데이터 과학을 위한 통계
1.임의표본추출과 표본편향
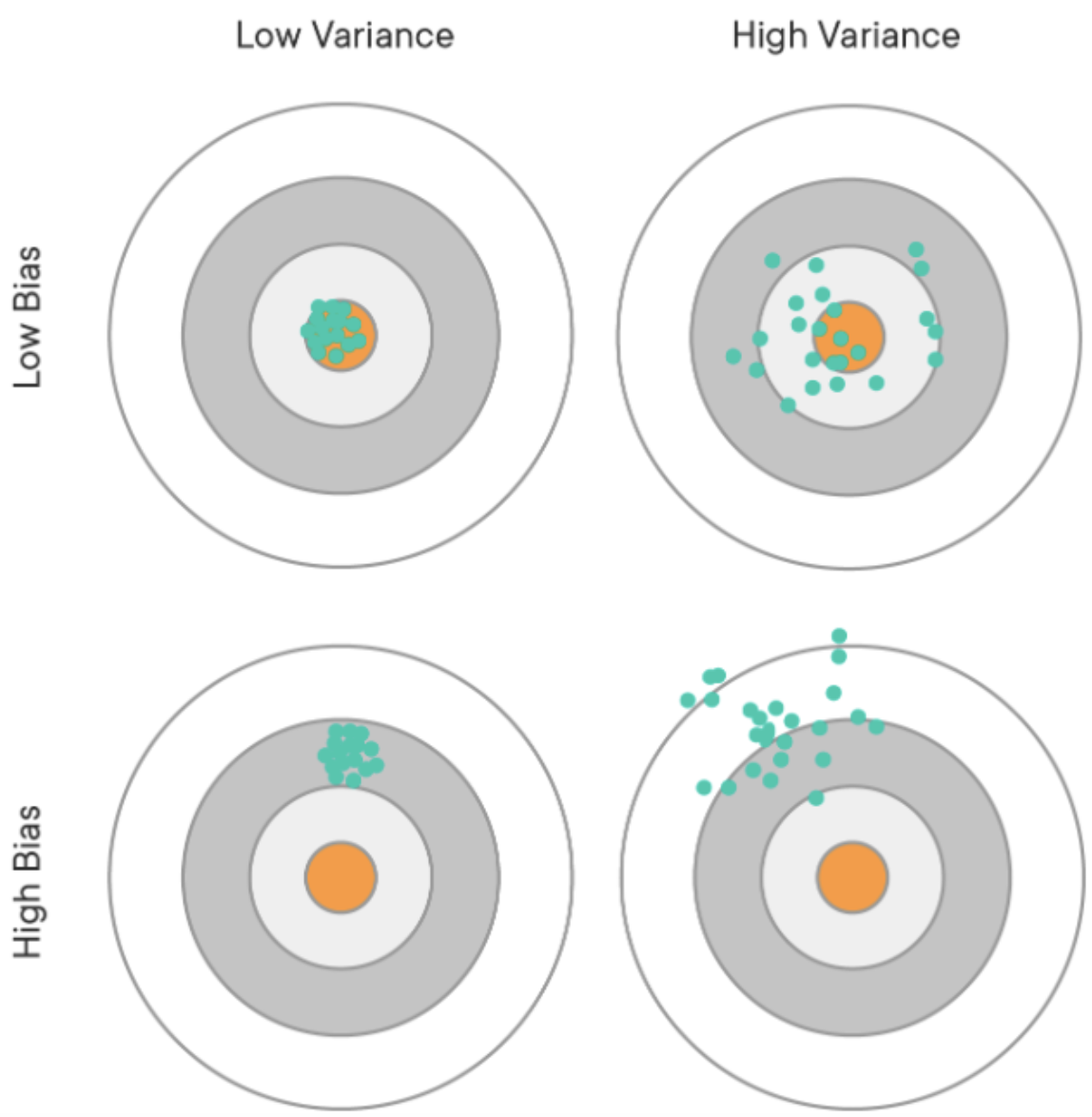
1\. 기본 용어 정리모집단(population): 데이터의 전체 집합표본(sample): 모집단의 부분 집합N(n): 모집단(표본)의 크기임의표본추출(random sampling): 무작위로 표본을 추출하는 것 층화표본추출(stratified sampling): 모
2.선택편향
1\. 용어 정리선택편향(selection bias): 관측 데이터를 선택하는 방식 때문에 생기는 평향데이터 스누핑(data snooping): 뭔가 흥미로운 것을 찾아 광범위하게 데이터를 살피는 것방대한 검색 효과(vast search effect): 중복 데이터 모
3.통계학에서의 표본 분포
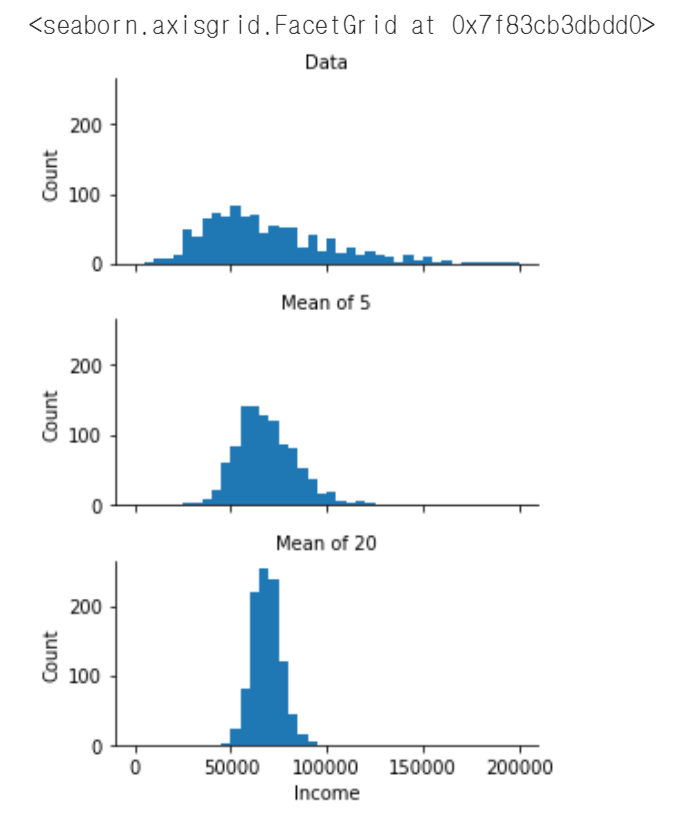
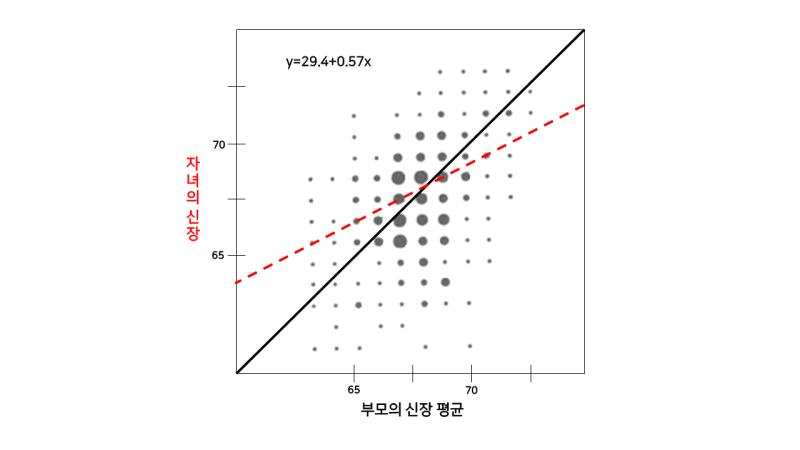
2.3 통계학에서의 표본분포 1. 용어정리 표본통계량(sample statistic): 더 큰 모집단에서 추출된 표본 데이터들로부터 얻은 측정 지표 데이터 분포(data distribution): 어떤 데이터 집합에서의 각 개별값의 도수 분포 표본분포(sampling
4.부트스트랩

1\. 용어정리부트스트랩 표본(bootstrap sample): 관측 데이터 집합으로부터 얻은 복원추출 표본재표본추출(resampling)관측데이터로부터 반복해서 표본추출하는 과정부트스트랩과 순열(셔플링) 과정을 포함2\. 부트스트랩의 재표본추출 알고리즘샘플 값을 하나
5.신뢰구간
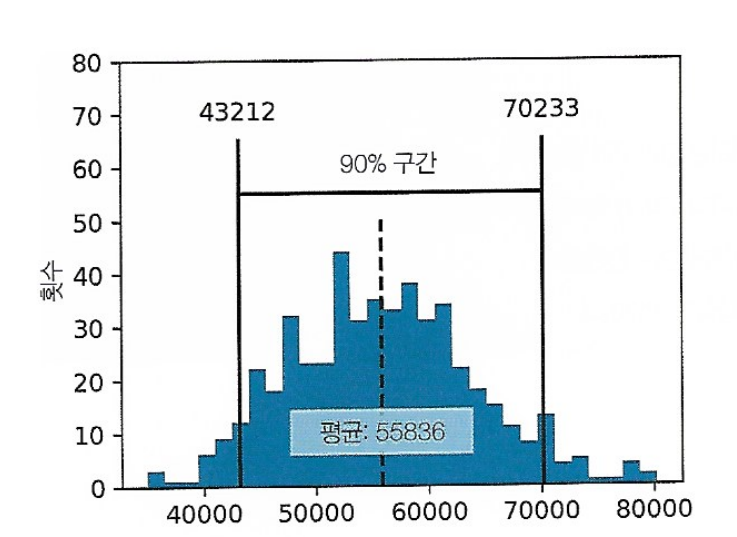
1\. 용어정리신뢰수준(confidence level): 같은 모집단으로부터 같은 방식으로 얻은, 관심 통계량을 포함할 것으로 예상되는, 신뢰구간의 백분율구간끝점(interval endpoint): 신뢰구간의 최상위, 최하위 끝점2\. 부트스트랩 신뢰구간 구하는 법데이
6.정규분포

1\. 용어정리오차(error): 데이터 포인트와 예측값 혹은 평균 사이의 차이표준화(정규화)하다(standardize): 평균을 빼고 표준편차로 나눈다.z 점수(z-score): 개별 데이터 포인트를 정규화한 결과표준정규분포(standard normal distrib
7.긴 꼬리 분포
1\. 용어 정리꼬리(tail): 적은 수의 극단값이 주로 존재하는, 도수분포의 길고 좁은 부분왜도(skewness): 분포의 한쪽 꼬리가 반대쪽 다른 꼬리보다 긴 정도2\. 긴 꼬리 분포일반적으로 데이터는 정규분포를 따르지 않는다.대칭 및 비대칭 분포 모두 긴 꼬리를
8.스튜던트의 t 분포
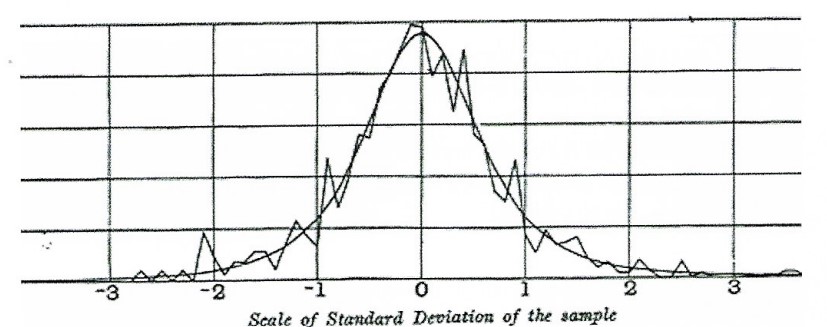
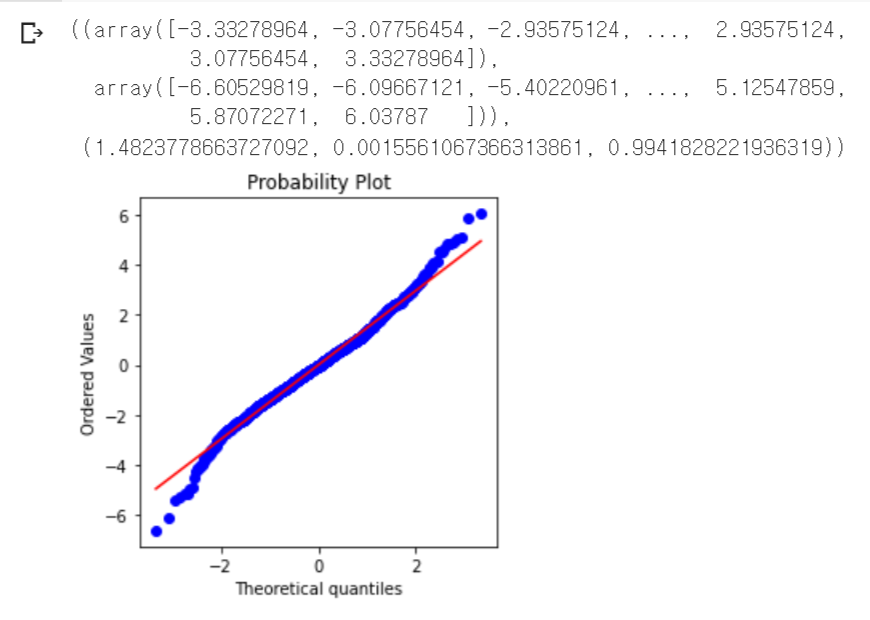
1\. 용어 정리n : 표본 크기자유도(degrees of freedom): 다른 표본크기, 통계량, 그룹의 수에 따라 t분포를 조절하는 변수2\. t 분포t 분포(t-distribution) \* 정규분포와 생김새가 비슷하지만, 꼬리 부분이 더 두껍고 길다.일반적으
9.이항분포

1\. 용어 정리시행(trial): 독립된 결과를 가져오는 하나의 사건성공(success): 시행에 대한 관심의 결과이항식(binomial): 두 가지 결과를 갖는다이항시행(binomial trial): 두 가지 결과를 가져오는 시행 (= 베르누이 시행)이항분포(bin
10.카이제곱분포
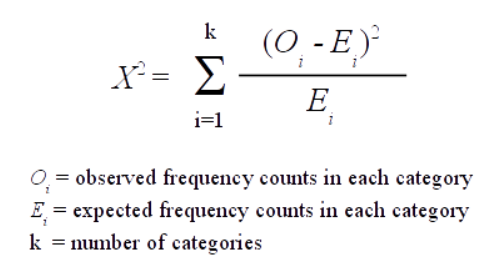
1\. 카이제곱통계량 이란?검정 결과가 독립성에 대한 귀무 기댓값에서 벗어난 정도를 측정하는 통계량관측 데이터가 특정 분포에 '적합'한 정도를 나타낸다.2\. 카이제곱 식관측값과 기댓값의 차이를 기댓값의 제곱근으로 나눈 값을 다시 제곱하고 모든 범주에 대해 합산한 값출
11.F 분포
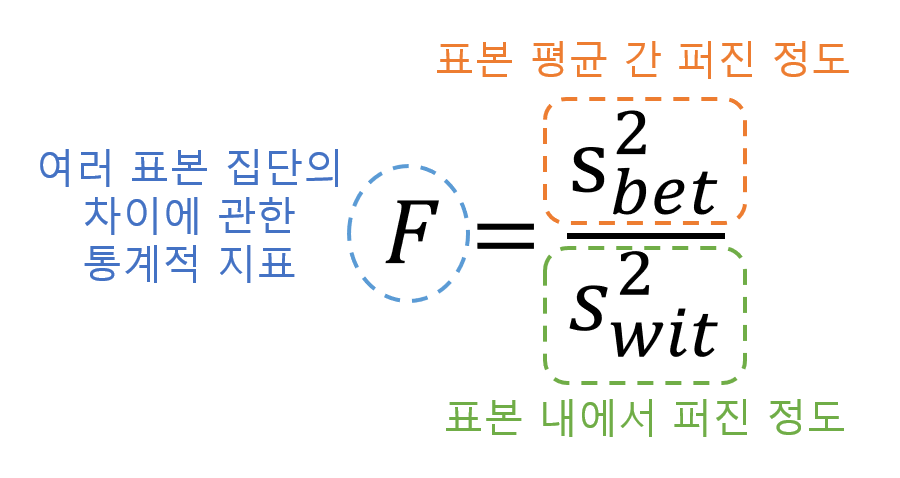
1\. F 통계량각 그룹 내 변동성(잔차 변동성)에 대한 그룹 평균 간 변동성의 비율분산분석(ANOVA) 라고도 함출처: https://angeloyeo.github.io2\. F 분포연속된 관측값을 처리회귀 모형에 의해 설명된 변동성을 데이터 전체의 변동과
12.푸아송 분포와 그 외 관련 분포들

1\. 용어 정리람다(lambda): 단위 시간이나 단위 면적당 사건이 발생하는 비율푸아송 분포(Poisson distribution): 표집된 단위 시간 혹은 단위 공간에서 발생한 사건의 도수분포지수분포(exponential distribution): 한 사건에서 그
13.통계적 실험과 유의성 검정

전통적인 통계추론 과정출처: 데이터 과학을 위한 통계1\. 용어 정리처리(treatment): 어떤 대산에 주어지는 특별한 환경이나 조건처리군(treatment group): 특정 처리에 노출된 대상들의 집단대조군(control group): 어떤 처리도 하지 않은 대
14.재표본 추출 & 통계적 유의성 & p값
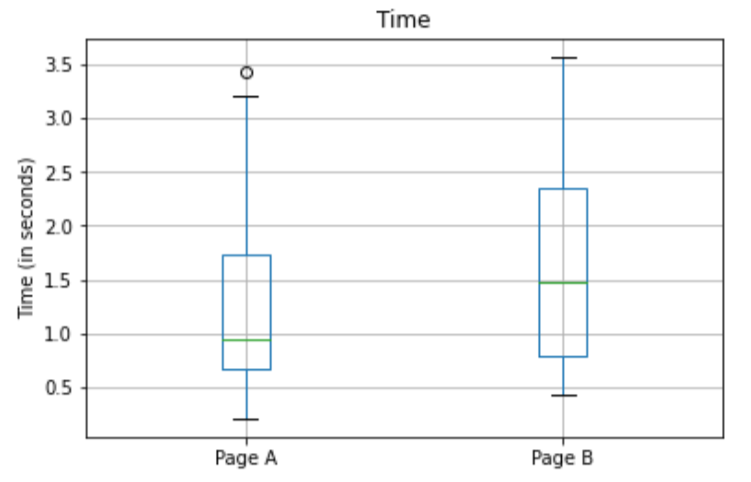
1\. 용어 정리재표본추출: 관측 데이터로부터 반복해서 표본 추출하는 과정.순열검정(permutation test): 두 개 이상의 표본을 함께 결합하여 관측값들을 무작위로(또는 전부를) 재표본으로 추출하는 과정을 말한다.복원/비복원(with or without rep
15.t 검정 & 다중 검정 & 자유도

1\. 용어 정리검정통계량(test statistic): 관심의 차이 또는 효과에 대한 측정 지표t 통계량(t-statistic): 평균과 같이 표준화된 형태의 일반적인 검정통계량t 분포(t-distribution): 관측된 t 통계량을 비교할 수 있는, (귀무가설에서
16.분산분석

1\. 용어 정리쌍별 비교(pairwise comparison): 여러 그룹 중 두 그룹 간의 가설검정총괄검정(omnibus test): 여러 그룹 평균들의 전체 분산에 관한 단일 가설 검정분산분해(decomposition of variance): 구성 요소 분리F 통
17.카이제곱검정

1\. 용어 정리카이제곱통계량(chi-square statistic): 기댓값으로부터 어떤 관찰값까지의 거리를 나타내는 측정치기댓값(expectation): 어떤 가정으로부터 데이터가 발생할 때, 그에 대해 기대하는 정도d.f.(degrees od freedom): 자
18.멀티암트 밴딧 알고리즘 & 검정력과 표본 크기

1\. 용어 정리멀티암트 밴딧(MAB): 고객이 선택할 수 있는 손잡이가 여러 개인 가상의 슬롯 머신을 말하며, 각 손잡이는 각기 다른 수익을 가져다준다. 다중 처리 실험에 대한 비유라고 생각할 수 있다.손잡이(arm): 실험에서 어떤 하나의 처리를 말한다상금(win)
19.주성분
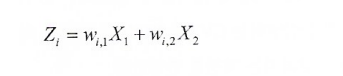
1\. 용어 정리주성분(principal component): 예측변수들의 선형결합부하(loading): 예측변수들을 성분으로 변형할 때 사용되는 가중치스크리그래프(screeplot): 성분들의 변동을 표시한 그림. 설명된 분산 혹은 설명된 분산의 비율을 이용하여 성분
20.k-평균 클러스터링

1\. 용어 정리클러스터(cluster): 서로 유사한 레코드들의 집합클러스터 평균(cluster mean): 한 클러스터 안에 속한 레코드들의 평균 벡터 변수k: 클러스터의 개수클러스터의 중심 (클러스터내에 존재하는 점들의 평균)클러스터 내부의 제곱합k-평균 할당법:
21.계층적 클러스터링
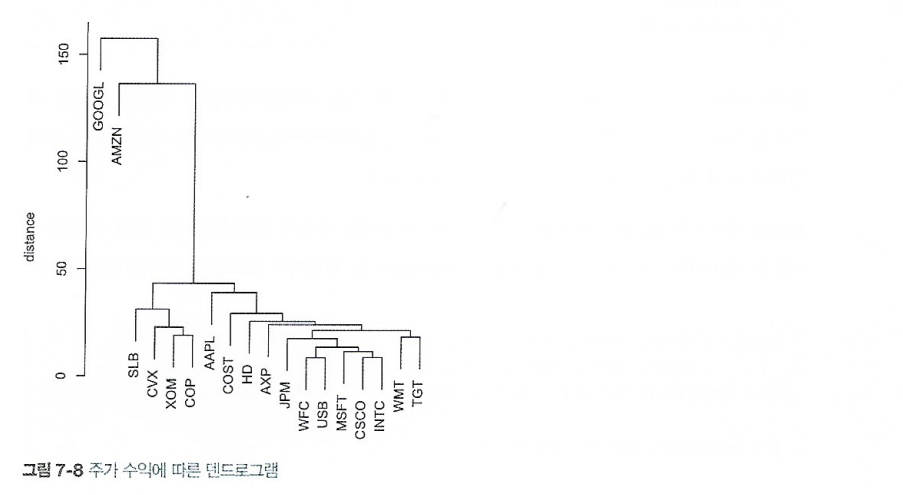
1\. 용어 정리덴드로그램(dendrogram): 레코드들, 그리고 레코드들이 속한 계측적 클러스터를 시각적으로 표현거리(distance): 한 레코드가 다른 레코드들과 얼마나 가까운지를 보여주는 측정 지표비유사도(dissimilarity): 한 클러스터가 다른 클러스
22.모델 기반 클러스터링
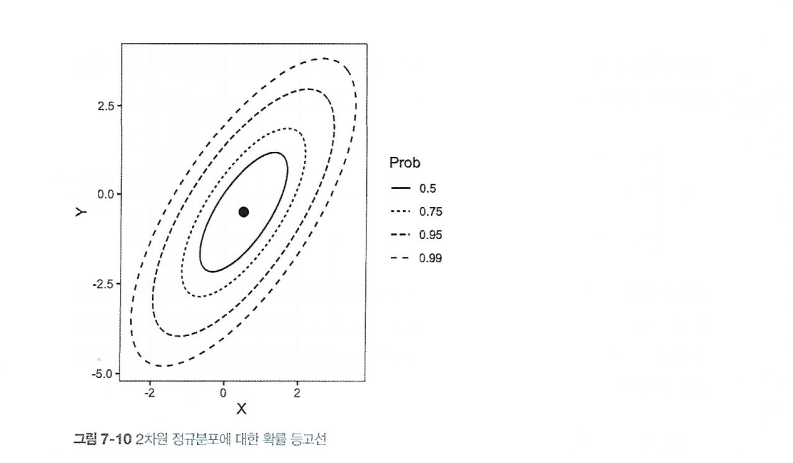
1\. 다변량정규분포란?p개의 변수 집합 X1, X2, X3, ... , Xp에 대해 정규분포를 일반화한 것분포는 평균 집합과 공분산행렬로 정의된다.공분산행렬은 변수가 서로 어떻게 상호 관련되어 있는지 나타내는 지표모델 기반 클러스터링의 핵심 아이디어는 각 레코드가 k
23.스케일링과 범주형 변수

1\. 용어 정리스케일링(scaling): 데이터의 범위를 늘리거나 줄이는 방식으로 여러 변수들이 같은 스케일이 오도록 하는 것정규화(normalization): 원래 변수 값에서 평균을 뺀 후에 표준편차로 나누는 방법으로, 스케일리의 일종이다.고워 거리(Gower's