SLA (Service Level Agreement)
서비스 수준 계약
- 협상, 계약서, 법적 책임, 런타임 지표 및 측정의 핵심사항
- 클라우드 제공자의 보증 내용을 공식화하고 가격 결정모델, 지불조건, 납기 결정
Service Quality Metrics
- Availabiliy 가용성
- Reliability 신뢰성
- Performance 성능
- Scalability 확장성
- Resiliency (에러에 대한) 복원력/회복성
위의 모든 항목들을 다 만족하기보다 본인의 기업 특성에 맞춰 필요한 지표들에 대해 contract를 맺는다
Service Quality Metrics 특징
- 정량화할 수 있는 Quantifiable
- 반복적인 Repeatable
- 비교할 수 있는 Comparable
- 획득이 용이한 Easily Obtainable
Service Availability Metric
- Availability Rate Metric 가용율 지표
서비스 가동시간 백분율
총 가동시간 / 총 시간
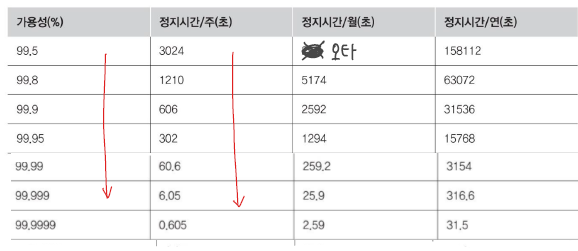
- Outage Duration Metric 가동 중단 기간 지표
단일 가동 중단 지속 기간
가동 중단 일/시간 - 가동 시작 일/시간 - 연속으로 60초 멈추는 것 ≠ 2초씩 30번 멈추는 것
Service Reliability Metric
주어진 환경에서 실패없이 IT자원이 의도된 기능을 수행하는 능력
(내가 원하는 기능을 실제로 수행하는가)
-
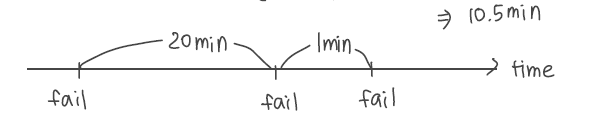
Mean-Time between Failures (MTBF) 평균고장간격
연이은 서비스 실패 사이의 기대시간
정상적인 구동시간 / 실패횟수
-
Reliability Rate Metric 신뢰율 지표
주어진 조건으로 성공적인 서비스 결과의 백분율
총 성공 응답횟수 / 총 요청 횟수- 100번 중 5번의 네트워크 연결 실패등 오류 = RRM 95%
Service Performance Metric
기능을 수행하는 능력 측정
- Network Capacity Metric 네트워크 용량 지표
네트워크 용량의 측정가능한 특징Bandwidth vs Throughput
- Bandwidth 10Mbps : 이론적으로 최대치
- 8Mbps가 나와도 상관 없음 - 최대 10Mbps이기때문
- Throughput 10Mbps : 실제로 측정되는 속도
- 차이가 발생하는 이유
: 네트워크 장비들의 성능 차이
: 동시 접속 기기 수
: 같은 이용기기 수여도 사용자가 송수신하는 데이터의 용량 차이
- Storage Device Capacity Metric 스토리지 장치 용량 지표
- Server Capaity Metric 서버용량지표
서버 용량의 측정가능한 특징
(CPU 개수, GHz 단위의 CPU주파수, GB단위의 RAM 크기,..)- Web Application Metric 웹 어플리케이션 용량 지표
웹 애플리케이션 용량의 측정가능한 특징
분당 요청률로 측정 ( 분당 몇명이 웹에 접속가능한가 )
Service Scalability Metric
- Storage Scalability (Horizontal) Metric 스토리지 확장성 지표
증가하는 작업부하(workload)에 대응해 허용가능한 스토리지 장치 용량 변화
- Server Scalability (Horizontal) Metric 서버 확장성 (수평적)
증가하는 작업부하에 대응해 허용가능한 서버 용량 변화
자원 풀 내의 가상 서버 수 - 서버의 개수
- Sever Scalability (Vertical) Metric 서버 확장성 (수직적)
증가하는 작업부하에 대응해 허용가능한 서버 용량 변화
CPU수, GB단위의 RAM 크기 - 사양!
Service Resiliency Metric
운용 장애로부터 회복하기위한 능력 측정
서버의 fail을 회복하는 법
- MTSO 다른걸로 바꾼다 ➡️ 대체하는데 걸리는 시간
- MTSR 고쳐쓴다 ➡️ 고쳐서 다시 사용하는 데까지 걸리는 시간
- Mean Time to Switch Over (MTSO) Metric 전환을 위한 평균시간
서버 실패에서 다른 지리적 영역의 복제된 인스턴스로 전환이 완료되기가 예상되는 시간
- Mean Time System Recovery (MTSR) Metric
시스템 실패로부터 완전히 회복하기까지 예상되는 시간
(회복시각/날짜 - 실패시각/날짜) / 총 실패횟수

🖥️