2.3 통계학에서의 표본분포
1. 용어정리
- 표본통계량(sample statistic): 더 큰 모집단에서 추출된 표본 데이터들로부터 얻은 측정 지표
- 데이터 분포(data distribution): 어떤 데이터 집합에서의 각 개별값의 도수 분포
- 표본분포(sampling distribution): 여러 표본들 혹은 재표본들로부터 얻은 표본통계량의 도수분포
- 중심극한정리(central limit theorem): 표본크기가 커질수록 표본분포가 정규분포를 따르는 경향
- 표준오차(standard error): 여러 표본들로부터 얻은 표본통계량의 변량
- 표준편차와 다름
2. 데이터 분포 vs 표본 분포
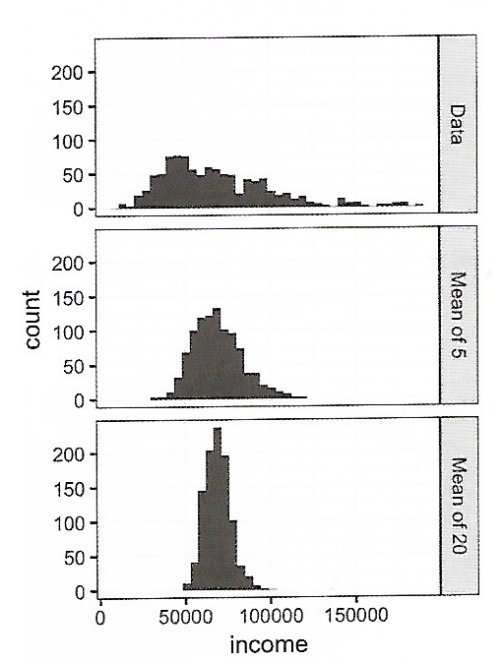
[출처: 데이터 과학을 위한 통계]
- 데이터 분포 : 개별 데이터들의 분포
- 표본 분포: 표본 통계량의 분포
3. 실습 예제
- 코드
책보고 코드 그대로 실행시켰는데 자꾸 오류 나서, 코드 조금 수정했다
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
url = "https://raw.githubusercontent.com/gedeck/practical-statistics-for-data-scientists/master/data/loans_income.csv"
loans_income = pd.read_csv(url)
sample_data = pd.DataFrame.from_records([{
'income': loans_income.sample(1000),
'type': 'Data'
}])
sample_mean_05 = pd.DataFrame.from_records([{
'income': [loans_income.sample(5).mean() for _ in range(1000)],
'type': 'Mean of 5'
}])
sample_mean_20 = pd.DataFrame.from_records([{
'income': [loans_income.sample(20).mean() for _ in range(1000)],
'type': 'Mean of 20'
}])
results = pd.concat([sample_data, sample_mean_05, sample_mean_20])
g = sns.FacetGrid(results, col = 'type', col_wrap = 1, height = 2, aspect = 2)
g.map(plt.hist, 'income', range = [0, 200000], bins = 40)
g.set_axis_labels('Income', 'Count')
g.set_titles('{col_name}')- 결과
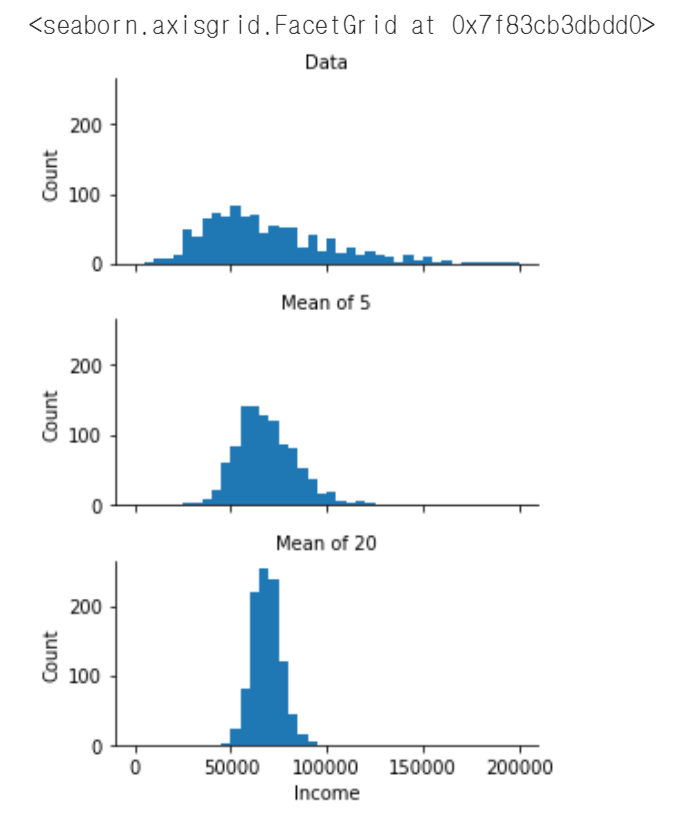
2.3.1 중심극한정리
1. 중심 극한 정리
- 모집단이 정규 분포가 아니더라도
- 표본크기가 충분하고 데이터가 정규성을 크게 이탈하지 않는 경우
- 여러 표본에서 추출한 평균은 종모양의 정규곡선을 따른다
2.3.2 표준오차
1. 표준오차란?
- 표본분포의 변동성을 말해주는 단일 측정 지표
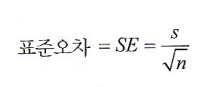
- 표준오차와 표본 크디는 반비례
2. 표준오차를 측정할 때 고려할 사항
- 모집단에서 완전히 새로운 샘플들을 많이 수집한다.
- 각각의 새 샘플에 대해 통계량(예: 평균)을 계산한다.
- 2단계에서 얻은 통계량의 표준편차를 계산한다. 이것을 표준오차의 추정치로 사용한다.
3. 부트스트랩
- 실제로 새로운 샘플을 지속적으로 수집하는 것은 불가능 & 비효율
- 부트스트랩 재표본 사용으로 해결
- 부트스트랩 = 표준 오차를 추정하는 표준 방법
4. 표준편차 vs 표준오차
- 표준편차: 개별 데이터 포인트의 변동성 측정
- 표준오차
- 표본 측정 지표의 변동성 측정
- 표본통계량의 변동성을 요약하는 주요 지표
피터 브루스, 앤드루 브루스의 <데이터 과학을 위한 통계(2판): 데이터 분석에서 머신러닝까지 50가지 핵심 개념> 을 읽고 정리한 내용입니다.

My_Spielraum