SNN
- a model of computation with neurons as the basic processing elements. Different from artificial neural networks, SNNs incorporate time as an explicit dependency in their computations. At some instant in time, one or more neurons may send out single-bit impulses, the spike, to neighbors through directed connections known as synapses, with a potentially nonzero traveling time. Neurons have local state variables with rules governing their evolution and timing of spike generation.
Hence the network is a dynamical system where individual neurons interact through spikes.
Computation with Spikes and Fine-grained Parallelism
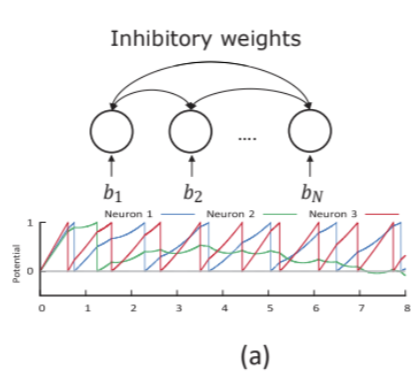
- competing to form an accurate representation of the data. By properly configuring the network, it can be established that as the network dynamics evolve, the average spike rates of the neurons will converge to a fixed point , and this fixed point is identical to the solution of the optimization problem
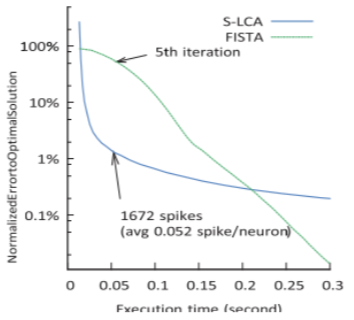
- Details about FISTA(Fast Iterative Shrinkage-Thresholding Algorithm)
1) 초기화: 시작 위치를 임의로 선택하고, 초기 스텝 사이즈와 반복 횟수 등 알고리즘 파라미터를 설정합니다.
2) 기울기 계산: 현재 위치에서의 함수의 기울기(그레디언트)를 계산합니다. 이를 이용해 현재 위치에서의 업데이트 방향을 결정합니다.
3) 새로운 위치 예측: 이전 스텝에서의 업데이트를 이용해 새로운 위치를 예측합니다. 이전 업데이트를 이용한 예측을 통해 현재 위치를 빠르게 조정합니다.
4) Thresholding(문턱 처리): 예측한 새로운 위치에 thresholding 연산을 적용하여, 해당 위치의 값을 조절합니다. 이를 통해 특정 조건을 만족하는 값들만 남겨놓습니다.
5) 스텝 사이즈 결정: Lipschitz 상수를 근사하여 스텝 사이즈를 결정합니다. 이 스텝 사이즈를 이용해 업데이트를 진행합니다.
6) 새로운 위치 업데이트: 예측한 새로운 위치와 결정된 스텝 사이즈를 이용하여 새로운 위치로 업데이트를 수행합니다.
7) 반복 및 수렴 확인: 설정한 반복 횟수나 수렴 조건에 도달할 때까지 위 단계를 반복합니다. 반복을 진행할수록 함수의 값을 최소화하고 최적화 문제에 수렴합니다.
위의 단계를 반복하면서 현재 위치를 조정하고 최적화를 수행하는 것이 FISTA의 핵심 알고리즘입니다. FISTA는 Proximal Gradient Descent와 비교하여 더 빠른 수렴 속도와 안정성을 제공하며, 특히 희소성과 같이 제약 조건을 갖는 문제에서 효과적으로 사용
- Details about S-LCA(Stream-based Spike-timing-dependent Plasticity Learning Algorithm)
1) 뉴런 활동 감지 및 시간 기록: 먼저 입력 데이터에 대한 스파이크 뉴런의 활동을 감지하고, 뉴런의 스파이크 타이밍을 기록합니다.
2) 시냅스 강도 초기화: 각 시냅스의 초기 가중치 값을 설정합니다. 일반적으로 무작위로 초기화하거나 학습에 적합한 초기값을 설정합니다.
3) 스파이크 타이밍 분석: 입력 데이터에서 발생한 스파이크의 타이밍을 분석합니다. 이때 뉴런 간의 스파이크 타이밍 차이를 측정하고, 어떤 뉴런이 먼저 활성화되었는지 등을 기록합니다.
4) 시냅스 강도 업데이트: 스파이크 타이밍 분석 결과를 기반으로 시냅스의 강도를 업데이트합니다. 일반적으로 스파이크 타이밍 의존 가소성(STDP) 규칙을 활용하여 업데이트를 수행합니다. STDP는 뉴런 간의 스파이크 타이밍 차이에 따라 시냅스의 강도를 증가 또는 감소시키는 규칙입니다.
5) 학습 반복: 입력 데이터의 스트림을 계속 처리하면서 반복적으로 스파이크 타이밍 분석 및 시냅스 강도 업데이트를 수행합니다. 이를 통해 뉴런 간의 상호 작용과 스파이크 타이밍에 기반한 학습이 진행됩니다.
6) 수렴 및 평가: 일정한 학습 반복 후에 시냅스 강도가 수렴하게 됩니다. 이때 학습된 네트워크를 다양한 작업이나 테스트 데이터에 대해 평가하여 학습의 효과를 확인합니다.
7) 온라인 학습 및 적응: S-LCA는 스트림 기반 학습 알고리즘으로, 실시간으로 데이터를 수신하면서 온라인으로 학습 및 적응이 가능합니다. 이를 통해 실시간 데이터에 대한 빠른 학습이 가능해집니다.
이러한 단계를 통해 S-LCA는 실시간으로 스파이크 데이터에 대한 학습과 적응을 수행하며, 스파이크 타이밍 의존 가소성 원리를 활용하여 시냅스 강도를 조절하여 네트워크의 학습을 진행
Learning with Local Information
1) express learning as the minimization of a particular loss function over many training samples.
- Spike traces
In particular, a short time constant allows the learning rule to utilize precise spike timing information, while a long time constant captures the information in spike rates. - Multiple spike traces
given spike train filtered with different time constants. - Rewards traces
correspond to special reward spikes carrying signed impulse values to represent reward or punishment signals for reinforcement learning.
Architecture
Loihi Chip overview
-
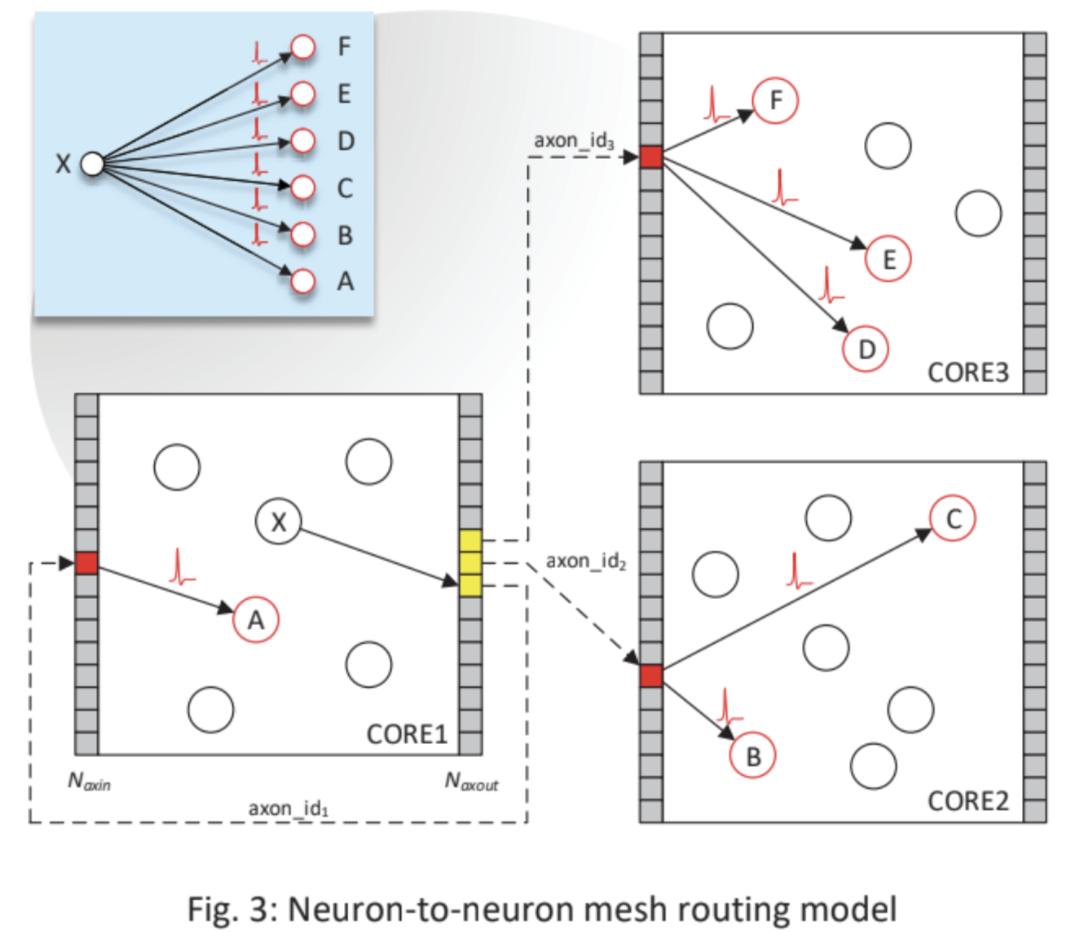
When a neuron’s activation exceeds some threshold level, it generates a spike message that is routed to a set of fanout compartments contained in some number of destination cores.
-
Loihi chip relaxed the constraint for programmers.
1) Sparse network compression
2) Core-to-core multicast
3) Variable synaptic formats
4) Population-based hierarchical connectivity
All prior chips, for example the previously most synaptically dense chip, store their synapses in dense matrix form that significantly constrains the space of networks that may be efficiently supported.
Barrier synchronization mechanism
- All the process reaches in barrier with same time. If the another process reached faster than anothers, the process just stop until the anothers reach.
Neuron-to-neuron mesh routing model
- each neuron 격자 또는 망 형태로 배치
- 2D 또는 3D 격자 형태로 뉴런이 배열
- 각 뉴런은 그것과 직접적으로 연결된 이웃 뉴런들이 있습니다. 이웃 뉴런들은 뉴런 간의 통신을 위한 경로로 사용
- 각 뉴런은 주변 뉴런과 직접적인 통신,(짧은 통신 경로)
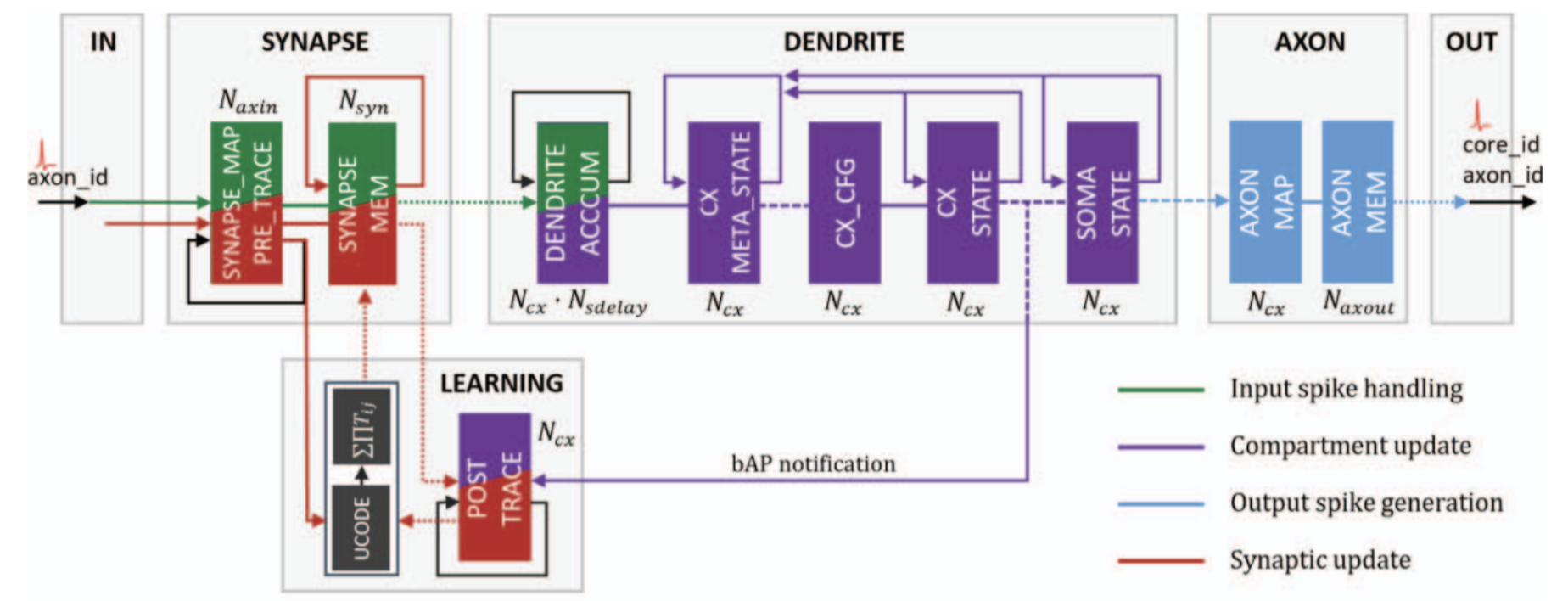
input spike handling (green)
neuron compartment updates (purple)
output spike generation (blue)
synaptic updates (red)
The black structure marked UCODE represents the configurable learning engine.
bAP notification은 주로 시냅스의 plasticity 및 학습과정에서 중요한 역할을 합니다. 한 뉴런에서 발생한 동작 전위가 다른 뉴런으로 역전파되면, 시냅스 강도를 조절하는데 사용될 수 있는 정보가 전달됩니다. 이를 통해 시냅스의 가중치가 조절되어 특정 패턴이나 정보를 기억하고 인지하는 데 활용될 수 있습니다.
신경망이 학습 데이터를 기반으로 자동으로 조정 및 최적화
Trace evaluation
Asynchronous Design Methodology
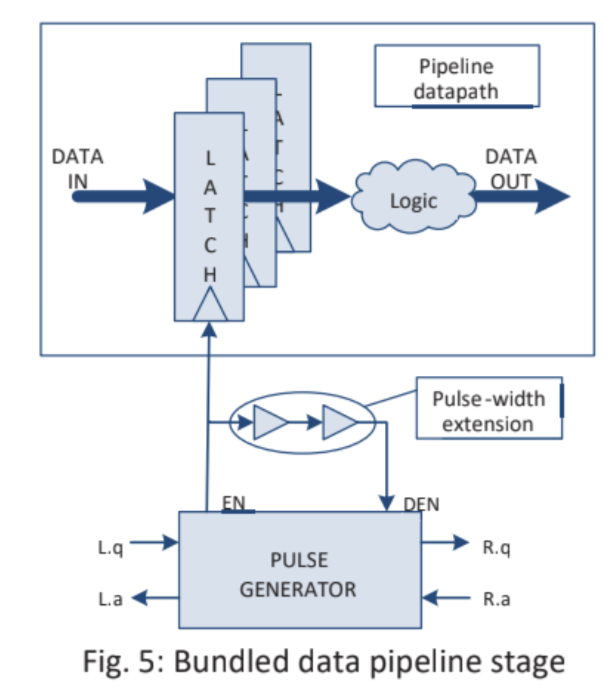
1) Template pipelinepath, solve the data in different states and efficiently process it. ex) CPU 명령어 실행 과정. 병렬성 활용 -> 처리 기능 향상
2) Handshake and latch sequencing, 비동기 디지털 회로에서 사용되는 통신 & 동기화 메커니즘.
- Handshake, 두 모듈 간에 데이터 교환에 사용되는 메커니즘. 두 모듈이 상호작용하면서 데이터를 전송하고 처리하는 방식.
- Latch sequencing, 데이터의 안정성을 보장하기 위해 사용되는 메커니즘. 데이터를 저장하고 전송하는데 사용되는 회로 구성 요소로, 데이터가 안전하게 저장되고 전달되도록 보장.
"Fine-grain flow control"
컴퓨터 architecture와 design에서 사용되는 개념으로, 작업의 실행과 데이터의 전송을 미세한 단위로 조절하고 제어하는 방식.
- 처리 과정에서 발생하는 활동을 더 정교하게 제어하여 효율성을 향상시키는데 사용.
- 다양한 컴퓨터 시스템에서 활용됨. 신경망 프로세싱을 위한 프로세서에서 활용. 각각의 뉴런이나 뉴런 그룹의 활성화 여부, 신호 전송, 데이터 전송.
여러 가지 장점)
1) 에너지 효율성, 작업이나 데이터 전송이 필요한 경우에만 활성화되므로 불필요한 에너지 소비 감소
2) 타이밍 제어, 각 작업이나 단계의 실행 타이밍을 정교하게 조절하여 처리 성능을 최적화
3) 자원 관리, 제한된 자원을 효율적으로 활용하고, 여러 작업이 동시에 실행될 때 간섭을 최소화
"Fine-grain flow control"은 비동기식 설계의 중요한 특성으로 신경형 응용 프로그램에서 여러가지 이점을 제공
1) SNN의 활동은 공간 & 시간 모두에서 매우 희소, 자동으로 발생하는 활동 게이팅은 지속적으로 실행되는 클럭으로 인해 종종 낭비되는 전력을 제거.
2) 로컬 플로우 컨트롤은 동일한 설계 내의 다른 모듈이 자연스로운 마이크로아키텍쳐 주파수에서 실행. (다양한 시간대에서 스파이크 뉴런 프로세스가 실행되어야 하는 필요와 맞물리며 백엔드 타이밍 클로저를 크게 단순화)
In Loihi, the mesh-level barrier synchronization mechanism is the best example of asynchronous handshaking providing a globally significant performance advantage by eliminating needless mesh-wide idle time.
- 동기적 vs 비동기적 architecture의 차이점
1)동기적, 한번에 한 프로세스를 실행.
2)비동기적, 한번에 여러 프로세스를 한꺼번에 실행.
-layout closure problem, 칩 또는 직접회로(IC)의 레이아웃을 최적화하는 과정에서 발생하는 문제.
1) 시간과 자원 제약
2) 신호 간 간섭
