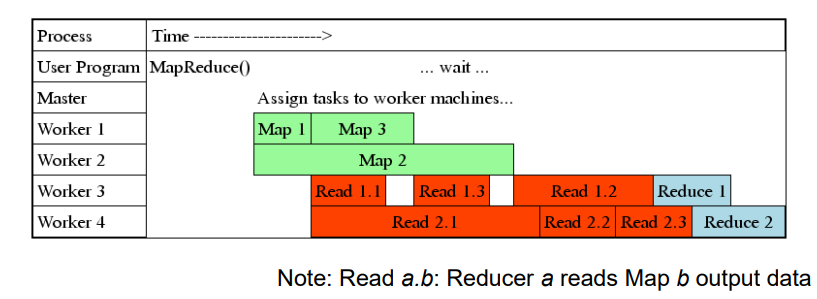
Coordination
🤴🏻 MASTER
- Master node (Name node)는 coordination을 관리한다
- task status : (idle | in-progress | completed)
- task ≠ job
- eg.
word count = job
word count를 하기위해 mapper, reducer가 각자 자기 일을 하는 잘게 쪼개 놓은 일 = task
- eg.
- task ≠ job
- idle tasks는 worker들이 available하면 schedule됨
- completed 되는 경우, master node에게 끝난 사실, location, path, size등을 모두 알려준다
- Master는 Reducer에게 해당 내용을 push한다
- Master pings workers
(핑 때린다)periodically ( Hearbeat )
: worker가 살아있는지 물어보기 위해- workers는 master의 ping에 대해 piggy backing으로 답한다.
( piggy backing = 살아있음 + assign 된 task에 대한 정보들
(네트워크 낭비 방지를 위해) )
- workers는 master의 ping에 대해 piggy backing으로 답한다.
⚒️ Dealing with Failures
-
failure는 일어날 수 밖에 없다
-
Re-execution (재실행) : main mechanism for fault-tolerance
Worker Failure 👷🏻♂️
- Master Node의 ping에 대답이 없는 경우 worker node가 죽었다고 판단
- Both completed & in-progress MAP tasks ) re-executed
- Only in-progress REDUCE tasks ) re-executed
💫 MAP task의 경우, 왜 completed task까지 re-execute해야하는가?
- Map task의 결과값은 HDFS가 아닌 LOCAL에 저장되기 때문
Master Failure 🤴🏻
-
Master Node가 죽으면 답이 없다 ( initial implementation _초기버전)
SOLUTION
- Checkpoint the state of internal structues in DFS
- 현재 상태를 그대로 복사해두는 것 ( meta data로 저장 _용량문제)
- Use replication techniques
- Master node를 replicate해두고 원래의 Namenode가 죽으며 그때 secondary namenode를 사용한다.
👍🏻 Rule of a thumb
M : number of Map tasks
R : number of Reduce tasks
Map task의 개수(M)는 pc의 CPU의 물리적인 코어 개수개만큼 자동(default)으로 생겨서 동시에 돌아간다
-
recovery의 속도가 빨라지며 load balancing을 더 세밀하게 할 수 있다
- 1GB를 복구하는 것보다 64MB를 복구하는 게 더 빠른것과 비슷
-
통상적으로 Reducer의 개수는 Mapper의 개수보다 훨씬*2 적다
- reducer는 final output을 도출하는데 reducer가 많으면..처리하기 힘듦
- 일반적으로 mapper가 일을 매우매우매우 많이하고 reducer는 놀다가 조금만 일하면 되는 것
세분화된 Task 파이프라이닝 🔧
- fault recovery를 위한 시간을 minimize한다
- Mapper와 Reducer사이에는 dependancy가 존재하기 때문에 pipelining하는 것이 빠른 일처리에 도움이 됨
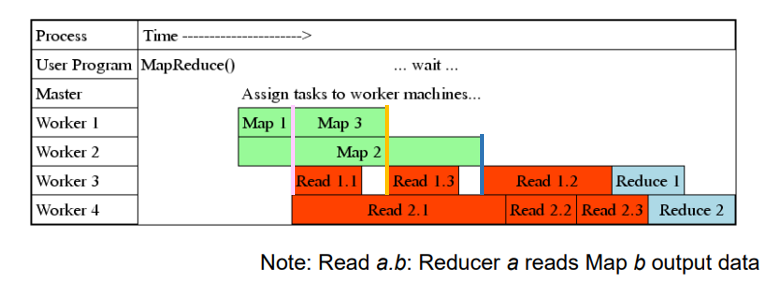
- 잘게 자름으로써 일처리가 끝나자마자 바로 fetch해올 수 있다.
🪄 Refinements
# Locality
- basic하게 돌아가는 하둡방식으로는 부족한 부분이 있으므로 그 성능을 업그레이드하기 위함
- Most input data is read locally
하둡은 가급적이면 local에 있는 map task를 가지고 assign하려고 한다
-💡 네트워크 bandwidth를 save하기 위해서 - fail이 일어나는 경우 ?
: 가까이 있는 replica 에게 시키려고 한다 (ex. 같은 렉에 있는 replica에게..)
# Backup Tasks (Speculative Execution)
>> speculative execution (하둡 용어) = Backup Tasks (구글의 논문 용어)- task들 중 하나라도 fail이 발생하면 일이 끝나질 않음
(문제는 fail이 무조건 발생할 수 밖에 없다는 것 _ 성능이 안좋은 node들을 쓰기 때문) - worker node 하나가 느려지면 나머지도 다같이 일을 못하게 되어 전체적인 속도가 느려짐
SOLUTION
- 다른 node들은 모두 일을 끝냈는데 다른애 하나가 오래 걸리고 있으면 NameNode는 똑같은 일을 다른 애한테 시켜버린다 (spawn).
- 그 중 누구든 빨리 끝내버리는 노드의 result가 선택되고 나머지들은 process kill 당한다.
==> completion time이 드라마틱하게 짧아진다
# Combiners
-
같은 key에 대한 value들이 많이 나오면 network가 많이 낭비되기 때문에 reducer로 넘기기 전에 key value value value로 묶는다
= pre-aggregating values in the mapperCombining(Grouping) 하는 건 Reducer의 일이 아닌 MAPPER의 일이다
# Partitioner
💡같은 key값이면 되도록 하나의 reducer가 다 처리해버리는게 낫지 않겠나? 라는 아이디어
- 똑같은 key값은 같은 partitioner에 넣으려는 노력을 한다
- Reduce needs to ensure that records with same intermediate key end up at the same workerhash(key) mod R
hash 함수를 사용하기 때문에 같은 key값의 hash값은 같다
😀 MapReduce가 유용한 task
- 각 단계의 dependancy가 없는 task
- Counting and summing
- ex. data querying, wordcount
- Collating 짝 맞추기
- ex. inverted index(search engine에서 자주 쓰임), ETL (Extract, Transform, Load ): 데이터 읽어오기, 처리, 가공된 데이터 저장
- Filtering , Parsing, Validation
- ex. data querying, ETL, data validation
- Distributed task execution
- ex. physical and engineering simulation , numerical analysis
- Sorting
- ex. ETL, data analysis
😥 MapReduce 쓰는게 불리한 task
- Iterative messaging passing 반복적인 일처리
- ex. 머신러닝
- 각 단계별로 처리해서 그 결과값을 다음단계로 넘겨야하는데 mapper로는 최종결과값이 나오지 않는 특성으로 인해 각 단계들을 모두 짜야한다
=> 'spark'의 출현 배경
- Cross-correlation 동시에 같은 일 수행
- ex. market analysis , text analysis
- ex. A,B가 똑같은 물건을 구매한 경우가 몇가지인가? mapreduce로 처리하기 어려움
- A가 샀다는 chunk, B가 샀다는 chunk는 존재하나 A,B가 동시에 샀다는 chunk는 존재하지 않기 때문
