데이터 주도 학습
입력 => 적절한 인식 => 결과
학습이란 훈련 데이터를 이용해 매개변수인 가중치의 최적값을 자동으로 구하는 것을 의미한다.
신경망이 학습할 때 손실 함수를 지표로 하는데, 손실 함수의 결과값을 가장 작게하는 가중치를 구하는 것이 학습하는 것의 목표이다!
훈련 데이터와 시험
머신러닝 문제는 데이터를 훈련 데이터(Traning Data)와 시험 데이터(Test Data)로 나눠 학습과 실험을 수행함.
훈련데이터로 학습을 하고 이를 기반으로 평가(시험 데이터)를 실행.
=> 유형, 값 등을 변경해도 결과가 잘 나와야 함!
(시험 공부를 할 때 기출문제를 많이 여러번 푸는 것과 동일함)
-
훈련 데이터만을 학습해 학습
최적의 매개변수(가중치와 편향) 찾기 -
시험 데이터를 사용해 훈련된 모델의 실력을 평가 -
훈련의 중요성
-
과소 적합(Underfitting)
오차(=실제값-예측값) -
최적합(Optimal)
오차를 최소화. -
과적합(Overfitting)
언더피팅, 오버피팅을 피하고 최적합을 찾는 것은 기계학습의 중요한 과제 중 하나임!
훈련데이터와 시험데이터 나누기
훈련의 목적: 범용적으로 사용할 수 있는 모델 확보
훈련된 데이터로 시험을 진행하면?
가지고 있는 데이터 셋에는 잘 동작, 경험해보지 않은 데이터는?
오버피팅: 한 데이터셋에만 지나치게 최적화된 상태
범용능력을 제대로 평가하기 위해 훈련 데이터와 시험 데이터를 분리 해야 함
손실 함수(Loss Function)
행복지수란?
건강, 안전, 환경, 경제, 교육 등의 지표를 고려한 수치
각 지표당 동일 가중치를 부여
AHP 분석을 통한 분야별 가중치 도출
손실함수란?
신경망에서 학습 상태를 나타내는 지표
손실 함수를 가장 작게 만들어주는 가중치 매개변수 탐색 시 사용
임의의 함수도 사용 가능하지만 일반적으로 평균 제곱 오차와 교차 엔트로피 오차 사용
평균 제곱 오차(Mean Square Error)
(신경망의 출력 값-정답) 값을 모두 더한후 반을 나눈 후 제곱한다.
def sum_square_error(y, t):
return -0.5*np.sum(y-t)**2교차엔트로피 오차(Cross Entropy Error)
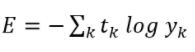
교차 엔트로피 오차의 수식에서 log는 밑이 e인 자연로그이다. t는 원-핫 인코딩으로 표현된 정답 레이블이므로, 실제로 정답일 때 (t=1), softmax 추정 값에 대한 자연로그를 계산하는 식이 된다. 예를 들어, 정답 레이블이 2이고 신경망의 softmax 출력 값이 0.6이면 교차 엔트로피 오차는 -log0.6=0.51이 되는 것이다.
같은 조건에서 신경망의 출력 값이 0.1이면 -log0.1=2.30이 된다.
결론적으로, 교차 엔트로피 오차는 정답일 때 신경망 출력값이 전체 값이 된다.
