
2018 - "Improving Language Understanding by Generative Pre-Training" (GPT)
논문 요약
Abstract
"Improving Language Understanding by Generative Pre-Training" 논문의 Abstract 부분은 다음과 같이 요약할 수 있습니다:
- 언어 이해 과제: 자연어 이해는 텍스트 함의, 질문 응답, 의미 유사성 평가, 문서 분류와 같은 다양한 작업을 포함합니다.
- 문제점: 대규모 비지도 텍스트 코퍼스는 풍부하지만, 특정 작업을 학습하기 위한 레이블이 있는 데이터는 부족하여 판별적으로 훈련된 모델이 적절히 작동하기 어렵습니다.
- 제안된 접근법: 다양한 비지도 텍스트 코퍼스에서 언어 모델을 생성적으로 사전 학습하고, 각 특정 작업에 대해 판별적으로 미세 조정하여 성능을 크게 향상시킬 수 있음을 보여줍니다. 이전 접근 방식과 달리, 모델 아키텍처의 최소한의 변경만으로도 효과적인 전이가 가능하도록 작업 인식 입력 변환을 사용합니다.
- 성능 평가: 자연어 이해를 위한 다양한 벤치마크에서 우리의 접근 방식이 효과적임을 보여줍니다. 우리의 일반적인 작업 비인지 모델은 각각의 작업을 위해 특별히 설계된 아키텍처를 사용하는 판별적으로 훈련된 모델보다 성능이 뛰어납니다. 12개의 작업 중 9개에서 새로운 최고 성능을 달성했습니다. 예를 들어, 상식적 추론(Stories Cloze Test)에서 8.9%, 질문 응답(RACE)에서 5.7%, 텍스트 함의(MultiNLI)에서 1.5%의 절대 개선을 이뤘습니다.
1. Introduction
"Improving Language Understanding by Generative Pre-Training" 논문의 "Introduction" 부분에서는 다음과 같은 주요 내용을 다룹니다:
- 비지도 학습의 중요성: 자연어 처리(NLP)에서 원시 텍스트로부터 효과적으로 학습하는 능력은 중요한데, 이는 수동으로 라벨링된 데이터에 대한 의존도를 줄여주기 때문입니다. 대부분의 심층 학습 방법은 상당한 양의 수동 라벨링 데이터가 필요하며, 이는 많은 도메인에서 적용 가능성을 제한합니다.
- 기존 문제점: 비지도 학습을 통해 단어 수준 이상의 정보를 활용하는 것은 두 가지 주요 이유로 어려운데, 첫째는 최적화 목표가 명확하지 않다는 것이고, 둘째는 학습된 표현을 목표 작업에 전이하는 방법에 대한 합의가 없다는 것입니다. 이러한 불확실성은 효과적인 반지도 학습 접근 방식을 개발하는 데 어려움을 주었습니다.
- 제안된 접근법: 비지도 사전 학습과 지도 미세 조정을 결합한 반지도 접근법을 탐구합니다. 언어 모델링 목표를 사용하여 대규모 라벨이 없는 텍스트로부터 신경망 모델의 초기 매개변수를 학습하고, 이러한 매개변수를 여러 NLP 작업에 적응시킵니다. Transformer 모델을 사용하여 장기 의존성을 처리하고, 다양한 작업에서 강력한 전이 성능을 제공합니다.
- 모델 평가: 자연어 추론, 질문 응답, 의미 유사성, 텍스트 분류와 같은 네 가지 언어 이해 작업에서 접근법을 평가했습니다. 일반적인 작업 비인지 모델이 각각의 작업을 위해 설계된 판별적으로 훈련된 모델보다 우수한 성능을 보였으며, 연구된 12개 작업 중 9개에서 새로운 최고 성능을 달성했습니다. 예를 들어, 상식적 추론(Stories Cloze Test)에서 8.9%, 질문 응답(RACE)에서 5.7%, 텍스트 함의(MultiNLI)에서 1.5%의 절대 개선을 이뤘습니다.
2. Related Work
논문의 "Related Work" 부분에서는 다음과 같은 주요 내용을 다룹니다:
반지도 학습 (Semi-supervised Learning) for NLP
- 반지도 학습의 중요성: 자연어 처리(NLP)에서 반지도 학습은 레이블이 부족한 상황에서 중요한 접근법입니다. 시퀀스 레이블링, 텍스트 분류 등의 작업에 적용되었습니다.
- 단어 임베딩: 최근 몇 년 동안, 언라벨드 코퍼스에서 학습된 단어 임베딩이 다양한 작업에서 성능을 향상시키는 데 사용되었습니다. 그러나 이러한 접근법은 주로 단어 수준 정보를 전이하는 반면, 우리는 더 높은 수준의 의미를 포착하고자 합니다.
비지도 사전 학습 (Unsupervised Pre-training)
- 비지도 사전 학습의 역할: 비지도 사전 학습은 좋은 초기화 지점을 찾기 위한 특별한 형태의 반지도 학습입니다. 초기 연구에서는 이미지 분류 및 회귀 작업에서 이 기법을 탐구했습니다. 최근에는 이미지 분류, 음성 인식, 엔티티 디스앰비규에이션, 기계 번역 등의 작업에서 딥 뉴럴 네트워크를 훈련하는 데 사용되었습니다.
- 관련 연구: 언어 모델링 목표를 사용하여 신경망을 사전 학습하고, 이를 목표 작업에 지도 학습으로 미세 조정하는 연구가 있었습니다. 그러나 LSTM 모델을 사용하는 기존 연구는 짧은 범위 예측 능력에 제한이 있습니다. 반면, Transformer 네트워크를 선택함으로써 우리는 더 긴 범위의 언어 구조를 포착할 수 있습니다.
보조 학습 목표 (Auxiliary Training Objectives)
- 보조 학습 목표의 효과: 보조 비지도 학습 목표를 추가하는 것도 반지도 학습의 한 형태입니다. 초기 연구에서는 다양한 보조 NLP 작업을 사용하여 성능을 향상시켰습니다. 최근 연구에서는 보조 언어 모델링 목표를 추가하여 시퀀스 레이블링 작업에서 성능 향상을 보였습니다.
3. Framework
"Improving Language Understanding by Generative Pre-Training" 논문의 "Framework" 부분에서는 다음과 같은 주요 내용을 다룹니다:
3.1 Unsupervised Pre-training
-
목적: 대규모 라벨이 없는 텍스트 코퍼스에서 언어 모델을 학습하여 신경망 모델의 초기 매개변수를 학습합니다.
-
언어 모델링 목표: 주어진 토큰 시퀀스 U = {u1, ..., un}에서 다음과 같은 언어 모델링 목표를 사용하여 최대화합니다:
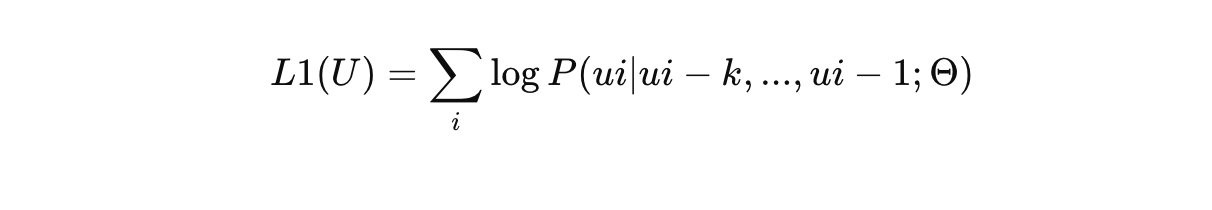
여기서 k는 컨텍스트 윈도우 크기, P는 신경망으로 모델링된 조건부 확률입니다. -
모델 아키텍처: 다층 Transformer 디코더를 사용하여 입력 컨텍스트 토큰에 대한 멀티-헤드 자기 어텐션 연산을 적용하고, 위치별 피드포워드 레이어를 통해 출력 토큰 분포를 생성합니다.
3.2 Supervised Fine-tuning
- 목적: 사전 학습된 모델 매개변수를 지도 학습 목표를 사용하여 대상 작업에 맞게 조정합니다.
- 입력과 출력: 각 인스턴스는 입력 토큰 시퀀스(x1, ..., xm)와 라벨 y로 구성됩니다. 입력은 사전 학습된 모델을 통해 전달되어 최종 Transformer 블록의 활성화 값 hml을 얻습니다. 이 활성화 값은 추가된 선형 출력 레이어를 통해 y를 예측하는 데 사용됩니다.
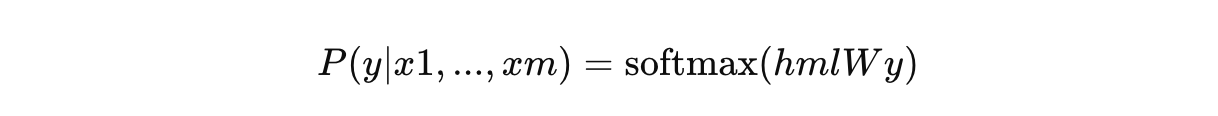
- 목표 최적화: 최종 최적화 목표는 다음과 같습니다:
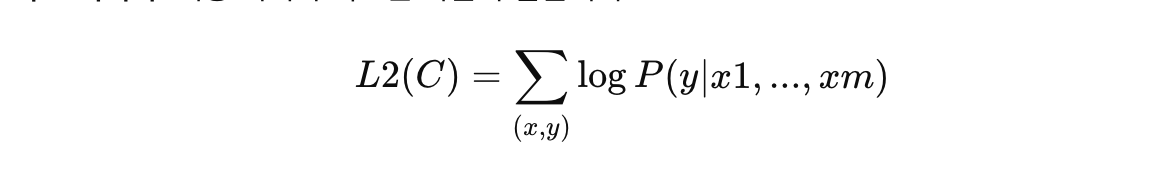
- 보조 언어 모델링 목표: 미세 조정 중에 언어 모델링을 보조 목표로 포함하여 학습을 돕습니다.
3.3 Task-specific Input Transformations
- 텍스트 분류: 직접 모델을 미세 조정합니다.
- 질문 응답 및 텍스트 함의: 구조화된 입력을 순서 있는 시퀀스로 변환하여 모델이 처리할 수 있도록 합니다. 예를 들어, 텍스트 함의 작업에서는 전제와 가설을 토큰 시퀀스로 결합하고 구분자 토큰을 추가합니다. 질문 응답 작업에서는 문서 컨텍스트와 질문을 각 가능한 답변과 결합하여 처리합니다.
4. Experiments
논문의 "Experiments" 부분에서는 BERT 모델의 성능을 평가하기 위해 다양한 실험을 수행합니다. 주요 내용은 다음과 같습니다:
4.1 Setup
- 데이터셋: BooksCorpus 데이터셋을 사용하여 언어 모델을 사전 학습합니다. 이 데이터셋은 다양한 장르의 7,000권 이상의 책으로 구성되어 있으며, 긴 연속 텍스트를 포함하고 있어 장기 의존성을 학습하는 데 유리합니다.
- 모델 사양: 12개의 레이어로 구성된 디코더 전용 Transformer 모델을 사용합니다. 모델은 768 차원의 상태와 12개의 자기 어텐션 헤드를 갖추고 있습니다.
- 최적화 방법: Adam 최적화 기법을 사용하며, 학습률은 2,000번의 업데이트 동안 선형으로 증가하고 이후에는 코사인 스케줄을 따라 감소합니다. 총 100 에포크 동안 학습합니다.
4.2 Supervised Fine-tuning
- 작업 유형: 자연어 추론(NLI), 질문 응답(QA), 의미 유사성, 텍스트 분류와 같은 다양한 지도 작업에서 성능을 평가합니다.
- 평가 결과:
- 자연어 추론: SNLI, MultiNLI, QNLI, RTE, SciTail 데이터셋에서 평가했습니다. BERT 모델은 대부분의 데이터셋에서 최고 성능을 기록했으며, 특히 MNLI에서 1.5%, SciTail에서 5%, QNLI에서 5.8%의 절대 성능 향상을 보였습니다.
- 질문 응답 및 상식적 추론: RACE 데이터셋과 Story Cloze Test에서 평가했습니다. BERT 모델은 Story Cloze Test에서 8.9%, RACE에서 5.7%의 성능 향상을 보였습니다.
- 의미 유사성: Microsoft Paraphrase Corpus (MRPC), Quora Question Pairs (QQP), Semantic Textual Similarity benchmark (STS-B)에서 평가했습니다. STS-B에서 1점의 절대 성능 향상을 보였습니다.
- 텍스트 분류: Corpus of Linguistic Acceptability (CoLA)와 Stanford Sentiment Treebank (SST-2)에서 평가했습니다. CoLA에서 45.4점, SST-2에서 91.3%의 정확도를 기록했습니다.
5. Analysis
"Improving Language Understanding by Generative Pre-Training" 논문의 "Analysis" 부분에서는 다음과 같은 주요 내용을 다룹니다:
1. 전이되는 레이어 수의 영향:
- MultiNLI와 RACE 작업 성능: 사전 학습된 언어 모델에서 전이되는 레이어 수가 증가함에 따라 성능이 향상되는 것을 관찰했습니다. 전이되는 레이어 수가 많을수록 성능이 꾸준히 증가하며, 특히 MultiNLI에서 최대 9%까지 성능 향상을 보였습니다. 이는 사전 학습된 모델의 각 레이어가 목표 작업을 해결하는 데 유용한 기능을 가지고 있음을 시사합니다.
2. 제로샷 성능:
-
언어 모델 사전 학습의 효과: 언어 모델 사전 학습이 다양한 작업에 유용한 기능을 학습하는 데 어떻게 도움이 되는지 이해하기 위해 제로샷 성능을 분석했습니다. 사전 학습된 모델이 다양한 작업에 유용한 언어적 지식을 습득하며, 이는 사전 학습이 진행됨에 따라 성능이 꾸준히 향상되는 것을 보여줍니다.
-
작업별 제로샷 성능: CoLA(문법성 판단), SST-2(감정 분석), RACE(질문 응답), DPRD(Winograd 스키마) 작업에서 제로샷 성능을 평가했습니다. 모델이 사전 학습 중에 유용한 언어적 지식을 학습하며, 이는 다양한 작업에서 좋은 성능으로 나타났습니다.
3. Ablation Studies:
- 보조 언어 모델 목표의 효과: 미세 조정 중 보조 언어 모델 목표를 포함한 경우와 그렇지 않은 경우를 비교했습니다. 보조 목표를 포함한 경우 NLI 작업과 QQP에서 성능이 향상되었으며, 이는 큰 데이터셋에서 특히 더 유용함을 시사합니다.
- 모델 아키텍처 비교: Transformer와 단일 레이어 2048 유닛 LSTM을 비교했습니다. LSTM을 사용할 경우 평균 성능 점수가 5.6점 감소했으며, 대부분의 작업에서 Transformer가 더 나은 성능을 보였습니다.
- 사전 학습의 중요성: 사전 학습 없이 감독된 목표 작업을 직접 훈련한 경우, 모든 작업에서 성능이 저하되었으며, 전체 모델에 비해 14.8%의 성능 감소가 나타났습니다.
6. Conclusion
"Improving Language Understanding by Generative Pre-Training" 논문의 "Conclusion" 부분에서는 다음과 같은 주요 내용을 다룹니다:
- 프레임워크 소개: 작업 비인지 모델을 통해 자연어 이해를 강화하기 위한 프레임워크를 도입했습니다. 이 프레임워크는 생성적 사전 학습과 판별적 미세 조정을 결합하여 다양한 작업에서 뛰어난 성능을 달성합니다.
- 사전 학습의 중요성: 연속된 긴 텍스트로 구성된 다양한 코퍼스에서 사전 학습을 통해 모델은 상당한 세계 지식과 장기 의존성을 처리하는 능력을 획득합니다. 이 능력은 질문 응답, 의미 유사성 평가, 함의 결정, 텍스트 분류와 같은 판별 작업을 해결하는 데 성공적으로 전이됩니다.
- 성능 향상: 제안된 접근법은 연구된 12개의 데이터셋 중 9개에서 새로운 최고 성능을 기록했습니다. 이는 생성적 사전 학습을 통해 판별 작업의 성능을 향상시키는 것이 가능하다는 것을 보여줍니다.
- 미래 연구 방향: 제안된 접근법이 새로운 비지도 학습 연구를 가능하게 하기를 희망하며, 자연어 이해뿐만 아니라 다른 도메인에서도 비지도 학습이 어떻게 그리고 언제 작동하는지에 대한 이해를 더욱 발전시키기를 기대합니다.
