네이밍 컨벤션
Pascal : PythonIsVeryGood / 각 단어를 대문자로 구별
Camel : pythonIsVeryGood / Pascal과 동일하지만, 첫 문자가 소문자로 시작
Snake : python_is_very_good / 각 단어를 언더바( _ )로 구분, 모든 문자 소문자
Class를 네이밍할 때는 Pascal 표기법
변수 / 함수를 네이밍할 때는 Snake 표기법
함수 - def hello_world():
변수 - hello_world = "123"
클래스 - class HelloWorld():
대문자와 언더바는 함께 혼용이 안됨.- 클래스, 함수, 변수 등을 네이밍할 때는 이름만 보고 해당 코드가 어떤걸 의미하는지 추측할 수 있어야 한다.
PIE = 3.14 상수를 표현할 때는 예외적으로 모든 문자를 대문자로 표현
PIE = 1
print(PIE) // 1 코드는 정상 실행된다. 문법이 틀린건 아니나 네이밍컨벤션이 틀림.
NUMBER_LIST // 긴 단어의 상수를 선언한다고 하면, 원래는 대문자와 언더바는 혼용이 안되지만 예외적으로 snake와 혼합해서 대문자 언더바로 쓴다.
numbers = [1,2,3,4] list를 표기할 때는 복수로 표현
(변수 이름이 numbers인 것을 보고 숫자가 들어있겠구나 생각)
(혹은 number_list와 같이 표현)
(for number in numbers: 반복문 사용 시 가독성을 늘릴 수 있음)
def add(a, b): return a + b 함수를 네이밍할 때는 해당 함수가 어떤 역할을 하는지 표현예시)
# django rest framework의 serializer 코드 일부
class ModelSerializer(Serializer): // Paskal
def validate(self, attrs): // snake(변수 / 함수)
"""
입력 된 데이터의 유효성을 검증하는 메소드입니다.
Args:
attrs : 검증할 데이터(attribute)입니다.
"""
def create(self, validated_data): // snake(변수 / 함수)
"""
유효성 검증(validate) 후 instance를 생성할 때 사용되는 메소드입니다.
Args:
validated_data : validate의 attrs에서 검증 된 데이터들이 담깁니다.
"""
def update(self, instance, validated_data): // snake
"""
생성 된 instance를 수정할 때 사용되는 메소드입니다.
Args:
instance : 수정 할 대상입니다.
validated_data : validate의 attrs에서 검증 된 데이터들이 담깁니다.
"""변수 유효 범위(variable scope)
1. 지역 변수(local variable) : 함수 내부에서 선언되며 다른 함수에 영향을 끼치지 않는다.
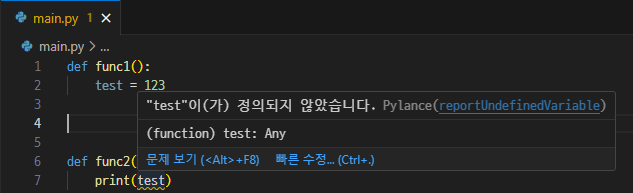
def func1():
test = 123 # 함수 내에서 test라는 지역 변수를 선언 / 선언된 함수 내에서만 유효함.
def func2():
print(test) # func2에서는 test라고 하는 변수가 선언된건지 안된건지 알 수가 없다. func1에서 생성된 지역 변수는 funt2에서 접근할 수 없다.
func1()
func2()
"""
Traceback (most recent call last):
File "c:/Users/jjoonnoo/Desktop/독수리/main.py", line 10, in <module>
func2()
File "c:/Users/jjoonnoo/Desktop/독수리/main.py", line 7, in func2
print(test)
NameError: name 'test' is not defined
"""2. 전역 변수(global variable) : 함수 밖에서 선언되며 어디서든 접근할 수 있다.
test = 123 # 함수 밖에서 test라는 전역 변수 생성
def func1():
pass
# test = 123
def func2():
print(test)# 전역 변수는 자유롭게 접근할 수 있다.
func1()
func2() # 함수를 실행하면 123이 정상적으로 출력된다.3. 효율성 면에서 보면 변수 선언을 전역 변수로만 하는게 좋은가? NO
- 함수 내에서 전역 변수의 값을 바꾸려 할 경우
test = 123
def func():
test = 456 # 전역 변수의 값이 바뀌는 것이 아닌, 지역 변수로 다시 선언된다.
func()
# 함수 내에서 재할당 된 지역 변수는 전역 변수에 영향을 끼치지 않는다.
print(test) # 456- 전역 변수 사용과 지역 변수 할당을 같이 하는 경우
test = 123
def func():
print(test)
test = 456 # 함수 내에서 선언(재할당)되는 지역 변수는 전역변수의 유무와 상관 없이 함수 내에서만 유효성을 띈다.
func()
"""
Traceback (most recent call last):
File "c:/Users/jjoonnoo/Desktop/독수리/main.py", line 9, in <module>
func()
File "c:/Users/jjoonnoo/Desktop/독수리/main.py", line 5, in func
print(test)
UnboundLocalError: local variable 'test' referenced before assignment
"""
# 에러가 나는 이유는 지역 변수가 선언되기 전 출력하려 했기 때문에 발생한 것이다. test = 123
def func(): # 지역 변수 선언 후 출력하도록 코드를 바꿔주면 에러 없이 456이 출력된다.
test = 456
print(test)
def func2(): # 이 함수 내에서는 지역 변수 선언이 따로 없기 때문에 전역 변수에 할당된 값이 출력된다.
print(test)
func()
func2()
# 456
# 123- 함수 내에서 전역 변수의 값을 바꾸려면? (global 키워드)
# global 키워드를 사용해 함수 내에서 전역 변수를 자유롭게 다시 할당할 수 있다.
test = 123
def func():
global test # 함수에서 test 변수를 다시 할당할 수 있도록 해준다.
test = 456 # global 키워드를 사용했기 때문에 전역 변수의 값이 변경된다.
print(test)
def func2():
print(test)
func()
func2()
# 456
# 456- 전역 변수(& global 키워드)를 권장하지 않는다.
# 코드가 길어질수록 전역 변수로 선언 된 값은 어디서 값이 변했는지 추적하기 어렵고, 문제가 생겼을 때 디버깅을 하기 어려워 지기 때문
test = 123
def func():
return 456 # 2. 변수에 값을 저장하는 것이 아니라 return으로 결과값을 반환하는 방법을 추천.
def func2(value): # 1. 다른 함수의 결과값을 가져와서 사용하고 싶다면,
print(value)
result = func() # 3. 결과값을 return으로 받음.
func2(result) # 4. func()의 결과값을 받아와서 함수에서 출력.
# 456자주 사용되는 모듈 및 패턴
1) type() / 값의 자료형이 어떤 타입인지 확인
integer = 10
float_ = 1.23
string = "hello world!!"
list_ = [1, 2, 3]
tuple_ = (1, 2, 3)
set_ = {1, 2, 3}
dictionary = {"key": "value"}
boolean = True
print(type(integer)) # <class 'int'>
print(type(float_)) # <class 'float'>
print(type(string)) # <class 'str'>
print(type(list_)) # <class 'list'>
print(type(tuple_)) # <class 'tuple'>
print(type(set_)) # <class 'set'>
print(type(dictionary)) # <class 'dict'>
print(type(boolean)) # <class 'bool'># 직접 선언한 변수 : 문제 없음
a = 1
b = '1'
# 특정 모듈을 사용했을 때, 결과값으로 받아오는 경우 : 숫자인지 문자인지 구분하기 어려울 때가 있음
print(a) # 1
print(b) # 1
print(a, type(a)) # 1 <class 'int'>
print(b, type(b)) # 1 <class 'str'>2) split() / string을 이용하여 문자열을 list로 변환하기
# split은 string.split("구분자")로 구성되어 있습니다.
string = "hello/python/world"
string_list = string.split("/") # split() 안에 들어간 값을 기준으로 문자를 나눈다.
print(string_list) # ['hello', 'python', 'world']3) join() / list를 string(문자열)으로 변환하기
# join은 "사이에 들어갈 문자".join(리스트) 로 구성되어 있다.
string_list = ["hello", "python", "world"]
string = "!! ".join(string_list)
print(string) # hello!! python!! world4) replace() / 문자열 바꾸기
# replace는 "변경할 문자".replace("변경 전 문자", "변경 후 문자")로 구성되어 있다.
before_string = "hello world!!!"
after_string = before_string.replace("!", "~") # !를 ~로 변경
print(after_string) # hello world~~~5) pprint() / 코드 예쁘게 출력하기(pretty print)
from pprint import pprint # 임포트 안하면 NameError: name 'pprint' is not defined 이런 에러가 난다.
sample_data = {
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters":
{
"batter":
[
{"id": "1001", "type": "Regular"},
{"id": "1002", "type": "Chocolate"},
{"id": "1003", "type": "Blueberry"},
{"id": "1004", "type": "Devil's Food"}
]
},
"topping":
[
{"id": "5001", "type": "None"},
{"id": "5002", "type": "Glazed"},
{"id": "5005", "type": "Sugar"},
{"id": "5007", "type": "Powdered Sugar"},
{"id": "5006", "type": "Chocolate with Sprinkles"},
{"id": "5003", "type": "Chocolate"},
{"id": "5004", "type": "Maple"}
]
}print(sample_data)
# {'id': '0001', 'type': 'donut', 'name': 'Cake', 'ppu': 0.55, 'batters': {'batter': [{'id': '1001', 'type': 'Regular'}, {'id': '1002', 'type': 'Chocolate'}, {'id': '1003', 'type': 'Blueberry'}, {'id': '1004', 'type': "Devil's Food"}]}, 'topping': [{'id': '5001', 'type': 'None'}, {'id': '5002', 'type': 'Glazed'}, {'id': '5005', 'type': 'Sugar'}, {'id': '5007', 'type': 'Powdered Sugar'}, {'id': '5006', 'type': 'Chocolate with Sprinkles'}, {'id': '5003', 'type': 'Chocolate'}, {'id': '5004', 'type': 'Maple'}]}pprint(sample_data)
# {'batters': {'batter': [{'id': '1001', 'type': 'Regular'},
{'id': '1002', 'type': 'Chocolate'},
{'id': '1003', 'type': 'Blueberry'},
{'id': '1004', 'type': "Devil's Food"}]},
'id': '0001',
'name': 'Cake',
'ppu': 0.55,
'topping': [{'id': '5001', 'type': 'None'},
{'id': '5002', 'type': 'Glazed'},
{'id': '5005', 'type': 'Sugar'},
{'id': '5007', 'type': 'Powdered Sugar'},
{'id': '5006', 'type': 'Chocolate with Sprinkles'},
{'id': '5003', 'type': 'Chocolate'},
{'id': '5004', 'type': 'Maple'}],
'type': 'donut'}6) random / 랜덤한 로직이 필요할 때
# 난수 생성, 임의의 숫자 생성 등 랜덤한(무작위의) 동작이 필요할 때 사용되는 모듈
import random
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
random.shuffle(numbers) # numbers를 무작위하게 섞기
print(numbers) # [2, 8, 6, 4, 3, 7, 1, 5]
random_number = random.randint(1, 10) # 1 ~ 10 사이의 무작위 번호 생성
print(random_number) # 4
# 코드를 실행할 때마다 결과들이 랜덤으로 달라짐.7) time / 시간 다루기
# 파이썬에서 코드의 실행 속도 측정, 코드를 잠시 중지 시키는 등 시간을 다룰 때 사용되는 모듈.
import time
start_time = time.time() # 현재 시간 저장
time.sleep(1) # 1초간 대기
end_time = time.time() # 코드가 종료된 시간 - 코드가 시작된 시간으로 실행 시간 구하기 (단위 : 초)
print(f"코드 실행 시간 : {end_time-start_time:.5f}") # 코드 실행 시간 : 1.004918) datetime / 날짜 다루기
from datetime import datetime, timedelta# 현재 날짜 및 시간 출력
print(datetime.now())
# 2023-08-18 16:13:15.291002 : string이 아니라 <class 'datetime.datetime'>이다. 즉, 문자열을 사용하는 모듈은 못 쓴다
ex1) now = datetime.now()
now = now.split(" ") # AttributeError: 'datetime.datetime' object has no attribute 'split'
ex2) now = str(datetime.now()) # str()로 datetime 클래스를 문자열로 바꿔주면 문자열 조작 모듈들을 사용할 수 있다.
now = now.split(" ")
print(now) # ['2023-08-18', '16:31:16.738347']# datetime의 format code (https://docs.python.org/ko/3/library/datetime.html#strftime-and-strptime-format-codes)
%y : 두 자리 연도 / 20, 21, 22
%Y : 네 자리 연도 / 2020, 2021, 2022
%m : 두 자리 월 / 01, 02 ... 11 ,12
%d : 두 자리 일 / 01, 02 ... 30, 31
%I : 12시간제 시간 / 01, 02 ... 12
%H : 24시간제의 시간 / 00, 01 ... 23
%M : 두 자리 분 / 00, 01 ... 58, 59
%S : 두 자리 초 / 00, 01 ... 58, 59# string(문자열)을 datetime(클래스) 날짜로 변경하기(datetime.strptime(날짜로 변경할 문자열, "날짜 포맷(datetime format code)")
string_datetime = "23/12/25 13:20"
class_datetime = datetime.strptime(string_datetime, "%y/%m/%d %H:%M")
print(class_datetime) # 2023-12-25 13:20:00# datetime(클래스) 날짜를 string(문자열)으로 변환하기(datetime.strftime(문자열로 바꿀 날짜, "날짜 포맷(datetime format code)"))
now = datetime.now()
string_datetime = datetime.strftime(now, "%y/%m/%d %H:%M:%S")
print(string_datetime) # 23/08/18 16:40:49# 3일 전 날짜 구하기 (timedelta : 특정 날짜를 더하고 뺄 수 있음)
three_days_ago = datetime.now() - timedelta(days=3)
print(three_days_ago)
# 2023-08-15 16:43:45.559152 (2023-08-18 16:43:45.559152 - 3일)
three_days_later = datetime.now() + timedelta(days=3)
print(three_days_later)
# 2023-08-21 16:43:45.559152조건문 심화
1) 비교 연산자들을 사용해 값을 비교하고, 결과가 True인지 False인지 판단할 수 있다.
값을 할당할 때('=')
a = 1
값이 일치하는지 비교 ('==')
"a" == "a" # True
"a" == "b" # False
1 == "1" # False, 값은 동일하지만 자료형이 다르기 때문
값이 일치하지 않는지 비교 ('!=')
0 != 1 # True
0 != 0 # False
값이 큰지 작은지 비교 ('>', '<')
5 > 2 # True
1 < 0 # False
1 > 1 # False
값이 크거나 같은지, 작거나 같은지 비교 ('>=', '<=')
1 >= 1 # True
특정 값이 list / tuple / set에 포함되어 있는지 확인 ('in')
4 in [1, 2, 3] # False
1 in (1, 2, 3) # True
# 모든 비교 연산자의 결과는 print()로 확인할 수 있다.
print(1 == 1) # True2) 특정 비교 결과 혹은 값이 True 혹은 False일 경우 실행 될 로직을 정의
if condition: # 조건이 True일 경우
# some code
# not 키워드를 사용할 경우 조건이 False일 때 실행됩니다.
elif not condition: # 조건이 False일 경우
# some code
else: # 위 조건들 중 만족하는게 없을 경우
# some code3) and, or을 사용해 2개 이상의 조건을 복합적으로 사용할 수 있다.
if condition1 and condition2: # 두 조건을 모두 만족할 경우
# some code
elif condition or condition: # 두 조건 중 하나라도 만족할 경우
# some code
else:
# some code4) 비어있는 string, list 등은 분기문에서 False로 판단한다.
empty_string = ""
empty_list = []
if not empty_string:
print("string is empty!!")
if not empty_list:
print("list is empty!!")
# string is empty!!
# list is empty!!
# empty_string과 empty_list는 둘 다 비어있기 때문에 값이 False, boolean 함수로 확인 가능
print(bool(empty_string)) # False
print(bool(empty_list)) # False
# if not은 조건이 False일 때 코드가 실행되기 때문에 출력된 것이다.5) 특정 값이 True인지 False인지는 bool() 함수를 사용해 확인할 수 있다.
print(bool("")) # False
print(bool(0)) # False
print(bool([])) # False
print(bool("sample")) # True
print(bool([1, 2])) # True
print(bool(1)) # True
print(bool(-1)) # True 0이 아닌 숫자는 True로 판단
print(bool([])) # False
print(bool([""])) # True 빈 string이 요소로 들어있음6) any() 혹은 all() 함수를 사용해 여러 값들에 대한 조건을 판단할 수 있다.
# all() : 요소들이 모두 True일 경우 True 리턴
if all([True, True, True, False, True]):
print("1. 통과!") # False가 존재하기 때문에 분기문을 통과하지 못함
# any() : 요소들 중 하나라도 True일 경우 True 리턴
if any([False, False, False, True, False]):
print("2. 통과!") # True가 1개 이상 존재하기 때문에 분기문을 통과함
# 2. 통과!함수의 인자와 리턴 타입
1) 리턴 타입에 따른 활용 방법
python에서 사용되는 함수들은 비슷해 보여도 사용 방법이나 리턴 타입들이 다를 수 있다. 그래서 특정 기능을 사용할 때 해당 기능의 결과물이 어떤 데이터를 리턴하는지 알아야한다. 예를 들어, list를 정렬하기 위해서 sorted 함수나 list.sort() 함수를 사용하는데 두 함수는 사용 방법이 다르다.
list.sort()
sample_list = [3, 2, 4, 1, 5]
sample_list.sort() # return data 없이 list 자체를 정렬시켜줌
print(sample_list) # [1, 2, 3, 4, 5]sorted
sample_list = [3, 2, 4, 1, 5]
sorted_list = sorted(sample_list) # 정렬된 list를 return해주기 때문에 따로 변수에 담아야함
print(sorted_list) # [1, 2, 3, 4, 5]잘못된 방법
sample_list = [3, 2, 4, 1, 5]
sorted_list = sample_list.sort() # .sort()의 return data는 None
print(sorted_list) # None
sample_list = [3, 2, 4, 1, 5]
sorted(sample_list)
print(sample_list) # [3, 2, 4, 1, 5] 정렬이 안 된 상태로 출력됨2) 내가 사용하는 코드의 리턴 타입을 확인하는 방법
- 구글에 'python 함수명' 검색
- docstring 확인
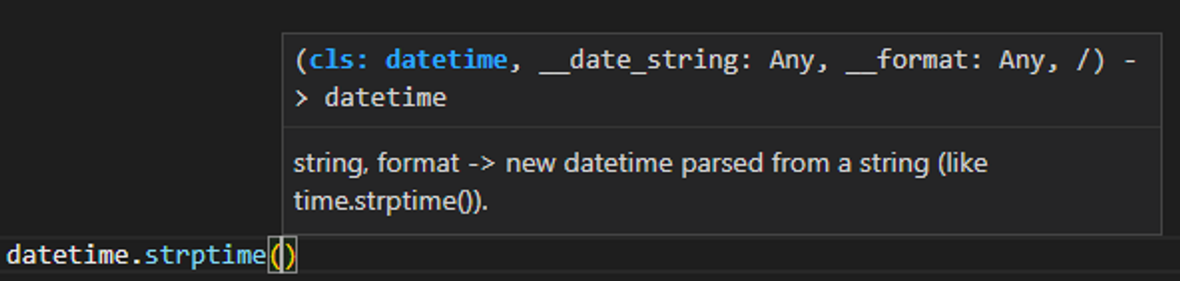
- 함수 구현 코드 확인 : vscode에서 사용하는 함수를 ctrl + click 하면 구현 코드를 확인할 수 있다.
try / exception을 활용한 에러 처리
1) python에서 에러가 발생했을 때 코드가 중지되는데 try / except 문법을 사용해 계속 실행시킬 수 있다.
number = "num"
# number = int(number) # number 변수를 string(문자열)에서 integer(정수)로 바꾸려고 하면 오류가 나면서 실행이 안된다.
# ValueError: invalid literal for int() with base 10: 'num'
# 숫자로 바꿀 수 없는 문자열을 숫자로 바꾸려고 했기 때문
try: # try 구문 안에서 에러가 발생할 경우 except로 넘어감
number = int(number) # "num"을 숫자로 바꾸는 과정에서 에러 발생
except: # 에러가 발생했을 때 처리
print(f"{number}은(는) 숫자가 아닙니다.")
# num은(는) 숫자가 아닙니다.2) 에러 종류에 따라 다른 로직 처리
number = input()
try:
int(number)
10 / number (나누기)
except ValueError: # int로 변환하는 과정에서 에러가 발생했을 떄
print(f"{number}은(는) 숫자가 아닙니다.")
except ZeroDivisionError: # 0으로 나누면서 에러가 발생했을 때
print("0으로는 나눌수 없습니다.")
except Exception as e: # 위에서 정의하지 않은 에러가 발생했을 때(권장하지 않음 : 나중에 에러를 파악할 때 추적이 어려울 수 있어서 구체적으로 적어주는 것이 좋음) / Exception에 대한 내용을 e에 할당하고 {e}에 출력
print(f"예상하지 못한 에러가 발생했습니다. error : {e}")
# number = "a" -> a은(는) 숫자가 아닙니다.
# number = 0 -> 0으로는 나눌수 없습니다.
# number = "1" -> 예상하지 못한 에러가 발생했습니다. error : unsupported operand type(s) for /: 'int' and 'str'(문자와 숫자의 나눗셈은 지원하지 않는다.)
# except 문법 또한 if / elif와 같이 연달아서 작성할 수 있다.패킹과 언패킹(요소들을 묶어주거나 풀어주는 것)
패킹은 인자로 받은 여러개의 값을 하나의 객체로 합쳐서 받을 수 있도록
packing은 여러개의 객체를 하나의 객체로 합쳐주었습니다
unpacking은 여러개의 객체를 포함하고 있는 하나의 객체를 풀어줍니다.
1) list에서의 활용(위치인자 패킹/언패킹 : * )
# 입력 값의 합을 출력하는 함수
# 입력 받는 인자의 갯수에 제한을 두지 않을 때 (함수가 받는 인자의 갯수에 제한을 둘 때는 num1, num2, ..와 같은 식으로 넣어주면 된다.)
def add(*args): # add 함수를 사용할 때 받는 인자들을 모두 위치 인자 형식(num1, num2, ...)으로(*) 변수 arg에 집어넣겠다.(= 패킹)
result = 0
for i in args:
result += i
return result
numbers = [1, 2, 3, 4]
print(numbers) # [1, 2, 3, 4]
print(*numbers) # 1 2 3 4
# *numbers의 '*'는 numbers 리스트의 중괄호를 풀어준다.
print(add(numbers)) # TypeError: unsupported operand type(s) for +=: 'int' and 'list' 정수와 리스트의 연산이 불가능하다.
# add함수에게 [1, 2, 3, 4]를 위치 인자로 변환시키지 않고 통쨰로 줬고 함수가 실행되면서 numbers리스트 인자 하나와 result = 0(숫자)와 더하는 것이 안되는 것이다.
print(add(*numbers)) # (= print(add*[1, 2, 3, 4]) = print(add(1, 2, 3, 4)))
# *numbers의 '*'는 numbers 리스트를 위치 인자 형식(1, 2, 3, 4)으로 풀어서 add함수에 준다.(= 언패킹)
# 10 (result output)
# print(args) = (1, 2, 3, 4) 튜플 형식으로 저장됨. (add함수로 numbers 리스트를 위치 인자 형식(1, 2, 3, 4)으로 풀어서 args 변수에 줬기 때문이다.)
# print(type(args)) = # <class 'tuple'>
print(add()) # 0
print(add(1)) # 1
print(add(5,6,7)) # 18
print(add*[5,6,7]) # 182) dictionary에서의 활용(키워드 인자 패킹/언패킹 : ** )
def sample(**kwargs): # sample 함수를 사용할 때 받는 인자들을 모두 키워드 인자 형식(a = "py", c = "on", b = "th")으로(**) kwargs에 집어넣고 딕셔너리로 만들겠다. (= 패킹)
sample_dict = {
"key" : "value",
"key2" : "value2",
"key3" : "value3"
}
print(sample_dict) # {'key': 'value', 'key2': 'value2', 'key3': 'value3'}
print(**sample_dict) # TypeError: 'key' is an invalid keyword argument for print() 오류 원인을 모르겠다.
print(sample(sample_dict)) # TypeError: sample() takes 0 positional arguments but 1 was given
# 키워드 인자로 변환시키지 않아서 sample함수에게 {"key" : "value", "key2" : "value2", "key3" : "value3"}를 통째로 하나의 위치 인자로 보내줬기 때문에 에러가 발생
print(sample(**sample_dict)) # (= sample(key = "value", key2 = "value2", key3 = "value3")(= 언패킹)
# {"key" : "value", "key2" : "value2", "key3" : "value3"}# 1
def sample(*kwargs):
print(kwargs) # ({'key': 'value', 'key2': 'value2', 'key3': 'value3'},)
# sample_dict를 통째로 위치 인자 1개로 sample함수로 보내고 kwargs에 받아서 출력
sample_dict = {
"key" : "value",
"key2" : "value2",
"key3" : "value3"
}
sample(sample_dict)
# 2
def sample(**kwargs):
print(kwargs) # {'a': {'key': 'value', 'key2': 'value2', 'key3': 'value3'}}
# sample함수에 키워드 인자 형식으로 sample함수로 보내서 변수 kwargs에 받아서 출력
sample_dict = {
"key" : "value",
"key2" : "value2",
"key3" : "value3"
}
sample(a=sample_dict)def set_profile(**kwargs):
profile = {}
profile["name"] = kwargs.get("name", "-") # kwargs 딕셔너리에 key "name"이 있으면 그 Value를 보여주고, 없으면 "-"를 보여줌.
profile["gender"] = kwargs.get("gender", "-")
profile["birthday"] = kwargs.get("birthday", "-")
profile["age"] = kwargs.get("age", "-")
profile["phone"] = kwargs.get("phone", "-")
profile["email"] = kwargs.get("email", "-")
return profile
user_profile = {
"name": "lee",
"gender": "man",
"age": 32,
"birthday": "01/01",
"email": "python@sparta.com",
}
print(set_profile(user_profile))
# (=
profile = set_profile(
name="lee",
gender="man",
age=32,
birthday="01/01",
email="python@sparta.com",
))
# result print
{
'name': 'lee',
'gender': 'man',
'birthday': '01/01',
'age': 32,
'phone': '-',
'email': 'python@sparta.com'
}def sample(a, b, *args, **kwargs):
print(a)
print(b)
print(args)
print(kwargs)
sample(1, 2, 3, 4, 5, 6, test="a", key="abc", test_key="test_value")
#
1
2
(3, 4, 5, 6)
{'test': 'a', 'key': 'abc', 'test_key': 'test_value'}class 심화
파이썬에서 class는 과자틀을 만드는 것. 과자 틀을 이용해서 찍어낸 쿠키가 인스턴스.
1) class의 init 함수 : class의 인스턴스를 생성하는 과정에서 무조건 실행되는 함수.
# class에 __init__메소드를 사용할 경우 인스턴스 생성 시 해당 메소드가 실행된다.
class CookieFrame():
def __init__(self, name):
print(f"생성 된 과자의 이름은 {name} 입니다!")
self.name = name
cookie1 = CookieFrame("Mint")
cookie2 = CookieFrame("Lemon")
cookie3 = CookieFrame()
print(cookie1.name) # 생성 된 과자의 이름은 Mint 입니다!
print(cookie2.name) # 생성 된 과자의 이름은 Lemon 입니다!
print(cookie3.name) # TypeError: __init__() missing 1 required positional argument: 'name' / init 함수에서 name이라는 인자로 받고 있는데 입력된 인자가 없어서 에러가 발생
# 인자가 입력되지 않았을 경우에도 함수가 실행되길 원하면 init함수의 name인자에 고정 값을 지정해주면 된다.
class CookieFrame():
def __init__(self, name="defalutname"):
print(f"생성 된 과자의 이름은 {name} 입니다!")
self.name = name
cookie3 = CookieFrame()
print(cookie3.name) # 생성 된 과자의 이름은 defalutname 입니다!
# 모든 종류의 함수에서 활용 가능하다.2) python의 class 상속
- 클래스를 생성할 때 다른 클래스에 선언된 변수, 메소드 등의 기능들을 가져와 사용할 수 있도록 해주는 기능
- 동일한 코드를 여러 클래스에서 조금씩 수정해 사용하거나 모듈에 내장되어 있는 클래스를 변경할 때 주로 사용
- 부모(parents) 혹은 슈퍼(super) 클래스 : 상속 해주는 클래스
- 자식(child) 혹은 서브(sub) 클래스 : 상속 받는 클래스
3) 상속 받은 클래스를 기반으로 새로운 클래스 만들기

class Monster():
hp = 100
alive = True
def damage(self, attack): # self는 내가 받은 attack은 내가 받은 데미지
self.hp = self.hp - attack
if self.hp < 0:
self.alive = False
def status_check(self): # 죽었는지 살았는지
if self.alive( == True):
print('살아있다')
else:
print('죽었다')
m1 = Monster()
m1.damage(150)
m1.status_check() # 죽었다.
m2 = Monster()
m2.damage(90)
m2.status_check() # 살았다.
# 자체적으로 관리가 가능
# m1, m2는 인스턴스- 몬스터 클래스를 선언하고 instance를 생성해봤는데 여기서 불 속성, 얼음 속성 등 다양한 속성을 가진 몬스터를 만들기 위해서 상속을 사용하면 코드를 간소화 시킬 수 있다.
## 상속을 사용하지 않는 경우
class FireMonster():
def __init__(self, hp):
self.hp = hp
def attack(self, damage):
self.hp -= damage
def status_check(self):
print(f"monster's hp : {self.hp}")
class IceMonster():
def __init__(self, hp):
self.hp = hp
def attack(self, damage):
self.hp -= damage
def status_check(self):
print(f"monster's hp : {self.hp}")
class WindMonster():
def __init__(self, hp):
self.hp = hp
def attack(self, damage):
self.hp -= damage
def status_check(self):
print(f"monster's hp : {self.hp}")
# attack이나 status_check 함수들이 중복으로 들어가게 된다.
# 코드 관리가 어렵고 보기도 어렵다.## 상속을 사용할 경우
class Monster(): # 고정. 건들지 않음.
def __init__(self, hp):
self.hp = hp
def attack(self, damage):
self.hp -= damage
def status_check(self):
print(f"monster's hp : {self.hp}")
class FireMonster(Monster): # class Monster을 상속받음. (class Monster : parents or super class / class FireMonster : child or sub class)
def __init__(self, hp):
self.attribute = "fire"
super().__init__(hp) # super()를 사용하면 부모 클래스의 코드(__init__함수 : self.hp = hp코드)를 그대로 사용할 수 있다.
# 부모 클래스에 존재하는 코드 중 변경하고 싶은 부분이 있으면 메소드(함수)를 overriding 한다.
def status_check(self):
print(f"fire monster's hp : {self.hp}")
class IceMonster(Monster):
def __init__(self, hp):
self.attribute = "ice"
super().__init__(hp)
def status_check(self):
print(f"ice monster's hp : {self.hp}")
fire_monster = FireMonster(hp=100) # FireMonster 클래스에는 attack 메소드가 없지만
# 부모 클래스에서 상속받았기 때문에 별도의 선언 없이 사용 가능하다.
fire_monster.attack(20)
fire_monster.status_check()
ice_monster = IceMonster(hp=200)
ice_monster.attack(50)
ice_monster.status_check()
# fire monster's hp : 80
# icd monster's hp : 1504) 상속 받은 클래스의 특정 코드를 변경해 사용하기
## 다른 사람이 만든 모듈의 계산기 코드를 사용하고 있다고 가정
class Calc:
def _print_zero_division_error(self):
print("can't be division by zero")
def plus(self, num1, num2):
...
def minus(self, num1, num2):
...
def divide(self, num1, num2):
if num2 == 0:
self._print_zero_division_error()
return False
...
def multiply(self, num1, num2):
...
calc = Calc()
calc.divide(5, 0)
# can't be division by zero
# 이 멘트를 한글로 출력하고 싶다고 해서 모듈의 코드는 건드리지 않는 것이 좋다.
# 이때 상속을 활용하면 모듈 내 코드를 변경하지 않고 코드를 수정할 수 있다.
class CustomCalc(Calc): # Calc라는 부코 클래스를 상속 받음
def _print_zero_division_error(self):
print("0으로는 나눌 수 없습니다.") # 코드 변경을 원하는 부분에 overriding 한다.
calc = CustomCalc() #
calc.divide(5, 0)
# 0으로는 나눌 수 없습니다.
class 객체(object)
1) 객체란?
Python에서 class는 과자 틀, class를 사용해서 만들어진 과자는 인스턴스라고 했다. 객체는 인스턴스와 동일한 용어이다.
CookieFrame class를 사용해 생성된 cookie를 "객체" 혹은 "CookieFrame의 인스턴스"라고 표현한다.
FireMonster class를 사용해 생성된 fire_monster는 "객채" 혹은 "FireMonster의 인스턴스"
2) 객체를 사용하는 방법
## list, dict와 같은 자료형 데이터를 생성하고 활용했던 것들이 모두 해당 클래스의 객체를 생성하고 메소드를 활용하는 과정이다.
sample_list = [1, 2, 3, 4]
sample_dict = {"key": "value"}
print(type(sample_list)) # <class 'list'>
print(type(sample_dict)) # <class 'dict'>
sample_list.sort() # list 클래스의 sort 메소드 사용
# FireMonster 클래스
fire_monster.attack(20) # Monster 클래스의 attack 메소드 사용3) datetime 모듈에서 객체 활용해보기
from datetime import datetime
now = datetime.now() # 현재 시간이 담긴 datetime의 객체(object) 생성
print(type(now)) # <class 'datetime.datetime'>객체에서 사용 가능한 메소드들은 함수의 리턴 타입을 확인하는 방법과 동일하게 1. 검색, 2. docstring, 3. 구현 코드(함수 Ctrl + click)
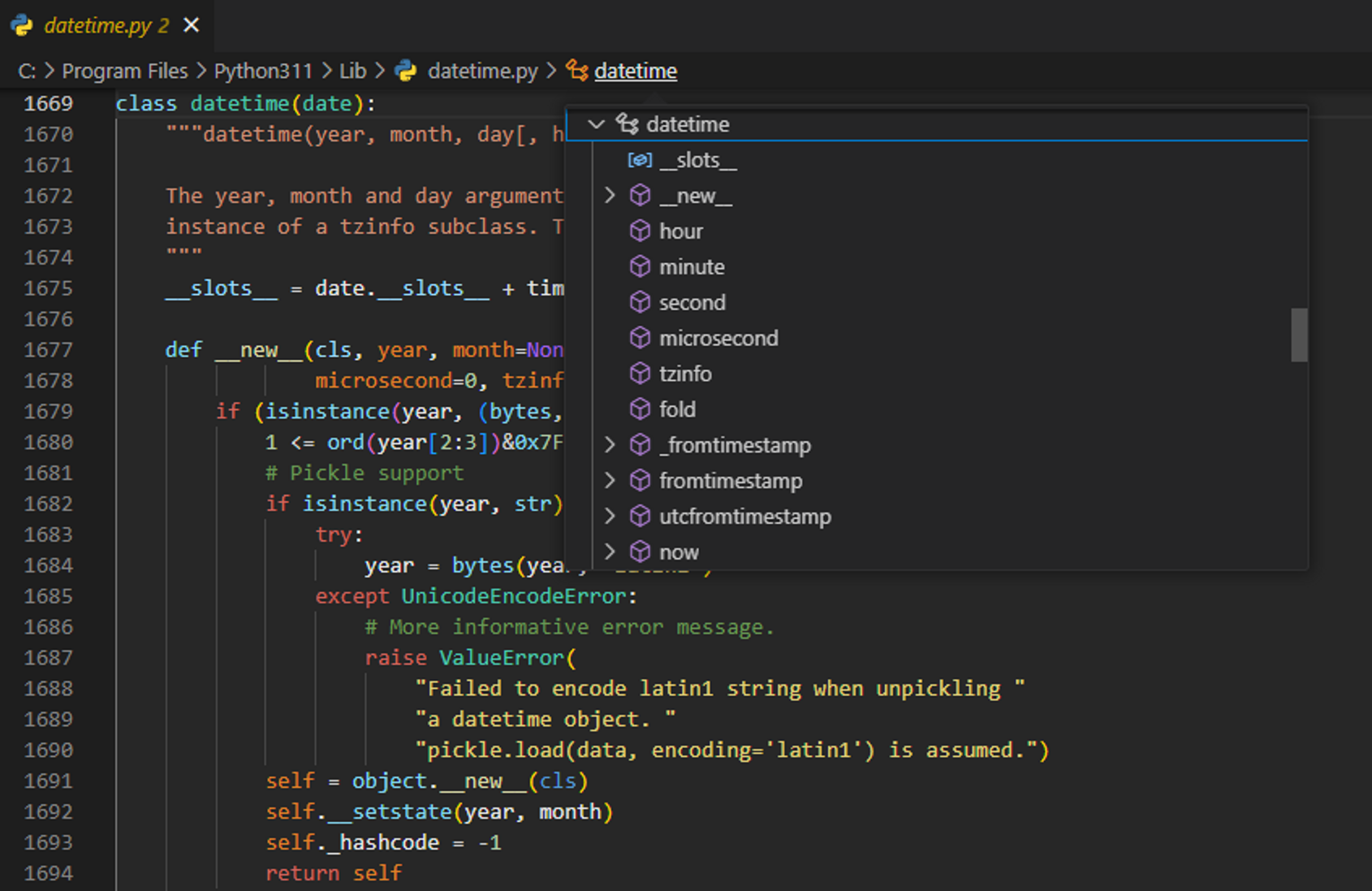
등을 확인하여 찾을 수 있다.
구현부 코드들을 찾아서 다른 사람들이 짜놓은 코드들을 보다보면 좋은 공부가 될 것이다.
정규표현식(regex : regular expression)
1) 정규표현식이란?
- 문자열이 특정 패턴과 일치하는지 판단하는 형식 언어
- 사용자가 입력한 이메일이 유효한 이메일인지, 유효한 핸드폰 번호를 입력했는지, 대문자로 시작하고 숫자로 끝나는 패턴의 단어가 몇번 반복되는지 등 다양한 패턴을 지정하고 검증할 수 있다.
2) 정규표현식 예제 (이메일 형식을 검증)
## 유효한 이메일인지 판단하는 최소한의 패턴
1. 숫자, 알파벳 대/소문자, 일부 특수문자( - _ . )를 조합한 문자로 시작
2. 문자열 중간에는 @가 반드시 1개 포함되어 있어야 함.
3. @ 이후에는 숫자, 알파벳 대/소문자, 일부 특수문자( - _ . )를 조합한 문자가 들어감.
4. 3번 문자 이후에는 .이 한 개 이상 포함되어 있어야 함.
5. 마지막 . 이후에는 2 ~ 4글자의 숫자, 알파벳 대/소문자, 일부 특수문자( - _ )를 조합한 문자 포함되어 있어야 함.## 정규표현식 없이 이메일 검증
from pprint import pprint
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
number = "0123456789"
special_char = "-_."
def verify_email(email):
# 이메일에 @가 한개 포함되어 있는지 확인
if email.count("@") != 1:
return False
# @를 기준으로 사용자명과 도메인을 분리
username, domain = email.split("@")
# username이 1자 이상인지 확인
if len(username) < 1:
return False
# 도메인에 한개 이상의 .이 포함되어 있는지 확인
if domain.count(".") < 1:
return False
# username에 알파벳, 숫자, 허용된 특수문자 이외의 문자가 포함되어 있는지 확인
if not all([x in alphabet + number + special_char for x in username]):
return False
# domain에 알파벳, 숫자, 허용된 특수문자 이외의 문자가 포함되어 있는지 확인
if not all([x in alphabet + number + special_char for x in domain]):
return False
# 마지막 .을 기준으로 도메인을 분리
_, last_level_domain = domain.rsplit(".", 1)
# 마지막 레벨의 도메인의 길이가 2~4글자인지 확인
if not 2 <= len(last_level_domain) <= 4:
return False
# 모든 검증이 완료되면 True를 리턴
return True
test_case = [
"apple", # False
"sparta@regex", # False
"$parta@regex.com", # False
"sparta@re&ex.com", # False
"sparta@regex.com", # True
"sparta@regex.co.kr", # True
"sparta@regex.c", # False
"sparta@regex.cooom", # False
"@regex.com", # False
]
result = [{x: verify_email(x)} for x in test_case]
pprint(result)## 정규표현식을 사용해 이메일 검증 : 코드간소화
from pprint import pprint
import re # (regex) 파이썬에서 정규표현식을 사용하기 위해 기본적으로 import함.
# rstring : backslash(\)를 문자 그대로 표현
# ^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$ : 이메일 검증을 위한 정규표현식 코드 -> 이 식의 순서와 조건을 맞춰야함.
email_regex = re.compile(r"^[\w\.-] + @([\w-]+\.) + [\w-]{2,4}$")
# \w : 알파벳 소문자, 대문자, 숫자, 언더바(_)
# \. : .
# - : -
def verify_email(email):
return bool(email_regex.fullmatch(email))
# 정규표현식 없이 만든 코드에서는 verify_email이라는 함수 안에 case들을 각각 검증하는 코드가 있었는데,
# 정규표현식으로 만든 코드에는 email_regex라는 변수를 하나 지정해주고,
# boolean함수로 email_regex가 email과 일치하는지 여부를 return해주고 있다.
test_case = [
"apple", # False
"sparta@regex", # False
"$parta@regex.com", # False
"sparta@re&ex.com", # False
"spar_-ta@regex.com", # True
"sparta@regex.co.kr", # True
"sparta@regex.c", # False
"sparta@regex.cooom", # False
"@regex.com", # False
]
result = [{x: verify_email(x)} for x in test_case]
pprint(result)3) 정규표현식 코드를 짜는 방법
- 이미 만들어져 있고, 검증 된 정규표현식을 가져다가 사용하는 것을 권장 (https://regexr.com/)
파일과 디렉토리 다루기
1) glob(라이브러리)을 활용한 파일 및 디렉토리 목록 확인
from pprint import pprint # 출력을 예쁘게
import glob
path = glob.glob("./venv/*") # 하위폴더들은 탐색 안함.
pprint(path)
# ['./venv\\Include', './venv\\Lib', './venv\\pyvenv.cfg', './venv\\Scripts']
# ./ : 현재 python 파일이 위치한 폴더
# ./venv/* : venv 폴더 내 모든 폴더 or 파일들
path = glob.glob("./venv/**", recursive=True)
pprint(path)
# ['./venv\\','./venv\\Include','./venv\\Lib','./venv\\Lib\\site-packages','./venv\\Lib\\site-packages\\autopep8-2.0.1.dist-info', ...]
# **은 해당 경로 하위 모든 파일을 의미하며, recursive 플래그와 같이 사용한다.
# recursive를 True로 설정하면 디렉토리 내부의 파일들을 탐색한다.
path = glob.glob("./venv/**/*.py", recursive=True)
pprint(path)
# ['./venv\\Lib\\site-packages\\autopep8.py','./venv\\Lib\\site-packages\\pycodestyle.py','./venv\\Lib\\site-packages\\pip\\__init__.py','./venv\\Lib\\site-packages\\pip\\__main__.py','./venv\\Lib\\site-packages\\pip\\__pip-runner__.py', ...]
# *.py와 같이 작성 시 특정 확장자를 가진 파일들만 볼 수 있다.
# ./venv/**/*.py는 venv 하위 모든 폴더들을 재귀적으로 탐색하며 .py 확장자 파일을 탐색한다.2) open을 활용한 파일 다루기
## python에서는 파일을 편집하거나 생성할 때, with open 문법을 사용할 수 있다.
# open 함수를 사용해 파일 열기
f = open("file.txt", "w", encoding="utf-8")
f.write("파이썬 파일 쓰기 테스트!\n")
f.close()
# open 함수를 실행하면 python 스크립트가 끝날때 까지 파일이 열려있게 된다.
# 파일에 대한 작업이 끝나면 close()를 사용해 파일을 닫아줘야 한다.
# "file.txt" : 파이썬에서 사용할 파일을 지정
# encoding : 파일의 encoding 형식을 지정
-------------------------------------------------
with open("file.txt", "a", encoding="utf-8") as w:
w.write("파이썬 내용 추가 테스트!")
# open을 with와 같이 사용하면 with 구문이 끝날 때 자동으로 파일이 close 된다.
# w 모드 : 파일을 쓰기 모드로 연다. 만약 파일이 없다면 새로 생성
# with를 사용할 떄는 별도로 close 해주지 않아도 된다.
# a 모드 : 기존 내용을 유지한 상태로 추가
------------------------------------------------
with open("file.txt", "r", encoding="utf-8") as r:
print(r.readlines())
# ['파이썬 파일 쓰기 테스트!파이썬 내용 추가 테스트!']
# r 모드 : 파일을 읽기 모드로 연다.
# readlines는 파일의 모든 내용을 list 자료형으로 한번에 읽어들인다.
------------------------------------------------
with open("file.txt", "r", encoding="utf-8") as r:
while True:
line = r.readline()
if not line:
break # 파일 끝까지 텍스트를 읽어들였다면 반복문을 중지.
line = line.strip() # 텍스트의 줄바꿈 문자 제거
print(line)
# 파이썬 파일 쓰기 테스트! 파이썬 내용 추가 테스트!
더 많은 mode의 종류 : https://docs.python.org/ko/3/library/functions.html?highlight=open#open
itertools
1) itertools란?
효율적인 루핑을 위한 이터레이터를 만드는 함수 : 특정 패턴이 무한하게 반복되는 배열을 만들거나 배열의 값을 일괄적으로 계산하는 등의 작업을 할 수 있음. 사용할 모듈을 임포트하고 안에 데이터만 넣어주면 알아서 계산해줌. 딱히 모듈들을 외울 필요는 없고 필요할 때 찾아보면 됨.
(https://docs.python.org/ko/3/library/itertools.html)
2) 조합형 이터레이터 - 데카르트곱 구하기
from itertools import product # 데카르트곱을 구하기 위해 itertools의 product 모듈 import
sample1 = ["A", "B", "C", "D", "E"]
sample2 = [1, 2, 3, 4]
# 결과물을 표처럼 행 / 열을 구분하여 프린트 하기 위해 enumerate 사용
# 단순히 데카르트곱만 구하려면 product에 sample들만 넣어도 됨.
for i, v in enumerate(product(sample1, sample2), 1):
print(v, end=" ")
if i % len(sample2) == 0:
print("")
#
('A', 1) ('A', 2) ('A', 3) ('A', 4)
('B', 1) ('B', 2) ('B', 3) ('B', 4)
('C', 1) ('C', 2) ('C', 3) ('C', 4)
('D', 1) ('D', 2) ('D', 3) ('D', 4)
('E', 1) ('E', 2) ('E', 3) ('E', 4)
3) 조합형 이터레이터 - 원소의 개수가 n개인 순열
from itertools import permutations
sample = ["A", "B", "C"]
# 원소의 개수가 3개인 순열 출력
for i in permutations(sample, 3):
print(i)
#
('A', 'B', 'C')
('A', 'C', 'B')
('B', 'A', 'C')
('B', 'C', 'A')
('C', 'A', 'B')
('C', 'B', 'A')4) 조합형 이터레이터 - 원소의 개수가 n개인 조합 구하기
from itertools import combinations
sample = ["A", "B", "C"]
# 원소의 개수가 2개인 조합 출력
for i in combinations(sample, 2):
print(i)
#
('A', 'B')
('A', 'C')
('B', 'C')
5) 조합형 이터레이터 - 원소의 개수가 n개인 조합 구하기(중복 허용)
from itertools import combinations_with_replacement
sample = ["A", "B", "C"]
# 중복을 포함한 원소의 개수가 3개인 조합 출력
for i in combinations_with_replacement(sample, 3):
print(i)
#
('A', 'A', 'A')
('A', 'A', 'B')
('A', 'A', 'C')
('A', 'B', 'B')
('A', 'B', 'C')
('A', 'C', 'C')
('B', 'B', 'B')
('B', 'B', 'C')
('B', 'C', 'C')
('C', 'C', 'C')
requests
1) requests란?
파이썬에서 http 통신을 가능하게 해주는 모듈로, beautifulsoup과 함께 웹 크롤링을 하거나 api 통신이 필요할 때 사용된다.
즉, 사용자가 https://www.naver.com 이라는 페이지에 접속했을 때 나오는 페이지를 python에서 requests 모듈을 사용하면 해당 데이터를 웹브라우저 없이 코드로 받아올 수 있다.
requests 요청에는 크게 네가지 종류의 method가 존재
- GET : 데이터 정보 요청
- POST : 데이터 생성 요청
- PUT : 데이터 수정 요청
- DELETE : 데이터 삭제 요청
requests를 요청하면 서버에서는 응답(response)을 내려주며, 응답은 내용(content)와 상태 코드(status code)를 받아오게 된다.
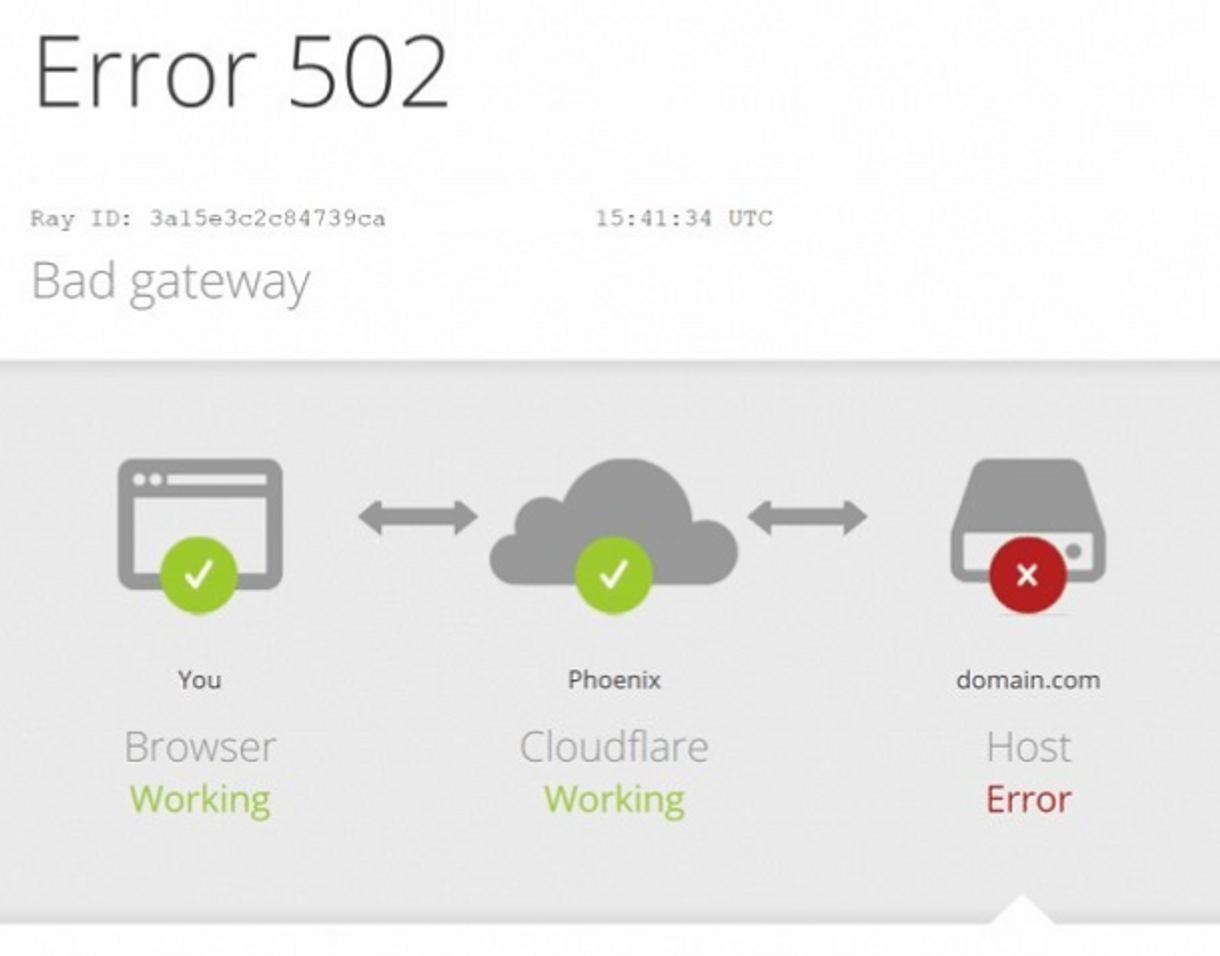
status code : 502
# 자주 사용되는 상태 코드 정보
- 2xx - 성공
- 200 : 정상 통신 완료
- 201 : 정상 생성 완료
- …
- 5xx : 서버 오류
- 500 : 서버에서 처리할 수 없음
- 502 : 게이트웨이에서 잘못된 응답을 받음
- …2) requests 모듈로 request 보내보기 (pip install requests 필수)
https://jsonplaceholder.typicode.com/에 http 통신 요청 보내기
get 요청
import requests
from pprint import pprint
# 통신 할 base url 지정
url = "https://jsonplaceholder.typicode.com/"
# 1번 사용자 정보를 받아오기 위해 users/1 경로에 get 요청
r = requests.get(f"{url}users/1")
pprint({
"contents": r.text,
"status_code": r.status_code,
})
#
{'contents': '{\n'
' "id": 1,\n'
' "name": "Leanne Graham",\n'
' "username": "Bret",\n'
' "email": "Sincere@april.biz",\n'
' "address": {\n'
' "street": "Kulas Light",\n'
' "suite": "Apt. 556",\n'
' "city": "Gwenborough",\n'
' "zipcode": "92998-3874",\n'
' "geo": {\n'
' "lat": "-37.3159",\n'
' "lng": "81.1496"\n'
' }\n'
' },\n'
' "phone": "1-770-736-8031 x56442",\n'
' "website": "hildegard.org",\n'
' "company": {\n'
' "name": "Romaguera-Crona",\n'
' "catchPhrase": "Multi-layered client-server neural-net",\n'
' "bs": "harness real-time e-markets"\n'
' }\n'
'}',
'status_code': 200}
post 요청
import requests
from pprint import pprint
# 통신 할 base url 지정
url = "https://jsonplaceholder.typicode.com/"
# 데이터 생성에 사용될 값 지정
data = {
"name": "sparta",
"email": "sparta@test.com",
"phone": "010-0000-0000",
}
# 사용자를 생성하기 위해 users 경로에 data를 담아 post 요청
r = requests.post(f"{url}users", data=data)
pprint({
"contents": r.text,
"status_code": r.status_code,
})
#
{'contents': '{\n'
' "name": "sparta",\n'
' "email": "sparta@test.com",\n'
' "phone": "010-0000-0000",\n'
' "id": 11\n'
'}',
'status_code': 201}
json (javascript Object Notation)
1) json이란?
- 데이터를 저장하거나 데이터 통신을 할 때 주로 사용.
- key: value 쌍으로 이루어져 있으며, 파이썬의 dictionary 형태와 매우 유사
- 파이썬에서는 json 데이터를 dictionary 데이터로 변경하고, 반대로 dictionary 데이터를 json으로 변경할 수 있다.
2) python에서 json 형태 다뤄보기 (import json 필수)
import json
import requests
# 해당 사이트는 요청에 대한 응답을 json 형태의 문자열로 내려줌.
url = "https://jsonplaceholder.typicode.com/"
r = requests.get(f"{url}users/1")
print(type(r.text)) # <class 'str'>
# 문자열 형태의 json을 dictionary 자료형으로 변경.
response_content = json.loads(r.text)
print(type(response_content)) # <class 'dict'>
# dictionary 자료형이기 때문에 key를 사용해 value를 확인할 수 있다.
print(f"사용자 이름은 {response_content['name']} 입니다.")
# 사용자 이름은 Leanne Graham 입니다.csv (comma-separated values)
1) csv 파일이란?
- 텍스트에 쉼표( , )를 사용해 필드를 구분하며 .csv 확장자를 사용
- 쉼표를 사용해 데이터를 구분한다는 특성 덕분에 텍스트 편집기를 사용해 간단한 csv 파일을 만드는 것도 가능
- 샘플 csv
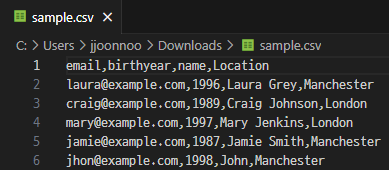
2) csv 파일 읽기
import csv # 파이썬에서 csv 파일을 다루기 위해 모듈 import
csv_path = "sample.csv"
# csv를 list 자료형으로 읽기
csv_file = open(csv_path, "r", encoding="utf-8")
csv_data = csv.reader(csv_file)
for i in csv_data:
print(i)
# 작업이 끝난 csv 파일을 닫아줌
csv_file.close()
# result output
"""
['email', 'birthyear', 'name', 'Location']
['laura@example.com', '1996', 'Laura Grey', 'Manchester']
['craig@example.com', '1989', 'Craig Johnson', 'London']
['mary@example.com', '1997', 'Mary Jenkins', 'London']
['jamie@example.com', '1987', 'Jamie Smith', 'Manchester']
['john@example.com', '1998', 'John', 'Manchester']
"""
# csv를 dict 자료형으로 읽기
csv_file = open(csv_path, "r", encoding="utf-8")
csv_data = csv.DictReader(csv_file)
for i in csv_data:
print(i)
csv_file.close()
#
{'email': 'laura@example.com', 'birthyear': '1996', 'name': 'Laura Grey', 'Location': 'Manchester'}
{'email': 'craig@example.com', 'birthyear': '1989', 'name': 'Craig Johnson', 'Location': 'London'}
{'email': 'mary@example.com', 'birthyear': '1997', 'name': 'Mary Jenkins', 'Location': 'London'}
{'email': 'jamie@example.com', 'birthyear': '1987', 'name': 'Jamie Smith', 'Location': 'Manchester'}
{'email': 'john@example.com', 'birthyear': '1998', 'name': 'John', 'Location': 'Manchester'}
3) csv 파일 쓰기
import csv
csv_path = "sample.csv"
# csv 파일을 쓸 때는 newline='' 옵션을 줘서 중간에 공백 라인이 생기는 것을 방지함
csv_file = open(csv_path, "a", encoding="utf-8", newline='')
csv_writer = csv.writer(csv_file)
# csv에 데이터를 추가
csv_writer.writerow(["lee@sparta.com", '1989', "lee", "Seoul"])
csv_file.close()
csv_file = open(csv_path, "r", encoding="utf-8")
csv_data = csv.reader(csv_file)
for i in csv_data:
print(i)
csv_file.close()
#
...
['lee@sparta.com', '1989', 'lee', 'Seoul'] # 추가 된 행
데코레이터(decorator)
1) 데코레이터란?
- 파이썬의 함수를 장식해주는 역할
- 데코레이터는 선언되는 함수 위에 골벵이를 사용해 @decorator 형태로 작성하며 해당 함수가 실행될 때 데코레이터에서 선언 된 코드가 같이 실행
2) 데코레이터 코드 구조 이해하기
# 데코레이터는 호출 할 함수를 인자로 받도록 선언
def decorator(func):
# 호출 할 함수를 감싸는 wrapper 함수를 선언
def wrapper():
# func.__name__에는 데코레이터를 호출 한 함수의 이름이 들어간다.
print(f"{func.__name__} 함수에서 데코레이터 호출")
func()
print(f"{func.__name__} 함수에서 데코레이터 끝")
# wrapper 함수를 리턴
return wrapper# 선언되는 함수 위에 @decorator를 추가해 데코레이터를 사용할 수 있습니다.
@decorator
def decorator_func():
print("decorator_func 함수 호출")
decorator_func()
#
decorator_func 함수에서 데코레이터 호출
decorator_func 함수 호출
decorator_func 함수에서 데코레이터 끝
3) 데코레이터 예제
# 특정 함수의 실행 시간 구하기
import time
import random
def time_checker(func):
def wrapper():
# 함수가 실행될 때 시간을 저장
start_time = time.time()
# 함수를 실행
func()
# 함수가 종료된 후 시간에 실행될 때 시간을 빼 실행 시간을 구한다.
executed_time = time.time() - start_time
# 실행 시간을 소수점 5자리까지만 출력
print(f"{func.__name__} 함수의 실행시간 : {executed_time:.05f}s")
return wrapper
@time_checker
def main():
# 함수의 실행 시간을 테스트하기 위해 0.1초 ~ 1초간 sleep
time.sleep(random.randint(1, 10) / 10)
for i in range(10):
main()
#
main 함수의 실행시간 : 0.80095s
main 함수의 실행시간 : 0.90009s
main 함수의 실행시간 : 1.00027s
main 함수의 실행시간 : 0.20020s
main 함수의 실행시간 : 0.90011s
main 함수의 실행시간 : 0.60041s
main 함수의 실행시간 : 0.30027s
main 함수의 실행시간 : 0.40024s
main 함수의 실행시간 : 0.10026s
main 함수의 실행시간 : 0.50032s
4) 인자가 있는 함수의 데코레이터 예제
# 입력받은 인자에 2를 곱해주기
def double_number(func):
def wrapper(a, b):
# 함수에서 받은 인자에 2를 곱해준다.
double_a = a * 2
double_b = b * 2
return func(double_a, double_b)
return wrapper
@double_number
def double_number_add(a, b):
return a + b
def add(a, b):
return a + b
print(double_number_add(5, 10))
print(add(5, 10))
#
30
15