썸네일 출처: toomanyafterthoughts 사이트
미리보는 결론
단일 DB의 환경이라면, 인덱스 크기를 고려하여 AUTO_INCREMENT를 사용하는 것이 좋다.
그러나 보안을 신경써야 하며 여러 노드가 동시에 ID를 생성하는 환경이라면, UUID가 좋다.
또한, UUID 버전 중 순수 랜덤이 필요 없는 경우에는 성능을 고려하여 v6 또는 v7을 사용하는 것이 효율적이다.
UUID란?
UUID(Universally Unique IDentifier)는 간단하게 겹치지 않는 ID라고 보면 된다.
일반적으로 32개의 16진수(HEX)로 구성되어있으며, 하이폰으로 구분해서 총 36글자로 되어있다.
UUID 예시)
d6e74418-2081-4256-8c44-d8922d26deceUUID 장점
AUTO_INCREMENT를 사용하는 ID 값과 대비하여 UUID가 가지는 장점이 있다.
- 보안적 이점: 순차 ID(1,2,..)는 쉽게 추측되어 예측이 가능하지만, UUID는 랜덤/비예측적이라 위험도가 낮다.
- 동시성 확장성 향상:
AUTO_INCREMENT는 DB가 시퀀스를 관리해 병목이 생기고 샤딩이 어렵다. UUID는 애플리케이션에서 독립 생성이 가능해 여러 서버나 리전에서 충돌없이 생성 가능하다.
UUID 버전별 차이점
| 버전 | 방식 / 기반 | 비트 순서 | 특징 | 단점 |
|---|---|---|---|---|
| v1 | 시간 기반 | timestamp → MAC 주소 | 시간 기반으로 저장 | 개인정보 노출 위험, 정확한 시간 순이 아님 |
| v2 | DCE Security | v1 기반 + UID/GID | 권한/보안용 | 거의 사용되지 않음 |
| v3 | 이름 기반 + MD5 | MD5 해시로 결정적 생성 | 동일 입력 → 동일 UUID | 충돌 가능, 순서 없음 |
| v4 | 랜덤 | 완전 랜덤 | 충돌 거의 없음, 보안적 안전 | 순서 없음 → DB 인덱스 비효율 |
| v5 | 이름 기반 + SHA1 | SHA1 해시로 결정적 생성 | 동일 입력 → 동일 UUID | 순서 없음, SHA1 → 느림 |
| v6 | 시간 기반 개선 | timestamp → random/node | 시간 순 정렬 최적화, MAC 제거 | 아직 표준 확정 전, 일부 라이브러리 미지원 |
| v7 | Unix timestamp + 랜덤 | timestamp → random | 최신 표준, 시간 순 정렬 최적화, 보안적 안전 | 최신 표준 → 일부 라이브러리 미지원 |
버전별 사용처
이름 기반
버전 v3, v5는 입력값에 따라 항상 동일한 UUID가 생성된다.
또한, v5는 MD5 대비 충돌 확률이 낮다.
즉, 입력값에 따른 고정 ID값이 필요한 경우에 v5 사용이 권장된다.
랜덤 기반
버전 v4는 완전히 랜덤하게 생성된다.
따라서 충돌 가능성이 거의 없으며, 보안적으로도 안전하다.
범용적으로 사용되는 버전이며, 유니크한 ID 값이 필요할 때 사용이 권장된다.
시간 기반
버전 v1, v6, v7은 생성 시, 시간 정보를 포함하므로 순차적으로 생성된다.
덕분에 DB B-Tree 인덱스 삽입 시 성능이 최적화된다.
그 중에서 v1은 완벽한 순차적 정렬이 보장되지 않으며, MAC 주소로 인해 개인정보 노출의 위험이 있어 최근에는 사용되는 기법이 아니라고 한다.
즉, DB의 효율을 생각한다면 v6, v7이 권장된다.
근거
v4는 완전 랜덤이기 때문에 데이터를 삽입할수록 인덱스 조각화가 심해진다. 이는 I/O 비용이 증가하고, 인덱스 조회 성능이 저하된다는 것을 의미한다.
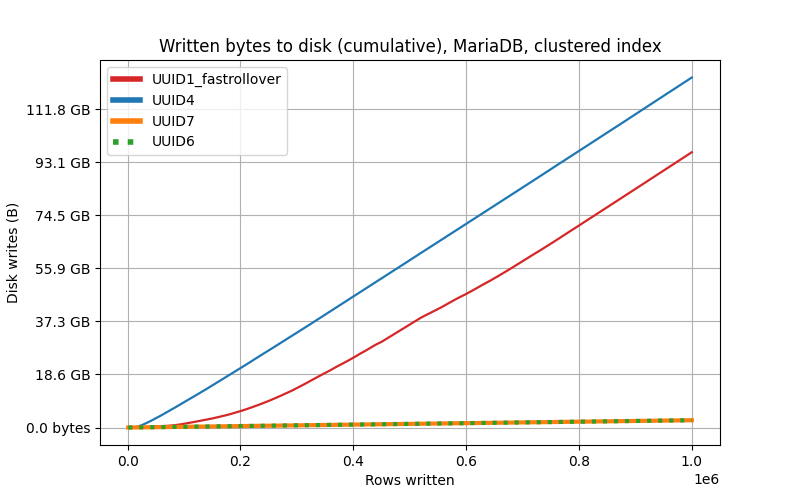
사진 출처: toomanyafterthoughts 사이트
위의 자료는 데이터 삽입 대비 디스크 사용량을 나타낸 자료이다. 시간 기반인 v6, v7은 데이터가 많이 삽입되도 디스크 페이지를 순차적으로 사용하므로 디스크 쓰기량이 최소화됨을 확인할 수 있다. (v1도 시간 기반이지만 정확한 시간 순서로 정렬되지 않아 v6, v7에 비해 디스크 사용 최적화가 덜 효율적임도 볼 수 있다.)
게시글 작성 순서를 '결론 -> 배경 -> 설명 -> 근거' 순으로 작성해 보았는데, 독자 입장에서 어떤 방식이 더 친화적인지 고민된다..
