안녕하세요!
오늘은 LLMs을 공부하면 빠질 수 없는 'Fine-Tuning'에 대해서 작성할 겁니다.
https://www.turing.com/resources/finetuning-large-language-models - 링크
위 내용을 중점적으로 다루고, 추가할 내용이 있으면 추가하는 식으로 작성하겠습니다.
Intro
- LLMs은 advanced capabilities and highly sophisticated solution을 통해 자연어 처리 분야를 크게 발전시켰습니다.
- LLMs은 방대한 덱스트 데이터셋을 통해 넓은 범위의 tasks를 학습합니다. (Ex. text generation, translation, summarization, and question answering)
- 하지만, 여전히 특정 tasks나 domain에 맞지 않는 경우가 있습니다.
- Fine-tuning은 pre-trained된 LLMs을 더 specialized된 task에 적응시킵니다.
- Fine-tuning을 통해 모델은 작은 데이터셋을 사용하여 task-specific data에서 일반적인 언어 지식을 유지면서 성능을 향상시킵니다.
- 예시로 구글은 pre-trained된 LLM을 sentiment analysis(감정분석)에 맞게 fine-tuning하니, 정확도가 10% 향상되었습니다.
- 이 블로그에서는 LLMs의 fine-tuning이 어떻게 모델 성능을 향상시키고, 훈련 비용을 절감하며, 더 정확하고 맥락에 맞는 결과를 가능하게 하는 방법에 대해서 알아볼 것입니다.
- 또한, 다양한 fine-tuning 방법과 사례를 보며, fine-tuning이 왜 LLM-powered solution(LLM 기반 솔루션)에서 주요하게 되었는지 알아볼 것입니다
1. What is fine-tuning, and why do you need it?
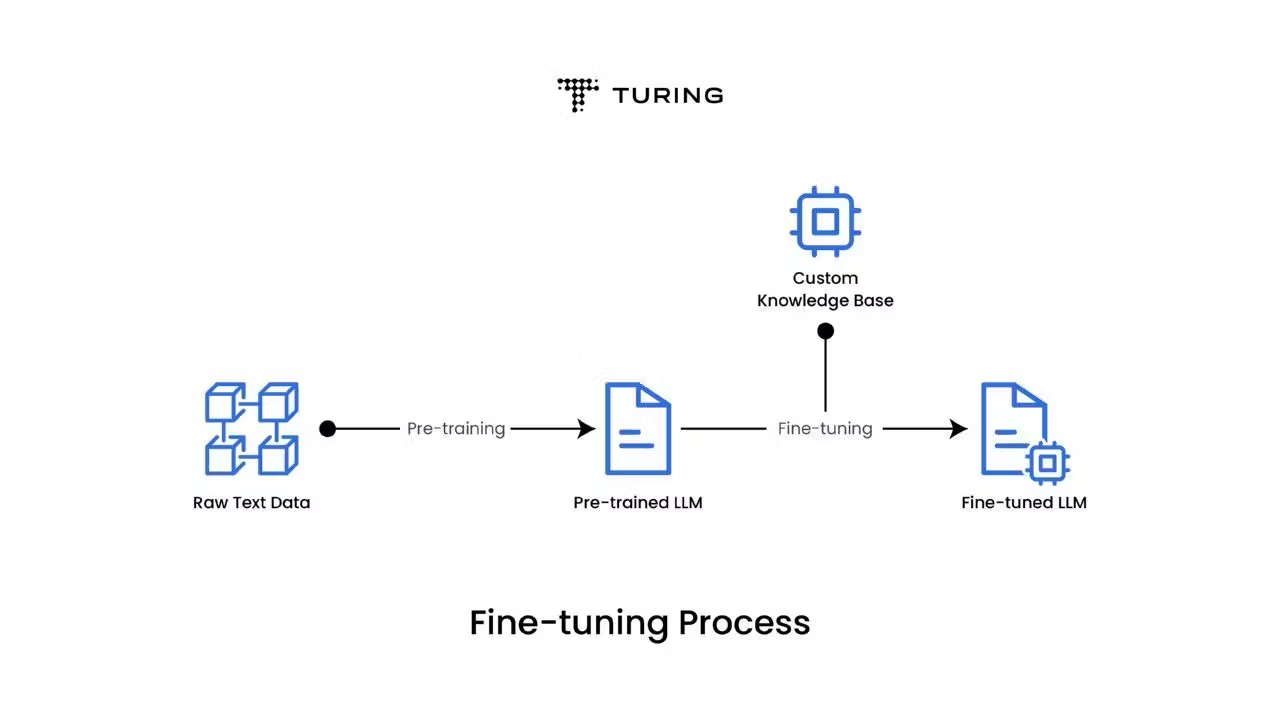
- Fine-tuning은 pre-trained된 LLM의 parameters를 특정 작업이나 도메인에 맞게 조정하는 과정입니다.
- GPT와 pre-trained된 LM은 방대한 언어 지식을 가지고 있지만, 특정 영역에 대한 전문성이 부족합니다.
- 따라서 fine-tuning은 특정 영역을 모델이 학습하여, 한계를 극복하고, 특정 분야에서 더 정확하고 효과적으로 만들 수 있습니다.
즉, Fine-tuning은 간단히 말해서, 기본적인 언어 능력을 갖춘 모델을 더 세부적인 역할을 잘 수행하도록 "미세하게 조정"하는 것입니다. 이를 통해 파인튜닝은 이미 강력한 언어 모델을 더 전문적이고 특화된 역할을 수행할 수 있게 만들어줌으로, 모델이 특정 요구에 더 잘 대응할 수 있게 됩니다.
- Fine-tuning 과정에서 모델을 task-specific example에 노출 시킴으로, 해당 영역에 대한 지식의 '미세한 뉘앙스'를 더 깊이 이해할 수 있습니다.
- 이는 general-purpose language와 specialized language model간 격차를 메웁니다.
- 또한, 특정 도메인이나 분야에서 LLM의 잠재력을 최대한 발휘할 수 있음.
- Fine-tuning을 하는 경우 :
1-a. Customizaiton
- 모든 도메인이나 작업에는 고유한 언어 패턴, 용어, 그리고 문맥적인 뉘앙스가 존재합니다.
- 따라서 pre-trained된 LLM을 fine-tuning하면 이러한 내용을 더 잘 이해하고, 해당 도메인에 특화된 콘텐츠를 생성할 수 있습니다.
- 이를 통해 모델의 특정 요구사항에 맞게, 정확하고 문맥에 맞는 출력을 생성합니다.
- 법률, 의료, 비지니스, 회사 등 어느 분야든, LLM은 전문화된 데이터셋으로 훈련할 때 해당 도메인의 accuracy한 지식을 제공합니다.
- Fine-tuning을 통해 cuntomization이 이루어지면, 특정 도메인의 지식의 정확성을 유지하면서 LLM의 강력한 기능을 활용할 수 있습니다.
1-b. Data compliance
- 법률, 의료, 금융 등 많은 분야에서 민감한 정보의 사용과 처리에 대해 엄격한 규제가 있습니다.
- Organization은 LLM을 '독점 데이터'나 '규제된 데이터'로 fine-tuning하여 모델이 data compliance을 유지할 수 있도록 합니다.
- 이 과정은 특정 데이터로 pre-trained된 LLM을 개발하여 민감한 정보를 외부 모델에 노출시키는 위험을 줄이고, 데이터의 보안과 프라이버시를 강화할 수 있습니다.
1-c. Limited labeled data (주석처리된 데이터)
- 많은 상황에서 특정 도메인에 대한 '레이블된 데이터'를 얻는 것은 어렵고 비용이 많이 듭니다.
- 하지만 Fine-tuning은 pre-trained된 LLM을 기존의 '레이블된 데이터'에 맞추어 조정하기 때문에, 사용 가능한 라벨 데이터의 성능을 최대화할 수 있습니다.
- 따라서 모델을 학습시킬 때 'limited labels data'라는 문제가 있지만, fine-tuning을 통해 이러한 문제를 해결할 수 있습니다.
- 그렇기 때문에, 여전히 도메인에 대한 모델의 정확성과 관련성을 크게 향상시킬 수 있습니다.
2. Primary fine-tuning approaches
- Fine-tuning은 LLM의 파라미터를 조정하는 과정이며, 범위는 수행하는 작업에 따라 다릅니다.
- 두 가지 대표적인 fine-tuning approaches : Feature extraction, Full fine-tuning
파라미터를 조정한다는 것은 모델의 가중치(weight)와 바이어스(bias)와 같은 내부 매개변수들을 변경하여 모델의 성능을 최적화하는 과정
2-a. Feature extraction (or repurposing)
- LLM을 fine-tuning하는 주요 접근법 중 하나입니다.
- Pre-trained된 LLM을 고정된 특징 추출기로 간주합니다.
- 따라서 pre-trained된 모델은 이미 방대한 데이터셋으로 특정 작업에 대사용할 수 있는 중요한 언어 특징을 학습했습니다.
고정된 특징 추출기(Fixed Feature Extractor)
사전 훈련된 모델의 대부분을 그대로 두고, 마지막 레이어만 새로운 작업에 맞게 조정하는 방법
- 모델의 최종 레이어만 작업별 데이터로 학습되며, 나머지 모델은 고정된 상태로 유지됩니다.
- 이 방식은 LLM이 trained한 풍부한 표현을 활용하여 특정 작업에 적응시키는 방법을 제공합니다.
2-b. Full fine-tuning
- LLM을 fine-tuning하는 또 다른 주요 접근법 중 하나입니다.
- Feature extraction과는 달리 full fine-tuning에서는 모델의 최종 레이어뿐만 아니라, 모든 레이어가 조정됩니다.
- 이 방식은 작업별 테이터셋이 크고 사전 pre-trained된 데이터와 크게 다를 때 유용합니다.
- 전체 모델이 작업별 데이터로부터 학습할 수 있게 합니다.
- 이로인해, 모델이 특정 작업에 깊이 적응하여, 잠재적으로 더 우수한 성능을 발휘할 수 있습니다.
- Full fine-tuning은 feature extraction에 비해 더 많은 계산, 자원, 시간이 필요합니다.
3. Prominent fine-tuning methods
- 모델 파라미터를 특정 요구사항에 맞추기 위해 여러가지 fine-tuning 방법과 기술이 있습니다.
- Supervised fine-tuning과 Reinforcement learning from human feedback(RLHF)로 분류 할 수 있습니다.
3-a. Supervised fine-tuning
- 이 방법에서는 각 input data point가 라벨과 연결된 작업별 라벨 데이터셋을 사용하여 모델을 훈련시킵니다.
- 모델은 이러한 라벨을 정확하게 예측하도록 파라미터를 조정하는 법을 학습합니다.
- 또한 대규모 데이터셋을 통해 pre-trained에서 얻은 기존 지식을 현재 작업에 적용하도록 안내합니다.
- Supervised fine-tuning은 특정 작업에서 모델의 성능을 크게 향상시킬 수 있으며, LLM을 cuntomizing하는 교효과적인 방법입니다.
input data point - 다양한 출처로부터 수집된 데이터를 의미
- 가장 일반적인 supervised fine-tuning 기법
1. Basic hyperparameter tuning
- Basic hyperparameter tuning은 학습률, 배치 크기, 에포크 수와 같은 모델 hyperparameter를 '수동으로 조정'하여 원하는 성능을 달성하는 간단한 접근 방식입니다.
- 목표는 학습 속도와 과적합 위험 간의 균형을 맞추면서 모델이 데이터에서 가장 효과적으로 학습할 수 있는 hyperparameter를 찾는 것입니다.
- 최적의 hyperparameter는 특정 작업에서 모델의 성능을 크게 향상시킬 수 있습니다.
hyperparameter는 머신러닝 모델의 학습 과정에서 사람이 설정하는 값. 이 값들은 모델의 학습 방식과 성능에 큰 영향을 미침. hyperparameter는 모델이 학습을 시작하기 전에 설정되며, 학습 도중에는 변경되지 않음.
2. Transfer learning
- Transfer learning은 제한된 데이터로 작업할 때 유용한 기법입니다.
- 이 접근 방식에서는 대규모 일반 데이터셋으로 pre-trained된 모델을 시작점으로 사용합니다.
- 이후 다음 모델을 작업별 데이터로 fine-tuning하여 기존 지식을 새로운 작업에 적응시킵니다.
- 이 과정은 필요한 데이터와 학습 시간을 크게 줄여주며, 처음부터 모델을 학습시키는 것보다 우수한 성능을 자주 보여줍니다.
3. Multi-task learing
- Multi-task learing은 모델을 여러 관련 작업에 동시에 fine-tuning합니다.
- 이 방식은 작업들 간 공통점과 차이점을 활용하여 모델의 성능을 향상시킵니다.
- 모델이 여러 작업을 동시에 수행하도록 학습하여, 데이터에 대한 더 강력하고 일반화된 이해를 develop할 수 있습니다.
- 이 방식은 수행할 작업들의 관계들이 밀접하거나 개별 작업에 대한 데이터가 제한되어 있을 때 설능을 향상시킵니다.
- Multi-task learing은 각 작업에 대한 라벨 데이터셋이 필요하므로 supervised fine-tuning의 inherent component(본질적인 요소)입니다.
4. Few-shot learning
- Few-shot learning은 적은 양의 작업별 데이터로 새로운 작업에 적응할 수 있게 합니다.
- 이는 pre-trained된 모델이 습득한 방대한 지식을 활용하여, 새로운 작업의 몇 가지 예제만으로 효과적인 학습을 합니다.
- 또한 작업별 라벨 데이터가 부족하거나 비용이 많이들 때 유용합니다.
- 이 기술에서는 모델이 새로운 작업을 학습하기 위해 추론 시간 동안 몇 가지 예제 또는 "shot"을 받습니다.
- Few-shot의 아이디어는 프롬프트에서 컨텍스트와 예제를 제공하여 모델의 예측을 안내하는 것입니다.
- Few-shot은 작업별 소량의 데이터에 human-feedback이 포함된 경우, reinforcement learning from human feedback(RLHF) 접근 방식에 통합될 수도 있습니다.
5. Task-specific fine-tuning
- Task-specific fine-tuning은 특정 작업의 뉘앙스와 요구사항에 맞게 파라미터를 조정하여 해당 작업에 대한 성능과 관련성을 높입니다.
- 작업별 fine-tuning은 단일, 잘 정의된 작업에서 모델의 성능을 최적화하고, 작업별 콘텐츠를 정확하고 정밀하게 생성하도록 보장하는데 가치가 있습니다.
- Task-specific fine-tuning은 Transfer learning과 밀접하게 관련되어 있지만, Transfer learning은 모델이 학습한 일반적인 특징을 활용하는 반면, Task-specific fine-tuning은 새로운 작업의 구체적인 요구사항에 맞게 모델을 적응시키는 것입니다.
3-b. Reinforcement learning from human feedback (RLHF)
- RLHF은 인간 피드백을 통해 언어 모델을 훈련하는 혁신적인 접근법입니다.
- human feedback을 포함시킴으로, 모델이 더 정확하고 문맥에 적합한 응답을 생성하도록 지속적으로 향상시킵니다.
- 이 접근법은 human feedback에서 전문 지식을 활용할 뿐만 아니라, 모델이 피드백 기반으로 적응 및 진화할 수 있게 합니다.
- 궁극적으로 더 효과적이고 정교한 모델이 될 수 있게합니다.
- 가장 일반적인 RLHF 기법
1. Reward modeling
- Reward Modeling에서는 모델이 여러 결과를 제시 하면, Human feedback을 통해 결과에 순위를 매기거나 평가합니다. (순위 매김 -> 점수 매김)
- 모델은 feedback을 통해 reward를 예측하는 법을 배우고, 예측된 보상을 최대화되도록 행동을 조정합니다.
- Reward Modeling은 Human feedback을 학습 과정에 포함시키는 방법을 통해, 함수로 정의하기 어려운 작업을 모델이 학습할 수 있게 합니다.
- 이 방법은 모델이 human feedback을 통한 reward를 기반으로 학습하고 적응하여 궁극적으로 모델의 기능을 향상시킵니다.
2. Proximal policy optimization (근접 정책 최적화 - PPO)
- PPO는 language model의 policy를 업데이트하여 expected reward를 최대화하는 "interative algorithm(반복 알고리즘)"입니다.
- PPO의 핵심 아이디어는 이전 policy에서 너무 급격하게 변하지 않으면서 정책을 개선하는 행동을 하는 것입니다.
- 이러한 점을 통해 유익한 작은 업데이트는 허용하지만, 유해한 큰 업데이트를 방지하는 policy 업데이트에 대한 제약을 도입함으로 달성합니다.
정책(Policy)은 강화 학습에서 특정 주체가 특정 상황(상태)에서 어떤 행동을 취할지 결정하는 규칙이나 전략이다. 정책은 주체가 환경에서 최적의 행동을 선택하도록 안내한다.
- 이 제약은 clipped probability ratio를 가진 대리 목표 함수(surrogate objective function)을 도입하여 강제됩니다.
- 이는 다른 reinforcement learning에 비해 알고리즘을 더 안정적이고 효율적으로 만듭니다.
정책 업데이트 제한: PPO는 정책이 너무 급격하게 변하지 않도록 제한을 둡니다.
클립된 확률 비율: 기존 정책과 새로운 정책 간의 확률 비율을 일정 범위 내로 클립하여 큰 변화를 방지합니다.
대리 목표 함수: 클립된 확률 비율을 사용하는 대리 목표 함수를 최적화하여, 정책이 안정적으로 개선되도록 합니다.
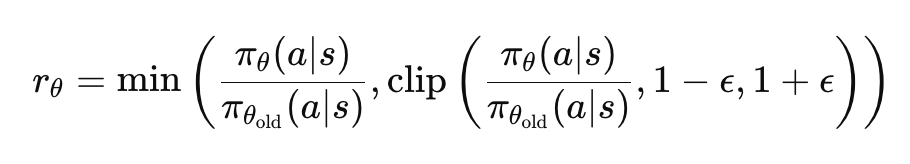
3. Comparative ranking
- Comparative ranking은 Reward modeling과 유사하지만, Comparative에서는 모델이 여러 result의 상대적인 순위를 학습합니다.
Comparative ranking vs Reward modeling
보상 모델링(Reward Modeling):
피드백: 개별 출력에 대한 절대적인 평가 점수.
학습 방식: 절대적인 점수를 최대화하는 방향으로 학습.
비교 순위 매기기(Comparative Ranking):
피드백: 여러 출력의 상대적인 순위.
학습 방식: 상대적인 순위를 최대화하는 방향으로 학습.
- Comparative에서는 모델이 여러 출력을 생성하면, human feedback을 통해 result를 평가 후 순위를 매깁니다.
- 모델은 더 높은 순위를 매긴 result를 출력하도록 행동을 조정합니다.
- Reward와는 달리 result을 개별적으로 평가하는 대신, 여러 result을 비교하고 순위를 매기는 방식으로, comparative model에 더 미세하고 상대적인 피드백을 제공합니다.
4. Preference learning (reinforcement learning with preference feedback, 강화 학습과 선호 피드백)
- Preference learning은 states, actions, 또는 trajectories 중에서 human preference을 학습하는 것에 중점을 둡니다.
- 이 접근법에서는 모델이 여러 출력을 생성하고, human feedback에서 pairs of outputs 중에서 preference를 표시합니다.
- 따라서 모델은 preference를 조정하는 법을 학습합니다.
- 이 방법은 result를 수치로 평가하기 어려울 때 유용하며, 두 result간의 preference를 표현할 때 더 효과적입니다.
- Preference learning은 인간의 세밀한 판단을 기반으로 복잡한 작업을 학습할 수 있게 합니다.
- 또한 모델을 실제 응용 프로그램에 맞게 미세 조정하는 데 효과적인 기술입니다.
5. Parameter efficient fine-tuning
- Parameter efficient fine-tuning(PEFT)는 pre-trained된 LLM의 성능을 특정 downstream tasks에서 향상 시키면서 동시에 파라미터 수를 최소화하는 기법입니다.
- 이는 fine-tuning 과정에서 모델 파라미터의 일부만 업데이트함으로, 더 효율적인 방식을 제공합니다.
다운스트림 작업(Downstream Task)은 사전 훈련된 모델을 활용하여 수행하는 특정 작업을 의미합니다. 사전 훈련된 모델이 언어의 일반적인 구조와 패턴을 학습한 후, 이러한 지식을 바탕으로 특정 응용 분야나 작업에 맞춰 미세 조정하는 것입니다.
- PEFT는 LLM의 파라미터 중 소수만 선택적으로 수정하며, 일반으로 새로운 레이어를 추가하거나 기존 레이어를 작업별로 수정하는 방식을 사용합니다.
- 이러한 접근법은 computational(계산) 및 storage requirements을 크게 줄이면서도 full fine-tuning과 비교할 만한 preformance를 유지할 수 있습니다.
4. Fine-tuning process and best practices
- Pre-trained된 모델을 specific case나 application requires에 맞게 fine-tuning하려면 최적의 결과를 보장하기 위한 well-defined process이 필요합니다.
- 아래는 best practices입니다.
4-a. Data preparation
- Data preparation은 specific task에 대한 dataset의 관련성과 품질을 보장하기 위해 데이터를 curating하고 preprocessing하는 과정을 포함합니다.
- 여기에는 데이터 정리, 누락 값 처리, 모델의 입력 요구사항에 맞게 텍스트 형식을 조정하는 작업 등이 포함됩니다.
Curating과 preprocessing이란?
큐레이팅은 데이터 준비의 첫 단계로, 목적에 맞는 데이터를 선택하고 정리하는 과정입니다. 전처리는 큐레이팅 후, 선택된 데이터를 모델이 이해하고 처리할 수 있는 형식으로 변환하는 과정입니다. 이 두 단계는 모두 데이터의 품질과 모델의 성능을 높이는 데 필수적입니다.
- 추가로, data augmentation techniques을 활용하여 training dataset을 확장하고 모델의 robustness(강건성)을 향상시킬 수 있습니다.
- 적절한 데이터 준비는 fine-tuning에 필수적이며, 이는 모델의 학습 및 일반화 능력에 직적접인 영향을 미쳐, 궁극적으로 작업별 출력의 성능과 정확성을 향상시키는 데 기여합니다.
4-b. Choosing the right pre-trained model
- targer task나 domain의 specific requirement에 맞는 pre-trained된 모델을 선택하는 것은 매우 중요합니다.
- pre-trained된 모델의 아키텍처, 입/출력 사양, 레이어에 대한 이해는 fine-tuning workflow에 원활하게 통합하는데 필수적입니다.
workflow란?
어떤 일을 효율적으로 처리하기 위해 따라야 하는 순서와 절차
- 모델 크기, 훈련 데이터, 관련 작업에 대한 성능과 같은 요소를 고려 후 선택해야 합니다.
- 목표하는 것과 밀접하게 일치하는 pre-trained된 모델을 선택함으로 fine-tuning 과정을 간소화하고 모델의 적응력과 효과를 극대화할 수 있습니다.
4-c. Identifying the right parameters for fine-tuning
- Fine-tuning 과정에서 최적의 성능을 달성하기 위해 fine-tuning parameters를 잘 구성해야합니다.
- 학습률, 학습 에포크 수, 배치 크기 등의 파라미터는 모델이 새로운 작업별 데이터에 어떻게 적응하는지를 결정하는 데 중요한 역할을 합니다.
- 또한, 최종 레이어를 훈련시키는 동안 특정 레이어(일반적으로 초기 레이어)를 선택적으로 고정시키는 것은 과적합을 방지하기 위한 일반적인 방법입니다.
- 초기 레이어를 고정함으로 모델은 pre-trained 동안 얻은 지식을 유지하며, 최종 레이어는 새로운 작업에 맞게 특화됩니다.
- 이 접근법은 모델이 일반화하는 능력을 유지하면서, 작업별 특징을 효과적으로 학습할 수 있도록 하여, 기존 지식을 활용하는 것과 새로운 작업에 적응하는 것 사이의 균형을 맞추는 데 도움을 줍니다.
4-d. Validation
- Validation은 fine-tuned된 모델의 성능을 validation set에 평가하는 과정입니다.
- 정확도, 손실, 정밀도, 재현율과 같은 지표를 모니터링하면 모델의 효과성과 일반화 능력을 파악할 수 있습니다.
- 이러한 지표를 평가함으로, fine-tuned된 모델이 작업별 데이터에서 얼마나 잘 작동하는지 판단하고, 개선이 필요한 부분을 식별할 수 있습니다.
- Validation 부분은 fine-tuning 파라미터와 모델 아키텍처를 개선하여, 최종적으로 의도된 응용 프로그램에 대해 정확한 출력을 생성하는 최적의 모델을 만드는 데 기여합니다.
4-e. Model iteration (반복)
-
Model iteration은 평가 결과를 바탕으로 모델을 개선하는 과정을 의미합니다.
-
모델의 성능을 평하한 후, 학습률, 배치 크기, 레이어 고정 정도 등의 fine-tuning 파라미터를 조정하여 모델의 효과성을 향상시킬 수 있습니다.
-
또한 regularization을 사용하거나 모델 아키텍처를 조정하는 등 다양한 전략을 탐색하여 모델 성능을 점진적으로 개설시킬 수 있습니다.
-
이를 통해 엔지니어들은 모델의 성능을 목표 수전에 도달할 때까지 반복적으로 개선하고 최적화할 수 있습니다.
4-f. Model deployment (배포)
-
Model deployment는 개발 단계에서 실질적인 응용 단계로의 전환을 의미하며, fine-tuning된 모델을 특정 환경에 통합하는 과정을 포함합니다.
-
이 과정에서 배포 환경의 하드웨어 및 소프트웨어 요구사항과 모델을 기존 시스템이나 응용 프로그램에 통합하는 작업이 포함됩니다.
-
또한, 확장성, 실시간 성능, 보안 조치와 같은 측면을 고려하여 원활하고 신뢰할 수 있는 배포를 보장해야 합니다.
-
Fine-tuning된 모델을 성공적으로 특정 환경에 배포함으로, 향상된 기능을 활용하여 실제 문제를 해결할 수 있습니다.
5. Fine-tuning applications (응용)
- Pre-trained된 model을 fine-tuning하는 것은 특정 작업을 위해 large-scale models의 강력한 성능을 활용하는 효율적인 방법입니다.
- 모델을 처음부터 훈련할 필요 없이, fine-tuning을 통해 LLM의 성능을 최적화할 수 있습니다.
5-a. Sentiment analysis (감정 분석)
- 회사의 특정 데이터, 고유한 도메인 또는 고유한 작업에 모델을 fine-tuning하면 텍스트 콘텐츠에 표현된 감정을 정확하게 분석하고 이해할 수 있습니다.
- 이를 통해 기업은 고객 피드백, 소셜 미디어 게시물 및 제품 리뷰에서 귀중한 인사이트를 얻을 수 있습니다.
- 이러한 인사이트는 의사 결정 과정, 마케팅 전략, 제품 개발에 활용할 수 있습니다.
- Sentiment analysis은 트렌드 식별, 고객 만족도 평가, 개선이 필요한 영역 파악에 도움이 됩니다.
- 소셜 미디어에서는 대중의 감정을 추적하여 평한 관리와 고객 소통을 향상시킬 수 있습니다.
5-b. Chatbots
- Fine-tuning된 chatbots은 맥락에 맞는 관련성 높은 대화를 생성하여 고객 상호작용을 개선하고, 다양한 산업에서 개인 맞춤형 지원을 제공합니다.
- 의료 분야에서는 상세한 질문에 답변하고 환자 케어를 향상시키며, 전자 상거래에서는 지품 문의 응답, 아이템 추천, 거래 지원을 수행하는 등 다양한 분야에서 사용할 수 있습니다.
5-c. Summarization
- Fine-tuning된 모델은 긴 문서, 기사, 대화를 간결하고 유익하게 요약하여 효율적인 정보 검색과 지식 관리를 촉진합니다.
- 이는 대량의 데이터를 분석해 주요 인사이트를 추출해야 하는 전문가들에게 유용합니다.
- 학문 및 연구 분야에서는 연구 논문을 요약해 주요 발견을 빠르게 파악하고, 기업 환경에서는 긴 보고서를 요약해주는 등 실질적인 생활에 도움을 줍니다.
Fine-tuning된 language model은 정보 접근성과 이해를 향상시켜 다양한 도메인에서 귀중한 도구가 됩니다.
6. Wrapping up
LLM(대형 언어 모델)의 파인튜닝은 기업이 사전 훈련된 모델을 비즈니스 데이터셋에 맞추어 활용하려는 접근법으로 점점 더 많이 사용되고 있습니다. 파인튜닝은 모델 성능을 향상시킬 뿐만 아니라 비용 효율적인 솔루션을 제공합니다. 그러나 효과적인 구현을 위해서는 모델 아키텍처, 벤치마크 성능, 적응성에 대한 깊은 이해가 필요합니다.
