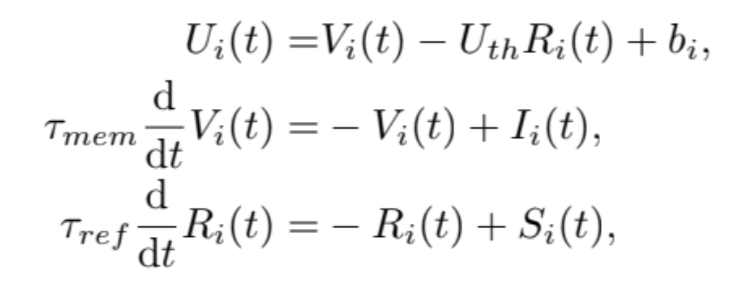
SOEL(Surrogate-gradient Online Error-Triggered Learning) 시스템
1) SOEL updates trigger when an error occurs, enabling faster learning with fewer updates.
-
(ANN의 활용성)
The current generation of Artificial Neural Networks (ANNs) achieve state of the art performance in applications ranging from image classification and object recognition, to object tracking, signal processing, natural language processing, self driving cars, health care diagnostics, and many more. -
(ANN의 뇌의 다이나믹한 아키덱쳐 모방 & 기본의 컴퓨터 아키텍쳐의 문제점 해결)
Neuromorphic systems mimic the brain’s event-driven dynamics, distributed architecture and massive parallelism to overcome the limitations of conventional von Neumann computing architectures -
Synaptic plasticity capability
perform training and inference online, using local information -
(SOEL의 특징)
a plasticity rule compatible with neuromorphic hardware derived from gradient-descent on SNNs and its efficient implementation using signals local to the neuromorphic cores.
By identifying SNNs as a type of Recurrent Neural Network (RNN), recent studies showed two reasons for this incompatibility
1) The spiking neuron has a non-differentiable activation function , which prevents the gradients from flowing across the network.
2) The computation of local errors requires the evaluation of a global loss function, which is a spatially and temporally non-local computation. (differentiable이 안되니, global loss function으로 시간적 개념의 minimum을 잡을수가 없게 됨)
solution
- 위의 2개 문제를 SG(Surrogate Gradient)로 addressing 할수있음.
SNN에서 기울기를 (loss function)에서 구할때, 기본 propagration의 방법이 아닌 surrgate gradient(기울기의 근사값)를 사용함. surrogate gradient를 대신 사용하며 가중치를 업데이트 하는 방식.
a pre-synaptic factor, a post-synaptic factor and an external error signal
Spike Time Dependent Plasticity (STDP) , a common synaptic plasticity model in neuroscience, contains only two factors and lacks the external signal.
The third factor drastically improves learning by projecting task-specific errors to the neurons.
In short, the SG bridges the worlds of ANNs and SNNs without simplifying assumptions on the latter.
A recent development of SG learning in spiking neurons
suggested that updating at every timestep is not necessary
if weight updates are triggered by task errors. In such
error-triggered learning , weight updates are made only when an error threshold is crossed. Consequently, the number of updates can be drastically reduced with a small penalty in final accuracy .
The goal of few-shot learning is to train a model to generalize from as few examples as possible.
Background
DVS(Dynamic Vision Sensor)
- The actions are recorded using a DVS camera, an event-based neuromorphic sensor, under three different lighting conditions. The task is to classify an action sequence video.
Neural Network Model, followed by LIF(leaky, Integrate & Fire model)
Equation
represents the spike train of neuron i spiking at time , represents the Dirac delta.
The spike emitted when the membrane potnetial reaches the threshold
Gradient-based Training of SNNs

is the global cost function, is the top layer of spike and the weights in the layer is l.
As discussed earlier, the SG approach consists in using a
smooth surrogate function in place of the non-differentiable
step function, such as the boxcar function
- explanation of boxcar function.
특정 구간에서 값이 1이고 다른 구간에서는 값이 0인 특징을 가지고 있습니다
rect(t) = 1, if a<=t<=b and 0, otherwise
To solve the hidden layer which is non-trivial and spatiotemporal credit assignment problem.
-explanation of spatiotemporal credit assignment problem
1) 시공간 데이터의 맥락에서, 신경망의 다양한 구성 요소에 대한 기여를 할당하거나 결정하는 어려움. 시공간 데이터는 공간(다른 뉴런 또는 유닛)과 시간(다른 시간 단계 또는 시퀀스) 모두에 걸쳐 정보가 분산된 데이터
2) 시공간 크레딧 할당 문제는 특정 뉴런, 시냅스 또는 시간 단계가 네트워크의 전체 성능이나 동작에 기여하는 방법을 이해해야 할 때 발생
3) 시공간 크레딧 할당 문제에 대응하기 위해서는 네트워크의 작동의 공간적 및 시간적 차원을 모두 고려하는 기술이 필요
2 learning methods
1) Surrogate-gradient Online Error-Triggered Learning (SOEL) Online training for Loihi
synaptic plasticity processor.
- the mean-squared error and the network consists
of only one layer, the first term becomes the task error
= −
becomes the box function where
where is a integer error event for neuron i
2) SLAYER Offline Training for Loihi:
(SLAYER definition)
SLAYER is a gradient computation method for training deep SNNs directly in the spiking domain
2 basic guiding principles in SLAYER:
1) Temporal error credit assignment
- Done by unfolding the temporal dynamics in time and backpropagating
through the unfolded graph
2) The surrogate gradient
- SLAYER uses a proxy function as an approximation of spike function derivative, similar to the surrogate gradient learning. These principles form the essential link in the computational graph used to calculate the gradients of the weights of the SNN and train it using standard deep learning optimization methods
Intel Loihi
1) Loihi offers a variety of local information for programmable synaptic learning processes such as spike traces with configurable time constants that can have different time constants.
- Plasticity Processor:
finite-difference equation(미분을 사용함에, 시간에 따른 함수의 변화를 측정 가능)
is the synaptic weight variable defined for the
destination-source neuron pair being updated
is a scaling constant
may be programmed to represent various state variables, including pre-synaptic spikes or traces, post-synaptic spikes or traces, where traces are represented as first-order linear filters.
Online few-shot learning using Surrogate-gradient Online Error-Triggered Learning (SOEL) plasticity for Loihi
, if or or C, otherwise
is the threshold value for the spike.
-
(The relationship between threshold and weight)
Intuitively, SOEL can be interpreted as follows. If err is
higher than θ, meaning the neuron is spiking at too high a
frequency, then there is a positive error and the weight of the
synapse will be penalized. Conversely if err is below −θ then
the weight of the synapse weight will be increased. -
Full learning rule
is the synapse from pre-synaptic neuron j to post-synaptic neuron i
, learning rate
, error
, pre-synaptic trace.
a new surrogate gradient based learning algorithm for few-shot online learning on an Intel Loihi neuromorphic processor using gesture recognition as a case study.
(details about the few-shot online learning)
-
모델이 매우 적은 양의 샘플(데이터)을 이용하여 새로운 클래스나 작업을 학습하는 상황을 다루는 방법.
-
기존의 머신 러닝 모델들은 많은 데이터로 훈련되어야 하며, 학습된 모델은 새로운 클래스나 작업을 추가로 학습하기 위해서는 해당 클래스의 대량의 데이터가 필요합니다. 그러나 현실 세계에서는 새로운 클래스나 작업에 대한 데이터가 제한적일 수 있거나, 실시간으로 학습해야 하는 경우가 있습니다. 이때 Few-shot online learning은 유용한 방법입니다.
-
Few-shot online learning은 몇 가지 주요 특징을 가지고 있습니다:
1) 작은 데이터셋: 새로운 클래스나 작업에 대한 데이터가 매우 제한적인 경우에도 학습을 수행할 수 있습니다. 이는 실제 상황에서 매우 유용합니다.
2) Online Learning: 모델이 새로운 데이터를 실시간으로 받아들이며 학습하는 방식을 강조합니다. 이를 통해 모델이 변화하는 데이터에 즉시 적응할 수 있습니다.
3) Few-shot Learning: 새로운 클래스나 작업을 학습할 때 필요한 데이터의 양이 매우 적어도 학습이 가능한 방법을 제공합니다. 이것은 많은 데이터가 필요한 전통적인 학습과는 대조적입니다.
(장점), Few-shot online learning은 실시간 감지, 실시간 분류, 동적 환경에서의 학습 등 여러 분야에서 유용하게 적용될 수 있습니다. 예를 들어, 자율 주행 차량은 새로운 상황에 대처하기 위해 적은 양의 데이터로 빠르게 학습해야 할 수 있습니다. 이런 상황에서 Few-shot online learning은 중요한 역할을 할 수 있습니다.
Discussions
- found that like ANNs, using a pre-trained network for transfer learning with SNNs significantly boosts few-shot learning accuracy.
(problems)
1) Being a local learning rule, SOEL only has information from pre- and post-synaptic neurons within its layer . Therefore training other layers will incur the spatial credit assignment because the neurons will not have a direct target to train on outside of the last layer.
Consequently, if the signal is not separable in the penultimate layer then the last layer cannot learn.
2) The approximations made with the SOEL algorithm.
Assumption: states do not change across the time window in which the error is calculated.
- This is beneficial to speed up training and can be adjusted to match the error dynamics . Second, due to limitations of the plasticity processor, the second term of the three factor rule cannot be implemented exactly and is instead ignored (set to one)
- These two approximations are likely to reduce the accuracy of the final result
SOEL only learns when there is sufficient error to trigger learning. This error-triggered learning helps prevent weight saturation and catastrophic forgetting leading to increased accuracy. However the increased accuracy comes with an increase in power consumption when compared to vanilla SGD.
