3.8 분산분석
1. 용어 정리
- 쌍별 비교(pairwise comparison): 여러 그룹 중 두 그룹 간의 가설검정
- 총괄검정(omnibus test): 여러 그룹 평균들의 전체 분산에 관한 단일 가설 검정
- 분산분해(decomposition of variance): 구성 요소 분리
- F 통계량(F-statistic): 그룹 평균 간의 차이가 랜덤 모델에서 예상되는 것에서 벗어나느 정도를 측정하는 표준화통계량
- SS(sum of squares): 어떤 평균으로부터의 편차들의 제곱합
2. 분산분석이란?
- 여러 그룹간의 통계적으로 유의미한 차이를 검정하는 통계적 절차
- ANOVA 라고 부르기도 한다.
3. 예제
- 코드
import pandas as pd
import numpy as np
url = "https://raw.githubusercontent.com/gedeck/practical-statistics-for-data-scientists/master/data/four_sessions.csv"
four_sessions = pd.read_csv(url)
observed_variance = four_sessions.groupby('Page').mean().var()[0]
print('Observed means:', four_sessions.groupby('Page').mean().values.ravel())
print('Variance:', observed_variance)
def perm_test(df):
df = df.copy()
df['Time'] = np.random.permutation(df['Time'].values)
return df.groupby('Page').mean().var()[0]
perm_variance = [perm_test(four_sessions) for _ in range(3000)]
print('Pr(Prob)', np.mean([var > observed_variance for var in perm_variance]))- 결과
각 그룹당 평균값, 분산 그리고 p 값을 확인할 수 있다.

3.8.1 F 통계량
1. F 통계량
- 잔차 오차로 인한 분산과 그룹 평균의 분산에 대한 비율을 기초로 한다.
- 비율이 높을수록 통계쩍으로 유의미하다고 할 수 있다.
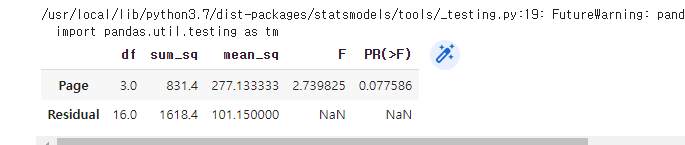
2. 예제: ANOVA 테이블 계산
- 코드
import statsmodels.api as sm
import statsmodels.formula.api as smf
model = smf.ols('Time ~ Page', data = four_sessions).fit()
aov_table = sm.stats.anova_lm(model)
aov_table- 결과
3.8.2 이원 분산분석
1. 주요 개념
- ANOVA는 여러 그룹의 실험 결과를 분석하기 위한 통계적 절차이다.
- A/B 검정과 비슷한 절차를 확장하여 그룹 간 전체적인 편차가 우연히 발생할 수 있는 범위 내에 있는지를 평가하기 위해 사용한다.
- ANOVA의 결과 중 유용한 점 중 하나는 그룹 처리, 상호작용 효과, 오차와 관련된 분산의 구성 요소들을 구분하는 데 있다.
피터 브루스, 앤드루 브루스의 <데이터 과학을 위한 통계(2판): 데이터 분석에서 머신러닝까지 50가지 핵심 개념> 을 읽고 정리한 내용입니다.

My_Spielraum