ANN(Artificial Neural Network) : 인공신경망이란, 인간의 뉴런 구조를 본떠 만든 기계학습 모델
인간의 뇌에서 뉴런들이 어떤 신호, 자극 등을 받고, 그 자극이 어떠한 임계값(threshold)을 넘어서면 결과 신호를 전달. 입력과 출력 사이를 은닉층이라고 부름.
결과값은 괜찮지만, 하드웨어에 부하량이 커서 문제였으니 최근에 반도체 발달로 쓸 수 있게 됨.
ANN에서 은닉층이 깊어진 것이 DNN이고, DNN을 응용한 알고리즘이 CNN, RNN.
대량의 데이터를 빠르게 생성하는 애플리케이션이 점점 더 많아지면서 온라인 학습 방식으로 학습하는 것이 점차 중요해지고 있습니다. 이러한 상황에서는 주로 메모리와 처리 시간 제한이 적용되며, 이러한 환경은 종종 변화가 입력 데이터 분포에 영향을 미칠 수 있는 진화하는 환경으로 전환됩니다. 이러한 변화는 이러한 데이터 스트림에서 훈련된 예측 모델이 더 이상 적절하게 새로운 분포에 적응하지 못하게 만들어 버립니다. 특히 이러한 비정상적인 시나리오에서는 가능한 빠르게 이러한 변화에 적응하는 새로운 알고리즘이 필요하며 동시에 좋은 성능을 유지해야 합니다.
불행하게도 많은 표준 분류 모델은 변화하는 환경에서 사용될 경우 완전한 재훈련이 필요한 경우가 많은데, 이는 확장성과 효율성을 저해할 수 있습니다. 스파이킹 뉴럴 네트워크(SNN)는 뇌의 동작과 학습 능력을 모델링하는 데 있어 가장 성공적인 접근 방식 중 하나로 나타났으며, 이를 활용하여 실제 온라인 학습 작업을 수행할 수 있습니다. 특히 일부 특별한 종류의 스파이킹 뉴럴 네트워크는 분포 변화 후에 재훈련이 필요하지 않을 수 있어서 동적인 시나리오에 적합합니다.
이 연구는 온라인 학습 및 스파이킹 뉴럴 네트워크 분야 간의 간극을 줄이고자 합니다. 이 작업은 온라인 학습 시나리오에 스파이킹 뉴럴 네트워크를 통합하는 데 대한 포괄적인 개요를 제공하며, 비전문가를 위한 친숙한 진입점 역할을 하여 이 유망한 접근 방식의 협력과 탐구를 장려하고자 합니다.
DNN
- 기본적으로 여러개의 층으로 이루어진 신경망.
각 층의 모든 노드가 연결, 이전 층의 모든 노드와 다음 층의 모든 노드가 연결되어 있다. - 일반적으로 고정된 베거 형태의 입력
ex) 이미지 처리시, 이미지를 일렬로 펼친 후 DNN에 입력값으로 제공. (문제: 이미지의 공간적 구조 정보의 손실) - 정보를 Spiking이 아닌 실수값으로 나타내며, 신경망을 갱신할 때 Gradient Descent나 아니면 optimizartion Rule을 사용한다는 점에서 생물학적으로 타당하지 못한다는 부분.
SNN
- pre-neuron에서 여러개의 spike가 post-neuron으로 들어가며, pre의 활동 전위는 spike를 받을 때 치솟으며, 그 이후 다시 줄어든다.
SNN의 이론은 현재 대부분 현실적인 뇌와 유사한 정보 처리를 묘사하는 데 수용되며, 이로 인해 빠르고 신뢰할 수 있는 하드웨어 플랫폼에서의 구현이 용이해집니다.
DNN과 SNN의 차이점.
- DNN은 Tensor끼리의 maxtrix calcuation으로 연산이 이뤄진다. ==> 행렬연산을 위한 Computing Unit(ARU)의 필요성.
SNN은 Spike의 누적에 의한 활동전위가 임계점을 넘으면 Spike를 보내는 단순한 구조. (직접적으로 신경망 구동 설계 가능)
개념 변화를 처리하는 알고리즘은 적응 또는 탐지 목적으로 설계될 수 있으며, 액티브한 전략인 경우 적응 프로세스를 트리거하기 위한 감지 메커니즘을 필요로 합니다. 적응 프로세스는 적응적인 방식(먼저 개념 변화를 감지하여 변화가 감지될 때만 모델을 업데이트하는 것으로 알려진 액티브 또는 정보를 받는 접근법)이나 수동적인 방식(새로운 데이터 샘플이 수신될 때마다 모델을 계속해서 업데이트하는 것으로 알려진 패시브 또는 블라인드 접근법)으로 수행될 수 있습니다. 패시브 접근법은 점진적인 변화와 반복되는 개념에 효과적이며(액티브 접근법도 가능하지만 더 어려울 수 있음), 배치 학습에 더 권장됩니다. 액티브 접근법은 변화가 급격할 때 잘 작동하며, OL에 더 권장됩니다.
IoT의 특성은 다음과 같습니다:
상호 연결성: 모든 것은 글로벌 정보 및 통신 인프라에 연결될 수 있습니다.
사물 관련 서비스: IoT는 사물의 제약 내에서 사물 관련 서비스를 제공할 수 있습니다(예: 개인 정보 보호 및 물리적 사물과 관련된 가상 사물 간의 의미적 일관성). 이러한 제약 내에서 사물 관련 서비스를 제공하기 위해서는 물리적 세계의 기술과 정보 모두가 변경되어야 합니다.
이질성: IoT 장치는 다른 하드웨어 플랫폼과 네트워크를 기반으로 하므로 이질적입니다. 이들은 다른 네트워크를 통해 다른 장치 또는 서비스 플랫폼과 상호 작용할 수 있습니다.
동적 변화: 장치의 상태는 동적으로 변화합니다. 예를 들어, 잠자는 상태와 깨어 있는 상태, 연결 및/또는 연결 해제, 장치의 위치 및 속도와 같은 컨텍스트가 포함됩니다. 또한 장치 수는 동적으로 변할 수 있습니다.
거대한 규모: 관리되어야 하는 장치의 수와 서로 통신해야 하는 장치 수는 현재 인터넷에 연결된 장치 수보다 적어도 한 순서 이상 많을 것입니다. 장치가 유발하는 통신의 비율은 인간이 유발하는 통신보다 장치 유발 통신 쪽으로 눈에 띄게 이동할 것입니다. 더 중요한 것은 생성된 데이터와 그것을 응용 프로그램 목적에 해석하는 데이터의 관리입니다. 이것은 데이터의 의미론 및 효율적인 데이터 처리와 관련이 있습니다.
Software
MOA: 아마도 데이터 스트림 마이닝을 위한 가장 인기 있는 오픈 소스 Java 프레임워크일 것입니다(Bifet, Gavalda, Holmes & Pfahringer, 2018).
SAMOA: 분산 스트림 학습을 위한 확장 가능한 고급 대용량 온라인 분석 도구인 SAMOA(Morales & Bifet, 2015)입니다.
Scikit-Multiflow: Python에서 구현되었으며(ML 커뮤니티에서 인기가 높아지고 있음), MOA에서 영감을 받은 온라인 학습 평가를 위한 ML 알고리즘, 데이터셋, 도구 및 메트릭의 컬렉션을 포함하고 있습니다(Montiel, Read, Bifet & Abdessalem, 2018).
Scikit-Learn: 주로 배치 학습에 중점을 두고 있지만, 이 프레임워크1은 다양한 OL 방법을 연구자들에게 제공합니다. 예를 들어 Multinomial Naive Bayes, Perceptron, Stochastic Gradient Descent 분류기, Passive Aggressive 분류기 등이 있습니다.
SparkML: 대규모 데이터 처리를 위한 Spark 기반 ML 라이브러리로, 대용량 데이터 처리를 위한 것입니다(Meng, Bradley, Yavuz, Sparks, Venkatara- man, Liu, Freeman, Tsai, Amde, Owen 등, 2016).
Online Learning(OL)의 어려움 & 미래 트랜드
구조화된 예측(Structured prediction): 하나의 출력 속성만 예측하는 대신, 구조화된 예측에서는 동시에 여러 출력 속성이 있을 수 있습니다. 이러한 출력 속성은 숫자형이나 이산형일 수 있습니다. 이러한 이산형 출력 속성을 다룰 때에는 다중 레이블 학습(multi-label learning)이라는 용어를 사용하고, 숫자형 출력 속성을 다룰 때에는 다중 대상 학습(multi-target learning)이라는 용어를 사용합니다.
반지도 및 지연 학습(Semisupervised and delayed learning): 클래스 레이블의 수가 작을 수 있기 때문에 대량의 레이블 없는 데이터를 활용하기 위해 반지도 기법을 사용해야 할 수 있습니다. 또한 클래스 레이블이 지연되어 도착하는 실제 시나리오도 있습니다. 이러한 지연된 상황을 다루기 위해 반지도 기법을 사용할 수도 있습니다.
*SSL에 대한 설명
https://www.altexsoft.com/blog/semi-supervised-learning/
액티브 학습(Active learning): 인스턴스의 레이블을 얻는 데 비용이 들 경우, 액티브 학습을 사용하여 어떤 인스턴스를 선택해야 할지 결정할 수 있습니다. 이는 비용과 사용되는 레이블 수를 최적화하는데 도움이 됩니다.
데이터 전처리(Data preprocessing): 고차원 데이터에서 모든 속성을 사용하는 것이 현실적이지 않을 수 있으며, 특성 선택 또는 특성 변환을 수행하기 위해 데이터를 전처리해야 할 수 있습니다. 효율적인 방법으로 이를 수행하는 것은 여전히 매우 어려운 문제입니다.
불균형 학습과 이상 탐지(Imbalanced learning and anomaly detection): 많은 응용 프로그램에서 데이터는 균형이 맞지 않을 수 있으며, 클래스 레이블의 분포가 균일하지 않을 수 있습니다. 이러한 불균형 학습의 응용 중 하나는 이상 탐지입니다. 이상 사례는 매우 낮은 빈도로 발생하기 때문에 이는 불균형 학습의 대표적인 예시입니다.
분산 컴퓨팅(Distributed computation): 대량의 데이터를 처리할 때, 중요한 동향은 Apache Spark, Apache Flink, Apache Storm 등과 같은 분산 스트리밍 엔진을 사용하여 OL을 어떻게 수행할 것인지에 대한 것입니다. 알고리즘은 효율적인 방식으로 분산되어야 하며, 분산 알고리즘의 성능이 데이터 분산의 네트워크 비용으로 인해 손상되지 않아야 합니다.
신경망의 사용(The use of neural networks): 데이터에 대해 단일 패스만 수행하는 방법은 현재 표준적인 딥 러닝 기술이 데이터에 여러 번 패스를 수행하는 반면, 이에 대한 중요한 연구 분야가 될 것입니다.
SNNs
SNN의 하드웨어 구현에는 여러 가지 트레이드 오프가 있습니다: 전통적인 모델과 달리 곱셈이 없으며, 펄스 처리는 시프트와 덧셈을 사용하여 구현할 수 있으며, 상호 연결은 실수 대신 단일 비트를 전송합니다. 희소 및 비동기 통신도 쉽게 구현할 수 있습니다. 그러나 이러한 잠재적인 이점이 일반 컴퓨터 플랫폼에서 SNN을 구현할 때 아직 나타나지는 않습니다.
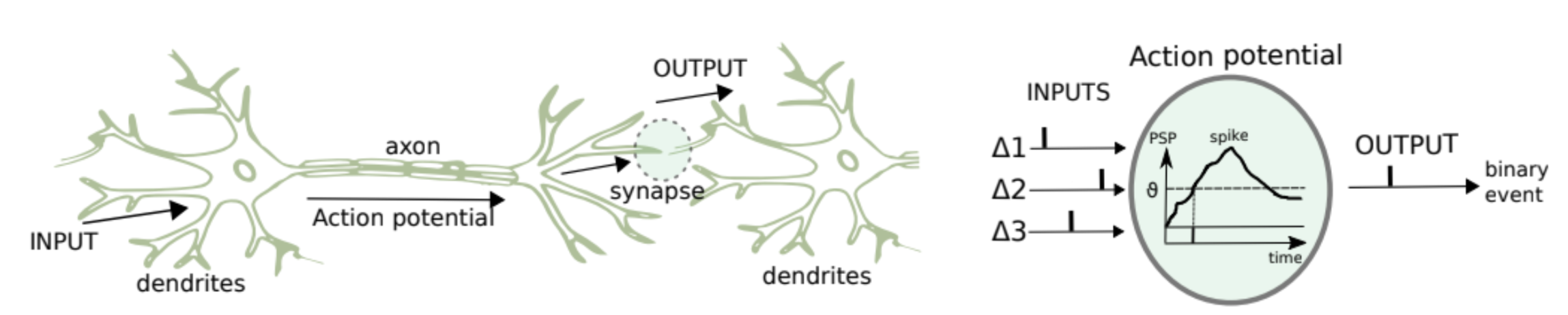
스파이크의 활용은 시간 변동하는 시냅스 후전 전위(PSP), 발화 임계값(θ), 그리고 스파이크 지연(∆)의 정의를 함께 가져옵니다. 이는 Figure 4에서 나타나 있습니다. 이러한 신경망은 네트워크 내에서 뉴런(시냅스) 간에 수행되는 프로세스를 모방하려고 합니다.
신경계 신호는 종종 시간축 그래프에 "l"모양의 spike가 언제 발생했는지 그려넣은 그래프로 나타내며, 이를 spike train이라고 한다.
신경계 신호인 spike를 어떤 식으로 encode하고, 그것을 machinary에서 다시 decoding 할 건지에 대한 기준이 모호함.
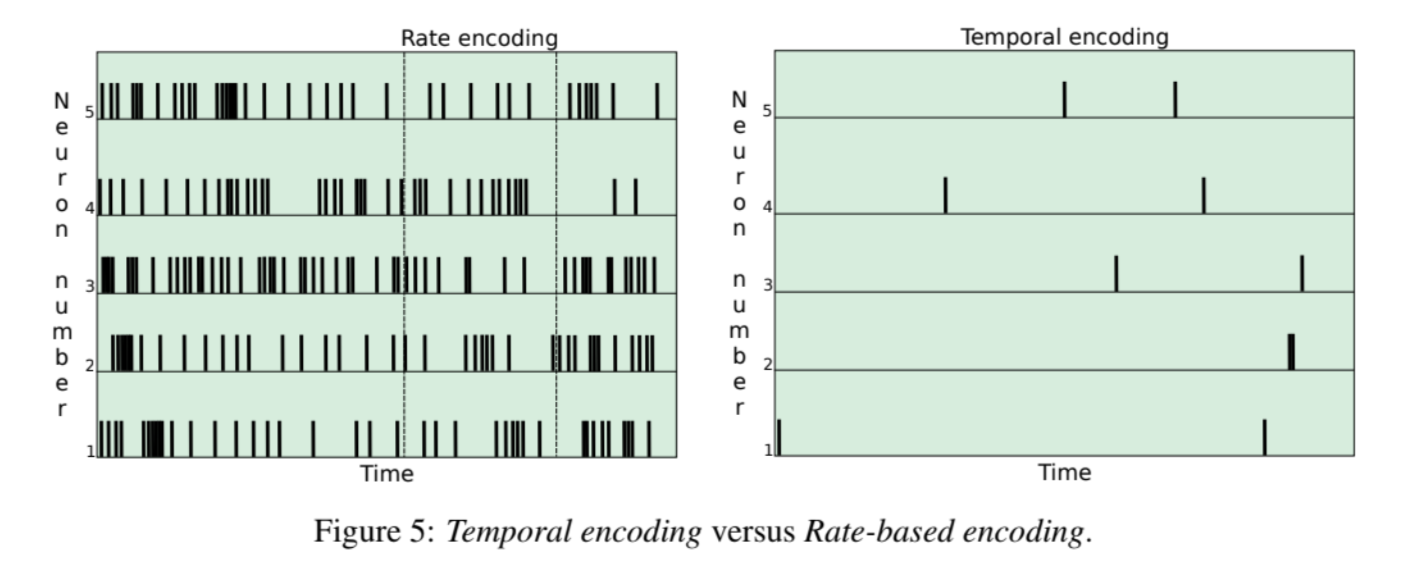
시간 인코딩(temporal encoding) vs 비율 기반 인코딩(rate-based encoding)
전자는 후자보다 인코딩 창 내에서의 패턴이 스파이크 수로부터 얻을 수 없는 자극에 관한 정보를 제공할 때 사용됩니다. 비율 기반 인코딩 방식은 시간 간격 내의 스파이킹 특성 (예: 주파수)에 기반하며, 시간 인코딩 방식에서는 정보가 스파이크의 시간에 인코딩됩니다.
rate-based encoding
1) rate as a spike count
2) rate as a spike density
3) rate as a population activity
temporal encoding
1) time to first spike, the first spike that contains all infromation about the new stimulus.
2) phase, for the periodic signal
3) correlations and synchrony, (where we use spikes from other neurons as the reference signal for a spike code)
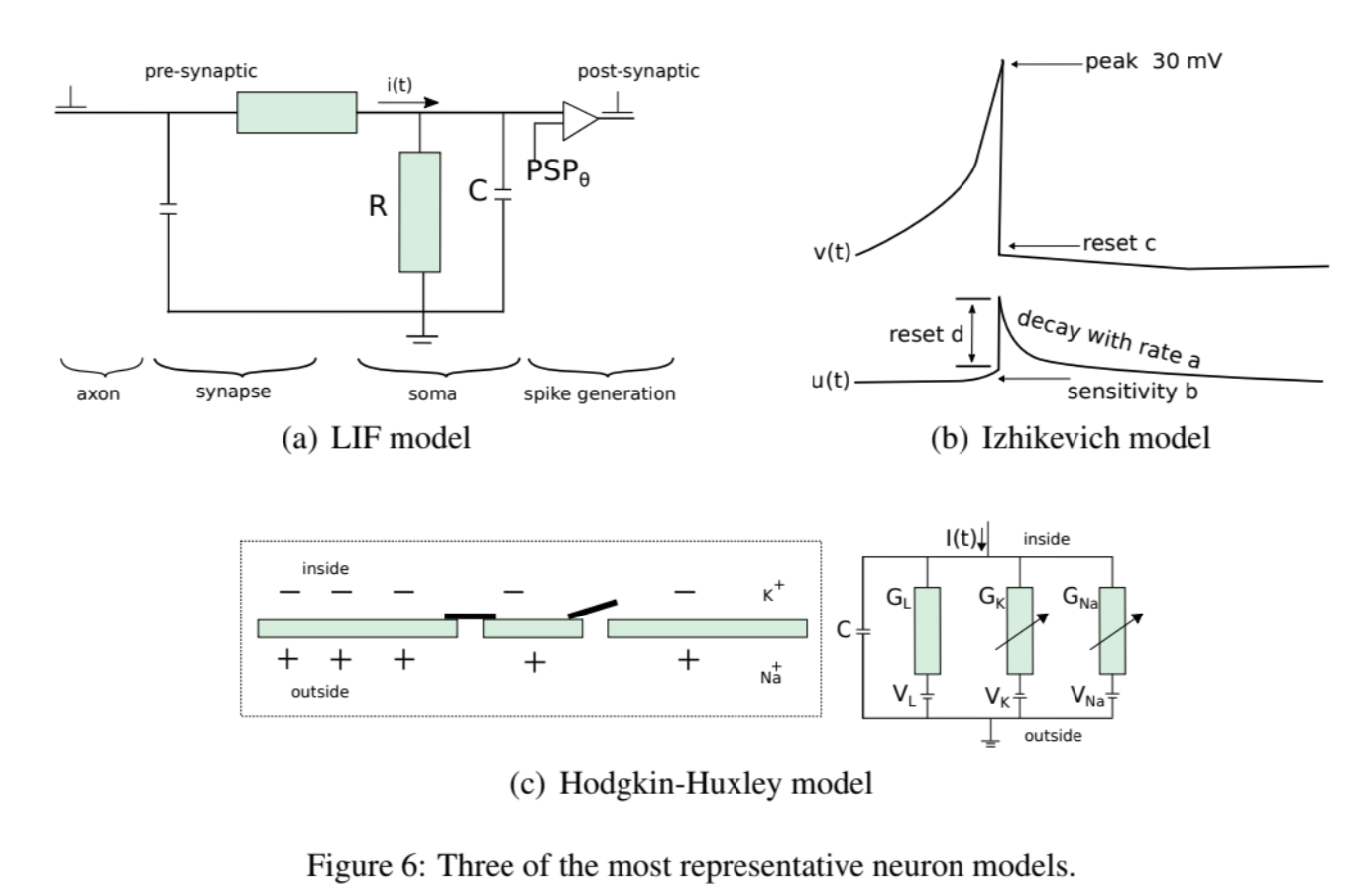
LIF model(Leaky Integrate and Fire)
membrane을 resistor-capacitor 회로화 , cell로 external current가 injecting 하는 것을 모델링
Kirchhooff's rule(키르히호프 법칙)
1) 연결지점(junction)에서 들어오는 전하와 나가는 전하의 합은 일정하다.
2) closed circuit에서 전위 변화의 합은 0이다. (Energy conservation)
LIF model을 적용시키면, 모든 전류의 합이 0이 된다.
이 뜻은, external current = resistive current + capactive current.
cell의 음전하가 membrane 내부를 따라서 축적되고, 외부에서 양전하를 끌어당긴다.
membrane이 capacitor의 역할을 한다는 것을 의미한다.
Membrane이 저장할 수 있는 charge(Q)는 capacitance equation,
, 은 membrane이 charge할수 있는 양의 ability를 의미
One of the most used approximations of the LIF model is the Spike Resposnse Model (SRM).
In Summary,
1) A neuron emits an spike each time its membrane potential reaches a threshold value ().
2) Then, after emitting the spike, the neuron goes through a phase of high hyperpolarization during which it is impossible to emit a second spike for some time (refractory period).
Hodgkin-Huxley model (HH model)
action potential을 정확하게 예측하고 묘사할 수 있는 방정식을 개발.
- 뉴런의 생물할적 특성을 모방하는 데 사용될 수 있는 계산 모델링의 초석이 되었다.
detailed description of the influences of the conductance of three ion channels (Na, K and L) on the spike activity of the giant azon of squid is given by the following equation:
When we differentiate the equation,
1) Na channel,
2) K channel,
3) L channel(skeletal muscle and linking membrane depolarization to release from intracellular stores,
are the conductance of the sodium, potasium, and leakage channels.
are constants called reverse potentials;
m and n control the Na channel ? and variable h controls the K channel; and are empirical functions of
Izhikevich
Better computational efficiency of LIF models and biological plausible than HH model.
if v >= 30mV, then c become v, and u+d become u.
(a,b,c,d are parameters of the model, v represents the membrane potential, and u the membrane recovery)
probabilistic
*stores its information in connection weights and probabilistic parameters related to spikes to the occurrence and the propagation of spikes.
Methods and Algorithsm in SNN
Synaptic plasticity is the capacity of synaptic connections to change their strength, which is the basis of the learning and memory processes in biological neural networks. Severals coexist, mainly differing on the time scale and conditions required for the induction.
LTP(Long-Term Potentiation)
해마 신경세포들의 시냅스 연결 강도는 고빈도의 시냅스 자극에 의해서 강화될 수 있다. 연속적이며 높은 빈도의 시냅스 자극이 주어진 후에 흥분성 시냅스후 전위의 크기는 2배 이상 커지며 이러한 시냅스의 강화현상이 수 시간 동안 유지될 수 있음을 관찰할 수 있다. 고빈도의 자극에 의해서 시냅스의 전달 효율이 증가하여 장기간 유지될 수 있음.(장기 강화 현상), 해마뿐만이 아니라 뇌의 여러 지역에서 관찰된다.
LTD(Long-Term Depression)
시냅스 연결 강조는 억제될 수도 있다. 낮은 빈도의 자극이 주어지면 시냅스의 효율이 감소하기도 한다.
In supervised learning, SHL(Supervised Hebbian Learning) provides the most straightforward solution for from a biologically realistic view.
- Additional teaching signal that reinforces the post-synaptic neruon to fire at the target times and remain silent at other times. (ReSuMe, SpikeProp)
In unsupervised learning, by modifying synaptic strengths of Hebbian processes, the connections are reorganized within a neural network and, under certain conditions, may lead to an emergence of new functions (input clustering, pattern recognition, source separation, dimensionality reduction, formation of associative memories or self-organizing maps).
It was demonstrated that the change in the synaptic efficacy after several repetitions of the experiment was a function of the relative differences of the spike times; and that whereas pre-synaptic spikes that precede post-synaptic ones induce potentiation, the reversed order of spikes induce synaptic depression. This phenomenon is called Spike-Time Dependent Plasticity (STDP)
Available Hardward and Software/Frameworks
software implementation / frameworks for SNNs.
Brian(파이썬2로 작성된 오픈 소스 SNN simulator)
Cypress(pyNN을 감싸는 C++ SNN simulation framework)
Neuron(해부학적 및 생리학적 특성에 중점)
Nest(전체 네트워크 모델에 중점)
PyNN(뉴런 네트워크 모델의 simulator에 독립적인 명세를 제공하는 python4 패키지)
NeuCube(뇌 데이터를 매핑, 학습 및 분석하는 3D eSNN)
PCSIM(대규모 SNN 네트워크의 분산 시뮬레이션에 주로 사용되는 python으로 작성된 software package)
ANNarchy(분산 비율 코딩, SNN을 위한 뉴럴 simulator)
Hardware platform
SpiNNaker(뇌과학, 컴퓨터 과학을 위한 타켓팅식 대규모 병렬 컴퓨팅 플렛폼), ARM architecture을 사용하여 맞춤형 디지털 멀티코어 칩에서 실시간으로 수행되는 수치 모델을 기반.
BrianScaleS(뇌 정보 처리에서 여러 공간 & 시간 스케일의 기능과 상호작용을 이해하고 emulation하는 프로젝트), 빠른 속도로 실행.
Selction of Model
SNN이 ANN들 보다 생물학적으로 더 현실적이며, 계산적으로 시간 단축이 강조 됨에도 계속하여, ANN이 사용되는 이유에 대한 질문.
LIF model(단순하지만 효율적인 경우로, 주로 컴퓨터 과학자와 엔지니어가 사용)
HH model(정교하지만 느린 경우로, 주로 뇌과학 연구자가 사용)
*정보 부호화(숫자가 아닌 시간적인 스파이크로 뇌가 작동한다는 사실은 알려져 있지만, 이러한 스파이크로 정보가 어떻게 부호화되는지가 관건)
*Spike timing education(학습 알고리즘에 대한 달성)
변화에 대한 적응력면에서 대부분의 기존 분류 모델은 변화하는 환경에서 사용될 경우 재학습해야 하며 확장성이 부족할 수 있습니다. 일부 SNN은 이러한 단점을 극복할 수 있습니다.
ex) 유사한 뉴런들을 병합하는 기반의 eSNN 은 데이터가 이용 가능해짐에 따라 지식을 누적시키는 것을 가능하게 만들며, 과거 샘플로 모델을 저장하고 재학습 할 필요가 없습니다.
Drawbacks and Tradeoffs of existing SNN approaches for Online Learning(OL)
SpikeProp is a learning rule based on gradient descent for training SNNs, and it is able to solve complex classification problems.
However it presents several drawbacks: it tends to be trapped in local minima, its convergence is not guaranteed because depends on fine parameter tuning before starting, it is too slow to be used in an online setting, and the large number of synaptic connections makes difficult to scale up when a high dimensional dataset is considered.
Machine learning algorithm
1) Supervised learning: 컴퓨터에게 정답이 무엇인지 알려주면서 컴퓨터를 학습하는 방법
2) Unsupervised Leraning: 정답을 알려주지 않고, 비슷한 데이터를 군집화하여 미래를 예측하는 학습 방법
SHL이 가진 2가지의 문제점
1) teaching signal currents suppress all undesired firest, the only correlations of pre-synaptic and post-synaptic activities happen aroudn the target firing times.
2) there is no mechanism that weakens the synapse weight.
Therer are ReSuMe, 해결방법, 가르치는 신호가 시넵스 plasticity에 margin 직접적인 영향을 미치지 않도록 변조하였다.
SpikeTemp 방법은 정확한 입력 스파이크 시간을 사용하여 시냅스 가중치의 변경을 결정하는 향상된 순위 순서 기반 학습 방법을 제공합니다. 그러나 대부분의 경우 이 방법들은 훈련 샘플을 한 번 제시한 후에 입력을 예측할 수 없으며, 이후에 다른 연구들은 보다 현실적인 접근으로 OL에 대처했습니다.
OL에 가장 유망한 SNN 중 하나는 Evolving Spiking Neural Networks (eSNNs)
이는 Thorpe 모델을 기반으로 하며 LIF 모델의 단순화된 버전입니다(계산 뉴런의 누수 작업을 단순화). 그리고 그 뉴런 모델은 대규모 네트워크의 매우 빠른 실시간 시뮬레이션과 낮은 계산 비용을 허용 합니다. 이러한 특성으로 인해 계산 비용과 처리 시간에 엄격한 제약 조건이 지배되는 시나리오에 적합합니다. 또한 이들의 진화하는 특성(스파이킹 뉴런은 시간이 경과함에 따라 점진적으로 발전하여 데이터로부터 시간 패턴을 추론)은 데이터가 도착함에 따라 지식을 누적할 수 있게 하며, 과거 데이터로 모델을 저장하고 재학습할 필요가 없습니다. 또한 이들은 비정상적인 환경에도 적합합니다. 왜냐하면 입력 스트림 데이터의 변화는 바이너리 이벤트 또는 스파이크로 즉시 인코딩되므로 변화에 적응하기 위한 가장 적합한 데이터 인코딩 전략 중 하나입니다. 최근에는 (Lobo, Lana, Del Ser, Bilbao & Kasabov, 2018b)에서 eSNN을 수정하여 변화에 대한 적응성을 향상시켰고, 뉴런 저장소의 크기를 제한하여 증분적인 성장을 피하는 더 현실적인 OL 형태를 고려했습니다. 그리고 이들은 (Lobo, Del Ser, Lana, Bilbao & Kasabov, 2018a)에서 변화 감지기로서 처음으로 사용되었으며, 이를 검출기로 사용하기 위해 뉴런 병합 메커니즘을 활용합니다. 지금까지는 이러한 몇 가지 예외를 제외하고는 효율적이고 확장 가능한 OL 시나리오를 위한 SNN 기반 알고리즘이 부족합니다.
OL에서 SNN을 적용하는 것은 매우 핫한 주제로, 실제 응용 프로그램에서 스트림 데이터를 기반으로 하는 경우가 많이 있습니다. 특히 데이터가 비정상적인 사건에 영향을 받아 개념 변화가 발생하는 시나리오에서 더욱 그렇습니다. SNN은 신경망의 세 번째 세대로 간주되며 뇌의 동작과 학습 능력을 모델링하는 데 가장 성공적인 접근 방식 중 하나로 드러났습니다. 그 결과 매우 빠른 실시간 대규모 네트워크 시뮬레이션과 낮은 계산 비용을 허용합니다. 또한 OL 시나리오에서 종종 나타나는 변화 감지 및 변화 적응 상황에서 매우 좋은 동작을 보였습니다. 이 모든 것은 우리에게 OL과 SNN의 분야를 매우 흥미로운 교차점으로 고려해야 함을 보여줍니다.

훌륭한 글 감사드립니다.