(1탄 정리)
- Map Reduce기술을 기반으로 만든 프로그램 = HaDoop
Map reduce는 구글에서 만든 기술
- Map Reduce는 여러대의 일반적인 컴퓨터들을 네트워크로 묶어서 병렬 프로그래밍으로 빅데이터를 처리하는 모델이다.
- single node는 빅데이터 처리에 부적합하다
- 여기서 switch는 네트워크 스위치
- 스위치가 감당해야하는 데이터 흐름이 크기 때문에 '네트워크'에서 문제가 생김
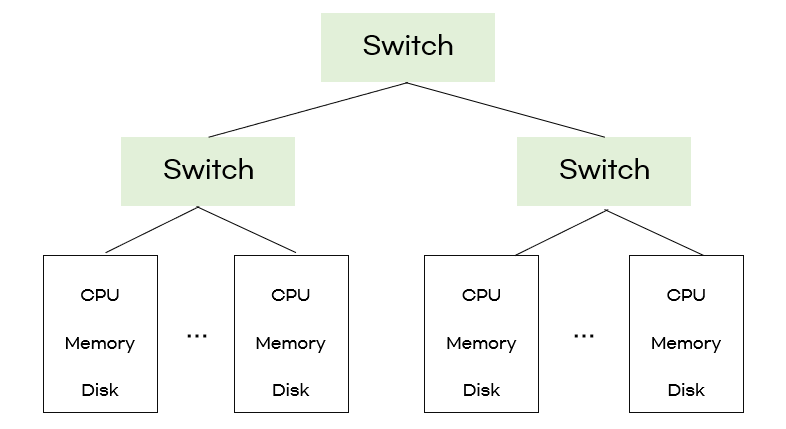
single node로는 더이상 감당할 수 없게 되어 large-scale computing으로 대체
Large-Scale Computing
- 큰 데이터를 감당할 수 없는 네트워크로 인해 'bottle neck'현상이 발생
( 네트워크 COST가 너무 높음 )➡️ computation을 local에서 ( data 가까이에서 ) 처리
: 데이터의 이동을 최소화한다➡️ file REPLICATION
: reliability를 위해 복사본을 만들어 저장Map Reduce로 위의 두가지 실현 가능
- storage infrastructure , Programming model
storage infrastructure - DFS
- Data nodes (chunk servers) , Master node (Name node)
- Data node : workers 데이터들 쪼개고 복제해서 저장
- Master node : 각 데이터들이 어디에 저장되어있는지 관리하는 metadata
Programming Model : MapReduce
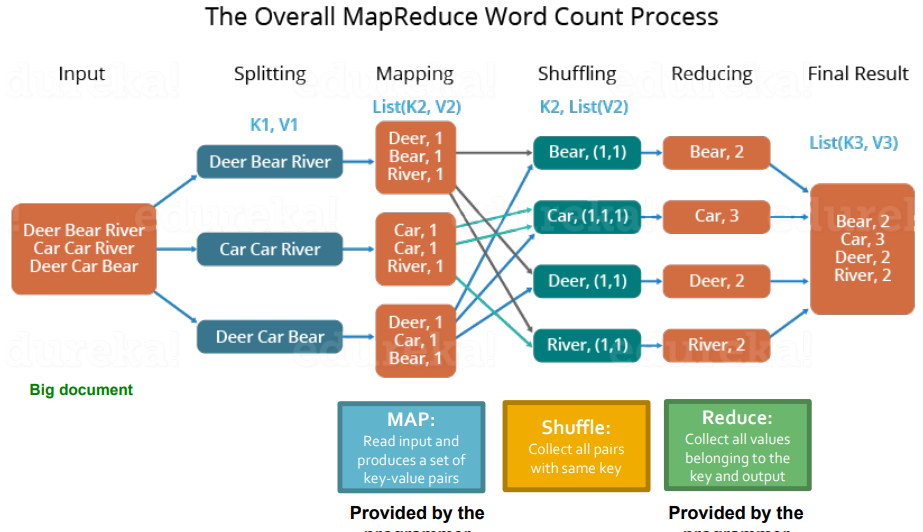
- ex. word count를 해야하는 경우
- 어떤 웹사이트가 가장 많이 검색되는 지 등을 파악할 때 자주 사용한다
> 파일 내용 읽기 -> 정렬 -> 중복되는 데이터 제거 ) 각 단계에서 서로 간섭 XMap Reduce 과정
- 모든 데이터를 sequentially 읽는다
- MAP
- Group by key : sort and shuffle
- Reduce
- Write the result
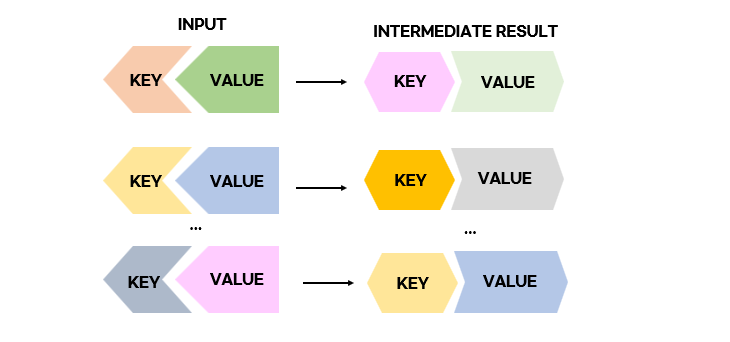
MAP step
-
Map Reduce에서 input, output 값은 무조건 key-value pair이다
-
input : a set of key-value pairs
Map(k,v) → <k',v'>*
*'는 ' 0 이상 ( many ) ' 를 의미한다e.g., (word count 예제에서) key = file name , value = 파일의 각 줄(line)즉, Mapper에서 key값은 아무런 의미가 없다.
코드
map(key, value): /* key: document name; value: text of the document*/ for each word w in value: emit(w, 1)
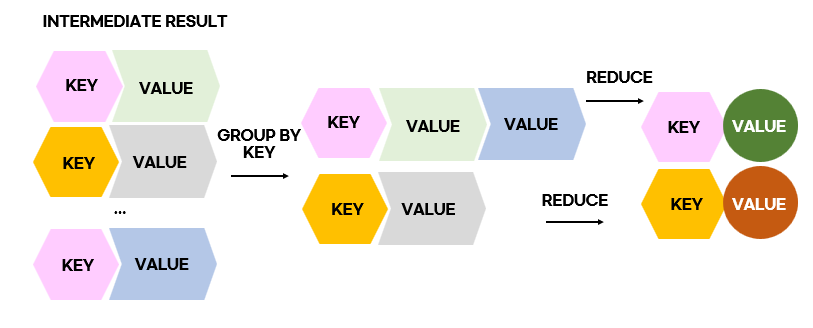
GROUP BY KEY
: 같은 key값의 value들을 grouping 하는 것
💡왜 필요한가?
map-> reduce로 데이터가 넘어가는 과정 :
- Reducer가 network를 타고와서 map의 결과(intermediate result)를 fetch해간다.
- 앞서 말했듯 network에서 bottleneck 현상이 발생하므로 이를 최소화하기위해 grouping 하여 겹치는 내용을 줄인다.
REDUCE step
key값은 같은데 reduce 과정을 거치며 value값이 달라진다
Reduce(k',<v'>) → <k',v''>
k'라는 같은 키를 가지는 모든 값들 v'은 reduced together.>
e.g., (word count 예제에서) key = word , value = count
코드
reduce(key, values): /* key: a word; value: an iterator over counts */ result = 0 for each count v in values: result += v emit(key, result) 22
MapReduce : physical view
- input으로 들어오는 데이터는 chunk단위로 쪼개짐
- mapper에서 2개의 partition으로 sorting (partitioning) 됨
- partition의 개수는 Reducer의 개수와 같아야만 한다 - Reducer는 mapper의 결과값(intermediate result)을 fetch 해간다
- 본인에 맞는 partion들을 fetch해와서 merge, sorting 후 reduce한다.
( ex. reducer1은 맨 위의 partion들만 가져옴, reducer2 는 두번째 partion들만 가져옴 )
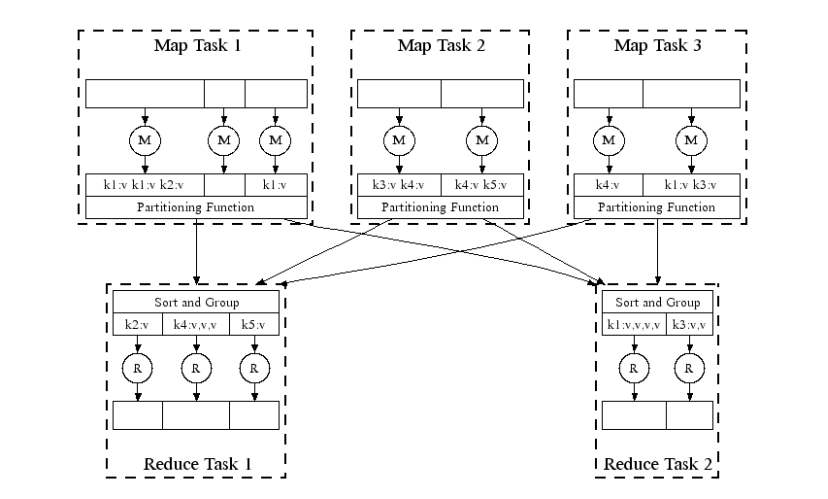
- 각각의 MAP TASK는 독립적으로 작업한다
- 각각의 REDUCE TASK는 독립적으로 작업한다
- 하지만 MAP과 REDUCE 사이에는 dependancy가 있다.
- Mapper의 작업이 모두 끝나야만 Reducer가 작업을 할 수 있기때문이다
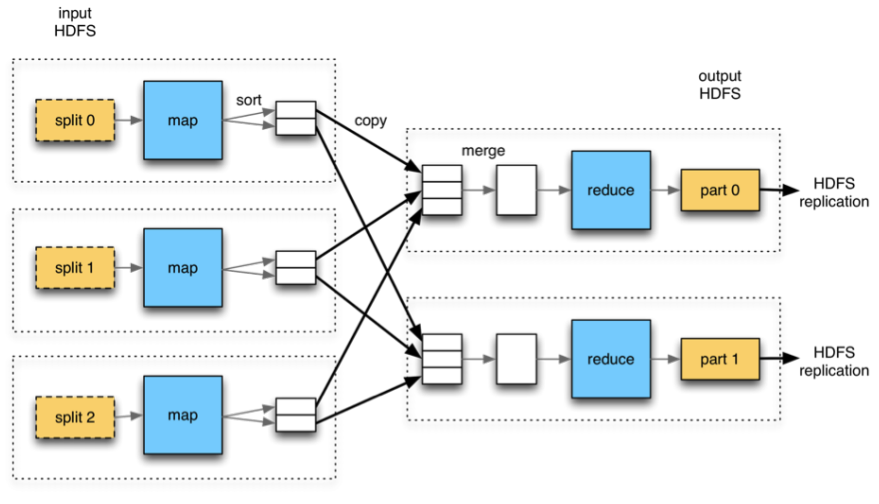
Data Flow
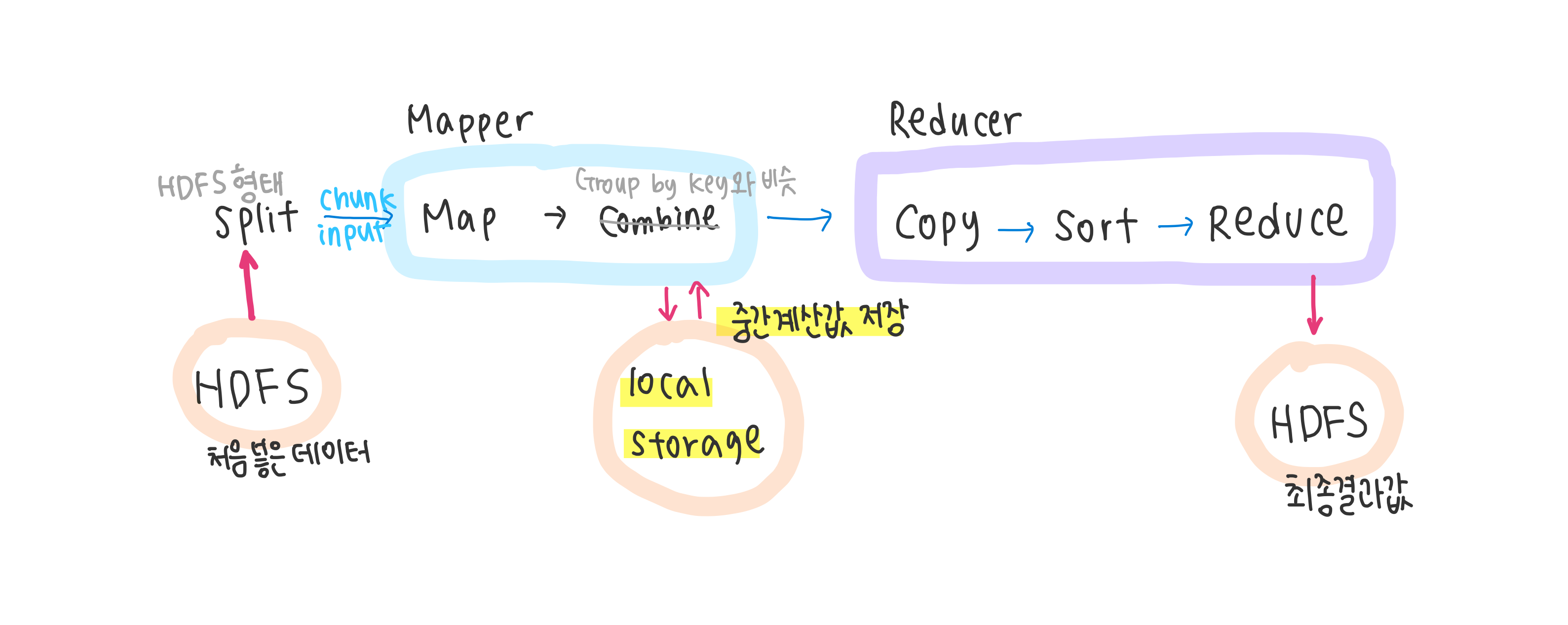
- Intermediate result는 왜 HDFS가 아닌 local에 저장하는가?
- Reducer가 fetch해가면 Mapper에겐 더이상 필요없는 데이터이므로 바로 삭제해버린다
DATAFLOW 과정
- mapper의 결과를 local에 저장한 뒤 완료사실과 저장된 주소를 namenode에게 알림
- reducer는 그 알림을 보고 mapper가 알린 주소에 접근하여 데이터 fetch해감
