안녕하세요!
앞서 LLM에 대한 3가지 단계를 영어로 작성했는데, 한국어로도 작성을 해야할 것 같아서, 작성합니다.
https://snorkel.ai/large-language-model-training-three-phases-shape-llm-training/ - 링크
Intro
LLM을 훈련시키는 방식은 하나만 있는 것이 아니라 여러개가 있습니다. 각 단계는 LLM 훈련 과정에서 굉장히 중요한 요소들입니다.
아래는 대표적인 3가지 훈련 단계입니다.
- self-supervised learning
- supervised learning
- reinforcement learning
Phase 1: self-supervised learning for language understanding
Self-supervised learning은 LLM 훈련에서 첫 번째 단계입니다.
이 단계에서는 unannotated(주석이 없는) 정보를 제공합니다. 주석이 없는 정보를 제공한다는 것은 데이터에 대한 설명 없이 모델에게 방대한 양의 데이터를 스스로 학습을 시키는 겁니다.
Unannotated를 사용하는 이유는?
1. 주석 없는 데이터는 대량으로 쉽게 확보 가능 (웹사이트, 오픈 소스 등)
2. 시간과 비용이 많이 드는 주석 데이터와 달리 시간과 비용 절약 가능
3. 주석 데이터와 달리 특정 도메인에 한정된다는 단점이 없음
물론 주석이 없는 데이터를 사용하면, 언어 모델은 초기에는 엉뚱한 답을 내놓습니다. 하지만, 스스로 학습을 통해 점차 정답에 근사한 답을 내놓습니다. 여기서 스스로 학습하는 방법은 많지만, 아래 대표적인 학습 방식 1가지를 소개해 드리겠습니다.
1. MASK - 기존 데이터에서 형태의 일부를 MASK(제거)해서, 이후 모델이 MASK한 부분을 예측하면, 해당 예측 값과 실제 값을 비교
2. Loss Function - 예측 값과 실제 값의 차이를 계산 후 Loss cost(손실 값)을 계산
3. Backpropagation - Loss cost를 기반으로, 역전파 알고리즘을 통해 모델의 가중치를 업데이트 후, 모델이 점진적으로 정확한 예측을 할 수 있도록 도와줌
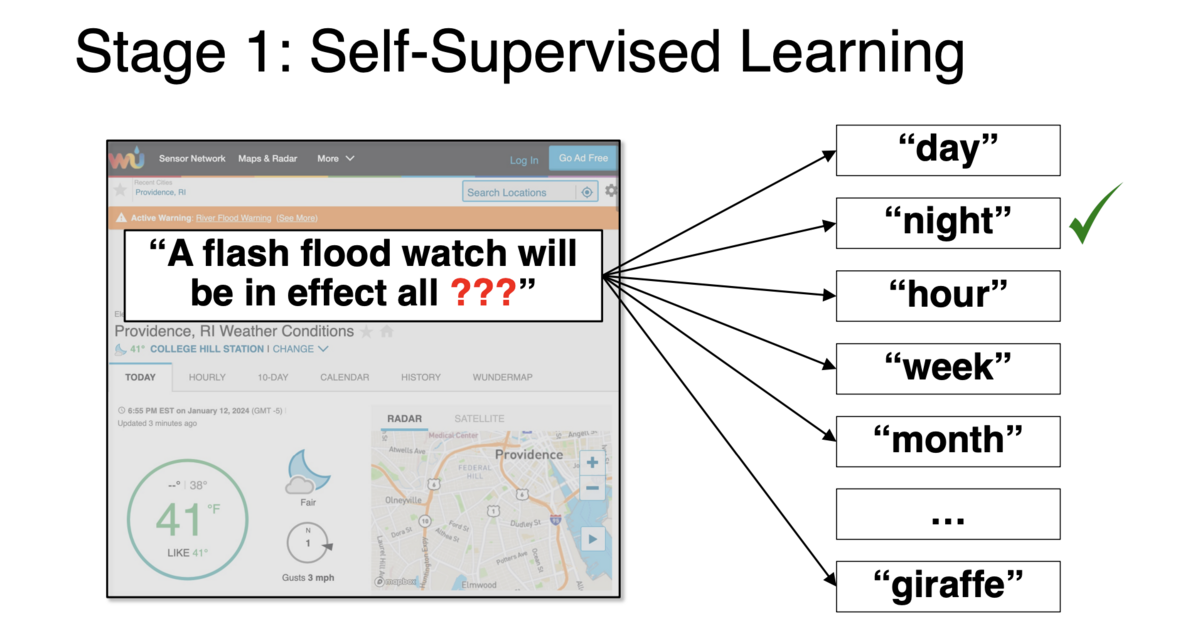
아래는 실제 글에 있던 예시입니다.
"A flash flood watch will be in effect all____."
이 문장에서 빈칸에 들어갈 단어를 맞추기 워해서, 모델은 언어와 날씨에 관련된 도메인을 통해 다음 단어를 예측해야 합니다.
아래 사진과 같이, 모델은 그럴듯한 단어부터 말도 안되는 단어까지 다양한 단어를 예측하고, 랭킹을 매깁니다.
1단계 사용 법 예시
주로 BERT(Bidirectional Encoder Representations from Transformers)와 같은 모델이 사용됩니다.
(BERT는 트랜스포머의 인코더 부분을 사용하여 양방향(contextual) 학습을 수행합니다. 이를 위해 마스킹된 언어 모델링(Masked Language Modeling, MLM)과 같은 기술을 사용)
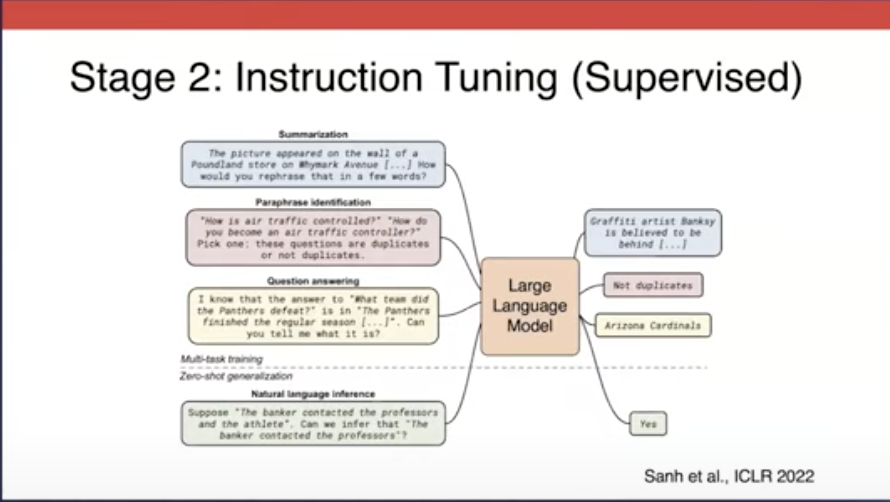
Phase 2 : Supervised learning for instruction understanding
Supervised learning은 instruction tuning으로도 불리우고, LLM 훈련에서 두 번째 단계입니다.
첫 번째 단계였던 self-supervised learning에서 습득한 지식을 기반으로 모델을 생성합니다.
즉, 모델은 문장과 단어를 예측하는 것을 넘어서, 특정 요청에 응답하는 법을 배웁니다. 특히, 주요 결과 중 하나는 모델이 새롭거나 처음본 작업에 대한 일반적인 성능이 향상이 되었습니다. 이는, 머신 러닝의 중요한 목표중 하나인 "새로운 데이터에 대한 성능 향상"에 있어 주요한 성과입니다.
왜 처음보는 데이터에 대한 성능이 향상되었을까?
- 1단계에서는 단순히 단어와 문장 예측과 언어의 일반적인 구조와 패턴을 학습
- 반면 2단계에서는 1단계 기반으로 번역, 질문, 요약 등의 구체적인 작업뿐만 아니라 다양한 지시를 학습하기 때문에, 처음 보는 데이터에 대한 성능이 크게 향상됨
- 이는 모델이 다양한 작업과 지시에 대해 구체적으로 훈련됨으로써 새로운 상황에서도 효과적으로 일반화할 수 있게 해줌
따라서, Supervised Learning은 LLM 훈련의 standard가 되었습니다. 2단계가 완료되면, 모델은 이제 단순히 다음 단어와 문장을 예측하는 것은 물론이고, 사용자의 요청을 이해하며, 알맞음 응답을 제공합니다.
2단계 사용 법 예시
주로 GPT(Generative Pre-trained Transformer)와 같은 모델이 사용됩니다.
(GPT는 트랜스포머의 디코더 부분을 사용하여 단방향 언어 생성 학습을 수행합니다. 이를 위해 지시 조정(Instruct Tuning)과 같은 기술을 사용합니다)
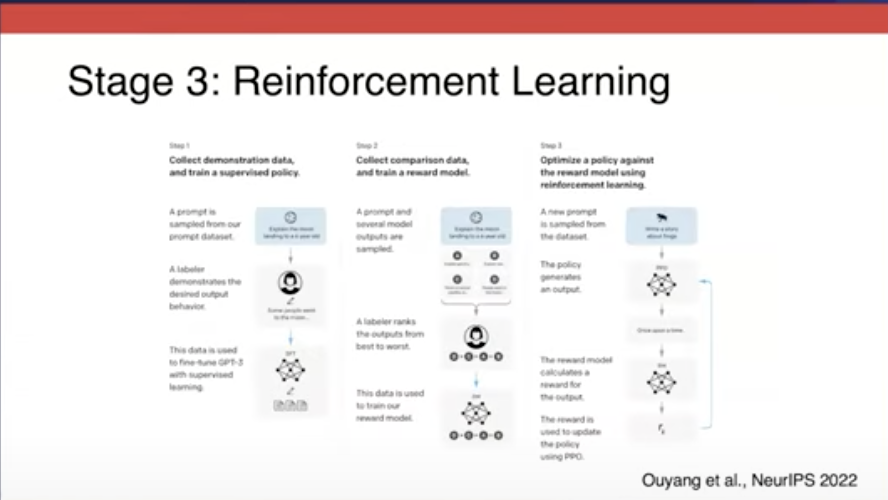
Phase 3 : reinforcement learning to encourage desired behavior
Reinforcement learning은 말 그대로 훈련을 강화하는 겁니다. 원하는 출력을 나오도록 유도하고, 원하지 않은 출력은 억제시킵니다.
또한 3단계에서는 모델의 정확한 출력을 제공하지 않고, 모델이 생성한 출력을 평가합니다.
따라서 3단계부터는 더 나은 답안과 덜 나은 답안을 구분하기 위해 Data Scientists들이 human annotations을 사용했습니다.
Human annotations란?
사람이 직접 데이터를 검토하고, 이에 대한 평가나 레이블을 다는 과정
2단계까지 학습된 모델은 이미 스스로 답을 내놓은 수 있습니다. 다만, 이 내놓은 답은 모델이 봤을 때는 비슷해 보여도, 인간이 보기에는 다를 수 있습니다. 따라서 Reinforcement Learning with Human Feedback(RLHF)을 사용하여 인간이 직접 모델이 내놓은 답안에 대해 순서를 매깁니다.
따라서, Human annotations 통해 "reward model"을 학습합니다.
Reward model은 인간이 매긴 순서를 통해 해당 질문과 유사한 질문이 나왔을 때, 더 순서가 높은 응답을 기반으로 result를 생성합니다. 이를 통해 언어 모델의 전반적인 품질을 향상시킬 수 있습니다.
이러한 과정을 통해 결국 모델의 품질을 향상 시키기 위해서는 인간의 참여가 중요하다는 점을 강조합니다.
3단계 사용 법 예시
주로 GPT-3와 같은 모델이 사용됩니다.
(GPT-3는 트랜스포머 아키텍처를 기반으로 한 모델로, 강화 학습을 통해 바람직한 행동을 장려하고 유해한 언어를 억제합니다. 이를 위해 인간의 피드백을 활용한 강화 학습(Reinforcement Learning with Human Feedback, RLHF)과 같은 기술을 사용합니다)
4. Three Phases. Three techniques. One improved model.
결론입니다. 모델을 학습시키기 위해서는 크게 3단계가 요구 되었습니다.
- self-supervised learning, supervised learning, reinforcement learning
Self-Supervised Learning : 모델이 언어에 대한 예측과 문장 이해를 할 수 있도록 돕습니다.
Supervised Learning : 모델이 지시를 따르고 다양한 사용자의 요구에 응답할 수 있습니다.
Reinforcement Learning : human annotation을 통해 model의 result에 대한 품질을 높일 수 있습니다.
이 단계들을 결합함으로써 대형 언어 모델(LLM)은 더 효과적이고 능력 있는 결과를 제공합니다.
여기까지가 내용입니다.
오늘 공부하면서 정리한거여서, 내용이 충분하지 않을 수 있습니다.
점차 알찬 내용으로 정리하겠습니다:)
감사합니다.
