미리보는 최적화 결과
노드 감소량: 1,410,449개 감소
노드 감소율: 59.32% 감소
메모리 절감량: 0.897 GB
메모리 절감율: 57.5%
해당 블로그 글에서 사용된 코드는 해당 Github Repository에서 확인하실 수 있습니다.
(코드까지 포함하면 글이 너무 길어져 Github 링크를 참조하게 된 점 양해 부탁드립니다.)
자료구조 설명
Trie
Compressed Trie를 보기 전에 아주 간단하게 Trie에 대해서 복기하자면 이렇다.
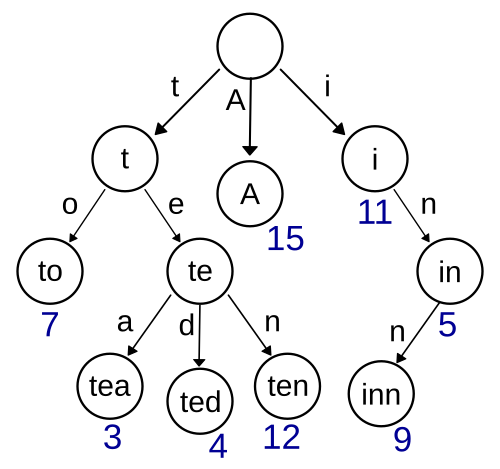
자료 출처: WIKIPEDIA
Trie는 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조이다.
각 노드마다 한 글자가 들어가며, 트리를 탐색하여 내려갈 때마다 글자가 조합되어 leaf node에 도달하면 단어가 완성이 되는 구조로 되어있다.
(사진에서 왼쪽으로 쭉 타고 내려가면 t 노드, o 노드를 지나 최종적으로 to 단어가 완성된다.)
Compressed Trie
Trie의 단점은 한 노드 당 하나의 글자만 저장하기 때문에 메모리 사용량이 크다는 단점이 있다. 이 때 단어들 간의 공통된 prefix는 하나의 노드로 묶고, 나머지 부분들은 분기하여 각각 하나의 노드로 묶는 식으로 구조를 변경하면 전체 노드 수를 크게 줄일 수 있다.
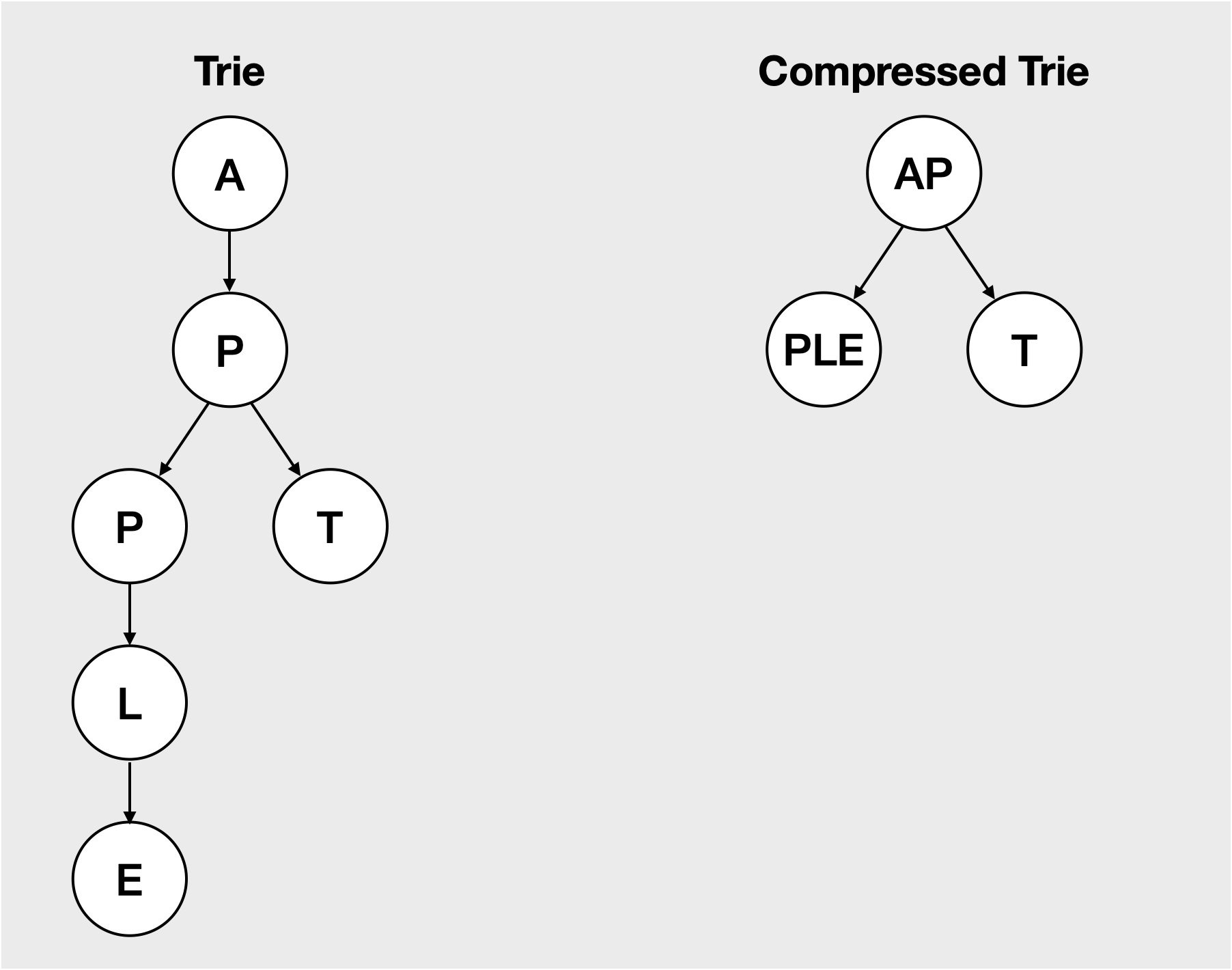
두 단어 APPLE과 APT가 주어졌다고 해보자.
두 단어의 공통된 부분(AP)을 하나의 노드로 합치고, 그 외의 겹치지 않는 글자(PLE, T)들을 각각 하나의 노드로 구성하면 Compressed Trie가 된다.
Trie에서는 노드 6개 였던 것이 Compressed Trie 에서는 노드 3개로 압축된 것을 확인 할 수 있다.
최적화 결과
데이터셋은 우리말샘 사전에서 가져왔으며, 총 단어는 1,190,944개로 테스트 데이터를 구축하였다.
Trie 구축 후
- 총 노드의 개수: 2378541
- 노드 insert 시간: 6.08초
- 노드 search 시간: 평균 0.002초
- 메모리 사용량: 1.559 GB
Compressed Trie 구축 후
- 총 노드의 개수: 968092
- 노드 insert 시간: 1분 16초
- 노드 search 시간: 평균 0.003초
- 메모리 사용량: 662 MB
정리
사전 데이터를 토대로 Compressed Trie를 구축했을 때 결과는 다음과 같다
총 결과
노드 감소량: 1,410,449개 감소
노드 감소율: 59.32% 감소
메모리 절감량: 0.897 GB
메모리 절감율: 57.5%
초기 데이터 로드에 12.5배 정도 늘어났지만 search 시간에는 큰 변동이 없으며,
메모리 절감율 57.5%면 Compressed Trie의 압축률은 훌륭하다고 볼 수 있다.
Insert 시간이 증가한 이유는 Compressed Trie에서는 단어 삽입 시 노드를 분할(split)하거나 병합(merge)해야 하는 경우가 생기기 때문이다.
(Trie는 Insert시 추가 연산이 없음)
블로그 정리를 위해 Compressed Trie 자료를 다시 찾아보다보니 한국어 자료가 부족하다는 걸 느꼈습니다.
그럴리는 없겠지만 반응이 좋다면, Compressed Trie의 Insert, Search, Delete 연산에 대해서 코드와 함께 블로그 정리하겠습니다.
