딥러닝기초
1.[딥러닝 기초] 0311 금

파이썬 프로그래밍다음주 수요일까지 비대면파이썬 언어는 쉽지만 복잡함c언어는 명령어가 쉬움언어의특징1\. 플랫폼에 독립적(인터프리터)2\. 객체지향적3\. 대화형 언어4\. c언어에 비해 많이 느림파이썬은 오픈소스, 필요하신 모듈/라이브러리 만들기 가능.파이썬을 사용하는
2.딥러닝기초_0316_wed

다음주 수요일까지 비대면 수업, 금요일부터 대면 수업if 조건문조건에 따라 코드 실행하거나 실행하지 않게 할 때 사용하는 구문들여쓰기는 지난 조건이 충족될 때 실행되는 코드를 표현for 반복문특정 명령문들의 반복 실행문자열, 리스트, 딕셔너리 등과 조합하여 for 반복
3.딥러닝기초_0318_ Fri
인공신경망의 한 종류, 코넬 항공 연구소의 프랑크 로젠 블라트에 의해 고안간단한 형태의 피드포워드(Feedforward) 네트워크네트워크한 곳에서 다른 한 곳으로 데이터를 보내는 것.x1, x2: 입력 신호w1, w2: 가중치(weight)=> 데이터가 얼만큼 중요하냐
4.딥러닝기초_0323
이번주 금요일은 녹화강의다음주 수요일부터 대면강의 진행.개념을 확실히 알고 있어야배타적 논리합두 개의 입력이 다를 경우 1을 출력, 같을 경우 0을 출력(비교 연산)XOR 게이트를 퍼셉트론으로 구현(b, w1, w2) = (-0.5, 1.0, 1.0)하나의 퍼셉트론으로
5.딥러닝기초_0325_Fri
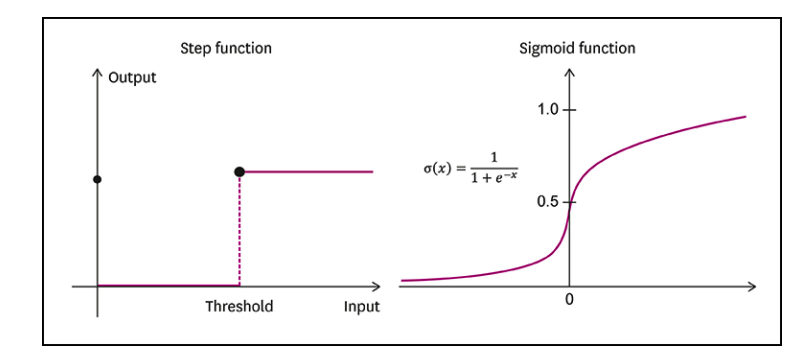
preview 활성화함수: 입력값이 들어오면 가중치를 곱한 후 다음 층으로 값을 넘김 시그모이드: 신경망에서 자주 사용되는 활성화함수이다. 계단함수와 달리 연속적인 함수임
6.딥러닝기초_0330
퍼셉트론: input-가중치를 곱해 => 값을 만들어 낸 후 편향을 더해 활성화함수를 통과시켜 어떠한 값을 출력할 지 결정.input입력값에 가중치를 곱함값에 편향 더함활성화 함수퍼셉트론이 모여서 신경망이 된다.다차원을 이용해서 하기때문에, 행렬의 곱을 잘 알아야!예를
7.딥러닝기초_0401

<과제>XOR을 이용한 전가산기, 반가산기파이썬을 실습하면서 에러가 난 경우압축 해제 에러이전에 받은 디렉토리에서 압축받은 Pythoncache 파일, pickle파일 등을 모두 삭제해야 함.pickle이란?왜냐면 불안전하게 다운로드 받은 파일에서 파이썬은 가져오
8.딥러닝기초_0406

데이터 주도 학습 입력 => 적절한 인식 => 결과 훈련 데이터와 시험 머신러닝 문제는 데이터를 훈련 데이터(Traning Data)와 시험 데이터(Test Data)로 나눠 학습과 실험을 수행함. 훈련데이터로 학습을 하고 이를 기반으로 평가(시험 데이터)를 실행.
9.딥러닝기초_0408
훈련데이터, 시험데이터공부를 할 때 잘 공부했는지 확인하기 위한 문제를 풀어봄.이때 문제를 맞히면 잘 알고있다는 것.하지만 문제의 답을 알고있다면, 문제를 당연히 맞힐 수 있음.훈련데이터의 특징을 추출한다면 답을 맞힐 확률이 올라감.따라서 시험데이터를 분리해서 시험데이
10.딥러닝기초_0413
중간고사 4월 27일 수요일 대면
11.딥러닝기초_0415

preview 예측값, 정답을 비교해 손실함수 계산 => 기울기 계산 to 손실함수가 적어지는 방향으로! 2층 신경망(input, hidden, output) 미니배치학습을 통해 TwoLayerNet 클래스를 구현, MNIST 데이터 셋을 이용한 학습의 수행. 학
12.딥러닝기초_0422
계산의 복잡도를 줄이기 위해오차역전파오른쪽 -> 왼쪽계산그래프왼쪽 => 오른쪽으로 미분 값 계산국소적 계산으로도 가능하류로 전달, 전달. ...복잡한 수식 미분은 어렵나, 덧셈/곱셈, 몇가지 함수에 대한 역전파라 난이도가 괜찮다.덧셈 노드: 그대로 전달한다.곱셈 노드:
13.딥러닝기초_0429
어떤 알고리즘을 익힐 때1\. 원리 이해2\. 간소화된 식 보기다음부터는 쉽게 이해할 수 있을 것.기말고사 없음.좀 더 원리와 알고리즘을 경험해보는 방향으로~!시그모이드 입력값, 출력값을 이용affine: 행렬softmax: 출력층의 활성화함수행렬의 곱셈에 대한 역전파
14.딥러닝 기초_0504
모델의 정확도를 높이기 위해 => 손실함수 최소화 하는 과정으로~1) mini-batch학습을 수행하는데 group으로 나누고 한 번에 행렬로 학습시켜 시간 절약훈련데이터 무작위로 가져옴수치미분, 오차역전파의 방법을 배움2) 기울기 산출그 미니배치의 손실함수 값을 줄이
15.딥러닝기초_0506
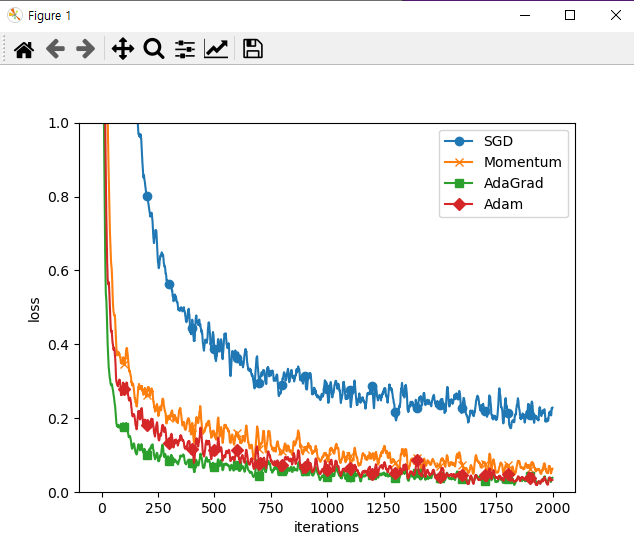
과제 => 어떠한 프로그램 보다 분석이 더 중요함프로젝트는 숙제처럼, 기말시험없이 프로젝트 발표하는 형식으로학습학습의 방법: 확률적 경사하강법 이용했음(지도를 없애고, 안대를 끼고 낮은 골짜기로 향하는 모험가를 상상하자)손실함수의 최솟값을 찾아가는 방법?모멘텀운동량을
16.딥러닝기초_0511
기말고사는 따로 없지만, 1주일정도 더 공부하고 퀴즈볼 예정(eclass)플젝그룹은 random임가중치의 초깃값 중요예를 들어 산 등산에 있어, 맨 밑바닥부터 or 중간부터 시작하느냐는 큰 차이임. 가급적이면 높은 곳에서 시작하면 좋음.초깃값 어떻게 설정 하느냐에 따라
17.딥러닝기초_0513
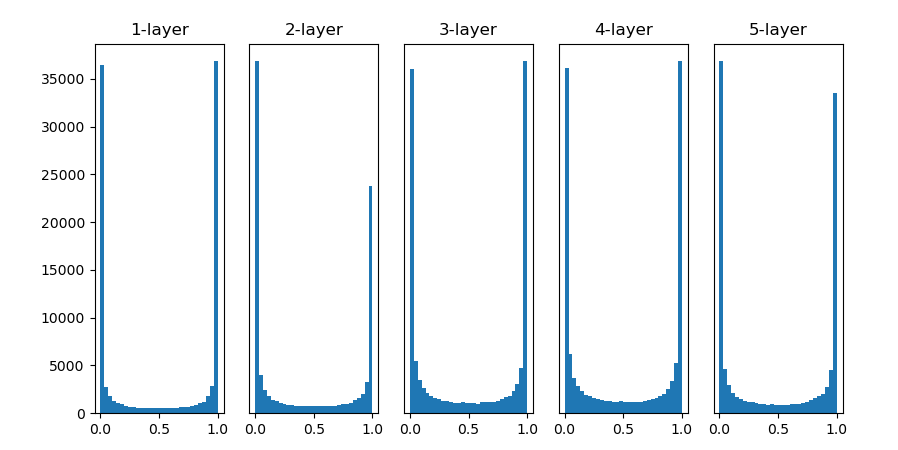
올바른 학습가중치 매개변수의 초깃값 설정히스토그램학습 과정 => 하이퍼파라미터 어떻게 잡음? => 학습 효과 달라짐골고루 분포 => 표준편차 어떻게?Xavier 초깃값(시그모이드 함수)He 초기값(ReLU)A+ => 4.5만점A+ => 4.3만점일수도절댓값으로 비교
18.딥기초_0518
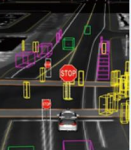
이미지처리에 가장 많이 사용하는 머신 러닝 기법인 합성곱 신경망합성곱=컴퓨터 비전 영역에서 많이 사용시각은 인간의 가장 강력한 인지 기능임다른 감각을 모두 합쳐도 시각이 가장 중요함그만큼 복잡한 내부 작용이 있음자율주행차는 신호, 차선, 도로의 모양 등을 인지한 후 주
19.딥기초_0520
Mnist 데이터 셋 사용어디에 목적을 둘 것인지?최고의 학습률(정확도)여러가지 요소 중 최소 노드 사용(mininum 있음)14주차: 프로젝트 진행15주차: 진행한 결과(상황보고 더 늘릴 수 있음) 발표 예정Affine, Relu에서 합성곱으로 바뀜합성-풀링 사이 활
20.딥러닝기초_0525
노드수, 정확도를 개의치 않게 실습을 진행함\-> 이제는 최적화까지 고려해보자물건을 선택하는 기준 => 가격도 낮으면서 성능이 좋은걸 선택가성비를 따진다.금요일 => CNN자체 데이터셋을 만들어도 괜찮음교수님께서 준비하신 테스트셋에는 엉망으로 한 글씨까지 포함할 예정임
21.딥러닝기초_0527
각 층에 대한 필터링을 통해 특징 추출딥러닝과 머신러닝의 차이는 특징 추출 조차도 자동으로 함인간의 개입 없이의 의미가 알아서 한다가 아닌, 특징을 기계가 찾아낸다는 것!최소의 비용으로 최대의 성능을 보이자노드수가 많아질 수록 (=파라미터 수가 많아질수록) 메모리 접근
22.딥러닝기초_0603
학습에 걸리는 시간 => 평가요소로 고려 x추론에 걸리는 컴퓨팅 자원은 제외메모리 자원(딥러닝이 얼마나 메모리 공간 차지?) 데스크탑이 아닌, 작은 임베디드 시스템에서도 작동해야모델 경량화메모리와 관련있는 요소 : 가중치 매개변수(노드 수), 편향입력의 크기, 필터의