2.1 임의표본추출과 표본편향
1. 기본 용어 정리
- 모집단(population): 데이터의 전체 집합
- 표본(sample): 모집단의 부분 집합
- N(n): 모집단(표본)의 크기
- 임의표본추출(random sampling): 무작위로 표본을 추출하는 것
- 층화표본추출(stratified sampling): 모집단을 층으로 나눈 뒤, 각 층에서 무작위로 표본을 추출하는 것
- 계층(stratum): 공통된 특징을 가진 도집단의 동종 하위 그룹
- 단순임의표본(simple random sample): 모집단 층화 없이 임의표본추출로 얻은 표본
- 편향(bias): 계통상의 오류
- 표본편향(sample bias): 모집단의 잘못 대표하는 표본
2. 자기선택 표본편향
- 소셜미디어 사이트의 호텔, 카테 등에 대한 리뷰어 = 편향된 표본
- 작성자 스스로 리뷰 작성에 대한 주도권을 쥐고 있음 = 자기선택편향
2.1.1 편향
1. 편향이란?
- 편향이 높다 = 예측 값과 정답의 차가 크다
2. 편향의 종류
- 임의표본추출로 인한 오류
- 편향에 따른 오류
3. 예시
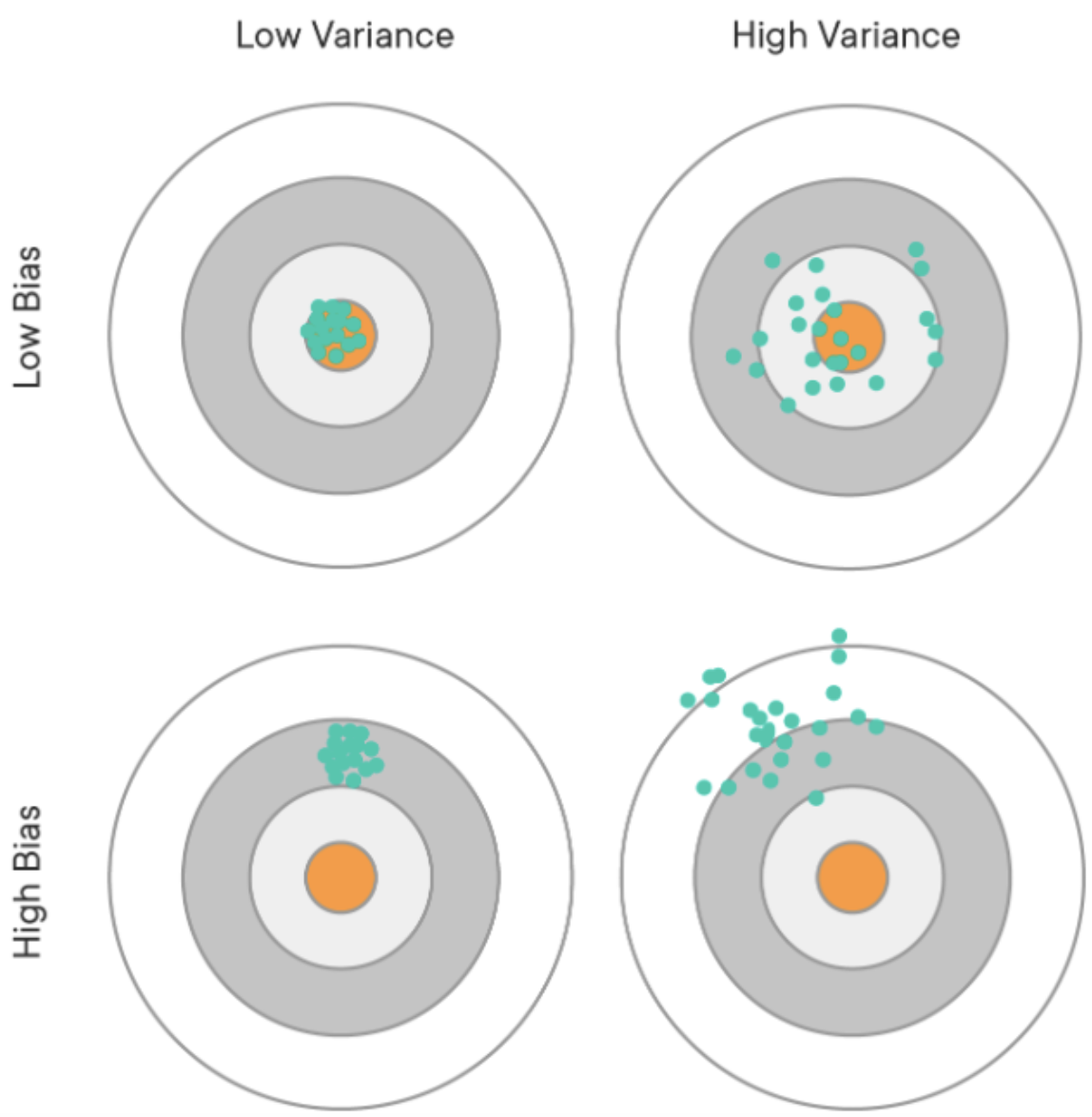
[출처: The Dangers of Under-fitting and Over-fitting]
2.1.2 임의 선택
-
임의 표본 추출
- 접근 가능한 모집단을 적절하게 정의
- 즉 모집단의 대표성 잘 정의
- 무작위로 표본 추출
-
층화 표본 추출
- 모집단을 층으로 나눈다.
- 각 층에서 무작위로 샘플 추출
2.1.3 크기와 품질: 크기는 언제 중요해질까?
-
빅데이터가 필요한 경우
- 데이터가 크고 동시에 희소한 경우
- 주어진 쿼리에 대해 가장 잘 예측된 검색 대상 결정
- 데이터가 누적될수록 효과적인 검색 결과 반환
-
굳이 빅데이터가 아니어도 되는 경우
- 연관된 레코드
- 예를 들어, 클릭한 사용자의 정보
- 수천 개 정도만 되어도 효과적일 수 있다.
2.1.4 표본평균과 모평균
- 모집단
- 모평균 = 모집단의 평균
- 모집단에 대한 정보 = 표본들로 추론
- 표본
- 표본 평균 = 모집단의 표본 평균
- 표본에 대한 정보 = 관찰을 통해 얻어짐
피터 브루스, 앤드루 브루스의 <데이터 과학을 위한 통계(2판): 데이터 분석에서 머신러닝까지 50가지 핵심 개념> 을 읽고 정리한 내용입니다.

My_Spielraum