하둡이란 ?
Open-source data storage and processing API
- Based on work from Google (GFS + MapReduce + BigTable)
하둡의 역사
2002 ) 'nutch' - 웹크롤링하다가 데이터양이 너무 많아짐
2003 ) GFS, MapReduce 논문 발표 (구글)
2004 ) Doug Cutting이 nutch에 GFS, MapReduce 개념을 합침
2006 ) 'nutch'에서 독립시켜 '하둡'으로 발표
2008 ) 하둡과 DB는 원래 관련이 없었지만, 하둡에서 SQL을 쓸 수 있도록 만듦 (Hive)
하둡을 쓰는 이유
- Scalability가 좋음 : 성능이 linear하게 올라감
- Faster : 하둡 출시 전까지 병렬 처리 개념이 없었기 때문에 혁신적이었다
- Better : 빅데이터 문제를 해결하는데 최적화
RDBMS vs. Hadoop
RDBMS
- Interactive and Batch (여러개의 job들을 모아서 한번에 처리해버림)
- Updates : Read and Write many times
- Structure : Static Schema - 스키마를 수정하기 힘들다
- Integrity 무결성 : High (ACID) = RDBMS 존재의 이유
- Scaling : nonlinear
여러개의 table들 사이의 관계를 찾아서 원하는 데이터를 찾아내는 것 -
Hadoop/ MapReduce
Batch , NOT Interactive (작업이 다 끝날때까지 기다려서 한번에 처리)
Updates : Write Once, Read many times (WORM)
Structure : Dynamic Schema (정해진 스키마가 없다 )
Integrity 무결성 : Low - 빅데이터의 빠른 처리가 중요하지 무결성은 중요치 않음
Scaling : Linear
use cases) Fraud Detection ( 신용카드 도용 방지, 평소 소비패턴과 달라지는 경우 확인 )
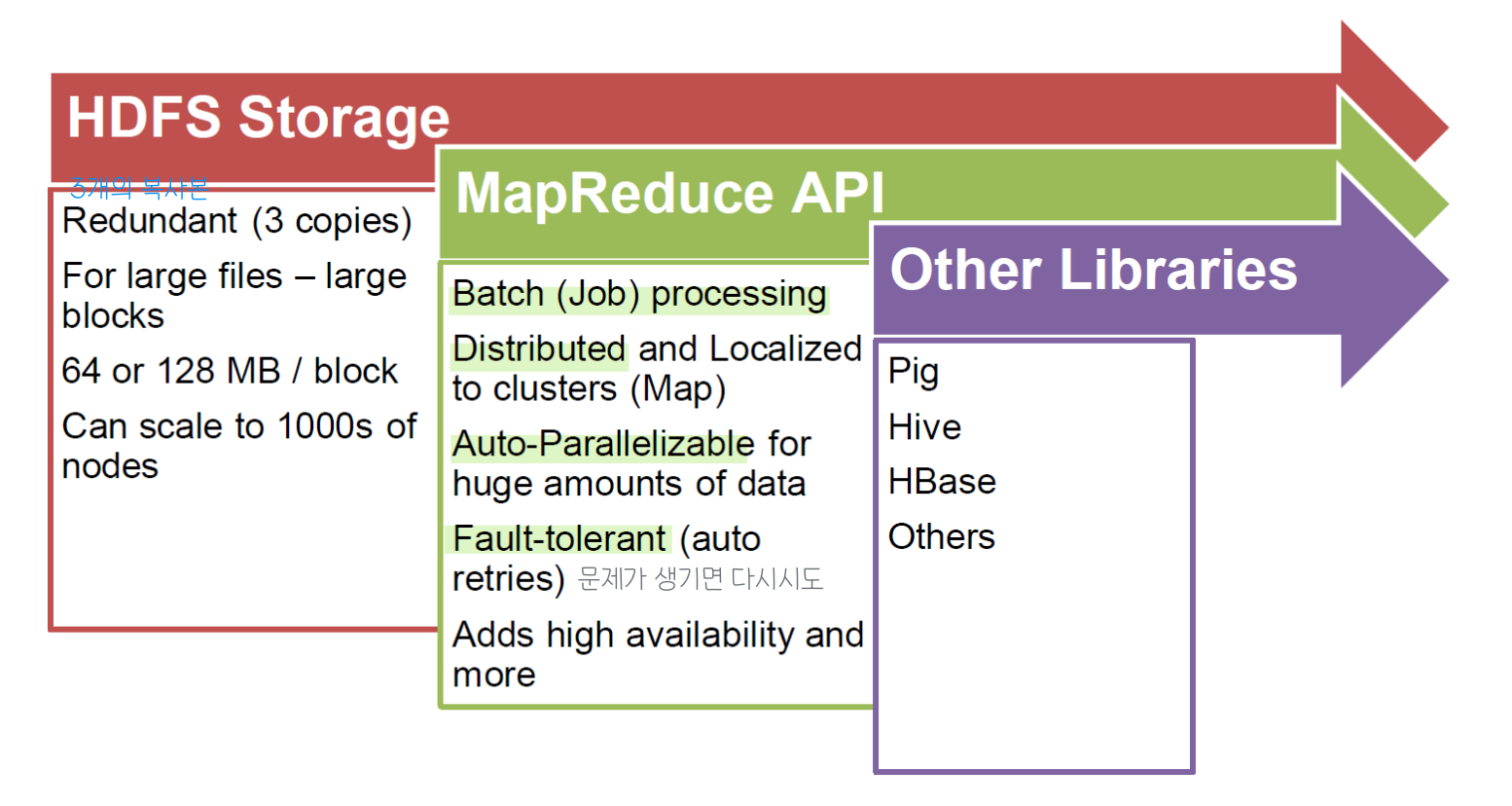
Hadoop Distributed File System HDFS
Basic Features
- Highly fault-tolerant
- High throughput
- Suitable for applications with large data sets
- Streaming access to file system data
- Can be built out of commodity hardware
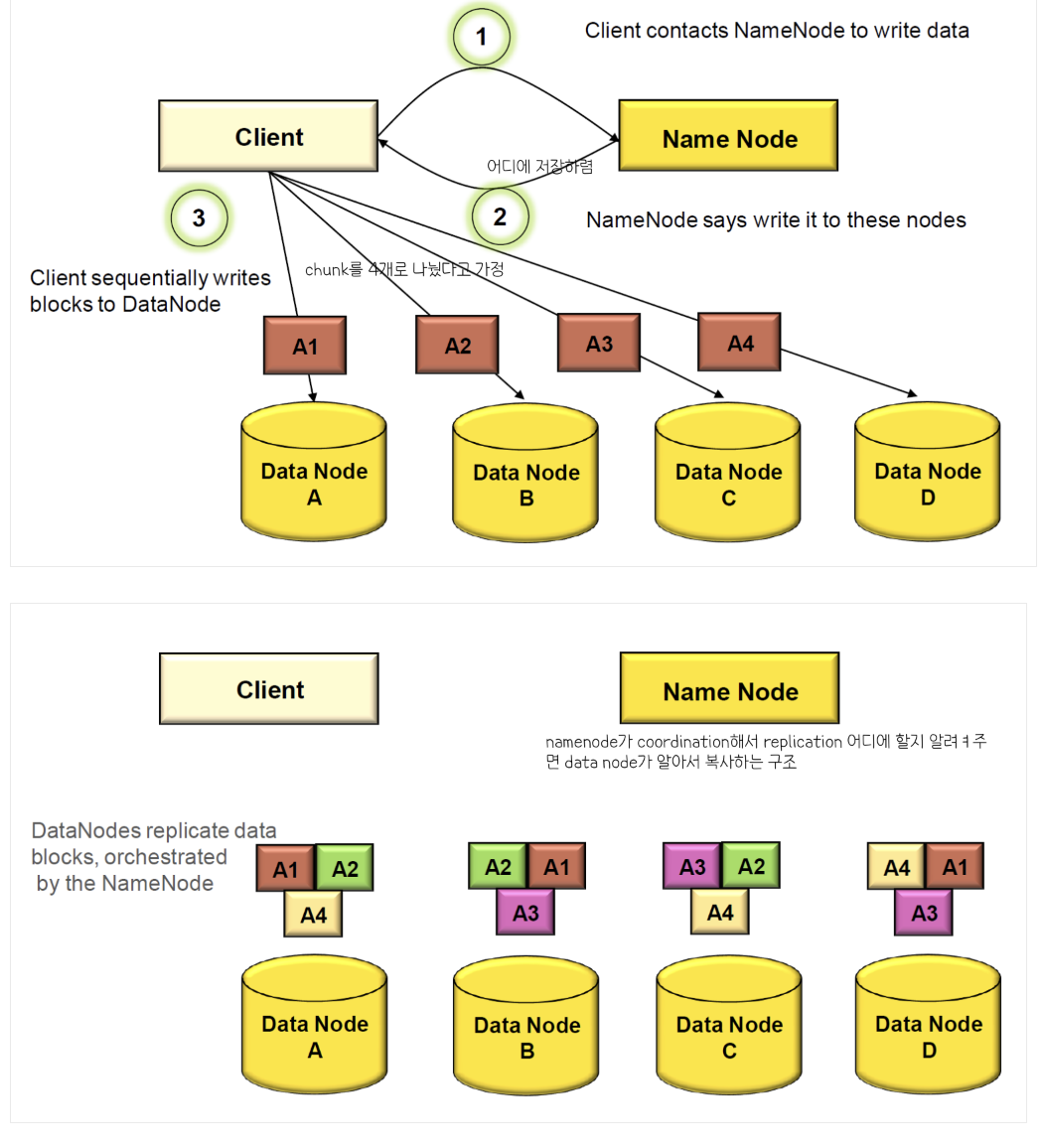
< HDFS Write >
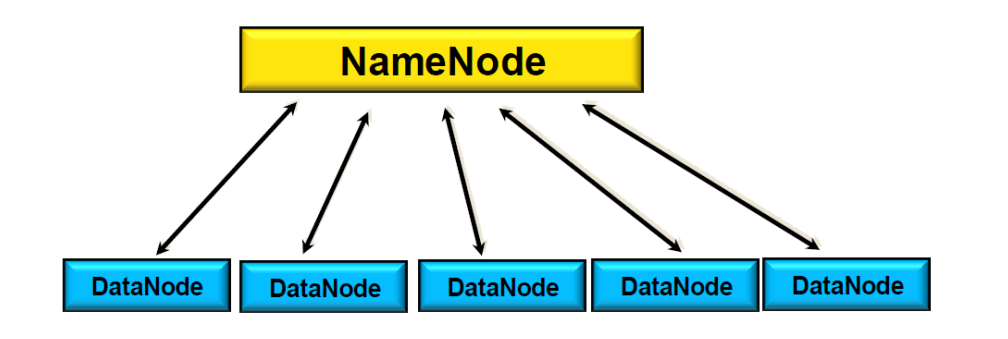
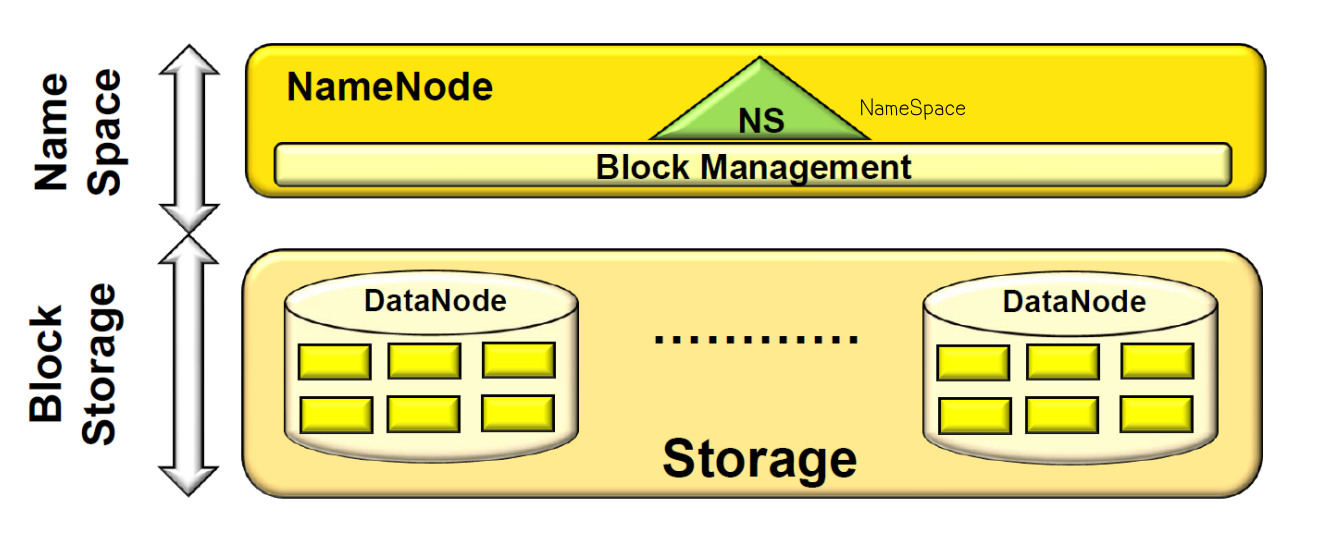
HA (High Availability) for NameNode
- Active NameNode
- Standby NameNode
: 네임노드가 죽으며 답이 없으므로 여분으로 하나 더 만듦
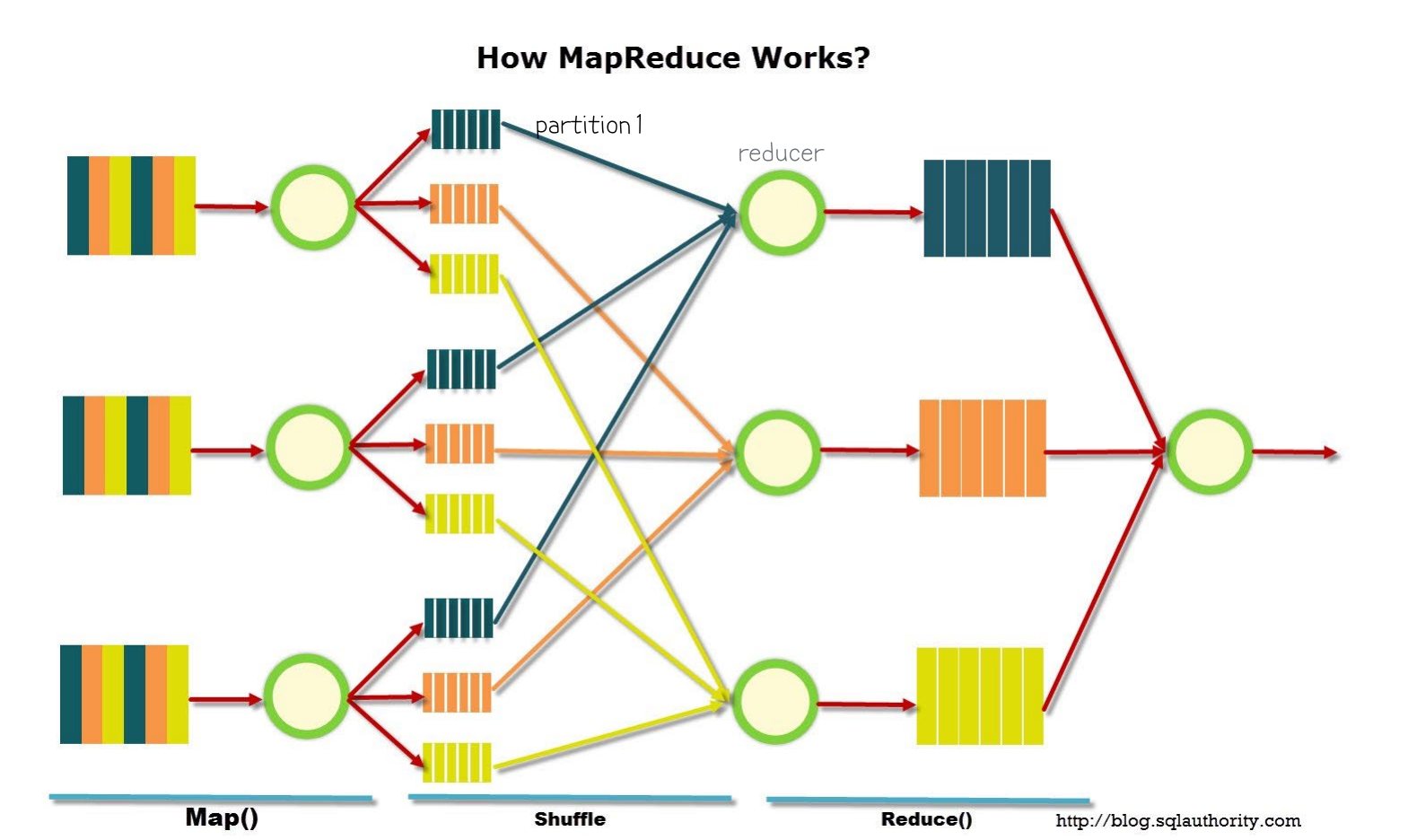
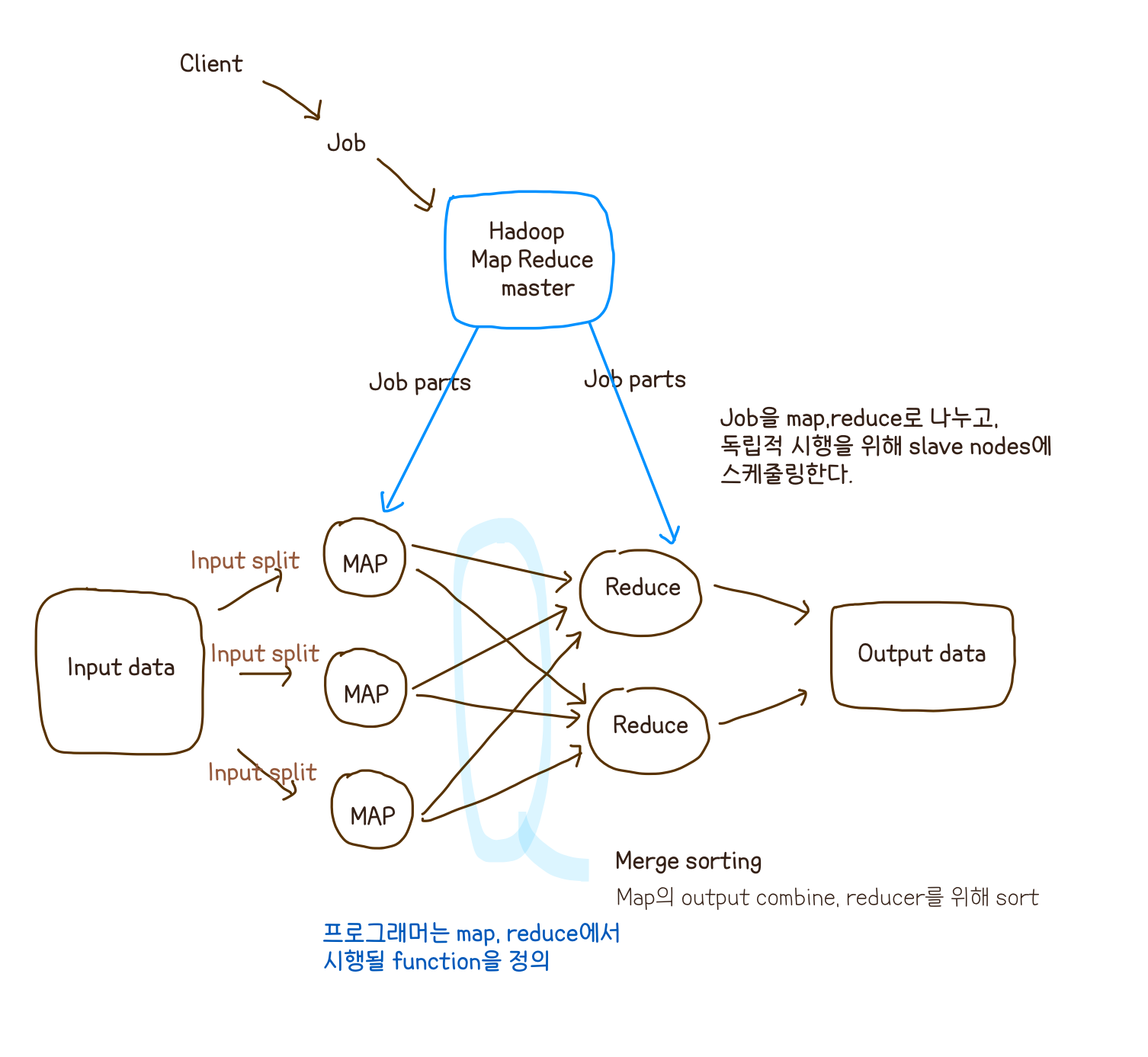
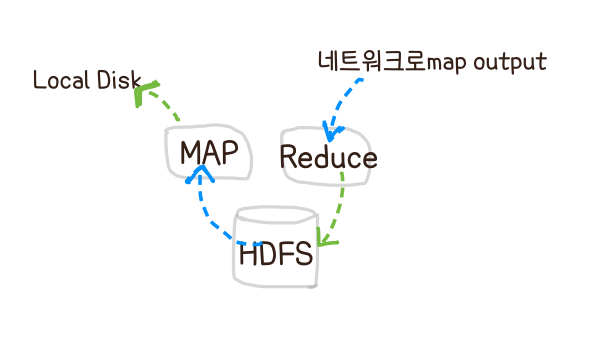
MapReduce
task들을 작게 쪼개 locality를 이용하여 가급적이면 같은 local에 있는 chunk에 assign 하려한다 (Locality _ Refinement)
Terminology
- job : a full program
- task : the execution of a single map/reduce work over data split
job을 쪼개면 task- mapper : a map task
- reducer : a reduce task
works only on KEY/VALUE pair format
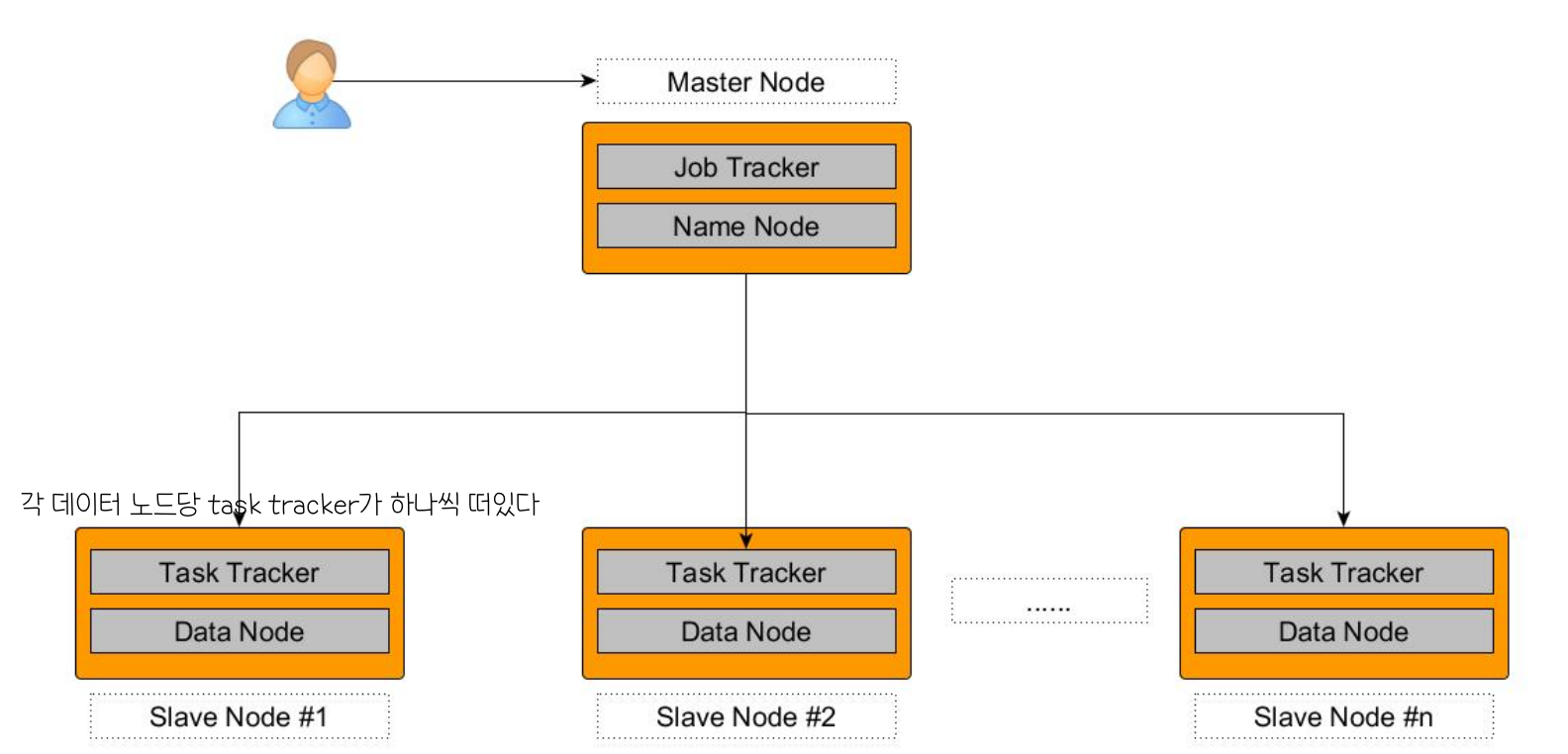
Hadoop MR Components
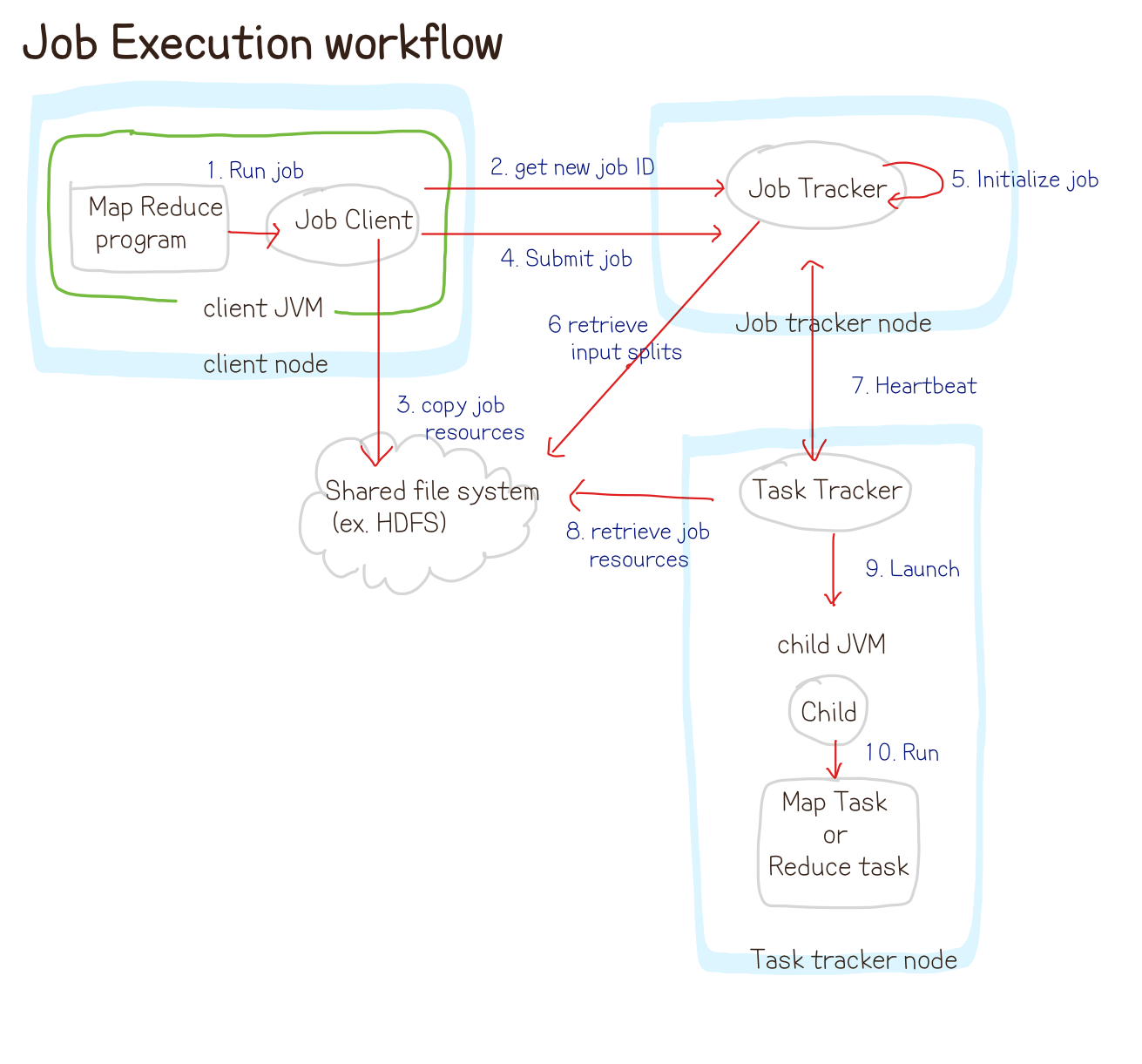
Master: JobTracker
Name Node 에 있는 Job Tracker라는 프로세서가 일을 한다
Slave : TaskTracker
- data node에서 한다고 했던 작업들을 수행하는 프로세서 (data node 하나당 하나의 tasktracker)
- Data node에 있는 각각의 task들을 manage한다
- task를 병렬적으로 처리하기 위해 JVM을 사용한다
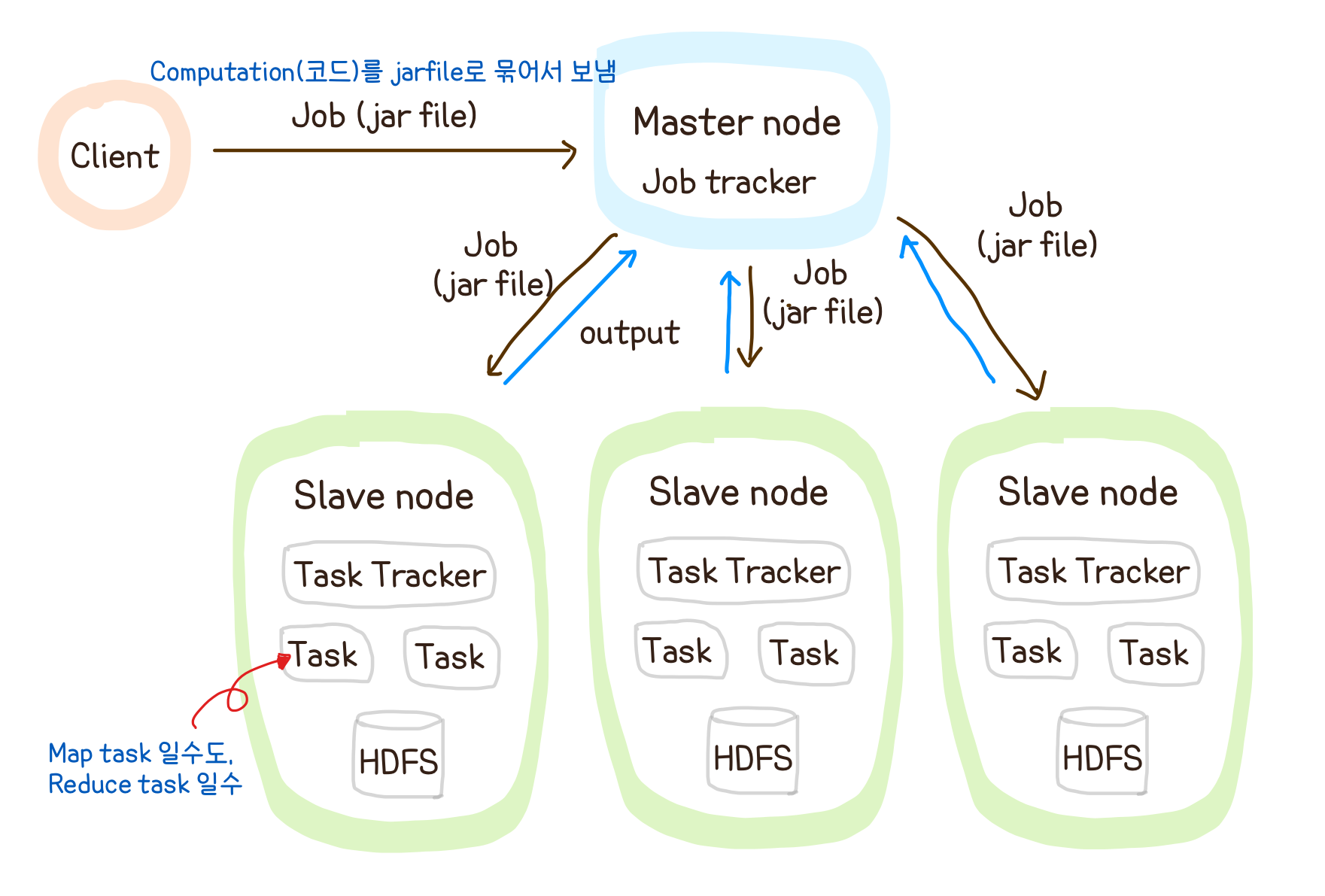
- 짜야하는 코드 (computation)
: Driver code (Setting을 짜는 코드), Mapper, Reducer
Map, Reduce는 같은 머신에서 같이 돌아간다
map task가 될수도, reduce task가 될 수도 있다
-> 어떤 머신에서는 mapper 만 돌기도, 어떤 머신에서는 mapper,reducer가 같이 돌아가기도 한다
정리
- HDFS의 Input data -> input format
- Input Split
- Record Reader
- 들어온 input을 key-value 형태로 묶어서 보냄
- key : 파일의 한 줄을 읽은 starting point의 offset
- value : 한 줄을 읽은 것
- Mapper
- Combiner
- 네트워크 save가 가능하다
- Partitioner
- 결과적으로 같은 key값으로 묶어 같은 Reducer가 한번에 처리하게 하기 위해서
- Shuffling and Sorting (merge sorting)
- Reducer
- Output format -> Output data on HDFS
Bottlenecks
-
Shuffle & Sort 에서의 bottleneck 해소
Mapper의 완성도가 100% 될때까지 기다리지 않고 몇 %이상이 되면 Reducer가 일을 시작할 수 있도록 한다 -
느린 Mapper로 인한 bottleneck 해소
speculative execution 사용
( 구글 논문에서의 "Backup Task"와 동일 )> 먼저 끝나는 애한테 늦게까지 도는 mapper의 일을 똑같이 시킨 후 먼저 output을 내는 mapper의 output사용
