🔎 Elastic Search 란?
오픈소스 검색 엔진
🗒 노드, 클러스터, 인덱스
노드는 하나의 검색엔진 서버를 의미합니다.
노드의 이름은 uuid로 고유한 이름을 갖게 되며, 다른 이름으로도 변경 가능하나 고유 값을 갖도록 설정 해주세요.
위의 노드들이 모인 것이 클러스터 입니다.
단일 데이터들이 다큐멘트이며, 이 데이터들의 모음이 인덱스 입니다. 인덱스는 indices라고도 불립니다. 이 인덱스들의 모음이 노드입니다.
샤드는 인덱스의 단위를 의미하며, 샤드가 존재하는 이유는 인덱스의 데이터가 커지거나 작업량이 많아질 경우를 대비하여 인덱스의 데이터를 분산할때 사용합니다.
좀 편하게 이해하자면 아래와 같습니다.
documents(데이터) < shard(데이터 분류) <= index(테이블) < node(검색 서버) < cluster
🛫 Install
Java, elastic search를 설치해야합니다.
아래 링크로 들어가셔서 java를 다운받아주세요.
https://www.java.com/ko/download/
다음으로는 elastic search를 받아야합니다.(mac기준)
home brew를 사용하시면 다운로드가 훨씬 편합니다.
터미널에 접속하셔서 아래 명령어들을 입력하시면 됩니다.
//brew 업데이트를 먼저 진행해줍니다.
$brew update
//아래 명령어들을 사용해 elasticseach를 다운로드 합니다.
$brew install elastic/tap/kibana-full
$brew install elasticsearch-full위와같이 설치가 완료되면 아래 명령어를 실행해주세요
$elasticsearchelasticsearch는 9200번 포트에서 작동합니다.
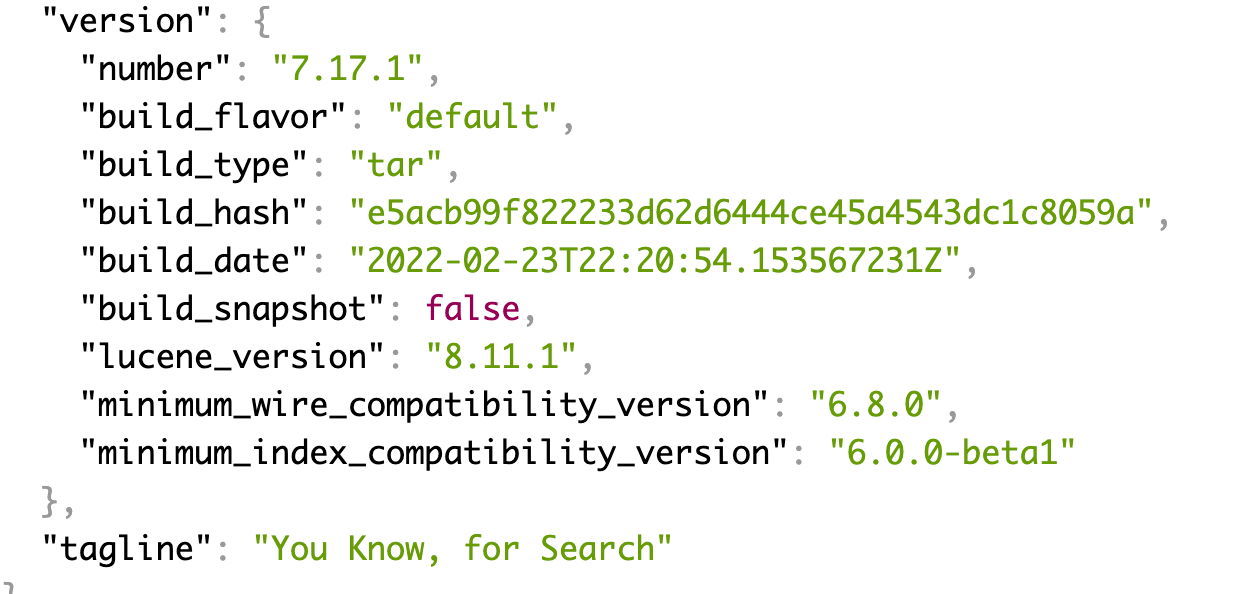
http://127.0.0.1:9200/
위로 접속하면 기본적인 클러스터 정보들이 뜨게 됩니다.
9200번 포트에서 잘 작동하는걸 확인 했다면 node js 서버와의 연동을 확인해보겠습니다.
npm 혹은 yarn으로 elastic search 패키지를 설치해주세요.
yarn add @elastic/elasticsearch위와같이 설치가 완료되면 node 서버와의 연결을 시도해볼까요?
import { Client } from "@elastic/elasticsearch";
const client = new Client({
node: "http://localhost:9200",
maxRetries: 5,
requestTimeout: 60000,
sniffOnStart: true,
});
async function bootstrap() {
try {
client.ping();
console.log("9200번 포트 연결");
} catch (e) {
console.log(e);
}
}
bootstrap();연결이 잘 되면 아래처럼 console log 찍은게 잘 뜨게 됩니다.
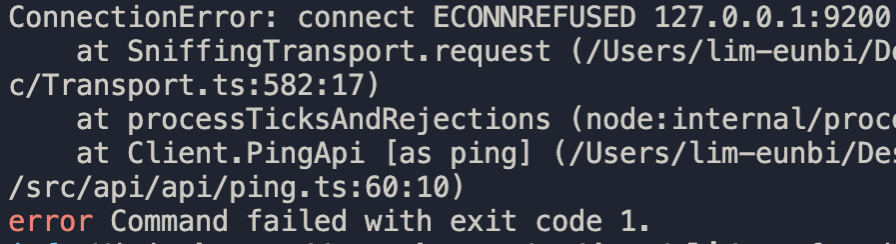
만약에 elastic search를 시작하지 않고 위의 코드만 실행 했다면 아래처럼 에러코드를 띄우며 node js가 실행되지 않습니다. 터미널에서 $elasticsearch 를 반드시 실행해주세요.
🔢 인덱스 생성
kibana 사용은 아래 링크를 참조해주세요. 저는 javascript만 사용했지만 kibana로 간단하게 진행하는 방법도 있습니다.
https://needjarvis.tistory.com/546
아래 코드를 활용하여 인덱스를 생성하였습니다. 인덱스 이름은 tickers로 생성하였습니다.
try {
client.indices.create({
index: "{인덱스 이름}",
});
} catch (error) {
console.log(error);
}
생성이 잘 되면 http://127.0.0.1:9200/{인덱스 이름} 에서 아래와 같은 화면이 뜨게됩니다.

이제 엘라스틱 서치 데이터를 삽입하려 합니다. 그럴려면 type 이나 document, index 개념에 슬슬 혼동이 올텐데, 아래를 참조하시면 이해하시기 편할겁니다.
| RDBMS | Elasticsearch |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
** 엘라스틱 7.0 부터는 인덱스의 개념과 type의 개념이 동일해져서 하나의 index당 하나의 타입을 갖는 것으로 변경 됐다고 합니다 **
␐ 데이터 INSERT
저는 서버리스를 사용하였기에 mysql과 elasticsearch가 연동가능한 logstash를 사용하지 않았습니다.
혹시나 해당 내용이 궁금하다면 아래 블로그를 참조해보세요. 설명이 자세합니다.
https://drhot552.github.io/web/Logstash-%EC%9D%B4%EC%9A%A9%ED%95%98%EC%97%AC-mysql%EC%99%80-ElasticSearch-%EC%97%B0%EB%8F%99%ED%95%98%EA%B8%B0/#logstash%EC%99%80-mysql%EC%99%80-elasticsearch-%EC%97%B0%EB%8F%99%ED%95%98%EA%B8%B0
저는 csv 파일을 elastic search 데이터로 저장할 것이기때문에 아래 코드를 활용 하였습니다.
위에서 만든 인덱스 밑으로 데이터를 넣어주면 됩니다.
document에는 데이터 내용을 적어주시면 됩니다. 제가 넣은 symbol이나 name 등을 테이블의 칼럼명으로 적어 주시면 됩니다.
추가적으로 fs.readFileSync는 꼭 절대 경로로 접근해야합니다.
import fs from "fs";
const file = fs.readFileSync(
"절대경로/파일이름.csv",
"utf8"
);
const data = file.split("\r\n");
for (let i = 1; i < data.length; i++) {
const ticker = data[i].split(",");
await client.index({
index: "{인덱스 이름}",
document: {
symbol: ticker[0],
name: ticker[1],
country: ticker[6],
sector: ticker[9],
industry: ticker[10],
},
});
}데이터가 잘 저장 됐는지 확인 하기 위해 아래 링크로 접속하시면 됩니다.
http://127.0.0.1:9200/{인덱스 이름}

이제 get으로 데이터가 잘 받아지는지 확인 해보겠습니다.
http://127.0.0.1:9200/{인덱스 이름}/_search?q={검색어}
아래와 같이 들어온다면 검색이 잘 되고 있는 겁니다! ㅎㅎ

🖨 Node js 에서 Search api와 연동
이제 쿼리로 검색어를 입력해서 해당하는 데이터를 보내는 nest js 코드를 작성하도록 하겠습니다.
elasticsearch를 연결하는 connection.ts는 아래와 같이 작성합니다.
// connection.ts
import { Client } from "@elastic/elasticsearch";
const client = new Client({
node: "http://localhost:9200",
maxRetries: 5,
requestTimeout: 60000,
sniffOnStart: true,
});
export default client;api 서비스를 처리하는 service.ts에서 위에서 연결한 client를 import 합니다.
import한 client를 사용하여 search를 진행합니다.
//findings.service.ts
async find(keyword): Promise<Findings[]> {
const query = keyword;
const elastic = client;
try {
const data = await elastic.search({
index: "{인덱스 이름}",
query: {
match: {
{칼럼명}: keyword,
},
},
});
//임시로 return 값은 query로 설정
return query;
} catch (error) {
console.log(error);
}
}controller에서 설정해준 url로 들어가 데이터를 받아오면 아래와 같이 타입이 object인 데이터로 들어오게됩니다.(저의 경우에는 http://127.0.0.1:4000/tickers/search?keyword={검색어} 로 설정하였습니다.)
object
{
took: 36,
timed_out: false,
_shards: { total: 1, successful: 1, skipped: 0, failed: 0 },
hits: {
total: { value: 104, relation: 'eq' },
max_score: 4.499482,
hits: [
[Object], [Object],
[Object], [Object],
[Object], [Object],
[Object], [Object],
[Object], [Object]
]
}
}분석해보면 아래와 같다고 합니다.(https://www.elastic.co/guide/en/elasticsearch/client/javascript-api/current/search_examples.html)
| 이름 | 의미 |
|---|---|
| took | Elasticsearch가 검색을 실행하는 데 걸린 시간(밀리초) |
| timed_out | 검색의 시간 초과 여부 |
| shards | 검색한 샤드 수 및 검색에 성공/실패한 샤드 수 |
| hits | 검색 결과 |
| hits.total | 검색 조건과 일치하는 문서의 총 개수 |
| hits.hits | 검색 결과의 실제 배열(기본 설정은 처음 10개 문서) |
| hits.sort | 결과의 정렬 키(점수 기준 정렬일 경우 표시되지 않음) |
| max_score | 매칭에 성공한 도큐먼트중 가장 높은 점수 |
저희는 hits 안에 있는 hits에 접근 해야합니다.
data.hits.hits를 콘솔 찍어보면 아래와 같은 형식으로 나오게됩니다.
//예시
[
//...(중략)
{
_index: 'tickers',
_type: '_doc',
_id: 'VFgSzH8B6Mx3vsBiOEzf',
_score: 3.2218409,
_source: {
symbol: 'ALIN^A',
name: 'Altera Infrastructure L.P. 7.25% Series A ',
country: 'Bermuda',
sector: '',
industry: ''
}
}
]이렇게 배열 안에 object로 들어온 데이터들을 for문, 혹은 forEach, map으로 원하는 형식의 데이터로 만들어줍니다.
//findings.service.ts
import client from "src/connection";
type findingDataType = {
[key: string]: string[];
};
async find(keyword): Promise<findingDataType[]> {
const query = keyword;
const elastic = client;
try {
const response = await elastic.search({
index: "{인덱스 이름}",
query: {
match: {
{칼럼명}: keyword,
},
},
});
const data = response.hits.hits.map((row) => {
return {
id: row._source["id"],
name: row._source["{칼럼명}"],
};
});
return data;
} catch (error) {
console.log(error);
}
}