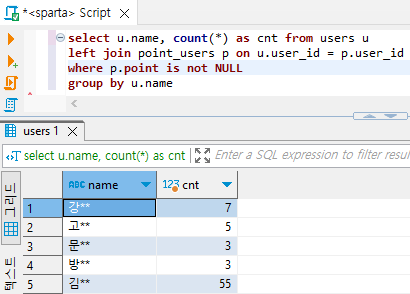
- 7월10일 ~ 7월19일에 가입한 고객 중, 포인트를 가진 고객의 숫자, 그리고 전체 숫자, 그리고 비율 구하기
# 7월10일 ~ 7월19일에 가입한 고객 데이터 뽑기
select * from users u
left join point_users p on u.user_id = p.user_id
where u.created_at between '2020-07-10' and '2020-07-20'# 포인트를 가진 고객의 숫자, 그리고 전체 숫자, 그리고 비율 구하기
select count(point_user_id) as pnt_user_cnt,
count(*) as tot_user_cnt,
round(count(point_user_id)/count(*),2) as ratio
from users u
left join point_users pu on u.user_id = pu.user_id
where u.created_at between '2020-07-10' and '2020-07-20'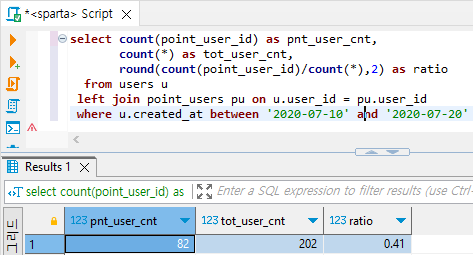
Union : 결과물 합치기
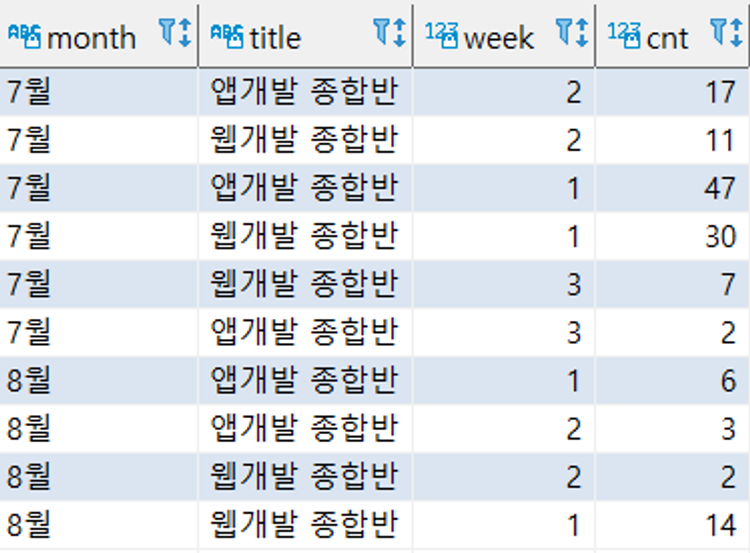
select '7월' as month, cs.title, ck.week, count(*) as cnt from courses cs
inner join checkins ck on cs.course_id = ck.course_id
inner join orders o on ck.user_id = o.user_id
where o.created_at < '2020-08-01'
group by cs.title, ck.week
order by cs.title, ck.week
select '8월' as month, cs.title, ck.week, count(*) as cnt from courses cs
inner join checkins ck on cs.course_id = ck.course_id
inner join orders o on ck.user_id = o.user_id
where o.created_at >= '2020-08-01'
group by cs.title, ck.week
order by cs.title, ck.week
# 따로 실행밖에 안된다. union all 사용하기
(
select '7월' as month, cs.title, ck.week, count(*) as cnt from courses cs
inner join checkins ck on cs.course_id = ck.course_id
inner join orders o on ck.user_id = o.user_id
where o.created_at < '2020-08-01'
group by cs.title, ck.week
)
union ALL
(
select '8월' as month, cs.title, ck.week, count(*) as cnt from courses cs
inner join checkins ck on cs.course_id = ck.course_id
inner join orders o on ck.user_id = o.user_id
where o.created_at >= '2020-08-01'
group by cs.title, ck.week
)
# union에서는 order by가 작동하지 않아서 없애줘도 된다.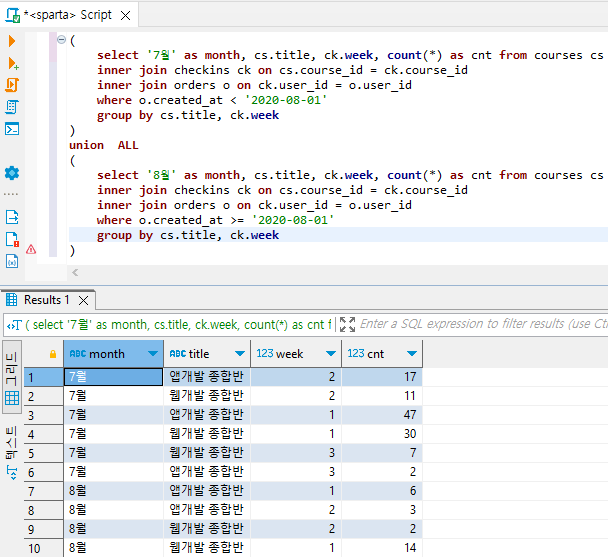
- 숙제
- enrolled_id별 수강완료(done=1)한 강의 갯수를 세어보고, 완료한 강의 수가 많은 순서대로 정렬해보기 (user_id도 같이 출력)
select * from enrolleds e
inner join enrolleds_detail ed on e.enrolled_id = ed.enrolled_idselect e.enrolled_id,
e.user_id,
count(*) as cnt
from enrolleds e
inner join enrolleds_detail ed on e.enrolled_id = ed.enrolled_id
where ed.done = 1
group by e.enrolled_id, e.user_id
order by cnt desc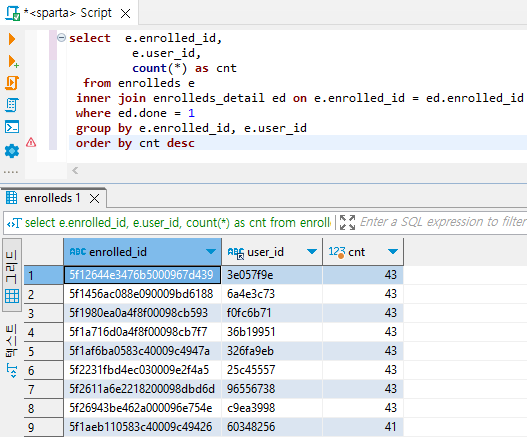
Subquery : 하나의 SQL 쿼리 안에 또다른 SQL 쿼리가 있는 것
kakaopay로 결제한 유저들의 정보 보기
# 두 테이블을 합치고 payment_method가 kakaopay인 값을 찾는 방법 (key = user_id)
select u.user_id, u.name, u.email from users u
inner join orders o on u.user_id = o.user_id
where o.payment_method = 'kakaopay'# 테이블을 합치기 전 원하는 데이터를 뽑은 후 합치는 방법
1) 우선 payment_method가 kakaopay인 key(= user_id) 찾기
select user_id from orders
where payment_method = 'kakaopay'
# 이 쿼리문이 다른 쿼리문의 조건으로 속하게 되는 것이다. = Subquery
2) payment_method가 kakaopay인 key(= user_id)를 추출했으니 테이블을 합친다.
select u.user_id, u.name, u.email from users u
where u.user_id in (
select user_id from orders
where payment_method = 'kakaopay'
)
# 조건을 먼저 찾고 출력은 합친 뒤에 원하는 값을 추출한다.
# users 테이블의 user_id 중 orders 테이블의 결제수단이 카카오페이인 user_id만 뽑아낸다.즉, 첫 번째 쿼리문은 두 테이블이 join되어 user의 데이터가 2번 들어가는 것이고, 두 번째 쿼리문은 조건을 만족하는 user의 데이터만 뽑아내서 하나의 테이블에 넣는 것이다.
1) Where 에 들어가는 Subquery (where 필드명 in (subquery))
- 카카오페이로 결제한 주문건 유저들만, 유저 테이블에서 출력
# 카카오페이로 결제한 주문건 유저
select user_id from orders
where payment_method = 'kakaopay'# 위 데이터를 유저 테이블에서 출력
select u.user_id, u.name, u.email from users u
where u.user_id in (select user_id from orders
where payment_method = 'kakaopay')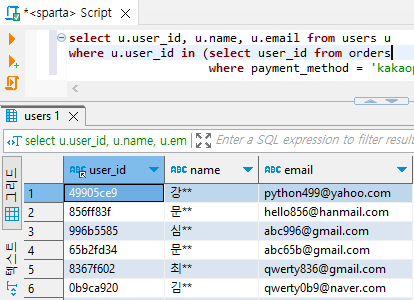
1-1) from 실행: users 데이터를 가져와줌
1-2) Subquery 실행: 해당되는 user_id의 명단을 뽑아줌
1-3) where .. in 절에서 subquery의 결과에 해당되는 'user_id의 명단' 조건으로 필터링 해줌
1-4) 조건에 맞는 결과 출력
2) Select 에 들어가는 Subquery (select 필드명, 필드명, (subquery) from .. )
- 오늘의 다짐 좋아요 평균치와 나의 좋아요 수 비교 : user_id, 내 likes, 내 좋아요 평균치 추출
# 유저 별 좋아요 평균 : checkins 테이블을 user_id로 group by
select user_id, round(avg(likes),1) as avg_like from checkins
group by user_id# checkins 테이블에 유저 별 좋아요 평균 추가
select c.checkin_id, c.user_id, c.likes,
(select avg(likes) from checkins sck
where sck.user_id = c.user_id) as avg_like_user
from checkins c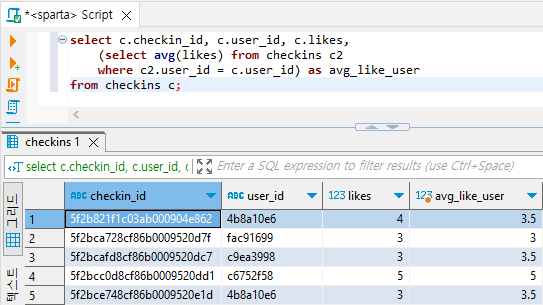
2-1) 밖의 select * from 문에서 데이터를 한줄한줄 출력하는 과정에서
2-2) select 안의 subquery가 매 데이터 한줄마다 실행되는데
2-3) 그 데이터 한 줄의 user_id를 갖는 데이터의 평균 좋아요 값을 subquery에서 계산해서
2-4) 함께 출력해준다.
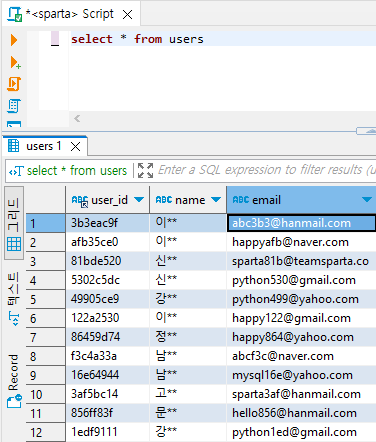
# user_id='4b8a10e6'의 데이터
select c.checkin_id, c.user_id, c.likes,
(select avg(likes) from checkins sck
where sck.user_id = c.user_id) as avg_like_user
from checkins c
where c.user_id = '4b8a10e6'
group by c.checkin_id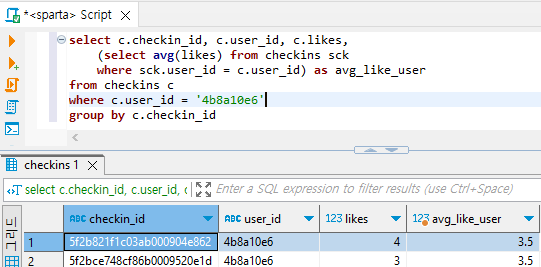
3) From 에 들어가는 Subquery (내가 만든 Select와 이미 있는 테이블을 Join하고 싶을 때 사용 : 가장 많이 사용되는 유형)
- 해당 유저 별 포인트와 내 라이크 평균 비교
# 유저 별 좋아요 평균 : checkins 테이블을 user_id로 group by
select user_id, round(avg(likes),1) as avg_like from checkins
group by user_id# 해당 유저 별 포인트 : point_users테이블에 Subquery문을 user_id로 join
select pu.user_id, alike.avg_like, pu.point from point_users pu
inner join (
select user_id, round(avg(likes),1) as avg_like from checkins
group by user_id
) alike on pu.user_id = alike.user_id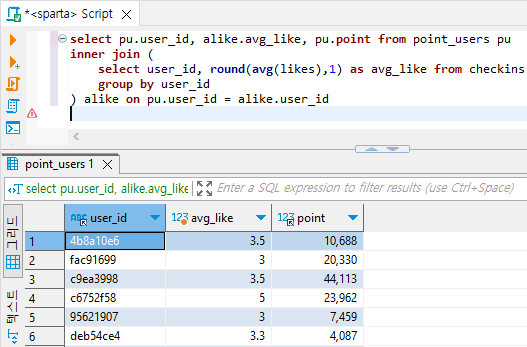
3-1) 먼저 서브쿼리의 select가 실행되고,
3-2) 이것을 테이블처럼 여기고 밖의 select가 실행!
Subquery 연습해보기 (where, select, from, inner join)
1) Where 절에 들어가는 Subquery 연습
- 전체 유저의 포인트의 평균보다 큰 유저들의 데이터 추출
# 전체 유저 포인트 평균 구하기
select avg(spu.point) from point_users spu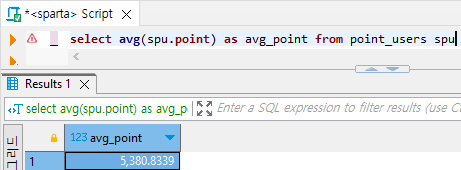
# where(조건) 문으로 포인트가 sub쿼리문의 전체 유저 포인트보다 큰 유저 데이터만 추출
select pu.point_user_id, pu.user_id, pu.point from point_users pu
where pu.point > (select avg(spu.point) from point_users spu)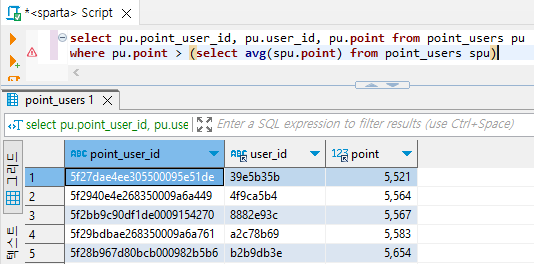
- 이씨 성을 가진 유저의 포인트의 평균보다 큰 유저들의 데이터 추출
select * from point_users pu
where point > (
)
select * from point_users
+
select * from users# 이씨 성을 가진 유저의 포인트 평균 구하기(1)
select avg(spu.point) from point_users spu
inner join users u on spu.user_id = u.user_id
where u.name = '이**'
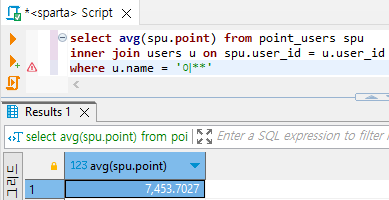
# 이씨 성을 가진 유저의 포인트 평균 구하기(2)
select avg(spu.point) from point_users spu
where user_id in (
select user_id from users
where name = '이**'
)
# 위의 쿼리문 중 아무거나 point_users 테이블의 where 조건문에 넣어준다.
select pu.point_user_id, pu.user_id, pu.point from point_users pu
where pu.point >
(select avg(spu.point) from point_users spu
inner join users u
on spu.user_id = u.user_id
where u.name = "이**");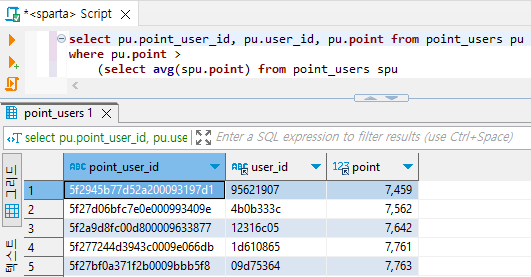
2) Select 절에 들어가는 Subquery 연습
- checkins 테이블에 course_id별 평균 likes수 필드 우측에 붙여보기
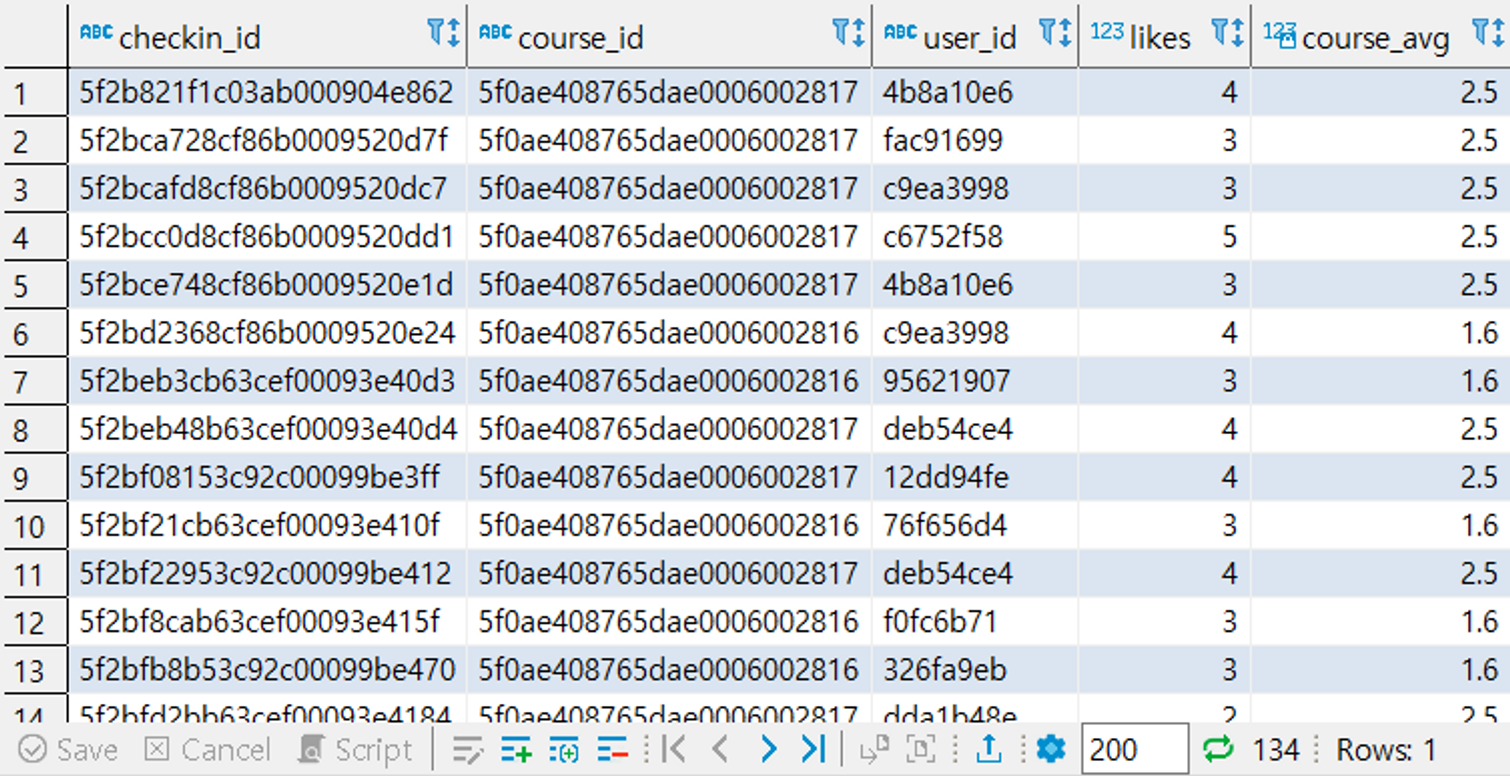
select checkin_id, course_id, user_id, likes, ( ) from checkins ck
select avg(likes) from checkins sck
where course_id = '5f0ae408765dae0006002817'
# checkins 테이블의 course_id 값과 subquery의 course_id 값이 같다는 조건으로 like의 평균을 낸 값을 출력해주면 각 course_id를 돌 때마다 checkin_id, course_id, user_id, likes, avg(sck.likes) 값이 출력된다.select ck.checkin_id, ck.course_id, ck.user_id, ck.likes,
(select avg(sck.likes) from checkins sck
where ck.course_id = sck.course_id) as course_avg
from checkins ck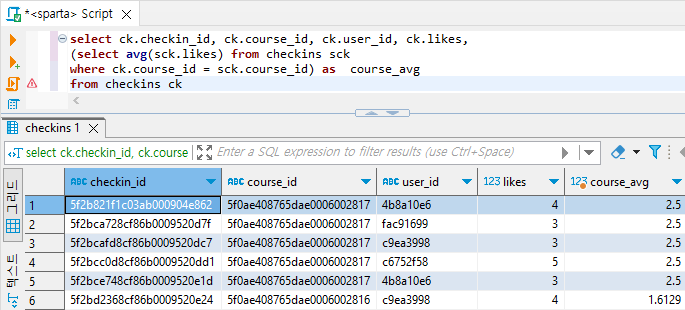
- checkins 테이블에 과목명별 평균 likes수 필드 우측에 붙여보기
select ck.checkin_id, ck.course_id, ck.user_id, ck.likes,
(select avg(sck.likes) from checkins sck
where ck.course_id = sck.course_id) as course_avg
from checkins ck
# 위 쿼리문에서 ck.course_id 대신에 courses 테이블에 있는 title 필드 값을 넣어주라는 것
# courses 테이블을 join하고 cs.title을 출력해주면 된다.select ck.checkin_id, cs.title, ck.user_id, ck.likes,
(select round(avg(likes),1) from checkins sck
where ck.course_id = sck.course_id) as course_avg
from checkins ck
inner join courses cs
on ck.course_id = cs.course_id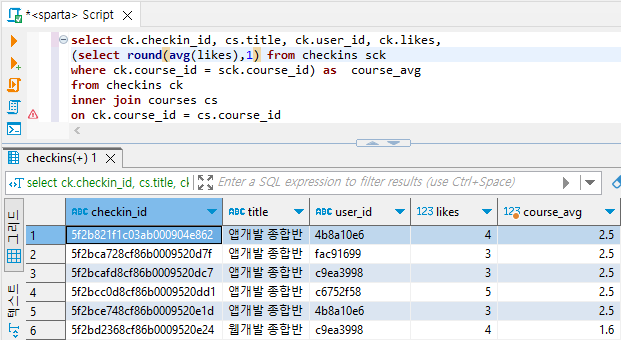
3) From 절에 들어가는 Subquery 연습해보기
- 과목별 인원 대비 체크인 비율 구하기
과정 1) 과목별 인원 구하기
# orders 테이블을 course_id로 group by하기
select course_id, count(*) as cnt_total from orders
group by course_id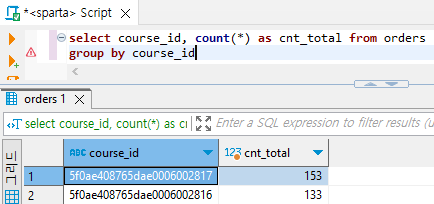
과정 2) 과목별 유저의 체크인 개수 구하기
# checkins 테이블을 course_id로 group by하기 (X)
# 중복이 있을 수 있으니 체크인을 한 번이라도 한 유저만 찾으면 된다.
# 데이터 중복 제거 : distinct
select course_id ,count(distinct(user_id)) as cnt_checkins from checkins ck
group by course_id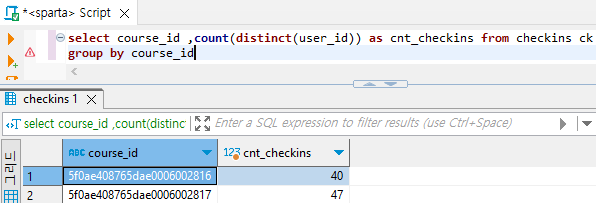
과정 3) 과목별 총 인원과 총 체크인 개수 합치기
# 과정 1과 2를 inner join
select * from (기준) a
inner join (붙일 것) b on a.course_id = b.course_idselect a.course_id, b.cnt_checkins, a.cnt_total from
(
select course_id, count(*) as cnt_total from orders
group by course_id
) a
inner join (
select course_id ,count(distinct(user_id)) as cnt_checkins from checkins ck
group by course_id
) b
on a.course_id = b.course_id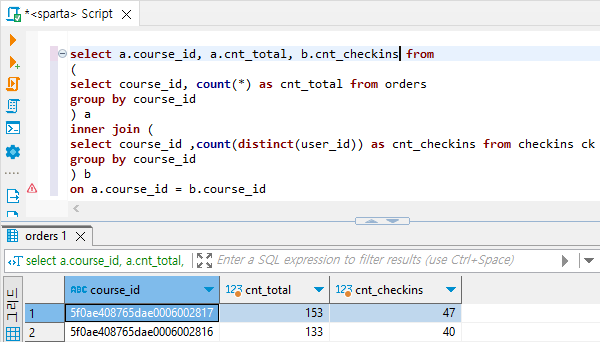
과정 4) 비율 구하기
select a.course_id, a.cnt_total, b.cnt_checkins, (b.cnt_checkins/a.cnt_total) as ratio from
(
select course_id, count(*) as cnt_total from orders
group by course_id
) a
inner join (
select course_id ,count(distinct(user_id)) as cnt_checkins from checkins ck
group by course_id
) b
on a.course_id = b.course_id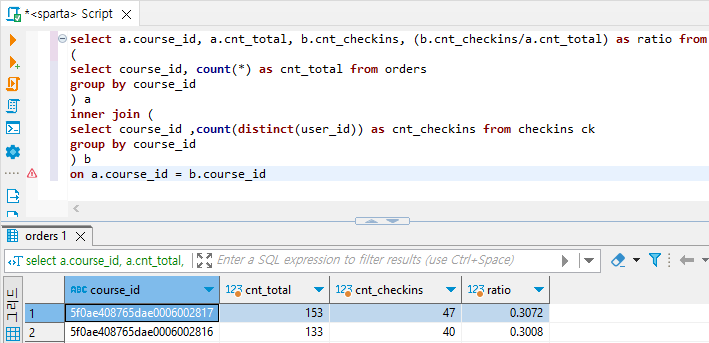
과정 5) 강의 제목 띄우기
# courses 테이블을 join
select cs.title, a.cnt_total, b.cnt_checkins, (b.cnt_checkins/a.cnt_total) as ratio from
(
select course_id, count(*) as cnt_total from orders
group by course_id
) a
inner join (
select course_id ,count(distinct(user_id)) as cnt_checkins from checkins ck
group by course_id
) b
on a.course_id = b.course_id
inner join courses cs on a.course_id = cs.course_id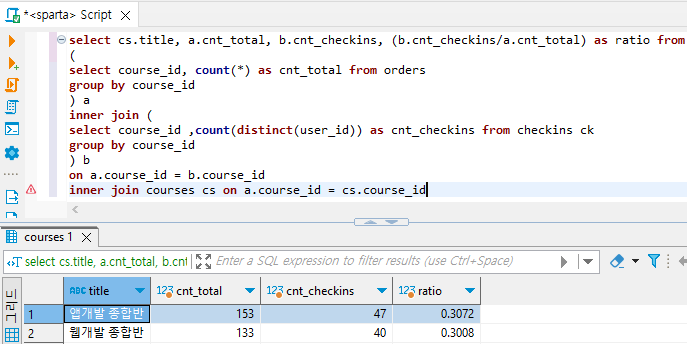
with절
select cs.title, a.cnt_total, b.cnt_checkins, (b.cnt_checkins/a.cnt_total) as ratio from
(
select course_id, count(*) as cnt_total from orders
group by course_id
) a
inner join (
select course_id ,count(distinct(user_id)) as cnt_checkins from checkins ck
group by course_id
) b
on a.course_id = b.course_id
inner join courses cs on a.course_id = cs.course_idwith table1 as (
select course_id, count(*) as cnt_total from orders
group by course_id
), table2 as (
select course_id ,count(distinct(user_id)) as cnt_checkins from checkins ck
group by course_id
)
select cs.title, a.cnt_total, b.cnt_checkins, (b.cnt_checkins/a.cnt_total) as ratio from table1 a
inner join table2 b on a.course_id = b.course_id
inner join courses cs on a.course_id = cs.course_id문자열 데이터 다뤄보기
1) 문자열 쪼개보기 (SUBSTRING_INDEX(쪼갤 것, 기준, 1 or -1)
- 이메일에서 아이디만 가져와보기
select user_id, email, SUBSTRING_INDEX(email, '@', 1) from users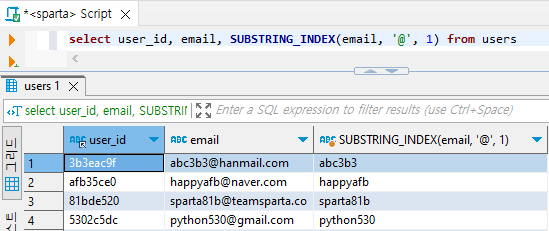
- 이메일에서 이메일 도메인만 가져와보기
select user_id, email, SUBSTRING_INDEX(email, '@', -1) from users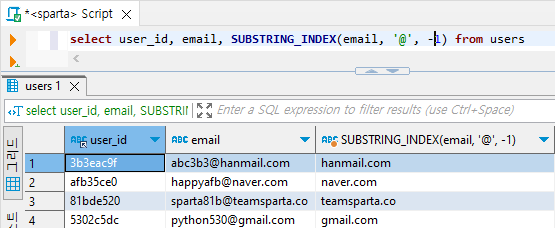
2) 문자열 일부만 출력하기 (SUBSTRING(쪼갤 것, 시작포인트, 몇 개까지))
- orders 테이블에서 날짜까지 출력하게 해보기
select order_no, created_at, substring(created_at,1,10) as date from orders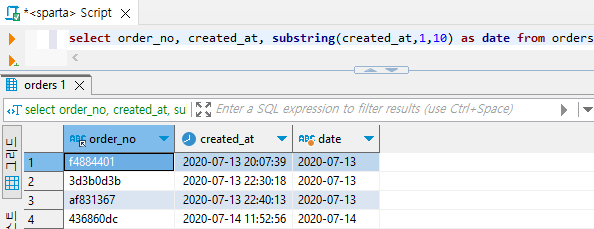
- 일별로 몇 개씩 주문이 일어났는지 살펴보기
# date로 group by를하고 count 해주면 일별 주문량이 나온다.
select substring(created_at,1,10) as date, count(*) as cnt_date from orders
group by date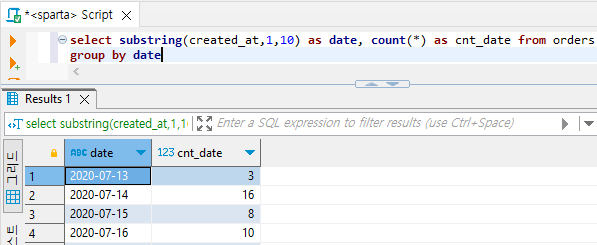
CASE(조건문): 경우에 따라 원하는 값을 새 필드에 출력 (case when 조건 then 내용 else 내용 End)
- 포인트 보유액에 따라 다르게 표시해주기
select * from point_users puselect user_id, point from point_users pu# 포인트 구간별로 멘트를 출력해주자.
select user_id, point,
(case when pu.point > 10000 then '잘 하고 있어요!'
else '조금 더 달려주세요!'END) as msg
from point_users pu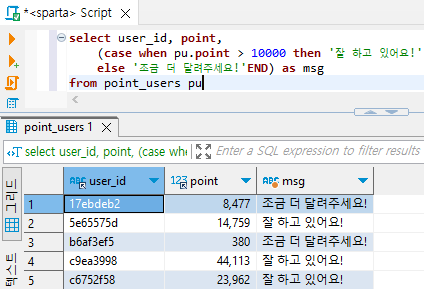
- Case에 Subquery를 이용해서 통계내기
select pu.user_id, pu.point,
(case when pu.point >= 10000 then '1만 이상'
when pu.point >= 5000 then '5천 이상'
else '5천 미만' END) as level
from point_users pu
# 이 쿼리문을 subquery문으로 두면 원하는 값을 select하여 뽑아올 수 있다.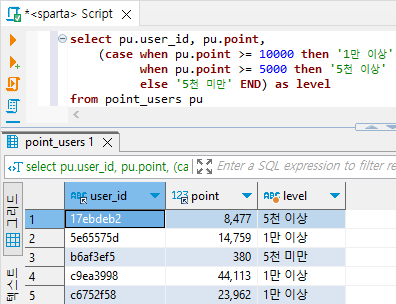
# level별 유저 수 알아보기
select a.level, count(user_id) as cnt_user from (
select pu.user_id, pu.point,
(case when pu.point >= 10000 then '1만 이상'
when pu.point >= 5000 then '5천 이상'
else '5천 미만' END) as level
from point_users pu
) a
group by a.level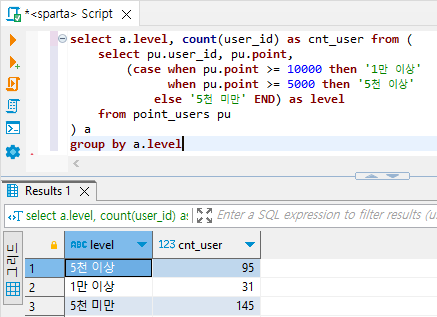
# with 절 이용
with table1 as (
select pu.user_id, pu.point,
(case when pu.point >= 10000 then '1만 이상'
when pu.point >= 5000 then '5천 이상'
else '5천 미만' END) as level
from point_users pu
)
select a.level, count(user_id) as cnt_user from table1 a
group by a.levelSQL 문법 연습
1) 평균 이상 포인트를 가지고 있으면 '잘 하고 있어요' / 낮으면 '열심히 합시다!' 표시하기 (CASE 문법 사용, CASE 안에서 Subquery로 평균을 계산하여 비교)
select * from point_users puselect pu.user_id, pu.point from point_users puselect pu.user_id, pu.point,
(case when point >= (subquery) then '잘 하고 있어요'
else '열심히 합시다!' end) as msg
from point_users puselect pu.user_id, pu.point,
(case when point >= (select avg(point) from point_users pu2 ) then '잘 하고 있어요!'
else '열심히 합시다!' end) as msg
from point_users pu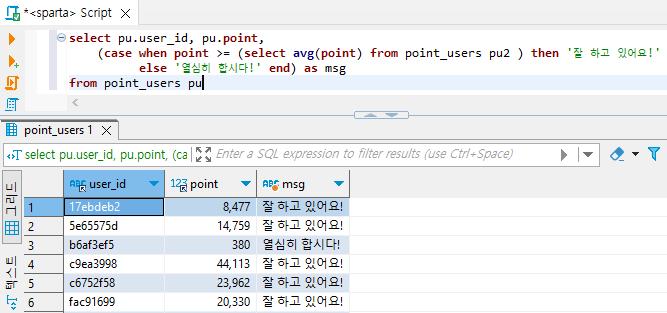
2) 이메일 도메인별 유저의 수 세어보기 (SUBSTRING_INDEX와 Group by 사용)
select * from users select email from users # 도메인
select SUBSTRING_INDEX(email, '@', -1) as domain from users
# 도메인을 도출한 위 쿼리문에서 group by로 묶어준 후 count를 하면 도메인 별 유저 수를 구할 수 있다.
select domain, count(*) as cnt from (
select SUBSTRING_INDEX(email, '@', -1) as domain from users
) a
group by domain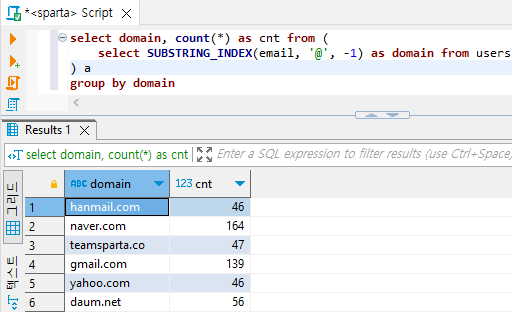
3) '화이팅'이 포함된 오늘의 다짐만 출력해보기 (like)
select * from checkins
where comment like '%화이팅%'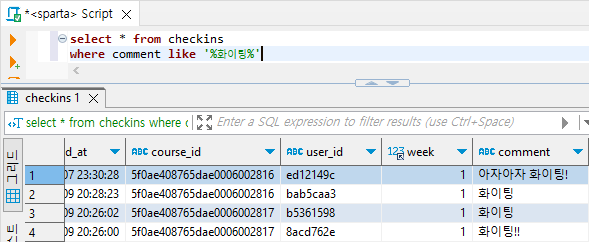
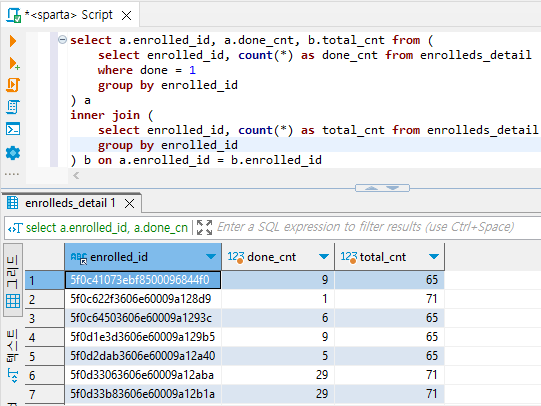
4) 수강등록정보(enrolled_id)별 전체 강의 수와 들은 강의의 수 출력해보기 (subquery 두 개를 만들어놓고, inner join)
select * from enrolleds_detail
전체 강의 (enrolled_id 묶어서 세주면 됨)
들은 강의 (done = 1)# 들은 강의
select enrolled_id, count(*) as done_cnt from enrolleds_detail
where done = 1
group by enrolled_id
# 전체 강의
select enrolled_id, count(*) as total_cnt from enrolleds_detail
group by enrolled_id# 위 두 쿼리문을 subquery로 inner join 해준다. (key = enrolled_id)
select a.enrolled_id, a.done_cnt, b.total_cnt from (
select enrolled_id, count(*) as done_cnt from enrolleds_detail
where done = 1
group by enrolled_id
) a
inner join (
select enrolled_id, count(*) as total_cnt from enrolleds_detail
group by enrolled_id
) b on a.enrolled_id = b.enrolled_id
- with절로도 가능
with table1 as (
select enrolled_id, count(*) as done_cnt from enrolleds_detail ed
where done = 1
group by enrolled_id
), table2 as (
select enrolled_id, count(*) as total_cnt from enrolleds_detail ed
group by enrolled_id
)
select a.enrolled_id,
a.done_cnt,
b.total_cnt
from table1 a
inner join table2 b on a.enrolled_id = b.enrolled_id- 진도율 출력해보기(들은 강의의 수 / 전체 강의 수)
with table1 as (
select enrolled_id, count(*) as done_cnt from enrolleds_detail ed
where done = 1
group by enrolled_id
), table2 as (
select enrolled_id, count(*) as total_cnt from enrolleds_detail ed
group by enrolled_id
)
select a.enrolled_id,
a.done_cnt,
b.total_cnt,
round((a.done_cnt/b.total_cnt),2) as ratio
from table1 a
inner join table2 b on a.enrolled_id = b.enrolled_id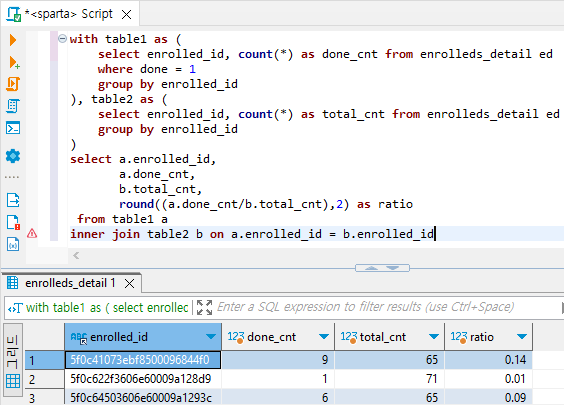
더 간단하고 직관적인 식으로도 표현이 가능하다.
select enrolled_id,
count(*) as total_cnt
from enrolleds_detail
group by enrolled_id
# 전체 강의 수는 구하기가 간단하다.
# 들은 강의는 done 값이 1인 것들이니 이것을 sum으로 더해줘도 된다.
select enrolled_id,
sum(done) as done_cnt,
count(*) as total_cnt,
round(sum(done)/count(*),2) as ratio
from enrolleds_detail
group by enrolled_id