파이썬에서 테이블을 병합하는 방법에는 4가지가 있다.
1. Merge
2. Join
3. Concat
4. Append
- Merge
SQL의 Join과 가장 유사하다.
inner join이 디폴트
주요옵션(파라미터)
-on: 합치는 기준이 되는 컬럼
-how: 조인방식(inner, outer, left, right)
-left on/right on: 각 테이블의 합치려는 컬럼 이름이 다르다면 컬럼 이름을 각각 말함
-sort: 병합 후 인덱스 정렬 여부(T/F)
-suffixes: 테이블에 공통 컬럼이 있고 컬럼이름이 같을 때, 근데 그걸 개별로 다 출력하고 싶을 때
-indicator: True로 할 경우, 마지막 열에 병합 정보를 출력
# 기본 작성구문으로, 디폴트값은 inner join
# 공통컬럼값은 합쳐져 하나의 컬럼으로 출력
merge_df = pd.merge(df2,df3)
# 위 코드와 동일한 기능입니다. on 절을 사용할 수 있어요.
#공통 컬럼이 여러 개일 수 있으므로 how, on을 사용할 것을 권장
merge_df = pd.merge(df2,df3, how='inner', on='Customer ID')
# 공통컬럼이 2개 이상일 때
merge_df = pd.merge(df2, df3, how='inner', on=['공통컬럼1','공통컬럼2'])
# 기준열 이름이 다를 때
merge_df = pd.merge(df2,df3, how='inner', left_on = 'Customer ID', right_on = 'user id')
# 공통컬럼을 개별로 출력하고 싶을 때
# '_'는 필수가 아님
merge_df = pd.merge(df2,df3, how='inner', on='Customer ID', suffixes=('_left','_rihgt'))
# 'Customer ID_left', 'Customer ID_right'으로 컬럼명이 출력됨-
Join
Index(축)를 기준으로 결합
Key column을 두고 의미 없는 Index를 기준으로 테이블을 합칠 필요가 없음
Index를 Key column으로 설정해서 테이블을 합칠 수도 있지만 merge를 사용하면 돼서 굳이,,, -
Concat
Union(수직 결합), Join(수평 결합) 둘 다 가능
축을 기준으로 결합하고, 없는 컬럼의 value는 NaN으로 표시
1) axis=0 (수직 결합)
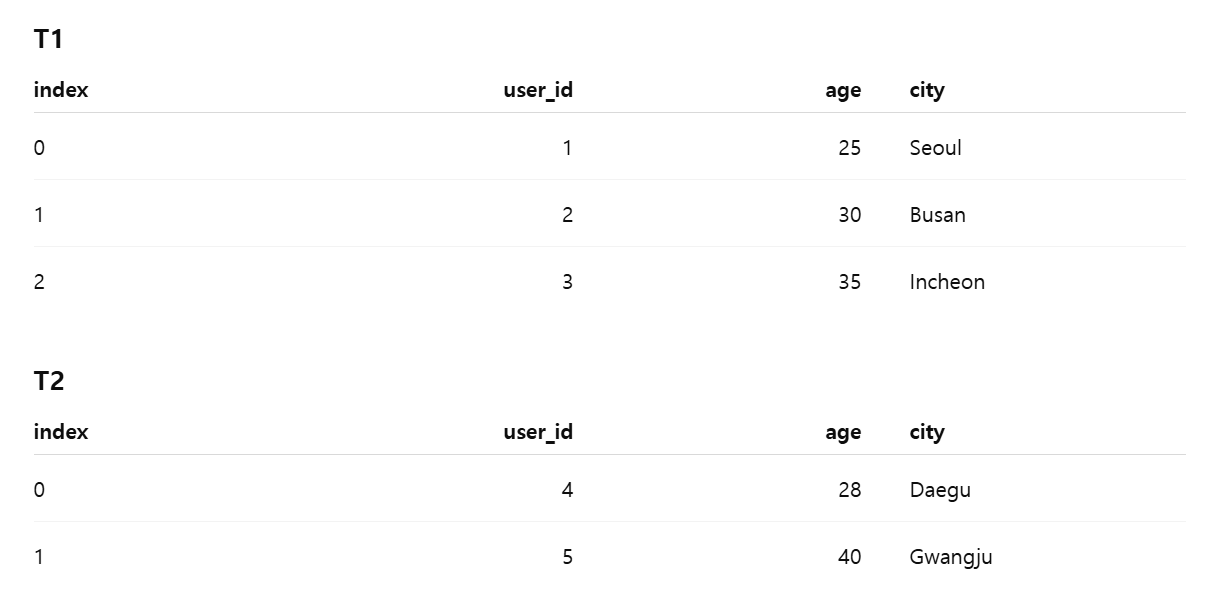
T1과 T2 테이블을 Concat axis=0 (수직 결합)하면,
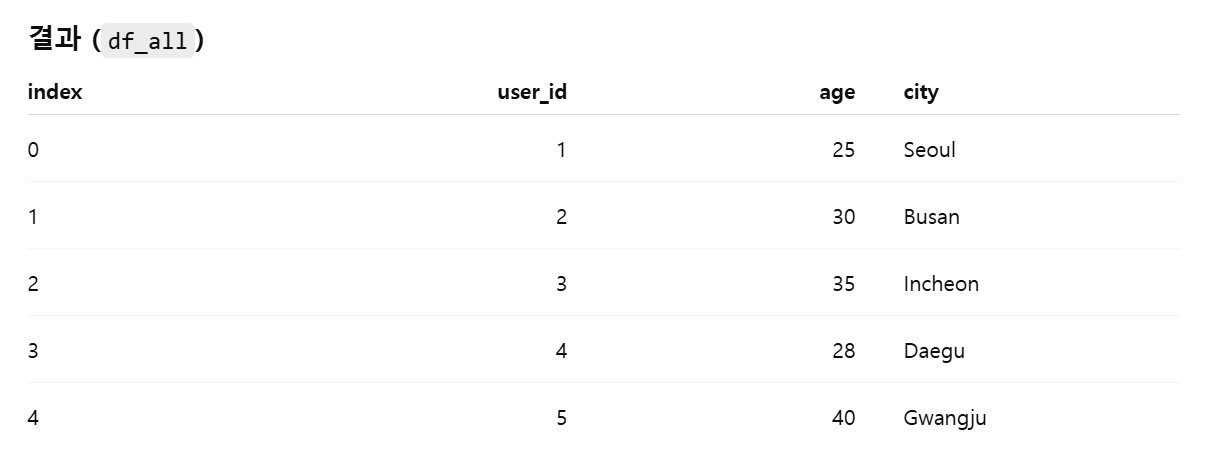
위와 같이 나타남
2) axis=1 (수평 결합)
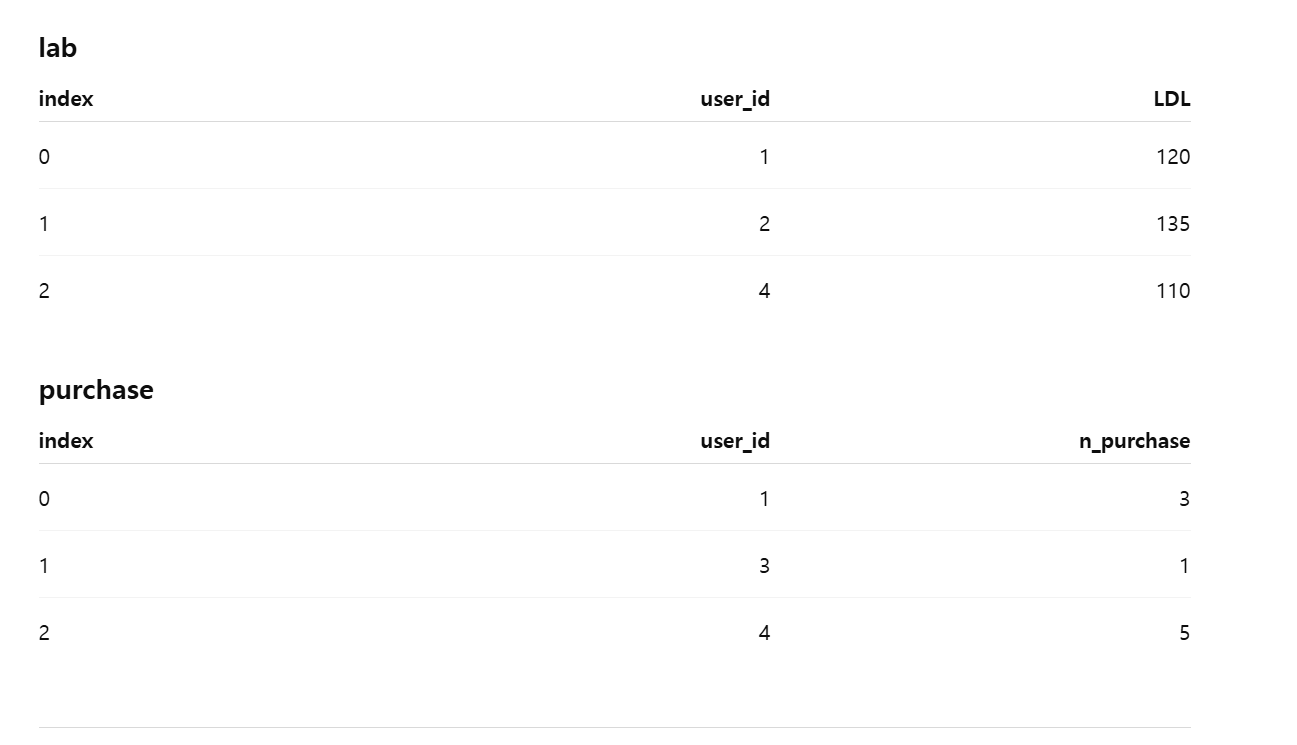
lab과 purchase 테이블을 Concat axis=1 (수평 결합)하면,
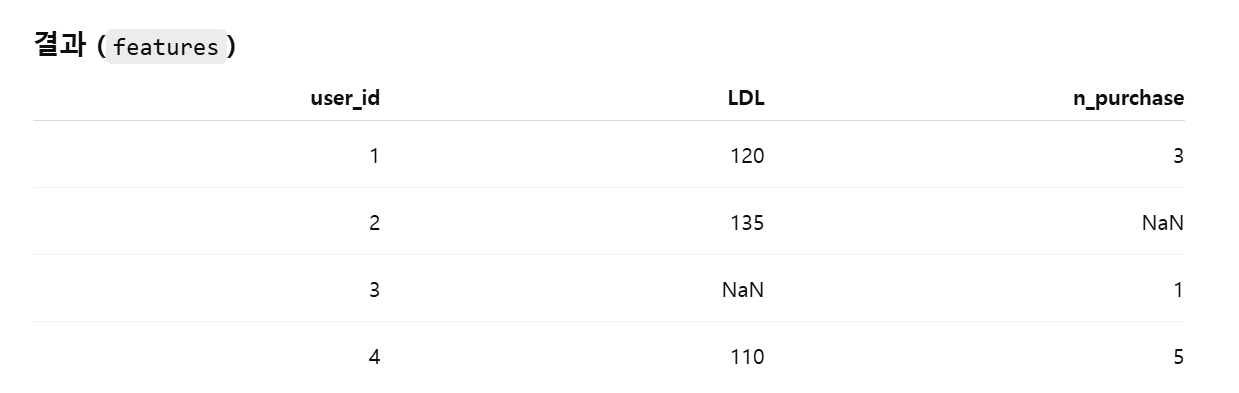
두 테이블에 있던 컬럼을 모두 가져오고, 없는 value는 NaN을 표시
Full outer join과 같음
결합의 기준이 되는 기준 축 설정 가능
테이블명1.set_index("기준컬럼1")
테이블명2.set_index("기준컬럼2")- Append
수직으로만 결합 가능
하지만, 곧 없어질 기능,,(라임 쩔었다)
다음은 파이썬으로 피벗테이블 만들기
파라미터는 다음과 같다
-index: 인덱스(축)으로 사용될 열
-columns: 열로 사용될 열
-values: 값으로 사용될 열
- index와 columns에 여러 컬럼을 리스트 형식 []으로 입력할 경우 멀티인덱스가 만들어짐
- values에 리스트를 입력할 경우 각 값에 대한 테이블이 연속적으로 생성됨.
-aggfunc
사용하는 function에는 다음과 같은 것들이 있다.

-fill_value: NaN 값을 처리하고 싶을 때 사용, fill_value=0이 가장 많이 사용됨
-dropna: 결측치 삭제 여부
-sort: index or columns 기준으로 정렬
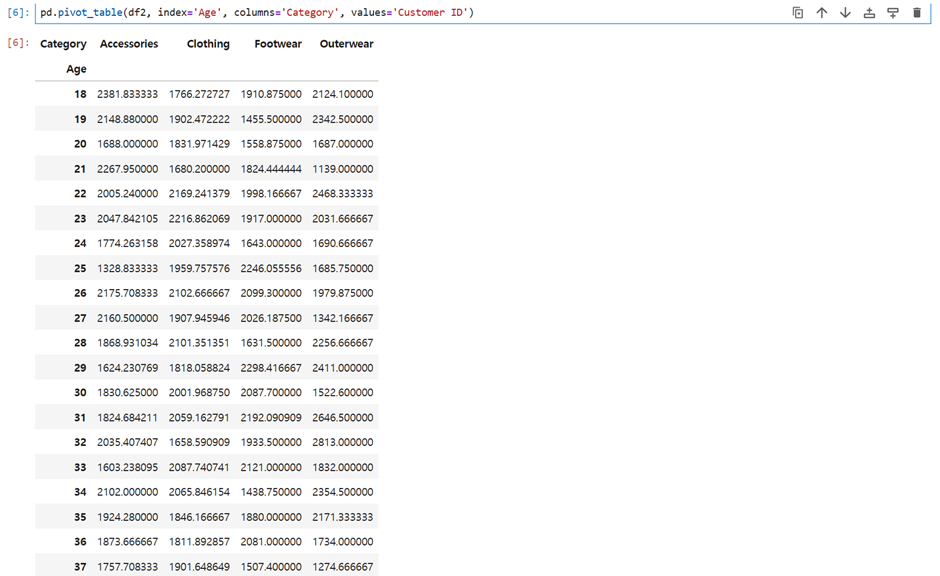
pd.pivot_table(df2, index='Age', columns='Category', values='Customer ID')aggfunc 안 쓰면 mean값이 나옴
즉 value는 각 나이, 카테고리에 속한 고객의 customer ID를 평균낸 값을 출력함
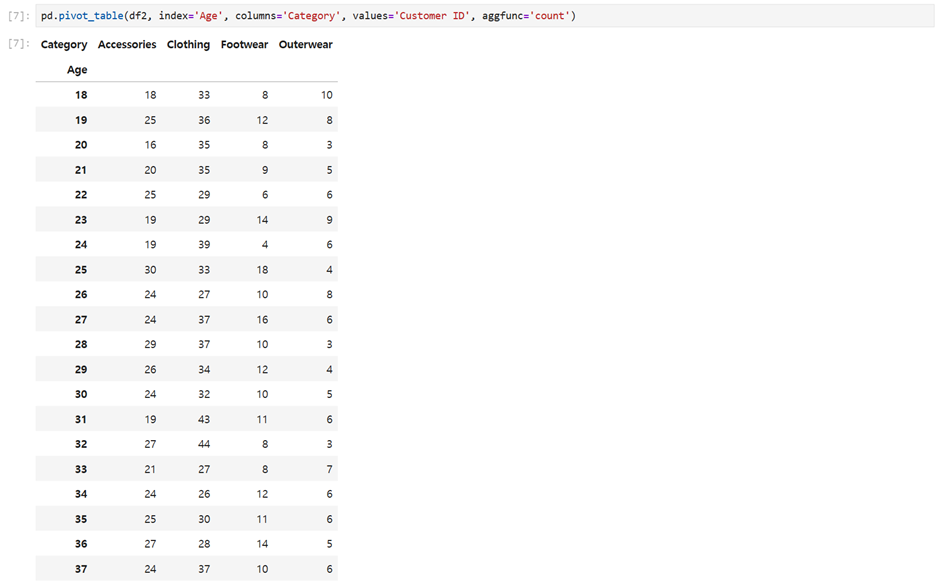
pd.pivot_table(df2, index='Age', columns='Category', values='Customer ID', aggfunc='count')aggfunc으로 각 고객의 수를 카운트하여 출력
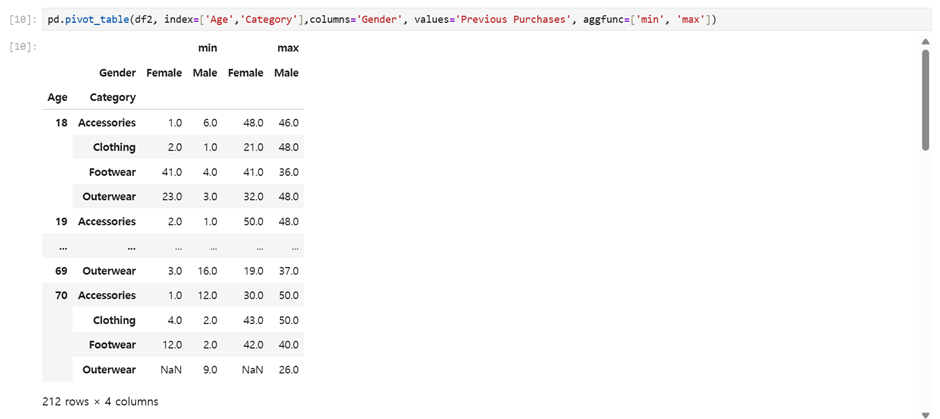
pd.pivot_table(df2, index=['Age','Category'],columns='Gender', values='Previous Purchases', aggfunc=['min', 'max'])나이, 카테고리별로 여성 남성에 따라 이전 구매한 물건 최소, 최대 개수 출력해줘
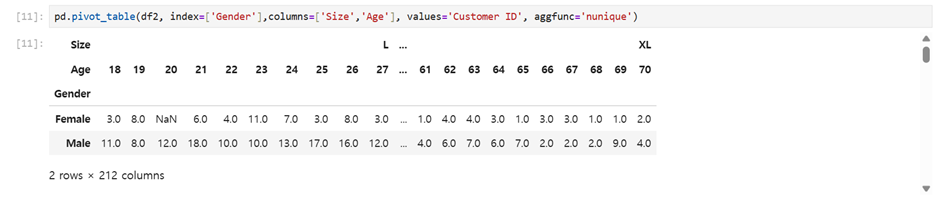
pd.pivot_table(df2, index=['Gender'],columns=['Size','Age'], values='Customer ID', aggfunc='nunique')성별 별로 사이즈, 나이에 따라 고객수를 중복 없이 카운트 해줘
생각보다 데이터 결합 함수의 차이를 이해하는 게 어려워서 지피티에게 끊임 없이 물어보고 테이블을 직접 합쳐보며 이해하려고 노력했다.
그래서 그런지 오늘은 목표했던 공부량을 절반도 못채운 느낌,,,
그래도 하나를 하더라도 제대로 하는 게 중요한 것 같다
주말에 추가로 하더라도 제대로 된 개념을 잡기 위해 노력하자
아자스!!
