hashCode를 재정의해야하는 이유
hashCode를 재정의하지 않으면hashCode일반규약을 어기게 되어hash값을 사용하는Collection(HashSet,HashMap)을 사용할 때 문제가 발생할 수 있다.
[hashCode를 재정의하지 않아 예상과 다르게 작동하는 HashSet]
public class HashMapSample {
public static void main(String[] args) {
final List<PhoneNumber> phoneNumbersList = new ArrayList<>();
phoneNumbersList.add(new PhoneNumber(707, 867, 5309));
phoneNumbersList.add(new PhoneNumber(707, 867, 5309));
System.out.println("list size: " + phoneNumbersList.size());
// 예상 실행결과 : 크기 2
final Set<PhoneNumber> phoneNumberSet = new HashSet<>();
// List에서 중복값을 허용하지 않는 Set으로 로직을 변경.
phoneNumberSet.add(new PhoneNumber(707, 867, 5309));
phoneNumberSet.add(new PhoneNumber(707, 867, 5309));
System.out.println("set size: " + phoneNumberSet.size());
// 예상 실행결과 : 크기 1
}
}
// 실행결과
list size: 2
set size: 2- 중복을 허용하지 않는
Set이 예상과 다르게2개의 크기를 갖는다는 결과가 나오는데 이는hash값을 사용하는Collection객체가 논리적으로 같은지 비교하는 과정을 살펴보면 그 원인을 알 수 있다.
[hash값을 사용하는 Collection 객체가 논리적으로 같은지 비교하는 과정]
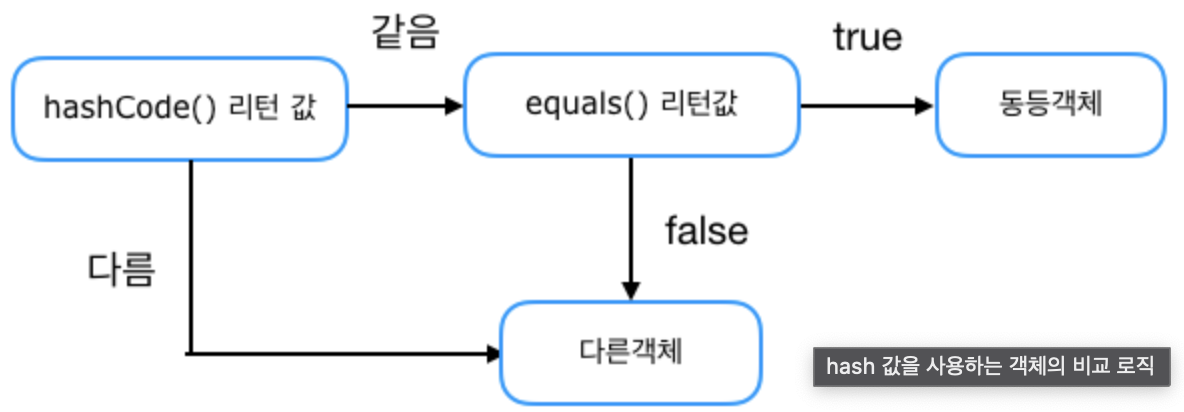
hashCode메서드의 리턴값이 일치하고equals메서드의 리턴값 또한 일치해야 동등한 객체라고 판단한다.PhoneNumber클래스는hashCode가 재정의되어있지 않아서Object클래스의hashCode메서드가 사용되었다.Object클래스의hashCode메서드는 객체마다 다른값을 리턴한다. 두 개의PhoneNumber클래스는hashCode메서드의 리턴 값으로 인해 다른 객체로 판단된 것이다.
hashCode 일반 규약
hashCode를 재정의할 때 지켜야하는 규약
-
equals비교에 사용되는 정보가 변경되지 않았다면, 애플리케이션이 실행되는 동안 그 객체의hashCode도 몇 번을 호출해도 항상 같은 값을 반환해야 한다.
(애플리케이션을 다시 실행한다면 이 값이 달라져도 상관없다.) -
equals가 두 객체가 같다고 판단했다면, 두 객체의hashCode는 똑같은 값을 반환한다.
(논리적으로 같은 객체는 같은 해시코드를 반환해야한다.) -
equals가 두 객체를 다르게 판단했더라도,hashCode는 꼭 다를 필요는 없다.
(하지만, 다른 객체에 대해서는 다른 값을 반환해야 해시테이블의 성능이 좋아진다.)
hashCode는 다른 객체에 대해서는 다른 값을 반환해야 한다.
논리적으로 같은 객체는 같은 해시코드를 반환해야 한다. 만약,
hashCode재정의를 잘못 한다면 일반규약의 두번째 조항이 문제가 된다.
[hashCode를 재정의하지 않아 두 객체가 서로가 다른 hashCode를 반환하는 경우]
public class PhoneNumber {
private final int areaCode, prefix, lineNum;
private int hashCode; // 자동으로 0으로 초기화
public PhoneNumber(final int areaCode, final int prefix, final int lineNum) {
this.areaCode = areaCode;
this.prefix = prefix;
this.lineNum = lineNum;
}
}
public class HashMapSample {
public static void main(String[] args) {
Map<PhoneNumber, String> map = new HashMap<>();
map.put(new PhoneNumber(707, 867, 5309), "제니");
System.out.println("size: " + map.size());
System.out.println(map.get(new PhoneNumber(707, 867, 5309)));
}
}
// 실행결과
size: 1
nullPhoneNumber 클래스는 hashCode를 재정의하지 않았기 때문에 논리적 동치인 두 객체가 서로 다른 해시코드를 반환하여 get 메서드는 엉뚱한 해시 버킷에가서 객체를 찾으려 한 것이다.
심지어 두 객체가 같은 해시 버킷에 담아져 있더라도 get메서드는 여전히 null을 반환한다. HashMap은 해시코드가 서로 다른 엔트리끼리는 동치성을 비교하지 않도록 최적화되어 있기 때문이다.
올바른 hashCode를 작성하는 방법
hashCode의 세번째 규약 - 좋은 해시함수라면 서로 다른 인스턴스에 다른 해시코드를 반환한다.
-
int변수result를 선언한 후 값c로 초기화한다. 이때c는 해당 객체의 첫번째 핵심 필드를 단계 2.A 방식으로 계산한 해시코드다.
(핵심코드란equals비교에 사용되는 필드) -
해당 객체의 나머지 핵심 필드
f각각에 대해 다음 작업을 수행한다.
A. 해당 필드의 해시코드c를 계산한다.- 기본 타입 필드라면,
Type.hashCode(f)를 수행한다. 여기서Type은 해당 기본 타입의 박싱 클래스 - 참조 타입 필드면서 이 클래스의
equals()가 이 필드의 equals를 재귀적으로 호출해 비교한다면, 이 필드의hashCode를 재귀적으로 호출한다. 계산이 더 복잡해질 것 같으면, 이 필드의 표준형을 만들어 그 표준형의hashCode를 호출한다. 필드의 값이null이면0을 사용한다. - 필드가 배열이라면, 핵심 원소 각각을 별도 필드처럼 다룬다. 이상의 규칙을 재귀적으로 적용해 각 핵심 원소의 해시코드를 계산한 다음, 단계 2.B 방식으로 갱신한다. 배열에 핵심 원소가 하나도 없다면
0을 사용한다. 모든 원소가 핵심 원소라면Arrays.hashCode를 사용한다.
B. 단계 2.A에서 계산한 해시코드
c로result를 갱신한다. 코드는 다음과 같다.
result = 31 * result + c; - 기본 타입 필드라면,
-
result를 반환한다.
단, 파생 필드는 hashCode 계산에서 제외해도 좋다. 즉, 다른 필드로부터 계산해 낼 수 있는 필드는 모두 무시해도 된다. 또한 equals 비교에 사용되지 않은 필드는 반드시 제외해야 한다. 그렇지 않다면 hashCode 규약을 어기게 될 위험이 있다.
[올바른 hashCode 메서드 작성방법을 적용한 경우]
@Override
public int hashCode() {
int result = Short.hashCode(areaCode);
result = 31 * result + Short.hashCode(prefix);
result = 31 * result + Short.hashCode(lineNum);
return result;
}PhoneNumber 인스턴스의 핵심 필드 3개를 사용해 계산을 하고, 이 과정에 비결정적 요소는 없다. 동치인 PhoneNumber 인스턴스는 서로 같은 해시코드를 반드시 가지게 된다.
Object 클래스에서도 hash 메서드를 제공한다.
[Object 클래스에서 제공하는 hash메서드를 구현한 hashCode() - 성능이 살짝 아쉽다.]
@Override
public int hashCode() {
return Objects.hash(lineNum, prefix, areaCode);
}이 메서드는 단 한줄로 작성할 수 있어 간편하지만 속도가 느리다. 입력 인수를 담기 위한 배열이 만들어지고 입력 중 기본 타입이 있다면 박싱과 언박싱도 거치기 때문이다. 따라서 성능에 민감하지 않은 상황에서만 사용하는것이 좋다.
해시코드의 캐싱
- 클래스가 불변이고 해시코드를 계산하는 비용이 크다면, 캐싱하는 방식을 고려하는 것이 좋다.
- 객체가 주로 해시의 키로 사용될 것 같다면 인스턴스가 만들어질 때 해시코드를 계산해둬야 한다.
지연 초기화
- 해시의 키로 사용되는 경우가 아니라면
hashCode가 처음 불릴때 지연 초기화하는 것이 좋다. - 필드를 지연 초기화하려면 그 클래스를 스레드 안전하게 만들도록 신경써야 한다.
[해시코드를 지연 초기화하는 hashCode() - 스레드 안정성을 고려해야 한다]
private int hashCode; // 자동으로 0으로 초기화
@Override
public int hashCode() {
int result = hashCode;
if(result == 0){
result = Short.hashCode(areaCode);
result = 31 * result + Short.hashCode(prefix);
result = 31 * result + Short.hashCode(lineNum);
hashCode = result;
}
return result;
}동시에 여러 쓰레드가 hashCode를 호출하면 여러 쓰레드가 동시에 계산하여 처음 의도와는 다르게 여러번 계산하는 상황이 발생할 수 있다. 따라서 지연 초기화를 하려면 동기화를 신경써주는것이 좋다.
hashCode 작성시 주의할 점
- 성능을 높인다고 해시코드를 계산할 때 핵심 필드를 생략해서는 안된다.
hashCode가 반환하는 값의 생성 규칙을 API사용자에게 자시히 공표하지 말자. 그래야 클라이언트가 값에 의지하지 않고 추후에 필요하다면 계산방식을 바꿀수도 있다.
[결론]
equals를 재정의할 때는 hashCode도 반드시 재정의 해야한다. 그렇지 않으면 프로그램이 제대로 동작하지 않는다. 재정의한 hashCode는 Object의 API문서에 기술된 일반규약을 따라야 하며, 서로 다른 인스턴스라면 되도록 해시코드도 서로 다르게 구현해야 한다.
